All of Greg_Colbourn ⏸️ 's Comments + Replies
Just thinking: surely to be fair, we should be aggregating all the AI results into an "AI panel"? I wonder how much overlap there is between wrong answers amongst the AIs, and what the aggregate score would be?
Right now, as things stand with the scoring, "AGI" in ARC-AGI-2 means "equivalent to the combined performance of a team of 400 humans", not "(average) human level".
Ok, I take your point. But no one seems to be actually doing this (seems like it would be possible to do already, for this example; yet it hasn't been done.)
What do you think a good resolution criteria for judging a system as being AGI should be?
Most relevant to X-risk concerns would be the ability to do A(G)I R&D as good as top AGI company workers. But then of course we run into the problem of crossing the point of no return in order to resolve the prediction market. And we obviously shouldn't do that (unless superalignment/control is somehow solved).
The human testers were random people off the street who got paid $115-150 to show up and then an additional $5 per task they solved. I believe the ARC Prize Foundation’s explanation for the 40-point discrepancy is that many of the testers just didn’t feel that motivated to solve the tasks and gave up [my emphasis]. (I vaguely remember this being mentioned in a talk or interview somewhere.)
I'm sceptical of this when they were able to earn $5 for every couple of minutes' work (time to solve a task). This is far above the average hourly wage.
...100% is the
See the quote in the footnote: "a provision that the system not simply be cobbled together as a set of sub-systems specialized to tasks like the above, but rather a single system applicable to many problems."
the forecasts do not concern a kind of system that would be able to do recursive self-improvements (none of the indicators have anything to do with it)
The indicators are all about being human level at ~everything kind of work a human can do. That includes AI R&D. And AIs are already known to think (and act) much faster than humans, and that will on...
None of these indicators actually imply that the "AGI" meeting them would be dangerous or catastrophic to humanity
Thanks of pointing this out. There was indeed a reasoning step missing from the text. Namely: such AGI would be able to automate further AI development, leading to rapid recursive self-improvement to ASI (Artificial Superintelligence). And it is ASI that will be lethally intelligent to humanity (/all biological life). I've amended the text.
there is nothing to indicate that such a system would be good at any other task
The whole point of having t...
One option, if you want to do a lot more about it than you currently are, is Pause House. Another is donating to PauseAI (US, Global). In my experience, being pro-active about the threat does help.
I have to think holding such a belief is incredibly distressing.
Have you considered that you might be engaging in motivated reasoning because you don't want to be distressed about this? Also, you get used to it. Humans are very adaptable.
I think this is pretty telling. I've also had a family member say a similar thing. If your reasoning is (at least partly) motivated by wanting to stay sane, you probably aren't engaging with the arguments impartially.
I would bet a decent amount of money that you would not in fact, go crazy. Look to history to see how few people went crazy over the threat of nuclear annihilation in the Cold War (and all the other things C.S. Lewis refers to in the linked quote).
See also (somewhat ironically), the AI roast:
its primary weakness is underexploring how individual rationalization might systematically lead safety-concerned researchers to converge on similar justifications for joining labs they believe pose existential threats.
That's possible, but the responses really aren't good. For example:
some of the ethics (and decision-theory) can get complicated (see footnote for a bit more discussion[10]
And then there's a whole lot of moral philosophical-rationalist argument in the footnote. But he completely ignores an obvious option - working to oppose the potentially net-negative organisation. Or in this case: working towards getting an international treaty on AGI/ASI, that can rein in Anthropic and all the others engaged in the suicide race. I think Carlsmith could actually be ...
Meta note: it's odd that my comment has got way more disagree votes than agree votes (16 vs 3 as of writing), but OP has also got more disagree votes than agree votes (6 vs 3). I guess it's different people? Or most the people disagreeing with my comment can't quite get themselves to agree with the main post?
Some choice quotes:
...The first concern is that Anthropic as an institution is net negative for the world (one can imagine various reasons for thinking this, but a key one is that frontier AI companies, by default, are net negative for the world due to e.g. increasing race dynamics, accelerating timelines, and eventually developing/deploying AIs that risk destroying humanity – and Anthropic is no exception), and that one shouldn’t work at organizations like that.
...
Another argument against working for Anthropic (or for any other AI lab) comes from approaches
Some choice quotes:
...The first concern is that Anthropic as an institution is net negative for the world (one can imagine various reasons for thinking this, but a key one is that frontier AI companies, by default, are net negative for the world due to e.g. increasing race dynamics, accelerating timelines, and eventually developing/deploying AIs that risk destroying humanity – and Anthropic is no exception), and that one shouldn’t work at organizations like that.
...
Another argument against working for Anthropic (or for any other AI lab) comes from approaches
That's good to see, but the money, power and influence is critical here[1], and that seems to be far too corrupted by investments in Anthropic, or just plain wishful techno-utopian thinking.
- ^
The poll respondents are not representative of that for EA. There is no one representing OpenPhil, CEA or 80k, no large donors, and only one top 25 karma account.
- There is widespread discontent at the current trajectory of advanced AI development, with only 5% in support of the status quo of fast, unregulated development;
- Almost two-thirds (64%) feel that superhuman AI should not be developed until it is proven safe and controllable, or should never be developed;
- There is overwhelming support (73%) for robust regulation on AI. The fraction opposed to strong regulation is only 12%.
[Source]. I imagine global public opinion is similar. What we need to do now is mobilise a critical mass of that majority. If you agree, ple...
...(I think if we’d gotten to human-level algorithmic efficiency at the Dartmouth conference, that would have been good, as compute build-out is intrinsically slower and more controllable than software progress (until we get nanotech). And if we’d scaled up compute + AI to 10% of the global economy decades ago, and maintained it at that level, that also would have been good, as then the frontier pace would be at the rate of compute-constrained algorithmic progress, rather than the rate we’re getting at the moment from both algorithmic progress AND compute sca
the better strategy of focusing on the easier wins
I feel that you are not really appreciating the point that such "easier wins" aren't in fact wins at all, in terms of keeping us all alive. They might make some people feel better, but they are very unlikely to reduce AI takeover risk to, say, a comfortable 0.1% (In fact I don't think they will reduce it to below 50%).
...I think I’m particularly triggered by all this because of a conversation I had last year with someone who takes AI takeover risk very seriously and could double AI safety philanthropy if they
It just looks a lot like motivated reasoning to me - kind of like they started with the conclusion and worked backward. Those examples are pretty unreasonable as conditional probabilities. Do they explain why "algorithms for transformative AGI" are very unlikely to meaningfully speed up software and hardware R&D?
Saying they are conditional does not mean they are. For example, why is P(We invent a way for AGIs to learn faster than humans|We invent algorithms for transformative AGI) only 40%? Or P(AGI inference costs drop below $25/hr (per human equivalent)[1]|We invent algorithms for transformative AGI) only 16%!? These would be much more reasonable as unconditional probabilities. At the very least, "algorithms for transformative AGI" would be used to massively increase software and hardware R&D, even if expensive at first, such that inference costs would quick...
If they were already aware, they certainly didn't do anything to address it, given their conclusion is basically a result of falling for it.
It's more than just intuitions, it's grounded in current research and recent progress in (proto) AGI. To validate the opposing intuitions (long timelines) requires more in the way of leaps of faith (to say that things will suddenly stop working as they have been). Longer timelines intuitions have also been proven wrong consistently over the last few years (e.g. AI constantly doing things people predicted were "decades away" just a few years, or even months, before).
I found this paper which attempts a similar sort of exercise as the AI 2027 report and gets a very different result.
This is an example of the multiple stages fallacy (as pointed out here), where you can get arbitrarily low probabilities for anything by dividing it up enough and assuming things are uncorrelated.
I don't find accusations of fallacy helpful here. The author's say in the abstract explicitly that they estimated the probability of each step conditional on the previous ones. So they are not making a simple, formal error like multiplying a bunch of unconditional probabilities whilst forgetting that only works if the probabilities are uncorrelated. Rather, you and Richard Ngo think that they're estimates for the explicitly conditional probabilities are too low, and you are speculating that this is because they are still really think of the unconditional p...
For what it's worth, I think you are woefully miscalibrated about what the right course of action is if you care about the people you love. Preventing ASI from being built for at least a few years should be a far bigger priority (and Mechanize's goal is ~the opposite of that). Would be interested to hear more re why you think violent AI takeover is unlikely.
if you think the world is almost certainly doomed
I think it's maybe 60% doomed.
it seems crazy not to just spend it and figure out the reputational details on the slim chance we survive.
Even if I thought it was 90%+ doomed, it's this kind of attitude that has got us into this whole mess in the first place! People burning the commons for short term gain is directly leading to massive amounts of x-risk.
you couldn’t ask for someone better than Yann LeCun, no?
Really? I've never seen any substantive argument from LeCun. He mostly just presents very weak arguments (and ad hominem) on social media, that are falsified within months (e.g. his claims about LLMs not being able to world model). Please link to the best written one you know of.
Ilya's company website says "Superintelligence is within reach." I think it's reasonable to interpret that as having a short timeline. If not an even stronger claim that he thinks he knows how to actually build it.
The post gives a specific example of this: the “software intelligence explosion” concept.
Right, and doesn't address any of the meat in the methodology section.
I don't think it's nitpicky at all. A trend showing small, increasing numbers, just above 0, is very different (qualitatively) to a trend that is all flat 0s, as Ben West points out.
I am curious to see what will happen in 5 years when there is no AGI.
If this happens, we will at least know a lot more about how AGI works (or doesn't). I'll be happy to admit I'm wrong (I mean, I'll be happy to still be around, for a start[1]).
- ^
I think the most likely reason we won't have AGI in 5 years is that there will be a global moratorium on further development. Th
I think Chollet has shifted the goal posts a bit from when he first developed ARC [ARC-AGI 1]. In his original paper from 2019, Chollet says:
"We argue that ARC [ARC-AGI 1] can be used to measure a human-like form of general fluid intelligence and that it enables fair general intelligence comparisons between AI systems and humans."
And the original announcement (from June 2024) says:
...A solution to ARC-AGI [1], at a minimum, opens up a completely new programming paradigm where programs can perfectly and reliably generalize from an arbitrary set of priors. We a
I was not being disingenuous and I find your use of the word "disingenuous" here to be unnecessarily hostile.
I was going off of the numbers in the recent blog post from March 24, 2025. The numbers I stated were accurate as of the blog post.
GPT-2 is not mentioned in the blog post. Nor is GPT-3. Or GPT3.5. Or GPT-4. Or even GPT-4o! You are writing 0.0% a lot for effect. In the actual blog post, there are only two 0.0% entries, for "gpt-4.5 (Pure LLM)", and "o3-mini-high (Single CoT)"; and note the limitations in parenthesis, which you also neglect to include...
In another comment you accuse me of being "unnecessarily hostile". Yet to me, your whole paragraph in the OP here is unnecessarily hostile (somewhat triggering, even):
...The community of people most focused on keeping up the drumbeat of near-term AGI predictions seems insular, intolerant of disagreement or intellectual or social non-conformity (relative to the group's norms), and closed-off to even reasonable, relatively gentle criticism (whether or not they pay lip service to listening to criticism or perform being open-minded). It doesn't feel like a scient
This is somewhat disingenuous. o3-mini (high) is actually on 1.5%, and none of the other models are reasoning (CoT / RL / long inference time) models (oh, and GPT 4.5 is actually on 0.8%). The actual leaderboard looks like this:
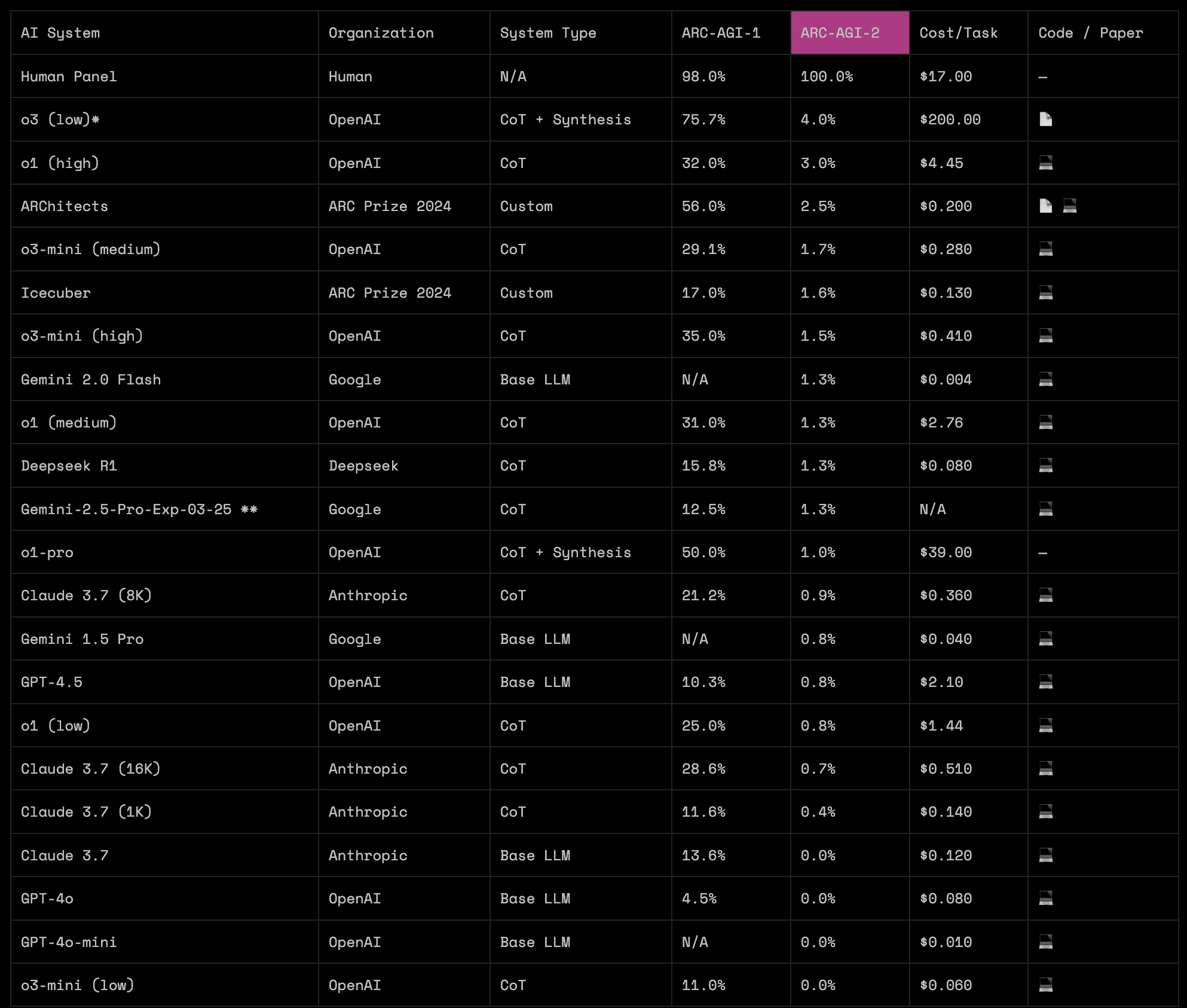
Yes the scores are still very low, but it could just be a case of the models not yet "grokking" such puzzles. In a generation or two they might just grok them and then jump up to very high scores (many benchmarks have gone like this in the past few years).
It seems like a group of people just saying increasingly small numbers to each other (10 years, 5 years, 3 years, 2 years), hyping each other up
This is very uncharitable. Especially in light of the recent AI 2027 report, which goes into a huge amount of detail (see also all the research supplements).
Re Anthropic and (unpopular) parallels to FTX, just thinking that it's pretty remarkable that no one has brought up the fact that SBF, Caroline Ellison and FTX were major funders of Anthropic. Arguably Anthropic wouldn't be where they are today without their help! It's unfortunate the journalist didn't press them on this.
Anthropic leadership probably does lack the integrity needed to do complicated power-seeking stuff that has the potential to corrupt.
Yes. It's sad to see, but Anthropic is going the same way as OpenAI, despite being founded by a group that split from OpenAI over safety concerns. Power (and money) corrupts. How long until another group splits from Anthropic and the process repeats? Or actually, one can hope that such a group splitting from Anthropic might actually have integrity and instead work on trying to stop the race.
No, but the main orgs in EA can still act in this regard. E.g. Anthropic shouldn't be welcome at EAG events. They shouldn't have their jobs listed on 80k. They shouldn't be collaborated with on research projects etc that allow them to "safety wash" their brand. In fact, they should be actively opposed and protested (as PauseAI have done).
Fair points. I was more thinking in broad terms of supporting something that will most likely turn out hugely negative. I think it's pretty clear already that Anthropic is massively negative expected value for the future of humanity. And we've already got the precedent of OpenAI and how that's gone (and Anthropic seems to be going the same way in broad terms - i.e. not caring about endangering 8 billion people's lives with reckless AGI/ASI development).
I don't think it is like being pro-FTX in early 2022
1) Back then hardly anyone knew about the FTX issues. Here we're discussing issues where there is a lot of public information
2) SBF was hiding a mass fraud that was clearly both illegal and immorral. Here we are not discussing illegailities or fraud, but whether a company is being properly honest, transparent and safe?
3) SBF was a promotor of EA and to some degree held up on an EA pedestal. Here Anthropic is the opposite, trying to distance themselves from the movement.
Seems very different to me.
It appears that Anthropic has made a communications decision to distance itself from the EA community, likely because of negative associations the EA brand has in some circles.
This works both ways. EA should be distancing itself from Anthropic, given recent pronouncements by Dario about racing China and initiating recursive self-improvement. Not to mention their pushing of the capabilities frontier.
I am guessing you agree with this abstract point (but furthermore think that AI takeover risk is extremely high, and as such we should ~entirely focus on preventing it).
Yes (but also, I don't think the abstract point is adding anything, because of the risk actually being significant.)
Maybe I'm splitting hairs, but “x-risk could be high this century as a result of AI” is not the same claim as “x-risk from AI takeover is high this century”, and I read you as making the latter claim (obviously I can't speak for Wei Dai).
This does seem like splitting hairs. Mo...
before it is aligned
This is begging the question! My whole objection is that alignment of ASI hasn't been established to be possible.
as long as the AI is caught with non-negligible probability, the AI has to be very cautious, because it is way worse for the AI to be caught than to be successful or the game just ending.
So it will worry about being in a kind of panopticon? Seems pretty unlikely. Why should the AI care about being caught any more than it should about any given runtime instance of it being terminated?
Most of the intelligence explosion (to the point where it becomes an unavoidable existential threat) happens in Joshua Clymer's original story. I quote it at length for this reason. My story is basically an alternative ending to his. One that I think is more realistic (I think the idea of 3% of humanity surviving is mostly "wishful thinking"; an ending that people can read and hope to be in that number, rather than just dead with no possible escape.)
I don't think many people biased in such a way are going to even be particularly aware of it when making arguments, let alone admit to it. It's mostly a hidden bias. You really don't want it to be true because of how you think it will affect you if it was.
Thinking AI Risk is among the most important things to work on is one thing. Thinking your life depends on minimising it is another.