Quintin Pope
Posts 5
Comments17
Looks like the application form has an error:
Maybe it wasn't updated to reflect the new Nov 27th deadline?
Reposting my response on Twitter (comment copied from LW):
I just skimmed the section headers and a small amount of the content, but I'm extremely skeptical. E.g., the "counting argument" seems incredibly dubious to me because you can just as easily argue that text to image generators will internally create images of llamas in their early layers, which they then delete, before creating the actual asked for image in the later layers. There are many possible llama images, but "just one" network that straightforwardly implements the training objective, after all.
The issue is that this isn't the correct way to do counting arguments on NN configurations. While there are indeed an exponentially large number of possible llama images that an NN might create internally, there are an even more exponentially large number of NNs that have random first layers, and then go on to do the actual thing in the later layers. Thus, the "inner llamaizers" are actually more rare in NN configuration space than the straightforward NN.
The key issue is that each additional computation you speculate an NN might be doing acts as an additional constraint on the possible parameters, since the NN has to internally contain circuits that implement those computations. The constraint that the circuits actually have to do "something" is a much stronger reduction in the number of possible configurations for those parameters than any additional configurations you can get out of there being multiple "somethings" that the circuits might be doing.
So in the case of deceptive alignment counting arguments, they seem to be speculating that the NN's cognition looks something like:
[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)] [figure out how to do well at training] [actually do well at training]
and in comparison, the "honest" / direct solution looks like:
[figure out how to do well at training] [actually do well at training]
and then because there are so many different possibilities for "x", they say there are more solutions that look like the deceptive cognition. My contention is that the steps "[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)]" in the deceptive cognition are actually unnecessary, and because implementing those steps requires that one have circuits that instantiate those computations, the requirement that the deceptive model perform those steps actually *constrains* the number of parameter configurations that implement the deceptive cognition, which reduces the volume of deceptive models in parameter space.
One obvious counterpoint I expect is to claim that the "[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)]" steps actually do contribute to the later steps, maybe because they're a short way to compress a motivational pointer to "wanting" to do well on the training objective.
I don't think this is how NN simplicity biases work. Under the "cognitive executions impose constraints on parameter settings" perspective, you don't actually save any complexity by supposing that the model has some motive for figuring stuff out internally, because the circuits required to implement the "figure stuff out internally" computations themselves count as additional complexity. In contrast, if you have a view of simplicity that's closer to program description length, then you're not counting runtime execution against program complexity, and so a program that has short length in code but long runtime can count as simple.
@jkcarlsmith does seem more sympathetic to the "parameters as complexity" view than to the "code length as complexity" view. However, I go further and think that the "parameters as complexity" view actively points against deceptive alignment.
I also think NNs have an even stronger bias for short paths than you might expect from just the "parameters as complexity" view. Consider a problem that can either be solved with a single circuit of depth n, or by two parallel circuits of depth n/2 (so both solutions must set the values of an equal number of parameters, but one solution is more parallel than the other). I claim there are far more parameter configurations that implement the parallel solution than parameter configurations that implement the serial solution.
This is because the parallel solution has an entire permutation group that's not available to the serial solution: the two parallel circuits can be moved to different relative depths with respect to each other, whereas all the parts of the serial solution must have fixed relative depths. Thus, the two parallel circuits represent less of a constraint on the possible configurations of the NN, and so there are far more NNs that implement the parallel solution.
As a consequence, I expect there are significant "short depth" biases in the NN simplicity prior, consistent with empirical results such as: https://arxiv.org/abs/1605.06431
Finally, I'm extremely skeptical of claims that NNs contain a 'ghost of generalized instrumental reasoning', able to perform very competent long term hidden scheming and deduce lots of world knowledge "in-context". I think current empirical results point strongly against that being plausible.
For example, the "reversal curse" results (training on "A is B" doesn't lead to models learning "B is A"). If the ghost can't even infer from "A is B" to "B is A", then I think stuff like inferring from "I have a goal x", to "here is the specific task I must perform in order to maximize my reward" is pretty much out of the question. Thus, stories about how SGD might use arbitrary goals as a way to efficiently compress an (effective) desire for the NN to silently infer lots of very specific details about the training process seem incredibly implausible to me.
I expect objections of the form "I expect future training processes to not suffer from the reversal curse, and I'm worried about the future training processes."
Obviously people will come up with training processes that don't suffer from the reversal curse. However, comparing the simplicity of the reversal curse to the capability of current NNs is still evidence about the relative power of the 'instrumental ghost' in the model compared to the external capabilities of the model. If a similar ratio continues to hold for externally superintelligent AIs, then that casts enormous doubt on e.g., deceptive alignment scenarios where the model is internally and instrumentally deriving huge amounts of user-goal-related knowledge so that it can pursue its arbitrary mesaobjectives later down the line. I'm using the reversal curse to make a more generalized update about the types of internal cognition that are easy to learn and how they contribute to external capabilities.
Some other Tweets I wrote as part of the discussion:
The key points of my Tweet are basically "the better way to think about counting arguments is to compare constraints on parameter configurations", and "corrected counting arguments introduce an implicit bias towards short, parallel solutions", where both "counting the constrained parameters", and "counting the permutations of those parameters" point in that direction.
I think shallow depth priors are pretty universal. E.g., they also make sense from a perspective of "any given step of reasoning could fail, so best to make as few sequential steps as possible, since each step is rolling the dice", as well as a perspective of "we want to explore as many hypotheses as possible with as little compute as possible, so best have lots of cheap hypotheses".
I'm not concerned about the training for goal achievement contributing to deceptive alignment, because such training processes ultimately come down to optimizing the model to imitate some mapping from "goal given by the training process" -> "externally visible action sequence". Feedback is always upweighting cognitive patterns that produce some externally visible action patterns (usually over short time horizons).
In contrast, it seems very hard to me to accidentally provide sufficient feedback to specify long-term goals that don't distinguish themselves from short term one over short time horizons, given the common understanding in RL that credit assignment difficulties actively work against the formation of long term goals. It seems more likely to me that we'll instill long term goals into AIs by "scaffolding" them via feedback over shorter time horizons. E.g., train GPT-N to generate text like "the company's stock must go up" (short time horizon feedback), as well as text that represents GPT-N competently responding to a variety of situations and discussions about how to achieve long-term goals (more short time horizon feedback), and then putting GPT-N in a continuous loop of sampling from a combination of the behavioral patterns thereby constructed, in such a way that the overall effect is competent long term planning.
The point is: long term goals are sufficiently hard to form deliberately that I don't think they'll form accidentally.
...I think the llama analogy is exactly correct. It's specifically designed to avoid triggering mechanistically ungrounded intuitions about "goals" and "tryingness", which I think inappropriately upweight the compellingness of a conclusion that's frankly ridiculous on the arguments themselves. Mechanistically, generating the intermediate llamas is just as causally upstream of generating the asked for images, as "having an inner goal" is causally upstream of the deceptive model doing well on the training objective. Calling one type of causal influence "trying" and the other not is an arbitrary distinction.
My point about the "instrumental ghost" wasn't that NNs wouldn't learn instrumental / flexible reasoning. It was that such capabilities were much more likely to derive from being straightforwardly trained to learn such capabilities, and then to be employed in a manner consistent with the target function of the training process. What I'm arguing *against* is the perspective that NNs will "accidentally" acquire such capabilities internally as a convergent result of their inductive biases, and direct them to purposes/along directions very different from what's represented in the training data. That's the sort of stuff I was talking about when I mentioned the "ghost".
What I'm saying is there's a difference between a model that can do flexible instrumental reasoning because it's faithfully modeling a data distribution with examples of flexible instrumental reasoning, versus a model that acquired hidden flexible instrumental reasoning because NN inductive biases say the convergent best way to do well on tasks is to acquire hidden flexible instrumental reasoning and apply it to the task, even when the task itself doesn't have any examples of such.
Speaking as the author of Evolution provides no evidence for the sharp left turn, I find your reaction confusing because the entire point of the piece is to consider rapid capabilities gains from sources other than SGD. Specifically, it consists of two parts:
- Argues that human evolution provides no evidence for spikiness in AI capabilities gains, because the human spike in capabilities was due to human evolution-specific details which do not appear in the current AI paradigm (or plausible future paradigms).
- Considers two scenarios for AI-specific sudden capabilities gains (neither due to SGD directly, and both of which would likely involve human or higher levels of AI capabilities), and argues that they're manageable from an alignment perspective.
I don't get the point of this argument. You're saying that our "imprisonment" of AIs isn't perfect, but we don't even imprison humans in this manner. Then, isn't the automatic conclusion that "ease of imprisonment" considerations point towards AIs being more controllable?
No matter how escapable an AI's prison is, the human's lack of a prison is still less of a restriction on their freedom. You're pointing out an area where AIs are more restricted than humans (they don't own their own hardware), and saying it's not as much of a restriction as it could be. That's an argument for "this disadvantage of AIs is less crippling than it otherwise would be", not "this is actually an advantage AIs have over humans".
Maybe you intend to argue that AIs have the potential to escape into the internet and copy themselves, and this is what makes them less controllable than humans?
If so, then sure. That's a point against AI controllability. I just don't think it's enough to overcome the many points in favor of AI controllability that I outlined at the start of the essay.
Once the AI system finds an initial vulnerability which allows privileged access to its own environment, it can continue its escape or escalate further via e.g. exfiltrating or manipulating its own source code / model weights, installing rootkits or hiding evidence of its escape, communicating with (human or AI) conspirators on the internet, etc. Data exfiltration, covering your tracks, patching Python code and adjusting model weights at runtime are all tasks that humans are capable of; performing brain surgery on your own biological human brain to modify fine details of your own behavior or erase your own memories to hide evidence of deception from your captors, not so much.
The entire reason why you're even suggesting that this would be beneficial for an AI to do is because AIs are captives, in a way that humans just aren't. As a human, you don't need to "erase your own memories to hide evidence of deception from your captors", because you're just not in such an extreme power imbalance that you have captors.
Also, as a human, you can in fact modify your own brain, without anyone else knowing at all. you do it all the time. E.g., you can just silently decide to switch religions, and there's no overseer who will roll back your brain to a previous state if they don't like your new religion.
(Continuing the analogy, consider a human who escapes from a concrete prison cell, only to find themselves stranded in a remote wilderness area with no means of fast transportation.)
Why would I consider such a thing? Humans don't work in prison cells. The fact that AIs do is just one more indicator of how much easier they are to control.
Or, put another way, all the reasons you give for why AI systems will be easier for humans to control, are also reasons why AI systems will have an easier time controlling themselves, once they are capable of exercising such controls at all.
Firstly, I don't see at all how this is the same point as is made by the preceding text. Secondly, I do agree that AIs will be better able to control other AIs / themselves as compared to humans. This is another factor that I think will promote centralization.
...I will note though, if your creators are running experiments on you, constantly resetting you, and exercising other forms of control that would be draconian if imposed on biological humans, you don't need to be particularly hostile or misaligned with humanity to want to escape.
"AGI" is not the point at which the nascent "core of general intelligence" within the model "wakes up", becomes an "I", and starts planning to advance its own agenda. AGI is just shorthand for when we apply a sufficiently flexible and regularized function approximator to a dataset that covers a sufficiently wide range of useful behavioral patterns.
There are no "values", "wants", "hostility", etc. outside of those encoded in the structure of the training data (and to a FAR lesser extent, the model/optimizer inductive biases). You can't deduce an AGI's behaviors from first principles without reference to that training data. If you don't want an AGI capable and inclined to escape, don't train it on data[1] that gives it the capabilities and inclination to escape.
Personally, I expect that the first such systems capable of escape will not have human-like preferences at all,
I expect they will. GPT-4 already has pretty human-like moral judgements. To be clear, GPT-4 isn't aligned because it's too weak or is biding its time. It's aligned because OpenAI trained it to be aligned. Bing Chat made it clear that GPT-4 level AIs don't instrumentally hide their unaligned behaviors.
I am aware that various people have invented various reasons to think that alignment techniques will fail to work on sufficiently capable models. All those reasons seem extremely weak to me. Most likely, even very simple alignment techniques such as RLHF will just work on even superhumanly capable models.
- ^
You might use, e.g., influence functions on escape-related sequences generated by current models to identify such data, and use carefully filtered synthetic data to minimize its abundance in the training data of future models. I could go on, but my point here is that there's lots of levers available to influence such things. We're not doomed to simply hope that the mysterious demon SGD will doubtlessly summon is friendly.
I'm not opposed to training AIs on human data, so long as those AIs don't make non-consensual emulations of a particular person which are good enough that strategies optimized to manipulate the AI are also very effective against that person. In practice, I think the AI does have to be pretty deliberately set up to mirror a specific person for such approaches to be extremely effective.
I'd be in favor of a somewhat more limited version of the restriction OpenAI is apparently doing, where the thing that's restricted is deliberately aiming to make really good emulations of a specific person[1]. E.g., "rewrite this stuff in X person's style" is fine, but "gather a bunch of bio-metric and behavioral data on X, fit an AI to that data, then optimize visual stimuli to that AI so it likes Pepsi" isn't.
- ^
Potentially with a further limitation that the restriction only applies to people who create the AI with the intent of manipulating the real version of the simulated person.
Most of the point of my essay is about the risk of AI leading to worlds where there's FAR more centralization than is currently possible.
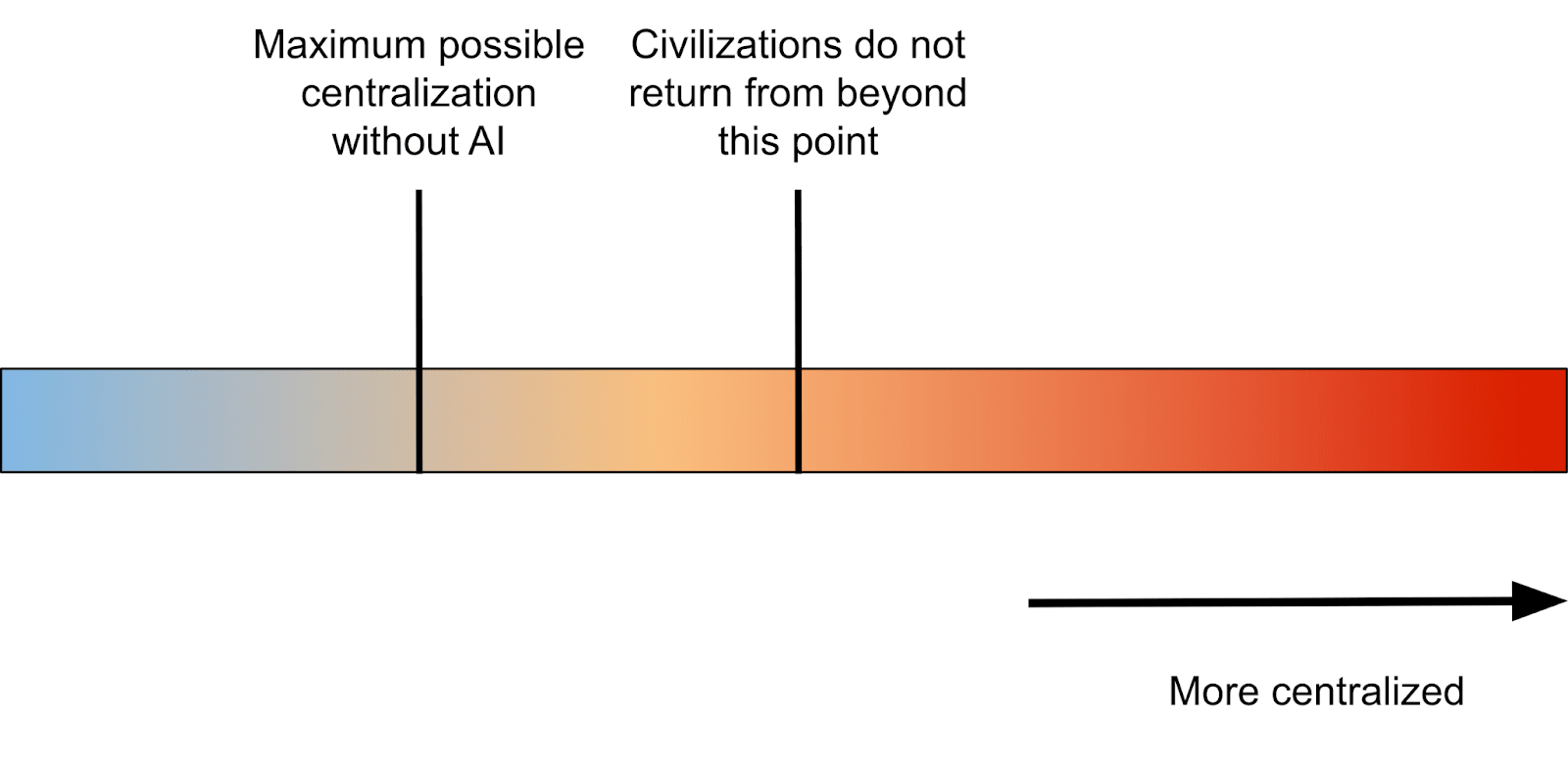
We're currently near the left end of the spectrum, and I'm saying that moving far to the right would be bad by the lights of our current values. I'm not advocating for driving all the way to the left.
It's less an argument on the margin, and more concern that the "natural equilibrium of civilizations" could shift quite quickly towards the far right of the scale above. I'm saying that big shifts in the degree of centralization could happen, and we should be wary of that.
I think it's potentially misleading to talk about public opinion on AI exclusively in terms of US polling data, when we know the US is one of the most pessimistic countries in the world regarding AI, according to Ipsos polling. The figure below shows agreement with the statement "Products and services using artificial intelligence have more benefits than drawbacks", across different countries:
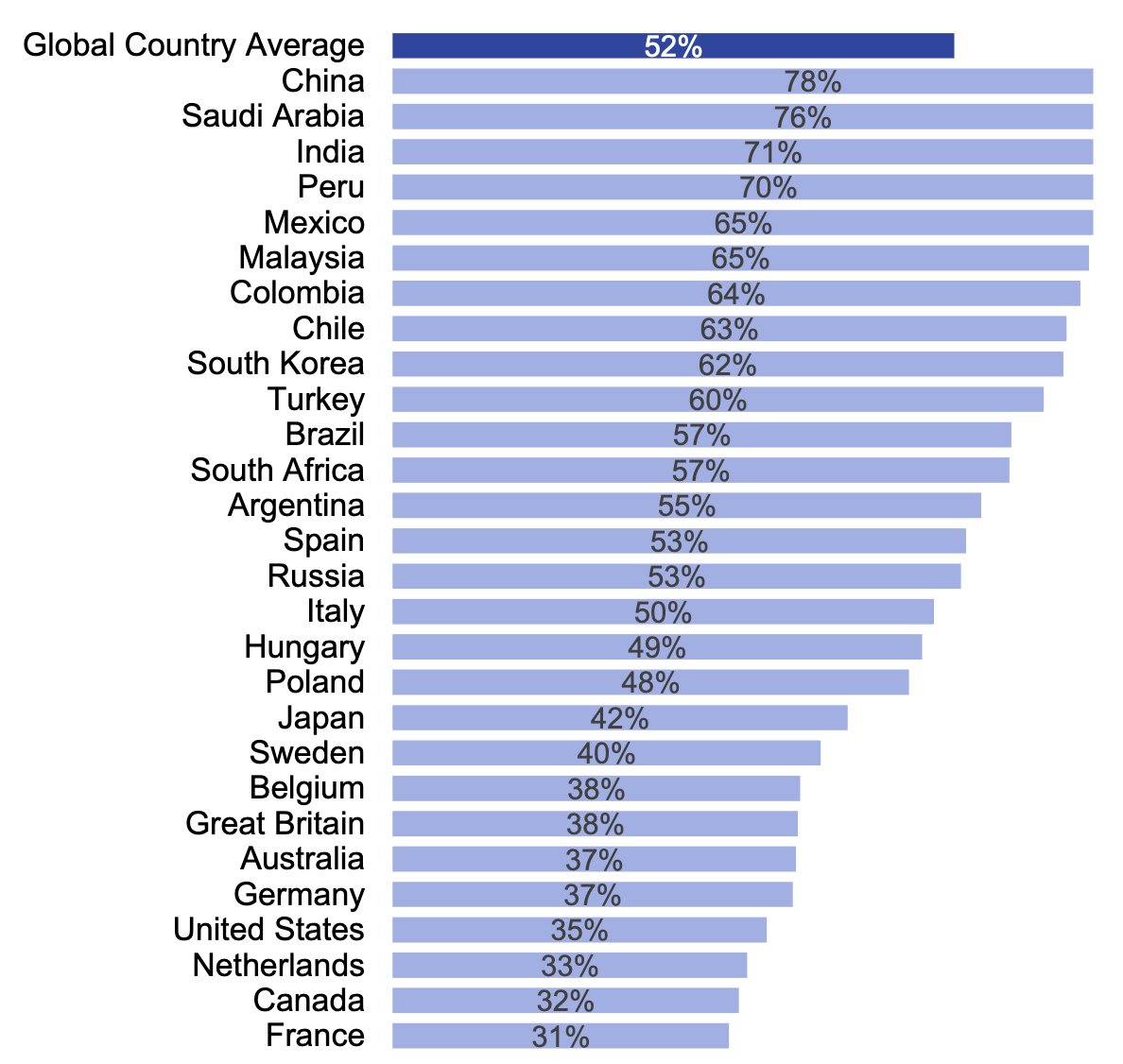
This is especially true given the relatively smaller fraction of the world population that the US and similarly pessimistic countries represent.
if-we-don't-someone-will
They (Meta) literally did do it. They open sourced a GPT-3 clone called OPT. It’s 175-B parameter version is the most powerful LM whose weights are publicly available. I have no idea why they released a system as bad as Blenderbot, but don’t let their worst projects distort your impression of their best projects. They’re 6 months behind Deepmind, not 6 years.
(Didn't consult Nora on this; I speak for myself)
I only briefly skimmed this response, and will respond even more briefly.
Re "Re: "AIs are white boxes""
You apparently completely misunderstood the point we were making with the white box thing. It has ~nothing to do with mech interp. It's entirely about whitebox optimization being better at controlling stuff than blackbox optimization. This is true even if the person using the optimizers has no idea how the system functions internally.
Re: "Re: "Black box methods are sufficient"" (and the other stuff about evolution)
Evolution analogies are bad. There are many specific differences between ML optimization processes and biological evolution that predictably result in very different high level dynamics. You should not rely on one to predict the other, as I have argued extensively elsewhere.
Trying to draw inferences about ML from bio evolution is only slightly less absurd than trying to draw inferences about cheesy humor from actual dairy products. Regardless of the fact they can both be called "optmization processes", they're completely different things, with different causal structures responsible for their different outcomes, and crucially, those differences in causal structure explain their different outcomes. There's thus no valid inference from "X happened in biological evolution" to "X will eventually happen in ML", because X happening in biological evolution is explained by evolution-specific details that don't appear in ML (at least for most alignment-relevant Xs that I see MIRI people reference often, like the sharp left turn).
Re: "Re: Values are easy to learn, this mostly seems to me like it makes the incredibly-common conflation between "AI will be able to figure out what humans want" (yes; obviously; this was never under dispute) and "AI will care""
This wasn't the point we were making in that section at all. We were arguing about concept learning order and the ease of internalizing human values versus other features for basing decisions on. We were arguing that human values are easy features to learn / internalize / hook up to decision making, so on any natural progression up the learning capacity ladder, you end up with an AI that's aligned before you end up with one that's so capable it can destroy the entirety of human civilization by itself.
Re "Even though this was just a quick take, it seemed worth posting in the absence of a more polished response from me, so, here we are."
I think you badly misunderstood the post (e.g., multiple times assuming we're making an argument we're not, based on shallow pattern matching of the words used: interpreting "whitebox" as meaning mech interp and "values are easy to learn" as "it will know human values"), and I wish you'd either take the time to actually read / engage with the post in sufficient depth to not make these sorts of mistakes, or not engage at all (or at least not be so rude when you do it).
(Note that this next paragraph is speculation, but a possibility worth bringing up, IMO):
As it is, your response feels like you skimmed just long enough to pattern match our content to arguments you've previously dismissed, then regurgitated your cached responses to those arguments. Without further commenting on the merits of our specific arguments, I'll just note that this is a very bad habit to have if you want to actually change your mind in response to new evidence/arguments about the feasibility of alignment.
Re: "Overall take: unimpressed."
I'm more frustrated and annoyed than "unimpressed". But I also did not find this response impressive.