All of Marcel2's Comments + Replies
I almost clarified that I know some models technically are multi-modal, but my impression is that the visual reasoning abilities of the current models are very limited, so I’m not at all surprised they’re limited. Among other illustrations of this impression, occasionally I’ve found they struggle to properly describe what is happening in an image beyond a relatively general level.
Again, I'd be interested to actually see humans attempt the test by viewing the raw JSON, without being allowed to see/generate any kind of visualization of the JSON. I suspect that most people will solve it by visualizing and manipulating it in their head, as one typically does with these kinds of problems. Perhaps you (a person with syntax in their username) would find this challenge quite easy! Personally, I don't think I could reliably do it without substantial practice, especially if I'm prohibited from visualizing it.
Just because an LLM can convert something to a grid representation/visualization does not mean it can itself actually "visualize" the thing. A pure-text model will lack the ability to observe anything visually. Just because a blind human can write out some mathematical function that they can input into a graphing calculator, that does not mean that the human necessarily can visualize what the function's shape will take, even if the resulting graph is shown to everyone else.
I wouldn't be surprised if that's correct (though I haven't seen the tests), but that wasn't my complaint. A moderately smart/trained human can also probably convert from JSON to a description of the grid, but there's a substantial difference in experience from seeing even a list of grid square-color labels vs. actually visualizing it and identifying the patterns. I would strike a guess that humans who are only given a list of square color labels (not just the raw JSON) would perform significantly worse if they are not allowed to then draw out the grids.
And I would guess that even if some people do it well, they are doing it well because they convert from text to visualization.
Can anyone point me to a good analysis of the ARC test's legitimacy/value? I was a bit surprised when I listened to the podcast, as they made it seem like a high-quality, general-purpose test, but then I was very disappointed to see it's just a glorified visual pattern abstraction test. Maybe I missed some discussion of it in the podcasts I listened to, but it just doesn't seem like people pushed back hard enough on the legitimacy of comparing "language model that is trying to identify abstract geometric patterns through a JSON file" vs. "humans that are just visually observing/predicting the patterns."
Like, is it wrong to demand that humans should have to do this test purely by interpreting the JSON (with no visual aide)?
I spent way too much time organizing my thoughts on AI loss-of-control ("x-risk") debates without any feedback today, so I'm publishing perhaps one of my favorite snippets/threads:
A lot of debates seem to boil down to under-acknowledged and poorly-framed disagreements about questions like “who bears the burden of proof.” For example, some skeptics say “extraordinary claims require extraordinary evidence” when dismissing claims that the risk is merely “above 1%”, whereas safetyists argue that having >99% confidence that things won’t go wrong is the “extr...
Venus is an extreme example of an Earth-like planet with a very different climate. There is nothing in physics or chemistry that says Earth's temperature could not one day exceed 100 C.
[...]
[Regarding ice melting -- ] That will take time, but very little time on a cosmic scale, maybe a couple of thousand years.
I'll be blunt, remarks like these undermine your credibility. But regardless, I just don't have any experience or contributions to make on climate change, other than re-emphasizing my general impression that, as a person who cares a lot about e...
Everything is going more or less as the scientists predicted, if anything, it's worse.
I'm not that focused on climate science, but my understanding is that this is a bit misleading in your context—that there were some scientists in the (90s/2000s?) who forecasted doom or at least major disaster within a few decades due to feedback loops or other dynamics which never materialized. More broadly, my understanding is that forecasting climate has proven very difficult, even if some broad conclusions (e.g., "the climate is changing," "humans contribute to climat...
I don't find this response to be a compelling defense of what you actually wrote:
since AIs would "get old" too [...] they could also have reason to not expropriate the wealth of vulnerable old agents because they too will be in such a vulnerable position one day
It's one thing if the argument is "there will be effective enforcement mechanisms which prevent theft," but the original statement still just seems to imagine that norms will be a non-trivial reason to avoid theft, which seems quite unlikely for a moderately rational agent.
Ultimately, perhaps much o...
Apologies for being blunt, but the scenario you lay out is full of claims that just seem to completely ignore very facially obvious rebuttals. This would be less bad if you didn’t seem so confident, but as written the perspective strikes me as naive and I would really like an explanation/defense.
Take for example:
...Furthermore, since AIs would "get old" too, in the sense of becoming obsolete in the face of new generations of improved AIs, they could also have reason to not expropriate the wealth of vulnerable old agents because they too will be in such a vu
Sure! (I just realized the point about the MNIST dataset problems wasn't fully explained in my shared memo, but I've fixed that now)
Per the assessment section, some of the problems with assuming that FRVT demonstrates NIST's capabilities for evaluation of LLMs/etc. include:
- Facial recognition is a relatively "objective" test—i.e., the answers can be linked to some form of "definitive" answer or correctness metric (e.g., name/identity labels). In contrast, many of the potential metrics of interest with language models (e.g., persuasiveness, knowledge about d
Seeing the drama with the NIST AI Safety Institute and Paul Christiano's appointment and this article about the difficulty of rigorously/objectively measuring characteristics of generative AI, I figured I'd post my class memo from last October/November.
The main point I make is that NIST may not be well suited to creating measurements for complex, multi-dimensional characteristics of language models—and that some people may be overestimating the capabilities of NIST because they don't recognize how incomparable the Facial Recognition Vendor Test is to this ...
I probably should have been more clear, my true "final" paper actually didn't focus on this aspect of the model: the offense-defense balance was the original motivation/purpose of my cyber model, but I eventually became far more interested in using the model to test how large language models could improve agent-based modeling by controlling actors in the simulation. I have a final model writeup which explains some of the modeling choices in more detail and talks about the original offense/defense purpose in more detail.
(I could also provide the model code ...
If offence and defence both get faster, but all the relative speeds stay the same, I don’t see how that in itself favours offence
Funny you should say this, it so happens that I just submitted a final paper last night for an agent-based model which was meant to test exactly this kind of claim for the impacts of improving “technology” (AI) in cybersecurity. Granted, the model was extremely simple + incomplete, but the theoretical results explain how this could possible.
In short, when assuming a fixed number of vulnerabilities in an attack surface, while atta...
Thank you so much for articulating a bunch of the points I was going to make!
I would probably just further drive home the last paragraph: it’s really obvious that the “number of people a lone maniac can kill in given time” (in America) has skyrocketed with the development of high fire-rate weapons (let alone knowledge of explosives). It could be true that the O/D balance for states doesn’t change (I disagree) while the O/D balance for individuals skyrockets.
I have increasingly become open to incorporating alternative decision theories as I recognize that I cannot be entirely certain in expected value approaches, which means that (per expected value!) I probably should not solely rely on one approach. At the same time, I am still not convinced that there is a clear, good alternative, and I also repeatedly find that the arguments against using EV are not compelling (e.g., due to ignoring more sophisticated ways of applying EV).
Having grappled with the problem of EV-fanaticism for a long time in part due to the ...
Since I think substantial AI regulation will likely occur by default, I urge effective altruists to focus more on ensuring that the regulation is thoughtful and well-targeted rather than ensuring that regulation happens at all.
I think it would be fairly valuable to see a list of case studies or otherwise create base rates for arguments like “We’re seeing lots of political gesturing and talking, so this suggests real action will happen soon.” I am still worried that the action will get delayed, watered down, and/or diverted to less-existential risks, onl...
Strange, unless the original comment from Gerald has been edited since I responded I think I must have misread most of the comment, as I thought it was making a different point (i.e., "could someone explain how misalignment could happen"). I was tired and distracted when I read it, so it wouldn't be surprising. However, the final paragraph in the comment (which I originally thought was reflected in the rest of the comment) still seems out of place and arrogant.
This really isn’t the right post for most of those issues/questions, and most of what you mentioned are things you should be able to find via searches on the forum, searches via Google, or maybe even just asking ChatGPT to explain it to you (maybe!). TBH your comment also just comes across quite abrasive and arrogant (especially the last paragraph), without actually appearing to be that insightful/thoughtful. But I’m not going to get into an argument on these issues.
I wish! I’ve been recommending this for a while but nobody bites, and usually (always?) without explanation. I often don’t take seriously many of these attempts at “debate series” if they’re not going to address some of the basic failure modes that competitive debate addresses, e.g., recording notes in a legible/explorable way to avoid the problem of arguments getting lost under layers of argument branches.
In policy spaces, this is known as the Brussels Effect; that is, when a regulation adopted in one jurisdiction ends up setting a standard followed by many others.
I am not clear how the Brussels effect applies here, especially since we’re not talking manufacturing a product with high costs of running different production lines. I recognize there may be some argument/step that I’m missing, but I can’t dismiss the possibility that the author doesn’t actually understand what the Brussels Effect really is / normally does, and is throwing it around like a buzzword. Could you please elaborate a bit more?
I was not a huge fan of the instrumental convergence paper, although I didn't have time to thoroughly review it. In short, it felt too slow in making its reasoning and conclusion clear, and once (I think?) I understood what it was saying, it felt quite nitpicky (or a borderline motte-and-bailey). In reality, I'm still unclear if/how it responds to the real-world applications of the reasoning (e.g., explaining why a system with a seemingly simple goal like calculating digits of pi would want to cause the extinction of humanity).
The summary in this forum pos...
Sorry about the delayed reply, I saw this and accidentally removed the notification (and I guess didn't receive an email notification, contrary to my expectations) but forgot to reply. Responding to some of your points/questions:
One can note that AIXR is definitely falsifiable, the hard part is falsifying it and staying alive.
I mostly agree with the sentiment that "if someone predicts AIXR and is right then they may not be alive", although I do now think it's entirely plausible that we could survive long enough during a hypothetical AI takeover to say "ah ...
Interesting. Perhaps we have quite different interpretations of what AGI would be able to do with some set of compute/cost and time limitations. I haven't had the chance yet to read the relevant aspects of your paper (I will try to do so over the weekend), but I suspect that we have very cruxy disagreements about the ability of a high-cost AGI—and perhaps even pre-general AI that can still aid R&D—to help overcome barriers in robotics, semiconductor design, and possibly even aspects of AI algorithm design.
Just to clarify, does your S-curve almost entir...
I find this strange/curious. Is your preference more a matter of “Traditional interfaces have good features that a flowing interface would lack“ (or some other disadvantage to switching) or “The benefits of switching to a flowing interface would be relatively minor”?
For example on the latter, do you not find it more difficult with the traditional UI to identify dropped arguments? Or suppose you are fairly knowledgeable about most of the topics but there’s just one specific branch of arguments you want to follow: do you find it easy to do that? (And more on...
Thanks for posting this, Ted, it’s definitely made me think more about the potential barriers and the proper way to combine probability estimates.
One thing I was hoping you could clarify: In some of your comments and estimates, it seems like you are suggesting that it’s decently plausible(?)[1] we will “have AGI“ by 2043, it’s just that it won’t lead to transformative AGI before 2043 because the progress in robotics, semiconductors, and energy scaling will be too slow by 2043. However, it seems to me that once we have (expensive/physically-limited) AG...
Are your referring to this format on LessWrong? If so I can’t say I’m particularly impressed, as it still seems to suffer from the problems of linear dialogue vs. a branching structure (e.g., it is hard to see where points have been dropped, it is harder to trace specific lines of argument). But I don’t recall seeing this, so thanks for the flag.
As for “I don’t think we could have predicted people…”, that’s missing my point(s). I’m partially saying “this comment thread seems like it should be a lesson/example of how text-blob comment-threads are inefficien...
Am I really the only person who thinks it's a bit crazy that we use this blobby comment thread as if it's the best way we have to organize disagreement/argumentation for audiences? I feel like we could almost certainly improve by using, e.g., a horizontal flow as is relatively standard in debate.[1]
With a generic example below:
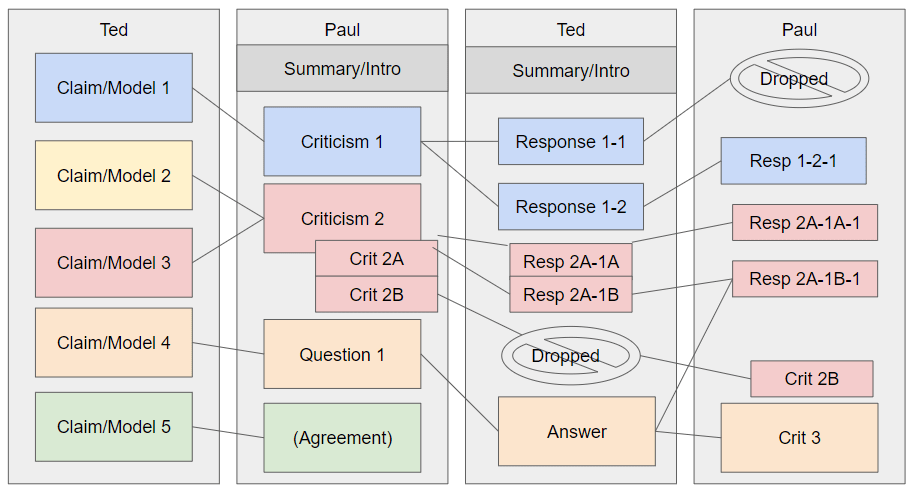
To be clear, the commentary could still incorporate non-block/prose text.
Alternatively, people could use something like Kialo.com. But surely there has to be something better than this comment thread, in terms of 1) ease of determini...
Epistemic status: writing fast and loose, but based on thoughts I've mulled over for a while given personal experience/struggles and discussions with other people. Thus, easy to misinterpret what I'm saying. Take with salt.
On the topic of educational choice, I can't emphasize enough the importance of having legible hard skills such as language or, perhaps more importantly, quantitative skills. Perhaps the worst mistake I made in college was choosing to double major in both international studies and public policy, rather than adding a second major in econ o...
Ultimately, I've found that the line between empirical and theoretical analysis is often very blurry, and if someone does develop a decent brightline to distinguish the two, it turns out that there are often still plenty of valuable theoretical methods, and some of the empirical methods can be very misleading.
For example, high-fidelity simulations are arguably theoretical under most definitions, but they can be far more accurate than empirical tests.
Overall, I tend to be quite supportive of using whatever empirical evidence we can, especially experim...
I see. (For others' reference, those two points are pasted below)
- All knowledge is derived from impressions of the external world. Our ability to reason is limited, particularly about ideas of cause and effect with limited empirical experience.
- History shows that societies develop in an emergent process, evolving like an organism into an unknown and unknowable future. History was shaped less by far-seeing individuals informed by reason than by contexts which were far too complex to realize at the time.
Overall, I don't really know what to make of these. They ...
I haven't looked very hard but the short answer is no, I'm not aware of any posts/articles that specifically address the idea of "methodological overhang" (a phrase I hastily made up and in hindsight realize may not be totally logical) as it relates to AI capabilities.
That being said, I have written about the possibility that our current methods of argumentation and communication could be really suboptimal, here: https://georgetownsecuritystudiesreview.org/2022/11/30/complexity-demands-adaptation-two-proposals-for-facilitating-better-debate-in-internationa...
Is your claim just that people should generally "increase [their] error bars and widen [their] probability distribution"? (I was frustrated by the difficulty of figuring out what this post is actually claiming; it seems like it would benefit from a "I make the following X major claims..." TLDR.)
I probably disagree with your points about empiricism vs. rationalism (on priors that I dislike the way most people approach the two concepts), but I think I agree that most people should substantially widen their "error bars" and be receptive to new information. An...
I think there is plenty of room for debate about what the curve of AI progress/capabilities will look like, and I mostly skimmed the article in about ~5 minutes, but I don't think your post's content justified the title ("exponential AI takeoff is a myth"). "Exponential AI takeoff is currently unsupported" or "the common narrative(s) for exponential AI takeoff is based on flawed premises" are plausible conclusions from this post (even if I don't necessarily agree with them), but I think the original title would require far more compelling arguments to be j...
TL;DR: Someone should probably write a grant to produce a spreadsheet/dataset of past instances where people claimed a new technology would lead to societal catastrophe, with variables such as “multiple people working on the tech believed it was dangerous.”
Slightly longer TL;DR: Some AI risk skeptics are mocking people who believe AI could threaten humanity’s existence, saying that many people in the past predicted doom from some new tech. There is seemingly no dataset which lists and evaluates such past instances of “tech doomers.” It seems somewhat ridic...
TBH, I think that the time spent scoring rationales is probably quite manageable: I don’t think it should take longer than 30 person-minutes to decently judge each rationale (e.g., have three judges each spend 10 minutes evaluating each), maybe less? It might be difficult to have results within 1-2 hours if you don’t have that many judges, but probably it should be available by the end of the day.
To be clear, I was thinking that only a small number (no more than three, maybe just two) of the total questions should be “rationale questions.”
But definitely th...
This situation was somewhat predictable and avoidable, in my view. I’ve lamented the early-career problem in the past but did not get many ideas for how to solve it. My impression has been that many mid-career people in relevant organizations put really high premiums on “mentorship,” to the point that they are dismissive of proposals that don’t provide such mentorship.
There are merits to emphasizing mentorship, but the fact has been that there are major bottlenecks on mentorship capacity and this does little good for people who are struggling to get ...
Although this article might interest me, it is also >30 minutes long and it does not appear to have any kind of TL;DR, and the conclusion is too vague for me to sample test the article‘s insights. It is really important to provide such a summary. For example, for an article of this type and length, I’d really like to know things like:
- What would summarize as the main deficiency in current methods? Or “Many people/readers probably believe X, or just haven’t considered Y.”
- What does this article argue instead? “I argue Y.”
- Why does this all matter? “Y is significantly better than X.”
I was also going to recommend this, but I’ll just add an implementation idea (which IDK if I fully endorse): you could try to recruit a few superforecasters or subject-matter experts (SMEs) in given field to provide forecasts on the questions at the same time, then have a reciprocal scoring element (I.e., who came closest to the superforecasters’/SMEs’ forecasts). This is basically what was done in the 2022 Existential Risk Persuasion/Forecasting Tournament (XPT), which Philip Tetlock ran (and I participated in). IDK when the study results for that tournam...
I think the ask-a-question feature on EAF/LW partially fills the need.
I considered this largely insufficient for what I have in mind; I want a centralized hub that I can check (and/or that I expect other people will check), whereas the ask-a-question feature is too decentralized.
I expect most professional researchers don't have a need for this, since they have a sufficiently strong network that they can ask someone who will know the answer or know who to ask.
Perhaps! I wouldn't know, I'm mostly just a wannabe amateur who doesn't have such a luxury. T...
One particularly confusing fact is that OAI's valuation appears to have gone from $14 billion in 2021 to $19 billion in 2023. Even ignoring anything about transformative AI, I would have expected that the success of ChatGPT etc. should have resulted in a more than a 35% increase.
I've frequently seen people fail to consider the fact that potential competitors (including borderline copycats) can significantly undermine the profitability of one company's technology, even if the technology could generate substantial revenue. Are you taking this into account?
Has anyone thought about trying to convince anti-regulatory figures (e.g., Marc Andreessen) in the new admin's orbit to speak out against the regulatory capture of banning cultivated meat? Has anyone tried painting cultivated meat as "Little Tech"?