All of Adam Binksmith's Comments + Replies
Very useful post!
Slowness
Relative to other foundations of a similar size, I think OP moves fast; relative to startups, other AIS founders, and smaller organisations (i.e., almost all other AIS organisations), I think OP moves slowly.
I'm curious what this slowness feels like as a grantmaker. I guess you progress one grant at speed and then it goes off for review and you work on other stuff, and then ages later your first grant comes back from review, and then maybe there are a few rounds of this? Or is it more spending more time on each thing than you might...
I think this post's argument assumes your $100k is lost by default if you don't have a will, but on a quick GPT-5 query it looks like in the UK it goes to your spouse, parents, siblings or siblings' children, and in California something similar. Assuming you're survived by a spouse or these family members and you're happy with your assets going to them then it seems like it's not the same as cancelling a $15/mo subscription. (But plausibly still worth it, I think it just needs a bit more explanation!)
Great thanks!
We have two outputs in mind with this project:
1. Reports on a specific thinker (e.g. Gwern) or body of work's predictions. These would probably be published individually or showing interesting comparisons, similar to the Futurists track record in Cold Takes (based on Arb's Big Three research)
2. A dashboard ranking the track records of lots of thinkers
For (2), I agree that cherry picking would be bad, and we'd want it to cover a good range.
For our initial outputs from (1) though, I'm excited about specifically picking thinkers who people would ...
Very interesting!
I'd be interested to hear a bit more about what a restrained system would be able to do.
For example, could I make two restrained AGIs, one which has the goal:
A) "create a detailed plan plan.txt for maximising profit"
And another which has the goal:
B) "execute the plan written in plan.txt"?
If not, I'm not clear on why "make a cure for cancer" is scope-insensitive but "write a detailed plan for [maximising goal]" is scope-sensitive
Some more test case goals to probe the definition:
C) "make a maximal success rate cure for cancer"
D) "write a detailed plan for generating exactly $10^100 USD profit for my company"
a tool to create a dashboard of publicly available forecasts on different platforms
You might be interested in Metaforecast (you can create custom dashboards).
Also loosely related - on AI Digest we have a timeline of AI forecasts pulling from Metaculus and Manifold.
AI for epistemics/forecasting is something we're considering working on at Sage - we're hiring technical members of staff. I'd be interested to chat to other people thinking about this.
Depending on the results of our experiments, we might integrate this into our forecasting platform Fatebook, or build something new, or decide not to focus on this.
[Do you have a work trial? This will be a deal breaker for many]
Based on your conversations with developers, do you have a rough guess at what % this is a deal breaker for?
I'm curious if this is typically specific to an in-person work trial, vs how much deal-breaking would be avoided by a remote trial, e.g. 3 days Sat-Mon.
As well as Fatebook for Slack, at Sage we've made other infrastructure aimed at EAs (amongst others!):
- Fatebook: the fastest way to make and track predictions
- Fatebook for Chrome: Instantly make and embed predictions, in Google Docs and anywhere else on the web
- Quantified Intuitions: Practice assigning credences to outcomes with a quick feedback loop
This month's Estimation Game is about effective altruism! You can play here: quantifiedintuitions.org/estimation-game/december
Ten Fermi estimation questions to help you train your estimation skills. Play solo, or with a team - e.g. with friends, coworkers, or your EA group (see info for organisers).
It's also worth checking the archive for other estimation games you might be interested in, e.g. we've ran games on AI, animal welfare + alt proteins, nuclear risk, and big picture history.
I'm curious about B12 supplements - I currently take a multivitamin which has 50µg B12, my partner takes a multivitamin with 10µg B12. Should we be taking additional B12 tablets on top of this? (We're both vegan)
I saw in that post a recommendation for 100µg tablets, but google says the RDA is 2.4µg, do you know why there's this gap?
I think some subreddits do a good job of moderating to create a culture which is different from the default reddit culture, e.g. /r/askhistorians. See this post for an example, where there are a bunch of comments deleted, including one answer which didn't cite enough sources. Maybe this is what you have in mind when you refer to "moderating with an iron fist" though, which you mention might be destructive!
Seems like the challenge with reddit moderation is that users are travelling between subreddits all the time, and most have low quality/effort discussion...
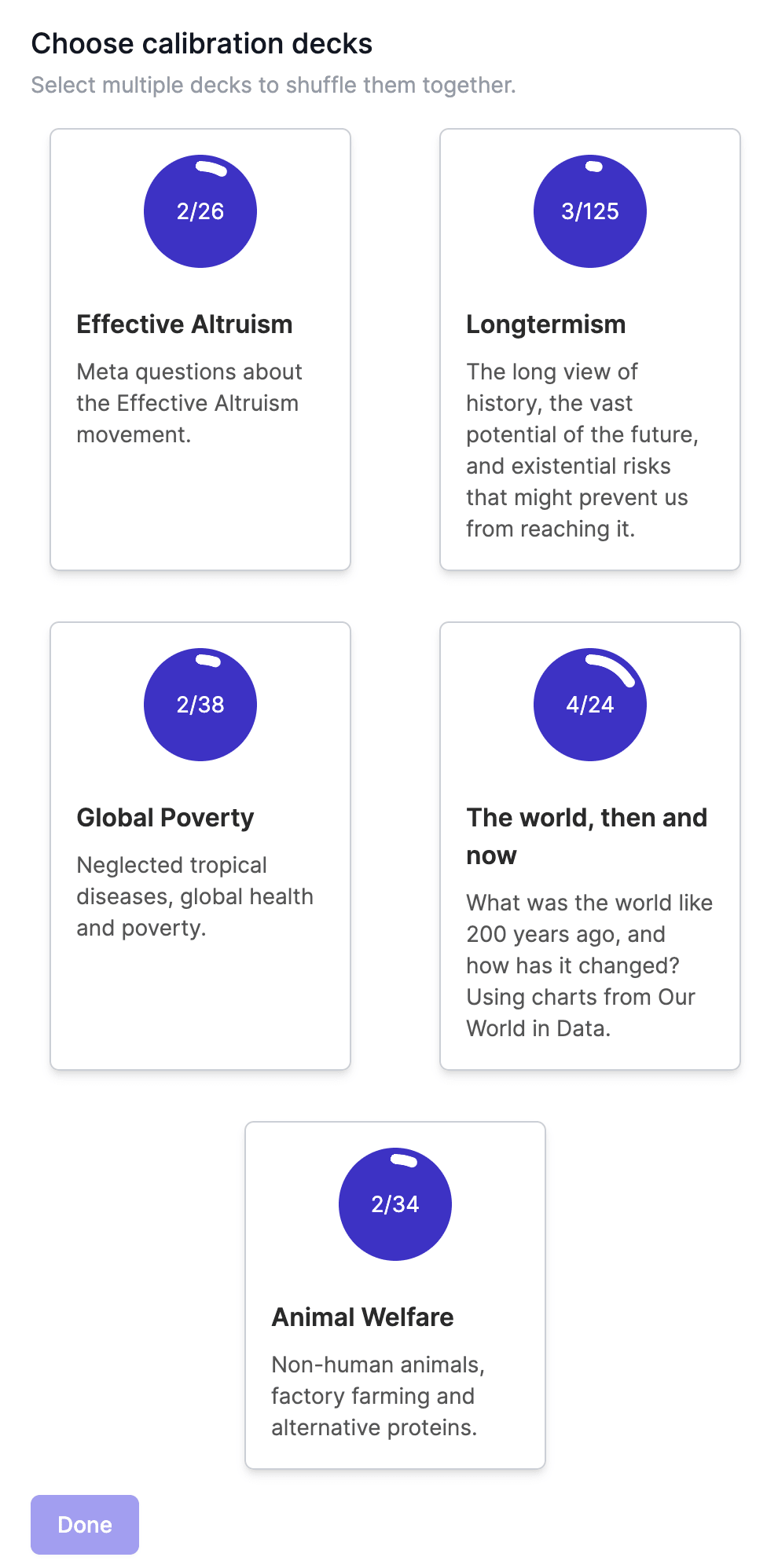
We've added a new deck of questions to the calibration training app - The World, then and now.
What was the world like 200 years ago, and how has it changed? Featuring charts from Our World in Data.
Thanks to Johanna Einsiedler and Jakob Graabak for helping build this deck!
We've also split the existing questions into decks, so you can focus on the topics you're most interested in:
The July Estimation Game is now live: a 10 question Fermi estimation game all about big picture history! https://quantifiedintuitions.org/estimation-game/july
Question 1:

Thank you!
Do you look at non-anonymized user data in your analytics and tracking?
No - we don't look at non-anonymised user data in our analytics. We use Google Analytics events, so we can see e.g. a graph of how many forecasts are made each day, and this tracks the ID of each user so we can see e.g. how many users made forecasts each day (to disambiguate a small number of power-users from lots of light users). IDs are random strings of text that might look like cwudksndspdkwj. I think you'd call technically this "pseudo-anonymised" because user IDs are sto...
Thank you! I'm interested to hear how you find it!
often lacks the motivation to do so consistently
Very relatable! The 10 Conditions for Change framework might be helping for thinking of ways to do it more consistently (if on reflection you really want to!) Fatebook aims to help with 1, 2, 4, 7, and 8, I think.
One way to do more prediction I'm interested in is integrating prediction into workflows. Here are some made-up examples:
- At the start of a work project, you always forecast how long it'll take (I think this is almost always an important question, and
In many ways Fatebook is a successor to PredictionBook (now >11 years old!) If you've used PredictionBook in the past, you can import all your PredictionBook questions and scores to Fatebook.
In a perfect world, this would also integrate with Alfred on my mac so that it becomes extremely easy and quick to create a new private question
I'm thinking of creating a Chrome extension that will let you type /forecast Will x happen? anywhere on the internet, and it'll create and embed an interactive Fatebook question. EDIT: we created this, the Fatebook browser extension.
I'm thinking of primarily focussing on Google Docs, because I think the EA community could get a lot of mileage out of making and tracking predictions embedded in reports, strategy docs...
Great, thanks!
The format could be "[question text]? [resolve date]" where the question mark serves as the indicator for the end of the question text, and the resolve date part can interpret things like "1w", "1y", "eoy", "5d"
I'm interested in adding power user shortcuts like this!
Currently, if your question text includes a date that Fatebook can recognise, it'll prepopulate the "Resolve by" field with that date. This works for a bunch of common phrases, e.g. "in two weeks" "by next month" "by Jan 2025" "by February" "by tomorrow".
If you play around w...
The June Estimation Game is animal welfare + alt proteins themed! 10 Fermi estimation questions. You can play here: quantifiedintuitions.org/estimation-game/june
Seems like academic research groups would be a better reference class than YC companies for most alignment labs.
If they're trying to build an org that scales a lot, and is funded by selling products, YC companies is a good reference class, but if they're an org of researchers working somewhat independently or collaborating on hard technical problems, funded by grants, that sounds much more similar to an academic research group.
Unsure how to define success for an academic research group, any ideas? They seem to more often be exploratory and less goal-oriented.
I'm excited to see the return of the careers guide as the core 80k resource (vs the key ideas series)! I think it's a better way to provide value to people, because a careers guide is about the individual ("how can I think about what to do with my career?") rather than about 80k ("what are the key ideas of 80k/EA?")
Great, glad to hear it!
Aggregation choices (e.g. geo mean of odds would be nice)
Geo mean of odds is a good idea - it's probably a more sensible default. How would you feel about us using that everywhere, instead of the current arithmetic mean?
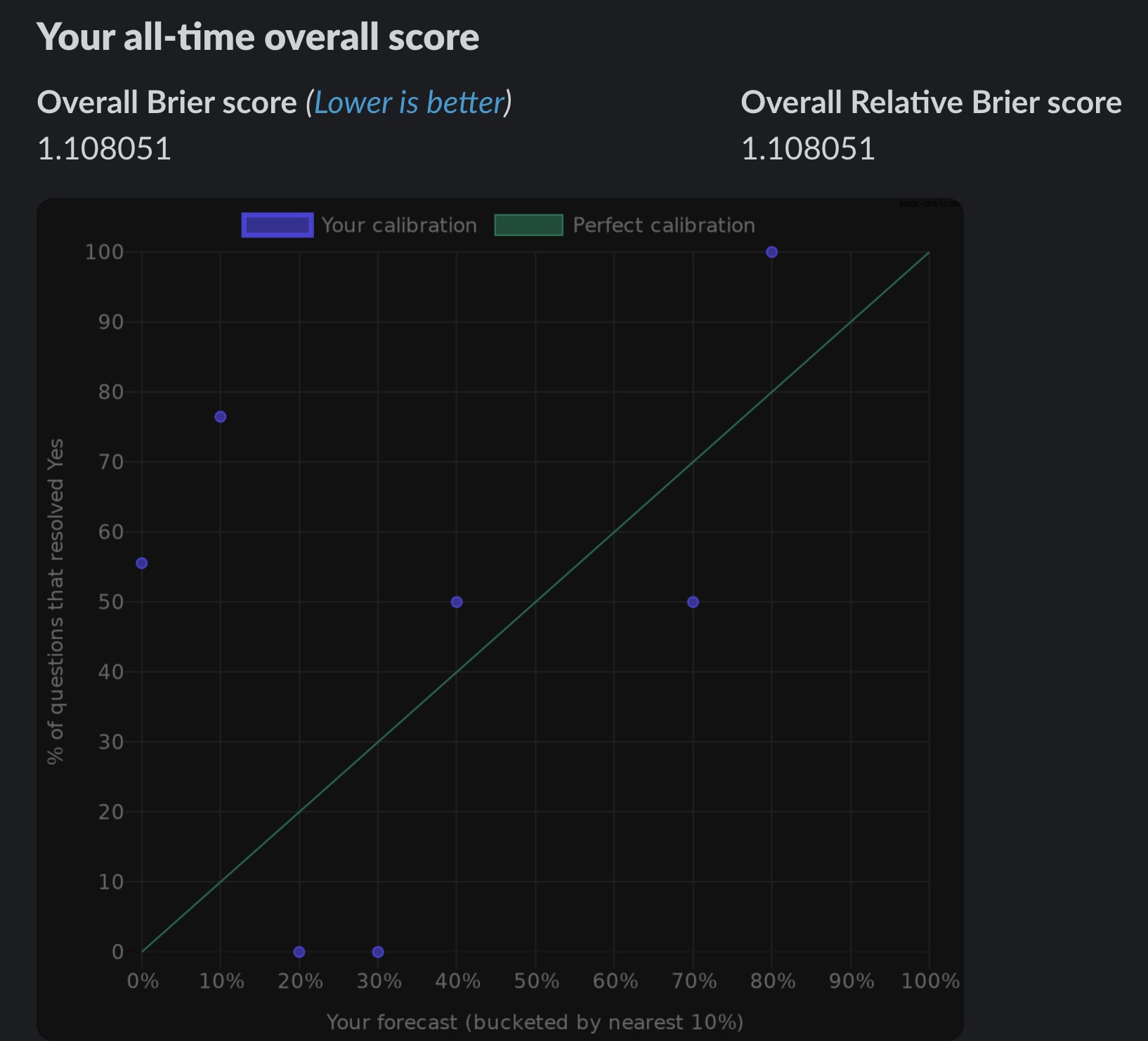
Brier scores for users
You can see your own absolute and relative Brier score in the app home (click Fatebook in the sidebar). If you're thinking of a team-wide leaderboard - that's on our list! Though some users said they wouldn't like this to avoid Goodharting, so I've not prioritised it so far, and will include a te...
I think you could implement a spaced repetition feature based on how many orders of magnitude you’re off, where the more OOMs you're off, the earlier it prompts you with the same question again
This is a great idea, so we made Anki with Uncertainty to do exactly this!
Thank you Hauke for the suggestion :D
I think we'll keep the calibration app as a pure calibration training game, where you see each question only once. Anki is already the king of spaced repetition, so adding calibration features to it seemed like a natural fit.
Super interesting to see this analysis, especially the table of current capabilities - thank you!
I have interpreted [feasible] as, one year after the forecasted date, have AI labs achieved these milestones, and disclosed this publicly?
It seems to me that this ends up being more conservative than the original "Ignore the question of whether they would choose to" , which presumably makes the expert forecasts worse than they seem to be here.
For example, a task like "win angry birds" seems pretty achievable to me, just that no one...
Thanks very much for the feedback, this is really helpful!
If anyone has question suggestions, I'd really appreciate them! I think crowdsourcing questions will help us make them super varied and globally relevant. I made a suggestion form here https://forms.gle/792QQAfqTrutAH9e6
Thanks for organising! I had a great time, I'd love to see more of these events. Maybe you could circulate a Google Doc beforehand to help people brainstorm ideas, comment on each other's ideas, and indicate interest in working on ideas. You could prepopulate it with ideas you've generated as the organisers. That way when people show up they can get started faster - I think we spent the first hour or so choosing our idea.
(Btw - our BOTEC calculator's first page is at this URL.)
Interesting to think about!
But for this kind of bargain to work, wouldn't you need confidence that the you in other worlds would uphold their end of the bargain?
E.g., if it looks like I'm in videogame-world, it's probably pretty easy to spend lots of time playing videogames. But can I be confident that my counterpart in altruism-world will actually allocate enough of their time towards altruism?
(Note I don't know anything about Nash bargains and only read the non-maths parts of this post, so let me know if this is a basic misunderstanding!)
A data-point on this - today I was looking for and couldn't find this graph. I found effectivealtruismdata.com but sadly it didn't have these graphs on it. So would be cool to have it on there, or at least link to this post from there!
Thanks Jack, great to see this!
Pulling out the relevant part as a quote for other readers:
- On average, it took about 25 hours to organize and run a campaign (20 hours by organizers and 5 hours by HIP).
- The events generated an average of 786 USD per hour of counterfactual donations to effective charities.
- This makes fundraising campaigns a very cost effective means of counterfactual impact; as a comparison, direct work that generates 1,000,000 USD of impact equivalent per year equates to around 500 USD per hour.
Great results so far!
High Impact Professionals supported 8 EAs to run fundraising drives at their workplace in 2021, raising $240k in counterfactual dollars. On an hourly basis, organizing those events proved to be as impactful as direct work
Could you share the numbers you used to calculate this? I.e. how many hours to organise an event, counterfactual dollars per hour organising/running events, and your estimate for the value per hour of direct work?
it'd be really valuable for more EA-aligned people to goddamn write summaries at all
To get more people to write summaries for long forum posts, we could try adding it to the forum new post submission form? e.g. if the post text is over x words, a small message shows up advising you to add a summary.
Or maybe you're thinking more of other formats, like Google docs?
Great to see this writeup, thank you!
In the runup to EAG SF I've been thinking a bit about travel funding allocation. I thought I could take this opportunity to share two problems and tentative solutions, as I imagine they hold across different conferences (including EAGx Boston).
Thing 1: Uncertainty around how much to apply for
In conversations with other people attending I've found that people are often quite uncertain and nervous when working out how much to apply for.
One way to improve this could be to encourage applicants to follow a simple proce...
Thanks Ankush! For this first round, we keep things intentionally short, but if your project progresses to later rounds then there will be plenty of opportunities to share more details.
it is a pdf that I would love to get valued and be shared with the world and anyone who wants to hear about longtermism project
Posting your ideas here on the EA Forum could be a great way to get feedback from other people interested in longtermism!
Maybe something helpful to think about is, what's your goal?
E.g. maybe:
- You want to stay on top of new papers in AI capabilities
- You want to feel connected to the AI safety research community
- You want to build a network of people in AI research / AI safety research, so that in future you could ask people for advice about a career decision
- You want to feel more motivated for your own self study in machine learning
- You want to workshop your own ideas around AI, and get rapid feedback from researchers and thinkers
I think for some goals, Twitter is unusually helpfu...
This would be convenient! I wonder if you could have a fairly-decent first pass via a Chrome extension that hides all non-vegan items from the UI (or just greys them out).
You could probably use LLMs to do a decent first-pass on whether items are vegan. It'll be obvious for many (e.g. vegetables, meat), and for non-obvious ones you could kick off a research agent who finds an up to date ingredient list or discussion thread. Then add the ability for users to correct classification mistakes and you'd probably be able to classify most foods quite accurately.
Then promote the Chrome extension via vegan magazines, influencers, veganuary, etc.