All of Gregory Lewis's Comments + Replies
I have previously let HLI have the last word, but this is too egregious.
Study quality: Publication bias (a property of the literature as a whole) and risk of bias (particular to each individual study which comprise it) are two different things.[1] Accounting for the former does not account for the latter. This is why the Cochrane handbook, the three meta-analyses HLI mentions here, and HLI's own protocol consider distinguish the two.
Neither Cuijpers et al. 2023 nor Tong et al. 2023 further adjust their low risk of bias subgroup for publication b...
I'm feeling confused by these two statements:
Although there are other problems, those I have repeated here make the recommendations of the report unsafe.
Even if one still believes the bulk of (appropriate) analysis paths still support a recommendation, this sensitivity should be made transparent.
The first statement says HLI's recommendation is unsafe, but the second implies it is reasonable as long as the sensitivity is clearly explained. I'm grateful to Greg for presenting the analysis paths which lead to SM < GD, but it's unclear to me how much ...
So the problem I had in mind was in the parenthetical in my paragraph:
To its credit, the write-up does highlight this, but does not seem to appreciate the implications are crazy: any PT intervention, so long as it is cheap enough, should be thought better than GD, even if studies upon it show very low effect size (which would usually be reported as a negative result, as almost any study in this field would be underpowered to detect effects as low as are being stipulated)
To elaborate: the actual data on Strongminds was a n~250 study by Bolton et al. 2003 th...
(@Burner1989 @David Rhys Bernard @Karthik Tadepalli)
I think the fundamental point (i.e. "You cannot use the distribution for the expected value of an average therapy treatment as the prior distribution for a SPECIFIC therapy treatment, as there will be a large amount of variation between possible therapy treatments that is missed when doing this.") is on the right lines, although subsequent discussion of fixed/random effect models might confuse the issue. (Cf. my reply to Jason).
The typical output of a meta-analysis is an (~) average effect size estimate (...
What prior to formally pick is tricky - I agree the factors you note would be informative, but how to weigh them (vs. other sources of informative evidence) could be a matter of taste. However, sources of evidence like this could be handy to use as 'benchmarks' to see whether the prior (/results of the meta-analysis) are consilient with them, and if not, explore why.
But I think I can now offer a clearer explanation of what is going wrong. The hints you saw point in this direction, although not quite as you describe.
One thing worth being clear on is HLI is ...
HLI kindly provided me with an earlier draft of this work to review a couple of weeks ago. Although things have gotten better, I noted what I saw as major problems with the draft as-is, and recommended HLI take its time to fix them - even though this would take a while, and likely miss the window of Giving Tuesday.
Unfortunately, HLI went ahead anyway with the problems I identified basically unaddressed. Also unfortunately (notwithstanding laudable improvements elsewhere) these problems are sufficiently major I think potential donors are ill-advised t...
Thank you for your comments, Gregory. We’re aware you have strong views on the subject and we appreciate your conscientious contributions. We discussed your previous comments internally but largely concluded revisions weren’t necessary as we (a) had already considered them in the report and appendix, (b) will return to them in later versions and didn’t expect they would materially affect the results, or (c) simply don’t agree with these views. To unpack:
- Study quality. We conclude the data set does contain bias, but we account for it (sections 3.2 and 5; it
I think I can diagnose the underlying problem: Bayesian methods are very sensitive to the stipulated prior. In this case, the prior is likely too high, and definitely too narrow/overconfident.
Would it have been better to start with a stipulated prior based on evidence of short-course general-purpose[1] psychotherapy's effect size generally, update that prior based on the LMIC data, and then update that on charity-specific data?
One of the objections to HLI's earlier analysis was that it was just implausible in light of what we know of psychotherapy's e...
I think I agree with the rest of this analysis (or at least the parts I could understand). However, the following paragraph seems off:
To its credit, the write-up does highlight this, but does not seem to appreciate the implications are crazy: any PT intervention, so long as it is cheap enough, should be thought better than GD, even if studies upon it show very low effect size
Apologies if I'm being naive here, but isn't this just a known problem of first-order cost-effectiveness analysis, not with this particular analysis per se? I mean, since cheapness cou...
Seemed not relevant enough to the topic, and too apt to be highly inflammatory, to be worthwhile to bring up.
I agree - all else equal - you'd rather have a flatter distribution of donors for the diversification (various senses) benefits. I doubt this makes this an important objective all things considered.
The main factor on the other side of the scale is scale itself: a 'megadonor' can provide a lot of support. This seems to be well illustrated by your original examples (Utility Farm and Rethink). Rethink started later, but grew much 100x larger, and faster too. I'd be surprised if folks at UF would not prefer Rethink's current situation, trajectory - and fundrai...
Getting (e.g.) 5000 new people giving 20k a year seems a huge lift to me. [...] A diffuse 'ecosystem wide' benefits of these additional funders struggles by my lights to vindicate the effort (and opportunity costs) of such a push.
One problem I have with these discussions, including past discussions about why national EA orgs should have fundraising platform, is the reductionist and zero-sum thinking given in response.
I identified above, how an argument stating less donors results in more efficiency, would never be made in the for profit world. ...
I'm not sure I count as 'senior', but I could understand some reluctance even if 'all expenses paid'.
I consider my EAG(x) participation as an act of community service. Although there are diffuse benefits, I do not get that much out of it myself, professionally speaking. This is not that surprising: contacts at EAG (or knowledge at EAG, etc. etc.) matter a lot less on the margin of several years spent working in the field than just starting out. I spend most of my time at EAG trying to be helpful - typically, through the medium of several hours of 1-1...
Hello Jason,
With apologies for delay. I agree with you that I am asserting HLI's mistakes have further 'aggravating factors' which I also assert invites highly adverse inference. I had hoped the links I provided provided clear substantiation, but demonstrably not (my bad). Hopefully my reply to Michael makes them somewhat clearer, but in case not, I give a couple of examples below with as best an explanation I can muster.
I will also be linking and quoting extensively from the Cochrane handbook for systematic reviews - so hopefully even if my attempt ...
I really appreciate you putting in the work and being so diligent Gregory. I did very little here, though I appreciate your kind words. Without you seriously digging in, we’d have a very distorted picture of this important area.
8%, but perhaps expected drift of a factor of two either way if I thought about it for a few hours vs. a few minutes.
Hello Michael,
Thanks for your reply. In turn:
1:
HLI has, in fact, put a lot of weight on the d = 1.72 Strongminds RCT. As table 2 shows, you give a weight of 13% to it - joint highest out of the 5 pieces of direct evidence. As there are ~45 studies in the meta-analytic results, this means this RCT is being given equal or (substantially) greater weight than any other study you include. For similar reasons, the Strongminds phase 2 trial is accorded the third highest weight out of all studies in the analysis.
HLI's analysis explains the rationale behind t...
Hello Gregory. With apologies, I’m going to pre-commit both to making this my last reply to you on this post. This thread has been very costly in terms of my time and mental health, and your points below are, as far as I can tell, largely restatements of your earlier ones. As briefly as I can, and point by point again.
1.
A casual reader looking at your original comment might mistakenly conclude that we only used StrongMinds own study, and no other data, for our evaluation. Our point was that SM’s own work has relatively little weight, and we rely on m...
HLI - but if for whatever reason they're unable or unwilling to receive the donation at resolution, Strongminds.
The 'resolution criteria' are also potentially ambiguous (my bad). I intend to resolve any ambiguity stringently against me, but you are welcome to be my adjudicator.
[To add: I'd guess ~30-something% chance I end up paying out: d = 0.4 is at or below pooled effect estimates for psychotherapy generally. I am banking on significant discounts with increasing study size and quality (as well as other things I mention above I take as adverse indi...
[Own views]
- I think we can be pretty sure (cf.) the forthcoming strongminds RCT (the one not conducted by Strongminds themselves, which allegedly found an effect size of d = 1.72 [!?]) will give dramatically worse results than HLI's evaluation would predict - i.e. somewhere between 'null' and '2x cash transfers' rather than 'several times better than cash transfers, and credibly better than GW top charities.' [I'll donate 5k USD if the Ozler RCT reports an effect size greater than d = 0.4 - 2x smaller than HLI's estimate of ~ 0.8, and below the bottom 0.1%
Could you say a bit more about what you mean by "should not have maintained once they were made aware of them" in point 2? As you characterize below, this is an org "making a funding request in a financially precarious position," and in that context I think it's even more important than usual to be clear about HLI has "maintained" its "mistakes" "once they were made aware of them." Furthermore, I think the claim that HLI has "maintained" is an important crux for your final point.
Example: I do not like that HLI's main donor advice page lists the 77 WELLBY p...
Hi Greg,
Thanks for this post, and for expressing your views on our work. Point by point:
- I agree that StrongMinds' own study had a surprisingly large effect size (1.72), which was why we never put much weight on it. Our assessment was based on a meta-analysis of psychotherapy studies in low-income countries, in line with academic best practice of looking at the wider sweep of evidence, rather than relying on a single study. You can see how, in table 2 below, reproduced from our analysis of StrongMinds, StrongMinds' own studies are given relatively little we
edited to that I only had a couple of comments rather than 4
I am confident those involved really care about doing good and work really hard. And i don't want that to be lost in this confusion. Something is going on here, but I think "it is confusing" is better than "HLI are baddies".
For clarity being 2x better than cash transfers would still provide it with good reason to be on GWWC's top charity list, right? Since GiveDirectly is?
I guess the most damning claim seems to be about dishonesty, which I find hard to square with the caliber of the team. So, what...
I suspect the 'edge cases' illustrate a large part of the general problem: there are a lot of grey areas here, where finding the right course requires a context-specific application of good judgement. E.g. what 'counts' as being (too?) high status, or seeking to start a 'not serious' (enough?) relationship etc. etc. is often unclear in non-extreme cases - even to the individuals directly involved themselves. I think I agree with most of the factors noted by the OP as being pro tanto cautions, but aliasing them into a bright line classifier for what is or i...
The issue re comparators is less how good dropping outliers or fixed effects are as remedies to publication bias (or how appropriate either would be as an analytic choice here all things considered), but the similarity of these models to the original analysis.
We are not, after all, adjusting or correcting the original metaregression analysis directly, but rather indirectly inferring the likely impact of small study effects on the original analysis by reference to the impact it has in simpler models.
The original analysis, of course, did not exclude ou...
I have now had a look at the analysis code. Once again, I find significant errors and - once again - correcting these errors is adverse to HLI's bottom line.
I noted before the results originally reported do not make much sense (e.g. they generally report increases in effect size when 'controlling' for small study effects, despite it being visually obvious small studies tend to report larger effects on the funnel plot). When you use appropriate comparators (i.e. comparing everything to the original model as the baseline case), the cloud of statistics looks ...
Thanks for this, Joel. I look forward to reviewing the analysis more fully over the weekend, but I have three major concerns with what you have presented here.
1. A lot of these publication bias results look like nonsense to the naked eye.
Recall the two funnel plots for PT and CT (respectively):
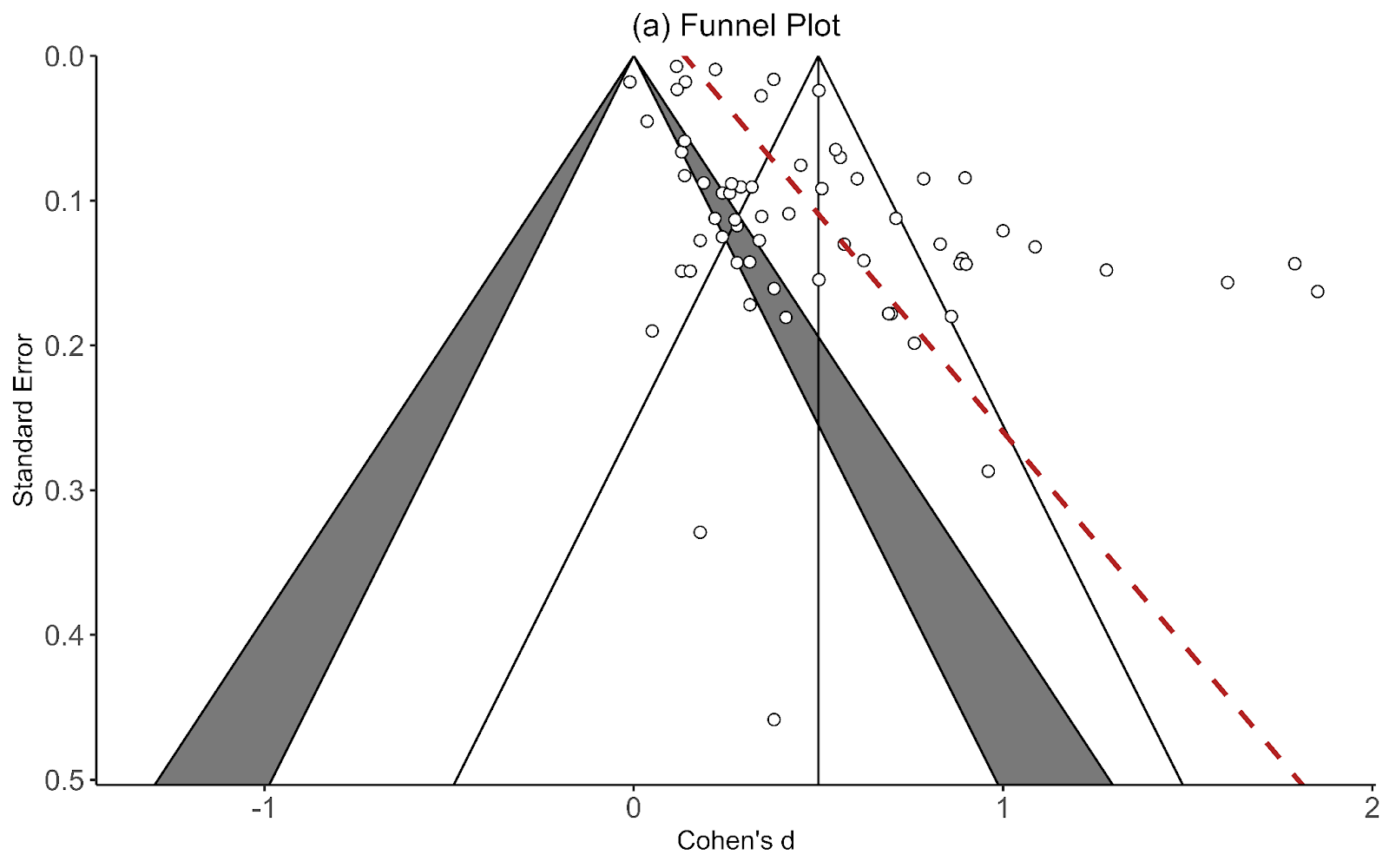
I think we're all seeing the same important differences: the PT plot has markers of publication bias (asymmetry) and P hacking (clustering at the P<0.05 contour, also the p curve) visible to the naked eye; the CT studies do not really show this at all. So heuristi...
I will try and summarise and comment on what I think are some possible suggestions you raise, which happen to align with your three sections.
1. Discard the results that don't result in a discount to psychotherapy [1].
If I do this, the average comparison of PT to CT goes from 9.4x --> 7x. That seems like a plausible correction, but I'm not sure it's the one I should use. I interpreted these results s as indicating none of the tests give reliable results. I'll quote myself:
...I didn’t expect this behaviour from these tests. I’m not sur
Hello Joel,
0) My bad re rma.rv output, sorry. I've corrected the offending section. (I'll return to some second order matters later).
1) I imagine climbing in Mexico is more pleasant than arguing statistical methods on the internet, so I've attempted to save you at least some time on the latter by attempting to replicate your analysis myself.
This attempt was only partially successful: I took the 'Lay or Group cleaner' sheet and (per previous comments) flipped the signs where necessary so only Houshofer et al. shows a negative effect. Plugging this into R me...
Thanks for the forest and funnel plots - much more accurate and informative than my own (although it seems the core upshots are unchanged)
I'll return to the second order matters later in the show, but on the merits, surely the discovery of marked small study effects should call the results of this analysis (and subsequent recommendation of Strongminds) into doubt?
Specifically:
- The marked small study effect is difficult to control for, but it seems my remark of an 'integer division' re. effect size is in the right ballpark. I would expect* (more
Thanks. I've taken the liberty of quickly meta-analysing (rather, quickly plugging your spreadsheet into metamar). I have further questions.
1. My forest plot (ignoring repeated measures - more later) shows studies with effect sizes >0 (i.e. disfavouring intervention) and <-2 (i.e.. greatly favouring intervention). Yet fig 1 (and subsequent figures) suggests the effect sizes of the included studies are between 0 and -2. Appendix B also says the same: what am I missing?
2. My understanding is it is an error to straightforwardly include multiple re...
Hi Gregory,
The data we use is from the tab “Before 23.02.2022 Edits Data”. The “LayOrGroup Cleaner” is another tab that we used to do specific exploratory tests. So the selection of studies changes a bit.
1. We also clean the data in our code so the effects are set to positive in our analysis (i.e., all of the studies find reductions in depression/increases in wellbeing). Except for the Haushofer et al., which is the only decline in wellbeing.
2. We attempt to control for this problem by using a multi-level model (with random intercepts clustered at th...
I found (I think) the spreadsheet for the included studies here. I did a lazy replication (i.e. excluding duplicate follow-ups from studies, only including the 30 studies where 'raw' means and SDs were extracted, then plugging this into metamar). I copy and paste the (random effects) forest plot and funnel plot below - doubtless you would be able to perform a much more rigorous replication.
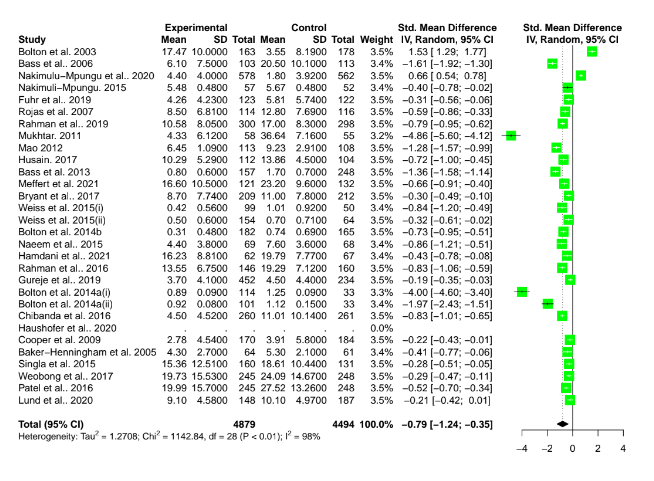
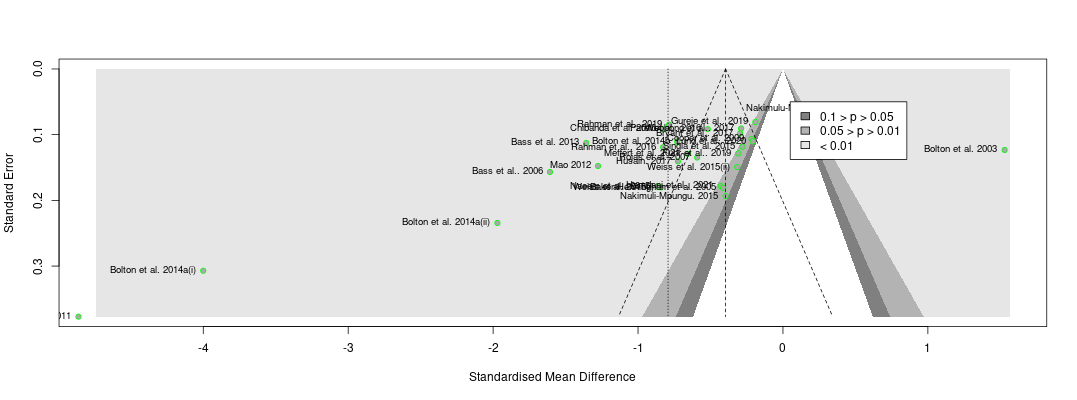
This is why we like to see these plots! Thank you Gregory, though this should not have been on you to do.
Having results like this underpin a charity recommendation and not showing it all transparently is a bad look for HLI. Hopefully there has been a mistake in your attempted replication and that explains e.g. the funnel plot. I look forward to reading the responses to your questions to Joel.
Re. the meta-analysis, are you using the regressions to get the pooled estimate? If so, how are the weights of the studies being pooled determined?
Per the LW discussion, I suspect you'd fare better spending effort actually presenting the object level case rather than meta-level bulverism to explain why these ideas (whatever they are?) are getting a chilly reception.
Error theories along the lines of "Presuming I am right, why do people disagree with me?" are easy to come by. Suppose indeed Landry's/your work is indeed a great advance in AI safety: then perhaps indeed it is being neglected thanks to collective epistemic vices in the AI safety community. Suppose instead this work is bunk: then perhaps i...
I'd guess the distinction would be more 'public interest disclosure' rather than 'officialness' (after all, a lot of whistleblowing ends up in the media because of inadequacy in 'formal' channels). Or, with apologies to Yes Minister: "I give confidential briefings, you leak, he has been charged under section 2a of the Official Secrets Act".
The question seems to be one of proportionality: investigative or undercover journalists often completely betray the trust and (reasonable) expectations of privacy of its subjects/targets, and this can ethically va...
Hello Luke,
I suspect you are right to say that no one has carefully thought through the details of medical career choice in low and middle income countries - I regret I certainly haven't. One challenge is that the particular details of medical careers will not only vary between higher and lower income countries but also within these groups: I would guess (e.g.) Kenya and the Phillipines differ more than US and UK. My excuse would be that I thought I'd write about what I knew, and that this would line up with the backgrounds of the expected audience. Maybe ...
Asserting (as epicurean views do) death is not bad (in itself) for the being that dies is one thing. Asserting (as the views under discussion do) that death (in itself) is good - and ongoing survival bad - for the being that dies is quite another.
Besides its divergence from virtually everyone's expressed beliefs and general behaviour, it doesn't seem to fare much better under deliberate reflection. For the sake of a less emotionally charged variant of Mathers' example, responses to the Singer's shallow pond case along the lines of, "I shouldn't step ...
Cf. your update, I'd guess the second order case should rely on things being bad rather than looking bad. The second-order case in the OP looks pretty slim, and little better than the direct EV case: it is facially risible supporters of a losing candidate owe the winning candidate's campaign reparations for having the temerity to compete against them in the primary. The tone of this attempt to garner donations by talking down to these potential donors as if they were naughty children who should be ashamed of themselves for their political activity also doe...
Maybe it's just a matter of degree but the Protect our Future PAC spent unprecedented levels on Carrick's campaign, and, maybe this more of a principled distinguishing feature, they seem to have spent $1.75M on attack ads against Salinas, which maybe biggest 'within party' attack ad budget in a primary. Seems understandable this can be seen as a norm violation (attack ads are more sticky) and perhaps it's poor 'cooperation with other value systems'.
I agree this form of argument is very unconvincing. That "people don't act as if Y is true" is a pretty rubbish defeater for "people believe Y is true", and a very rubbish defeater for "X being true" simpliciter. But this argument isn't Ord's, but one of your own creation.
Again, the validity of the philosophical argument doesn't depend on how sincerely a belief is commonly held (or whether anyone believes it at all). The form is simply modus tollens:
- If X (~sanctity of life from conception) then Y (natural embryo loss is - e.g. a much greater moral priority
Sure - I'm not claiming "EA doctrine" has no putative counter-examples which should lead us to doubt it. But these counter-examples should rely on beliefs about propositions not assessments of behaviour: if EA says "it is better to do X than Y", yet this seems wrong, this is a reason to doubt EA, but whether anyone is actually doing X (or X instead of Y) is irrelevant. "EA doctrine" (ditto most other moral views) urges us to be much less selfish - that I am selfish anyway is not an argument against it.
I think this piece mostly misunderstands Ord's argument, through confusing reductios with revealed preferences. Although you quote the last sentence of the work in terms of revealed preferences, I think you get a better picture of Ord's main argument from his description of it:
...The argument then, is as follows. The embryo has the same moral status as an adult human (the Claim). Medical studies show that more than 60% of all people are killed by spontaneous abortion (a biological fact). Therefore, spontaneous abortion is one of the most serious problems faci
The guiding principle I recommend is 'disclose in the manner which maximally advantages good actors over bad actors'. As you note, this usually will mean something between 'public broadcast' and 'keep it to yourself', and perhaps something in and around responsible disclosure in software engineering: try to get the message to those who can help mitigate the vulnerability without it leaking to those who might exploit it.
On how to actually do it, I mostly agree with Bloom's answer. One thing to add is although I can't speak for OP staff, Esvelt, etc., I'd ex...
Thanks for this, Richard.
As you (and other commenters) note, another aspect of Pascalian probabilities is their subjectivity/ambiguity. Even if you can't (accurately) generate "what is the probability I get hit by a car if I run across this road now?", you have "numbers you can stand somewhat near" to gauge the risk - or at least 'this has happened before' case studies (cf. asteroids). Although you can motivate more longtermist issues via similar means (e.g. "Well, we've seen pandemics at least this bad before", "What's the chance folks raising grave conce...
Thanks for the post.
As you note, whether you use exponential or logistic assumptions is essentially decisive for the long-run importance of increments in population growth. Yet we can rule out exponential assumptions which this proposed 'Charlemagne effect' relies upon.
In principle, boundless forward compounding is physically impossible, as there are upper bounds on growth rate from (e.g.) the speed of light, and limitations on density from the amount of available matter in a given volume. This is why logistic functions, not exponential ones, are use...
I don't find said data convincing re. CFAR, for reasons I fear you've heard me rehearse ad nauseum. But this is less relevant: if it were just 'CFAR, as an intervention, sucks' I'd figure (and have figured over the last decade) that folks don't need me to make up their own mind. The worst case, if that was true, is wasting some money and a few days of their time.
The doctor case was meant to illustrate that sufficiently consequential screw-ups in an activity can warrant disqualification from doing it again - even if one is candid and contrite about them. I ...
CFAR's mistakes regarding Brent
Although CFAR noted it needed to greatly improve re. "Lack of focus on safety" and "Insufficient Institutional safeguards", evidence these have improved or whether they are now adequate remains scant. Noting "we have reformed various things" in an old update is not good enough.
Whether anything would be 'good enough' is a fair question. If I, with (mostly) admirable candour, describe a series of grossly incompetent mistakes during my work as a doctor, the appropriate response may still be to disqualify me from future medical p...
Hi Gregory, I will be running these workshops together with John, so I'd like to respond to your comments.
I think that it is fair for you to post your warning/recommendation but as far as I can tell, today's CFAR is quite different from the organization that you say demonstrated "gross negligence and utter corporate incompetence" in the past. You say that the evidence is sparse that anything has changed and I'm not sure about that but I'm also not the person to make that case because I'm not CFAR - I'm a CFAR developer running a p...
I strongly disagree with Greg. I think CFAR messed up very badly, but I think the way they messed up is totally consistent with also being able to add value in some situations.
We have data I find convincing suggesting a substantial fraction of top EAs got value from CFAR. ~ 5 years have passed since I went to a CFAR workshop, and I still value what I learned and think it's been useful for my work. I would encourage other people who are curious to go (again, with the caveat that I don't know much about the new program), if they feel like they're in a ...
Howdy, and belatedly:
0) I am confident I understand; I just think it's wrong. My impression is HIM's activity is less 'using reason and evidence to work out what does the most good', but rather 'using reason and evidence to best reconcile prior career commitments with EA principles'.
By analogy, if I was passionate about (e.g.) HIV/AIDS, education, or cancer treatment in LICs, the EA recommendation would not (/should not) be I presume I maintain this committment, but rather soberly evaluate how interventions within these areas stack up versus all othe...
I think your two comments here are well-argued, internally consistent, and strong. However, I think I disagree with
As, to a first approximation, reality works in first-order terms
in the context of EA career choice writ large, which I think may be enough to flip the bottom-line conclusion.
I think the crux for me is that I think if the differences in object-level impact across people/projects is high enough, then for anybody whose career or project is not in the small subset of the most impactful careers/projects, their object-level impacts will ...
It seems bizarre that, without my strong upvote, this comment is at minus 3 karma.
Karma polarization seems to have become much worse recently. I think a revision of the karma system is urgently needed.
Thanks. Perhaps with the benefit of hindsight the blue envelopes probably should have been dropped from the graph, leaving the trace alone:
- As you and Kwa note, having a 'static' envelope you are bumbling between looks like a violation of the martingale property - the envelope should be tracking the current value more (but I was too lazy to draw that).
- I agree all else equal you should expect resilience to increase with more deliberation - as you say, you are moving towards the limit of perfect knowledge with more work. Perhaps graph 3 and 4 [I've adde
I worry a lot of these efforts are strategically misguided. I don't think noting 'EA should be a question', 'it's better to be inclusive' 'positive approach and framing' (etc.) are adequate justifications for soft-peddling uncomfortable facts which nonetheless are important for your audience to make wise career decisions. The most important two here are:
- 'High-impact medicine' is, to a first approximation, about as much of a misnomer as 'High-impact architecture' (or 'high-impact [profession X]'). Barring rare edge cases, the opportunities to have the great
Hi Greg,
Thank you for your comment.
Big picture, I wanted to clarify two specific points where you have misunderstood the aims of the organisation (we take full responsibility for these issues however as if you have got this impression it is possible others have too).
1. We do not necessarily encourage people to apply for and study medicine. We are not giving any advice to high school level students about degree choices and paths to impact. To quote what you wrote, "medicine often selects for able, conscientious, and altruistic people, who can do a lot of go...
Bravo. I think diagrams are underused as crisp explanations, and this post gives an excellent demonstration of their value (among many other merits).
A minor point (cf. ThomasWoodside's remarks): I'd be surprised if one really does (or really should) accept no trade-offs between "career quality" for "career impact". The 'isoquoise ' may not slant all the way down from status quo to impactful toil, but I think it should slant down at least a little (contrariwise, you might also be willing to trade less impact for higher QoL etc).
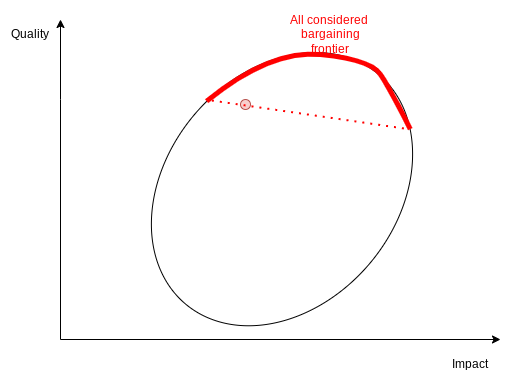
[own views etc]
I think the 'econ analysis of the EA labour market' has been explored fairly well - I highly recommend this treatment by Jon Behar. I also find myself (and others) commonly in the comment threads banging the drum for it being beneficial to pay more, or why particular ideas to not do so (or pay EA employees less) are not good ones.
Notably, 'standard economic worries' point in the opposite direction here. On the standard econ-101 view, "Org X struggles as competitor Org Y can pay higher salaries", or "Cause ~neutral people migrate ...
Thanks for the reply, and with apologies for brevity.
Re. 1 (ie. "The primary issue with the VRC is aggregation rather than trade-off"). I take it we should care about plausibility of axiological views with respect to something like 'commonsense' intuitions, rather than those a given axiology urges us to adopt. It's at least opaque to me whether commonsense intuitions are more offended by 'trade-offy/CU' or 'no-trade-offy/NU' intuitions. On the one hand:
- "Any arbitrarily awful thing can be better than nothing providing it is counterbalanced by k good things
Do you mean trivial pains adding up to severe suffering? I can see how if you would accept lexicality or thresholds to prevent this, you could do the same to prevent trivial pleasures outweighing severe suffering or greater joys.
Yeah, that's it. As you note these sorts of moves seem to have costs elsewhere, but if one thinks on balance they nonetheless should be accepted, then the V/RC isn't really a strike against 'symmetric axiology' simpliciter, but merely 'symmetric axiologies with a mistaken account of aggregation'. If instead 'straightforward/unadorn...
...Tradeoffs like the Very Repugnant Conclusion (VRC) are not only theoretical, because arguments like that of Bostrom (2003) imply that the stakes may be astronomically high in practice. When non-minimalist axiologies find the VRC a worthwhile tradeoff, they would presumably also have similar implications on an arbitrarily large scale. Therefore, we need to have an inclusive discussion about the extent to which the subjective problems (e.g. extreme suffering) of some can be “counterbalanced” by the “greater (intrinsic) good” for others, because this has dire
(Edit: Added a note(*) on minimalist views and the extended VRC of Budolfson & Spears.)
Thanks for highlighting an important section for discussion. Let me try to respond to your points. (I added the underline in them just to unburden the reader’s working memory.)
This seems wrong to me,
The quoted passage contained many claims; which one(s) seemed wrong to you?
and confusing 'finding the VRC counter-intuitive' with 'counterbalancing (/extreme) bad with with good in any circumstance is counterintuitive' (e.g. the linked article to Omelas) is unfortunate -...
I strongly agree with all this. Another downside I've felt from this exercise is it feels like I've been dragged into a community ritual I'm not really a fan of where my options are a) tacitly support (even if it is just deleting the email where I got the codes with a flicker of irritation) b) an ostentatious and disproportionate show of disapproval.
I generally think EA- and longtermist- land could benefit from more 'professional distance': that folks can contribute to these things without having to adopt an identity or community that steadily metast...
Thanks, but I've already seen them. Presuming the implication here is something like "Given these developments, don't you think you should walk back what you originally said?", the answer is "Not really, no": subsequent responses may be better, but that is irrelevant to whether earlier ones were objectionable; one may be making good points, but one can still behave badly whilst making them.
(Apologies if I mistake what you are trying to say here. If it helps generally, I expect - per my parent comment - to continue to affirm what I've said before however the morass of commentary elsewhere on this post shakes out.)
Greg, I want to bring two comments that have been posted since your comment above to your attention:
- Abby said the following to Mike:
Your responses here are much more satisfying and comprehensible than your previous statements, it's a bit of a shame we can't reset the conversation.
2. Another anonymous commentator (thanks to Linch for posting) highlights that Abby's line of questioning regarding EEGs ultimately resulted in a response satisfactory to her and which she didn't have the expertise to further evaluate:
...if they had given the response that they
[Own views]
I'm not sure 'enjoy' is the right word, but I also noticed the various attempts to patronize Hoskin.
This ranges from the straightforward "I'm sure once you know more about your own subject you'll discover I am right":
I would say I expect you to be surprised by certain realities of neuroscience as you complete your PhD
'Well-meaning suggestions' alongside implication her criticism arises from some emotional reaction rather than her strong and adverse judgement of its merit.
...I’m a little baffled by the emotional intensity here but I’d su
Greg, I have incredible respect for you as a thinker, and I don't have a particularly high opinion of the Qualia Research Institute. However, I find your comment to be unnecessarily mean: every substantive point you raise could have been made more nicely and less personal, in a way more conducive to mutual understanding and more focused on an evaluation of QRI's research program. Even if you think that Michael was condescending or disrespectful to Abby, I don't think he deserves to be treated like this.
Here's the OWID charts for life satisfaction vs. GDP/capita. First linear (per the dovecote model):
Now with a log transform to GDP/capita (per the MHR):
I think it is visually clear the empirical relationship is better modelled as log-linear rather than linear. Compared to this, I don't think the regression diagnostics suggesting non-inferiority of linear GDP (in the context of model selected from thousands of variables, at least some of which could log-linearly proxy for GDP, cf. Dan_Key's comment) count for much.
Besides the impact of GDP (2.5% versu... (read more)