Epistemic status: Half-baked at best
I have often been skeptical of the value of a) critiques against effective altruism and b) fully general arguments that seem like they can apply to almost anything. However, as I am also a staunch defender of hypocrisy, I will now hypocritically attempt to make the case for applying a fully general critique to effective altruism.
In this post, I will claim that:
- Motivated reasoning inhibits our ability to acquire knowledge and form reasoned opinions.
- Selection bias in who makes which arguments significantly exacerbates the problem of motivated reasoning
- Effective altruism should not be assumed to be above these biases. Moreover, there are strong reasons to believe that incentive structures and institutions in effective altruism exacerbate rather than alleviate these biases.
- Observed data and experiences in effective altruism support this theory; they are consistent with an environment where motivated reasoning and selection biases are rampant.
- To the extent that these biases (related to motivated reasoning) are real, we should expect the harm done to our ability to form reasoned opinions to also seriously harm the project of doing good.
I will use the example of cost-effectiveness analyses as a jumping board for this argument. (I understand that effective altruism, especially outside of global health and development, has largely moved away from explicit expected value calculations and cost-effectiveness analyses. However, I do not believe this change invalidates my argument (see Appendix B)).
I also list a number of tentative ways to counteract motivated reasoning and selection bias in effective altruism:
- Encourage and train scientific/general skepticism in EA newcomers.
- Try marginally harder to accept newcomers, particularly altruistically motivated ones with extremely high epistemic standards
- As a community, fund and socially support external (critical) cost-effectiveness analyses and impact assessments of EA orgs
- Within EA orgs, encourage and reward dissent of various forms
- Commit to individual rationality and attempts to reduce motivated reasoning
- Maybe encourage a greater number of people to apply and seriously consider jobs outside of EA or EA-adjacent orgs
- Maintain or improve the current culture of relatively open, frequent, and vigorous debate
- Foster a bias towards having open, public discussions of important concepts, strategies, and intellectual advances
Motivated reasoning: What it is, why it’s common, why it matters
By motivated reasoning, I roughly mean what Julia Galef calls “soldier mindset” (H/T Rob Bensinger):
In directionally motivated reasoning, often shortened to "motivated reasoning", we disproportionately put our effort into finding evidence/reasons that support what we wish were true.
Or, from Wikipedia:
emotionally biased reasoning to produce justifications or make decisions that are most desired rather than those that accurately reflect the evidence
I think motivated reasoning is really common in our world. As I said in a recent comment:
My impression is that my interactions with approximately every entity that perceives themself as directly doing good outside of EA* is that they are not seeking truth, and this systematically corrupts them in important ways. Non-random examples that come to mind include public health (on covid, vaping, nutrition), bioethics, social psychology, developmental econ, climate change, vegan advocacy, religion, US Democratic party, and diversity/inclusion. Moreover, these problems aren't limited to particular institutions: these problems are instantiated in academia, activist groups, media, regulatory groups and "mission-oriented" companies.
What does motivated reasoning look like in practice? In the field of cost-effectiveness analyses, it might look like this comment on a blog post about scientific conflicts of interest:
Back in the 90’s I did some consulting work for a startup that was developing a new medical device. They were honest people–they never pressured me. My contract stipulated that I did not have to submit my publications to them for prior review. But they paid me handsomely, wined and dined me, and gave me travel opportunities to nice places. About a decade after that relationship came to an end, amicably, I had occasion to review the article I had published about the work I did for them. It was a cost-effectiveness analysis. Cost-effectiveness analyses have highly ramified gardens of forking paths that biomedical and clinical researchers cannot even begin to imagine. I saw that at virtually every decision point in designing the study and in estimating parameters, I had shaded things in favor of the device. Not by a large amount in any case, but slightly at almost every opportunity. The result was that my “base case analysis” was, in reality, something more like a “best case” analysis. Peer review did not discover any of this during the publication process, because each individual estimate was reasonable. When I wrote the paper, I was not in the least bit aware that I was doing this; I truly thought I was being “objective.”
Importantly, motivated reasoning is often subtle and insidious. In the startup consultant’s case above, any given choice or estimate in the cost-effectiveness analysis seems reasonable, but the balance of all the concerns together became very improbable (“at virtually every decision point in designing the study and in estimating parameters, I had shaded things in favor of the device”).
You might think that you’re immune to such biases, or at least not very affected by them, as an EA who wants to do good and cares a lot about the truth, as a person who thinks hard about reasoning, or even as someone who read Scout Mindset and/or The Sequences and/or other texts that exhort the harms of motivated reasoning. But I think this view is too cavalier and misses the point.
Again, motivated reasoning often doesn’t look like motivated reasoning externally, and it certainly doesn’t feel like motivated reasoning from the inside. To slightly misquote the character Wanda from Bojack Horseman:
You know, it’s funny, when you look at {an EA org, your own research} with rose-colored glasses, all the red flags just look like flags.

Selection bias in who makes which arguments significantly exacerbates the problem of motivated reasoning
The problem of motivated reasoning doesn’t just stop at the individual level. At a collective level, even if your own prior beliefs are untainted by motivated reasoning (e.g. because you don’t care about the results at all) your information environment is adversarially selected by who holds which opinions and who chooses to voice them.
For example, I was chatting with a friend who works in cryptocurrency trading, and he pointed out that the business propositions of pretty much all of the startups joining this space only really make sense if you think bitcoin (BTC) will go up by >5x (or at least assign sufficiently high probability to BTC going up by ~5x or more). Thus, even if you think everybody individually has unbiased estimates of the value of BTC (a big “if”!), nonetheless, the selection of people working in this space will basically only include people who are very optimistic (relative to otherwise identical peers) about the future of bitcoin.
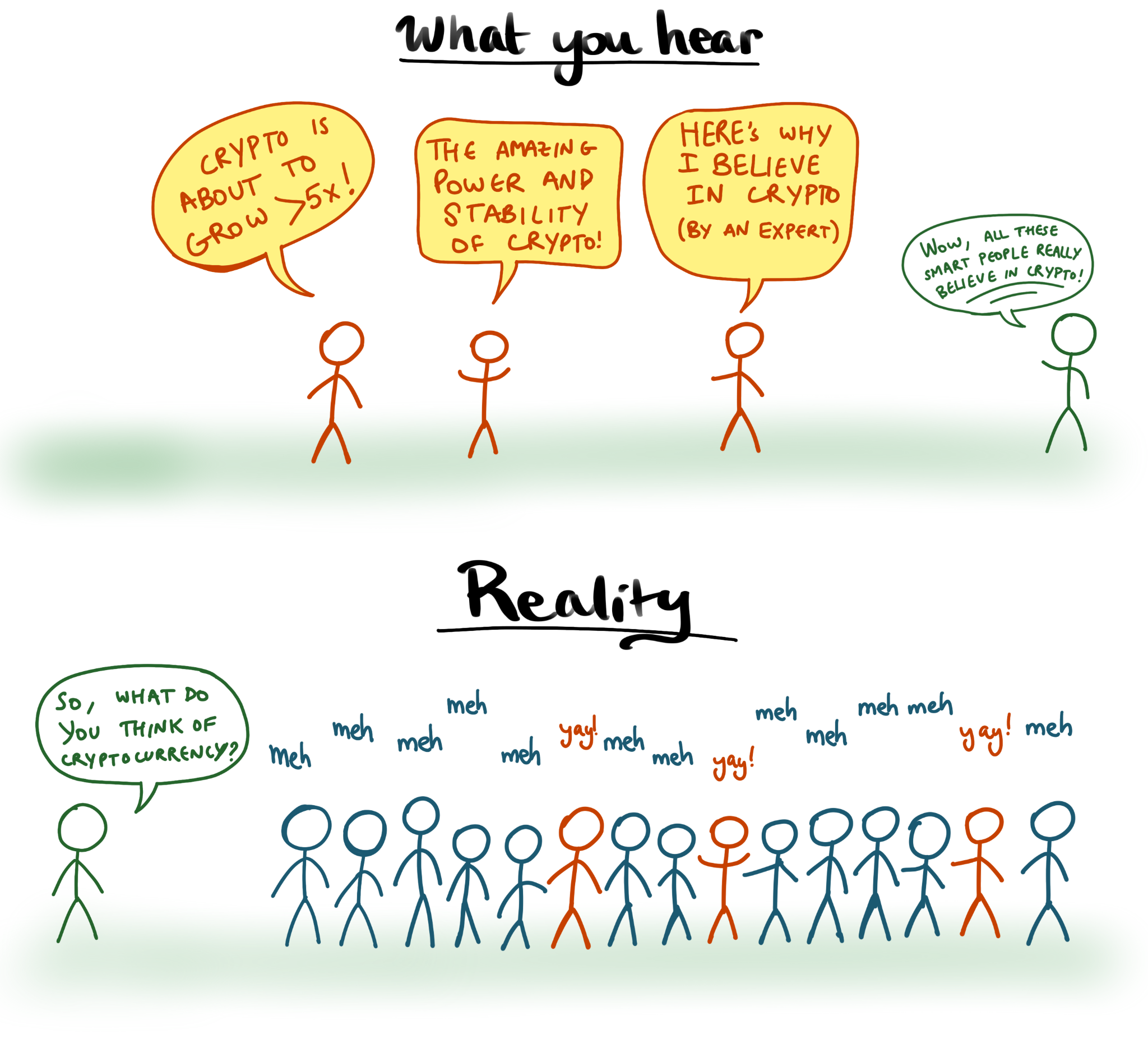
Similarly, studies about medical interventions or social psych will be selectively biased by being more likely to be conducted by people who believe in them (“experimenter effects”), analysis about climate change (or other cause areas) will be selectively conducted by people who think climate change (or other cause areas) are unusually important and tractable, etc.
Note that the problem is not just an issue of who holds which beliefs but also who chooses to voice them. Suppose for the sake of the argument that 100 smart people initially have unbiased (but noisy) priors about whether cryptocurrency is valuable. If our beliefs about cryptocurrency were formed by an unweighted poll, we may hope to take advantage of crowd wisdom and get, if not true, then at least unbiased beliefs about cryptocurrency[1]. But instead, the only beliefs you’re likely to hear are from true believers (and a few curmudgeons with their own idiosyncratic biases), which sharply biases your views (unless you have a very careful search).

Similarly, consider again the medical device startup consultant’s case above. Suppose we’re trying to decide whether the medical device is cost-effective and we read 5 different cost-effectiveness analyses (CEAs). Then, “the process works” if many people have different biases (including but not limited to motivated reasoning) but these biases are uncorrelated with each other. But this is probably not what happens. Instead, we are much more likely to read studies that are motivated (whether by funding or by ideology) by people with sharp and unusual prior beliefs about the effectiveness of such a device.
Aside on how “enemy action” can exacerbate perfectly innocent selection bias.
Suppose there are “innocent” reasoners for specific questions, that is, people who are not ideologically or otherwise motivated by the question at hand, and independently come up with unbiased (but high variance) analyses of a given issue. In a naive epistemic environment, we’ll hear all of these analyses (or a random selection of them) and our collective epistemic picture will be ideologically unbiased (though of course can still be wrong because of variance or other issues).
But our epistemic environment is often not naive. Instead, it’s selection biased by funding that makes more profitable opinions be more public (as with the startup CEA example above), by publication norms that makes surprising and/or ideologically soothing “discoveries'' more likely to be published, by media reporting, by hiring (including tenure) in academia and think tanks, and so forth.
A toy model to ponder is considering a situation where money tends to increase political success and all political donations are anonymous. I claim that even if the politicians do not do anything untoward, it is sufficiently concerning merely if a) there are initially differing opinions on a range of political issues and b) money differentially helps certain candidates succeed or have their voices amplified. These factors combined would effectively result in regulatory capture, without any specific individual doing anything obviously wrong.
Effective altruism should not be assumed to be above these biases
The following sections pertain mainly to a) longtermism, b) community building, c) prioritization of new interventions and/or causes, and to a lesser extent, d) animal welfare. I have not recently followed the EA global poverty space enough to weigh in on that front, but I would guess these biases apply (to a lesser degree) there as well. Unfortunately, I am of course not an expert on a)-d) either.
Perhaps you might consider these biases (motivated reasoning and argument-generation selection bias) an unfortunate state of affairs for the world at large, but not a major problem for effective altruism. I think the strongest argument against that perspective is to consider that, before you look at the data (next section), our broad prior should very strongly be that these are large issues. Further, if we take into account specific features of effective altruism, we should probably become more worried, not less.
First, consider what exacerbates motivated reasoning. If I were to hypothesize a list of criteria for common features of directionally motivated reasoning, especially within communities, I’d probably include features like:
- Strong ideological reasons to believe in a pre-existing answer before searching further (consider mathematical modeling of climate change or coronavirus lockdowns vs pure mathematics)
- Poor/infrequent feedback loops and low incentives to arrive at the truth (consider PR/brand consulting vs sales[2])
- A heavily insular group without much contact with sufficiently high-status outsiders who have dissenting opinions (consider a presidential cabinet vs a parliamentary deliberative body)
Unfortunately, effective altruism is on the wrong side of all these criteria.
At this point, astute readers may have noticed that my list is itself not balanced. I did not include features that look favorable for effective altruism. For example our culture of relatively open, frequent, and vigorous debate. However, at least among important+obvious features I can easily generate after a quick 10-20 minutes of introspection, I think the balance of features makes EA look worse rather than better. Readers may be interested in generating their own lists and considering this situation for themselves.
We now consider selection bias. I think it is relatively uncontroversial that the current composition of EA suffers from selection effects, and this is true since the very beginning (possible search terms include “EA monoculture” and “diversity and inclusion in effective altruism”). The empirics of the situation are rarely debated. Instead, there is a robust secondary literature on whether and to what degree specific axes of diversity (e.g. talent, opinion, experience, appearance) are problems, and whether and to what degree specific proposed solutions are useful.
I will not venture a position on the overall debate here. However, I will note that selection effects in EA’s composition are not necessarily much evidence for selection bias in EA’s conclusions. For example, if you were to learn that almost all EA organizational leaders have the same astrological sign, you should not then make a strong update towards EA organization’s cause prioritization being heavily selection biased, as horoscopes and birthdays are not known to be related to cause prioritization. To argue that selection effects may have important selection biases in our conclusions, we should probably believe that these effects are upstream of differing conclusions. [3]
I will venture a specific selection effect to consider: that most prominent arguments we hear in EA are made by people who work in EA or EA-aligned orgs, or people in our close orbit. For example, consider the question of the value of working in EA orgs. In addition to the usual issues of motivated reasoning (people would like to believe that their work and those of their friends are important), there are heavy selection biases in who chooses to work in EA orgs. Akin to the cryptocurrency example above, EA orgs are primarily staffed by true believers of EA org work! For example, the largest and loudest purveyor of EA career advice is staffed by people who work in an EA org, and unsurprisingly comes to the conclusion that work in an EA organization is very impactful.
(I find this issue a hard one to consider, as I inside-view strongly buy that much EA org work is quite valuable, mostly through what I perceive to be an independent assessment, and have said things to that effect. Nonetheless, it would be collectively dishonest for our community to not collectively acknowledge this significant selection bias in who makes which arguments, and how often they say it)
We cannot rule out motivated reasoning and selection bias being common in EA
Theory aside, should we be worried about these biases in practice? That is, does the data confirm that these biases are common and pernicious?
Unfortunately, to give a full treatment of this issue, one would need to do a careful, balanced, and comprehensive look at the data for all (or a representative sample of) the cost-effectiveness analysis or other arguments in EA. Due to time constraints, I am far from able to give a fully justified treatment here. Instead, I will argue a much weaker claim: that the limited data I’ve looked at so far is consistent with a world where motivated reasoning and selection bias are common in EA arguments in practice. In Bayesian terms, I’m trying to answer P(Evidence|Hypothesis) and not P(Hypothesis|Evidence).
Recall again the definition of motivated reasoning:
reasoning to produce justifications or decisions that are most desired rather than those that accurately reflect the evidence
In worlds where motivated reasoning is commonplace, we’d expect to see:
- Red-teaming will discover errors that systematically slant towards an organization’s desired conclusion.
- Deeper, more careful reanalysis of cost-effectiveness or impact analyses usually points towards lower rather than higher impact.
In other words, error alone is not evidence for motivated reasoning. Motivated reasoning (especially frequent motivated reasoning) instead implies that initial estimates are biased (in the statistical sense) estimates.
Let’s consider a few cause areas in EA to see whether the data is consistent with the motivated reasoning hypothesis.
Meta-EA:
EA orgs, including my own (Rethink Priorities), frequently do internal cost-effectiveness analyses (CEAs) or looser and more qualitative “impact assessments.” I don’t think I’ve read any of them in careful detail, so I don’t have definitive evidence of motivated reasoning, but the following seems consistent with a motivated reasoning world:
- To the best of my knowledge, internal CEAs rarely if ever turn up negative. I.e., people almost never say after evaluation that the org’s work isn’t worth the money or staff time.
- (Un?)fortunately, the existing evidence is also consistent with a world where EA orgs do end up doing unusually impactful work. However, the observed evidence does not preclude heavy motivated reasoning, at least without a much more careful look.
- There are few if any careful and public evaluations of meta-EA work a) in general or b) by people not connected via funding or social connections to the specific EA orgs being evaluated.
Some more loose evidence (note I have not read their impact assessments carefully, also note that at least in Giving What We Can’s case, their direction and leadership has substantially changed since the quoted impact assessment was calculated):
- 80,000 Hours was somewhat credulous in their initial evaluation of the expected counterfactual strength of career changes.
Ajeya Cotra – a senior research analyst at Open Philanthropy – followed up with some people who made some of the top plan changes mentioned in our 2018 review, and found that when asked more detailed questions about the counterfactual (what would have happened without 80,000 Hours), some of them reported a significantly smaller role for 80,000 Hours than what we claimed in our evaluation.
- The median case of Giving What We Can If (2015)’s “realistic impact calculation” has three large issues
- The impact of future donations are time-discounted using numbers from UK Green Book (3.5%), but
- EAs can’t borrow at anywhere near 3.5%
- we can get higher expected returns from the stock market, especially with leverage and
- Around the same time the impact calculation was made(2015), EA orgs were estimating (arguably correct, in retrospect) a ~10-20% implicit discount rate (from MIRI, but I’ve seen similar numbers from other orgs) for donating now to them vs later
- So overall, 3.5% seems like a suspiciously low discount rate for donations in 2015.
- The impact of GWWC is discounted by a) counterfactual impact of people maybe donating even without the pledge and b) by the raw attrition rate
- But the two interface poorly: the raw attrition rate is likely an underestimate of the marginal attrition rate of people persuaded to donate by Giving What We Can!
- Giving What We Can estimates an annual attrition rate of 5%, which in retrospect is overly optimistic
- While it may have been hard to know at the time, the actual annualized attrition rate of Giving What We Can members over 5 years is closer to 17%, >3x the estimated attrition rate.
- While it may have been hard to know at the time, the actual annualized attrition rate of Giving What We Can members over 5 years is closer to 17%, >3x the estimated attrition rate.
- The impact of future donations are time-discounted using numbers from UK Green Book (3.5%), but
(H/T Alexander Gordon-Brown for both examples, some details are filled in by me)
More broadly, I’m moderately concerned that insufficient attention is paid to people’s likely counterfactuals. In (meta-)EA, it is often implicitly assumed that career plan/donation changes are either positive or neutral as long as the changes are a) actions consistent broadly with EA and b) carefully considered.
I agree that this might be what we think in expectation, but I think reality has a lot of noise, and we should only be at most 75% or so confident that meta-org inspired changes for any given individual is actually positive, which cuts expected impact of orgs by another factor of 2 or so (made-up numbers).

Animals
When I look at more recent criticisms of Animal Charity Evaluator (ACE)'s cost-effectiveness analyses (e.g., Halstead (2018)), I think motivated reasoning is a very plausible explanation. In particular, the observed data (errors much more biased towards higher rather than lower estimates) is consistent with a world where ACE researchers really wanted animal charities to have a very high impact. Now this was written in 2018, and hopefully ACE has improved since then, so it feels unfair to penalize ACE too much for past mistakes. Nonetheless, from a purely forecasting or Bayesian perspective, the past is a good and mostly unbiased predictor of the future, so we should not assume that ACE has improved a lot in research quality before we get sufficient evidence to that effect.
Similarly, the Good Food Institute (GFI), an alternative proteins research/advocacy org, has recently (2021) funded a mission-aligned consultancy to do what’s called a “techno-economic analysis (TEA)” for the feasibility of mass-produced cultured meat, which attracted a ton of external attention (e.g, 40k karma on reddit). The result unsurprisingly came out to be much more positive than an earlier, more careful, analysis from a more skeptical source directly funded by Open Phil. This seems consistent with a story of both motivated reasoning and selection bias. (EDIT 2021/09/25: I've spent significant time researching both the CE Delft and Humbird studies professionally, see Cultured meat: A comparison of techno-economic analyses
for some tentative conclusions).
Longtermism:
I haven’t done an exhaustive search, but I’m not aware of many cost-effectiveness analyses in this space (despite nominally working in this area). One of the few commendable exceptions I’m aware of is Alliance to Feed the Earth in Disasters (ALLFED)’s own cost-effectiveness analysis.
A moderately rigorous review by an unconnected third party resulted in noticeably lower numbers for cost-effectiveness. This appears consistent with a story of motivated reasoning, where “Deeper, more careful reanalysis of cost-effectiveness or impact analyses usually points towards lower rather than higher impact.”
EDIT: I mentioned ALLFED because it's one of the few publicly available cost-effectiveness analyses, so it looks like ALLFED got hit particularly hard, but as the reviewer puts it:
I don't think they're uniquely terrible, but rather uniquely transparent.
I think this is worth keeping in mind, and make sure we consume transparency responsibly.
This subsection may seem shorter and less damning than the other subsections, but I note this is more due to lack of data than to active evidence against motivated reasoning. I consider the lack of cost-effectiveness analyses a bug, not a feature, as I will discuss in Appendix B.
New causes:
When Giving Green launched, it very quickly became an apparent EA darling. People were linking the post a lot, some people were making donations according to Giving Green’s recommendations, and peripheral EA orgs like High Impact Athletes were recommending Giving Green. Giving Green even got positive reception in the Atlantic and the EA-aligned Vox vertical Future Perfect.
As far as I can tell, Giving Green’s research quality was mediocre at best. As this critique puts it:
What this boils down to is that in every case where I investigated an original recommendation made by Giving Green, I was concerned by the analysis to the point where I could not agree with the recommendation.
(NB: I did not independently evaluate the original sources.)
Note that an org starting out and making mistakes while finding its feet is not itself a large issue. I’m a big fan of experimentation and trying new and hard things! But the initially uncritical acceptance of the EA community is suspicious: I do not believe this error is random.
Neither the existence of errors nor the credulity of accepting errors at face value is itself strong evidence of motivated reasoning. For the motivated reasoning case to stick, we need to believe in e.g., personal, ideological, etc. biases for wanting to believe in the results of certain analysis and thus being less likely to check your work when the “results” agree with your predetermined conclusions (cf. motivated stopping, isolated demands for rigor), or on a community level, the same thing happening where the group epistemic environment is more conducive to believing new arguments or evidence that are ideologically favorable or otherwise palatable (e.g. having a climate change charity to donate to that doesn’t sound “weird”).
Unfortunately, I believe both things (motivated reasoning in the research conclusions and in the community’s easy acceptance of them) have happened here.
(An aside: I’m out-of-the-loop enough and I don’t have direct evidence of these problems (motivated reasoning and selection bias) being significant in the global health and development space. However, I note that when some developmental economists venture out to do something new in climate change, these problems immediately rear up. This to me is moderate evidence for motivated reasoning and selection bias also being rampant in that cause area. I also think there is motivated reasoning in human neartermism’s marketing/PR (e.g. here). Motivated reasoning in marketing/PR is not itself definitive evidence of bad research or low epistemic quality, but it is indicative. So I’d be quite surprised if the global health and development space is immune to such worries.)
Why motivated reasoning and selection bias are bad for effective altruism
Truth is really important to the project of doing lots and lots of impartial good, and motivated reasoning harms truth. For example, see this post by Stefan Schubert about why truth-seeking is especially important for utilitarianism:
Once we turn to application, truth-seeking looms large. Unlike many other ethical theories, and unlike common-sense morality, utilitarianism requires you maximise positive impact. It requires you to advance the well-being of all as effectively as possible. How to do that best is a complex empirical question. You need to compare actions and causes which are fundamentally different. Investments in education need to be compared with malaria prevention. Voting reform with climate change mitigation. Prioritising between them is a daunting task.
And it’s made even harder by utilitarian impartiality. It’s harder to estimate distant impact than to estimate impact on those close to us. So the utilitarian view that distance is ethically irrelevant makes it even more epistemically challenging. That’s particularly true of temporal impartiality. Estimating the long-run impact of our present actions presents great difficulties.
So utilitarianism entails that we do extensive research, to find out how to maximise well-being. But it’s not enough that we put in the hours. We also need to be guided by the right spirit. There are countless biases that impede our research. We fall in love with our pet hypotheses. We refuse to change our mind. We fail to challenge the conventional wisdom of the day. We’re vain, and we’re stubborn. To counter those tendencies, utilitarians need a spirit of honest truth-seeking.
I believe a similar argument can be made for effective altruism.
That said, I want to be careful here. It’s theoretically consistent for you to believe a) truth is really important to EA and b) motivated reasoning is harmful for truth but c) motivated reasoning isn’t a big deal for the EA project.
However, I do not personally believe reasons to explain this discrepancy, whether alone or in aggregate, to be sufficiently strong. I briefly sketch out my reasoning in appendix A.
Tentative ways to counteract motivated reasoning and selection biases in effective altruism
I’m not very confident that I’ve identified the right problem, and even less confident that I could both identify the right problem and come up with the right solutions to it. (There’s a graveyard of failed attempts to solve perceived systematic problems in EA, and I do not view myself as unusually special). Nevertheless, here are a few attempts:
- Encourage and train scientific/general skepticism in EA newcomers. Every year, we have an influx of newcomers, some of whom are committed and care about the same things we do, and some of whom are very good at reasoning, but who are on average not captivated by the same biases and sunk costs that plague veteran EAs. If we introduce them to EA through a lens of scientific and general skepticism (e.g. introductions via red-teaming, also see some thoughts from Buck about deference), we may hope to get fresh perspectives and critiques that do not share all of our biases.
- Try marginally harder to accept newcomers, particularly altruistically motivated ones with extremely high epistemic standards, and/or outsiders from other backgrounds, experiences, and worldviews than is typical in EA. This can be done by directing more resources (including money, highly talented people, institutional prestige, and management capacity) towards recruiting such people. While there are other costs and benefits to EA growth, I think on balance specific types of growth are helpful for reducing our internal groupthink, motivated reasoning, and heavy selection biases in how EA conversations are engaged.
- As a community, fund and socially support critical and external cost-effectiveness analyses and impact assessments of EA orgs. (Cf. Jepsen for EA?) Too high a fraction of cost-effectiveness analyses and impact assessments are conducted internally by EA orgs right now (or occasionally by people in the close orbit of such orgs). We should instead have a norm where the community as a whole fund and socially support relatively independent parties (e.g. EA consultants) to do impact assessments of relatively core orgs like CEA, 80k, EA Funds, GPI, FHI, Rethink Priorities, ACE, GiveWell, Founder’s Pledge, Effective Giving, Longview, CHAI, CSET, etc. (Conspicuously missing from my list is Open Phil. Unfortunately, I perceive the funding situation in EA for pretty much all orgs and individual researchers to be so tied to Open Phil that I do not think it’s realistic to expect to see independent/unmotivated analyses or critiques of Open Phil.)
- Within EA orgs, encourage and reward dissent of various forms, including critical in-house reviews of various research and strategy docs. Rethink Priorities has a fairly strong/critical internal review culture for research, and I’ve benefited a lot from the (sometimes harsh, usually fair) reviews of my own writings. Other orgs should probably consider this as well if they don’t already do so. That said, I expect org employees to have strategic blindspots about macro-level issues with e.g., their org’s theories of change, so while internal dissent, disagreement, review and criticism may improve research quality and microstrategy, it should be insufficient to counteract org-wide motivated reasoning and/or mistaken worldviews.
- Commit to individual rationality and attempts to reduce motivated reasoning. Notes on how to reduce motivated reasoning include Julia Galef’s Scout Mindset (which I have not read) and my own scattered notes here. Aside from the institutional benefits, I think having less motivated reasoning is individually really helpful in improving the quality of and reducing the bias in e.g., individual research and career decisions. That said, we should be wary of surprising and suspicious convergence, and I am in general suspicious of exhortations to solving institutional epistemic issues by appealing to individual sacrifice. So while I think people should strive to reduce motivated reasoning in their own thinking/work, I do not believe this individual solution should be a frontline solution to our collective problems.
- Maybe encourage a greater number of people to apply and seriously consider jobs outside of EA or EA-adjacent orgs. I think it is probably an unfortunate epistemic situation that many of our most committed members primarily work in a very small and niche set of organizations. So there’s an argument that it will be good if committed members are more willing to work elsewhere, purely to help counteract our own motivated reasoning and selection bias issues. Unfortunately, I personally strongly buy the arguments that for most people, working within core EA organizations can accomplish a lot of good relative to their likely counterfactuals, so I hesitate to broadly advise that people who can work in core EA orgs not do so.
- Maintain or improve the current culture of relatively open, frequent, and vigorous debate. I think this is one of the strongest reasons for why motivated reasoning hasn’t gotten much worse in our community, and it will be good to sustain it.
- Bias towards having open, public discussions of important concepts, strategies, and intellectual advances. Related to the above point, there may well be many good specific reasons against having public discussions of internal concepts (a canonical list is here). However, subjecting our arguments/conclusions to greater scrutiny is probably on balance helpful for a) truth-seeking b) making sure we don’t get high on our own supply and c) improving collective rather than just individual intellectual advancement (cf. The Weapon of Openness). So all else equal, we should probably bias towards more rather than less openness, particularly for non-sensitive issues.
Thanks to Alexander Gordon-Brown, Michael Aird, Neil Dullaghan, Andrea Lincoln, Jake Mckinnon, and Adam Gleave for conversations that inspired this post. Thanks also to Charles Dillon, @mamamamy_anona, Michael St.Jules, Natália Mendonça, Adam Gleave, David Moss, Janique Behman, Peter Wildeford, and Lizka Vaintrob for reading and giving comments on earlier drafts of this post.
I welcome further comments, analyses, and critiques.
Appendices and Endnotes
Appendix A: Quick sketch of “If you think truth is in general necessary for EA, and you think motivated reasoning limits truth, you should be worried about motivated reasoning in EA.”
This part may sound tautological. But the argument does have holes. I do not plug all the holes here, but briefly sketch why I think the balance of considerations should strongly point in favor of this argument.
It’s theoretically consistent for you to believe a) truth is really important to EA and b) motivated reasoning is harmful for truth but c) motivated reasoning isn’t a big deal for the EA project.
For example, you may believe that
- Motivated reasoning is a problem for truth-seeking in EA but we have so many other problems that harm truth-seeking that motivated reasoning is not high on the list.
- Truth in general is really important for EA but the specific ways that motivated reasoning causes us to diverge from the truth are irrelevant to doing good.
- Motivated reasoning is just another bias (in the statistical sense). Once identified, you (whether individual grantmakers or the community overall) can adjust for statistical biases.
For 1), you might imagine that there are many causes of error other than motivated reasoning (for example, we might just be really bad at arithmetic for reasons unrelated to wanting certain arithmetic conclusions to be true). So if motivated reasoning is just one of many many other errors of equal import harming our truth-seeking, we should not give it special weight.
My rejoinder here is that I just think it’s empirically very implausible that there are many (say >10) other errors with equal or greater importance to motivated reasoning.
(I also place some weight on the claim that the EA movement is on average smarter than many other epistemic groups [citation needed], and most errors being lower for smarter people while motivated reasoning is uncorrelated or even positively correlated with intelligence. That said, I don’t buy this argument too strongly compared to empirical observations/intuitions of the relevant error rates.)
For 2), you might imagine that motivated reasoning is common in EA but while truth in general is really important for EA, motivated-reasoning specific biases are nearly irrelevant (analogy: if an alternative EA movement had a pervasive bias towards rhyming statements, we would not automatically conclude that this particular rhyming bias will be massively harmful to Rhyme EA’s epistemology).
I just find this very very implausible since motivated reasoning seems to cut at the critical points of importance in EA -- impartially evaluating donation and career opportunities, and other “big deals” for large groups of moral patients. So I just don’t think it’s plausible that motivated reasoning isn’t unusually harmful for the prospect of doing impartial good, never mind that it’s unusually benign.
For 3), you may think that commonplace motivated reasoning is just a predictable feature of the world, and like other predictable features good Bayesians learn to adjust for it and have a fairly accurate view of the truth regardless.
I think this is probably the strongest argument against this section of my post. However, I think while this argument attenuates the strength of my post, it doesn’t counteract my post because to believe adjustment is enough, we need to assume that the degree of bias is uniform or at least highly predictable. I do think there’s a real effect from adjustments that mitigate the harms of motivated reasoning somewhat but a) such adjustments are costly in effort and b) the degree of bias is not infinitely predictable, so we’re likely somewhat less collectively accurate due to motivated reasoning, in both theory and practice.
That said, I have not constructed an exhaustive list of reasons why you may believe that motivated reasoning is both common and in practice not a big deal for EA (comments welcome!). Nonetheless, I will contend that it would be surprising, in worlds where motivated reasoning and selection bias is common in EA, for such biases to turn out to actually not be that big a deal.
Appendix B: Not using cost-effectiveness analyses does not absolve you of these problems
Most of my examples above have been made with reference to cost-effectiveness analyses.
Now, the EA movement has largely moved away from explicit cost-effectiveness analyses in recent years, especially outside the global health and development space. For example, in ACE’s charity evaluation criteria, “cost effectiveness” is only 1 of things they look for when evaluating a charity.
Similarly, in longtermism, a recent post argued forcibly against the use of cost-effectiveness/expected value calculations for longtermism, saying:
Expected value calculations[1], the favoured approach for EA decision making, are all well and good for comparing evidence backed global health charities, but they are often the wrong tool for dealing with situations of high uncertainty, the domain of EA longtermism.
Most of the posts’ comments were critical, but they didn’t positively argue against EV calculations being bad for longtermism. Instead they completely disputed that EV calculations were used in longtermism at all!
(To check whether my general impressions from public EA conversations matches private work, I briefly discussed with 3 EA grantmakers about what they see as the role of cost-effectiveness analyses in their own work. What they said is consistent with the picture painted above).
So overall it doesn’t appear that explicit cost-effectiveness analyses (outside of neartermism) are used much in EA anymore. Instead, decisions within effective altruism seem primarily to be made with reference to good judgment, specific contextual factors, and crucial considerations.
I’m sure there are very good reasons (some stated, some unstated) for moving away from cost-effectiveness analysis. But I’m overall pretty suspicious of the general move, for a similar reason that I’d be suspicious of non-EAs telling me that we shouldn’t use cost-effectiveness analyses to judge their work, in favor of say systematic approaches, good intuitions, and specific contexts like lived experiences (cf. Beware Isolated Demands for Rigor):
I’m sure you have specific arguments for why in your case quantitative approaches aren’t very necessary and useful, because your uncertainties span multiple orders of magnitude, because all the calculations are so sensitive to initial assumptions, and so forth. But none of these arguments really point to verbal heuristics suddenly (despite approximately all evidence and track records to the contrary) performing better than quantitative approaches.
In addition to the individual epistemic issues with verbal assessments unmoored by numbers, we also need to consider the large communicative sacrifices made by not having a shared language (mathematics) to communicate things like uncertainty and effect sizes. Indeed, we have ample evidence that switching away from numerical reasoning when communicating uncertainty is a large source of confusion.To argue that in your specific situation, verbal judgment is superior without numbers than with numbers, never mind that your proposed verbal solutions obviates the biases associated with trying to do numerical cost-effectiveness modeling of the same, the strength of your evidence and arguments needs to be overwhelming. Instead, I get some simple verbal heuristic-y arguments, and all of this is quite suspicious.
{kind=link}
Or more succinctly:
It’s easy to lie with numbers, but it’s even easier to lie without them
So overall I don’t think moving away from explicit expected value calculations and cost-effectiveness analyses is much of a solution, if at all, for motivated reasoning or selection biases in effective altruism. Most of what it does is makes things less grounded in reality, less transparent and harder to critique (cf. “Not Even Wrong”).
Endnotes
[1] Examples in this post are implicitly critical of the epistemics of cryptocurrency optimists, but in the interest of full disclosure, >>90% of my own current net worth is in cryptocurrency (long story).
[2] Both are "social" tasks but sales has a clear deliverable, good incentives, and feedback loops. It is much more ambiguous what it means to successfully maintain a brand or reputation.
[3] A reviewer noted one potential complication: if you find that EA has a highly suspicious compositional bias, then this is some reason to be suspicious about bias in our conclusions, even if the compositional bias itself seems unrelated to our conclusions. e.g. if all EA leaders have red hair, even if you are confident red hair does not influence conclusions, it is evidence that there was some other selection effect that may be related to conclusions.
Of course it’s possible that “highly-suspicious” compositional biases were arrived at by chance. Maybe what matters more is how probable it is that the observed bias (e.g. all red hair) represents a real source of selection bias (e.g. all the staff are all part of a particular pre-existing red-hair heavy social network) rather than just random chance, and that the selection bias be probably related to something epistemic.
I’ve been on the EA periphery for a number of years but have been engaging with it more deeply for about 6 months. My half-in, half-out perspective, which might be the product of missing knowledge, missing arguments, all the usual caveats but stronger:
Motivated reasoning feels like a huge concern for longtermism.
First, a story: I eagerly adopted consequentialism when I first encountered it for the usual reasons; it seemed, and seems, obviously correct. At some point, however, I began to see the ways I was using consequentialism to let myself off the hook, ethically. I started eating animal products more, and told myself it was the right decision because not doing so depleted my willpower and left me with less energy to do higher impact stuff. Instead, I decided, I’d offset through donations. Similar thing when I was asked, face to face, to donate to some non-EA cause: I wanted to save my money for more effective giving. I was shorter with people because I had important work I could be doing, etc., etc.
What I realized when I looked harder at my behavior was that I had never thought critically about most of these “trade-offs,” not even to check whether they were actually trade-offs! I was using consequentialism as a license to do whatever I wanted to do anyway, and it was easy to do that because it’s harder for every day consequentialist decisions to be obviously incorrect, the way deontological ones can be. Hand-wavey, “directionally correct” answers were just fine. It just so happened that nearly all of my rough cost-benefit analyses turned up the answers I wanted to hear.
I see a similar issue taking root in the longtermist community: It’s so easy to collapse into the arms of “if there’s even a small chance X will make a very good future more likely …” As with consequentialism, I totally buy the logic of this! The issue is that it’s incredibly easy to hide motivated reasoning in this framework. Figuring out what’s best to do is really hard, and this line of thinking conveniently ends the inquiry (for people who want that). My perception is that “a small chance X helps” is being invoked not infrequently to justify doing whatever work the invoker wanted to do anyway, and to excuse them internally from trying to figure out impact relative to other available options.
Longtermism puts an arbitrarily heavy weight on one side of the scales, so things look pretty similar no matter what you’re comparing it to. (Speaking loosely here: longtermism isn’t one thing, not all people are doing this, etc. etc.) Having the load-bearing component of a cost-benefit analysis be effectively impossible to calculate is a huge downside if you’re concerned about “motivational creep,” even if there isn’t a better way to do that kind of work.
I see this as an even bigger issue because, as I perceive it, the leading proponents of longtermism are also sort of the patron saints of EA generally: Will MacAskill, Toby Ord, etc. Again, the issue isn’t that those people are wrong about the merits of longtermism — I don’t think that — it’s that motivated reasoning is that much easier when your argument pattern-matches to one they’ve endorsed. I’m not sure if the model of EA as having a “culture of dissent” is accurate in the first place, but if so it seems to break down around certain people and certain fashionable arguments/topics.
I have seen something like this happen, so I'm not claiming it doesn't, but it feels pretty confusing to me. The logic pretty clearly doesn't hold up. Even if you accept that "very good future" is all that matters, you still need to optimize for the action that most increases the probability of a very good future, and that's still a hard question, and you can't just end the inquiry with this line of thinking.
Yeah I'm surprised by this as well. Both classical utilitarianism (in the extreme version, "everything that is not morally obligatory is forbidden") and longtermism just seem to have many lower degrees of freedom than other commonly espoused ethical systems, so it would naively be surprising if these worldviews can justify a broader range of actions than close alternatives.
I liked the post. Some notes:
Oh I agree. Do you think it's worth editing my post to make that clearer?
Yeah, I'd appreciate that.
Thanks, done.
Can you say a bit more about the first point? Do you think of cases of EA groups that where too disagreeable and paranoid to be sustained or cases of the opposite sort? Or maybe cases where motivated reasoning was targeted directly?
How so? I hadn't gotten this sense. Certainly we still do lots of them internally at Open Phil.
Re: cost-effectiveness analyses always turning up positive, perhaps especially in longtermism. FWIW that hasn't been my experience. Instead, my experience is that every time I investigate the case for some AI-related intervention being worth funding under longtermism, I conclude that it's nearly as likely to be net-negative as net-positive given our great uncertainty and therefore I end up stuck doing almost entirely "meta" things like creating knowledge and talent pipelines.
It might be helpful if you published some more of these to set a good example.
They do discuss some of these and have published a few here, though I agree it would be cool to see some for longtermism (the sample BOTECs are for global health and wellbeing work).
I guess no one is really publishing these CEAs, then?
Do you also have CEAs of the meta work you fund, in terms of AI risk reduction/increase?
Is this for both technical AI work and AI governance work? For both, what are the main ways these interventions are likely to backfire?
Some quick thoughts: I would guess that Open Phil is better at this than other EA orgs, both because of individually more competent people and much better institutional incentives (ego not wedded to specific projects working). For your specific example, I'm (as you know) new to AI governance, but I would naively guess that most (including competence-weighted) people in AI governance are more positive about AI interventions than you are.
Happy to be corrected empirically.
(I also agree with Larks that publishing a subset of these may be good for improving the public conversation/training in EA, but I understand if this is too costly and/or if the internal analyses embed too much sensitive information or models)
I immediately thought of GiveWell's Why We Can't take EV Calculations Literally Even When They're Unbiased: https://blog.givewell.org/2011/08/18/why-we-cant-take-expected-value-estimates-literally-even-when-theyre-unbiased/
Except this comes all the way from 2011 so can't really be used to strongly argue EA has recently moved away from explicit EV calculations. It looks more likely that strong skepticism of explicit EV calculations has been a feature of the EA community since its inception.
Here's one example of an EA org analyzing the effectiveness of their work, and concluding the impact sucked:
CFAR in 2012 focused on teaching EAs to be fluent in Bayesian reasoning, and more generally to follow the advice from the Sequences. CFAR observed that this had little impact, and after much trial and error abandoned large parts of that curriculum.
This wasn't a quantitative cost-effectiveness analysis. It was more a subjective impression of "we're not getting good enough results to save the world, we can do better". CFAR did do an RCT which showed disappointing results, but I doubt this was CFAR's main reason for change.
These lessons percolated out to LessWrong blogging, which now focuses less on Bayes theorem and the Sequences, but without calling a lot of attention to the less.
I expect that most EAs who learned about CFAR after about 2014 underestimate the extent to which CFAR's initial strategies were wrong, and therefore underestimate the evidence that initial approaches to EA work are mistaken.
Another two examples off the top of my head:
It might be orthogonal to the point you're making, but do we have much reason to think that the problem with old-CFAR was the content? Or that new-CFAR is effective?
Thanks a lot! Is there a writeup of this somewhere? I tend to be a pretty large fan of explicit rationality (at least compared to EAs or rationalists I know), so evidence that reasoning in this general direction is empirically kind of useless would be really useful to me!
The original approach was rather erratic about finding high value choices, and was weak at identifying the root causes of the biggest mistakes.
So participants would become more rational about flossing regularly, but rarely noticed that they weren't accomplishing much when they argued at length with people who were wrong on the internet. The latter often required asking embarrassing questions their motives, and sometimes realizing that they were less virtuous than assumed. People will, by default, tend to keep their attention away from questions like that.
The original approach reflected trends in academia to prioritize attention on behaviors that were most provably irrational, rather than on what caused the most harm. Part of the reason that CFAR hasn't documented their successes well is they've prioritized hard-to-measure changes.
tl;dr: I think the 3 greatest issues of my post are: 1) My post treated "EAs" as a monolith, rather than targeting the central core of EA. 2) My post targeted actions, but EA has much more a problem with inaction than action. 3) I'm not aware of useful results/outcomes from the post, so it mostly wasted time.
It's been a year since the post was written. Here are the strongest criticisms of this post that was surfaced to me privately:
I think both criticisms are valid. My main response to them is something like "I agree my critique is biased/less useful for those reasons, but man, it sure seems hard to criticize the things you mentioned. So while streetlight effect is formally wrong, there's a meta-critique here where it's hard to have a surface to attack/criticize because a) private reasoning made by core EAs is hard to criticize and b) inaction is hard to criticize."
That said, I think both a) and b) are somewhat in the process of self-correction. I think more decisions/reasoning by core EAs are made public than they used to be, and also EAs have a greater bias towards action than than they did before 2021.
The biggest self-critique of the post is less conceptual than empirical: I think this post generated a lot of heat. But I'm not aware of useful results from the post (e.g. clearer thinking on important decisions, better actions, etc). So I think it wasn't a particularly useful post overall, and likely not worth either my time writing it or readers' time reading it.
Going forwards, I will focus my critiques to be more precise and action-oriented, with clearer/more precise recommendations for how individuals or organizations can change.
I have also privately received some criticisms/feedback about my post that I think were lower importance or quality.
I think you might be overinterpreting the lack of legible useful results from the post.
I think trying to write all critiques such that they're precise and action-oriented is a mistake, leaving much value on the table.
I agree that 1) is possible, but I don't think it's likely that there are many large actions that were changed as a result, since I'd have heard of at least one. One thing that drives my thinking here is that EA is just a fairly small movement in absolute terms, and many/most decisions are made by a small subset of people. If I optimized for a very public-facing forum (e.g. made a TikTok or internet meme convincing people to be vegetarian) I'd be less sure information about its impact would've reached me. (But even then it'd be hard to claim e.g. >100 made large dietary changes if I can't even trace 1)
For 2), I agree improving discourse is important and influential. I guess I'm not sure what the sign is. If it gets cited a bunch but none of the citations ended up improving people's quality of thinking or decisions, then this just multiplies the inefficiency. In comparison I think my key numbers question post, while taking substantially less time from either myself or readers, likely resulted in having changes to the discourse in a positive way (making EA more quantitative). It's substantially less splashy, but I think this is what intellectual/cultural progress looks like.
I also think the motivated reasoning post contributed to EA being overly meta, though I think this is probably a fair critique for a large number of my posts and/or activities in general.
For 3), if I understand your perspective correctly, a summary is that my post will foreseeably not have a large positive impact if it's true. (and presumably also not much of an impact if it's false). I guess if a post foreseeably will not have large effects commiserate with the opportunity costs, then this is more rather than less damning on my own judgement.
Regarding 1, I agree that it's unlikely that your post directly resulted in any large action changes. However, I would be surprised if it didn't have small effects on many people, including non-EAs or non-core EAs socially distant from you and other core members, and helped them make better decisions. This looks more like many people making small updates rather than a few big actions. To use the animal example, the effect is likely closer to a lot of people becoming a bit warmer to animal welfare and factory farming mattering rather than a few people making big dietary changes. While sometimes this may lead to no practical effect (e.g. the uptick in sympathy for animal welfare dies down after a few months without leading to any dietary or other changes), in expectation the impact is positive.
Regarding 3, that's not exactly what I meant. The post highlights big, persistent problems with EA reasoning and efforts due to structural factors. No single post can solve these problems. But I also think that progress on these issues is possible over time. One way is through increasing common knowledge of the problem - which I think your post does a great job of making progress on.
I think the most actionable thing people could have done would be requesting more feedback/criticism/red teaming from less aligned individuals (e.g. non-EAs, EAs focusing on other causes, skeptics of the specific cause), like the EA Criticism and Red Teaming Contest. Maybe the thing to do with the highest value of information per unit of effort is ask whether this contributed to the decision to hold the contest?
Your post was cited in the announcement: https://forum.effectivealtruism.org/posts/8hvmvrgcxJJ2pYR4X/announcing-a-contest-ea-criticism-and-red-teaming
Looks like the Red Team Challenge
https://forum.effectivealtruism.org/posts/DqBEwHqCdzMDeSBct/apply-for-red-team-challenge-may-7-june-4
was inspired by
https://forum.effectivealtruism.org/posts/obHA95otPtDNSD6MD/idea-red-teaming-fellowships
which has a hat tip to your shortform, not this post
https://forum.effectivealtruism.org/posts/myp9Y9qJnpEEWhJF9/linch-s-shortform?commentId=hedmemCCrb4jkviAd
The EA Criticism and Red Teaming Contest pre-announcement also cites your shortform comment
https://forum.effectivealtruism.org/posts/Fx8pWSLKGwuqsfuRQ/pre-announcing-a-contest-for-critiques-and-red-teaming#fn6yusgtf8c3i
Meta-comment: I noticed while reading this post and some of the comments that I had a strong urge to upvote any comment that was critical of EA and had some substantive content. Introspecting, I think this was partly due to trying to signal-boost critical comments because I don't think we get enough of those, partly because I agreed with some of those critiques, ... but I think mostly because it feels like part of the EA/rationalist tribal identity that self-critiquing should be virtuous. I also found myself being proud of the community that a critical post like this gets upvoted so much - look how epistemically virtuous we are, we even upvote criticisms!
On the one hand that's perhaps a bit worrying - are we critiquing and/or upvoting critiques because of the content or because of tribal identity? On the other hand, I suppose if I'm going to have some tribal identity then being part of a tribe where it's virtuous to give substantive critiques of the tribe is not a bad starting place.
But back on the first hand, I wonder if this would be so upvoted if it came from someone outside of EA, didn't include things about how the author really agrees with EA overall, and perhaps was written in a more polemical style. Are we only virtuously upvoting critiques from fellow tribe members, but if it came as an attack from outside then our tribal defense instincts would kick in and we would fight against the perceived threat?
[EDIT: To be clear, I am not saying anything about this particular post. I happened to agree with a lot of the content in the OP, and I have voiced these and related concerns several times myself.]
I've noted similar patterns, and think that criticisms of EA sometimes get more attention than they deserve. I wrote on related themes here.
(I think this particular post - the OP - makes a good point, however.)
Some other concerns that seem to me to be consistent with motivated reasoning in animal welfare have been:
cage-free is better for egg-laying hens and thatslower growing breeds are better for chickens farmed for meat. There are of course arguments/considerations for each, but I haven't seen anyone (publicly) carefully weigh the considerations against, i.e.higher mortality in egg-laying hens in cage-free systems,more meat chickens alive at any moment to produce the same amount of meat with broiler reforms. I think these issues are being addressed now, through the work of https://welfarefootprint.org/.https://www.openphilanthropy.org/focus/us-policy/farm-animal-welfare/how-will-hen-welfare-be-impacted-transition-cage-free-housing
Hmm, I guess I hadn't read that post in full detail (or I did and forgot about the details), even though I was aware of it. I think the argument there that mortality will roughly match some time after transition is pretty solid (based on two datasets and expert opinion). I think there was still a question of whether or not the "short-term" increase in mortality outweighs the reduction in behavioural deprivation, especially since it wasn't clear how long the transition period would be. This is a weaker claim than my original one, though, so I'll retract my original claim.
FWIW, although this is completely different claim, bone fracture is only discussed in that post as a potential cause of increased mortality in cage-free systems, but not as a source of additional pain regardless of mortality that could mean cage-free is worse and would remain worse. The post was primarily focused on mortality and behavioural deprivation/opportunities. Fractures have since been weighted explicitly here (from https://welfarefootprint.org/research-projects/laying-hens/).
My pithy critique of effective altruism is that we have turned the optimizer's curse into a community.
Thanks for posting Linch. I think I've always assumed a level of motivated reasoning or at least a heavy dose of optimism from the EA community about the EA community, but it's nice to see it written up so clearly, especially in a way that's still warm towards the community.
Fwiw my suggestions for how to act under conditions where you know your reasoning is biased are:
I'm suspicious of 1), especially if taken too far, because I think if taken too far it would justify way too much complacency in worlds where foreseeable moral catastrophes are not only possible but probable.
Just defer to Mike Huemer. He gets from common sense mortality to veganism and anarcho-capitalism. :P
I agree with what you said and I am concerned and genuinely worried because I interpret your post as expressing sincere concerns of yours and view your posts highly and update.
At the same time, I have different models of the underlying issue and these have different predictions.
Basically, have you considered the perspective that “some EA orgs aren’t very good” to be a better explanation for the problems?
This model/perspective has very different predictions and remedies, and some of your remedies make it worse.
What does it mean to be "not motivated" or "unbiased"?
I can’t think of any strong, successful movement where there isn’t “motivated” reasoning.
I often literally say that “I am biased towards [X]” and “my ideology/aesthetics [say this]”.
That is acceptable because that’s the truth.
As far as I can tell, that is how all people, including very skilled and extraordinary people/leaders reason. Ideally (often?) it turns out the “bias” is “zero” or at least, the “leaders are right”.
I rapidly change my biases and ideology/aesthetics (or at least I think I do) when updated.
In my model, for the biggest decisions, people rarely spend effort to be “unbiased” or "unmotivated".
It’s more like, what’s the plan/vision/outcomes that I will see fulfilled with my “motivated reasoning”? How will this achieve impact?
Impractical to fix things by “adding CEA” or undergirding orgs with dissent and positivism
My models of empiricism says it's hard to execute CEAs well. There isn't some CEA template/process that we can just apply reliably. Even the best CEA or RCTs involve qualitative decisions that have methods/worldviews embedded. Think of the Science/AER papers that you have seen fall apart in your hands.
Also, in my model, one important situation is that sometimes leaders and organizations specifically need this “motivated” reasoning.
This is because, in some sense, all great new initiatives are going to lack a clear cost effectiveness formula. It takes a lot of “activation energy” to get a new intervention or cause area going.
Extraordinary leaders are going to have perspectives and make decisions with models/insights that are difficult to verify, and sometimes difficult to even conceptualize.
CEA or dissent isn’t going to be helpful in these situations.
Promoting empiricism or dissent may forestall great initiatives and may create environments where mediocre empiricism supports mediocre leadership.
It seems like we should expect the supply of high quality CEA or dissent to be as limited as good leadership.
I interpret your examples as evidence for my model:
How would we fix the above, besides "getting good"?
As another example, ALLFED may have gotten dinged in a way that demonstrates my concern:
It seems likely that the underlying issues that undermine success on the object level would also make “meta” processes just as hard to execute, or worse.
As mentioned at the top, this isn’t absolving or fixing any problems you mentioned. Again, I share the underlying concerns and also update to you.
Maybe an alternative? Acknowledge these flaws?
A sketch of a solution might be:
1) Choose good leaders and people
2) Have knowledge of the “institutional space” being occupied by organizations, and have extraordinarily high standards for those that can govern/interact/filter the community
3) Allow distinct, separate cause areas and interventions to flourish and expect some will fail
This is just a sketch and there’s issues (how do you adequately shutdown and fairly compensate interests who fail, because non-profits and especially meta-orgs often perpetuate their own interests, for good reasons. We can’t really create an "executioner org" or rely on orgs getting immolated on the EA forum).
I think the value of this sketch is that it draws attention to the institutional space occupied by orgs and how it affects the community.
I think what you said is insightful and worth considering further. Nonetheless, I will only address a specific subpoint for now, and revisit this later.
Hmm I'm not sure what you mean, and I think it's very likely we're talking about different problems. But assuming we're talking about the same problems, at a high-level any prediction problem can be decomposed to bias vs error (aka noise, aka variance).
I perceive that many of the issues I've mentioned to be better explained by bias than error. In particular I just don't think we'll see equivalently many errors in the opposite direction. This is an empirical question however, and I'd be excited to see more careful followups to test this hypothesis.
(as a separate point, I do think some EA orgs aren't very good, with "very good" defined as I'd rather the $s be spent on their work rather than in Open Phil coffers, or my own bank account. I imagine many other EAs would feel similarly about my own work).
Hi,
Thank you for your thoughtful reply. I think you are generous here:
I think you are pointing out that, when I said I think I have many biases and these are inevitable, that I am confusing bias with error.
What you are pointing out seems right to me.
Now, at the very least, this undermines my comment (and at the worst suggests I am promoting/suffering from some other form of arrogance). I’m less confident about my comment now. I think now I will reread and think about your post a lot more.
Thanks again.
Hi. I'm glad you appear to have gained a lot from my quick reply, but for what it's worth I did not intend my reply as an admonishment.
I think the core of what I read as your comment is probably still valid. Namely, that if I misidentified problems as biases when almost all of the failures are due to either a) noise/error or b) incompetence unrelated to decision quality (eg mental health, insufficient technical skills, we aren't hardworking enough), then the bias identification isn't true or useful. Likewise, debiasing is somewhere between neutral to worse than useless if the problem was never bias to begin with.
I like this post. Some ideas inspired by it:
If "bias" is pervasive among EA organisations, the most direct implication of this seems to me to be that we shouldn't take judgements published by EA organisations at face value. That is, if we want to know what is true we should apply some kind of adjustment to their published judgements.
It might also be possible to reduce bias in EA organisations, but that depends on other propositions like how effective debiasing strategies actually are.
A question that arises is "what sort of adjustment should be applied?". The strategy I can imagine, which seems hard to execute, is: try to anticipate the motivations of EA organisations, particularly those that aren't "inform everyone accurately about X", and discount those aspects of their judgements that support these aims.
I imagine that doing this overtly would cause a lot of offence A) because it involves deliberately standing in the way of some of the things that people at EA organisations want and B) because I have seen many people react quite negatively to accusations "you're just saying W because you want V".
Considering this issue - how much should we trust EA organisations - and this strategy of trying to make "goals-informed" assessments of their statiments, it occurs to me that a question you could ask is "how well has this organisation oriented themselves towards truthfulness?".
I like that this post has set out the sketch of a theory of organisation truthfulness. In particular
"In worlds where motivated reasoning is commonplace, we’d expect to see:
Presumably, in worlds where motivated reasoning is rare, red-teaming will discover errors that slant towards and away from an organisation's desired conclusion and deeper, more careful reanalysis of cost-effectiveness points towards lower and higher impact equally often.
I note that you are talking about a collection of organisations while I'm talking about a specific organisation. I think you are thinking about it from "how can we evaluate truth-alignment" and I'm thinking about "what do we want to know about truth-alignment". Maybe it is only possible to evaluate collections of organisations for truth-alignment. At the same time I think it would clearly be useful to know about the truth-alignment of individual organisations, if we could.
It would be interesting, and I think difficult, to expand this theory in three ways:
To be clear, I'm not saying these things are priorities, just ideas I had and haven't carefully evaluated.
Thanks for your extensions! Worth pondering more.
I think this is first-order correct (and what my post was trying to get at). Second-order, I think there's at least one important caveat (which I cut from my post) with just tallying total number (or importance-weighted number of) errors towards versus away from the desired conclusion as a proxy for motivated reasoning. Namely, you can't easily differentiate "motivated reasoning" biases from perfectly innocent traditional optimizer's curse.
Suppose an organization is considering 20 possible interventions and do initial cost-effectiveness analyses for each of them. If they have a perfectly healthy and unbiased epistemic process, then the top 2 interventions that they've selected from that list would a) in expectation be better than the other 18 and b) in expectation will have more errors slanted towards higher impact rather than lower impact.
If they then implement the top 2 interventions and do an impact assessment 1 year later, then I think it's likely the original errors (not necessarily biases) from the initial assessment will carry through.
External red-teamers will then discover that these errors are systematically biased upwards, but at least on first blush "naive optimizer's curse issues" looks importantly different in form, mitigation measures, etc, from motivated reasoning concerns.
I think it's likely that either formal Bayesian modeling or more qualitative assessments can allow us to differentiate the two hypotheses.
Here's one possible way to distinguish the two: Under the optimizer's curse + judgement stickiness scenario retrospective evaluation should usually take a step towards the truth, though it could be a very small one if judgements are very sticky! Under motivated reasoning, retrospective evaluation should take a step towards the "desired truth" (or some combination of truth an desired truth, if the organisation wants both).
Overall great post, and I broadly agree with the thesis. (I'm not sure the evidence you present is all that strong though, since it too is subject to a lot of selection bias.) One nitpick:
I think you're (unintentionally) running a motte-and-bailey here.
Motte: Longtermists don't think you should build explicit quantitative models, take their best guess at the inputs, chug through the math, and do whatever the model says, irrespective of common sense, verbal arguments, model uncertainty, etc.
Bailey: Longtermists don't think you should use numbers or models (and as a corollary don't consider effectiveness).
(My critical comment on that post claimed the motte; later I explicitly denied the bailey.)
Oh I absolutely agree. I generally think the more theoretical sections of my post are stronger than the empirical sections. I think the correct update from my post is something like "there is strong evidence of nonzero motivated reasoning in effective altruism, and some probability that motivated reasoning + selection bias-mediated issues are common in our community" but not enough evidence to say more than that.
I think a principled follow-up work (maybe by CEA's new epistemics project manager?) would look like combing through all (or a statistically representative sample of) impact assessments and/or arguments made in EA, and try to catalogue them for motivated reasoning and other biases.
I think this is complicated. It's certainly possible I'm fighting against strawmen!
But I will just say what I think/believe right now, and others are free to correct me. I think among committed longtermists, there is a spectrum of trust in explicit modeling, going from my stereotype of weeatquince(2020)'s views to maybe 50% (30%?) of the converse of what you call the "motte."(Maybe Michael Dickens(2016) is closest?). My guess is that longtermist EAs ( like almost all humans) have never been that close to purely quantitative models guiding decisions, and we've moved closer in the last 5 years to reference classes of fields like the ones that weeatquince's post pulls from.
I also think I agree with MichaelStJules' point about the amount of explicit modeling that actually happens relative to effort given to other considerations. "Real" values are determined not by what you talk about, but by what tradeoffs you actually make.
I agree with the literal meaning of that, because it is generally a terrible idea to just do what a purely quantitative model tells you (and I'll note that even GiveWell isn't doing this). But imagining the spirit of what you meant, I suspect I disagree.
I don't think you should collapse it into the single dimension of "how much do you use quantitative models in your decisions". It also matters how amenable the decisions are to quantitative modeling. I'm not sure how you're distinguishing between the two hypotheses:
(Unless you want to defend the position that longtermist questions are just as easy to model as, say, those in global poverty? That would be... an interesting position.)
Also, just for the sake of actual evidence, here are some attempts at modeling, biased towards AI since that's the space I know. Not all are quantitative, and none of them are cost effectiveness analyses.
Fwiw, my understanding is that weeatquince(2020) is very pro modeling, and is only against the negation of the motte. The first piece of advice in that post is to use techniques like assumption based planning, exploratory modeling, and scenario planning, all of which sound to me like "explicit modeling". I think I personally am a little more against modeling than weeatquince(2020).
Thanks so much for the response! Upvoted.
(I'm exaggerating my views here to highlight the differences, I think my all-things-considered opinion on these positions are much closer to yours than the rest of the comment will make it sound)
I think my strongest disagreement with your comment is the framing here:
If we peel away the sarcasm, I think the implicit framing is that
Unless I'm missing something, I think this is logically invalid. The obvious response here is that I don't think longtermist questions are more amenable to explicit quantitative modeling than global poverty, but I'm even more suspicious of other methodologies here.
Medicine is less amenable to empirical testing than physics, but that doesn't mean that clinical intuition is a better source of truth for the outcomes of drugs than RCTs. (But medicine is relatively much less amenable to theorems than physics, so it's correct to use less proofs in medicine than physics.)
More minor gripes:
I think I'm willing to bite the bullet and say that GiveWell (or at least my impression of them from a few years back) should be more rigorous in their modeling. Eg, weird to use median staff member's views as a proxy for truth, weird to have so few well-specified forecasts, and so forth.
I think we might just be arguing about different things here? Like to me, these seem more like verbal arguments of questionable veracity than something that has a truth-value like cost-effectiveness analyses or forecasting. (In contrast, Open Phil's reports on AI, or at least the ones I've read, would count as modeling).
What's the actual evidence for this? I feel like this type of reasoning (and other general things like it in the rough cluster of "injunctions against naive consequentialism") are pretty common in our community and tend to be strongly held, but when I ask people to defend it, I just see weird thought experiments and handwaved intuitions (rather than a model or a track record)?
This type of view also maps in my head to being the type of view that's a) high-status and b) diplomatic/"plays nicely" with high-prestige non-EA Western intellectuals, which makes me doubly suspicious that views of this general shape are arrived at through impartial truth-seeking means.
I also think in practice if you have a model telling you to do one thing but your intuitions tell you to do something else, it's often worth making enough updates to form a reflective equilibrium. There are at least two ways to go about this:
1) Use the model to maybe update your intuitions, and go with your intuitions in the final decision, being explicit about how your final decisions may have gone against the naive model.
2) Use your intuitions to probe which pieces your model is making, update your model accordingly, and then go with your (updated) model in the final decision, being explicit about how your final model may have been updated for unprincipled reasons.
I think you (and by revealed preferences, the EA community, including myself) usually goes with 1) as the correct form of intuition vs model reflective equilibrium. But I don't think this is backed by too much evidence, and I think we haven't really given 2) a fair shake.
Now I think in practice 1) and 2) might end up getting the same result much of the time anyway. But a) probably not all the time and b) this is an empirical question.
Yeah, I'm just way, way more suspicious of quantitative modeling relative to other methodologies for most longtermist questions.
Makes sense, I'm happy to ignore those sorts of methods for the purposes of this discussion.
You can't run an RCT on arms races between countries, whether or not AGI leads to extinction, whether totalitarian dictatorships are stable, whether civilizational collapse would be a permanent trajectory change vs. a temporary blip, etc.
It just seems super obvious in almost every situation that comes up? I also don't really know how you expect to get evidence; it seems like you can't just "run an RCT" here, when a typical quantitative model for a longtermist question takes ~a year to develop (and that's in situations that are selected for being amenable to quantitative modeling).
For example, here's a subset of the impact-related factors I considered when I was considering where to work:
I think incorporating just these factors into a quantitative model is a hell of an ask (and there are others I haven't listed here -- I haven't even included the factors for the academia vs industry question). A selection of challenges:
I think just getting a framework that incorporates all of these things is already a Herculean effort that really isn't worth it, and even if you did make such a framework, I would be shocked if you could set the majority of the inputs based on actually good reference classes rather than just "what my gut says". (And that's all assuming I don't notice a bunch more effects I failed to mention initially that my intuitions were taking into account but that I hadn't explicitly verbalized.)
It seems blatantly obvious that the correct choice here is not to try to get to the point of "quantitative model that captures the large majority of the relevant considerations with inputs that have some basis in reference classes / other forms of legible evidence", and I'd be happy to take a 100:1 bet that you wouldn't be able to produce a model that meets that standard (as I evaluate it) in 1000 person-hours.
I have similar reactions for most other cost effectiveness analyses in longtermism. (For quantitative modeling in general, it depends on the question, but I expect I would still often have this reaction.)
If you mean that the weighting on saving vs. improving lives comes from the median staff member, note that GiveWell has been funding research that aims to set these weights in a manner with more legible evidence, because the evidence didn't exist. In some sense this is my point -- that if you want to get legible evidence, you need to put in large amounts of time and money in order to generate that evidence; this problem is worse in the longtermist space and is rarely worth it.
I'm not defending what you think is a bailey, but as a practical matter, I would say until recently (with Open Phil publishing a few models for AI), longtermists have not been using numbers or models much, or when they do, some of the most important parameters are extremely subjective personal guesses or averages of people's guesses, not based on reference classes, and risks of backfire were not included.
This seems to me to not be the case. For a very specific counterexample, AI Impacts has existed since 2015.
Fair. I should revise my claim to being about the likelihood of a catastrophe and the risk reduction from working on these problems (especially or only in AI; I haven't looked as much at what's going on in other x-risks work). AI Impacts looks like they were focused on timelines.
Replied to Linch -- TL;DR: I agree this is true compared to global poverty or animal welfare, and I would defend this as simply the correct way to respond to actual differences in the questions asked in longtermism vs. those asked in global poverty or animal welfare.
You could move me by building an explicit quantitative model for a popular question of interest in longtermism that (a) didn't previously have models (so e.g. patient philanthropy or AI racing doesn't count), (b) has an upshot that we didn't previously know via verbal arguments, (c) doesn't involve subjective personal guesses or averages thereof for important parameters, and (d) I couldn't immediately tear a ton of holes in that would call the upshot into question.
I feel that (b) identifying a new upshot shouldn't be necessary; I think it should be enough to build a model with reasonably well-grounded parameters (or well-grounded ranges for them) in a way that substantially affects the beliefs of those most familiar with or working in the area (and maybe enough to change minds about what to work on, within AI or to AI or away from AI). E.g., more explicitly weighing risks of accelerating AI through (some forms of) technical research vs actually making it safer, better grounded weights of catastrophe from AI, a better-grounded model for the marginal impact of work. Maybe this isn't a realistic goal with currently available information.
Yeah, I agree that would also count (and as you might expect I also agree that it seems quite hard to do).
Basically with (b) I want to get at "the model does something above and beyond what we already had with verbal arguments"; if it substantially affects the beliefs of people most familiar with the field that seems like it meets that criterion.
The other perspective is that EA was actually able to solve Yudkowsky's Why Our Kind Can't Cooperate.
Nice post! Regarding
I'm curious what you think these strong ideological reasons are. My opinion is that EA is on the right side here on most questions. This is because in EA you get a lot of social status (and EA forum karma) for making good arguments against views that are commonly held in EA. I imagine that in most communities this is not the case. Maybe there is an incentive to think that a cause area or an intervention is promising if you want to (continue to) work within that cause area but anything you can challenge within a cause area or an intervention seems encouraged.
Speaking for myself, I think I have strong ideological reasons to think that predictably doing (lots of) good is possible.
I also have a bias towards believing that things that are good for X reason are also good for Y reason, and this problem rears itself up even when I try to correct for it. E.g. I think Linch(2012-2017) too easily bought in to the "additional consumption $s don't make you happier " narratives, and I'm currently lactovegetarian even though I started being vegetarian for very different reasons than what I currently believe to be the most important. I perceive other EAs as on average worse at this (not sure the right term. Decoupling?) than me, which is not necessarily true of the other biases on this list.
A specific instantiation of this is that it's easier for me to generate solutions to problems that are morally unambiguous by the standards of non-EA Western morality, even though we'd expect the tails to come apart fairly often.
To a lesser extent, I have biases towards thinking that doing (lots of) good comes from things that I and my friends are predisposed to be good at (eg cleverness, making money).
Another piece of evidence is that EAs seem far from immune from ideological capture for non-EA stuff. My go-to example is the SSC/NYT thing.
Really enjoyed the post. Would like clarification on something
I'm not fully following this point and would like to hear more about it. Is this suggesting that development economists over-estimate the impacts of climate change or something else? And do you have any examples (any will do, they don't have to be good) of what you've noted?
To me, modern-day development economics seems incredibly cognizant of how technocracy and grand theories could go wrong. It's therefore more rigorous (at least compared to other areas and other domains of economics). I'm curious if that rigor disappears when it comes to climate change.
I didn't mean anything special, just that IDInsight developmental economists started Giving Green and was overly credulous in a bunch of ways, as mentioned in the New causes section.