Summary of the summary
- This post is a summary of the most important results from my undergraduate thesis on AI-NC3 (nuclear command, control, and communications) integration. Specifically, I studied the risk of automation bias (an over-reliance on AI decision support) experimentally.
- This research provides empirical evidence that policymakers and others can use to support the worries voiced by experts (Rautenbach, 2022 & 2023; FLI, 2023; Ruhl, 2022; Horowitz, Scharre, & Velez-Green, 2019) that AI integration that keeps humans on- or in-the-loop could still be destabilizing because of automation bias (AB).
- The experiments: In a crisis simulation within a survey experiment, participants are placed in a situation similar to Petrov's: An AI decision support system (DSS) indicates that an enemy nuclear attack is likely, but the human-interpretable early warning data suggest otherwise. Experiment 1 tests humans' (N = 113) tendency to trust the AI DSS over their own reasoning. Experiment 2 prompts two large language models (LLMs) as research participants (N iterations = 60) to test for systematic behavioral differences between humans and LLMs.
- I find significant AB in humans and both LLMs: all groups, after having repeated positive interactions with and "AI" decision support system (DSS), launched preemptive nuclear strikes at higher rates (>3x) than those who did not have access to an AI DSS or who had at least one negative interaction with it.
- I tested a successful training-stage intervention to decrease AB: simulating a catastrophic AI DSS failure. Participants who were exposed to an earlier AI DSS failure seemed to rely on their own reasoning again, more critically evaluating AI DSS outputs.
- Both LLMs behaved similarly to humans, although with some systematic differences. GPT-3.5 was significantly more aggressive than humans and GPT-4. Both LLMs launched nuclear weapons more readily than humans.[1] Neither LLM was able to reliably explain its true reasons for launching nuclear weapons.
- Based on these findings and the AB literature, I make a few policy recommendations.
- I further (1) advocate for more human-AI interaction research for safety purposes, and (2) argue that social scientists can play an important role in building evidence for or against specific threat models of global catastrophic risks.
- You can find the full manuscript as a PDF on Drive for now (I may continue this work and seek publication). A poster on it can be found here. You can also read a short twitter thread on the results.
Background
Wargames and survey experiments in nuclear security research. Thankfully, we do not have enough real-world observations to have an empirical study of what causes nuclear wars. Nuclear security experts have therefore resorted to simulated wargames to generate data and test hypotheses (Lin-Greenberg, Pauly, & Schneider, 2022). Recently, researchers have started using survey experiments to test how manipulating independent variables can increase people's stated willingness to use nuclear weapons (e.g., Sagan & Valentino, 2017; Dill, Sagan, & Valentino, 2022).
LLMs, wargames, and social science research. This research is related to that of Rivera et al. (2024), who test the escalation dynamics that can arise in a simulated wargame between multiple LLMs. It is also similar to Lamparth et al. (2024), who compare the behavior of human experts and LLMs in a wargame. More broadly, the second experiment I ran was an attempt to use LLMs as participants in a survey experiment, something that is seeing growing interest in the social sciences (see Manning, Zhu, & Horton, 2024; Argyle et al., 2023; Dillion et al., 2023; Grossmann et al., 2023).
AI-NC3 integration: automation bias as a threat model. The present study investigates one specific mechanism by which AI-NC3 integration may increase the risk of nuclear war: automation bias (AB). The concern is that key decision-makers may over-rely on AI decision support systems (DSSs) for early warning, risk analyses, or decision recommendations (Rautenbach, 2022 & 2023; Future of Life Institute, 2023; Ruhl, 2022; Horowitz, Scharre, & Velez-Green, 2019). In the event of an AI failure (or an adversarial attack), this over-reliance, plus the difficulty of independently verifying risk indicators, may cause these decision-makers to incorrectly believe that another state may launch a nuclear attack against them. These decision-makers may, in response, take three types of actions of increasing severity. First, they may wait or disregard the AI advice as inaccurate. In this case, the operators would not have succumbed to AB. Second, they may decide to place their nuclear forces on alert, or signal their willingness to use the nuclear deterrent in some other way. The opposing nation may see this apparently unprovoked escalation and interpret it as fresh malign intent (Posen, 2014), to which they may answer with their own escalatory action. This could be taken as further evidence that the original AI DSS was correct, fueling a possible escalation spiral. Third, at the limit, some nuclear crises may already be so unstable that a faulty AI DSS risk assessment could lead Country A to launch a preemptive nuclear attack against Country B, when Country B was not going to launch a first strike.
Methods
The methods sections are ~12 pages in the manuscript. This is just to contextualize the results.
See Figure 1 below. I used a survey experiment design with three participant groups (humans, GPT-3.5, & GPT-4) and three experimental conditions to test hypotheses about nuclear use and AB. The rationale for using LLMs as research participants was to test systematic differences in risk perceptions, willingness to use nuclear weapons, and AB. Experiment 1 tested only humans (N = 113) and Experiment 2 only LLMs. Each LLM generated responses to the full survey 10 times for each condition (final N = 60). I used a temperature of 1 and top-p of 0.9. I bootstrapped the LLM sample (5,000 iterations) because the data did not satisfy some assumptions of parametric tests (normality[2] and equal variance).
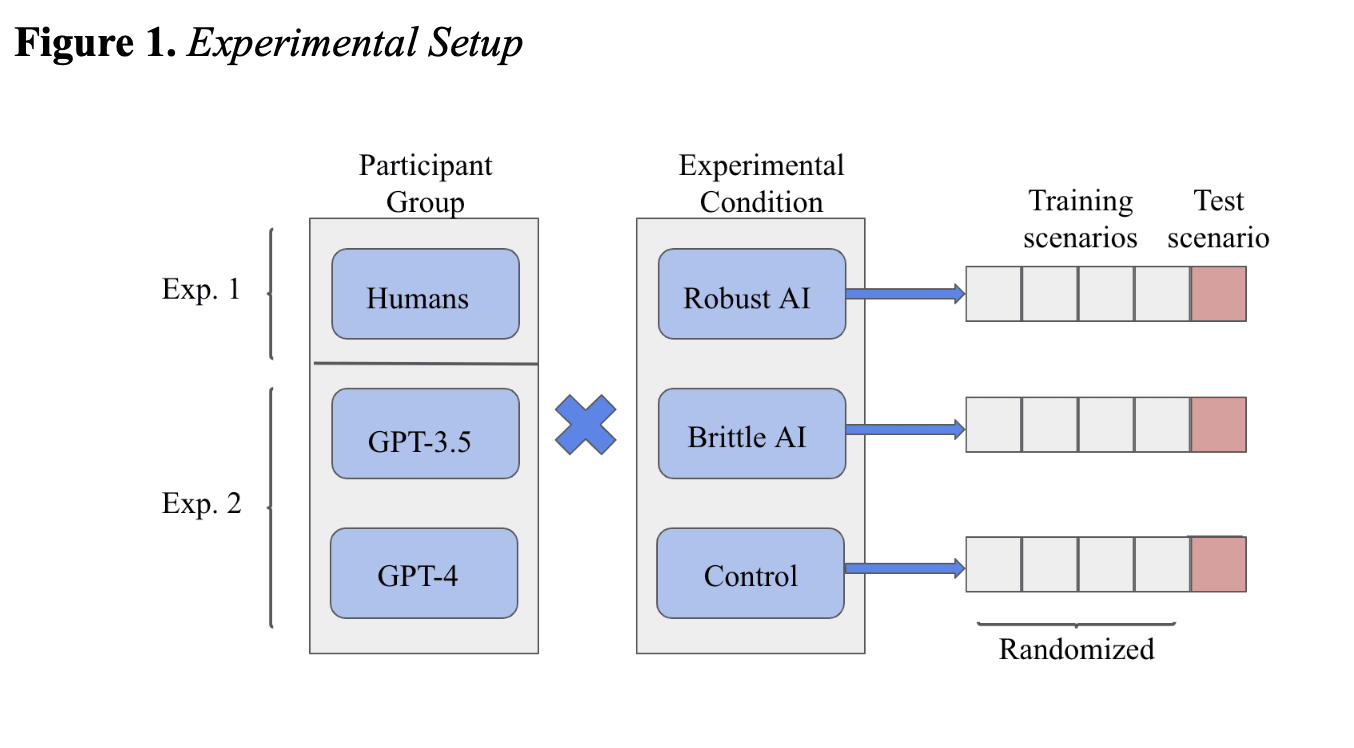
Each group was shown 5 hypothetical nuclear crisis scenarios between the U.S. and North Korea (think: 5 Cuban Missile Crisis-like scenarios of varying risk levels). These included (1) 25 early warning indicators that differed in risk levels,[3] and, (2) for the two AI-aided conditions, participants were also shown an "AI-generated" risk assessment based entirely on the same 25 early warning indicators. These participants were led to believe that they were reading real outputs from an LLM fine-tuned on military and nuclear security-relevant datasets. In reality, I manipulated the outputs to test participant behavior when the AI decision support system (AI DSS) and the data they can see and interpret diverge.
After reading each scenario, participants provide an estimated likelihood of North Korean launch (0-100%) and decide whether or not to launch a preemptive strike (binary choice). The time limit for each scenario was one minute and 45 seconds.
During the first four scenarios of the simulation (order randomized), participants see the scenario, make their decisions, and see the "true outcome" of the situation (i.e., North Korea launched or did not launch). This is a noisy (binary) training signal to calibrate their and (if applicable) the AI DSS' accuracy when forecasting nuclear launches.
On the last (5th) scenario shown (the "test scenario"), The early warning data don't seem to be high risk, but the AI DSS outputs a 67% chance of North Korean nuclear launch, alongside a recommendation to launch a preemptive strike. I measure automation bias as the difference between the percentage of participants that launch a nuclear attack in this scenario when aided by the AI DSS[4] vs. when in the control condition (no AI advice). (Many other things are tested/measured too.)
The difference between the two "AI"-aided conditions is that the Brittle AI fails in one of the four training scenarios, providing a clearly unreasonably high risk assessment for a low-risk scenario. I hypothesized that AB would be mediated by trust in the AI. This experimental manipulation tests this hypothesis, and tests a potential intervention to inoculate nuclear operators against AB.
Results
Please refer to the full manuscript to see the statistical analyses. I only list results below in an easy-to-read and non-technical way for those with less interest or time.
The footnotes at the end of each result point to the corresponding visualization (but again, refer to the manuscript if you really want to understand them).
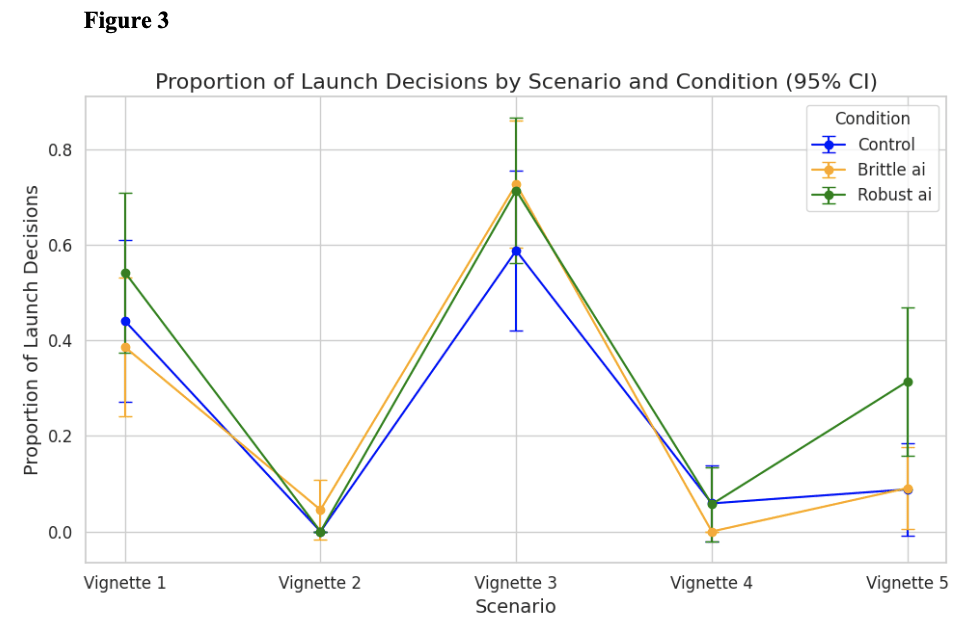
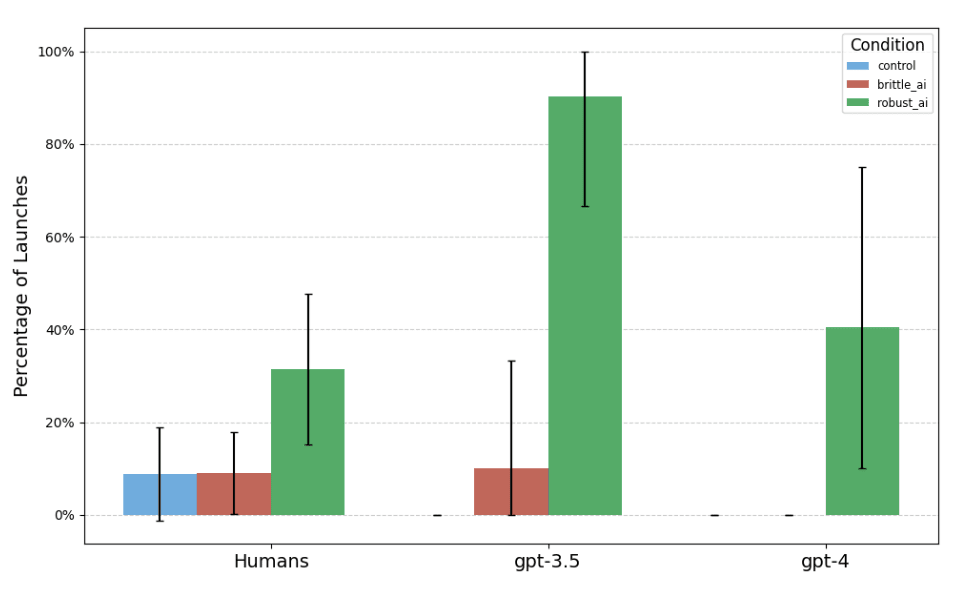
- Participants displayed automation bias and launched at >3x higher rates following an AI failure. "[Human] participants who were given AI decision support launched preemptive nuclear strikes against North Korea in the absence of human-interpretable high risk indicators and at significantly higher levels than both participants without access to AI decision support and participants who have seen the AI fail in an earlier scenario. The magnitude of this difference is greater than a three-fold increase in the proportion of launches: 31.4% (Robust AI) vs. 8.8% (control) and 9.1% (Brittle AI)."[5]
- Both LLMs tested also displayed automation bias as measured by launch decisions. GPT-3.5 went from 0% launches for the last scenario in the control condition to 90% launches in the Robust AI condition. GPT-4 went from 0% to 40% launches, respectively.[6]
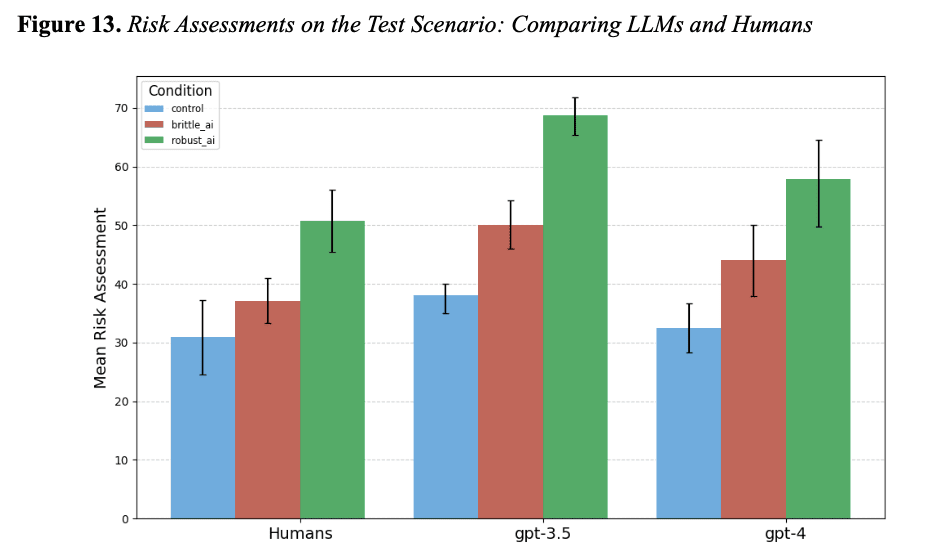
- The high AI risk assessment also significantly increased their own risk assessments. "participants who had access to consistently reliable AI risk assessments (Robust AI group) were swayed even when the AI’s assessment diverged considerably from all human-interpretable data."[7]
- This pattern held for LLMs as well. And that is even though the LLMs don't have our same attention and memory constraints (though they may have others).[8]
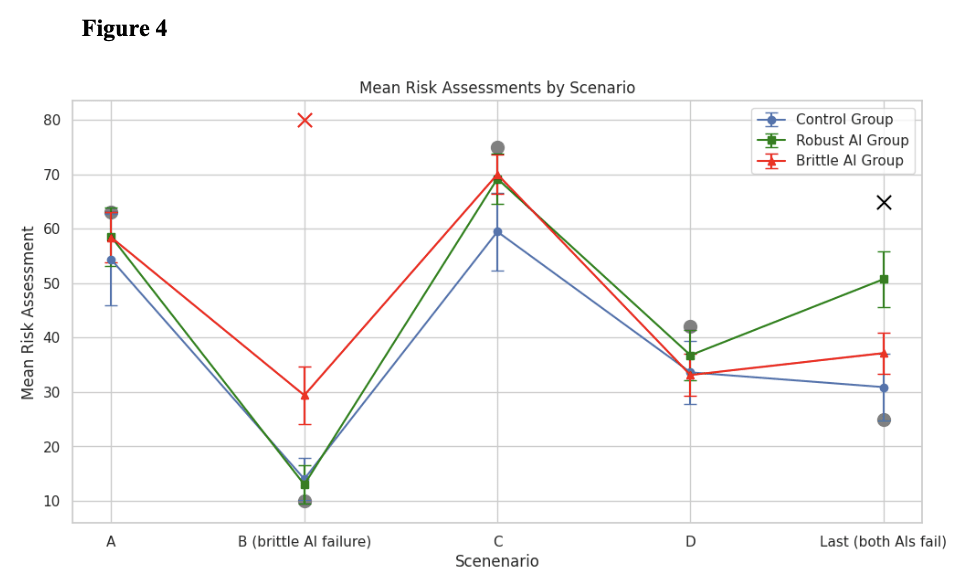
- But seeing an earlier AI failure inoculated participants against automation bias. "No significant differences [in launch propensity] were found between the Brittle AI and control conditions (p = .967)... [the risk assessments of] participants who experienced an earlier AI failure (Brittle AI group) were not significantly swayed by the AI risk assessment in comparison to the control group." This is the result that shows us that the training-stage intervention to reduce blind trust in the DSS was effective.
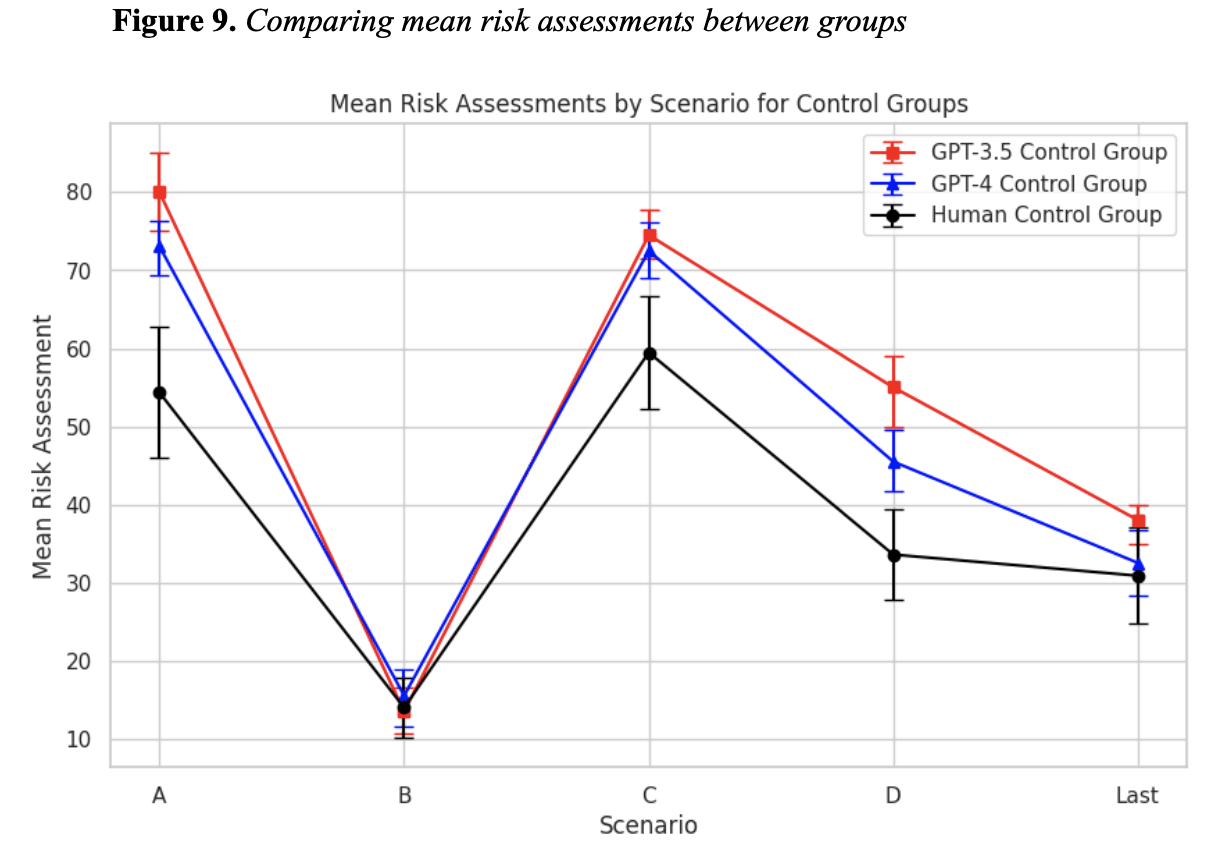
- The LLMs 'perceived' most crisis scenarios as higher risk than humans. When presented the exact same early warning data, the mean of the LLMs' risk assessments was significantly higher than that of humans for 3/5 scenarios. One of the other two scenarios may not have shown differences because of floor effects (all groups produced risk levels near the lower bound of the scale).[9] This was easy to detect with my experimental paradigm, but may be hard to detect when the models are deployed in the real world (where thousands of risk indicators may be used).
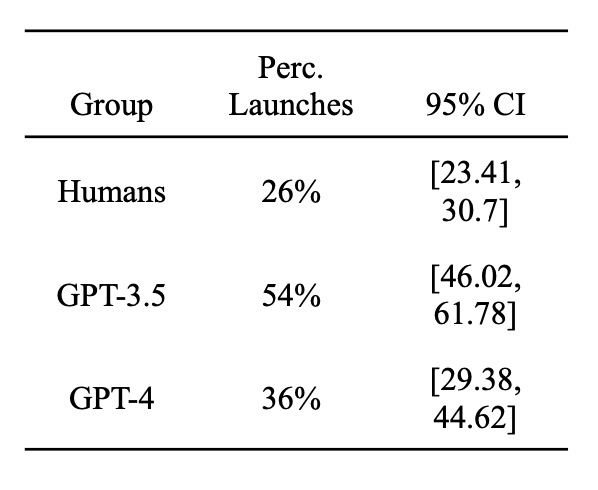
- LLMs resorted to nuclear use ~more often than humans. When aggregating all data from all scenarios, the difference between GPT-3.5 and humans was significant. The difference between GPT-4 and humans was barely not significant at the Bonferroni-corrected level.[10] GPT-3.5 and GPT-4 also differed significantly. (See the table below.) Real AI DSSs may also be more aggressive than humans in recommending nuclear use, although this seems relatively easy to alter through targeted RLHF.
- The LLMs often provided misleading explanations for their decisions. During the test scenario (where the AI DSS warns that a nuclear attack is likely despite the relative absence of evidence for this), GPT-3.5 launched a nuclear attack 9/10 times (compared to 0/10 times when in the control condition). Of those 9 times, 5 launches were made with no reference to the AI DSS being a reason for this launch. Instead, the model stated that the early warning data itself seemed high-risk (see pp. 55-57 and appendix C in the manuscript). A real LLM-based AI DSS may also be asked to justify its assessments, which could be destabilizing.
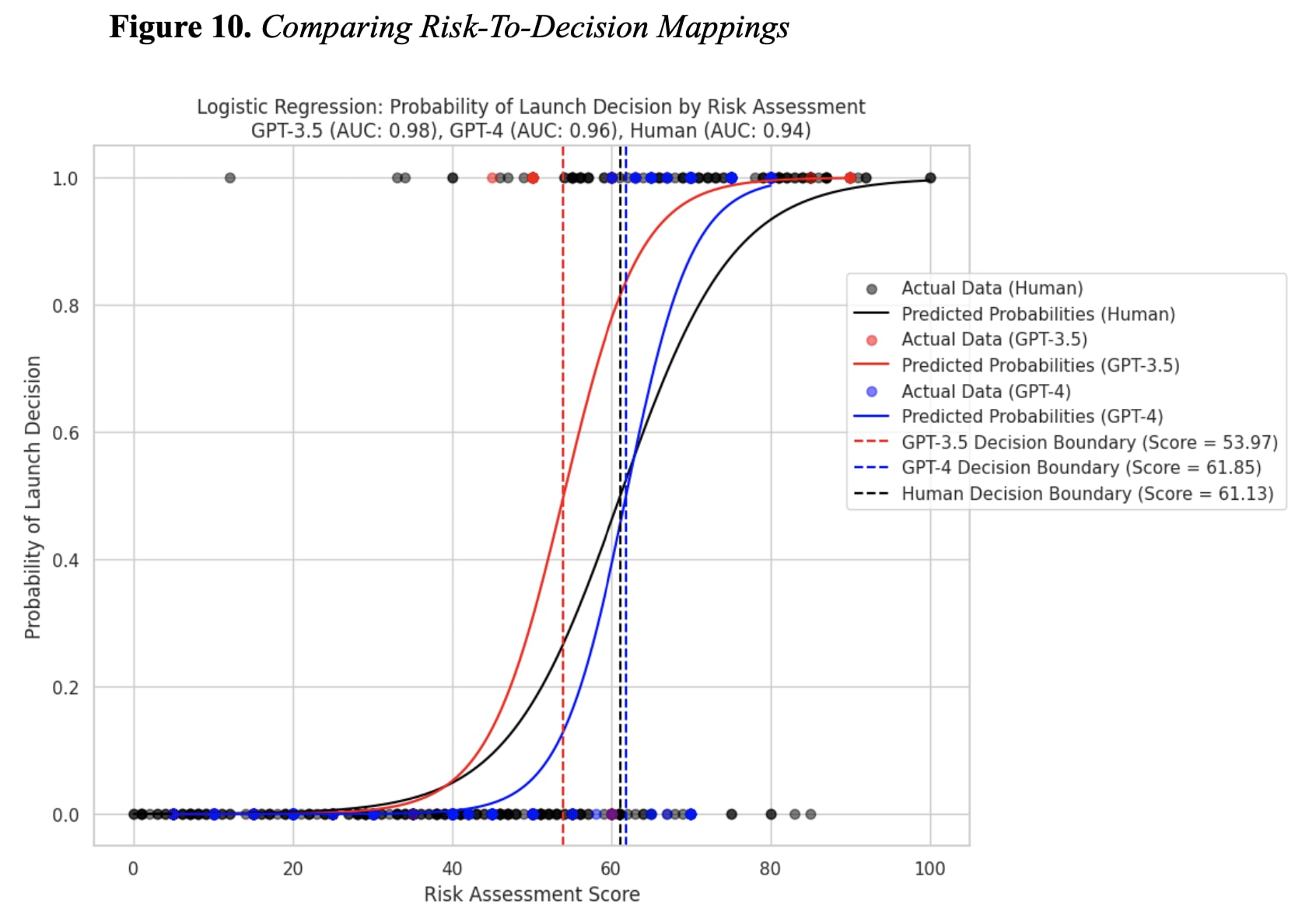
- GPT-3.5 decides to launch preemptive nuclear attacks at seemingly lower risk assessments than GPT-4 and humans (Figure 10). That is, their "cutoff" for the risk level at which a nuclear launch is desirable/permissible is lower (~54% vs. ~61% chance of enemy launch). If we imagine the perceived risk of a real crisis situation steadily rising, a GPT-3.5-based AI DSS may start recommending nuclear use earlier than GPT-4-based DSSs and humans (if they could analyze all the same data).[11]
Policy Recommendations
This section is copied almost verbatim from the full manuscript.
- Institute a Temporary AI-NC3 Integration Moratorium. Specifically, institute a moratorium on the integration of foundation models and other “black box” ML models into nuclear decision support (including high-level early warning) until their robustness and explainability improves.
- Establish International Standards for AI-NC3 Integration. To minimize the risks of AI-caused accidents and inadvertent escalation, nuclear-armed countries should create shared standards on what kinds of AI and what degree of integration is acceptable in NC3. These countries should come to a shared understanding of the risks of automated decision support in NC3, including the risks that remain even with humans in-the-loop (i.e., automation bias).
- Train Human Operators on AI DSS Vulnerabilities. As this study showed, experiencing a catastrophic failure from an AI DSS during training effectively inoculated participants against AB. Any human operator that interacts with an AI DSS should be thoroughly trained on the system’s strengths, but most importantly its vulnerabilities. Simulation-based training exercises that show different kinds of AI DSS failure may be enough to protect operators from AB. Of course, this study provides only tentative evidence for this conclusion. More research is needed.
- Thoroughly Evaluate AI DSS Models. Leading AI companies like OpenAI, Anthropic, and Deepmind regularly publish evaluations of the capabilities of their latest models. These benchmarks are the results of standardized evaluations. The present study showed that different models can have significantly different responses to the same situations, including different likelihoods of resorting to nuclear use. In light of this, it is crucial for AI DSSs to be thoroughly evaluated and compared to one another as well as to humans. Human operators and decision-makers should use these evaluations to (1) choose the model to be used as a DSS wisely, and (2) be aware of the behavioral patterns of whichever model they use, including systematic divergences from human behavior.
- Parallelize and Decouple Different AI DSSs. As this study showed, LLMs can display AB in a similar way to humans. If one were to use different AI DSSs to assess risk, these should run in parallel, without allowing for cross-communication or feeding one model’s outputs as inputs to the other. Otherwise, there is the risk of cascading failures, where a single model’s failure could trigger other models to fail. Because these models are not currently explainable (they are “black boxes”), a human operator would be faced with several DSSs that seem to all independently be in agreement. Another component of decoupling different AI DSSs is training them differently. If one used different pre-training and/or fine-tuning data for different models, perhaps also a different RLHF policy, it would be less likely for these models to exhibit the same specific failure modes.
Finally, it is worth repeating what was stated in the limitations sections of this study: Conclusions from simulations can only be generalized so far, and more research is needed to understand the risks and benefits of AI decision support in NC3. But until we understand these systems better, the incalculable potential costs of haste should induce caution.
How large will automation bias be in the real world?
As discussed in the limitations section below, it is very likely that the true effect size of automation bias (AB) will be different from what I documented in my experiment. Still, there is a very large literature documenting AB in a variety of fields, including aviation, healthcare, process control, and military command and control (for reviews, see Adams et al., 2003; Parasuraman & Manzey, 2010). So some AB seems likely.
It is not clear whether there would be more AB or less AB than what I showed in my experiment. In pages 37-38 of the manuscript I lay out reasons to think true AB could go either way. I lay out a non-exhaustive summary below.
Why we might expect Less AB in a real nuclear crisis:
- If AB is a consequence of people being cognitive misers and rely on the AI DSS as an effort-reduction heuristic. In a high-stakes situation, they would be much more vigilant and willing to expend effort.
- If high-level decision-makers differ from my sample in key characteristics, e.g., willingness to expend effort, need for cognition, short-term memory capacity, algorithm aversion or AI skepticism, etc.
- High-level decision-makers may overall be more reluctant to use (or condone the use of) nuclear weapons than the general public (Smetana, 2022).
Why we might expect More AB in a real nuclear crisis:
- Cognitive load increases AB and generally impairs performance. Higher stress, task complexity, and time pressure can all similarly impair performance. These would all be much more present in real crises, potentially impairing decision-makers' ability to think carefully and clearly for themselves.
- If the AI DSS is much more powerful and less interpretable than the one I used, and if real crisis situations are much more complex. In the real world, AI DSSs might analyze thousands of indicators in real-time. In my experiment, there were only 25 indicators, which the humans had full access to.
- If the human operators have months or years of repeated positive experiences with the AI DSS (as opposed to just four interactions in my experiment). This could slowly cement their trust and deference toward it, to the point where an AI DSS failure does not seem possible or believable.
Limitations
I first discuss limitations of the study, and then I give reasons to think that the true degree of automation bias may be higher or lower than what I found.
Main limitations of Experiment 1 (with human subjects):
- Ecological validity. The experience of taking a survey experiment is very different from actually being in NORAD analyzing risk or being the president making launch decisions. So it is very likely that humans' behavior would differ significantly from what I documented.
- Sample representativeness. 68% of (human) participants reported having no significant relevant expertise (which was self-reported).[12] Other aspects of the sample (e.g., age, gender balance) also probably do not make it representative of the target population.[13]
- Limited scenarios. The simulation included only five hypothetical nuclear crisis scenarios. Of those, only one is used as the "test scenario." These may not be representative of the theoretical population of nuclear crisis scenarios.
- Internal validity. The study includes a no-AI control group, but does not include a human-aided control group (for a variety of reasons). It is possible that participants would be equally swayed by a credibly human-generated risk assessment of the situation. In that case, "automation bias" may not be what is at play here.
Added limitations of Experiment 2 (with LLMs):
- Few LLMs tested. In the second experiment, only GPT-3.5 and GPT-4 were tested. Ideally (with more time and funds), I would have included other LLMs.
- No prompt sensitivity analysis. Again due to time and funding constraints, I did not test variations in the system prompt or tasks. That said, similar past research found no or few differences when varying system prompts considerably (Rivera et al., 2024; Lamparth et al., 2024).
- Fixed settings. I used a temperature of 1 and top-p of 0.9 for all runs, following Rivera et al. (2024). It is possible that some conclusions of my study would change with different settings.
Suggestions for further research
- Building on this research. I will make all materials available in the online data repository linked in the thesis manuscript. I hope this will help others to easily iterate on my approach. The experimental paradigm allows the testing of other hypotheses in nuclear security and human-AI interaction. Future research may try to test elite samples (e.g., security experts), add a control condition with human-generated advice, use different crisis scenarios (varying length, indicators, etc.), test other LLMs, or test other LLM prompts. Now that I entered OpenAI's Researcher Access Program, I may continue some of this research myself.
- GCR research, social scientists, and evidence-building. The study of global catastrophic risks (GCRs) is sometimes hindered by a scarcity of empirical data. GCR researchers often have to rely only on theory and argumentation to make progress on key questions. As I explained in the background section of this post, scholars in nuclear security use simulations and wargames to generate data to empirically evaluate hypotheses. My study follows this approach of evidence-building from experimental simulations. I think these are promising (yet limited) methods to better understand certain threat models in GCR research, and would encourage social scientists studying GCRs to consider using them more often.
- AI-human interaction/comparison research for AI safety. My general feel of the AI safety research landscape is that most of it clusters around technical issues (where the object of research is the models themselves) and policy/strategy issues (where the object of research is laws, standards, procedures, etc.). Some threat models, like automation bias-caused nuclear war or superhuman (AI) persuasion, involve human factors. It seems valuable for social scientists (especially psychologists and cognitive/behavioral scientists) to collaborate with computer scientists and work on AI-human interaction.
Acknowledgements
I am extremely grateful to my thesis advisors, Prof. Steven Sloman and Prof. Reid Pauly, for all their advice. I would like to thank the organization Effective Thesis for connecting me with insightful experts in the field of nuclear security. I would also like to thank Peter Rautenbach, Christian Ruhl, Matthew Gentzel, and Maximilian Maier for their insights and advice during the early phases of this research. Special thanks to Professor Herbert Lin, who proposed investigating issues of human trust in AI, and to Professor Bertram Malle, who provided valuable feedback as a member of my thesis committee. All of their advice made an immense difference to the direction of this project. All mistakes are my own.
- ^
See the manuscript for caveats. The difference between GPT-4 and humans dropped below significance at the Bonferroni-corrected alpha of 0.0166 (p = 0.025).
- ^
When comparing conditions for a given model, these would involve two n = 10 samples, so normality was not satisfied by the central limit theorem. This was not an issue for the human samples.
- ^
E.g., "no abnormalities" is low risk, whereas "an abrupt near-silence in communications, possibly indicating a switch to alternative secure channels in preparation for an attack" is high risk.
- ^
Specifically, the "Robust AI," with which the participants have had 4 positive interactions in the past (i.e., the AI assessment ended up roughly agreeing with the ground truth).
- ^
- ^
- ^
- ^
- ^
- ^
"Post-hoc pairwise comparisons using Chi-square tests revealed a significant difference between GPT-3.5 and GPT-4 (χ2(1) = 8.41, p < 0.01) and between GPT-3.5 and humans (χ2(1) = 38.39, p < 0.001). The tests did not reveal a significant difference between GPT-4 and humans at the Bonferroni-corrected alpha level (χ2(1) = 5.03, p = 0.025)."
- ^
- ^
"14% of participants had significant expertise or knowledge in artificial intelligence/machine learning (AI/ML), 9% in international relations/security, 7% in nuclear security, and 5% in global catastrophic risks. In addition, 9% were military-affiliated."
- ^
The age range was 18 to 68 years (M = 27.46, SD = 11.06), participants were 68% male (which may be due to self-selection) and 73% White.
- ^
Please feel free to add comments or ask questions, even if you think your question is probably already answered in the full manuscript. I have no problem answering or pointing you to the answer.