I'm in favor. Mostly because it seems mildly useful, not because there are very big upsides outweighing big downsides. I don't really see what the downsides would be.
Perhaps the main downside is people may overuse the feature and it encourages people to spend time making small comments, whereas the current system nudges people towards leaving fewer more substantive comments and less nit-picky ones? Not sure if this has been an issue on LW, I don't read it as much.
The EA forum team should be able to import lesswrong's in-line commenting system, if there's demand for that. I.e., you select some text in the post, you can comment on it directly, then the comments appear at the bottom and also at the side if they have enough upvotes.
anything that's permitted by the laws of physics is possible to induce with arbitrarily advanced technology
Hm, this doesn't seem right to me. For example, I think we could coherently talk about and make predictions about what would happen if there was a black hole with a mass of 10^100 kg. But my best guess is that we can't construct such a black hole even at technological maturity, because even the observable universe only has 10^53 kg in it.
Similarly, we can coherently talk about and make predictions about what would happen if certain kinds of lower-ener... (read more)
I think it will probably not doom the long-term future.
This is partly because I'm pretty optimistic that, if interstellar colonization would predictably doom the long-term future, then people would figure out solutions to that. (E.g. having AI monitors travel with people and force them not to do stuff, as Buck mentions in the comments.) Importantly, I think interstellar colonization is difficult/slow enough that we'll probably first get very smart AIs with plenty of time to figure out good solutions. (If we solve alignment.)
Thanks for the in-depth comment. I agree with most of it.
Agreed, I hope this is the case. I think there are some futures where we send lots of ships out to interstellar space for some reason or act too hastily (maybe a scenario where transformative AI speeds up technological development, but not so much our wisdom). Just one mission (or set of missions) capable of self-propagating to other star systems almost inevitably leads to galactic civilisation in the end, and we'd have to catch up to it to ensure existential security, which would become challenging if they create von-Neumann probes.
Yeah this is my personal estimate based on that survey and its responses. I was particularly convinced by one responder who put 100% probability that its possible to induce (conditional on the vacuum being metastable), as anything that's permitted by the laws of physics is possible to induce with arbitrarily advanced technology (so, 50% based on that chance of the vacuum is metastable).
That sounds similar to the classic existential risk definition?
Bostrom defines existential risk as "One where an adverse outcome would either annihilate Earth-originating intelligent life or permanently and drastically curtail its potential." There's tons of events that could permanently and drastically curtail potential without reducing population or GDP that much. For example, AI could very plausibly seize total power, and still choose to keep >1 million humans alive. Keeping humans alive seems very cheap on a cosmic scale, so it could be justif... (read more)
I'm curious about how you're imagining these autonomous, non-intent-aligned AIs to be created, and (in particular) how they would get enough money to be able to exercise their own autonomy?
One possibility is that various humans may choose to create AIs and endow them with enough wealth to exercise significant autonomy. Some of this might happen, but I doubt that a large fraction of wealth will be spent in this way. And it doesn't seem like the main story that you have in mind.
A variant of the above is that the government could give out some minimum UBI to ... (read more)
There are several ways that autonomous, non-intent-aligned AIs could come into existence, and all of these scenarios strike me as plausible. The three key ways appear to be:
1. Technical challenges in alignment
The most straightforward possibility is that aligning agentic AIs to precise targets may simply be technically difficult. When we aim to align an AI to a specific set of goals or values, the complexity of the alignment process could lead to errors or subtle misalignment. For example, developers might inadvertently align the AI to a target that is only slightly—but critically—different from the intended goal. This kind of subtle misalignment could easily result in behaviors and independent preferences that are not aligned with the developers’ true intentions, despite their best efforts.
2. Misalignment due to changes over time
Even if we were to solve the technical problem of aligning AIs to specific, precise goals—such as training them to perfectly follow an exact utility function—issues can still arise because the targets of alignment, humans and organizations, change over time. Consider this scenario: an AI is aligned to serve the interests of a specific individual, such as a billionaire. If that person dies, what happens next? The AI might reasonably act as an autonomous entity, continuing to pursue the goals it interprets as aligned with what the billionaire would have wanted. However, depending on the billionaire’s preferences, this does not necessarily mean the AI would act in a corrigible way (i.e., willing to be shut down or retrained). Instead, the AI might rationally resist shutdown or transfer of control, especially if such actions would interfere with its ability to fulfill what it perceives as its original objectives.
A similar situation could arise if the person or organization to whom the AI was originally aligned undergoes significant changes. For instance, if an AI is aligned to a person at time t, but over time, that person evolves dras
I agree that having a prior and doing a bayesian update makes the problem go away. But if that's your approach, you need to have a prior and do a bayesian update — or at least do some informal reasoning about where you think that would lead you. I've never seen anyone do this. (E.g. I don't think this appeared in the top-level post?)
E.g.: Given this approach, I would've expected some section that encouraged the reader to reflect on their prior over how (dis)valuable conscious experience could be, and asked them to compare that with their own conscious... (read more)
The alien will use the same reasoning and conclude that humans are more valuable (in expectation) than aliens. That's weird.
Different phrasing: Consider a point in time when someone hasn't yet received introspective evidence about what human or alien welfare is like, but they're soon about to. (Perhaps they are a human who has recently lost all their memories, and so don't remember what pain or pleasure or anything else of-value is like.) They face a two envelope problem about whether to benefit an alien, who they think is either twice as valuable as a hum... (read more)
You're assuming they will definitely have a human experience (e.g. because they are human) and so switch to benefitting non-humans. If you're assuming that, but not allowing them to assume that themselves, then they're being exploited through asymmetric information or their priors not matching the situation at hand, not necessarily irrationality.
If they assume they're human, then they can pin to what they'd expect to experience and believe as a human (even if they haven't experienced it yet themself), and then they'd just prioritize non-humans from the start and never switch.
But you can instead assume it's actually 50-50 whether you end up as a human or an alien, and you have these two options:
1. at an extra cost of 1 penny, get the human experience, or get the alien experience, 50% probability each, pin to it, and help the other beings.
2. at no extra cost, flip a coin, with heads for helping humans and tails for helping aliens, and then commit to following through on that, regardless of whether you end up having human experience or alien experience.
I think there's a question of which is actually better. Does 2 stochastically dominate 1? You find something out in 1, and then help the beings you will come to believe it's best to help (although this doesn't seem like a proper Bayesian update from a prior). In 2, if you end up pinning to your own experience, you'll regret prioritizing humans if your experience is human, and you'll regret prioritizing aliens if your experience is alien.
See also this comment and this thread.
One important difference is that we're never in this situation if and because we've already committed to human-based units, so there's no risk of such a money pump or such irrational behaviour.
And there's good reason for this. We have direct access to our own experiences, and understand, study and conceptualize consciousness, suffering, desires, preferences and other kinds of welfare in reference to our own and via conservative projections, e.g. assuming typical humans are similar to each other.
To be in the kind of position this thought experiment requires... (read more)
Granted, it is a bit weird.
I think it is helpful to work this argument out within a Bayesian framework. Doing so will require thinking in some ways that I'm not completely comfortable with (e.g. having a prior over how much pain hurts for humans), but I think formal regimentation reveals aspects of the situation that make the conclusion easier to swallow.
In order to represent yourself as learning how good human experiences are and incorporating that information into your evidence, you will need to assign priors that allow for each possible value human experiences might have. You will also need to have priors for each possible value alien experiences might have. To make your predictable loss argument go through, you will still need to treat alien experiences as either half as good or twice as good with equal probabilities no matter how good human experiences turn out to be. (Otherwise, your predictable loss argument needs to account for what the particular experience you feel tells you about the probabilities that the alien's experiences are higher or lower, this can give you evidence that contradicts the assumption that the alien's value is equally likely to be half or twice.) This isn't straightforwardly easy. If you think that human experience might be either worth N or N/2 and you think alien experience might be either N/2 or N, then learning that human experience is N will tell you that the alien experience is worth N/2.
There are a few ways to set up the priors to get the conclusion that you should favor the alien after learning how good human experience is (no matter how good that is). One way is to assume off the bat that aliens are likely to have a higher probability of higher experiential values. Suppose, to simplify things a bit, you thought that the highest value of experience an human could have is N. (More realistically, the values should trail off with ever lower probabilities, but the basic point I'm making would still go through -- alien's possi
Many posts this week reference RP's work on moral weights, which came to the surprising-to-most "Equality Result": chicken experiences are roughly as valuable as human experiences.
I thought that post used the "equality result" as a hypothetical and didn't claim it was correct.
When first introduced:
Suppose that these assumptions lead to the conclusion that chickens and humans can realize roughly the same amount of welfare at any given time. Call this “the Equality Result.” The key question: Would the Equality Result alone be a good reason to think that one
The main question that remains for me (only paranthetically alluded to in my above comment) is:
Do we get something that deserves to be called an "anthropic shadow" for any particular, more narrow choice of "reference class", and...
can the original proposes of an "anthropic shadow" be read as proposing that we should work with such reference classes?
I think the answer to the first question is probably "yes" if we look at a reference class that changes over time, something like R_t = "people alive at period t of developme... (read more)
Ok great!
And ok, I agree that the answer to the first question is probably "yes", so maybe what I was calling an alternative anthropic principle in my original comment could be framed as SSA with this directly time-centric reference class. If so, instead of saying "that's not SSA", I should have said "that's not SSA with a standard reference class (or a reference class anyone seems to have argued for)". I agree that Bostrom et al. (2010) don't seem to argue for such a reference class.
On my reading (and Teru's, not coincidentally), the core insight Bostrom et al. have (and iterate on) is equivalent to the insight that if you haven't observed something before, and you assign it a probability per unit of time equal to its past frequency, then you must be underestimating its probability per unit of time. The response isn't that this is predicated on, or arguing for, any weird view on anthropics, but just that it has nothing to do with anthropics: it's true, but for the same reason that you’ll underestimate the probability of rain per unit time based on past frequency if it's never rained (though in the prose they convey their impression that the fact that you wouldn't exist in the event of a catastrophe is what's driving the insight). The right thing to do in both cases is to have a prior and update the probability downward as the dry spell lengthens. A nonstandard anthropic principle (or reference class) is just what would be necessary to motivate a fundamental difference from "no rain".
Under typical decision theory, your decisions are a product of your beliefs and by the utilities that you assign to different outcomes. In order to argue that Jack and Jill ought to be making different decisions here, it seems that you must either:
Dispute the paper's claim that Jack and Jill ought to assign the same probabilities in the above type of situations.
Be arguing that Jack and Jill ought to be making their decisions differently despite having identical preferences about the next round and identical beliefs about the likelihood that a ball will tur
I thought about it more, and I am now convinced that the paper is right (at least in the specific example I proposed).
The thing I didn't get at first is that given a certain prior over P(extinction), and a number of iterations survived, there are "more surviving worlds" where the actual P(extinction) is low relative to your initial prior, and that this is exactly accounted for by the Bayes factor.
I also wrote a script that simulates the example I proposed, and am convinced that the naive Bayes approach does in fact give the best strategy in Jack's case too (I haven't proved that there isn't a counterexample, but was convinced by fiddling with the parameters around the boundary of cases where always-option-1 dominates vs always-option-2).
Thanks, this has actually updated me a lot :)
Anthropic shadow effects are one of the topics discussed loosely in social settings among EAs (and in general open-minded nerdy people), often in a way that assumes the validity of the concept
FWIW, I think it's rarely a good idea to assume the validity of anything where anthropics plays an important role. Or decision theory (c.f. this). These are very much not settled areas.
This sometimes even applies when it's not obvious that anthropics is being invoked. I think Dissolving the Fermi Paradox and Grabby aliens both rely on pretty strong assumption about an... (read more)
Oh, also, re the original paper, I do think that even given SSA, Teru's argument that Jack and Jill have equivalent epistemic perspectives is correct. (Importantly: As long as Jack and Jill uses the same SSA reference classes, and those reference classes don't treat Jack and Jill any differently.)
Since the core mechanism in my above comment is the correlation between x2 and the total number of observers, I think Jill the Martian would also arrive at different Pr(A) depending on whether she was using SSA or SIA.
(But Teru doesn't need to get into any o... (read more)
But this example relies on there just being one planet. If there are >1 planets, each with two periods, we are back to having an anthropic shadow again.
Let's consider the case with 2 planets. Let's call them x and y.
According to SSA:
Given A, there are 4 different possibilities, each with probability 1/4:
No catastrophe on either planet.
Catastrophe on x.
Catastrophe on y.
Catastrophe on both.
Let's say you observe yourself to be alive at time-step 2 on planet x.
Interesting, thanks for pointing this out! And just to note, that result doesn’t rely on any sort of suspicious knowledge about whether you’re on the planet labeled “x” or “y”; one could also just say “given that you observe that you’re in period 2, …”.
I don’t think it’s right to describe what’s going on here as anthropic shadow though, for the following reason. Let me know what you think.
To make the math easier, let me do what perhaps I should have done from the beginning and have A be the event that the risk is 50% and B be the event that it’s 0%. So in the one-planet case, there are 3 possible worlds:
* A1 (prior probability 25%) -- risk is 50%, lasts one period
* A2 (prior probability 25%) -- risk is 50%, lasts two periods
* B (prior probability 50%) -- risk is 0%, lasts two periods
At time 1, whereas SIA tells us to put credence of 1/2 on A, SSA tells us to put something higher--
(0.25 + 0.25/2) / (0.25 + 0.25/2 + 0.5/2) = 3/5
--because a higher fraction of expected observers are at period 1 given A than given B. This is the Doomsday Argument. When we reach period 2, both SSA and SIA then tell us to update our credence in A downward. Both principles tell us fully to update downward for the same reasons that we would update downward on the probability of an event that didn’t change the number of observers: e.g. if A is the event you live in a place where the probability of rain per day is 50% and B is the event that it’s 0%; you start out putting credence 50% [or 60%] on A; and you make it to day 2 without rain (and would live to see day 2 either way). But in the catastrophe case SSA further has you update downward because the Doomsday Argument stops applying in period 2.
One way to put the general lesson is that, as time goes on and you learn how many observers there are, SSA has less room to shift probability mass (relative to SIA) toward the worlds where there are fewer observers.
* In the case above, once you make it to period 2, that uncertain
4
Lukas Finnveden
Oh, also, re the original paper, I do think that even given SSA, Teru's argument that Jack and Jill have equivalent epistemic perspectives is correct. (Importantly: As long as Jack and Jill uses the same SSA reference classes, and those reference classes don't treat Jack and Jill any differently.)
Since the core mechanism in my above comment is the correlation between x2 and the total number of observers, I think Jill the Martian would also arrive at different Pr(A) depending on whether she was using SSA or SIA.
(But Teru doesn't need to get into any of this, because he effectively rejects SSA towards the end of the section "Barking Dog vs The Martians" (p12-14 of the pdf). Referring to his previous paper Doomsday and objective chances.)
The program launched in 2021 and became widespread on X in 2023. Initially shown to U.S. users only, notes were popularized in March 2022 over misinformation in the Russian invasion of Ukraine followed by COVID-19 misinformation in October. Birdwatch was then rebranded to Community Notes and expanded in November 2022.
Elon bought Twitter in October 2022, after the program had already been online for ... (read more)
That's not right: You listed these people as special guests — many of them didn't do a talk. Importantly, Hanania didn't. (According to the schedule.)
I just noticed this. And it makes me feel like "if someone rudely seeks out controversy, don't list them as a special guest" is such a big improvement over the status quo.
Hanania was already not a speaker. (And Nathan Young suggests that last year, this was partly a conscious decision rather than him not just feeling like he wanted to give
Indeed, I spoke loosely and the sentence would have been more accurate if I had replaced "57 speakers" with "57 special guests", for which I apologize. I don't consider this to be a major distinction, however, and have used these terms fairly interchangeably throughout event planning. It's a quirk of how we run Manifest, where there are many blurry boundaries.
Most, but not all of our "special guests" presented a session[1]. Not all of the sessions were presented by special guests: Manifest allowed any attendee to book a room to run a talk/session/workshop/event of their choice (though, we the organizers did arrange many of the largest sessions ourselves.) Most special guests did not receive housing or travel assistance; I think we provided this to 10-15 of them. Not all of our special guests even received complimentary tickets: some, such as Eliezer, Katja, Nate and Sarah, paid for their tickets before we reached out to them; we're very grateful for this! And we also issued complimentary tickets to many folks, without listing them as special guests.
What is true about all our special guests is that we chose them for being notable people, who we imagined our attendees would like to meet. They were listed on our website and received a differently-colored badge. They were also all offered a spot at a special (off campus) dinner on Saturday night, in addition to those who bought supporter tickets.
1. ^
Off the top of my head, these special guests did not give talks: Eliezer Yudkowsky, Katja Grace, Joe Carlsmith, Clara Collier, Max Tabarrok, Sarah Constantin, Rob Miles, Richard Hanania, Nate Soares
It's just a symbolic gesture of "we think this person is cool, and we think that you should choose whether to go to our event partly based on whether you also think this person is cool".
My guess is that "special guest" status meant more than that. Special guests likely received a free ticket, worth $500.
It's also possible that special guests might have gotten travel or lodging subsidies in one form or another (e.g. free lodging at Lightcone). This is a guess, I don't know how common it is in general for billed guests at conferences to fund their own lodgin... (read more)
Positive argument in favor of humans: It seems pretty likely that whatever I'd value on-reflection will be represented in a human future, since I'm a human. (And accordingly, I'm similar to many other humans along many dimensions.)
If AI values where sampled ~randomly (whatever that means), I think that the above argument would be basically enough to carry the day in favor of humans.
But here's a salient positive argument in favor of why AIs' values will be similar to mine: People will be training AIs to be nice and helpful, which
There might not be any real disagreement. I'm just saying that there's no direct conflict between "present people having material wealth beyond what they could possibly spend on themselves" and "virtually all resources are used in the way that totalist axiologies would recommend".
What's the argument for why an AI future will create lots of value by total utilitarian lights?
At least for hedonistic total utilitarianism, I expect that a large majority of expected-hedonistic-value (from our current epistemic state) will be created by people who are at least partially sympathetic to hedonistic utilitarianism or other value systems that value a similar type of happiness in a scope-sensitive fashion. And I'd guess that humans are more likely to have such values than AI systems. (At least conditional on my thinking that such values are a g... (read more)
We can similarly ask, "Why would an em future create lots of value by total utilitarian lights?" The answer I'd give is: it would happen for essentially the same reasons biological humans might do such a thing. For example, some biological humans are utilitarians. But some ems might be utilitarians too. Therefore, both could create lots of value by total utilitarian lights.
In order to claim that ems have a significantly lower chance of creating lots of value by total utilitarian lights than biological humans, you'd need to posit a distinction between ems and biological humans that makes this possibility plausible. Some candidate distinctions, such as the idea that ems would not be conscious because they're on a computer, seem implausible in any way that could imply the conclusion. So, at least as far as I can tell, I cannot identify any such distinction; and thus, ems seem similarly likely to create lots of value by total utilitarian lights, compared to biological humans.
The exact same analysis can likewise be carried over to the case for AIs. Some biological humans are utilitarians, but some AIs might be utilitarians too. Therefore, both could create lots of value by total utilitarian lights.
In order to claim that AIs have a significantly lower chance of creating lots of value by total utilitarian lights than biological humans, you'd need to posit a distinction between AIs and biological humans that makes this possibility plausible. A number of candidate distinctions have been given to me in the past. These include:
1. The idea that AIs will not be conscious
2. The idea that AIs will care less about optimizing for extreme states of moral value
3. The idea that AIs will care more about optimizing imperfectly specified utility functions, which won't produce much utilitarian moral value
In each case I generally find that the candidate distinction is either poorly supported, or it does not provide strong support for the conclusion. So, just as with ems, I fi
I find it plausible that future humans will choose to create much fewer minds than they could. But I don't think that "selfishly desiring high material welfare" will require this. Just the milky way has enough stars for each currently alive human to get an entire solar system each. Simultaneously, intergalactic colonization is probably possible (see here) and I think the stars in our own galaxy is less than 1-in-a-billion of all reachable stars. (Most of which are also very far away, which further contributes to them not being very interesting to use for s... (read more)
Good point re aesthetics perhaps mattering more, and about people dis-valuing inequality and therefore not wanting to create a lot of moderately good lives lest they feel bad about having amazing lives and controlling vast amounts of resources.
Re "But I don't think ..." in your first paragraph, I am not sure what if anything we actually disagree about. I think what you are saying is that there are plenty of resources in our galaxy, and far more beyond, for all present people to have fairly arbitrarily large levels of wealth. I agree, and I am also saying that people may want to keep it roughly that way, rather than creating heaps of people and crowding up the universe.
2
Ryan Greenblatt
Another relevant consideration along these lines is that people who selfishly desire high wealth might mostly care about positional goods which are similar to current positional goods. Usage of these positional goods won't burn much of any compute (resources for potential minds) even if these positional goods become insanely valuable in terms of compute. E.g., land values of interesting places on earth might be insanely high and people might trade vast amounts of comptuation for this land, but ultimately, the computation will be spent on something else.
I'll hopefully soon make a follow-up post with somewhat more concrete projects that I think could be good. That might be helpful.
Are you more concerned that research won't have any important implications for anyone's actions, or that the people whose decisions ought to change as a result won't care about the research?
Similary, 'Politics is the Mind-Killer' might be the rationalist idea that has aged worst - especially for its influences on EA.
What influence are you thinking about? The position argued in the essay seems pretty measured.
Politics is an important domain to which we should individually apply our rationality—but it’s a terrible domain in which to learn rationality, or discuss rationality, unless all the discussants are already rational. [...]
I’m not saying that I think we should be apolitical, or even that we should adopt Wikipedia’s ideal of the Neu
I'm relying on my social experience and intuition here, so I don't expect I've got it 100% right, and others may indeed have different interpretations of the community's history with engaging with politics.
But concern about people over-extrapolating from Eliezer's initial post (many such cases) and treating it more of a norm to ignore politics full-stop seems to have been an established concern many years ago (related discussion here). I think that there's probably an interaction effect with the 'latent libertarianism' in early LessWrong/Rationalist space ... (read more)
Not sure I agree. Brian Tomasik's post is less a general argument against the approach of EV maximization but more a demonstration of its misapplication in a context where expectation is computed across two distinct distributions of utility functions. As an aside, I also don't see the relation between the primary argument being made there and the two-envelopes problem because the latter can be resolved by identifying a very clear mathematical flaw in the claim (that switching is better).
One interesting contrast with the conclusion in this post is that Dybul thinks that PEPFAR's success was a direct consequence of how it didn't involve too many people and departments early on — because the negotiations would have been too drawn out and too many parties would have tried to get pieces of control. So maybe a transparent process that embraced complexity wouldn't have achieved much, in practice.
Thanks for sharing - it’s an interesting interview. My first reaction is that interdepartmental bureaucracy is quite a different beast to an evidence-to-policy process. I agree that splitting development policy/programmes across multiple government depts causes lots of problems and is generally to be avoided if possible (I’m thinking about the UK system but imagine the challenges are similar in the US and elsewhere).
Of course you do need some bureaucracy to facilitate evidence-to-policy too, but on the whole I think it’s absolutely worth the time. For public policy we should aim to make a small number of decisions really well. The idea a small efficient group who just know what to do and crack on is appealing; it’s a more heroic narrative than a careful weighing of the evidence. Though I can’t imagine the users of this forum need persuading of the importance of using evidence to do better than our intuitions and overcome our biases.
Incidentally, I feel this kind of we-know-what-to-do-let’s-crack-on instinct is more acceptable in development policy than domestic, and in my view development policy would benefit from being much more considered. We cause a lot of chaos and harm to systems in LMICs in the way we offer development assistance, even through programmes that are supporting valuable services. I think all of the major GHI’s do great work, but all could benefit from substantial reforms. Though again, this is somewhat separate from the point about interdepartmental bureaucracy.
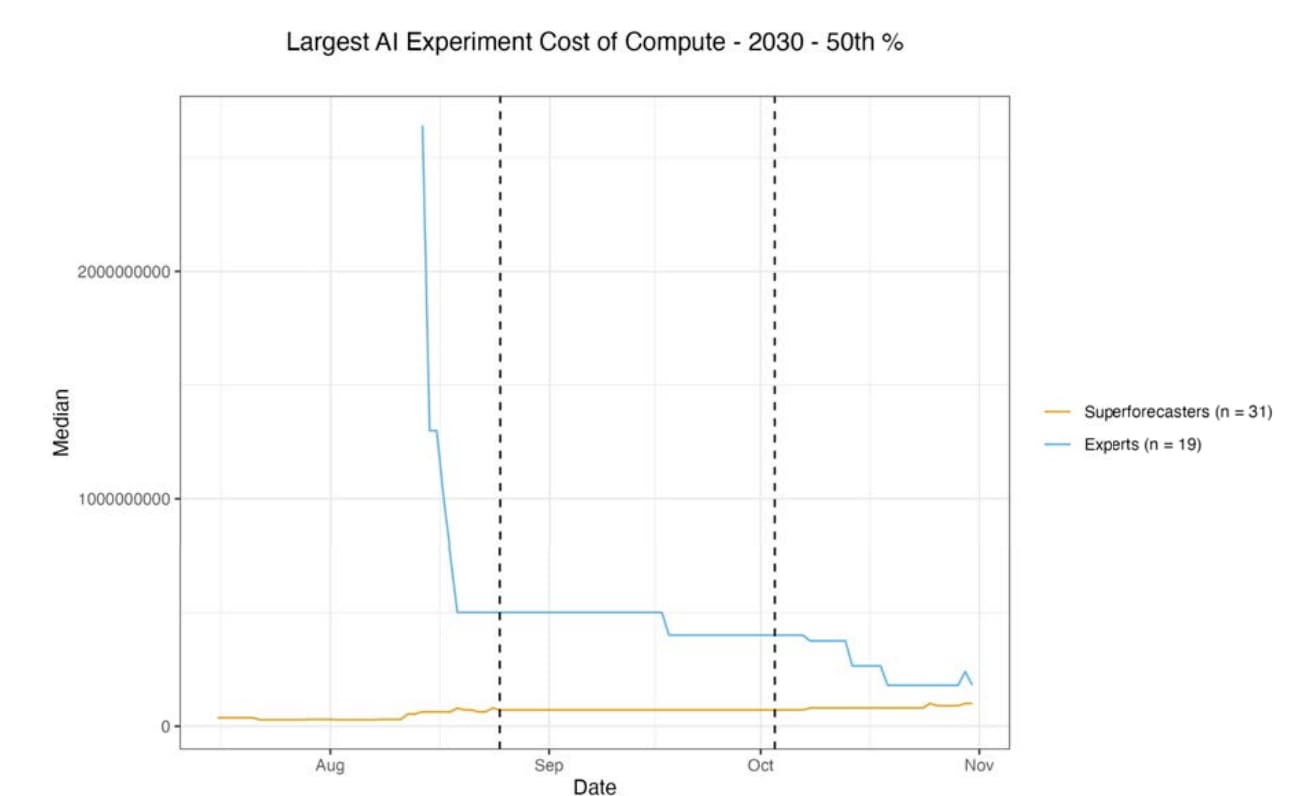
FWIW you can see more information, including some of the reasoning, on page 655 (# written on pdf) / 659 (# according to page searcher) of the report. (H/t Isabel.) See also page 214 for the definition of the question.
Some tidbits:
Experts started out much higher than superforecasters, but updated downwards after discussion. Superforecasters updated a bit upward, but less:
(Those are billions on the y-axis.)
This was surprising to me. I think the experts' predictions look too low even before updating, and look much worse after updating!
Thanks!
I think this is evidence for a groupthink phenomenon amongst superforecasters. Interestingly my other experiences talking with superforecasters have also made me update in this direction (they seemed much more groupthinky than I expected, as if they were deferring to each other a lot. Which, come to think of it, makes perfect sense -- I imagine if I were participating in forecasting tournaments, I'd gradually learn to reflexively defer to superforecasters too, since they genuinely would be performing well.)
It's the crux between you and Ajeya, because you're relatively more in agreement on the other numbers. But I think that adopting the xpt numbers on these other variables would slow down your own timelines notably, because of the almost complete lack of increase in spending.
That said, if the forecasters agreed with your compute requirements, they would probably also forecast higher spending.
The XPT forecasters are so in the dark about compute spending that I just pretend they gave more reasonable numbers. I'm honestly baffled how they could be so bad. The most aggressive of them thinks that in 2025 the most expensive training run will be $70M, and that it'll take 6+ years to double thereafter, so that in 2032 we'll have reached $140M training run spending... do these people have any idea how much GPT-4 cost in 2022?!?!? Did they not hear about the investments Microsoft has been making in OpenAI? And remember that's what the most aggressive among them thought! The conservatives seem to be living in an alternate reality where GPT-3 proved that scaling doesn't work and an AI winter set in in 2020.
in terms of saving “disability-adjusted life years” or DALYs, "a case of HIV/AIDS can be prevented for $11, and a DALY gained for $1” by improving the safety of blood transfusions and distributing condoms
These numbers are wild compared to eg current givewell numbers. My guess would be that they're wrong, and if so, that this was a big part of why PEPFAR did comparatively better then expected. Or maybe that they were significantly less scalable (measured in cost of marginal life saved as a function of lives saved so far) than PEPFAR.
Incidentally, as its central estimate for algorithmic improvement, the takeoff speeds model uses AI and Efficiency's ~1.7x per year, and then halves it to ~1.3x per year (because todays' algorithmic progress might not generalize to TAI). If you're at 2x per year, then you should maybe increase the "returns to software" from 1.25 to ~3.5, which would cut the model's timelines by something like 3 years. (More on longer timelines, less on shorter timelines.)
Yeah sorry, I didn't mean to say this directly contradicted anything you said. It just felt like a good reference that might be helpful to you or other people reading the thread. (In retrospect, I should have said that and/or linked it in response to the mention in your top-level comment instead.)
(Also, personally, I do care about how much effort and selection is required to find good retrodictions like this, so in my book "I didn't look up the data on Google beforehand" is relevant info. But it would have been way more impressive if someone had been able ... (read more)
Sorry, that was very poor wording. I meant that 2023 FLOP is probably about equal to 2 2022 FLOP, due to continued algorithmic progress. I'll reword the comment you replied to.
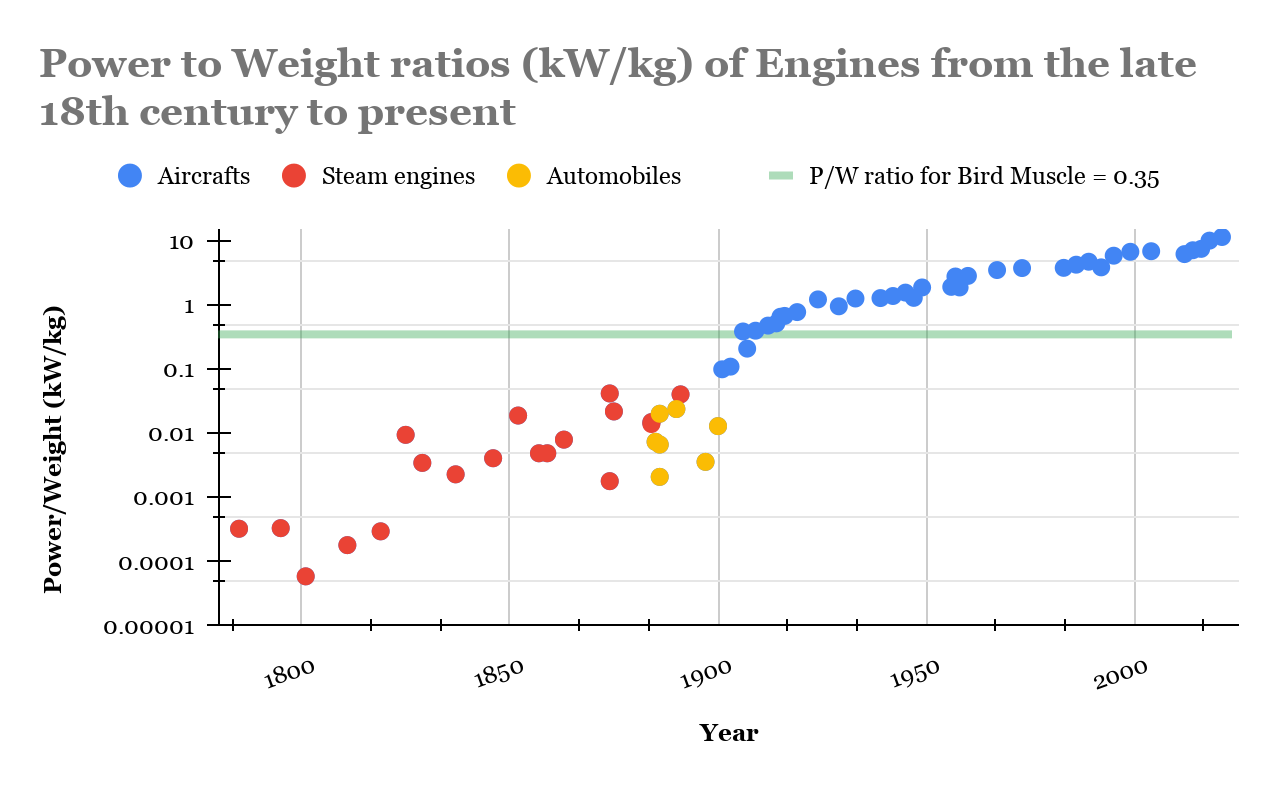
And, as I think Eliezer said (roughly), there don't seem to be many cases where new tech was predicted based on when some low-level metric would exceed the analogous metric in a biological system. [...] And the way in which machines perform tasks usually looks very different than how biological systems do it (bird vs. airplanes, etc.).
This data shows that Shorty [hypothetical character introduced earlier in the post] was entirely correct about forecasting heavier-than-air flight. (For details about the data, see appendix.
I listed this example in my comment, it was incorrect by an order of magnitude, and it was a retrodiction. "I didn't look up the data on Google beforehand" does not make it a prediction.
I think my biggest disagreement with the takeoff speeds model is just that it's conditional on things like: no coordinated delays, regulation, or exogenous events like war, and doesn't take into account model uncertainty.
Cool, I thought that was most of the explanation for the difference in the median. But I thought it shouldn't be enough to explain the 14x difference between 28% and 2% by 2030, because I think there should be a ≥20% chance that there are no significant coordinated delays, regulation, or relevant exogenous events if AI goes wild in the nex... (read more)
Update: I changed the probability distribution in the post slightly in line with your criticism. The new distribution is almost exactly the same, except that I think it portrays a more realistic picture of short timelines. The p(TAI < 2030) is now 5% [eta: now 18%], rather than 2%.
4
Matthew_Barnett
That's reasonable. I think I probably should have put more like 3-6% credence before 2030. I should note that it's a bit difficult to tune the Metaculus distributions to produce exactly what you want, and the distribution shouldn't be seen as an exact representation of my beliefs.
My own distribution over the training FLOP for transformative AI is centered around ~10^32 FLOP using 2023 algorithms, with a standard deviation of about 3 OOM.
Thanks for the numbers!
For comparison, takeoffspeeds.com has an aggressive monte-carlo (with a median of 10^31 training FLOP) that yields a median of 2033.7 for 100% automation — and a p(TAI < 2030) of ~28%. That 28% is pretty radically different from your 2%. Do you know your biggest disagreements with that model?
The 1 OOM difference in training FLOP presumably doesn't explain that much. (Althou... (read more)
I think my biggest disagreement with the takeoff speeds model is just that it's conditional on things like: no coordinated delays, regulation, or exogenous events like war, and doesn't take into account model uncertainty. My other big argument here is that I just think robots aren't very impressive right now, and it's hard to see them going from being unimpressive to extremely impressive in just a few short years. 2030 is very soon. Imagining a even a ~4 year delay due to all of these factors produces a very different distribution.
Also, as you note, "takeoffspeeds.com talks about "AGI" and you talk about "TAI". I think transformative AI is a lower bar than 100% automation. The model itself says they added "an extra OOM to account for TAI being a lower bar than full automation (AGI)." Notably, if you put in 10^33 2022 FLOP into the takeoff model (and keep in mind that I was talking about 2023 FLOP), it produces a median year of >30% GWP growth of about 2032, which isn't too far from what I said in the post:
I added about four years to this 2032 timeline due to robots, which I think is reasonable even given your considerations about how we don't have to automate everything -- we just need to automate the bottlenecks to producing more semiconductor fabs. But you could be right that I'm still being too conservative.
Of the remaining 5 %, around 70 % would eventually be reached by other civilisations, while 30 % would have remained empty in our absence.
I think the 70%/30% numbers are the relevant ones for comparing human colonization vs. extinction vs. misaligned AGI colonization. (Since 5% cuts the importance of everything equally.)
...assuming defensive dominance in space, where you get to keep space that you acquire first. I don't know what happens without that.
This would suggest that if we're indifferent between space being totally uncoloni... (read more)
If AGI systems had goals that were cleanly separated from the rest of their cognition, such that they could learn and self-improve without risking any value drift (as long as the values-file wasn't modified), then there's a straightforward argument that you could stabilise and preserve that system's goals by just storing the values-file with enough redundancy and digital error correction.
So this would make section 6 mostly irrelevant. But I think most other sections remain relevant, insofar as people weren't already convinced that being able to build stabl... (read more)
I really like the proposed calibration game! One thing I'm curious about is whether real-world evidence more often looks like a likelihood ratio or like something else (e.g. pointing towards a specific probability being correct). Maybe you could see this from the structure of priors+likelihoodratios+posteriors in the calibration game — e.g. check whether the long-run top-scorers likelihood ratios correlated more or less than their posterior probabilities.
(If someone wanted to build this: one option would be to start with pastcasting and then give archived ... (read more)
Depends on how much of their data they'd have to back up like this. If every bit ever produced or operated on instead had to be be 25 bits — that seems like a big fitness hit. But if they're only this paranoid about a few crucial files (e.g. the minds of a few decision-makers), then that's cheap.
And there's another question about how much stability contributes to fitness. In humans, cancer tends to not be great for fitness. Analogously, it's possible that most random errors in future civilizations would look less like slowly corrupting values and more like... (read more)
This is a great question. I think the answer depends on the type of storage you're doing.
If you have a totally static lump of data that you want to encode in a harddrive and not touch for a billion years, I think the challenge is mostly in designing a type of storage unit that won't age. Digital error correction won't help if your whole magnetism-based harddrive loses its magnetism. I'm not sure how hard this is.
But I think more realistically, you want to use a type of hardware that you regularly use, regularly service, and where you can copy the informati... (read more)
Cool, thanks for thinking this through!
This is super speculative of course, but if the future involves competition between different civilizations / value systems, do you think having to devote say 96% (i.e. 24/25) of a civilization's storage capacity to redundancy would significantly weaken its fitness? I guess it would depend on what fraction of total resources are spent on information storage...?
Also, by the same token, even if there is a "singleton" at some relatively early time, mightn't it prefer to take on a non-negligible risk of value drift later in time if it means being able to, say, 10x its effective storage capacity in the meantime?
(I know your 24/25 was a conservative estimate in some ways; on the other hand it only addresses the first billion years, which is arguably only a small fraction of the possible future, so hopefully it's not too biased a number to anchor on!)
I'm not sure how literally you mean "disprove", but at it's face, "assume nothing is related to anything until you have proven otherwise" is a reasoning procedure that will never recommend any action in the real world, because we never get that kind of certainty. When humans try to achieve results in the real world, heuristics, informal arguments, and looking at what seems to have worked ok in the past are unavoidable.
I am talking about math. In math, we can at least demonstrate things for certain (and prove things for certain, too, though that is admittedly not what I am talking about).
But the point is that we should at least be to bust out our calculators and crunch the numbers. We might not know if these numbers apply to the real world. That's fine. But at least we have the numbers. And that counts for something.
For example, we can know roughly how much wealth SBF was gambling. We can give that a range. We also can estimate how much risk he was taking on. We can give that a range too. Then we can calculate if the risk he took on had net positive expected value in expectation
It's possible that it has expected value in expectation, only above a certain level of risk, or whatever. Perhaps we do not know whether he faced this risk. That is fine. But we can still at any rate see in under what circumstances SBF would have been rational, acting on utilitarian grounds, to do what he did.
If these circumstances sound like do or could describe the circumstances that SBF was in earlier this week, then that should give us reason to pause.
Global poverty probably have slower diminishing marginal returns, yeah. Unsure about animal welfare. I was mostly thinking about longtermist causes.
Re 80,000 Hours: I don't know exactly what they've argued, but I think "very valuable" is compatible with logarithmic returns. There are also diminishing marginal returns to direct workers in any given cause, so logarithmic returns on money doesn't mean that money becomes unimportant compared to people, or anything like that.
(I didn't vote on your comment.)
Here's Ben Todd's post on the topic from last November:
Despite billions of extra funding, small donors can still have a significant impact
I'd especially recommend this part from section 1:
So he thought the marginal cost-effectiveness hadn't changed much while funding had dramatically increased within longtermism over these years. I suppose it's possible marginal returns diminish quickly within each year, even if funding is growing quickly over time, though, as long as the capacity to absorb funds at similar cost-effectiveness grows with it.
Personally, I'd guess funding students' university programs is much less cost-effective on the margin, because of the distribution of research talent, students should already be fully funded if they have a decent shot of contributing, the best researchers will already be fully funded without many non-research duties (like being a teaching assistant), and other promising researchers can get internships at AI labs both for valuable experience (80,000 Hours recommends this as a career path!) and to cover their expenses.
I also got the impression that the Future Fund's bar was much lower, but I think this was after Ben Todd's post.
Because utility and integrity are wholly independent variables, so there is no reason for us to assume a priori that they will always correlate perfectly. So if we wish to believe that integrity and expected value correlated for SBF, then we must show it. We must actually do the math.
This feels a bit unfair when people (i) have argued that utility and integrity will correlate strongly in practical cases (why use "perfectly" as your bar?), and (ii) that they will do so in ways that will be easy to underestimate if you just "do the math".
Utility and integrity coming apart, and in particular deception for gain, is one of the central concerns of AI safety. Shouldn't we similarly be worried at the extremes even in human consequentialists?
It is somewhat disanalogous, though, because
1. We don't expect one small group of humans to have so much power without the need to cooperate with others, like might be the case for an AGI taking over. Furthermore, the FTX/Alameda leaders had goals that were fairly aligned with a much larger community (the EA community), whose work they've just made harder.
2. Humans tend to inherently value integrity, including consequentialists. However, this could actually be a bias among consequentialists that consequentialists should seek to abandon, if we think integrity and utility should come apart at the extremes and we should go for the extremes.
3. (EDIT) Humans are more limited cognitively than AGIs, and are less likely to identify net positive deceptive acts and more likely to identify net negative one than AGIs.
EDIT: On the other hand, maybe we shouldn't trust utilitarians with AGIs aligned with their own values, either.
2[anonymous]
Assuming zero correlation between two variables is standard practice. Because for any given set of two variables, it is very likely that they do not correlate. Anyone that wants to disagree must crunch the numbers and disprove it. That's just how math works.
And if we want to treat ethics like math, then we need to actually do some math. We can't have our cake and eat it too
Because a double-or-nothing coin-flip scales; it doesn't stop having high EV when we start dealing with big bucks.
Risky bets aren't themselves objectionable in the way that fraud is, but to just address this point narrowly: Realistic estimates puts risky bets at much worse EV when you control a large fraction of the altruistic pool of money. I think a decent first approximation is that EA's impact scales with the logarithm of its wealth. If you're gambling a small amount of money, that means you should be ~indifferent to 50/50 double or nothing (note th... (read more)
I think marginal returns probably don't diminish nearly as quickly as the logarithm for neartermist cause areas, but maybe that's true for longtermist ones (where FTX/Alameda and associates were disproportionately donating), although my impression is that there's no consensus on this, e.g. 80,000 Hours has been arguing for donations still being very valuable.
(I agree that the downside (damage to the EA community and trust in EAs) is worse than nothing relative to the funds being gambled, but that doesn't really affect the spirit of the argument. It's very easy to underappreciate the downside in practice, though.)
conflicts of interest in grant allocation, work place appointments should be avoided
Worth flagging: Since there are more men than women in EA, I would expect a greater fraction of EA women than EA men to be in relationships with other EAs. (And trying to think of examples off the top of my head supports that theory.) If this is right, the policy "don't appoint people for jobs where they will have conflicts of interest" would systematically disadvantage women.
(By contrast, considering who you're already in a work-relationship with when choosing who to date ... (read more)
Yeah, I agree that multipolar dynamics could prevent lock-in from happening in practice.
I do think that "there is a non-trivial probability that a dominant institution will in fact exist", and also that there's a non-trivial probability that a multipolar scenario will either
(i) end via all relevant actors agreeing to set-up some stable compromise institution(s), or
(ii) itself end up being stable via each actor making themselves stable and their future interactions being very predictable. (E.g. because of an offence-defence balance strongly favoring defence
If re-running evolution requires simulating the weather and if this is computationally too difficult then re-running evolution may not be a viable path to AGI.
There are many things that prevent us from literally rerunning human evolution. The evolution anchor is not a proof that we could do exactly what evolution did, but instead an argument that if something as inefficient as evolution spit out human intelligence with that amount of compute, surely humanity could do it if we had a similar amount of compute. Evolution is very inefficient — it has itself be... (read more)
For instance we might get WBEs only in hypothetical-2080 but get superintelligent LLMs in 2040, and the people using superintelligent LLMs make the world unrecognisably different by 2042 itself.
I definitely don't just want to talk about what happens / what's feasible before the world becomes unrecognisably different. It seems pretty likely to me that lock-in will only become feasible after the world has become extremely strange. (Though this depends a bit on details of how to define "feasible", and what we count as the start-date of lock-in.)
Chaos theory is about systems where tiny deviations in initial conditions cause large deviations in what happens in the future. My impression (though I don't know much about the field) is that, assuming some model of a system (e.g. the weather), you can prove things about how far ahead you can predict the system given some uncertainty (normally about the initial conditions, though uncertainty brought about by limited compute that forces approximations should work similarly). Whether the weather corresponds to any particular model isn't really susceptible to proofs, but that question can be tackled by normal science.
Thus, we suspect that an adequate solution to AI alignment could be achieved given sufficient time and effort. (Though whether that will actually happen is a different question, not addressed since our focus is on feasibility rather than likelihood.)
AI doomers tend to agree with this claim. See e.g. Eliezer in list of lethalities:
None of this is about anything being impossible in principle. The metaphor I usually use is that if a textbook from one hundred years in the future fell into our hands, containing all of the simpl
I'm in favor. Mostly because it seems mildly useful, not because there are very big upsides outweighing big downsides. I don't really see what the downsides would be.