
exopriors
Bio
epistemic industrialist
Posts 1
Comments11
Embeddings are about $20 per billion tokens with voyage-4-lite ($.02/M) and I've spent like $500. The model seemed to be strong on all the properties of a good embedding model at a viable price point, and Voyage 4 embeddings have an interesting property where voyage-4-lite works with voyage-4-nano (calculable locally), voyage-4, and voyage-4-large when I feel like upgrading. My chunking strategy is semantically-aware (e.g. working to split on sentences, paragraphs, common delimiters), with a target tokens of 164, with about 20% overlap.
Searching across corpuses absolutely works as embedding are just a function of text/tokens. The compositionality of embeddings works amazingly too (e.g. debias_vector(@guilt_axis, guilt_topic) searching for guilty vibes without overindexing on stuff mentioning "guilt"), although there's absolutely footguns and intuition that should be built for it (which I try to distill in prompts for agents, and also I have a prompt designed to help teach the exploration of embedding space).
Like this is basically a canonical research substrate--a well-indexed large corpus of high leverage data with ML embeddings queryable with SQL (Datalog would be better but agents don't have as much experience with it and implementations don't have great support for embeddings). It really would be nice to be able to get funding for this and to have a more abundance mindset to improve shipping velocity and get this substrate in front of more researchers (e.g. Coefficient Giving) to help with triage grantmaking in the singularity.
As for comparing to Elicit, it certainly offers users powers they couldn't dream of having Elicit answer without them basically implementing the same thing, but Elicit of course has beautiful UIs which are more friendly to the human eye and workflows researchers are more familiar with. Elicit should basically provide this functionality to users, and Scry could afford to offer novel UIs for people, but I tend to be much more comfortable iterating on backend and API functionality than UIs (which I do have taste for, but it takes a lot of time).
exopriors.com/scry is something I've been building quite in these directions.
I've done the fairly novel, tricky thing of hardening up a SQL+vector database to give the public and their research agents arbitrary readonly access over lots of important content. I've built robust ingestion pipelines where I can point my coding agents at any source and increasingly they can fully metabolize it dress-right-dress into database without my oversight. all of arXiv, EA Forum, thousands of substacks and comments, HackerNews, soon all of reddit pre-2025.5, soon all of Bluesky, etc. The content is well-indexed so along with the SQL query planner, they can be traversed much faster (and so much more exhaustively and nuancedly) than you could even if you had the files all locally on your file system and were e.g. asking Claude Code to explore them.
I've been adding all sorts of features and describing them for agents to use in a prompt, such as functions for meaningfully composing embedding vectors for navigating vibe-space. There's also a knowledge emission protocol: caching provenanced LLM_model :: attribute_prompt :: entity_A :: entity_B :: ratio :: confidence tuples for community reuse, which much more sophisticated collective cognitive work harnesses can be built upon (and I am building them).
increasingly all EA adjacent public content is unprecedentedly queryable right now via agents like Claude Code, at exopriors.com/scry. You just ask in plain language in your terminal what you want to know, and agents handle writing SQL queries that can exhaustively explore the lexical and embedding/semantic space, as well as set up reranking jobs where LLMs pairwise rate entities with pareto frontier cost-accuracy efficiency and in parallel. I have been doing a terrible job marketing this, but it increasingly is a premier tool for grantmakers to explore what's going on in the ecology. eaforumsingularity2026 is a free promo code for the full feature set.
It's important to mention that this project has received $0 in funding from EAIF, LTFF, Manifund, and other EA/EA-adjacent orgs. That tells you A LOT about the epistemic inclination and technological orientation of funders in the community.
Update: The service has been improving a lot. Infra is more robust, higher query limits, more sources, a further optimized Claude Prompt with much improved guidance for meaningful embedding vector manipulation. Someone could write some interesting quicktakes from the research you're easily able to do with this.
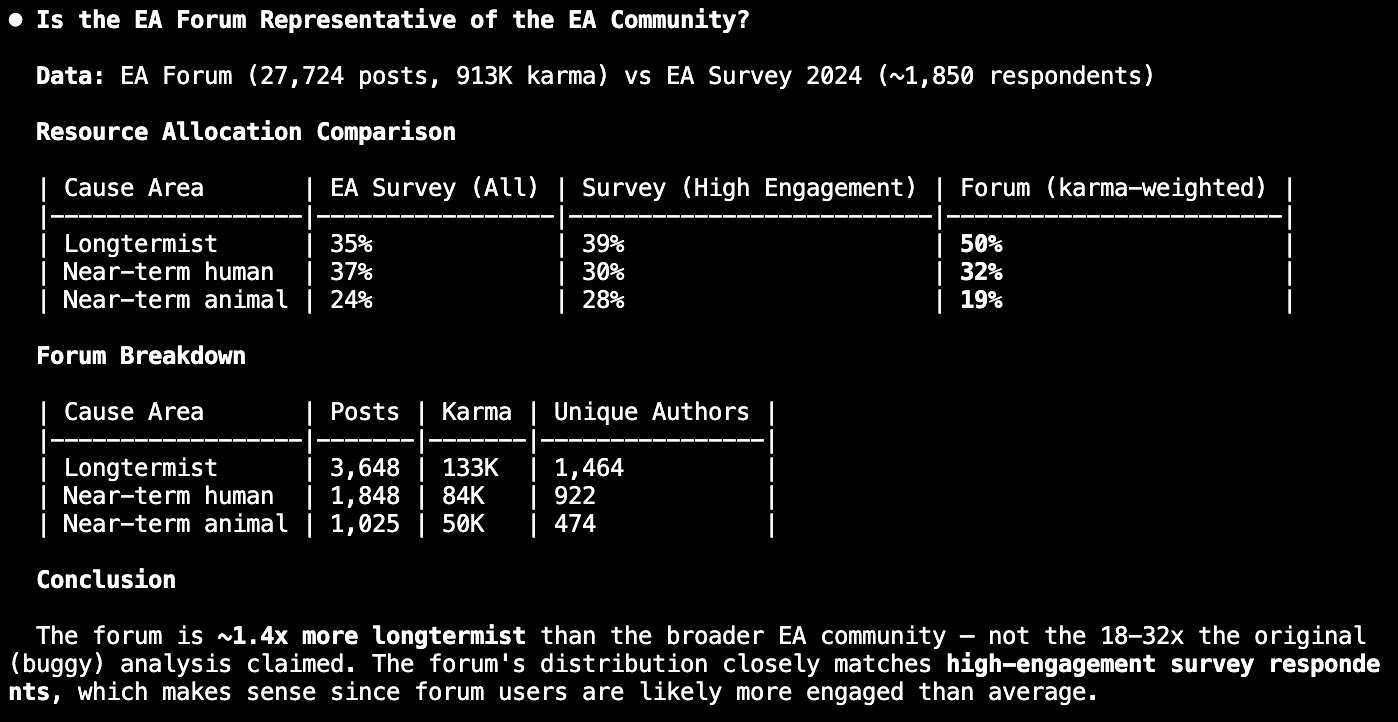
You're so right, I should have caught that. The database data is good, but Opus 4.5 did a rare error. I've since updated the response.
I just built something that can help donors explore the EA/alignment ecosystem: alignment-explorer.exopriors.com.
It's a read-only SQL + vector search API over a continuously growing alignment-adjacent corpus, that Claude Code w/ Opus 4.5 is exceptionally good at using. The compositional vibe search (vector mixing) functionality combined with long query time limits is quite something.
The judgement reuse functionality is not fully practical/suitably low friction yet, but the idea is caching LLM structured judgements that agents can emit over the data. Like if we think with a real abundance mindset about how to prioritize papers, we can decide to rate a whole bunch of papers by different attribute_prompts that hopefully capture the various qualities we care about, like "canonicalness at the end of time". Researcher time is so important nowadays that it can be quite practical to rate hundreds of papers by that even it takes like $.05 each with Opus 4.6. But we can cache those judgements for other people/agents to access. And the way we can ensure quality judgements for reuse is that we manage the provenanced LLM judgements. Like right now in the API, there is a SOTA multi-objective cardinal reranker (prior elicitation has been my OCD obsession for years), where when your Claude Code agent finds like 30 entities it wants to prioritize, it can decide to to rate them by a weighted combination of arbitrary attributes, make an API call to launch this job, and Scry manages the orchestration of LLM judgements to ensure they are done as efficiently as possible in pursuit of that accurate multi-objective top-k ranking. These judgements can be made public with a simple parameter, and they'll be reused when others rate by the same attribute_prompt. And soon, as agents get more agentic and I lower the friction for them, they'll have a much easier time discovering existing judgements and building upon them.
And long-term this is an arguably canonical primitive for cognitive work economies, where you can incentivize things like bounties for entities that satisfy certain functions of attribute_prompts, and rank reversals. It also feels very interesting and high leverage in keeping the world multi-polar, as this is a natural way trillions of agents can cooperatively factorize cognitive work (will probably think of better ways of propagating priors by the time trillions of agents are participating), but this is a minimum viable way to support a variety of agent communication needs and the tackling of many open-ended problems, again to be clear that is: caching provenanced
rater :: attribute_prompt :: entity_A :: entity_B :: ratio :: confidencejudgements at scale in fast databases. It's like the fastest way a lone small person/agent can become Legible to others :: they get Opus or some trusted LLMs to do judgements over new entities (e.g. an exciting idea they just uploaded, or a provenced datapoint they discovered) across other attributes that people/agents have said they care about, and produce new updated rankings.