Under-Investigated Fields List (Version 1.0)
Nominations for fields that are not being researched as much as they should be
| UPDATED
10/04/2019 Update: Due to popular request, I have ammended each section with examples of known groups/researchers working on these areas. If you know of researchers in the areas mentioned that are not listed at the ends of their respective sections, please reach out to me at @MatthewMcAteer0.
Table of Contents
🧙♂️ Origins of this List
📃 THE LIST
- 👶 Lifelong learning
- 💿 Transfer Learning
- 🖇️ Computronium
- 💣 Existential risks posed by technical debt
- 🏗️ Higher-level programming languages (and actually building large systems with them)
- 🗜️ Specialized Hardware for Probabilistic computing
- 🛂 Intuitive Visual cryptographic proofs
- 👨⚖️ Lexicographic conversions between algorithms and legal codes
- ⛱️ High-energy Radiation insulation
- 🏺 High-density self-healing materials
- 🌲 Incorporation of still-living materials into structures
🐁 Biology
- 🥶 Cryobiology
- 🧫 Immortal Model Organisms
- 🧬 Biological Radiation resistance
- 📉 Chaotic systems in biology
- ⏲️ Intentionally Self-destructing organizations
- 💰 Successful anti-corruption strategies
- 👨🏭 Organizational psychology and operations for unions
- 🏙️ Charter Cities
- 🤷 How to account for the revealed preference problem
- 🧮 Different categories of neural plasticity
- 🤗 Extreme Empathy
- 🧘 Healthy psychological baselines
- 😰 Anti-neurosis & PTSD-resistance
- 🧟♂️ Necroneurology
- 🎲 Communication of Probability and Uncertainty
- 🔁 Techniques for combining dependent instead of independent p-values for meta-analysis
- 🔲 Experimental design using solutions to problems in Latin Squares
- 🌐 Patterns among proofs for subspace-packing problems
⚛️ Physics
- 🎛️ Increasing Iteration Speed of Experimental Physics
- 🌀 Reservoir Computing for Dynamical Systems
- 🧿 Ball Lightning
- 🚀 Nuclear-powered propulsion for Aeronautics
- ♾️ What is the actual value of “Mathematical beauty”?
Origins of this list
This piece started out as a list I kept of interesting scientific questions. Like anyone who does any kind of research, I had a lot more questions than I had the time or resource-bandwidth to investigate. A few friends of mine have channeled this much more productively (my friend Andre founded FOR.ai for specifically this kind of extra-institutional research), but I decided to list more than just the questions I had in biotechnology or machine learning.
It was turned into a larger, public-facing, fully-fleshed out blog post for a few reasons.
Those who are familiar with the works of Tyler Cowen or Peter Thiel are familiar with the idea that we’re in a period of scientific stagnation. For those who aren’t familiar, it goes something like this:
The American economy has plateaued compared to its previous meteoric rise, and this is because the figurative technological “low-hanging fruit” that drove growth for most of America’s history has largely been spent.

Figures like Peter Thiel like to point to the difference in the advancement of certain scientific and technological milestones before and after the 1970s, as well as which fields have lagged behind the meteoric advancement of computers. As he said in one talk, “The Star Trek computer is not enough”.
Regardless of whether you agree with Cowen & Thiel (or if you sympathize more with optimistic thinkers on progress like José Luis Ricón), you have probably observed that some areas of scientific research, philosophical or economic schools of thought, or areas of technological development don’t get anywhere near the attention you think they should. One of my more recent methods of procrastinating was the curation of a “wish list” of areas that I’d like to see more research focus on.
This post was made public so that, on the off chance these fields did see more investigation, I could update the list with the newly relevant references. As a stretch goal, it would be nice if some of the areas mentioned could inspire more people to actively work on them (a similar goal as Daniel Gross’s Frontier Markets blog post, but with much more detail)I started my career in biological aging at a time when most of the people devoting a significant portion of their time to such research could fit in a medium-sized room. While aging biology has thankfully gotten more attention and grown as a community of researchers, there may still be plenty of other fields that could have huge impact but are under-reported-on in the news. For example, few people probably realized the paradigm shift happening in digital cash theory circa 2008, or knew of the research being done on those now-famous alternatives to TALENs, right under our noses in 2008. Even the Wright brothers did much less than you’d expect to publicize their first flights. In other words, I’m hoping that making this list public will make it easier to find some of these not-yet-famous projects.
With that in mind, the original list (by which I mean the Google doc that I would add to as I procrastinated) had to undergo a few changes first:
Criteria for inclusion
Not all of the scientific questions in my original list are included in this post. I decided to avoid questions that either sounded too rhetorical, or sounded like the senseless half-conceived questions you’d expect to overhear from a stoner (in my defence, the speech to text systems I use are far from perfect). These questions were a minority (i.e., >3%), but they had to be cleared out regardless
In terms of scientific rigor, I have tried to steer towards fields which focus on Karl Popper’s criterion of falsifiability. This not only meant removing some questions (e.g., the existence or non-existence of the reincarnation phenomena described in Andy Weir’s “The Egg”), but also re-phrasing some problems so they could potentially be better defined in a grant application. However, many will note that Popper’s falsifiability is not necessarily a sufficient criterion for scientific rigor. For example, String theory is notorious for putting forth untestable hypotheses (not counting compactified string theories which have a slightly better track record), while astrology repeatedly puts forth testable hypotheses. Certain areas relating to philosophy of science, ethics, and experimental methodology require evaluation on different criteria, and are reserved for the end.
Assumptions: These questions are being listed and/or included based on the following criteria
Understanding of this field can be improved with greater iteration speed
OR
Understanding of this field can be improved with greater fraction of research funding
OR
Understanding of this field can be improved with a larger number of man-hours being focused on it
The List
Computer Science
Areas in this part range from under-prioritized areas in academia that industry uses a lot to areas that academia is working on far more than industry (but even then, not much). While it’s easy to point to areas in computer science that might be over-researched (after all, Machine Learning conferences often get more papers than they can effectively review), there are still areas that are neglected with respect to their potential benefit.
Computer Science: Lifelong learning
In many toy or academic settings, machine learning models are often trained for a long period of time (ranging from hours to days, or weeks in the case of particularly well-funded labs), and then deployed to the real world with little thought on updating them. I include this topic because there seems to be a large divide between how much this subject is prioritized in academia vs industry. For example, a recent article criticised Alphabet’s DeepMind on it’s costly approach to applying neuroscience principles to machine learning. While I have a few issues with the article (it seems to ignore how useful reinforcement learning is in algorithmic trading or gaming when it discusses its usefulness), it does raise some interesting points. For the most part, heavily interconnected biological brains that have been optimized for making sure an organism stays alive are very different from the ML systems that companies and consumers want to behave as general-purpose interchangeable modules that can be applied to any arbitrary problem. However, perhaps the most applicable benefit from biologically-inspired machine learning systems would be to understand how the system as a whole is able to continuously learn (e.g., less separated training and testing phases). Having machine learning models that can continuously learn from real-world data while not forgetting the critical patterns is definitely an area where industry would benefit.


Known Groups / Researchers working on this: Sergey Levine, Peter Stone, Jacob Andreas, Karol Hausman, Martha White, Natalia Diaz Rodriguez, Jeff Clune, Nicolas Heess, Benjamin Rosman
Computer Science: Transfer Learning
In some ways this is the opposite of lifelong learning. In deep learning, models are often trained on lots of data and for long periods of time, often using lots of computational resources. Doing this kind of training from scratch for every single application is usually not feasible. Transfer learning is the process of taking pre-trained networks or models, modifying them slightly, and then using the pre-trained model to either make the learning faster, or reducing the need entirely. Like with lifelong learning, I include this topic because there seems to be a large divide between how much this subject is prioritized in academia versus industry. While researchers within academia may think this space crowded, I suspect this is more a function of numbers of post-docs/grad-students/researchers per PI rather than the research getting as much attention as ML engineers in industry wish it did. Again, I want to stress that whether it’s NLP or computer vision engineers in industry, everyone and their mothers wants more out of transfer learning.
Known Groups / Researchers working on this: Visual Geometry Group at the University of Oxford, Hadsell’s group, Baroni’s team, Jeff Dean’s Group at Google Brain, NV Chawla’s Group (in the early 2000s, at least), Bingel & Søgaard, as well as many others in industry that cannot actually share their research with the community.
Computer Science: Computronium
In Nick Bostrom’s “Superintelligence”, he brings up the concept of computronium a lot. This is not a specific substance, but rather can be thought of as a state of matter in which components can form NAND-gates, and therefore can assemble into larger constructs that can form intelligence. Already we are facing the limitations of silicon as a computing medium. Some recent research has showed the usability of carbon nanotubes as a substrate for building transistors. One of my favorite demonstrations of this has been to use special glass to create an image-classifier (made possible through strategically-placed bubbles and impurities in the embedded graphene). A better general theory of computronium might have unforeseen consequences in all aspects of computing. This will probably become even more important as Moore’s law is eventually retired (which I’m in favor of being retired as a concept, as its continuation puts an unrealistic linear narrative on technological development, and it’s “end” would support an unrealistic idea of a “peak” to technological development).

Known Groups / Researchers working on this: Zongfu Yu’s team at the University of Wisconsin–Madison
Computer Science: Existential risks posed by technical debt
Lots of companies have encountered the problem of technical debt. We’ve seen how NASA has run into trouble communicating with the Voyager probes, because many of the people who know FORTRAN well enough to help them with that are either retiring, retired, or dead. In the United States, nuclear launch systems are still controlled by machines that still use 8” floppy disks. The department of defense justifies this by pointing out how this intentionally makes it difficult to be hacked. Still, if too much time passes, having too few people who know how the parts of a computer were built could pose a much larger threat. For a non-nuclear example, a lot of the challenge with fighting global warming has come from the fact that much of our infrastructure has been built up around petrochemicals. If humanity does manage to survive to the end of the century without ecological collapse or nuclear war, it’s likely such an outcome would be dependent on finding a way to dismantle and/or repurpose existing technological systems.


Known Groups / Researchers working on this: James Koppel
Computer Science: Higher-level programming languages (and actually building large systems with them)
While modern programming languages seem much more intuitive and easier to use than COBOL or Assembly, there is still a lot of room for improvement. For example, building an initial application, and then scaling up that application to thousands or millions of users often seems to require distinct skillsets. Some projects (such as the MIT Media Lab’s Scratch) have been geared towards lowering the barrier to entry for programming by making the languages higher level. One issue with projects like this is that the users often stop using the simpler language after a while, often citing that they want to move beyond tutorials, or that the language still feels like it’s for children. There are no services like Facebook or well-known apps that are built in these higher-level languages. What this means is that, in addition to the programming language theory behind the languages, this will also advance by building increasingly ambitious projects with the language. Python became popular early on with its tabular data manipulation tools, but it’s popular skyrocketed when it became the de facto language for machine learning.

Known Groups / Researchers working on this: Mitch Resnick an the Scratch team at the MIT Media Lab, unknown if anyone is seriously trying the big projects part
Computer Science: Specialized Hardware for Probabilistic computing
One of the consequences of the deep learning revolution is the emergence of specialized hardware for deep learning models. Companies like NVIDIA have released GPUs that can be used to train massive models. Companies like Google have released “Tensor processing units” (TPUs) which reduce the number of decimal places in the values for the weights, biases, and other parameters in the network (i.e., speeding up training by being stingier about the level of precision needed for some parameters). One of the best examples of Deep learning driving this design is the recent announcement by Cerebras that they’re developing a 400,000 cores GPU chip (compared to 5,000 cores in typical high-end GPUs) by using an entire silicon wafer to construct one gargantuan chip. There is one major problem with these hardware designs: They’re built with the most popular backpropagation-based ANN algorithms in mind, and these algorithms are far from perfect. Any neurologist can tell you how ANNs do not actually resemble real neurons that much, but one of the more major flaws is that such ANNs often fail to take into account he uncertainty surrounding the data or their decisions (a property that contributes to their weakness in the face of adversarial attacks). One approach to fixing this is by replacing these ANNs with probabilistic or bayesian neural networks. In such networks, the parameters are replaced with probability distributions rather than specific values, and the network can in turn conclude that it cannot make a decision based on the available information. The issue is that Bayesian and probabilistic machine learning is still this: while recent work on probabilistic bit (p-bit) transistors is very promising, probabilistic machine learning may need something on the scale of p-bit GPUs before it can truly become popular. I also want to stress that this probabilistic hardware can and should be achievable without being dependent on Quantum computing.
Known Groups / Researchers working on this:Shunsuke Fukami and his colleagues at Tohoku University in Japan and Purdue University in Indiana
Computer Science: Intuitive Visual cryptographic proofs
Everyone has been talking about how deepfakes make it harder to trust video evidence. At the same time, you can find many more papers on how to build better deepfakes than how to detect them or act against them. One of the proposed methods is to have a pixel in the video that’s set to a specific color code based on the encryption of the rest of the pixels in the video (either that frame, or the entire video itself). Still, requiring a video player or software to verify a video might not be enough. If faked videos or images are to be combatted, it may be necessary to create proofs that are even simpler. It’s possible that a version of zero-knowledge proofs (proofs where you don’t show the solution, but rather proof that you know the solution less directly) could be a framework for this (e.g., a simple green or red pixel indicating whether the image has been modified based on whether the pixels satisfy an encryption system that takes in the pixels of the original video). It’s entirely possible that a new file format could be created for this, so that the proof of authenticity (or lack thereof) exists without a special reader (in practice, this could potentially be similar to the tools that Facebook uses to embed tracking tools in your images posted on Facebook so it can find where else they are used on the web).

Known Groups / Researchers working on this: Amber team at Unveiled Labs
Computer Science: Lexicographic conversions between algorithms and legal codes
Smart contracts garnered a lot of excitement for creating automatically enforceable legal contracts. There’s one problem though, the people with the knowledge of how to make and read the smart contracts and the people who know how to develop legal documents often aren’t the same people. For example, consider a smart contract based on the outcome of a prediction model when you provide Team X and Team Y for a given sports game:
Prediction result (that Team X wins) = Infer prediction model with Team X against Team Y
If ( Prediction result > 0.80 ) { send Money to bet Team X wins }
Else if ( Prediction result < 0.20 ) { send Money to bet Team Y wins }
Else { do nothing }Smart contracts are usually far less legible than this.
This issue also works the other way around. For example, suppose we had an algorithm for drawing districts with minimal gerrymandering.

How would it be translated into a form that could be incorporated into a state or national law/constitutional amendment? How could such an algorithm be conveyed so that some random state representative in Arkansas could understand it without a CS background, for example?
Known Groups / Researchers working on this: Aquinas Hobor’s team at National University of Singapore & Yale-NUS College (understandable enough to find bugs/loopholes easily, but not quite the understandability described above)
Materials Science
There’s some overlap with computer science and biology. The rationale behind this section was the knowledge of how technologies like cheaper aluminum manufacturing or vulcanization impacted modern society. This part resulted from thinking of other hypothetical advances that could have similar impact:
Materials Science: High-energy Radiation insulation
One of the challenges faced by everyone working on quantum computers is that while there is theoretically a lot you could do with just a few Qubits, the intrusion of outside radiation requires Quantum systems to have a lot of redundancy. By some estimates, you would need 100 replicate Qubits in our noisy universe to replicate the behavior of a single Qubit in a noise-free universe. At least one pessimistic mathematician has suggested that quantum-computing itself may be intractable, on the grounds that the noise contaminating the system would scale along with the number of Qubits being used in the processor. If this truly is the case (and I’m praying to Atheismo that it’s not), our only remaining option would be to find some way of shielding computers from the rest of the universe.

Known Groups / Researchers working on this: Unknown
Materials Science: High-density self-healing materials
With few exceptions, a lot of our materials are not resilient in a temporal sense. When neglected and exposed to the elements, steel-reinforced concrete cracks as the steel inside rusts and expands. While there is a lot of research into softer materials (like plastics) that can self-repair, there seems like a comparative lack in the space of harder substances like metals or ceramics. One company is making microbes that can be stored as spores within cement. When the spores become exposed, they can use calcium deposits to repair the crack. Such advances would not only reduce the cost of infrastructure maintenance, but would also make space colonization much easier. Living on Mars would be much more straightforward if repairs from pressure leaks or micrometeorite strikes were automatic.

Known Groups / Researchers working on this: Henk Jonkers’ team at TU Delft. Here is also a good short summary of some of the technologies being used in self-healing cement & concrete
Materials Science: Incorporation of still-living materials into structures
A general extension of the example from the self-healing materials. Examples of this include trees that can be modified to become actual buildings. Construction with cement is one of the largest sources of greenhouse gas emissions that most people do not realize. One possible way of sequestering carbon AND maximizing economic growth at the same time would be to make the building process itself sequester carbon.
Known Groups / Researchers working on this: Henk Jonkers’ team at TU Delft. Here is also a good short summary of some of the technologies being used in self-healing cement & concrete
Biology
Given that my original background was in aging biology, a lot of the parts of this section are at least tangentially related to biological aging. Aging as a whole easily qualifies as an under-researched field, but there are still certain subfields and overlapping fields that seem to have much lower (current research efforts)/(potential impact) ratios than others.
Biology: Cryobiology
Cryobiology is the study of living things at low temperatures.

What can be done with this? Tim Urban wrote an excellent piece describing the rationale of cryopreserving one’s body after death. Aside from pointing out that with cryopreservation your chances of reservation are slightly slightly more optimistic than “crapshoot”, he also mentions the usefulness to research. Back in 2016, a team at 21st Century Medicine described their new technique for aldehyde-stabilized cryopreservation, which allowed the cells of a rabbit’s brain to be preserved at -135 °C (-211 °F) with minimal damage to the neuronal membranes’ structures. Being able to preserve such delicate structures without them being shredded by ice crystals might be crucial for brain-mapping efforts. On the more immediately beneficial side a team at Mass General hospital demonstrated a method for storing human livers for transplant at much lower temperatures, increasing the maximum storage time from 3 hours to ~27 hours. I think that out of all the topics I list here, cryobiology is one of those with much more dramatically obvious benefits, even beyond someday preserving transplantable tissues as easily as we would food from the supermarket.

Known Groups / Researchers working on this: 21st Century Medicine, MGH Transplant Center
Biology: Immortal Model Organisms
Aging research typically progresses by either increasing the total lifespan (or length of the fraction that is healthy) of a shorter-lived model organism one intervention or modification at a time, or improving the prognosis for some chronic age-related conditions in humans. These are the approaches that have more obvious transitions to addressing aging symptoms in humans. However, I think there are some fundamental questions regarding how living things interact with time that are not even being asked. For example, what kind of “immortality” (put in quotes because if the universe itself won’t live forever, then by extension neither will anything else inside it) should the field of aging research ultimately strive for? What would it take to make a model organism like budding yeast immortal? Should we define immortality as a death rate that is statistically independent of chronological age, or something else entirely? Obviously, even making something as insignificant as yeast “immortal” might require huge leaps in experiment automation and parallelization. Even with these advances, it would still demand enormous resources, like the kinds at the disposal of large government research budgets or organizations like Calico. Still, a project like this could go far to answer questions such as which parts of aging are programmed, and which parts are just inevitable extensions of thermodynamics.

Known Groups / Researchers working on this: Unknown
Biology: Biological Radiation resistance
Like the one above, this also has some overlap with aging. In order to remain “living”, living things have to maintain homeostasis (i.e., a consistent internal environment). The evolution of animal life on earth can be thought of as a progression of increasingly inventive ways of maintaining a stable internal state. Land-dwelling animals gained some independence from whatever varying levels of elements were dissolved in the ocean. Birds and Mammals can maintain a less variable internal body temperature than ectothermic animals like reptiles. Avian respiratory systems evolved anterior and posterior air sacs to ensure consistent oxygen flow. One of the areas where most living things have faltered by comparison in has been radiation resistance. This makes some sense, as aside from natural uranium deposits or radon-filled caves, most animals do not need to deal with random gamma ray bursts or any other unusual radiation spikes. Even with measurable variation in background radiation among the world’s cities, it’s difficult to find variations in cancer risk that are directly attributable to background radiation. However, when it comes to surviving for much longer periods of time (i.e., I’m bringing this back to aging again), or surviving in an environment like outer space, improved radiation resistance is a much more pressing need. When it comes to maintaining homeostasis, this is one area that most animals have not had a chance to significantly develop, outside of organisms like tardigrades that have evolved this trait as a side-effect of desiccation-resistance. As humans, not only do we have a pressing need to develop this, unlike other animals we have the ability to develop radiation countermeasures.
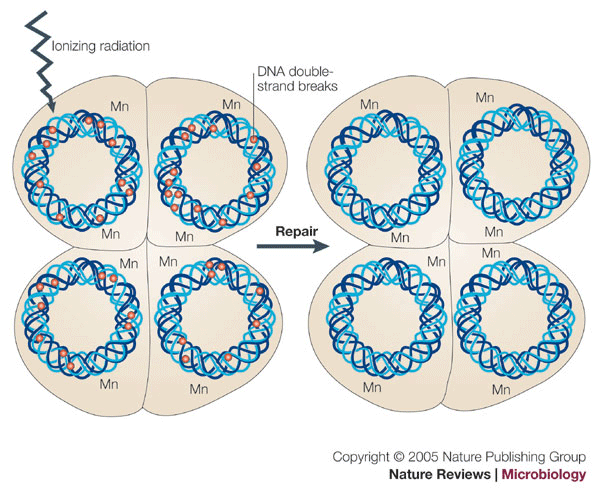
Known Groups / Researchers working on this: Laboratory for Radiation Biology, School of Medicine, Tohoku University, Abraham Minsky’s team at Weizmann Institute of Science
Biology: Chaotic systems in biology
One of the common assumptions in biology is that in their ideal functioning form, systems often behave in predictable cycles. Outside of this behavior, these systems are considered broken. However, if we ignore some of these metastable states, we might be ignoring critical parts of how life functions. J.E. Skinner was perhaps one of the most well-known biologists to write about low-dimensional chaos in biological systems. Similar to how computer science concepts from the 1980s & 1990s are being revived due to more convenient hardware, I think the availability of tools like reservoir computing make revisiting some of Skinner’s ideas (not to mention finding better mathematical formalizations for them) worthwhile.

Known Groups / Researchers working on this: Andrew C Ahn at HMS
Geoscience
Given the sheer scale of resources that might be required, it’s slightly more forgivable that these areas are under-investigated than the under-investigated sub-fields in computer science.
Geoscience: Terraforming & Weather control
I’m aware of how ironic it is to suggest this area, especially after mentioning chaotic systems in biology just a couple lines up. Weather is famously given as an example of a system in which measurement error or rounding decisions can lead to massive differences between prediction and reality after only two weeks. That being said, there’s still plenty of room for accurate predictions in the space prior to the two-week mark, not to mention the fact that long-term patterns in climate are much more tractable. Technologies such as cloud seeding have existed for decades and there is still a lot of room for improvement in finding less toxic alternatives to silver iodide for seeding, or figuring out which types of seeding increase or decrease the chances of hail/rain/snow. If any of the proposals for massive a forestation to combat global warming are taken seriously, they will need a lot of help from weather modification to be able to encroach on Earth’s expanding deserts.

Known Groups / Researchers working on this: Desert Research Institute (DRI)
Geoscience: Exploration of Earth’s Mantle
One Italian team suggested embedding a probe into a hematite deposit, dislodging it with underground nuclear explosions, and getting gyroscope and accelerometer data as it travels through the upper mantle. A litany of unsolved problems in geology could be solved with this data. Such data could be useful in figuring out the structure of the 660 km discontinuity and its relation to our models of polar drift, potentially also an explanation for the chandler wobble. Of course, the main challenges behind this are are still 1) building a probe that can send the information through kilometers of solid rock, and 2) getting governments to approve of both the massive explosions and the massive use of hematite.

Known Groups / Researchers working on this: [David J. Stevenson] (though there hasn’t been much news of this since the early 2000s)
Economics
While it is common to pay lip service to economic frameworks like Keynesianism or Capitalism or Marxism, there are a bunch of scenarios that these frameworks are pretty terrible at dealing with.
Economics: Intentionally Self-destructing organizations
An often-cited contributor to economic or governmental stagnation (like the kind referenced in Tyler Cowen’s work) is organizations that have optimized for keeping themselves in existence rather than their original mission. Even charities may optimize for the ability to consistently raise large amounts of money, rather than addressing the issue they claim to fix. How do we create incentive structures for organizations to both solve their intended problem, all with the knowledge that at if they succeed they might be disbanded. While this has been a vexing problem for some time, I think some recent technological advances put possible solutions within reach. Consider a smart contract where for every ethereum token added, the depositor gets back two ethereum tokens. This would be a pretty attractive offer. However suppose that if a certain percentage of all the available ethereum tokens (say, 50% of all available tokens) are added to the account, those tokens are burned or destroyed (or switched out with some other entirely different token). This scenario provides a simplified example of how people could be incentivized to rush towards a goal, even with the knowledge that the organizing structure around it would self-destruct at some point.

Known Groups / Researchers working on this: Unknown
Economics: Successful anti-corruption strategies
How does one remove corruption in either organizations or countries. Bruce Bueno de Mesquita and Alastair Smith put forth the thesis in The Dictator’s Handbook that corruption is partially a function coalition size, or the number of people that a leader needs to rely upon to stay in power (with dictatorships having smaller coalition sizes, and democracies being defined by larger coalition sizes). In small-coalition systems, an autocrat stays in power just by keeping their inner circle happy rather than the populace. This is given as an explanation not just for autocracies redirecting foreign aid to benefit the ruling elites, but also for situations like corporate executives giving themselves massive bonuses even when company performance didn’t meet goals. However, de Mesquita and Smith pointed out that there are some scenarios in which the coalition size needs to be increased (i.e., power being diluted among more people) in order for the leaders to stay in power, such as during the fall of the Soviet Union. The question is how can we find examples of successfully-implemented anti-corruption strategies, and make future strategies based off of them? In some ways this is similar to the self-destructing organization, but instead it is a question of a self-diluting coalition. This is also not to suggest that this be the only guideline for finding other examples of anti-corruption success stories.

Known Groups / Researchers working on this: Bruce Bueno de Mesquita, Alastair Smith
Economics: Organizational psychology and operations for unions
Corporations and private enterprises typically receive the lion’s share of talent when it comes to improving organizational efficiency. Unfortunately, despite the best intentions, unions and labor organizations have fallen far behind in this arms race.
Known Groups / Researchers working on this: Unknown, save for one stealth startup I’ve interacted with personally
Economics: Charter Cities
More precisely, this refers to the economics behind building attractive new cities in the middle of nowhere. For example,if one were to build cities in the middle of the Sahara, the middle of the ocean, how would one create one from scratch? Would we need to modify this if we wanted to settle the Antarctic, the Moon, or Mars? Inspiration for research directions could include China’s special economic zone projects, or research into successful intentional communities (both religious and irreligious) and what distinguishes them from those that failed.

Known Groups / Researchers working on this: Blue Book Cities
Economics: How to account for the revealed preference problem
Because someone can afford all the options, doesn’t necessarily mean they are revealing preferences. This is a big problem with Money in speech. Politics aside, researching ways of bridging the gap between how much one can pay for an option vs. how much they can afford to pay for an option is going to be critical for market design to be effective. Outside of law enforcement (for example, fines being scaled up based on the offender’s income, though this is a largely unsettled question in the United States), there seems to have been little serious effort on this front. In some ways the motivation for not investigating makes sense; If you can successfully generate cash flow, you may question how much it really matters what the revenue reveals about someone’s preferences
Known Groups / Researchers working on this: Unknown, save for economists pointing out the flaws since the 1970s.
Neuroscience
Extending from the biology section above, this part covers under-investigated subfields in neurology and psychology.
Neuroscience: Different categories of neural plasticity
You are probably familiar with the concept of neural plasticity. You are probably aware that in the early 20th century the brain was thought of as static in terms of its function, and then researchers found many ways in which the connections in the brain could change in response to repeated exposure to certain tasks or stimulus, and that this phenomena is observable in all age groups. The problem with neural plasticity is that it has been described in so many different scenarios, and has been applied to so many different tasks, that invoking “neural plasticity”has ceased to become more informative than invoking the “practice makes perfect” concept that humans have already known about for millenia. Machine Learning researchers are often criticized for extrapolating that a single-multipurpose algorithm could be used to generate systems that resemble human-level intelligence. My opinion is that we should cut such ML researchers some slack, not because I think they are correct, but because neuroscientists seem to be guilty of similar assumptions that are almost too general to be useful or explanatory.
Known Groups / Researchers working on this: Unknown
Neuroscience: Extreme Empathy
When it comes to lack of empathy, there is plenty of research into this. Countless economists and law-enforcement officials have devoted their careers to understanding this, and I probably don’t need to tell you the value in understanding. By comparison, I believe there is less research focus than there should be on people who exhibit unusually high levels of empathy. I refer to cases of empaths who may feel the emotions or mental states or physical discomfort of others much more strongly than most people (or in extreme cases may do things like donate organs to total strangers). From an economic standpoint, it’s worth exploring non-monetary motivations for actions in much more depth (see Michael J. Sandel’s What Money Can’t Buy: The Moral Limits of Markets). This also may be useful in research into curing psychopaths, possibly by suggesting symptoms of recovery that would be difficult or unusual for a true psychopath to fake. After all, if you’re trying to treat individuals that are usually only diagnosed long after childhood, and are often extremely dangerous to those around them, overshooting when it comes to treatment aims may not be the worst thing. A non-behaviorist understanding of differences in motivations is especially valuable if you are trying to determine whether or not a subject is just feigning empathy.
Known Groups / Researchers working on this: Unknown
Neuroscience: Healthy psychological baselines
One frequent criticism of psychology over the past century has been it’s overwhelming focus on diseases and conditions, with comparatively less thought about what an ideal healthy state looks like. The recently released DSM-5, covering a much wider array of symptoms than previous versions, have caused some mental health professionals to wonder if some diagnoses might be overreactions to completely normal behaviors. The Positive Psychology movement is a step in the right direction, but there are still plenty of questions that too few are even asking. What does the overall structure of the brain look like in its ideally healthy state? Are there multiple distinct healthy baselines? At a structural level, are there consistent patterns in the Default Mode network (DMN) in healthy baselines? How many of these symptoms of health can any mortal really be expected to exhibit simultaneously?
Known Groups / Researchers working on this: Unknown. Verily is mainy focusing on overall physiology
Neuroscience: Anti-neurosis & PTSD-resistance
Is it possible to condition someone, either through traditional psychological conditioning or pharmacologically to be resistant to PTSD, no matter how much pain? The book series Altered Carbon featured an interstellar human empire, whose distant worlds were enforced by “envoys”. These envoys were not just soldiers, but also political operators trained to be able to start and/or stop rebellions, and install new governments loyal to Earth. In addition to superhuman intuition, the Envoys were given the ability to resist torture, while also remaining psychologically intact after truly harrowing experiences. While scenes from the book show that it doesn’t always work so well for them in practice (e.g., this conflicts with their engineered perfect recall, not to mention Envoys typically are banned from public office due to sociopathic traits), it did raise the question of what it would take to create resistance to neurosis or PTSD. Already some groups are looking into possible genetic predisposition (Dr. Liberzon’s group at Mt. Sinai has been investigating how SNPs in ADRB2 may affect how soldiers recover from trauma), but this space is still in its infancy. After all, there are likely different treatments for different types of trauma. Even beyond trauma research, investigations into common backgrounds or genetic factors behind people who score exceptionally low on the Neuroticism (N) axis of the Big5/OCEAN/CANOE traits could have far-reaching benefits (beyond just something other than MBTI for Ray Dalio to obsess over).
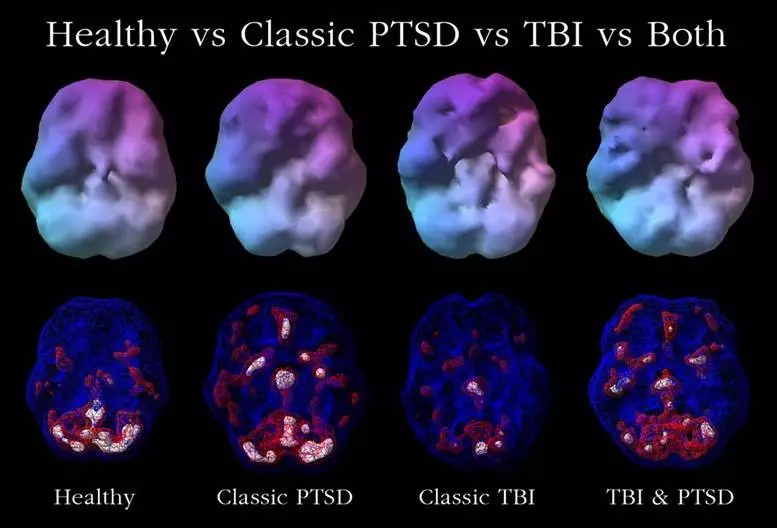
Known Groups / Researchers working on this: Dr. Liberzon’s group at Mt. Sinai
Neuroscience: Necroneurology
I couldn’t find any named sub-fields or names of journals focusing on this particular area (I’m willing to accept that I may have just been looking in the wrong areas). I’m defining “Necroneurology” study of nervous physiology changes around death. Not only does this include precisely defining the nature of the damage (e.g., how does cellular structure or gene expression change after clinical death), but also investigating methods for slowing, halting, or potentially reversing damage. While the work of groups like the Borjigin Lab at UMichigan is a step in the rigtht direction, I think we need to go further. One particularly valuable piece of research I came across in this space was a recent project involving keeping pig brains functioning hours after they had been removed from the rest of the body. Recovery from certain types of brain injury may only be possible with further research like this (and we should probably conduct this research more often than once every 56 years). If any advocates for cryonic preservation want to realize their dreams of being recovered from the deep freeze, we first need to become supremely competent at restoring brain function when the rest of the body has become less than reliable at providing life support. At the very least, there are plenty of ethical and legal questions that need to be answered before someone tries going further, such as inducing awareness in a disembodied brain. As we saw with CRISPR experiments on humans, just counting on scientists everywhere to not go through with a line of research is by no means foolproof.


Known Groups / Researchers working on this: Borjigin Lab at UMichigan
Neuroscience: Communication of Probability and Uncertainty
This refers to the psycholinguistics of how to get humans to visualize and intuit probabilities other than 0%, 1%, 50%, 99%, and 100%. When it comes to democracies making financial decisions for the long-term future, or even understanding the results of the latest IPCC report on global warming, accurately communicating uncertainty is critical. This has some overlap with computer science, and some overlap with design. There is also likely more insight to be gained from how people such as professional stock traders or IARPA challenge leaders interpret probabilities, and if there’s a simple way to improve this ability in laypersons. For some examples of creative solutions to the visualization problem, I would look at this excellent explanation at Nathan Yau’s FlowingData.

Known Groups / Researchers working on this: See the CIA, HBS, & FlowingData mentioned above
Architecture
Fewer examples here than in the other fields, but there still seemed like a few areas for massive improvement.
Architecture: Large-scale Reconfigurable architecture
In the book “The Great Stagnation”, Tyler Cowen attributes the loss of undeveloped land as a contributing factor to the perceived stagnation. A possible solution: architecture that’s designed to be easily modified and reconfigured or extended at some point in the future. An architectural movement loosely inspired by Hasbro’s Transformers might not be a bad thing. For example, many large particle accelerators are reconfigurable to a certain degree to accommodate experiments in many fields. If olympic stadiums could be built with similar reconfigurability in mind somehow, this would make hosting the Olympic games much less of a drain for any hosting cities. This could even be combined with the self-destructing organizations and anti-corruption problems mentioned above. For example, prisons that can be reconfigured for more profitable non-prison use if there are too few prisoners to house, in order to safeguard against perverse incentives from private prisons or corrupt government officials. This school of architecture could potentially be made more popular if it is made known as an anti-corruption signal.

Known Groups / Researchers working on this: Unknown, at least when it comes to the scale described above
Mathematics
One of the challenges in mathematical research is that it’s often tough to define a full day’s work. A lot of mathematical discoveries seem heavily dependent on finding that 1% of inspiration, even in projects that use computers to come up with brute-force solutions for problems. Still, I suggest a few areas where it might be beneficial if mathematicians kept them in mind more often.
Mathematics: Techniques for combining dependent instead of independent p-values for meta-analysis
Though independent p-values can be combined using Fisher’s method, techniques for handling the case of dependent p-values are still lacking. As such, this may result in cases where the assumption of independence is applied to real-world scenarios where it does not actually hold. For example, consider the infamous case of banks before the subprime mortgage crisis assuming that the chances of more than 8% of home-owners defaulting on their mortgages independently at the same time were negligible. This also has importance with regards to meta-analysis, or the process of looking at a bunch of experiments focusing on the same question and being able to summarize the results.

Known Groups / Researchers working on this: Unknown (obvious difficulties in finidng mathematicians with partial results on this)
Mathematics: Experimental design using solutions to problems in Latin Squares
As the theory of Latin squares is a cornerstone in the design of experiments, solving the problems in Latin squares could have immediate applicability in this space. In other words, solutions regarding research into the Bounds on the maximal number of transversals in a Latin square, Characterization of Latin subsquares in multiplication tables of Moufang loops, Densest partial Latin squares with Blackburn property, or the Largest power of 2 dividing the number of Latin squares could potentially result in more robust experimental design.

Known Groups / Researchers working on this: Unknown (obvious difficulties in finidng mathematicians with partial results on this)
Mathematics: Patterns among proofs for subspace-packing problems
I recently posted a rant about this on Twitter, but here it is again. This is related to the topic of Grassmannians. In short, the Grassmannian space is the space of all -dimensional subspaces of -dimensional Euclidean space. The packing problem is to find the best packing of of these subspaces. In other words, you need to choose points in (or lines, or planes, or whatever the lower dimensional form is) so that the minimum distance between any two of them is as big as possible. An applied example: How should 16 laser beams passing through a single point be arranged so as to make the angle between any two of the beams as large as possible? Or another example: You have a table of data with 4 columns and you want to project it onto the screen in 48 different ways. Which set of 48 planes in 4-space should you use for the projections? You could also refer to the classic framing as how best to pack a bunch of multidimensional tennis balls. Basically, this particular concept has a bunch of use cases from quantum error correcting codes, to signal processing, to even facial recognition. BUT, outside really small values for , , and , (try saying that five times fast) solving for these optimal configurations is monstrously hard. In fact, this is still one of those areas where it’s more practical to keep lists of known solutions (thank you Neil Sloan), than computing them from scratch, kind of like lists of p-values your old statistics textbook or one of these old books of pre-calculated logarithms. In fact, solutions to higher dimensional solutions are those kinds of problems that go unsolved for decades, and when they are solved in a specific case they make the news. If you did have a general-purpose algorithm for optimal Grassmannian packing solving, that would probably earn you at least a Fields medal and near-guaranteed tenure at a university of your choosing.
Why is now a good time to focus on this area if these packings have been unsolved for decades? Because now we are making incredible advances in automatic theorem proving. While theorem-checking has existed for a long time in tools like Coq (yes, pronounced exactly like you hoped it wasn’t), for the first time there are teams that can learn from the structures and strategies past proofs and develop new ones. Even better, some of these methods can then learn from these new correct proofs that they generated and improve even further. Patterns among proofs for high-dimensional Grasmannian packings could also make use of recent advancements of in-memory hyperdimensional computing. If it truly does become the case where understanding general patterns among proofs for hard problems is only limited by available training data, then this might be an area of mathematics that’s more dependent on the 99% perspiration than the 1% inspiration (This is also probably one of the few areas where that Thomas Edison quote is even more relevant when you take into account that he had a lot of workers doing that “perspiration” in parallel).


Known Groups / Researchers working on this: Kaiyu Yang & Jia Deng (on the automatic theorem generation aspect)
Physics
Modern Physics often gets a lot of criticism for investigating areas where hypotheses can’t be proven or disproven, or that have little foreseeable use cases. Here are a few areas that probably deserve more attention than they are currently getting:
Physics: Increasing Iteration Speed of Experimental Physics
The speed with which science advances is often directly related to how quickly scientists can run, learn from, and iterate on experiments and observations. While some fields are inherently limited by their subject matter (e.g., geologists monitoring volcanoes, botanists studying crop rotation or long-lived plants), there is plenty of room for improvement in the space of nuclear and particle physics. How can we design facilities for resource-intensive physics experiments to be readily reconfigurable and rapidly-reusable? Researchers at companies like TAE Technologies are working on speeding up their nuclear fusion experiments in hopes of being able to make use of probabilistic machine learning. Multiple groups are working on tools such as Laser wakefield particle accelerators, which, if successful, may allow more researchers to run their experiments without taking up bandwidth at the crowded Lawrence Berkeley National laboratory.
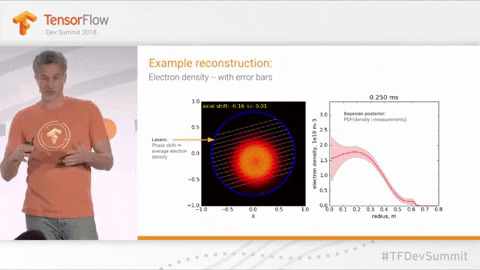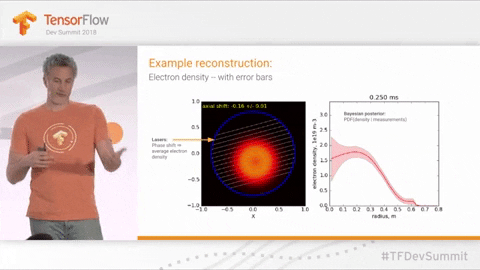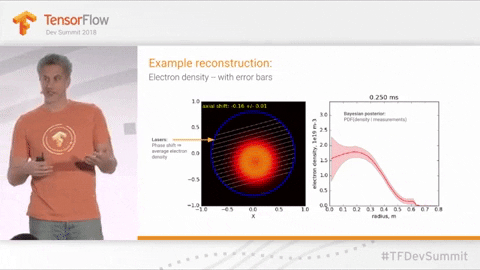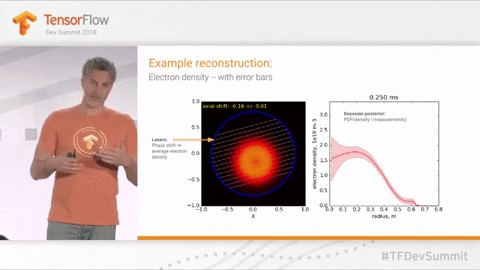
Known Groups / Researchers working on this: TAE Technologies
Physics: Reservoir Computing for Dynamical Systems
Reservoir computing is a special type of machine learning for Dynamical systems. In this framework, the input signal is fed into a random but fixed selection of neurons (the “reservoir”), which allows the patterns of the input to be mapped to a higher dimension. From here, it’s easier to map the input to an interpretable output, be that either classification or regression or some other form. Just last year, a team at Jacobs University in Bremen, Germany published results detailing how this could be used to make predictions for the behavior of dynamical systems much further into the future than previously possible. While the IEEE Task Force on Reservoir Computing (also created just last year) is a step in the right direction, this still deserves the attention of man more theoretical and applied physicists.
Known Groups / Researchers working on this: Herbert Jaeger’s team at Jacobs University, Edward Ott’s team at University of Maryland
Physics: Ball lightning
Outside of Nikola Tesla’s poorly-documented experiments on the subject, not much is known about ball lightning. The first full optical spectrum of ball lightning wasn’t even recorded until 2014, and a general explanatory theory for it still doesn’t exist. Given the possibility for reducing danger in high-altitude aviation, possible explanations for some UFO sightings, understanding of other atmospheres in the solar system, or still still-unknown benefits, I’m nominating ball lightning as a phenomenon deserving of more attention.

Known Groups / Researchers working on this: Simin Xue’s group at Northwest Normal University
Physics: Nuclear-powered propulsion for Aeronautics
I want to stress that when I nominate nuclear-powered propulsion as deserving of more attention, I’m specifically referring to the use case of space travel, NOT in trying to gain an edge in the race-to-the-bottom Mexican Standoff that the world’s nuclear superpowers have been trapped in since the advent of atomic weapons. After all, if any nation gets around the safety issue of putting lots of fissionable cargo onto a rocket, this would make it easier for any Mars astronauts to use thermoelectric batteries to speed up the early stages of colonization.

Known Groups / Researchers working on this: Unknown (outside Russian Military)
Physics: What is the actual value of “Mathematical beauty”?
Since before Ptolemy’s use of epicycles to justify the geocentric model of the universe, “mathematical beauty” or mathematical orderliness has often been used to argue in favor of certain models of physical phenomena. How much are we actually supposed to rely on this concept when it comes to understanding reality? Does every physical law proposed need to look like an applicable-everywhere precursor to a “theory of everything”? Is there unrealized value in mathematical ugliness? So many areas of science and mathematics are still permeated by some form of essentialism, but it’s often been the case that advances in our understanding of the universe came about by rejecting this assumption. For some well-known examples: Relativity rejected notions of absolute space or an ether, quantum mechanics dashed hopes of deterministic measurements of fundamenal particles, and Chaos theory finally accepted that real-world periods of pendulums weren’t as fixed or rigid as had been taught since Galileo’s time.

Known Groups / Researchers working on this: Unknown (obvious difficulties in finidng physicists with only partial results on this)
Philosophy
I saved this part for last because the under-explored areas in philosophy strays the furthest from the scientific rigor requirements I mentioned towards the beginning of this post. Still, putting all our cards on science and not on philosophy can only get us so far. After all, the demarcation problem in the philosophy of science is still unsolved. Like with the mathematics section, this part recommends areas where it would probably be better for more scholars to keep these concepts in mind (at least if there is no close allegory for actively working on them in the same sense as material-outcome-focused scientific work).
Philosophy: Experimental Ethics
Anyone that’s taken an intro philosophy course is aware of how many different moral frameworks there are (utilitarianism, deontological, Nietzschean, etc.). Given that we’re aware of the choices, it’s much more imperative that we also understand how we should decide on which of these choices and frameworks to abide by. This topic has been touched upon by researchers ranging from evolutionary biologists, psychologists, neuroscientists, and behavioral economists. The key difference is that these researchers have worked to explain what and why we have certain moral intuitions, but have avoided the question of what we should feel. Philosophers like Kwame Anthony Appiah have made the case that morality shouldn’t be completely independent of the sciences, and that scientific reasoning about morality doesn’t necessarily undermine its authority (I recommend taking look at Experimental Ethics: Toward an Empirical Moral Philosophy). This is an especially important field given the pace of advancement in autonomous vehicles and autonomous weapons. After all, if we are giving these devices the agency to act in the real world, we need to decide what framework they should use for situations that boil down to moral choice.

Known Groups / Researchers working on this: [Kwame Anthony Appiah](https://en.wikipedia.org/wiki/KwameAnthonyAppiah), to name the most famous.
Philosophy: Effective Altruism
Put simply, this refers to the use of reasoning and evidence to determine the most effective ways to benefit others. While this area has been popularized by public figures such as Peter Singer, Dustin Moskovitz, and William MacAskill, I’m still including this in the space of under-researched fields given that its stated mission is literally how to most effectively benefit others. A field may be criticized as “over-researched” when it reaches a point where incremental improvements in knowledge or understanding either result it comparatively little benefit, or even begin to have a prohibitively high cost (a common criticism of high-energy particle physics).

Known Groups / Researchers working on this: Effective Altruism
Philosophy: Improving the iteration speed of scientific knowledge
I saved this and the next one for last because it pertains to under-researched fields as a whole. One of the common reasons why certain fields may go under-researched is because our current scientific review and publication process does not support them. Regarding publishing as a method of updating our scientific understanding, it has definitely seen better days. Ideas that should be retired may not be caught because publication bias does not favor retractions or corrections. It’s usually only the positive results that are viewed as publishable. Plus, results of research may often only be visible to small, anonymous groups of people for long stretches of time before they’re made visible to the public. If we want to improve on the iteration speed in scientific research, one of the more promising ways would be to incorporate methods from software engineering. Software engineering has gone from waterfall projects that release updates as standalone monoliths from a closed-source warehouse, to agile-developed remotely-updated differential improvements that may be supported a large community. Academic literature by contrast is still structured as it was in the early days of physical publishing, and has barely adapted (and this is putting it extremely kindly) for tasks such as retractions or sharing data. Citations often do not distinguish between which works are being used as supporting material, which are discredited, which are being supported, or which are being used as examples (positive or negative). The idea of making techniques like revision control, bug-flagging, and dependency management available for scientific research (much like what software engineering uses) is a change I’m definitely in favor of. Some projects are already underway in restructuring scientific knowledge into these kinds of collaborative tools, such as Roam Research or the Polymath Project. Having a scientific literature version of Knowledge Graph would be a far superior alternative to the increasingly bureaucratic review and publishing process.

Known Groups / Researchers working on this: Roam Research, the [Polymath Project](https://en.wikipedia.org/wiki/PolymathProject)_
Philosophy: Alternatives to Peer-review-based funding
The alternative to peer-review-review based funding for grants is a slightly tricker, but still critical. The current peer review system came about in a time where more than 3 out of 10 grants could expect to be funded based on the balance between supply-of and demand-for public research funding. Unfortunately, the peer review system has failed to adapt to shifts in that supply and demand, and now the funding rate is in the lower single digits. As such, funding is much more critical on not only the researchers being exceptionally talented, but also intensely persistent and (most critically) really good at selling the idea that a given project will succeed. Aside from introducing much more funding insecurity (many scientists are altogether abandoning research in favor of more stable income elsewhere), this also selects against the high-risk high-reward research that’s usually the source of paradigm-shifting discoveries. Most of what remains is the easier and more straightforward projects that simply have a higher chance of succeeding. This system also neglects cross-disciplinary projects, as funding approval is dependent on having a panel of reviewers with relevant expertise in all the different fields a project would touch.
While many have introduced small tweaks to the system, they typically do more harm than good. It may be that anything short of a complete overhaul is not enough. One possible way to allocate funding on metrics that the scientific community can still agree on, such as peer esteem. A researcher’s career could be divided into four-year periods (starting with the 4 years prior to the start being “Period 1”). Period 2 is funded on low entry-level requirements (e.g., having a PhD, number of postdoc years) and without regard for specific proposal details. Period 3 is funded as a percentage of total available funds for a given discipline, and based on the citations from the previous research periods (again, ignoring specific funding decisions). Citations are weighted based on whether an applicant was a primary, secondary, or other author (and self-citations are omitted). The importance of the 4-year period becomes relevant here, as it’s an estimate of how long it would take the previous research to be published. Period 4 is funded based on similar metrics as Period 2, and so on. Across all periods, the bulk of the funding could be made available during the first year of each period for projects that are more capital-intensive. The advantage of this example system is that there is zero time spent submitting and resubmitting proposals, and the proposal evaluation process itself is simplified much more. Researchers could still apply for separate grants and make other resources available to them, and this system could conceivably still be integrated into our existing funding framework. This is still a very minimal framework, and I encourage readers to comment with possible improvements (including but not limited to new metrics that could be used to judge progress).

Known Groups / Researchers working on this: See this review
Conclusion: Next Steps
At some point in the near future, I’m going to put together a Part 2 to this list. As you could probably observe, much of this list was written while being biased towards my own research background (e.g., a lot of the under-researched areas in mathematics being problems of statistics). Part 2 by contrast will involve reaching out to subject-matter experts and getting their opinions on the under-researched sub-fields. While this would have the advantage of seeing parts that only subject matter experts would be familiar with, there is obviously the risk of relying too heavily on experts that have built their careers on what has now become mainstream research. Still I estimate that for Part 2 the upside risk to this approach far outweighs the downside.
If any readers have any suggestions for fields that I have forgotten in this exploration (or you know of subject matter experts that would be helpful to reach out to for the sequel to this post), please don’t hesitate to DM me on Twitter @MatthewMcAteer0.
Cited as:
@article{mcateer2019underinvestigated,
title = "Under-Investigated Fields List (Version 1.0)",
author = "McAteer, Matthew",
journal = "matthewmcateer.me",
year = "2019",
url = "https://matthewmcateer.me/blog/under-investigated-fields/"
}If you notice mistakes and errors in this post, don’t hesitate to contact me at [contact at matthewmcateer dot me] and I will be very happy to correct them right away! Alternatily, you can follow me on Twitter and reach out to me there.
See you in the next post 😄


