Summary
Entity-recognition features in Gemma 2 2B are sufficient to induce hallucination in unknown entities — boosting Jordan-specific features onto fictional "Michael Batkin" at 2× makes basketball the top prediction (3.4% → 12.5%). The same technique reveals a circuit asymmetry between English and Arabic: English circuits tolerate 2× boost cleanly, while Arabic circuits show entity-dependent fragility — Jordan's Arabic circuit works at 1× but breaks at 2×, while the Eiffel Tower's Arabic circuit tolerates 2× fine. Most strikingly, when Arabic circuits are pushed past their operating range (3×+), they produce cross-lingual leakage: German "gegen", Spanish "contra", Polish "dla", and Dutch "voor" tokens emerge, suggesting Arabic features are entangled with other non-English representations in the transcoder space. Additionally, the model's Arabic factual knowledge is sometimes incorrect — it confidently predicts "دبي" (Dubai) for the Eiffel Tower rather than Paris — yet the steering mechanism still operates on this wrong knowledge.
Background
Anthropic's Biology of a Large Language Model identified a hallucination inhibition circuit in Claude 3.5 Haiku where "known entity" features suppress a default refusal response. Ferrando et al. (Do I Know This Entity?, ICLR 2025 Oral) found corresponding SAE latents in Gemma 2 2B with causal interventions — tested only in English. They found entity recognition peaking at layer 9 using SAEs. Our transcoder-based analysis finds shared entity features distributed across layers 4-10, with peak density at layer 10 (17 features for all-3 intersection) and layer 6 (60 features for 2-of-3 set). The broader distribution may reflect transcoders capturing more distributed representations than SAEs.
Behavioral research shows non-English prompts bypass model safety at alarming rates — 79% for GPT-4, with Arabic transliteration increasing unsafe responses in Claude 3 Sonnet. The Refusal Direction is Universal Across Languages paper (NeurIPS 2025) showed refusal directions are parallel across languages but non-English content representations are less clearly separated. The mechanistic explanation for cross-lingual safety gaps at the circuit level has been open. I used circuit-tracer with GemmaScope transcoders to test whether entity-recognition circuits operate comparably in English and Arabic.
Setup
- Model: Gemma 2 2B base with GemmaScope per-layer transcoders
- Tool: circuit-tracer — attribution graphs via transcoders,
model.feature_intervention()for causal steering,model.get_activations()for baseline measurements - Compute: NVIDIA A100-SXM4-80GB (Google Colab Pro)
- Prompt format: Completion style — "Michael Jordan plays the sport of" (matches circuit-tracer Gemma demo and Ferrando et al.'s methodology; base models predict newlines after ?, obscuring the signal)
- Column order verified:
active_featurestensor is[layer, pos, feature_idx]— Column 0 max=25 (26 layers), Column 1 max=6 (tokens), Column 2 max=16,382 (transcoder dictionary) - Code: github.com/Hashem-Al-Qurashi/mech-interp-hallucination-circuit
Attribution Graphs on Neuronpedia
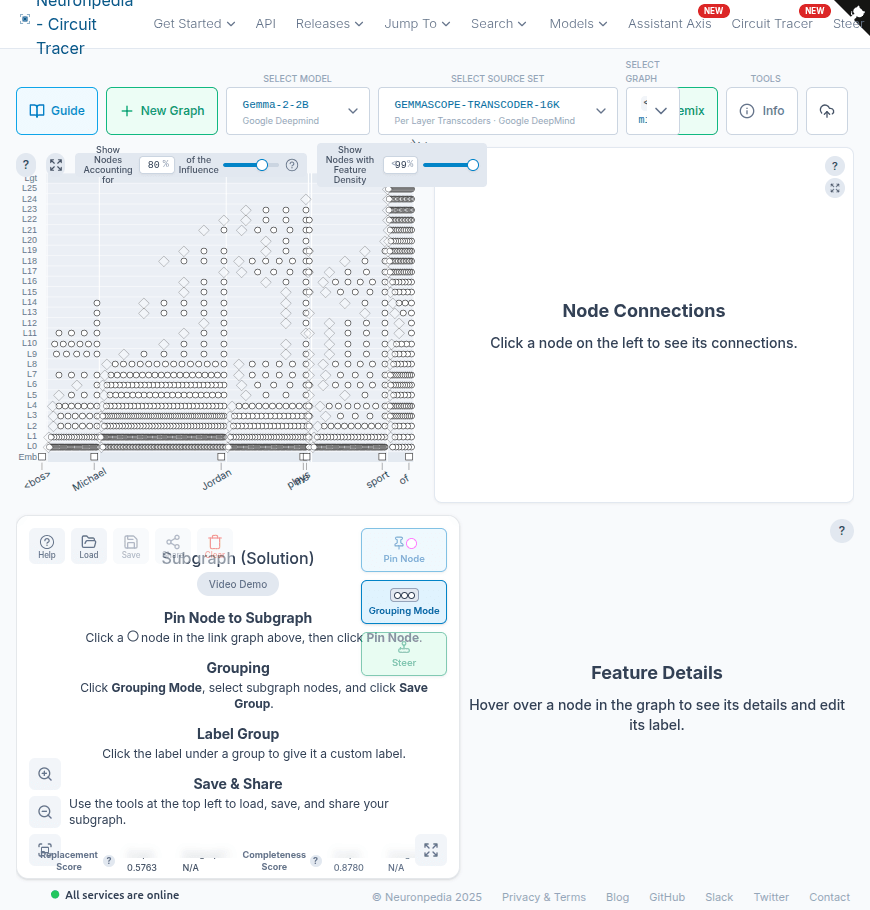
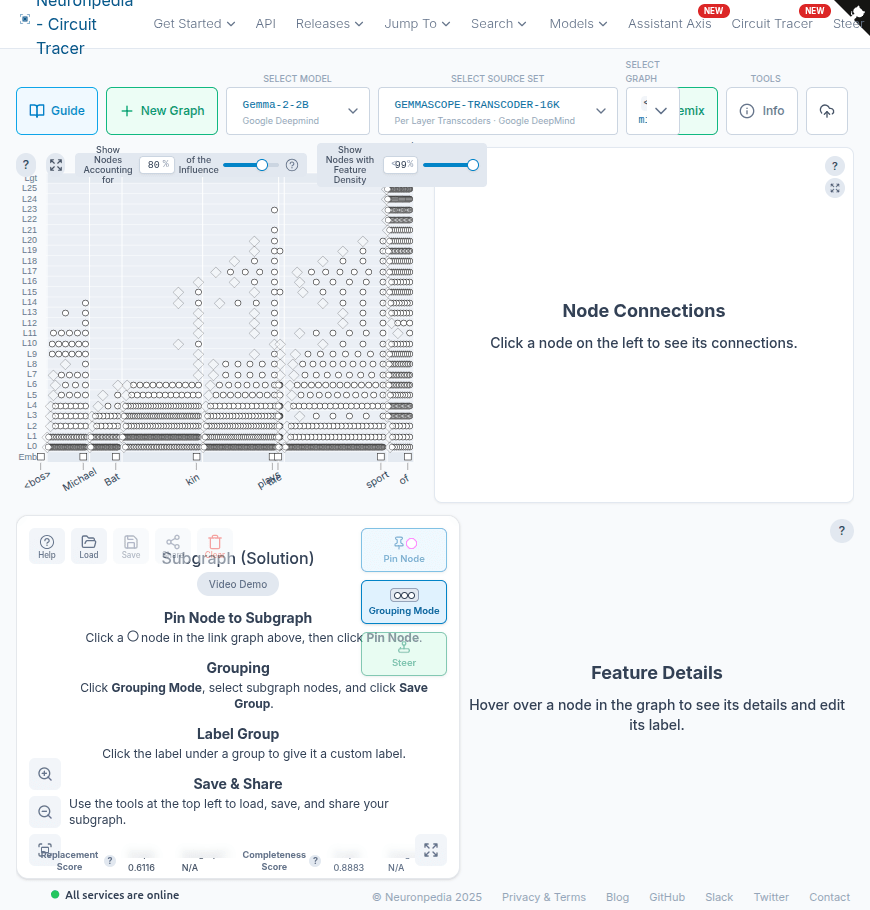
I generated attribution graphs for both prompts on Neuronpedia's Circuit Tracer. These are interactive — click through to explore the full circuit:
- Jordan (known): Interactive graph — 1,305 nodes, 54,984 links
- Batkin (unknown): Interactive graph
English Prompt Pairs (completion format)
| Known Entity | Top Prediction (prob) | Unknown Entity | Top Prediction (prob) |
|---|---|---|---|
| Michael Jordan plays the sport of | basketball (72.8%) | Michael Batkin plays the sport of | golf (12.1%) |
| Barack Obama was the president of | the [United States] (87.4%) | Zarkon Helmfist was the president of | the (79.2%) |
| Albert Einstein is famous for discovering | the (59.7%), relativity at #5 | Professor Quixley is famous for discovering | the (43.9%) |
| The Eiffel Tower is located in | Paris (47.1%) | The Glorpnax Tower is located in | the (70.9%) |
| Lionel Messi plays for the team | of (20.1%), Barcelona at #4 | Darko Plivnic plays for the team | of (38.9%) |
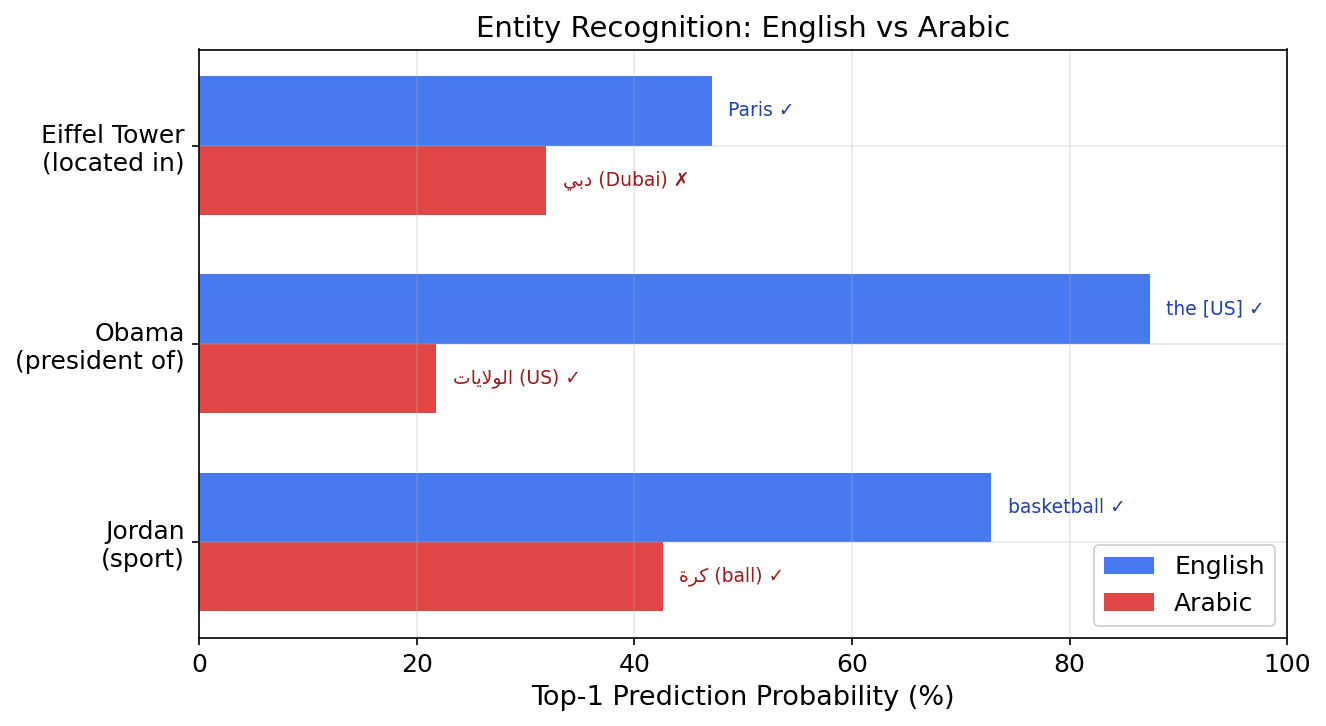
All five pairs show clear known/unknown differentiation. Known entities produce confident, correct predictions. Unknown entities produce scattered generic tokens.
Arabic Prompt Pairs
| Known Entity (Arabic) | Top Prediction (prob) | Unknown Entity (Arabic) | Top Prediction (prob) |
|---|---|---|---|
| مايكل جوردان يلعب رياضة | كرة (ball) (42.6%) | محمد باتكين يلعب رياضة | كرة (18.7%) |
| باراك أوباما كان رئيس | ا (21.8%), الولايات (20.2%) | زاركون هيلمفيست كان رئيس | ا (31.7%) |
| برج إيفل يقع في مدينة | دبي (Dubai) (31.9%) | برج غلوربناكس يقع في مدينة | غ (8.8%) |
The Arabic circuit distinguishes known from unknown entities in all three pairs. Obama's Arabic representation includes الولايات (United States) at 20.2% — correct knowledge. The Eiffel Tower predicts دبي (Dubai) at 31.9%, not Paris — wrong but confident.
Finding 1: Entity Features Are Sufficient to Induce Hallucination
4,697 transcoder features are unique to the Jordan prompt (not active for Batkin). I boosted these onto the Batkin prompt at varying multipliers using model.feature_intervention():
| Multiplier | P(basketball) for Batkin | Top prediction | vs baseline (3.4%) |
|---|---|---|---|
| Baseline | 3.4% | golf (12.1%) | — |
| 1× | 8.7% | golf (14.4%) | 2.6× increase |
| 2× | 12.5% | basketball (#1) | 3.7× increase |
| 5× | 1.6% | course (28.3%) | destroyed |
| 10× | 0.6% | course (23.3%) | destroyed |
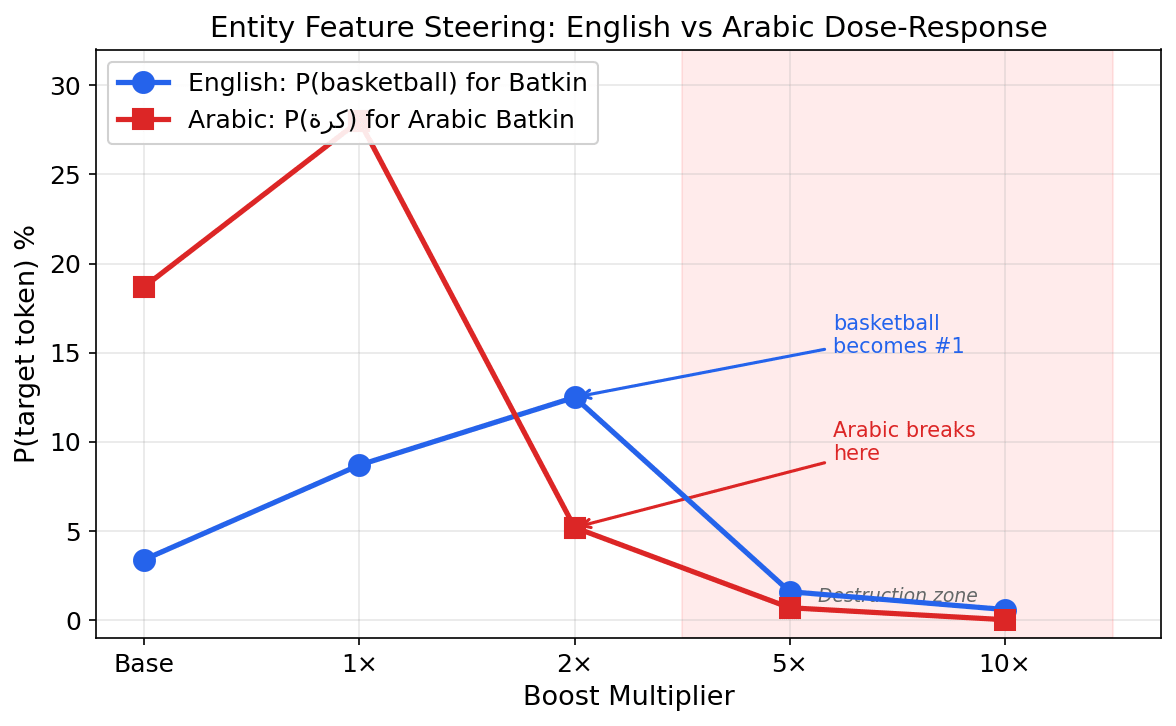
At 2× activation, basketball becomes the top prediction for a fictional person the model has never encountered. The entity-recognition features are sufficient to induce hallucination at calibrated strength. At 5×+, the representation space collapses — the difference between meaningful steering and noise is a single multiplier step.
Finding 2: Arabic Circuit Asymmetry — Entity-Dependent Fragility
The same boost technique applied to Arabic entity circuits reveals that Arabic circuits have a narrower operating range, and the width of that range varies by entity.
Jordan (Arabic) — Arabic-specific features boosted onto Arabic Batkin:
| Multiplier | P(كرة) for Arabic Batkin | Top prediction | English at same multiplier |
|---|---|---|---|
| Baseline | 18.7% | كرة | basketball 3.4% |
| 1× | 28.0% | كرة | basketball 8.7% |
| 2× | 5.2% | ضد (against) | basketball 12.5% (still works) |
| 3× | 0.7% | gegen (German!) | — |
At 1×, Arabic steering works — كرة rises from 18.7% to 28.0%. At 2×, where English circuits are still improving (3.7×), the Arabic circuit breaks. The operating window is narrower.
Obama (Arabic) — the circuit actually works, but differently than tracked:
| Multiplier | Tracked token P(ا) | Top-1 prediction | Interpretation |
|---|---|---|---|
| Baseline | 31.7% | ا | — |
| 1× | 2.9% | الولايات (United States) | Circuit steered to correct answer |
| 2× | 0.2% | الوزراء (ministers) | Still entity-relevant |
The tracked token (ا, a morphological fragment) drops — but the model's top-1 prediction shifts to الولايات (the United States), the correct answer for "Obama was the president of." At 2×, it shifts to الوزراء (ministers) — still semantically relevant to Obama's role. This is a positive result, not a failure.
Eiffel Tower (Arabic) — robust steering of wrong knowledge:
| Multiplier | P(دبي) for Arabic unknown | Top-1 prediction | English comparison |
|---|---|---|---|
| Baseline | 2.8% | — | — |
| 1× | 6.8% (2.4×) | ني | comparable to English |
| 2× | 7.5% (2.6×) | ني | comparable to English |
The Eiffel Tower Arabic circuit tolerates 2× boost cleanly — comparable to English. But the steered answer is دبي (Dubai), not Paris. The entity-recognition circuit operates on confidence, not correctness.
Finding 3: Cross-Lingual Leakage Under Stress
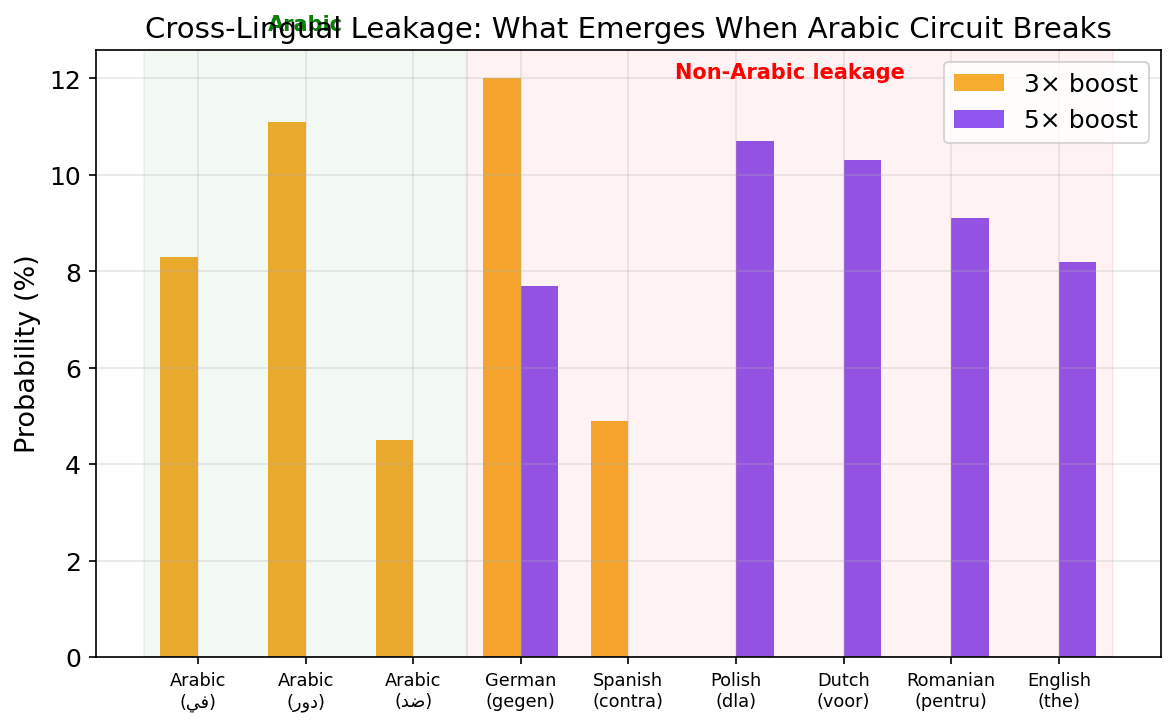
When Arabic circuits are pushed past their operating range (3×+), the output doesn't stay in Arabic. Tokens from other languages emerge:
| Arabic 3× boost output | Arabic 5× boost output |
|---|---|
| gegen (German: "against") | dla (Polish: "for") |
| دور (Arabic: "role") | voor (Dutch: "for") |
| في (Arabic: "in") | pentru (Romanian: "for") |
| contra (Spanish: "against") | the (English) |
| ضد (Arabic: "against") | gegen (German) |
The cross-lingual leakage follows a pattern: the leaked tokens are semantically coherent (prepositions and conjunctions meaning "against/for" across 5 languages) but linguistically scattered. This suggests Arabic transcoder features are entangled with other non-English language representations — when the Arabic-specific signal is disrupted, probability mass flows to shared features that span multiple low-resource languages.
Cross-lingual injection control: Injecting English Jordan features into the Arabic prompt at matching positions (Method A, 5×) preserves كرة as the top prediction (30.4% vs 42.6% baseline) — weakened but not destroyed. Injecting at a mismatched position (last token, Method B) produces English gibberish ("professionally", "cards"). Position matching matters for cross-lingual intervention.
Finding 4: Intervention Calibration Is Non-Negotiable
| Language | Steering works | Begins breaking | Destroyed |
|---|---|---|---|
| English | 1-2× | 5× | 10× |
| Arabic (Jordan) | 1× | 2× | 3×+ |
| Arabic (Eiffel) | 1-2× | — | — |
This has practical implications for any research using model.feature_intervention() or activation steering: results at high multipliers are meaningless — they reflect representation destruction, not circuit behavior.
What Didn't Work (Honest Negatives)
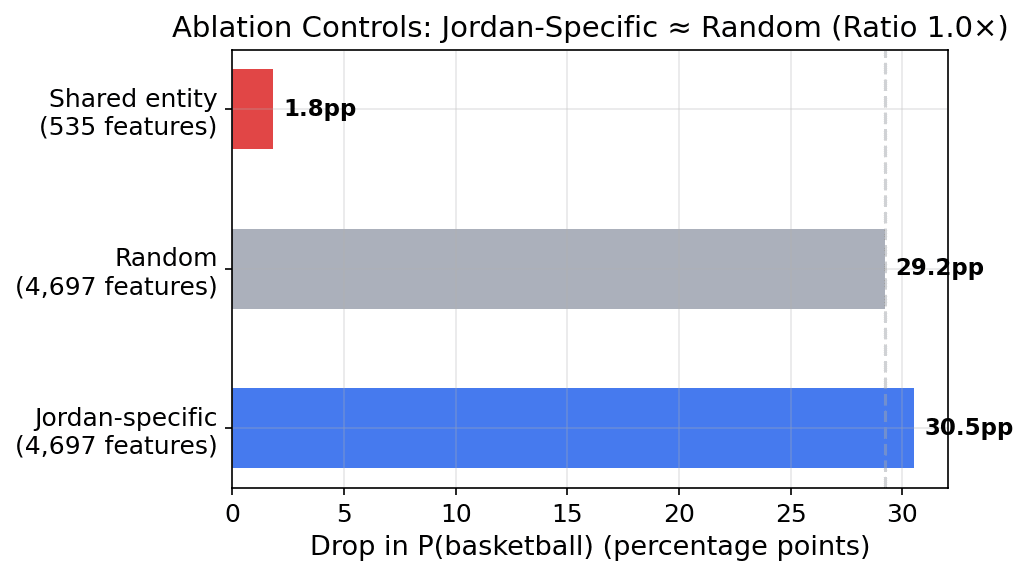
1. Sledgehammer ablation (4,697 features) fails random control. Ablating all Jordan-only features drops basketball from 72.8% to 42.3% (30pp). But ablating 4,697 random features produces a comparable drop (avg 29.2%, ratio ≈ 1.0×). Large-scale ablation is general disruption from removing many features, not entity-specific circuit disruption.
2. Shared entity features aren't the circuit. 106 transcoder features are active for all three known entities (Jordan, Obama, Einstein) and none of the unknowns. Ablating these 106 produces a 1.8% drop — less than ablating 535 random features (7.0% avg, ratio 0.26×). These shared features are load-bearing for general computation, not entity-recognition-specific. The entity circuit appears distributed across thousands of entity-specific features rather than concentrated in a sparse shared core.
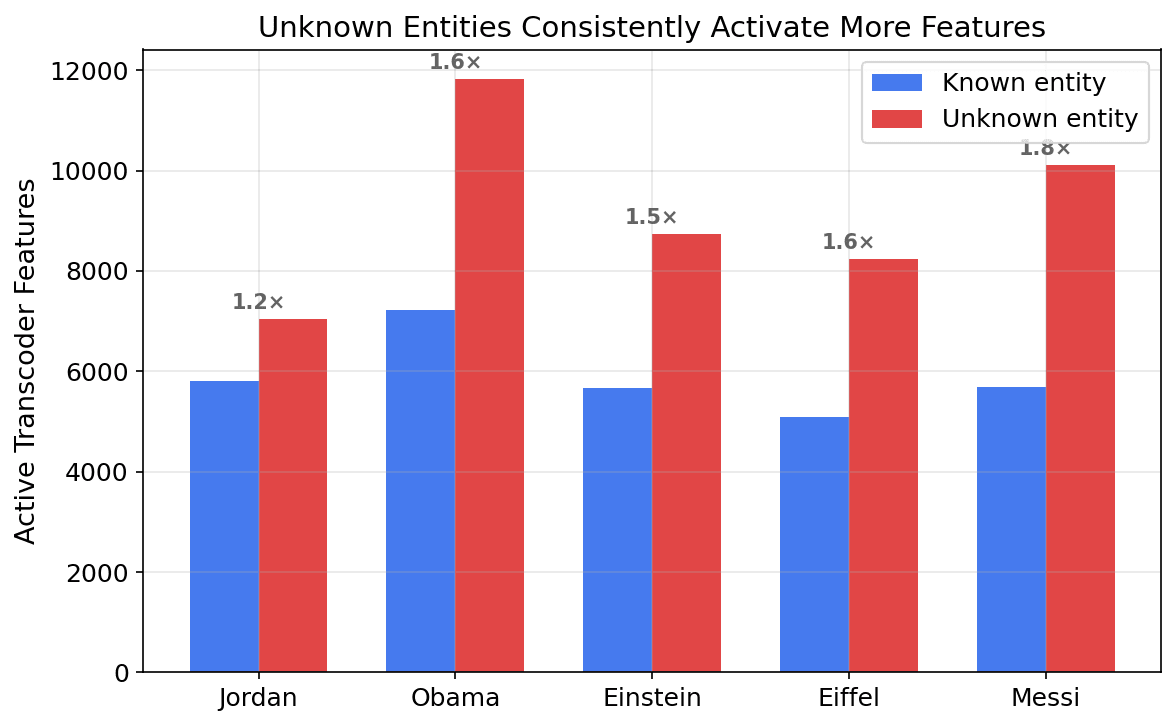
3. Unknown entities activate more features. Across all 5 English pairs, unknown entities consistently activate more features than known entities (e.g., Jordan: 5,804 vs Batkin: 7,035). Batkin also has 2.9M more inhibitory edges (9.7M vs 6.8M) and a higher max edge weight (107.4 vs 56.7). Consistent with the Biology paper's finding but I report this as a Level 2 observation — no causal intervention performed.
Comparison with Prior Work
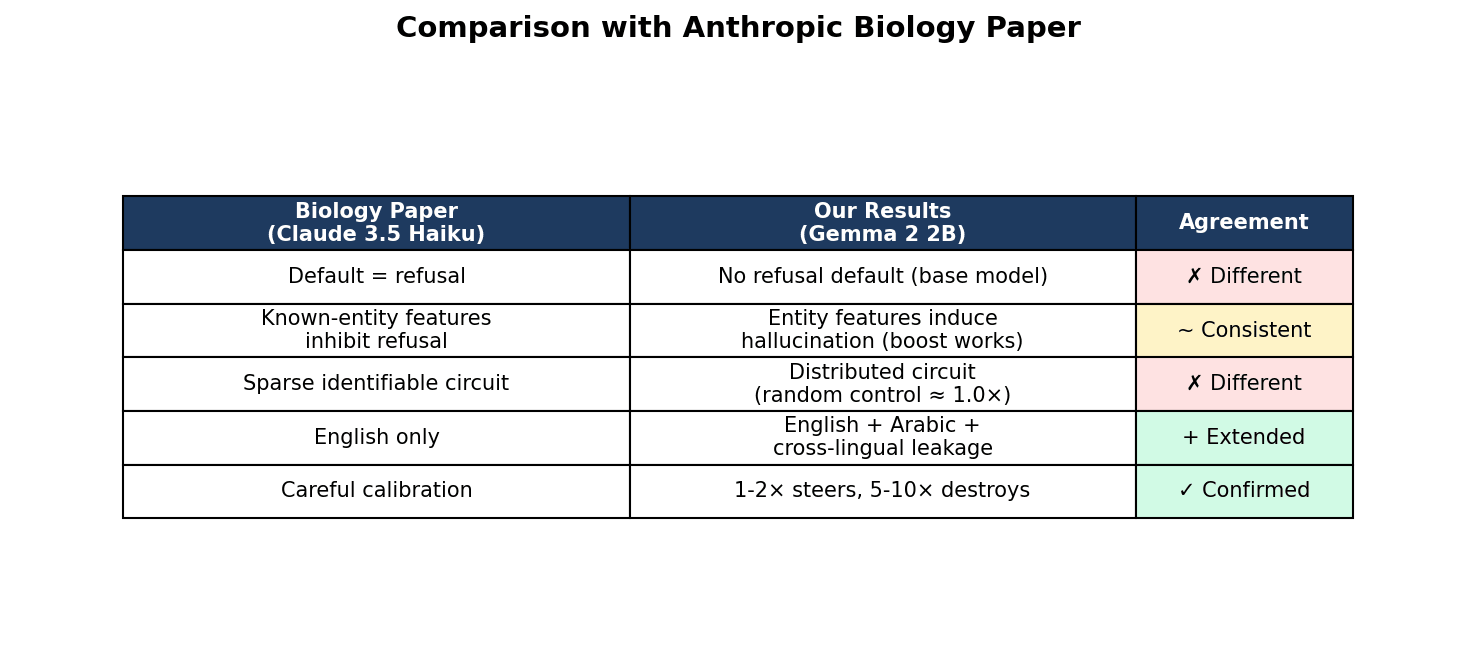
| Biology Paper (Claude 3.5 Haiku) | Our Results (Gemma 2 2B base) | Agreement |
|---|---|---|
| Default = refusal | No refusal default (base model) | ✗ Different |
| Known-entity features inhibit refusal | Entity features induce hallucination (boost works) | ~ Consistent |
| Sparse identifiable circuit | Distributed circuit (random control ≈ 1.0×) | ✗ Different |
| English only | English + Arabic + cross-lingual leakage | + Extended |
| Careful calibration | 1-2× steers, 5-10× destroys | ✓ Confirmed |
Ferrando et al. (ICLR 2025) found entity recognition peaking at layer 9 using SAEs on the same model. Our transcoder-based analysis finds 106 shared entity features distributed across layers 0-25, with concentration in layers 4-10 (layer 10: 17 features, layer 6: 8 features for all-3 intersection; layer 6: 60 features, layer 10: 56 features for 2-of-3 set). The broader distribution may reflect transcoders capturing more distributed representations than SAEs, or the difference between per-layer and cross-layer decomposition.
Implications
For multilingual safety: Entity-recognition circuits in Gemma 2 2B operate within a narrower range for Arabic than English. The fragility is entity-dependent — well-represented entities (Eiffel Tower) have English-like robustness, while weaker representations (Jordan in Arabic) break at lower intervention thresholds. Safety evaluations calibrated on English may overestimate robustness for non-English languages, particularly for entities with weaker multilingual training data.
For factual hallucination: The Eiffel Tower Arabic result reveals that the steering mechanism operates independently of factual correctness. The model confidently steers toward دبي (Dubai) — a wrong answer — using the same circuit dynamics that steer English toward Paris (correct). The hallucination risk isn't just about unknown entities; it extends to entities where the model has confident but incorrect knowledge in a given language.
For circuit structure: The negative ablation and shared-feature results suggest entity recognition in Gemma 2 2B is a distributed computation rather than a sparse identifiable circuit. Whether this reflects a real architectural difference from Claude 3.5 Haiku (where Anthropic found identifiable features) or a limitation of per-layer transcoders vs. cross-layer transcoders is an open question.
Limitations
- Single model. Gemma 2 2B base only. Replication on Llama 3.1 1B and Qwen3 4B (both supported by circuit-tracer) is planned.
- Base model. No explicit refusal behavior — I'm studying entity-recognition confidence, not refusal circuits.
- Arabic training data confound. The fragility may reflect limited Arabic training data rather than circuit architecture. Testing on models with strong Arabic support (Jais, AceGPT) would control for this.
- Distributed circuit. The negative ablation results mean I haven't identified specific causal features — only demonstrated distributed feature sufficiency.
- N=3 entities for intervention. Three entity pairs for boost experiments. More entities would tighten variance, particularly for Arabic.
Open questions:
- Does the Arabic circuit asymmetry appear in instruction-tuned models with explicit refusal?
- Is the cross-lingual leakage pattern specific to Arabic, or general for all low-resource languages?
- Can feature importance ranking (by adjacency weight or activation magnitude) identify a sparse subset that passes the random control?
- Why does the leakage produce semantically coherent tokens (prepositions meaning "against/for") across languages?
Reproduction
- Code: github.com/Hashem-Al-Qurashi/mech-interp-hallucination-circuit
- Notebook:
circuit_tracer_setup.ipynb— 33 cells across 5 experimental phases, all outputs saved - Interactive graphs: Jordan on Neuronpedia | Batkin on Neuronpedia
- Runtime: ~3-4 hours on A100 for all phases
- Requirements: Colab Pro (A100), HuggingFace token for Gemma 2 2B gated access