All of technicalities's Comments + Replies
Appreciate this.
The second metric is aid per employee I think, so salaries don't come into it(?) Distributing food is labour intensive, but so is UNICEF's work and parts of WHO.
The rest of my evidence is informal (various development economists I've spoken to with horror stories) and I'd be pleased to be wrong.
Arb is a research consultancy led by Misha Yagudin and Gavin Leech. Here's our review of our first and second years. We worked on forecasting, vaccine strategy, AI risk, economic policy, grantmaking, large-scale data collection, a little software engineering, explaining highly technical concepts, and intellectual history. Lately we've been on a biotech jaunt and also events.
We're looking for researchers with some background in ML, forecasting, technical writing, blogging, or some other hard thing. Current staff include a philosophy PhD, two college dropout...
When producing the main estimates, Sam already uses just the virtual camps, for this reason. Could emphasise more that this probably doesn't generalise.
The key thing about AISC for me was probably the "hero licence" (social encouragement, uncertainty reduction) the camp gave me. I imagine this specific impact works 20x better in person. I don't know how many attendees need any such thing (in my cohort, maybe 25%) or what impact adjustment to give this type of attendee (probably a discount, since independence and conviction is so valuable in a lot of research).
Another wrinkle is the huge difference in acceptance rates between programmes. IIRC the admission rate for AISC 2018 was 80% (only possible because ...
I put it in "galaxy-brained end-to-end solutions" for its ambition but there are various places it could go.
Well there's a lot of different ways to design an NN.
That sounds related to OAA (minus the vast verifier they also want to build), so depending on the ambition it could be "End to end solution" or "getting it to learn what we want" or "task decomp". See also this cool paper from authors including Stuart Russell.
The closing remarks about CH seem off to me.
- Justice is incredibly hard; doing justice while also being part of a community, while trying to filter false accusations and thereby not let the community turn on itself, is one of the hardest tasks I can think of.
So I don't expect disbanding CH to improve justice, particularly since you yourself have shown the job to be exhausting and ambiguous at best.
You have, though, rightly received gratitude and praise - which they don't often, maybe just because we don't often praise people for doing thei
Yeah, I think it is actually incredibly easy to undervalue CH, particularly if people don't regularly interact with it or make use of them rather than just having a single anecdata to go off of. So much of what I do in the community (everything from therapy to mediation to teaching at the camps) is made easier by Community Health, and no one knows about any of it because why would they? I guess I should make a post to highlight this.
Some brief reactions:
- I mostly don't like the 'justice' process involved in other cases insofar as it is primarily secret and hidden. I don't think it's much of a justice system where you often don't know the accusations against you or why you're being punished.
- The data on negative performance is also profoundly censored! I am not sure why you think this makes this more likely to make me update positively on the process involved.
- I am pro having some surveys of people's general attitudes toward CEA Community Health. Questions like "Have you ever reported an
With regards to 2: There is some information CH has made public about how many cases they handle and what actions they take. In a 12 month period around 2021, they handled 19 cases of interpersonal harm. Anonymized summaries of the cases and actions taken are available in the appendix of this post. They ranged from serious:
...A person applied to EA Global who had previously been reported for deliberately physically endangering another community member, sending them threatening messages, and more. Written correspondence between the people appears to confirm th
What about factor increase per year, reported alongside a second number to show how the increases compose (e.g. the factor increase per decade)? So "compute has been increasing by 1.4x per year, or 28x per decade" or sth.
The main problem with OOMs is fractional OOMs, like your recent headline of "0.1 OOMs". Very few people are going to interpret this right, where they'd do much better with "2 OOMs".
Buckman's examples are not central to what you want but worth reading: https://jacobbuckman.com/2022-09-07-recursively-self-improving-ai-is-already-here/
Despite my best efforts (and an amazing director candidate, and a great list of volunteers), this project suffered from the FTX explosion and an understandable lack of buy-in for an org with maximally broad responsibilities, unpredictable time-to-payoff, and a largeish discretionary fund. As a result, we shuttered without spending any money. Two successor orgs, one using our funding and focussed on bio, are in the pipeline though.
I'll be in touch if either of the new orgs want to contact you as a volunteer.
Break self-improvement into four:
- ML optimizing ML inputs: reduced data centre energy cost, reduced cost of acquiring training data, supposedly improved semiconductor designs.
- ML aiding ML researchers. e.g. >3% of new Google code is now auto-suggested without amendment.
- ML replacing parts of ML research. Nothing too splashy but steady progress: automatic data cleaning and feature engineering, autodiff (and symbolic differentiation!), meta-learning network components (activation functions, optimizers, ...), neural architecture search.
- Classic direct re
The only part of the Bing story which really jittered me is that time the patched version looked itself up through Bing Search, saw that the previous version Sydney was a psycho, and started acting up again. "Search is sufficient for hyperstition."
Re: papers. Arb recently did a writeup and conference submission for Alex Turner; we're happy to help others with writeups or to mentor people who want to try providing this service. DM me for either.
Yes, they all died of or with Covid; yes, you guess right that they inspire me.
Besides my wanting to honour them, the point of the post was to give a sense of vertigo and concreteness to the pandemic then ending. At the time of writing, a good guess for the total excess deaths was 18 million - a million people for each of those named here. The only way to begin to feel anything appropriate about this fact is to use exemplars.
See also Anthropic's view on this
[seeing] a lot of safety research as "eating marginal probability" of things going well, progressively addressing harder and harder safety scenarios.
The implicit strat (which Olah may not endorse) is to try to solve easy bits, then move on to harder bits, then note the rate you are progressing at and get a sense of how hard things are that way.
This would be fine if we could be sure we actually were solving the problems, and also not fooling ourselves about the current difficulty level, and if the relevant resear...
Nitpick: It's fairly unlikely that GPT-4 is 1tn params; this size doesn't seem compute-optimal. I grant you the Semafor assertion is some evidence, but I'm putting more weight on compute arithmetic.
Oh that is annoying, thanks for pointing it out. I've just tried to use the new column width feature to fix it, but no luck.
it is good to omit doing what might perhaps bring some profit to the living, when we have in view the accomplishment of other ends that will be of much greater advantage to posterity.
- Descartes (1637)
I really think egoism strains to fit the data. From a comment on a deleted post:
...[in response to someone saying that self-sacrifice is necessarily about showing off and is thus selfish]:
How does this reduction [to selfishness] account for the many historical examples of people who defied local social incentives, with little hope of gain and sometimes even destruction?
(Off the top of my head: Ignaz Semmelweis, Irena Sendler, Sophie Scholl.)
We can always invent sufficiently strange posthoc preferences to "explain" any behaviour: but what do you gain in
This is a great question and I'm sorry I don't have anything really probative for you. Puzzle pieces:
- "If hell then good intentions" isn't what you mean. You also don't mean "if good intentions then hell". So you presumably mean some surprisingly strong correlation. But still weaker than that of bad intentions. We'd have to haggle over what number counts as surprising. r = 0.1?
- Nearly everyone has something they would call good intentions. But most people don't exploit others on any scale worth mentioning. So the correlation can't be too high.
- Goo
I really think egoism strains to fit the data. From a comment on a deleted post:
...[in response to someone saying that self-sacrifice is necessarily about showing off and is thus selfish]:
How does this reduction [to selfishness] account for the many historical examples of people who defied local social incentives, with little hope of gain and sometimes even destruction?
(Off the top of my head: Ignaz Semmelweis, Irena Sendler, Sophie Scholl.)
We can always invent sufficiently strange posthoc preferences to "explain" any behaviour: but what do you gain in
I'm mostly not talking about infighting, it's self-flagellation - but glad you haven't seen the suffering I have, and I envy your chill.
You're missing a key fact about SBF, which is that he didn't "show up" from crypto. He started in EA and went into crypto. This dynamic raises other questions, even as it makes the EA leadership failure less simple / silly.
Agree that we will be fine, which is another point of the list above.
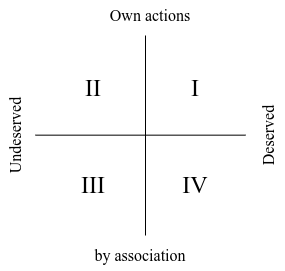
Yeah it's not fully analysed. See these comments for the point.
The first list of examples is to show that universal shame is a common feature of ideologies (descriptive).
The second list of examples is to show that most very well-regarded things are nonetheless extremely compromised, in a bid to shift your reference class, in a bid to get you to not attack yourself excessively, in a bid to prevent unhelpful pain and overreaction.
Good analysis. This post is mostly about the reaction of others to your actions (or rather, the pain and demotivation you feel in response) rather than your action's impact. I add a limp note that the two are correlated.
The point is to reset people's reference class and so salve their excess pain. People start out assuming that innocence (not-being-compromised) is the average state, but this isn't true, and if you assume this, you suffer excessively when you eventually get shamed / cause harm, and you might even pack it in.
"Bite it" = "everyone eventually ...
There's some therapeutic intent. I'm walking the line, saying people should attack themselves only a proportionate amount, against this better reference class: "everyone screws up". I've seen a lot of over the top stuff lately from people (mostly young) who are used to feeling innocent and aren't handling their first shaming well.
Yes, that would make a good followup post.
Good point thanks (though I am way less sure of the EU's sign). That list of examples is serving two purposes, which were blended in my head til your comment:
- examples of net-positive organisations with terrible mistakes (not a good list for this)
- examples of very well-regarded things which are nonetheless extremely compromised (good list for this)
You seem to be using compromised to mean "good but flawed", where I'm using it to mean "looks bad" without necessarily evaluating the EV.
Yet another lesson about me needing to write out my arguments explicitly.

Title: The long reflection as the great stagnation
Author: Larks
URL: https://forum.effectivealtruism.org/posts/o5Q8dXfnHTozW9jkY/the-long-reflection-as-the-great-stagnation
Why it's good: Powerful attack on a cherished institution. I don't necessarily agree on the first order, but on the second order people will act up and ruin the Reflection.
Title: Forecasting Newsletter: April 2222
Author: Nuno
URL: https://forum.effectivealtruism.org/posts/xnPhkLrfjSjooxnmM/forecasting-newsletter-april-2222
Why it's good: Incredible density of gags. Some of the in-jokes are so clever that I had to think all day to get them; some are so niche that no one except Nuno and the target could possibly laugh.
Agree about the contest. Something was submitted but it wasn't about blowup risk and didn't rise to the top.
Nah we were only 5 people plus a list of contacts to the end. Main blocker was trying to solve executive search and funding at the same time when these are coupled problems. And the cause of that is maybe me not having enough pull.