TL;DR If you believe the key claims of "there is a >=1% chance of AI causing x-risk and >=0.1% chance of bio causing x-risk in my lifetime" this is enough to justify the core action relevant points of EA. This clearly matters under most reasonable moral views and the common discussion of longtermism, future generations and other details of moral philosophy in intro materials is an unnecessary distraction.
Thanks to Jemima Jones for accountability and encouragement. Partially inspired by Holden Karnofsky’s excellent Most Important Century series.
Disclaimer: I recently started working for Anthropic, but this post entirely represents my opinions and not those of my employer
Introduction
I work full-time on AI Safety, with the main goal of reducing x-risk from AI. I think my work is really important, and expect this to represent the vast majority of my lifetime impact. I am also highly skeptical of total utilitarianism, vaguely sympathetic to person-affecting views, prioritise currently alive people somewhat above near future people and significantly above distant future people, and do not really identify as a longtermist. Despite these major disagreements with some common moral views in EA, which are often invoked to justify key longtermist conclusions, I think there are basically no important implications for my actions.
Many people in EA really enjoy philosophical discussions and debates. This makes a lot of sense! What else would you expect from a movement founded by moral philosophy academics? I’ve enjoyed some of these discussions myself. But I often see important and controversial beliefs in moral philosophy thrown around in introductory EA material (introductory pitches and intro fellowships especially), like strong longtermism, the astronomical waste argument, valuing future people equally to currently existing people, etc. And I think this is unnecessary and should be done less often, and makes these introductions significantly less effective.
I think two sufficient claims for most key EA conclusions are “AI has a >=1% chance of causing human extinction within my lifetime” and “biorisk has a >=0.1% chance of causing human extinction within my lifetime”. I believe both of these claims, and think that you need to justify at least one of them for most EA pitches to go through, and to try convincing someone to spend their career working on AI or bio. These are really weird claims. The world is clearly not a place where most smart people believe these! If you are new to EA ideas and hear an idea like this, with implications that could transform your life path, it is right and correct to be skeptical. And when you’re making a complex and weird argument, it is really important to distill your case down to the minimum possible series of claims - each additional point is a new point of inferential distance, and a new point where you could lose people.
My ideal version of an EA intro fellowship, or an EA pitch (a >=10 minute conversation with an interested and engaged partner) is to introduce these claims and a minimum viable case for them, some surrounding key insights of EA and the mindset of doing good, and then digging into them and the points where the other person doesn’t agree or feels confused/skeptical. I’d be excited to see someone make a fellowship like this!
My Version of the Minimum Viable Case
The following is a rough outline of how I’d make the minimum viable case to someone smart and engaged but new to EA - this is intended to give inspiration and intuitions, and is something I’d give to open a conversation/Q&A, but is not intended to be an airtight case on its own!
Motivation
Here are some of my favourite examples of major ways the world was improved:
- Norman Borlaug’s Green Revolution - One plant scientist’s study of breeding high-yield dwarf wheat, which changed the world, converted India and Pakistan from grain importers to grain exporters, and likely saved over 250 million lives
- The eradication of smallpox - An incredibly ambitious and unprecedented feat of global coordination and competent public health efforts, which eradicated a disease that has killed over 500 million people in human history
- Stanislav Petrov choosing not to start a nuclear war when he saw the Soviet early warning system (falsely) reporting a US attack
- The industrial and scientific revolutions of the last few hundred years, which are responsible for this incredible graph.
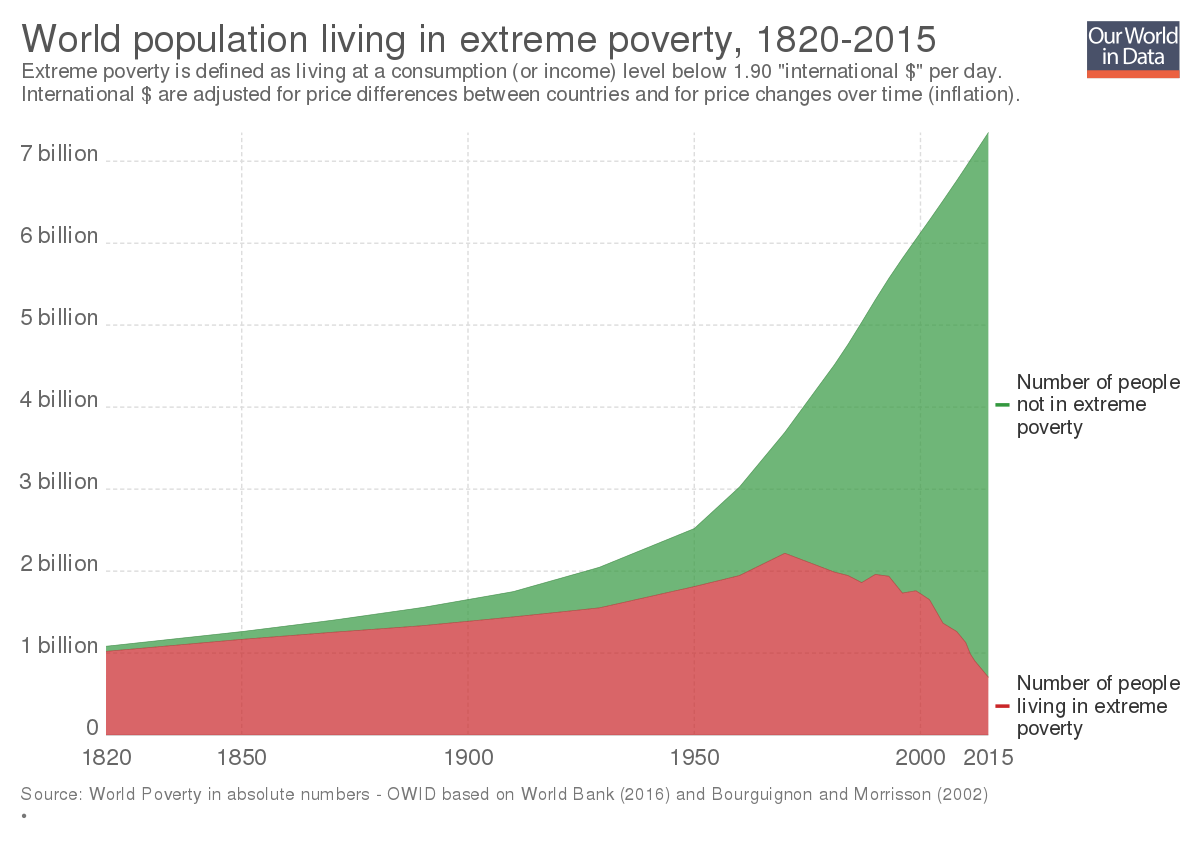
When I look at these and other examples, a few lessons become clear if I want to be someone who can achieve massive amounts of good:
- Be willing to be ambitious
- Be willing to believe and do weird things. If I can find an important idea that most people don’t believe, and can commit and take the idea seriously, I can achieve a lot.
- If it’s obvious, common knowledge, someone else has likely already done it!
- Though, on the flipside, most weird ideas are wrong - don’t open your mind so much that your brains fall out.
- Look for high-leverage!
- The world is big and inter-connected. If you want to have a massive impact, it needs to be leveraged with something powerful - an idea, a new technology, exponential growth, etc.
When I look at today’s world through this lens, I’m essentially searching for things that could become a really big deal. Most things that have been really big, world-changing deals in the past have been some kind of major emerging technology, unlocking new capabilities and new risks. Agriculture, computers, nuclear weapons, fossil fuels, electricity, etc. And when I look for technologies emerging now, still in their infancy but with a lot of potential, AI and synthetic biology stand well above the rest.
Note that these arguments work about as well for focusing on highly leveraged positive outcomes or negative outcomes. I think that, in fact, given my knowledge of AI and bio, that there are plausible negative outcomes, and that reducing the likelihood of these is tractable and more important than ensuring positive outcomes. But I’d be sympathetic to arguments to the contrary.
AI - ‘AI has a >=1% chance of x-risk within my lifetime’
The human brain is a natural example of a generally intelligent system. Evolution produced this, despite a bunch of major constraints like biological energy being super expensive, needing to fit through birth canals, using an extremely inefficient optimisation algorithm, and intelligence not obviously increasing reproductive fitness. While evolution had the major advantage of four billion years to work with, it seems highly plausible to me that humanity can do better. And, further, there’s no reason that human intelligence should be a limit on the capabilities of a digital intelligence.
On the outside view, this is incredibly important. We’re contemplating the creation of a second intelligence species! That seems like one of the most important parts of the trajectory of human civilisation - on par with the dawn of humanity, the invention of agriculture and the Industrial Revolution. And it seems crucial to ensure this goes well, especially if these systems end up much smarter than us. It seems plausible that the default fate of a less intelligent species is that of gorillas - humanity doesn’t really bear gorillas active malice, but they essentially only survive because we want them to.
Further, there are specific reasons to think that this could be really scary! AI systems mostly look like optimisation processes, which can find creative and unexpected ways to achieve these objectives. And specifying the right objective is a notoriously hard problem. And there are good reasons to believe that such a system might have an instrumental incentive to seek power and compete with humanity, especially if it has the following three properties:
- Advanced capabilities - it has superhuman capabilities on at least some kinds of important and difficult tasks
- Agentic planning - it is capable of making and executing plans to achieve objectives, based on models of the world
- Strategic awareness - it can competently reason about the effects of gaining and maintaining power over humans and the real world
See Joseph Carlsmith’s excellent report for a much more rigorous analysis of this question. I think it is by no means obvious that this argument holds, but I find it sufficiently plausible that we create a superhuman intelligence which is incentivised to seek power and successfully executes on this in a manner that causes human extinction that I’m happy to put at least a 1% chance of AI causing human extinction (my fair value is probably 10-20%, with high uncertainty).
Finally, there’s the question of timelines. Personally, I think there’s a good chance that something like deep learning language models scale to human-level intelligence and beyond (and this is a key motivation of my current research). I find the bio-anchors and scaling based methods of timelines pretty convincing as an upper bound of timelines that’s well within my lifetime. But even if deep learning is a fad, the field of AI has existed for less than 70 years! And it takes 10-30 years to go through a paradigm. It seems highly plausible that we produce human-level AI with some other paradigm within my lifetime (though reducing risk from an unknown future paradigm of AI does seem much less tractable)
Bio - ‘Biorisk has a >=0.1% chance of x-risk within my lifetime’
I hope this claim seems a lot more reasonable now than it did in 2019! While COVID was nowhere near an x-risk, it has clearly been one of the worst global disasters I’ve ever lived through, and the world was highly unprepared and bungled a lot of aspects of the response. 15 million people have died, many more were hospitalised, millions of people have long-term debilitating conditions, and almost everyone’s lives were highly disrupted for two years.
And things could have been much, much worse! Just looking at natural pandemics, imagine COVID with the lethality of smallpox (30%). Or COVID with the age profile of the Spanish Flu (most lethal in young, healthy adults, because it turns the body’s immune system against itself).
And things get much scarier when we consider synthetic biology. We live in a world where multiple labs work on gain of function research, doing crazy things like trying to breed Avian Flu (30% mortality) that’s human-to-human transmissible, and not all DNA synthesis companies will stop you trying to print smallpox viruses. Regardless of whether COVID was actually a lab leak, it seems at least plausible that it could have come from gain-of-function research on coronaviruses. And these are comparatively low-tech methods. Progress in synthetic biology happens fast!
It is highly plausible to me that, whether by accident, terrorism, or an act of war, that someone produces an engineered pathogen capable of creating a pandemic far worse than anything natural. It’s unclear that this could actually cause human extinction, but it’s plausible that something scary enough and well-deployed enough with a long incubation period could. And it’s plausible to me that something which kills 99% of people (a much lower bar) could lead to human extinction. Biorisk is not my field and I’ve thought about this much less than AI, but 0.1% within my lifetime seems like a reasonable lower bound given these arguments.
Caveats
- These are really weird beliefs! It is correct and healthy for people to be skeptical when they first encounter them.
- Though, in my opinion, the arguments are strong enough and implications important enough that it’s unreasonable to dismiss them without at least a few hours of carefully reading through arguments and trying to figure out what you believe and why.
- Further, if you disagree with them, then the moral claims I’m dismissing around strong longtermism etc may be much more important. But you should disagree with the vast majority of how the EA movement is allocating resources!
- There’s a much stronger case for something that kills almost all people, or which causes the not-necessarily-permanent collapse of civilisation, than something which kills literally everyone. This is a really high bar! Human extinction means killing everyone, including Australian farmers, people in nuclear submarines and bunkers, and people in space.
- If you’re a longtermist then this distinction matters a lot, but I personally don’t care as much. The collapse of human civilisation seems super bad to me! And averting this seems like a worthy goal for my life.
- I have an easier time seeing how AI causes extinction than bio
- There’s an implicit claim in here that it’s reasonable to invest a large amount of your resources into averting risks of extremely bad outcomes, even though we may turn out to live in a world where all that effort was unnecessary. I think this is correct to care about, but that this is a reasonable thing to disagree with!
- This is related to the idea that we should maximise expected utility, but IMO importantly weaker. Even if you disagree with the formalisation of maximising expected value, you likely still agree that it’s extremely important to ensure that bridges and planes have safety records far better than 0.1%
- But also, we’re dealing with probabilities that are small but not infinitesimal. This saves us from objections like Pascal’s Mugging - a 1% chance of AI x-risk is not a Pascal’s Mugging.
- It is also reasonable to buy these arguments intellectually, but not to feel emotionally able to motivate yourself to spend your life reducing tail risks. This stuff is hard, and can be depressing and emotionally heavy!
- Personally, I find it easier to get my motivation from other sources, like intellectual satisfaction and social proof. A big reason I like spending time around EAs is that this makes AI Safety work feel much more viscerally motivating to me, and high-status!
- This is related to the idea that we should maximise expected utility, but IMO importantly weaker. Even if you disagree with the formalisation of maximising expected value, you likely still agree that it’s extremely important to ensure that bridges and planes have safety records far better than 0.1%
- It’s reasonable to agree with these arguments, but consider something else an even bigger problem! While I’d personally disagree, any of the following seem like justifiable positions: climate change, progress studies, global poverty, factory farming.
- A bunch of people do identify as EAs, but would disagree with these claims and with prioritising AI and bio x-risk. To those people, sorry! I’m aiming this post at the significant parts of the EA movement (many EA community builders, CEA, 80K, OpenPhil, etc) who seem to put major resources into AI and bio x-risk reduction
- This argument has the flaw of potentially conveying the beliefs of ‘reduce AI and bio x-risk’ without conveying the underlying generators of cause neutrality and carefully searching for the best ways of doing good. Plausibly, similar arguments could have been made in early EA to make a “let’s fight global poverty” movement that never embraced to longtermism. Maybe a movement based around the narrative I present would miss the next Cause X and fail to pivot when it should, or otherwise have poor epistemic health.
- I think this is a valid concern! But I also think that the arguments for “holy shit, AI and bio risk seem like really big deals that the world is majorly missing the ball on” are pretty reasonable, and I’m happy to make this trade-off. “Go work on reducing AI and bio x-risk” are things I would love to signal boost!
- But I have been deliberate to emphasise that I am talking about intro materials here. My ideal pipeline into the EA movement would still emphasise good epistemics, cause prioritisation and cause neutrality, thinking for yourself, etc. But I would put front and center the belief that AI and bio x-risk are substantial and that reducing them is the biggest priority, and encourage people to think hard and form their own beliefs
- An alternate framing of the AI case is “Holy shit, AI seems really important” and thus a key priority for altruists is to ensure that it goes well.
- This seems plausible to me - it seems like the downside of AI going wrong could be human extinction, but that the upside of AI going really well could be a vastly, vastly better future for humanity.
- There are also a lot of ways this could lead to bad outcomes beyond the standard alignment failure example! Maybe coordination just becomes much harder in a fast-paced world of AI and this leads to war, or we pollute ourselves to death. Maybe it massively accelerates technological progress and we discover a technology more dangerous than nukes and with a worse Nash equilibria and don’t solve the coordination problem in time.
- I find it harder to imagine these alternate scenarios literally leading to extinction, but they might be more plausible and still super bad!
- There are some alternate pretty strong arguments for this framing. One I find very compelling is drawing an analogy between exponential growth in the compute used to train ML models, and the exponential growth in the number of transistors per chip of Moore’s Law.
- Expanding upon this, historically most AI progress has been driven by increasing amounts of computing power and simple algorithms that leverage them. And the amount of compute used in AI systems is growing exponentially (doubling every 3.4 months - compared to Moore’s Law’s 2 years!). Though the rate of doubling is likely to slow down - it’s much easier to increase the amount of money spent on compute when you’re spending less than the millions spent on payroll for top AI researchers than when you reach the order of magnitude of figures like Google’s $26bn annual R&D - it also seems highly unlikely to stop completely.
- Under this framing, working on AI now is analogous to working with computers in the 90s. Though it may have been hard to predict exactly how computers would change the world, there is no question that they did, and it seems likely that an ambitious altruist could have gained significant influence over how this went and nudged it to be better.
- I also find this framing pretty motivating - even if specific stories I’m concerned by around eg inner alignment are wrong, I can still be pretty confident that something important is happening in AI, and my research likely puts me in a good place to influence this for the better.
- I work on interpretability research, and these kind of robustness arguments are one of the reasons I find this particularly motivating!
I think this is a good demonstration that the existential risk argument can go through without the longtermism argument. I see it as helpfully building on Carl Shulman's podcast.
To extend it even further - I posted the graphic below on twitter back in Nov. These three communities & sets of ideas overlap a lot and I think reinforce one another, but they are intellectually & practically separable, and there are people in each section doing great work. My personal approach is to be supportive of all 7 sections, but recognise just because someone is in one section doesn't mean they have to be, or are, committed to others.
My main criticism of this post is that it seems to implicitly suggest that "the core action relevant points of EA" are "work on AI or bio", and doesn't seem to acknowledge that a lot of people don't have that as their bottom line. I think it's reasonable to believe that they're wrong and you're right, but:
This is a fair criticism! My short answer is that, as I perceive it, most people writing new EA pitches, designing fellowship curricula, giving EA career advice, etc, are longtermists and give pitches optimised for producing more people working on important longtermist stuff. And this post was a reaction to what I perceive as a failure in such pitches by focusing on moral philosophy. And I'm not really trying to engage with the broader question of whether this is a problem in the EA movement. Now OpenPhil is planning on doing neartermist EA movement building funding, maybe this'll change?
Personally, I'm not really a longtermist, but think it's way more important to get people working on AI/bio stuff from a neartermist lens, so I'm pretty OK with optimising my outreach for producing more AI and bio people. Though I'd be fine with low cost ways to also mention 'and by the way, global health and animal welfare are also things some EAs care about, here's how to find the relevant people and communities'.
I think to the extent you are trying to draw the focus away from longtermist philosophical arguments when advocating for people to work on extinction risk reduction, that seems like a perfectly reasonable thing to suggest (though I'm unsure which side of the fence I'm on).
But I don't want people casually equivocating between x-risk reduction and EA, relegating the rest of the community to a footnote.
It's not enough to have an important problem: you need to be reasonably persuaded that there's a good plan for actually making the problem better, the 1% lower. It's not a universal point of view among people in the field that all or even most research that purports to be AI alignment or safety research is actually decreasing the probability of bad outcomes. Indeed, in both AI and bio it's even worse than that: many people believe that incautious action will make things substantially worse, and there's no easy road to identifying which routes are both safe and effective.
I also don't think your argument is effective against people who already think they are working on important problems. You say, "wow, extinction risk is really important and neglected" and they say "yes, but factory farm welfare is also really important and neglected".
To be clear, I think these cases can be made, but I think they are necessarily detailed and in-depth, and for some people the moral philosophy component is going to be helpful.
Thanks for this!
This seems to me like more than a caveat--I think it reverses this post's conclusions that "the common discussion of longtermism, future generations and other details of moral philosophy in intro materials is an unnecessary distraction," and disagreement on longtermism has "basically no important implications for [your, and implicitly, others'] actions."
After all, if (strong) longtermism has very big, unique implications about what cause areas people should focus on (not to mention implications about whether biosecurity folks should focus on preventing permanent catastrophes or more temporary ones)... aren't those some pretty important implications for our actions?
That seems important for introductory programs; if longtermism is necessary to make the case that AI/bio are most important (as opposed to "just" being very important), then introducing longtermism will be helpful for recruiting EAs to work on these issues.
TL;DR I think that in practice most of these disagreements boil down to empirical cruxes not moral ones. I'm not saying that moral cruxes are literally irrelevant, but that they're second order, only relevant to some people, and only matter if people buy the empirical cruxes, and so should not be near the start of the outreach funnel but should be brought up eventually
Hmm, I see your point, but want to push back against this. My core argument is essentially stemming from an intuition that you have a limited budget to convince people of weird ideas, and that if you can only convince them of one weird ideas it should be the empirical claims about the probability of x-risk, not the moral claims about future people. My guess is that most people who genuinely believe these empirical claims about x-risk will be on board with most of the action relevant EA recommendations. While people who buy the moral claims but NOT the empirical claims will massively disagree with most EA recommendations.
And, IMO, the empirical claims are much more objective than the moral claims, and are an easier case to make. I just don't think you can make moral philosophy arguments that are objectively convincing.... (read more)
Hm, I think I have different intuitions about several points.
I'm not sure this budget is all that fixed. Longtermism pretty straightforwardly implies that empirical claims about x-risk are worth thinking more about. So maybe this budget grows significantly (maybe differentially) if someone gets convinced of longtermism. (Anecdotally, this seems true--I don't know any committed longtermist who doesn't think empirical claims about x-risk are worth figuring out, although admittedly there's confounding factors.)
Maybe some of our different intuitions are also coming from thinking about different target audiences. I agree that simplifying pitches to just empirical x-risk stuff would make sense when talking to most people. Still, the people who sign up for intro programs aren't most people--they're strongly (self-)selected for interest in prioritization, interest in ethical reasoning, and for having ethically stronger competing demands on their careers.
... (read more)Suppose it takes $100 billion to increase our chance of completely averting extinction (or the equivalent) by 0.1%. By this, I don't mean averting an extinction event by having it be an event that only kills 98% of people, or preventing the disempowerment of humanity due to AI; I mean that we save the entire world's population. For convenience, I'll assume no diminishing marginal returns. If we only consider the 7 generations of lost wellbeing after the event, and compute $100 billion / (7 * 8 billion * 0.1%), then we get a cost-effectiveness of $1,780 to save a life. With the additional downside of being extremely uncertain, this estimate is only in the same ballpark as the Malaria Consortium's seasonal chemoprevention program (which takes ~$4,500 to save a life). It's also complicated by the fact that near-term animal charities, etc. are funding-constrained while longtermist orgs are not so much. Unlike a strong longtermist view, it's not at all clear under this view that it would be worthwhile to pivot your career to AI safety or biorisk, instead of taking the more straightforward route of earning to give to standard near-term interventions.
One thing I find really tricky about this is figuring out where the margin will end up in the future.
It seems likely to me that $100bn will be spent on x-risk reduction over the next 100 years irrespective of what I do. My efforts mainly top up that pot.
Personally I expect the next $10bn might well reduce x-risk by ~1% rather than 0.1%; but it'll be far less once we get into the next $90bn and then $100bn after it. It might well be a lot less than 0.1% per $10bn billion.
(I thought about it for a few more hours and haven't changed my numbers much).
I think it's worth highlighting that our current empirical best guesses (with a bunch of uncertainty) is that catastrophic risk mitigation measures are probably better in expectation than near-term global health interventions, even if you only care about currently alive people.
But on the other hand, it's also worth highlighting that you only have 1-2 OOMs to work with, so if we only care about present people, the variance is high enough that we can easily change our minds in the future. Also, e.g. community building interventions or other "meta" interventions in global health (e.g. US foreign aid research and advocacy) may be better even on our current best guesses. Neartermist animal interventions may be more compelling as well.
Finally, what axilogies you have would have implications for what you should focus on within GCR work. Because I'm personally more compelled by the longtermist arguments for existential risk reduction than neartermist ones, I'm personally comparatively more excited about disaster mitigation, robustness/resilience, and recovery, not just prevention. Whereas I expect the neartermist morals + empirical beliefs about GCRs + risk-neutrality should lead you to believe that prevention and mitigation is worthwhile, but comparatively little resources should be invested in disaster resilience and recovery for extreme disasters.
I'm not saying this consideration is overriding, but one reason you might want moral agreement and not just empirical agreement is that people who agree with you empirically but not morally may be more interested in trading x-risk points for ways to make themselves more powerful.
I don't think this worry is completely hypothetical, I think there's a fairly compelling story where both DeepMind and OpenAI were started by people who agree with a number of premises in the AGI x-risk argument but not all of them.
Fortunately this hasn't happened in bio (yet), at least to my knowledge.
I'm sympathetic to this style of approach. I attempted to do a similar "x-risk is a thing" style pitch here.
Two wrinkles with it:
Both points mean I think it is important to bring in longtermism at some point, though it doesn't need to be the opening gambit.
If I was going to try to write my article again, I'd try to mention pandemics more early on, and I'd be more cautious about the 'most people think x-risk is low' claim.
One other thing to play with: You could experiment with going even more directly for 'x-risk is a thing' and not having the lead in section on leverage. With AI, what I've been playing with is opening with Katja's survey results: "even the people developing AGI say they think it has a 10% chance of ending up with an extremely bad outcome 'e.g. extinction'." A... (read more)
Thanks, Neel, this got me thinking a bunch!
I think this approach may have a lot of benefits. But it also at least two (related) costs:
- We may miss something very core to EA: "EA is a question". EA is trying to figure out how to do the most good, and then do it. So I think that this big focus on EA as being a "prioritization-focused" movement makes it very special and if there were pitches focused directly on reducing x-risk, we would miss something very core to the movement (and I'm not sure how I feel about it). (as a personal anecdote, I think that it's the question of EA really made me able to change my mind, and move from working on development aid to climate change to AI).
- We may reduce the quality of truth-seeking/rationality/"Scout Mindset" of the movement by saying that we already have the answer. By treating EA as a question, the movement has attracted a lot of people who (I think) have interest in being rational and having good epistemic. These norms are very important. Rationality and good epistemics are very valuable to do good, so we should think about how to keep those excellent norms if we shift to a pitch which is "we know how to do the most good, and it's by re
... (read more)I guess I'm not wild about this approach, but I think it is important to consider (and sometimes use) alternative frames, so thanks for the write-up!
To articulate my worries, I suppose it's that this implies a very reductionist and potentially exclusionary idea of doing good; it's sort of "Holy shit, X-risks matters (and nothing else does)". On any plausible conception of EA, we want people doing a whole bunch of stuff to make things better.
The other bit that irks me is that it does not follow, from the mere fact that's there's a small chance of something bad happening, that preventing that bad thing is the most good you can do. I basically stop listening to the rest of any sentence that starts with "but if there's even a 1% chance that ..."
FWIW, the framing of EA I quite like are versions of "we ought to do good; doing more good is better"
Think about how hard you would try to avoid getting the next wave of COVID if it turned out it had a 1% chance of killing you. Not even 1% conditional on you getting it; 1% unconditional. (So for concreteness, imagine that your doctor at the next checkup tells you that based on your blood type and DNA you actually have a 10% chance of dying from COVID if you were to get it, and based on your current default behavior and prevalence in the population it seems like you have a 10% chance of getting it before a better vaccine for your specific blood type is developed.)
Well, I claim, you personally are more than 1% likely to die of x-risk. (Because we all are.)
I'd actually hoped that this framing is less reductionist and exclusionary. Under total utilitarianism + strong longtermism, averting extinction is the only thing that matters, everything else is irrelevant. Under this framing, averting extinction from AI is, say, maybe 100x better than totally solving climate change. And AI is comparatively much more neglected and so likely much more tractable. And so it's clearly the better thing to work on. But it's only a few orders of magnitude, coming from empirical details of the problem, rather than a crazy, overwhelming argument that requires estimating the number of future people, the moral value of digital minds, etc.
... (read more)I've seen a lot of estimates in this world that are more than 100x off so I'm also pretty unconvinced by "if there's even a 1% chance". Give me a solid reason for your estimate, otherwise I'm not interested.
Thanks for this! I think it's good for people to suggest new pitches in general. And this one would certainly allow me to give a much cleaner pitch to non-EA friends than rambling about a handful of premises and what they lead to and why (I should work on my pitching in general!). I think I'll try this.
I think I would personally have found this pitch slightly less convincing than current EA pitches though. But one problem is that I and almost everyone reading this were selected for liking the standard pitch (though to be fair whatever selection mechanism EA currently has, it seems to be pretty good at attracting smart people and might be worth preserving). Would be interesting to see some experimentation, perhaps some EA group could try this?
Thanks for the feedback! Yep, it's pretty hard to judge this kind of thing given survivorship bias. I expect this kind of pitch would have worked best on me, though I got into EA long enough ago that I was most grabbed by global health pitches. Which maybe got past my weirdness filter in a way that this one didn't.
I'd love to see what happens if someone tries an intro fellowship based around reading the Most Important Century series!
I like this pitch outline; it's straightforward, intuitive, and does a good job of explaining the core ideas. If this were to actually be delivered as a pitch I would suggest putting more focus on cognitive biases that lead to inaction (e.g. the human tendency to disbelieve that interesting/unusual/terrible things will happen in one's own lifetime, or the implicit self-concept of not being the "sort of person" who does important/impactful things in the world). These are the sorts of things that people don't bring up because they're unconscious beliefs, but they're pretty influential assumptions and I think it's good to address them.
For instance, it took me some doing to acquire the self-awareness to move past those assumptions and decide to go into x-risk even though I had known for quite a while on an intellectual level that x-risk existed. It required the same sort of introspection that it did for me to, when I was offered a PETA brochure, notice my instinctive negative reaction ("ew, PETA, what a bunch of obnoxious and sanctimonious assholes"), realize that that was a poor basis for rejecting all of their ideas, and then sit down and actually consider their arguments. I think that it is uncommon even for bright and motivated people to naturally develop that capacity, but perhaps with some prompting they can be helped along.
Yes! I've been thinking along similar lines recently. Although I have framed things a bit differently. Rather than being a top-level EA thing, I think that x-risk should be reinstated as a top level cause area it's own right, separate to longtermism, and that longtermism gives the wrong impression of having a lot of time, when x-risk is an urgent short-term problem (more).
Also, I think ≥10% chance of AGI in ≤10 years should be regarded as "crunch time", and the headlines for predictions/timelines should be the 10% estimate, not the 50% estimate, given the ... (read more)
Hi - I'm new to the forums and just want to provide some support for your point here. I've just completed the 8-week Intro to EA Virtual Pro... (read more)
Sorry I haven't watched the video but I have a feeling this argument misses the point.
People may dismiss working on AI x-risk not because the probability of x-risk is very small, but because the x-risk probability decrease we can achieve is very small, even with large amounts of resources. So I don't think it's enough to say "1% is actually kind of high". You have to say "we can meaningfully reduce this 1%".
Neel, I agree with this sentiment, provided that it does tot lead to extremist actions to prevent x-risk (see https://www.lesswrong.com/posts/Jo89KvfAs9z7owoZp/pivotal-act-intentions-negative-consequences-and-fallacious).
Specifically, I agree that we should be explicit about existential safety — and in particular, AI existential safety — as a broadly agreeable and understandable cause area that does not depend on EA, longtermism, or other niche communities/stances. This is main reason AI Research Considerations for Human Existential Safety (ARCHES; h... (read more)
It seems to me that the relevant probability is not the chance of AI x-risk, but the chance that your efforts could make a marginal difference. That probability is vastly lower, possibly bordering on mugging territory. For x-risk in particular, you make a difference only if your decision to work on x-risk makes a difference to whether or not the species survives. For some of us that may be plausible, but for most, it is very very unlikely.
I’ve arrived at this post very late, but a relevant point I’d add is that as someone with person-affecting, non totalist consequentialist views, I disagree with many of the ideas of longtermism, but working on pandemics and AI alignment still makes sense to me on ‘disaster mitigation’ grounds. I think of the big three cause areas as ‘global health and poverty, farmed animal welfare and disaster mitigation’. Also, working on pandemics fits pretty neatly as a subset of global health work.
Could someone explain to me the meaning of 'paradigm' in this context? E.g. '10-30 years to go through a paradigm'