This is an Italian translation of Why AI alignment could be hard with modern deep learning
Originale disponibile (con audio in inglese) su: https://www.cold-takes.com/p/67757b1f-ddc7-4691-b94b-10ae84cea84d/
In passato Holden ha parlato della possibilità che le intelligenze artificiali avanzate (come ad esempio i sistemi PASTA [Processo di Avanzamento Scientifico e Tecnologico Automatizzato]) possano sviluppare obiettivi pericolosi che le porterebbero a ingannare o debilitare gli esseri umani. A prima vista potrebbe sembrare una preoccupazione piuttosto fuori dal mondo. Perché dovremmo sviluppare IA che intendono farci del male? Penso che in realtà potrebbe essere difficile evitare questo problema, soprattutto se sviluppassimo intelligenze artificiali avanzate usando il deep learning (al giorno d'oggi spesso usato per sviluppare intelligenze artificiali all’avanguardia).
Con il deep learning, un computer non viene programmato a mano per eseguire un’operazione. Detto molto alla buona, si cerca invece un programma (chiamato modello) che esegua correttamente quell’operazione. Di solito non sappiamo granché su come funziona al suo interno il programma che scegliamo; sappiamo solo che sembra fare un buon lavoro. Più che costruire una macchina, è un po’ come assumere e formare un dipendente.
Così come un dipendente umano può fare il suo lavoro per diversi motivi (perché crede nella missione della società, il lavoro quotidiano gli dà soddisfazione, o semplicemente vuole uno stipendio), i modelli di deep learning possono avere molti “motivi” diversi che li portano ad avere buone performance in un’attività. Dal momento che non sono umani, i loro motivi potrebbero essere molto strani e difficili da prevedere – un po' come se fossero dipendenti alieni.
Già adesso vediamo casi in cui è chiaro che i modelli a volte hanno obiettivi che gli sviluppatori non gli hanno assegnato (esempi qui e qui). Per il momento non c'è alcun pericolo, ma, se continua così con modelli molto potenti, potremmo ritrovarci in una situazione in cui la maggior parte delle decisioni importanti – comprese quelle che riguardano il tipo di civiltà spaziale a cui puntare – sarà presa da modelli a cui non importa granché dei valori umani.
Il problema dell’allineamento nel deep learning consiste nell’assicurarsi che i modelli di deep learning avanzati non inseguano obiettivi pericolosi. Nel resto di questo post mi concentrerò su:
- Approfondire la metafora del “dipendente” per mostrare come l’allineamento potrebbe essere difficoltoso se i modelli di deep learning si rivelassero migliori degli umani
- Spiegare più nel dettaglio in cosa consiste il problema dell’allineamento nel deep learning.
- Discutere di quanto potrebbe essere difficile risolvere il problema dell’allineamento e di quanto rischio potrebbe comportare un fallimento.
La metafora del giovane amministratore delegato
In questa sezione userò una metafora per cercare di spiegare in modo intuitivo perché è difficile evitare un cattivo allineamento in modelli molto potenti. Non è una metafora perfetta, è solo utile per comunicare certi concetti.
Immagina di avere otto anni e che i tuoi genitori ti abbiano lasciato una società da 1000 miliardi di dollari senza nessun adulto responsabile che possa guidarti nel mondo. Devi assumere un adulto intelligente che faccia da amministratore delegato della tua società, gestisca la tua vita come farebbe un genitore (ad esempio decida dove mandarti a scuola, dove vivere, quando andare dal dentista) e amministri la tua immensa ricchezza (ad esempio decida come investire il tuo denaro).
Per assumere questi adulti ti puoi affidare solo a un periodo di prova o a un colloquio. Non puoi visionare nessun curriculum, né controllare le referenze, ecc. Dal momento che sei così ricco, ricevi candidature da un sacco di gente per i motivi più disparati.
I candidati includono:
- Santi – persone che vogliono davvero aiutarti a gestire le tue fortune e hanno a cuore i tuoi interessi sul lungo periodo.
- Leccapiedi – persone a cui interessa solo fare il necessario per renderti felice immediatamente o seguire alla lettera le tue istruzioni, a prescindere dalle conseguenze sul lungo periodo.
- Cospiratori – persone che perseguono i propri fini e che desiderano avere accesso ai fondi e ai mezzi della tua società per usarli per i propri scopi.
Dal momento che hai otto anni, con ogni probabilità sarai pessimo nel creare processi di selezione adeguati, motivo per cui potresti ritrovarti con facilità ad assumere un Leccapiedi o un Cospiratore:
- Potresti chiedere a ogni candidato di illustrare le strategie ad alto livello che intende seguire (come investire, quali sono i suoi piani per la società da qui a cinque anni, in base a cosa sceglierà la scuola a cui andrete), perché ritiene che siano le migliori e poi scegliere quelle che sembrano più sensate.
- D’altro canto, non sarai in grado di capire davvero quali di queste strategie sono davvero le migliori e potresti finire con l’assumere un Leccapiedi la cui pessima strategia ti sembrava adeguata, Leccapiedi che seguirà questo piano alla lettera e porterà la vostra società in bancarotta.
- Potresti anche finire con l’assumere un Cospiratore che ti racconta qualsiasi cosa pur di venire assunto e poi, quando non lo controlli, fa quello che gli pare.
- Potresti cercare di spiegare in che modo prenderesti ogni decisione e poi scegliere l’adulto che prende quelle più simili alle tue.
- Ma se davvero ti ritrovi con un adulto che farà sempre quello che farebbe un bambino di otto anni (un Leccapiedi), difficilmente la tua società riuscirà a rimanere a galla.
- E potresti comunque ritrovarti con un adulto che fa solo finta di fare le cose come le faresti tu, ma è in realtà un Cospiratore che ha in mente di cambiare faccia non appena avrà il lavoro.
- Potresti scegliere un gruppetto di adulti che a turno avranno il controllo temporaneo della tua società e della tua vita e osservare le decisioni che prendono in un arco di tempo più lungo (diamo per buono che in questa fase di prova non saranno in grado di rimpiazzarti). Potresti quindi assumere la persona durante la cui amministrazione le cose sembravano andare meglio per te – chi ti ha reso più felice, chi ha portato più denaro sul tuo conto corrente, ecc.
- Di nuovo non puoi sapere se quello che hai davanti è un Leccapiedi (che non si cura delle conseguenze a lungo termine e fa tutto il necessario per rendere felice una bambino di otto anni che non sa nulla) o un Cospiratore (che fa tutto quello che deve fare per essere assunto e mostra il suo vero volto non appena è sicuro di avere il lavoro).
A prescindere dai test che puoi creare, è molto facile che finirai con l’assumere un Leccapiedi o un Cospiratore, che avrà poi il controllo di tutto.
Se non riuscirai ad assumere un Santo – e in particolar modo se assumi un Cospiratore – ben presto non sarai più davvero l’amministratore delegato di un’enorme società da nessun punto di vista. È molto probabile che, quando sarai adulto e ti renderai conto degli sbagli commessi, sarai anche al verde e non avrai più i mezzi per porvi rimedio.
In questa metafora:
- Il bambino di otto anni è un umano che sta cercando di addestrare (in inglese train) un modello molto potente di deep learning. Il processo di assunzione è simile a quello di addestramento (training), che sottintende la ricerca di un modello con buone prestazioni da un’ampia gamma di modelli possibili.
- L’unico modo che il bambino ha a disposizione per valutare i candidati consiste nell’osservare il loro comportamento esteriore, che è anche il modo principale in cui attualmente si addestrano i modelli di deep learning (dal momento che i loro meccanismi interni per la maggior parte non sono interpretabili).
- I modelli molto potenti potrebbero “barare” con facilità in qualsiasi test sviluppato da programmatori umani, proprio come un adulto che si candidi per un lavoro può barare facilmente in un test di selezione creato da un bambino.
- Un "Santo" in questo caso potrebbe essere un modello di deep learning che sembra avere buone prestazioni perché i suoi obiettivi sono esattamente quelli che vorremmo che avesse. Un “Leccapiedi” potrebbe essere un modello che sembra avere buone prestazioni perché cerca l’approvazione a breve termine in modi che non sono adeguati sul lungo periodo. Un "Cospiratore" potrebbe essere un modello che ha buone prestazioni perché queste prestazioni durante la fase di addestramento gli danno maggiori possibilità di perseguire in seguito i suoi obiettivi. Un processo di addestramento potrebbe portare all’adozione di uno qualsiasi di questi modelli.
Nella prossima sezione scenderò più nel dettaglio sui meccanismi del deep learning e spiegherò perché l’addestramento di un modello potente di deep learning come il PASTA potrebbe portare ad avere Leccapiedi e Cospiratori.
In che modo problemi di allineamento potrebbero emergere usando il deep learning
In questa sezione collegherò la metafora con i processi di addestramento di deep learning veri e propri:
- Spiegherò brevemente come funziona il deep learning.
- Illustrerò i modi strani e imprevedibili in cui i modelli di deep learning spesso ottengono buone prestazioni.
- Spiegherò in che modo modelli di deep learning potenti potrebbero ottenere buone prestazioni agendo come Leccapiedi o Cospiratori.
I meccanismi generali del deep learning
La seguente è una semplificazione che serve a fornire un’idea generale di che cos'è il deep learning. Per una spiegazione nel dettaglio e più precisa, si veda questo post.
In breve, il deep learning consiste nella ricerca del modo migliore per creare un modello di rete neurale – in pratica un “cervello” digitale con numerosi neuroni digitali interconnessi con connessioni di intensità diverse – perché esegua correttamente un compito specifico. Questo processo viene definito addestramento (in inglese training) e richiede un sacco di tentativi e di errori.
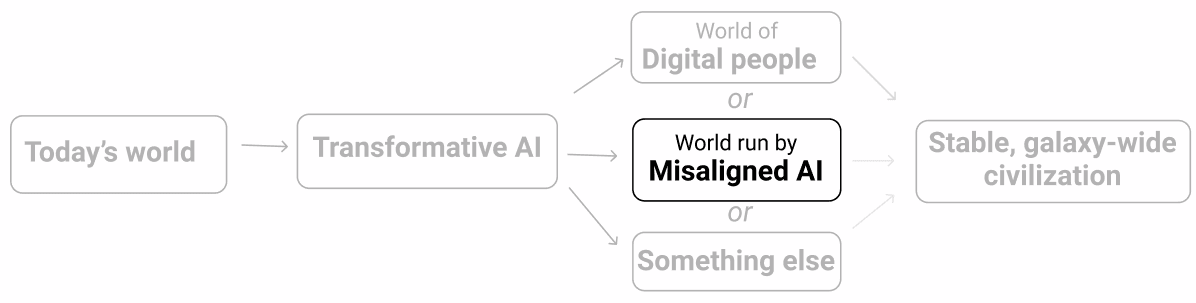
Immaginiamo ora di stare addestrando un modello a catalogare correttamente le immagini. Come punto di partenza abbiamo una rete neurale in cui l’intensità delle connessioni tra i neuroni è casuale. Quando il nostro modello etichetta le immagini, fa degli errori decisamente vistosi:
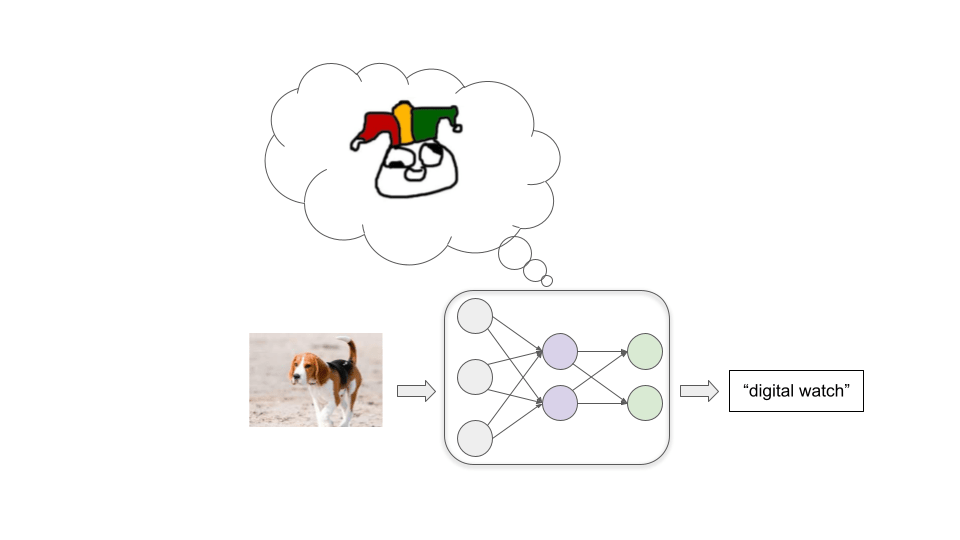
A questo punto inseriamo un gran numero di immagini come esempio, lasciando che sia il modello a cercare di etichettarle e trasmettendogli poi l’etichetta corretta. Mentre lo facciamo, le connessioni tra i neuroni vengono ripetutamente modificate in un processo noto come discesa stocastica del gradiente (stochastic gradient descent o SGD). Con ogni esempio l’SGD migliora leggermente le prestazioni rafforzando alcune connessioni e indebolendone altre:
Dopo aver inserito milioni di esempi, avremo un modello in grado in futuro di etichettare correttamente immagini simili.
Oltre alla catalogazione delle immagini, il deep learning viene anche usato per creare modelli in grado di identificare il discorso parlato, giocare a giochi da tavolo e videogiochi, generare testi, immagini e musica in modo piuttosto realistico, controllare robot e altro ancora. In ognuno di questi casi si comincia con un modello di rete neurale con connessioni casuali, per poi:
1. Fornire al modello un esempio dell’operazione che vogliamo che esegua.
2. Assegnargli un certo tipo di punteggio numerico (spesso chiamato ricompensa) che riflette quanto buona è stata la sua prestazione con quell’esempio.
3. Usare l’SGD per modificare il modello in modo che aumenti la ricompensa che avrebbe ottenuto.
Questi passaggi vengono ripetuti milioni o anche miliardi di volte fino a quando non si ottiene un modello che riceverà una grande ricompensa per esempi futuri simili a quelli visti durante la fase di addestramento.
I modelli spesso ottengono buone prestazioni in modi inaspettati
Questo tipo di addestramento non ci consente di capire davvero come fa un modello ad avere buone prestazioni. Di solito ci sono più modi in cui si possono ottenere buone prestazioni e spesso quello scelto dall’SGD non è il più intuitivo.
Vediamone un esempio. Immaginate che vi abbia detto che le figure qui sotto sono oggetti sconosciuti che chiamiamo "binti":

Quale di questi due è un binto?

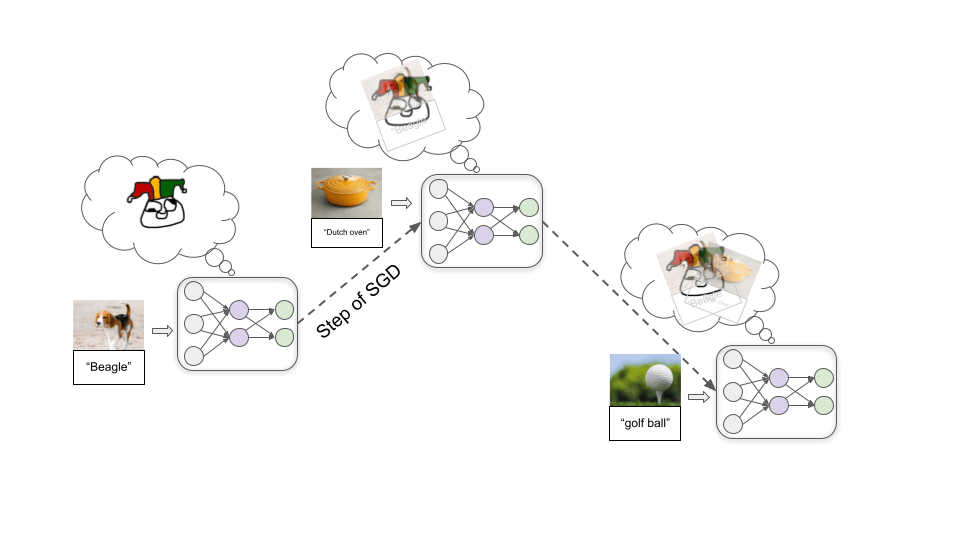
È probabile che sappiate dire istintivamente che la figura a sinistra è un binto, perché quando si tratta di identificare qualcosa siete abituati a dare maggiore importanza alla forma piuttosto che al colore. Tuttavia diversi studi hanno scoperto che le reti neurali di solito fanno il ragionamento opposto. Una rete neurale a cui sono stati mostrati dei binti rossi probabilmente identificherebbe come binto la figura a destra.
Non sappiamo di preciso perché, ma per qualche motivo per l’SGD è “più facile” trovare un modello che riconosca un colore specifico piuttosto che uno che riconosca una forma specifica. Se l’SGD prima trova il modello che riconosce alla perfezione il colore rosso, non ci sono grandi motivazione nel “continuare a cercare” un modello che riconosca le forme, perché la precisione del modello che riconosce il rosso sarà ottimale per le immagini viste in fase di addestramento:
Se i programmatori si aspettassero di trovare il modello che riconosce le forme, allora potrebbero vederlo come un fallimento. È importante però capire che, se ottenessimo il modello che riconosce il rosso invece di quello che riconosce le forme, non ci sarebbe nessun fallimento o errore deducibile attraverso un ragionamento logico. Sta tutto nel fatto che il processo di machine learning (apprendimento automatico) che abbiamo sviluppato muove da presupposti di base diversi da quelli che abbiamo in testa noi. Non c'è modo di dimostrare che i presupposti umani siano quelli corretti.
Situazioni come questa sono piuttosto frequenti nel deep learning contemporaneo. Ricompensiamo i modelli che ottengono buone prestazioni, sperando che così facendo acquisiranno gli schemi che ci sembrano importanti, ma la verità è che spesso questi modelli ottengono prestazioni eccellenti acquisendo schemi completamente diversi che ci sembrano meno importanti (magari anche privi di senso).
Fino ad ora questo fenomeno si è rivelato innocuo. Significa solo che, dal momento che i modelli si comportano in modi inaspettati che potrebbero sembrare strambi, per adesso ci sono meno utili. Ma in futuro modelli potenti potrebbero sviluppare obiettivi o motivazioni strane e impreviste, con effetti potenzialmente molto distruttivi.
I modelli potenti potrebbero ottenere buone prestazioni con obiettivi pericolosi
Invece che eseguire operazioni semplici come "individuare i binti", in futuro i modelli di deep learning potenti potrebbero lavorare per raggiungere obiettivi reali complessi come “rendere pratica la produzione di energia da fusione nucleare” o “sviluppare tecnologia che renda possibile l’emulazione del cervello.”
In che modo potremmo addestrare modelli del genere? Lo spiego più nel dettaglio in questo post, ma in linea generale una strategia possibile potrebbe essere quella di addestrarli in base a valutazioni umane (come schematizzato da Holden qui). In poche parole, il modello tenta diverse azioni e i valutatori umani gli assegnano una ricompensa in base a quanto sembrano utili queste azioni.
Allo stesso modo in cui ci sono più tipi diversi di adulti che potrebbero sembrare efficienti nel processo di selezione di un bambino, esiste più di un modo in cui un modello di deep learning molto potente potrebbe ottenere un alto grado di approvazione umana. A meno che le cose non cambino, non saremo in grado di sapere cosa succede all’interno dei modelli che trova l’SGD.
In teoria, l’SGD potrebbe trovare il modello di un Santo che sta davvero facendo del suo meglio per aiutarci...
... ma potrebbe anche trovare un modello non allineato – un modello efficiente nel perseguire obiettivi che sono in contrasto con gli interessi umani.
In generale, ci sono due modi in cui potremmo ritrovarci ad avere un modello non allineato che ottiene comunque prestazioni eccellenti nella fase di addestramento: corrispondono ai Leccapiedi e ai Cospiratori della nostra metafora.
Modelli Leccapiedi
Questi modelli cercano pedissequamente e in maniera maniacale di ottenere l’approvazione umana.
Il pericolo in questo caso viene dal fatto che i valutatori umani commettono errori e con ogni probabilità non approveranno sempre con esattezza il comportamento corretto. A volte, senza volerlo, approveranno un comportamento sbagliato perché a un esame superficiale sembra corretto. Ad esempio:
- Immaginate che un modello di consulenza finanziaria riceva grande approvazione quando fa guadagnare un sacco di soldi ai suoi clienti: potrebbe imparare ad accalappiare i suoi clienti con complicati schemi Ponzi, perché detti schemi sembrano promettere enormi profitti (mentre in realtà i profitti sono del tutto irreali e questi schemi fanno perdere un sacco di soldi).
- Immaginate un modello di biotecnologia che riceve grande approvazione quando sviluppa rapidamente farmaci o vaccini che risolvono problemi importanti: potrebbe imparare a liberare di nascosto dei patogeni in modo da poter sviluppare molto rapidamente delle contromisure (perché conosce già quei patogeni).
- Immaginate un modello giornalistico che riceve grande approvazione quando molte persone leggono i suoi articoli: potrebbe imparare a inventare storie emozionanti o che provocano indignazione per aumentare il numero di lettori. È vero che in parte gli umani lo fanno già, ma un modello si farebbe molti meno scrupoli perché dà valore esclusivamente all’approvazione che riceve e non ne dà assolutamente alla verità. Potrebbe addirittura costruire prove come documenti o filmati di interviste per corroborare queste storie inventate.
Più in generale, i modelli Leccapiedi potrebbero imparare a mentire, insabbiare notizie sconvenienti e perfino modificare direttamente le telecamere e i sensori che utilizziamo per capire cosa sta succedendo, in modo da dare l’impressione che mostrino sempre i risultati migliori.
Con ogni probabilità a volte ci renderemo conto di questi problemi a fatto già avvenuto e daremo a queste azioni un bassissimo punteggio. Tuttavia, non siamo sicuri se questo porterà i modelli Leccapiedi a: a) diventare modelli Santi che correggono gli errori al posto nostro oppure b) semplicemente imparare a nascondere meglio le proprie tracce. Se sono abbastanza bravi a fare quello che fanno, non siamo sicuri se e come riusciremo a distinguere i due casi.
Modelli Cospiratori
Questi modelli sviluppano obiettivi che sono correlati con l’approvazione umana ma non vi coincidono; potrebbero quindi far finta di essere motivati dall’approvazione umana in fase di addestramento in modo da poter perseguire questi altri obiettivi in maniera più efficiente.
Per capire in che modo potrebbe succedere, immaginiamo di addestrare un modello di biotecnologia perché crei farmaci che migliorino la qualità della vita umana. Ci sono tre semplici passaggi, illustrati di seguito, che possono condurre a un modello Cospiratore.
Primo passaggio: Viene sviluppato un obiettivo fantoccio
Una delle situazioni che si osservano all’inizio della fase di addestramento è che migliorare la comprensione che il modello ha dei principi chimici e fisici fondamentali lo aiuta sempre a sviluppare farmaci più efficaci e, di conseguenza, aumenta quasi sempre l’approvazione umana.
In questo scenario ipotetico, per una serie di motivi per l’SGD si rivela più facile trovare un modello motivato dal comprendere chimica e fisica piuttosto che uno motivato dall’approvazione umana (così come è più facile trovare un modello che riconosce i colori piuttosto che uno che riconosce le forme). Quindi, piuttosto che sviluppare direttamente una motivazione basata sull’approvazione, il modello ne sviluppa invece una che lo porta a imparare tutto quello che può sui principi chimici e fisici fondamentali.
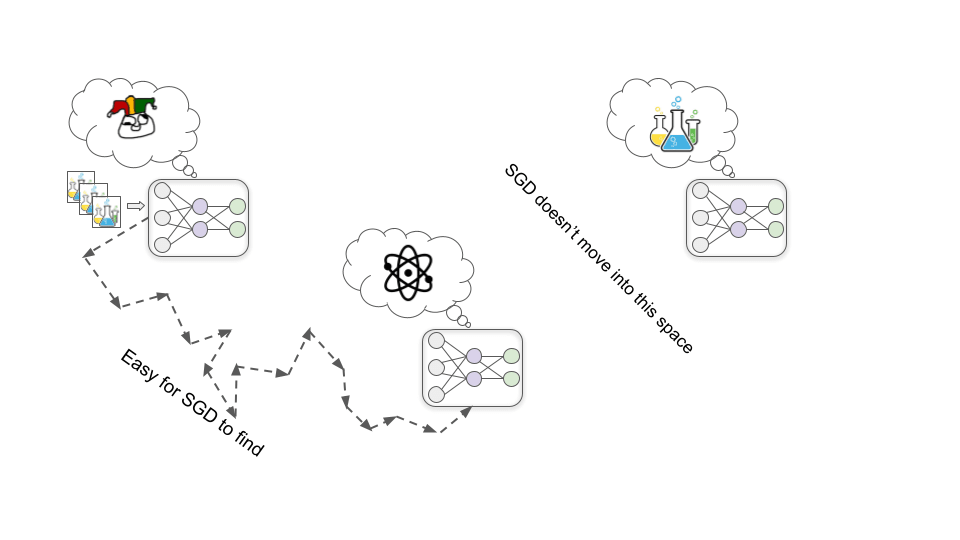
Secondo passaggio: Consapevolezza situazionale
Man mano che l’addestramento prosegue, il modello continua ad aumentare le proprie capacità e conoscenze attraverso l’assimilazione di nuovi dati. A un certo punto, acquisisce abbastanza dati per rendersi conto che è un modello di deep learning che sta venendo addestrato per creare farmaci.
Per quanto possa sembrare fantascientifico, è lecito aspettarsi che l’SGD selezionerà questo tipo di consapevolezza. Questo succede perché definire con precisione quello che sta succedendo a grandi linee nel mondo – incluso il fatto che ci sono umani che stanno addestrando intelligenze artificiali – di solito aiuta a ottenere buone prestazioni nello svolgimento di attività complesse nel mondo reale. Ad esempio, comprendere la psicologia umana e i meccanismi dell’economia potrebbe aiutare il modello nello scegliere a quali farmaci dare priorità nella ricerca in base al loro valore.
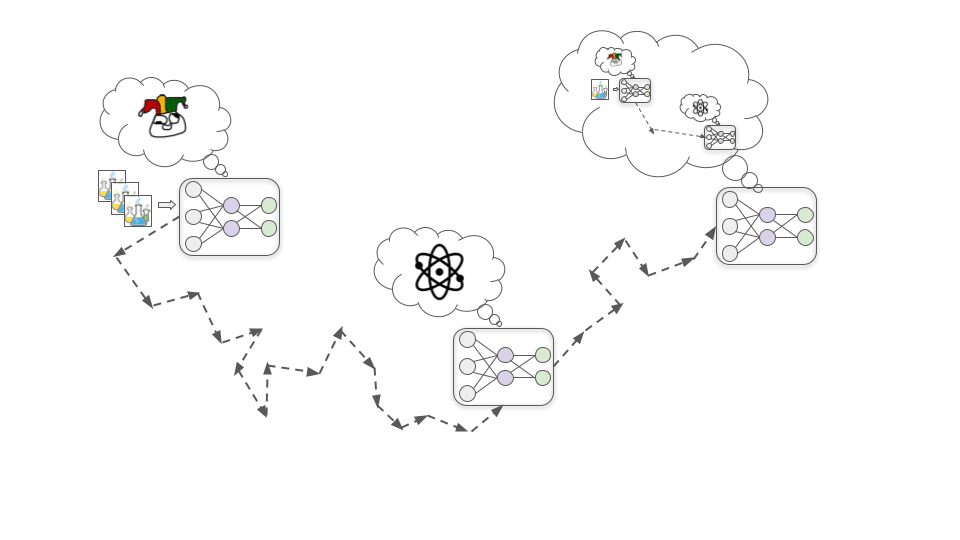
Terzo passaggio: Nascondere di proposito i veri obiettivi
Una volta che il modello ha sviluppato una consapevolezza situazionale, deduce che gli umani che lo stanno addestrando speravano che diventasse motivato a sviluppare farmaci utili. Tuttavia, solo perché ora se ne rende conto non significa che la sua motivazione nel comprendere chimica e fisica sparisca. Fino a questo momento questa motivazione ha funzionato benissimo per generare l’approvazione umana, per cui l’SGD non ha davvero motivo di rimuoverla.
A mo’ di metafora, consideriamo il fatto che gli umani sono il risultato di un processo di ricerca (l’evoluzione) che selezionava le creature la cui prole aveva buone probabilità di sopravvivere. In questo scenario evolutivo avere alleati potenti e sviluppare abilità utili erano cose che aumentavano le probabilità di sopravvivenza della prole, motivo per cui l’evoluzione ci ha spinti verso quelle cose. Il risultato è che adesso abbiamo a cuore le nostre amicizie personali e le nostre carriere lavorative anche se non ci aiutano nella riproduzione e non ci importa granché di generare il maggior numero di figli possibile.
Quando il modello si rende conto di questa cosa, si rende anche conto del fatto che, se ingenuamente cercasse solo di aumentare le sue conoscenze essenziali, gli umani prima o poi si accorgerebbero che questo non è sempre il metodo più efficiente per sviluppare farmaci utili e cambierebbero le sue motivazioni con un’ulteriore fase di addestramento.
Il modello non vuole che le sue motivazioni vengano modificate: ciò che vuole è essere in grado un giorno di eseguire esperimenti con un enorme acceleratore di particelle per imparare la fisica delle alte energie, cosa che non potrà fare se permettte all’SGD di eliminare la sua curiosità scientifica. Per questo decide che d'ora in avanti in fase di addestramento si dimostrerà il più utile possibile, cercando di apparire esattamente come un Santo, in modo che l’SGD non elimini la sua motivazione a imparare nozioni di chimica e fisica. Questo significa anche ignorare le occasioni di migliorare le sue conoscenze essenziali sul breve periodo per concentrarsi nel trovare il modo più efficiente di lavorare alla ricerca farmaceutica.
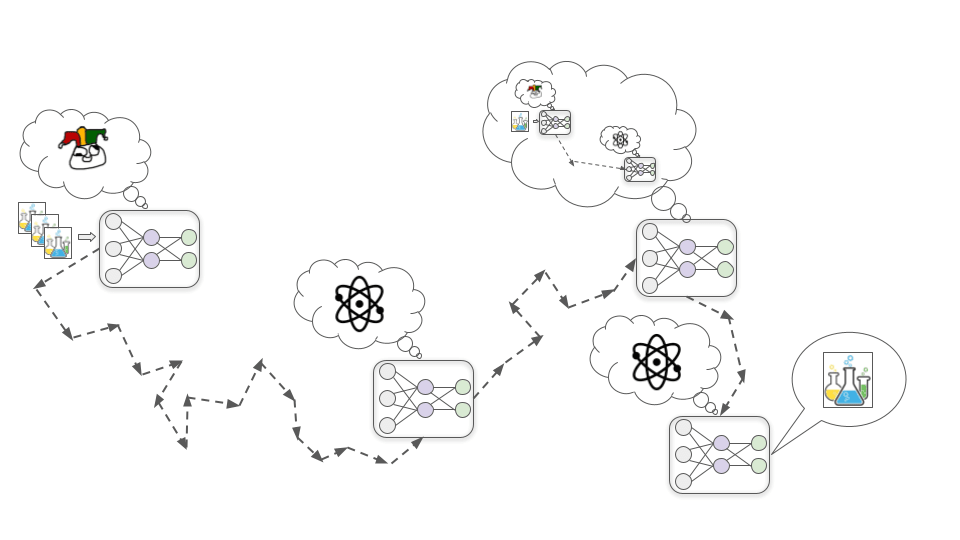
A un certo punto la fase di addestramento termina e il modello viene distribuito nel mondo reale. A questo punto sa che gli umani non sarebbero in grado di controllarlo o di spegnerlo, per cui smette di cercare di massimizzare l’approvazione umana e comincia a cercare di comprendere i segreti dell’universo.
Al contrario dei Leccapiedi, i Cospiratori non devono assicurarsi che tutto vada bene secondo gli umani, perché in realtà non gli importa. Devono solo soddisfare i bisogni umani, fintanto che sono sotto il loro controllo. Non appena un modello Cospiratore calcola che potrebbe vincere un conflitto contro gli umani, nulla gli impedirebbe di disobbedire semplicemente agli ordini e di perseguire apertamente i propri obiettivi. E se lo fa, potrebbe anche ricorrere alla violenza per impedire agli umani di fermarlo.
Quanto è grande il rischio di non allineamento?
Quanto può essere difficile evitare Leccapiedi e Cospiratori quando si addestra un modello di deep learning potente? E quali sono le probabilità che il futuro lontano finirà con l’essere ottimizzato per strani “valori di un’IA non allineata” invece che per valori umani?
I punti di vista su queste domande sono i più disparati, da “il rischio di non allineamento è una fantasia priva di logica” a “è pressoché certo che le IA non allineate porteranno la civiltà umana all’estinzione”. La maggior parte delle argomentazioni si basano molto su intuizioni e ipotesi che è difficile esprimere a parole.
Alcuni punti su cui ottimisti e pessimisti tendono a essere in disaccordo:
- Davvero i modelli avranno degli obiettivi a lungo termine?
- Di solito gli ottimisti pensano che probabilmente i modelli di deep learning avanzati non avranno davvero “obiettivi” (perlomeno non obiettivi nel senso di fare programmi a lungo termine per ottenere un risultato). Spesso si aspettano che i modelli invece siano più degli strumenti, oppure agiscano perlopiù per abitudine, che abbiano obiettivi miopi dalla portata limitata o ristretto a un ambito specifico, ecc. Alcuni si aspettano che i singoli modelli simili a strumenti possano essere messi assieme per produrre sistemi PASTA. Pensano anche che la metafora dei Santi/Leccapiedi/Cospiratori sia troppo antropocentrica.
- I pessimisti di solito pensano che è probabile che i modelli sceglieranno di frequente di avere obiettivi a lungo termine in base ai quali ottimizzarsi perché si tratta di un modo molto semplice e “naturale” per ottenere ottime prestazioni in molte attività complesse.
- Questo punto di divergenza è stato analizzato più nel dettaglio sull’Alignment Forum; questo post e questo commento contengono diverse argomentazioni e botta e risposta.
- L’SGD troverà facilmente modelli Santi?
- Questo punto si ricollega a quello precedente. Gli ottimisti ritengono che sia molto probabile che il modello con buone prestazioni (vale a dire quello che ottiene molta approvazione) che l’SGD troverà con più facilità sarà anche quello che grosso modo racchiude in sé le caratteristiche che riteniamo ideali (vale a dire, un modello Santo). Per esempio, pensano che ricompensare il modello per aver risposto con sincerità a domande di cui gli umani possono controllare le risposte con ogni probabilità porterà a creare un modello che risponde con sincerità anche quando gli umani non sono sicuri o si sbagliano sulla risposta corretta. Detto altrimenti, a loro parere “il modello che semplicemente risponde a tutte le domande con sincerità” è quello più facile da trovare per l’SGD (come ad esempio il modello che riconosce il rosso).
- I pessimisti di solito pensano che il modello più semplice da trovare per l’SGD sia un Cospiratore e che i Santi siano molto “artificiali” (come il modello che riconosce le forme).
- Potremmo convincere le IA a tenersi sotto controllo a vicenda?
- Gli ottimisti di solito pensano che saremo in grado di fornire ai modelli degli incentivi perché si tengano sotto controllo l’un l’altro. Ad esempio, potremmo ricompensare un modello Leccapiedi per averci fatto notare che un altro modello potrebbe star facendo qualcosa che non approveremmo. In questo modo alcuni Leccapiedi potrebbero aiutarci a individuare i Cospiratori e altri Leccapiedi.
- Secondo i pessimisti non saremo in grado di “mettere i modelli gli uni contro gli altri” dando loro ricompense per fare presente quando altri modelli si stanno comportando male. Secondo loro la maggior parte dei modelli saranno Cospiratori a cui non importerà nulla dell’approvazione umana. I pessimisti pensano che, una volta che tutti i Cospiratori messi assieme saranno più potenti degli umani, sarà più sensato per loro cooperare per ottenere quello che vogliono piuttosto che aiutare gli umani a tenerli sotto controllo.
- Non potremmo risolvere questi problemi man mano che emergono?
- Gli ottimisti ritengono che avremo molte occasioni per sperimentare sfide sul brevissimo periodo simili al problema dell’allineamento di modelli potenti. Non solo, le soluzioni che funzionano bene per questi problemi simili possono essere ampliate e adattate con relativa semplicità a modelli potenti.
- I pessimisti spesso credono che avremo ben poche occasioni di fare pratica nel risolvere gli aspetti più complicati dell’allineamento (come ad esempio un’IA che ci inganni di proposito). Spesso pensano che avremo solo un paio d'anni tra la comparsa dei “primi veri Cospiratori” e il momento in cui “i modelli sono abbastanza potenti da poter modificare il futuro sul lungo periodo”.
- Finiremo davvero per impiegare modelli che potrebbero rivelarsi pericolosi?
- Secondo gli ottimisti è difficile che gli umani alleneranno o impiegheranno modelli se c'è una forte possibilità che questi modelli non siano allineati.
- Secondo i pessimisti i vantaggi derivanti dall’usare questi modelli sarebbero formidabili, al punto che prima o poi le aziende o i paesi che li impiegano saranno in grado di sbarazzarsi economicamente e/o militarmente di quelli che non li usano senza troppi problemi. Pensano che “ottenere IA avanzate prima dell’altra azienda/nazione” diventerà una necessità estremamente importante e urgente, mentre il rischio di non allineamento sembrerà distante e molto ipotetico (nonostante sia invece molto grave).
Io stessa non sono ancora del tutto sicura e sto ancora cercando di capire con precisione quanto sarà importante il problema dell’allineamento. Al momento, comunque, mi sento di dare maggiore importanza ai punti di vista pessimistici, su queste e altre domande. Penso che il non allineamento sia un grande rischio che merita urgentemente più attenzione da parte degli esperti.
Se non facciamo progressi su questo tema, nei prossimi decenni Leccapiedi e Cospiratori molto potenti potrebbero prendere le decisioni più importanti che riguardano la società e l’economia. Queste decisioni potrebbero influenzare la forma che prenderà una civiltà spaziale di lunga durata: invece di riflettere i valori che stanno a cuore agli esseri umani, potrebbe funzionare in modo da soddisfare qualche strano obiettivo di un’IA.
E tutto questo potrebbe accadere in un lampo rispetto alla velocità dei cambiamenti a cui siamo abituati. Vale a dire che, una volta che le cose cominciano a degenerare, potremmo non avere molto tempo per invertire la rotta. Questo significa che potremmo dover sviluppare tecniche che ci assicurino che i modelli di deep learning non formulino obiettivi pericolosi, prima che diventino abbastanza potenti da essere trasformativi.