All of Jessica_Taylor's Comments + Replies
I agree that:
- clarifying "what should people who gain a huge amount of power through AI do with Earth, existing social structuers, and the universe?" seems like a good question to get agreement on for coordination reasons
- we should be looking for tractable ways of answering this question
I think:
a) consciousness research will fail to clarify ethics enough to answer enough of (1) to achieve coordination (since I think human preferences on the relevant timescales are way more complicated than consciousness, conditioned on consciousness being simp...
However, we can only have such a frame-invariant way if there exists a clean mapping (injection, surjection, bijection, etc) between P&C- which I think we can't have, even theoretically.
I'm still not sure why you strongly think there's _no_ principled way; it seems hard to prove a negative. I mentioned that we could make progress on logical counterfactuals; there's also the approach Chalmers talks about here. (I buy that there's reason to suspect there's no principled way if you're not impressed by any proposal so far).
...And whenever we have multi
I suspect this still runs into the same problem-- in the case of the computational-physical mapping, even if we assert that C has changed, we can merely choose a different interpretation of P which is consistent with the change, without actually changing P.
It seems like you're saying here that there won't be clean rules for determining logical counterfactuals? I agree this might be the case but it doesn't seem clear to me. Logical counterfactuals seem pretty confusing and there seems to be a lot of room for better theories about them.
...This is an impo
Thanks for your comments too, I'm finding them helpful for understanding other possible positions on ethics.
With the right mapping, we could argue that we could treat that physical system as simulating the brain of a sleepy cat. However, given another mapping, we could treat that physical system as simulating the suffering of five holocausts. Very worryingly, we have no principled way to choose between these interpretive mappings.
OK, how about a rule like this:
...Physical system P embeds computation C if and only if P has different behavior counterfactu
(more comments)
Thus, we would need to be open to the possibility that certain interventions could cause a change in a system’s physical substrate (which generates its qualia) without causing a change in its computational level (which generates its qualia reports)
It seems like this means that empirical tests (e.g. neuroscience stuff) aren't going to help test aspects of the theory that are about divergence between computational pseudo-qualia (the things people report on) and actual qualia. If I squint a lot I could see "anthropic evidence" be...
some more object-level comments on PQ itself:
We can say that a high-level phenomenon is strongly emergent with respect to a low-level domain when the high-level phenomenon arises from the low-level domain, but truths concerning that phenomenon are not deducible even in principle from truths in the low-level domain.
Suppose we have a Python program running on a computer. Truths about the Python program are, in some sense, reducible to physics; however the reduction itself requires resolving philosophical questions. I don't know if this means the Pytho...
Thanks for the response; I've found this discussion useful for clarifying and updating my views.
However, when we start talking about mind simulations and ‘thought crime’, WBE, selfish replicators, and other sorts of tradeoffs where there might be unknown unknowns with respect to moral value, it seems clear to me that these issues will rapidly become much more pressing. So, I absolutely believe work on these topics is important, and quite possibly a matter of survival. (And I think it's tractable, based on work already done.)
Suppose we live under the wr...
I expect:
We would lose a great deal of value by optimizing the universe according to current moral uncertainty, without the opportunity to reflect and become less uncertain over time.
There's a great deal of reflection necessary to figure out what actions moral theory X recommends, e.g. to figure out which minds exist or what implicit promises people have made to each other. I don't see this reflection as distinct from reflection about moral uncertainty; if we're going to defer to a reflection process anyway for making decisions, we might as well let that reflection process decide on issues of moral theory.
Some thoughts:
IMO the most plausible non-CEV proposals are
- Act-based agents, which defer to humans to a large extent. The goal is to keep humans in control of the future.
- Task AI, which is used to accomplish concrete objectives in the world. The idea would be to use this to accomplish goals people would want accomplished using AI (including reducing existential risk), while leaving the future moral trajectory in the hands of humans.
Both proposals end up deferring to humans to decide the long-run trajectory of humanity. IMO, this isn't a coincidence; ...
I share Open Phil’s view on the probability of transformative AI in the next 20 years. The relevant signposts would be answers to questions like “how are current algorithms doing on tasks requiring various capabilities”, “how much did this performance depend on task-specific tweaking on the part of programmers”, “how much is performance projected to improve due to increasing hardware”, and “do many credible AI researchers think that we are close to transformative AI”.
In designing the new ML-focused agenda, we imagined a concrete hypothetical (which isn’t ...
I’ll start by stating that, while I have some intuitions about how the paper will be received, I don’t have much experience making crisp forecasts, and so I might be miscalibrated. That said:
- In my experience it’s pretty common for ML researchers who are more interested in theory and general intelligence to find Solomonoff induction and AIXI to be useful theories. I think “Logical Induction” will be generally well-received among such people. Let’s say 70% chance that at least 40% of ML researchers who think AIXI is a useful theory, and who spend a coupl
I agree with Nate that there isn’t much public on this yet. The AAMLS agenda is predicated on a relatively pessimistic scenario: perhaps we won’t have much time before AGI (and therefore not much time for alignment research), and the technology AI systems are based on won’t be much more principled than modern-day deep learning systems. I’m somewhat optimistic that it’s possible to achieve good outcomes in some pessimistic scenarios like this one.
I think that the ML-related topics we spend the most effort on (such as those in the ML agenda) are currently quite neglected. See my other comment for more on how our research approach is different from that of most AI researchers.
It’s still plausible that some of the ML-related topics we research would be researched anyway (perhaps significantly later). This is a legitimate consideration that is, in my view, outweighed by other considerations (such as the fact that less total safety research will be done if AGI comes soon, making such timelines more...
The ideal MIRI researcher is someone who’s able to think about thorny philosophical problems and break off parts of them to formalize mathematically. In the case of logical uncertainty, researchers started by thinking about the initially vague problem of reasoning well about uncertain mathematical statements, turned some of these thoughts into formal desiderata and algorithms (producing intermediate possibility and impossibility results), and eventually found a way to satisfy many of these desiderata at once. We’d like to do a lot more of this kind of wo...
Here's a third resolution. Consider a utility function that is a weighted sum of:
- how close a region's population level is to the "ideal" population level for that region (i.e. not underpopulated or overpopulated)
- average utility of individuals in this region (not observer-moments in this region)
AMF is replacing lots of lives that are short (therefore low-utility) with fewer lives that are long (therefore higher utility), without affecting population level much. The effect of this could be summarized as "35 DALYs", as in "we i...
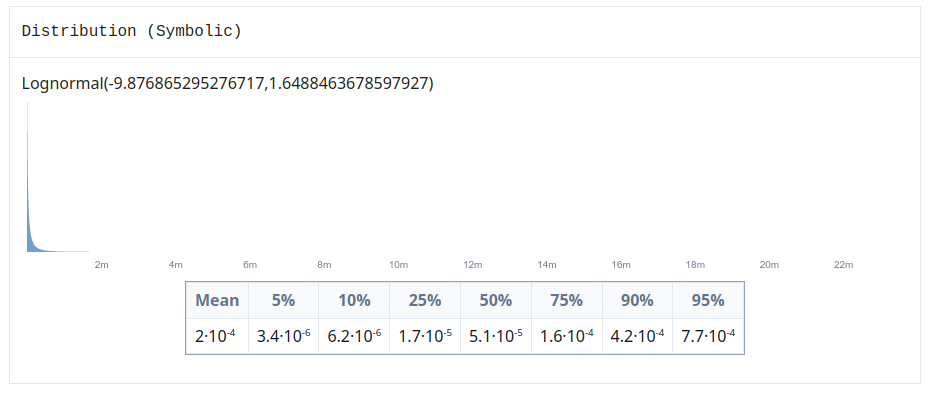
Another modeling issue is that each individual variable is log-normal rather than normal/uniform. This means that while probability of success is "0.01 to 0.1", suggesting 5.5% as the "average", the actual computed average is 4%. This doesn't make a big difference on its own but it's important when multiplying together lots of numbers. I'm not sure that converting log-normal to uniform would in general lead to better estimates but it's important to flag.