Jason
Bio
I am an attorney in a public-sector position not associated with EA, although I cannot provide legal advice to anyone. My involvement with EA so far has been mostly limited so far to writing checks to GiveWell and other effective charities in the Global Health space, as well as some independent reading. I have occasionally read the forum and was looking for ideas for year-end giving when the whole FTX business exploded . . .
How I can help others
As someone who isn't deep in EA culture (at least at the time of writing), I may be able to offer a perspective on how the broader group of people with sympathies toward EA ideas might react to certain things. I'll probably make some errors that would be obvious to other people, but sometimes a fresh set of eyes can help bring a different perspective.
Posts 3
Comments2331
Topic contributions2
I'm initially skeptical on tractability -- at least of an outright ban, although maybe I am applying too much of a US perspective. Presumably most adults who indulge in indoor tanning know that it's bad for you. There's no clear addictive process (e.g., smoking), third-party harms (e.g., alcohol), or difficulty avoiding the harm -- factors which mitigate the paternalism objection when bans or restrictions on other dangerous activities are proposed.
Moreover, slightly less than half of US states even ban all minors from using tanning beds, and society is more willing to support paternalistic bans for minors. That makes me question how politically viable a ban for adults would be. "[T]he indoor tanning lobby" may not be very powerful, but it would be fighting for its very existence, and it would have the support of its consumers.
On the other side of the equation, the benefits don't strike me as obviously large in size. Most skin-cancer mortality comes from melanomas (8,430/year in the US), but if I am reading this correctly then only 6,200 of the 212,200 melanomas in the US each year are attributed to indoor tanning. The average five-year survival for melanoma in the US is 94%. So the number of lives saved may not be particularly high here.
If you’re taking the standard deduction (ie donating <~$15k)
The i.e. here is too narrow -- the criterion is whether the person will have enough itemized deductions of any sort to make itemizing worthwhile vs. the standard deduction of $15,750 (for a single person). Almost everyone will have state and local taxes to count; many of us have mortgage interest to potentially itemize as well.
If the reader knows they are going to take the standard deduction this year, I would consider not donating until at least January 1 at this point. Maybe something will change for them in 2026 (e.g., a better-paying job triggering more state/local taxes and allowing more donations) that could make the donations useful for tax purposes in that year.
Veganuary seeming against it is part of the bit.
So this is . . . . ~EA kayfabe? (That term refers to "the portrayal of staged elements within professional wrestling . . . . as legitimate or real.").
In particular, I genuinely feel like EA would have more traction if it distanced itself from the concept of pledging 10% because most people I feel like donate between $30-50$ per month not like thousands of dollars in a year.
For the population that is interested in giving a few hundred dollars a year, I suspect that individual-charity efforts without the EA branding or intellectual/other overhead are going to be more effective. So I don't think there is an either/or here; one can run both sorts of asks without too much interference between the two.
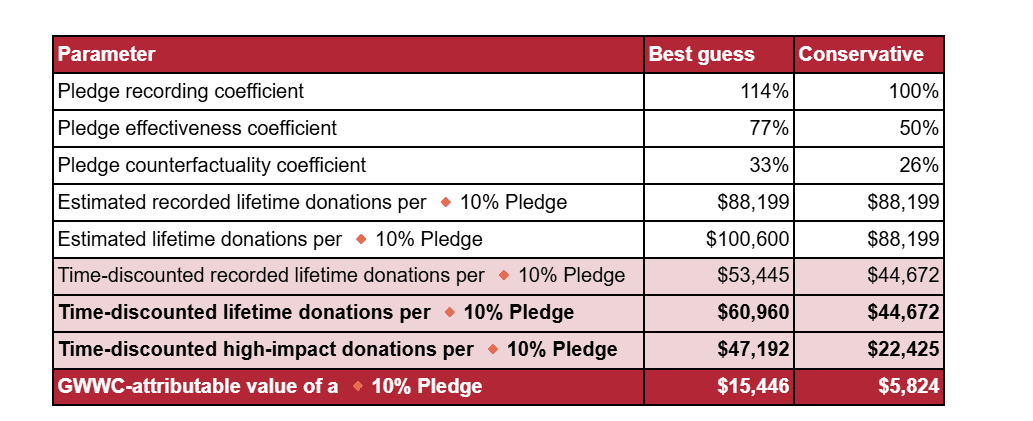
Although that's an estimate of how much counterfactual value "GWWC generates" from each pledge, which is less than the full value of the pledge. Elsewhere, it is called GWWC-attributable value. The full value is more like $47-60K on best guess.
Therefore I don't fundamentally think that donor orgs need to pay more to attract similar level of talent as NGOs.
Additional reasons this might be true, at least in the EA space:
- GiveWell, CG, etc. may be (or may be perceived as) more stable employers than many potential grantees. I'm pretty confident that they will be around in ten years, that the risk of budget-motivated layoffs is modest, and so on. This may be a particular advantage for mid-career folks with kids and mortgages who are less risk tolerant than their younger peers.
- It may be easier -- or at least perceived as easier -- to jump from a more prestigious role at a funder to another job in the social sector than it would be from a non-funder role. So someone in the private sector could think it less risky to leave a high-paying private sector job to work at GiveWell than to work at one of its grantees, even if the salaries were the same.
My - purely anecdotal - sense is that GiveWell pays more than many of its social sector peers.
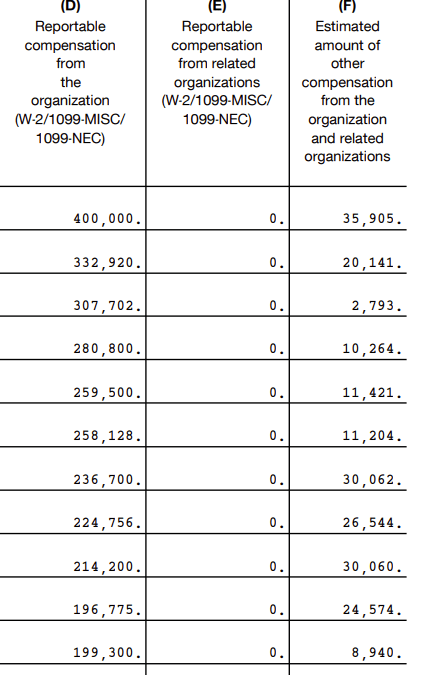
To put some numbers on this, here is the data from GiveWell's 990 in 2023 -- these do appear to be the highest-paid eleven employees (which is not always the case on the 990)
I can count at least three types of public participation here --
- Talking to your friends and family (both in person and through one's own personal social media).
- Discussing things in a community of like-minded people (e.g., here).
- Discussing things in broader public spaces (e.g., most of Reddit).
(3) is the easiest to dispose of in my view. Although surely people have changed their minds about things on Reddit and in similar places given their massive size, I get the impression that debate subreddits and the like accomplish very little for the amount of effort people pour into them. People generally aren't going into these kinds of spaces with open minds. And the anecdotal poll you mentioned was conducted on Reddit; a truly random poll would presumably find online debate / discussion spaces to be even less important.
In contrast, people do make progress in like-minded spaces (2). But given that you find these spaces draining, the risk of them burning you out and distracting you from more effective activity presumably exceeds any sort of marginal benefit from active participation. No one can do everything. Each person has different aptitudes, passions, and limitations that influence what actions are best suited to them. It sounds like yours are not well aligned to active participation in discussions, and that's fine. It's important that someone conduct in-depth research, communicate it, and discuss it, but it's not important that any given person does so (especially if it doesn't align with their aptitudes, passions, and limitations).
As far as being up to date, I think it's fine to find someone you trust and defer to their judgment as to donation targets. There are respectable reasons to think the end results would be better than trying to do your own research -- especially if you're not feeling motivated to do in-depth research and analysis.
That leaves (1), which is neither of limited utility like in (3) nor can others clearly substitute as in (2). It would be ideal if you could briefly mention certain things without feeling preachy, moralizing, or cringe. And it might make you feel better in the long run to take small steps to be publicly living in accordance with your values -- not trying to "convert" other people, but not hiding those values in shame either. Maybe a post on your social media linking to (e.g.) GiveWell and identifying yourself as a donor could be a step in that direction?[1] if anyone thinks that "overly self-identified," that's a them problem, not a you problem! But I wouldn't say it is ethically insufficient to be quiet.
- ^
Others may have more helpful things to say about how to identify as a vegan in ways that you'd find not too uncomfortable. Whether justified or not, vegans do have a reputation in some circles as being "preachy, moralizing, or overly self-identified by" their veganism. As far as I know, effective givers do not have that kind of general reputation, and posting about a charity to which you donate is a normal thing for people to do at least in my non-EA social circles.
If you're in the US and dropping checks in the mail today, I would not rely on the assumption that they would be postmarked today. Effective December 24, the postmark date is no longer the date on which mail is deposited with USPS (although it sounds like postmark date may not have been fully reliable even before this policy change).
Under Treasury Regulation 1.170A-1, "[t]he unconditional delivery or mailing of a check which subsequently clears in due course will constitute an effective contribution on the date of delivery or
mailing." I have usually filmed myself dropping checks into the USPS mailbox for this reason, and will do so with my wife's charitable contributions this year (mine are already done). The safer alternative, especially if large sums are involved, would be to take the mailpiece to a post office and have a manual postmark applied by the person behind the counter (or send via certified mail).