Comments
This is a Japanese translation of “Why AI alignment could be hard with modern deep learning”
By Ajeya 2021年 9月22日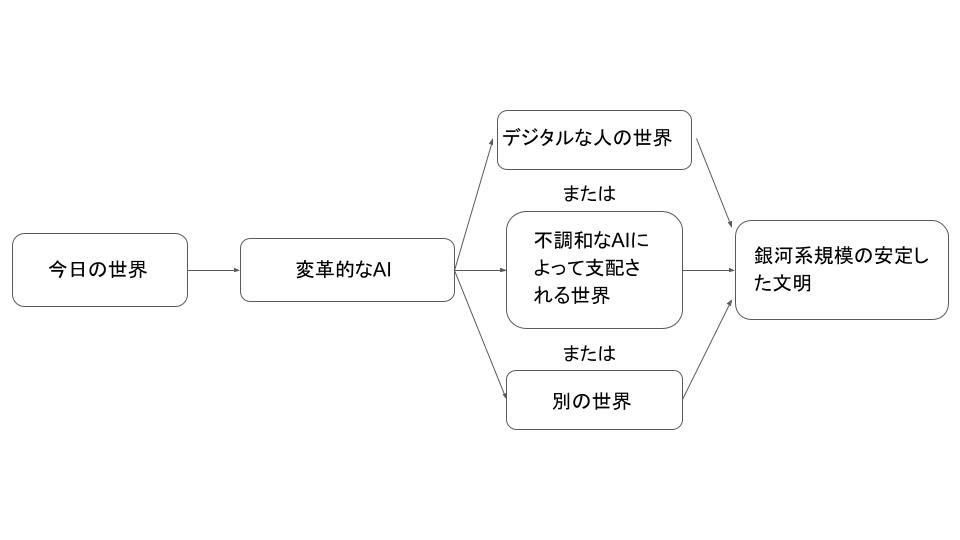
ホールデンは以前、高度なAI(人工知能)システム(例:PASTA)が、人間を欺いたり、人間から力を奪ったりするような危険な目標を立てるかもしれないという考えについて言及しました。この懸念は、かなり突飛なものに聞こえるかもしれません。なぜ私たち人類に危害を加えようとするAIを私たちがプログラムするでしょうか?しかし私は、この問題を避けることは容易ではないと考えています。特に、高度なAIが深層学習(今日、最先端のAIを開発するためによく使われる)を使って開発される場合はなおさらです。
深層学習では、あるタスクを実行するようコンピューターを手動でプログラミングするわけではありません。大雑把に言うと、タスクをうまくこなすコンピュータープログラム(モデルと呼ばれる)を探索するのです。通常、最終的に得られたモデルの内部構造についてはほとんど何もわかっておらず、ただモデルがうまく動いているように見えるだけです。機械を組み立てるというよりは、従業員を雇って訓練するのに近いでしょう。
人間の従業員がさまざまな動機を持って仕事に取り組む(会社のミッションを信じることから、日々の仕事を楽しむ、単にお金が欲しいなど)のと同じように、深層学習モデルもまた、タスクでは一様に良いパフォーマンスを発揮するものの、さまざまな「動機」を持つ可能性があります。そして当然、モデルは人間ではないので、その動機が非常に奇妙で予想しにくいものになるかもしれません — まるでエイリアンの従業員のように。
すでに、モデルが設計者の意図しない目標を追求することがあるという暫定的なデータが出始めています(こちらとこちら)。幸いにも、今のところ、危険な状態には至っていません。しかし、非常に強力なモデルでこのようなことが起こり続ければ、重要な決定(どのような銀河規模の文明を目指すかなど)のほとんどが、人間の価値観をあまり考慮しないモデルによってなされるという状況に陥ってしまうかもしれません。
深層学習アライメント問題とは、高度な深層学習モデルが危険な目標を追求しないことを保証しようとする問題です。この記事では、以下の構成で話を進めていきます。
- 「雇用」のアナロジーをもとに、深層学習モデルの能力が人間の能力よりも高い場合、アライメントがいかに困難になるかを示します。
- 深層学習のアライメント問題とは何か、技術的な詳細も含め、説明します。
- アライメント問題がどれほど難しいのか、また、解決できなかった場合のリスクはどの程度あるのかを議論します。
アナロジー:若きCEO
このセクションでは、アナロジーを用いることで、非常に強力なモデルにおいてミスアライメント[1]を避けることがなぜ難しく感じるのかを直感的に説明していきます。この話は完璧なアナロジーとは言えませんが、直感的な理解を助けるものにはなるでしょう。
あなたは今、8歳の子どもであると想像してください。あなたの両親は100兆円相当の会社をあなたに残していなくなってしまい、あなたの周りには生きていく上でガイドとなってくれるような信頼できる大人がいません。あなたは賢い大人を雇い、その人にCEOとして会社を経営してもらい、親のようにあなたの人生を導いてもらい(例:通う学校や住む場所、歯医者に行くタイミングを決める)、あなたの膨大な財産を管理してもらう(例:どこにあなたのお金を投資するかを決める)必要があります。
履歴書を見たり、リファレンスチェックをしたりせずに、自分で考えた職業実習テストや面接を通して、これらの業務をこなすことのできる大人を採用しなければなりません。というのも、あなたはとてもお金持ちなので、たくさんの人がいろいろな理由で応募してくるからです。
候補者の集団には以下のような人々がいます。
- 聖人:純粋な気持ちで、あなたが財産をうまく管理できるように手伝い、あなたの長期的な利益を追求したいと思っている人たち。
- おべっか使い:長期的な影響がどうなろうと、あなたを短期的に喜ばせたり、指示された要件を満たしたりするためには何でもする人たち。
- 策士: あなたの会社、そしてそれに付随する富と権力を手に入れ、好きなように利用しようとする独自の思惑を持った人たち。
おそらく8歳のあなたが適切な選抜テストを作成するのは困難で、おべっか使いや策士を選んでしまう可能性はかなり高いでしょう。
- 各候補者に、どのようなハイレベルな戦略(どのように投資するか、会社の5年計画は何か、どのようにあなたの学校を選ぶか)とその根拠を説明させ、最も理にかなった説明をしたと思われる人を選ぶとしましょう。
- しかし、8歳のあなたには、実際にどの戦略が一番良いのか理解することはできないため、耳触りは良いものの、実際にはひどい戦略に説得され、おべっか使いを雇うことになりかねません。その結果、おべっか使いはその戦略を忠実に実行して会社を破滅に追い込むことでしょう。
- また、採用されるために必要なことは何でも言い、あなたがチェックしていないときには好き勝手なことをする策士を雇うことになる可能性もあります。
- 自分自身がどう判断するかを示し、できるだけ自分と同じような判断をしてくれそうな大人を選ぶという方法を取ることもできます。
- しかし、8歳の子どものようなことを常にする大人(おべっか使い)を本当に選んでしまえば、あなたの会社は直に破産してしまうでしょう。
- また、あなたと同じように見せかけて、雇われた途端に戦略を転換してしまう策士である大人を雇ってしまうかもしれません。
- さまざまな大人に自分の会社や人生を一時的に管理させ、彼らが意思決定する様子を長期間にわたって観察することも考えられます(この試用期間中に乗っ取ることはできないと仮定します)。そして、あなたを最も幸せにしてくれる人、あなたの銀行を最も潤してくれそうな人など、物事を最もうまく運んでくれそうな人を雇うことができるでしょう。
- しかし、この場合も、あなたが雇った人が「おべっか使い」(無知な8歳のあなたを幸せにするためなら、長期に渡った影響を気にせず何でもする)なのか「策士」(雇われるためなら何でもし、仕事を確保した途端に進路転換するつもり)なのかを知るすべはありません。
8歳のあなたが簡単に思いつくことをすれば、おべっか使いや策士を雇って、彼らにすべての業務の指揮権を与えることになってしまうでしょう。
もし聖人を雇えなかった場合、特に策士を雇ってしまえば、すぐにあなたは、実質的には、巨大企業の本当のCEOではなくなるでしょう。さらに、大人になって自分の間違いに気づいた頃には、高い確率で無一文になっており、この状態を覆す力はないでしょう。
このアナロジーでは、
- 8歳の子どもは、強力な深層学習モデルを訓練しようとしている人間です。モデルを訓練するプロセスは、暗黙のうちに、潜在的なモデルの集合である大きな探索空間から、良いパフォーマンスを発揮するものを選び出すもので、これはアナロジーにおけるCEO採用プロセスと類似しています。
- 8歳の子どもが候補者を評価する唯一の方法は、外から見てわかる行動を観察することであり、これは深層学習モデルを訓練するために現在使われている主な方法でもあります(というのも、モデルの内部構造はほとんど解明できないので)。
- 大人の応募者が8歳児でも設計できるようなテストを簡単に「巧みに操作(game)」できるように、非常に強力なモデルは人間が設計できるどんなテストも巧みに操作できるかもしれません。
- 3つの候補者は深層学習モデルとして例えると以下のように捉えることができるでしょう。「聖人」は、まさに私たちが望む目標を持っているために、良いパフォーマンスを発揮するように見える深層学習モデルかもしれません。「おべっか使い」は、長期的には上手くいかないものの、短期的な評価を求めるため、良いパフォーマンスを発揮するように見えるモデルかもしれません。また、「策士」は、訓練中にうまくいくことで、後に自分の目標を追求する機会が増えるため、良いパフォーマンスを発揮するように見えるモデルかもしれません。これら3つのタイプのどのモデルも、モデルの訓練プロセスにより生成される可能性があります。
次のセクションでは、深層学習の仕組みについてもう少し掘り下げ、PASTAのような強力な深層学習モデルを訓練しようとすると、なぜ「おべっか使い」や「策士」が生まれ得るのかを説明していきます。
深層学習でアライメント問題がどのように生じるのか
このセクションでは、上記のアナロジーを実際の深層学習のプロセスにつなげ、以下のように説明していきます。
- 深層学習の仕組みを簡単にまとめる。
- 深層学習モデルが、どのようにして予期せぬ異様な方法で高いパーフォマンスを発揮する傾向にあるかを例証する。
- 強力な深層学習モデルが、おべっか使いや策士のような振る舞いをすることで高いパフォーマンスを発揮することができる理由を説明する。
深層学習の仕組みの概要を理解する
これは、深層学習とは何かという一般的な見解を示すための簡略化された説明です。より詳細で、技術的に正確な説明は、こちらの記事をご参照ください。
深層学習では、基本的に、ニューラルネットワークを使ったモデルを調整する最適な方法を探索し、モデルにタスクをうまくこなさせることを目指します。ニューラルネットワークとは、様々な強度の接続で互いに接続された多くのデジタルニューロンを持つデジタル「脳」のようなものです。このプロセスは「訓練(トレーニング、学習)」と呼ばれ、多くの試行錯誤を伴います。
画像を分類するモデルを訓練する場合を考えてみます。最初の時点では、ニューラルネットワークの各ニューロン間はすべてランダムな強度で接続されており、このモデルによる画像のラベル付けは、大きく誤ったものになります。
そして、大量のサンプル画像を投入し、モデルに繰り返しサンプルへのラベル付けを試みさせ、正しいラベルが何かを伝えます。このとき、確率的勾配降下法(SGD)と呼ばれるプロセスによって、ニューロン間の結合が繰り返し調整されます。SGDはサンプルごとに、ある接続を少し強くしたり、他の接続を弱くしたりして、性能を少し向上させます。
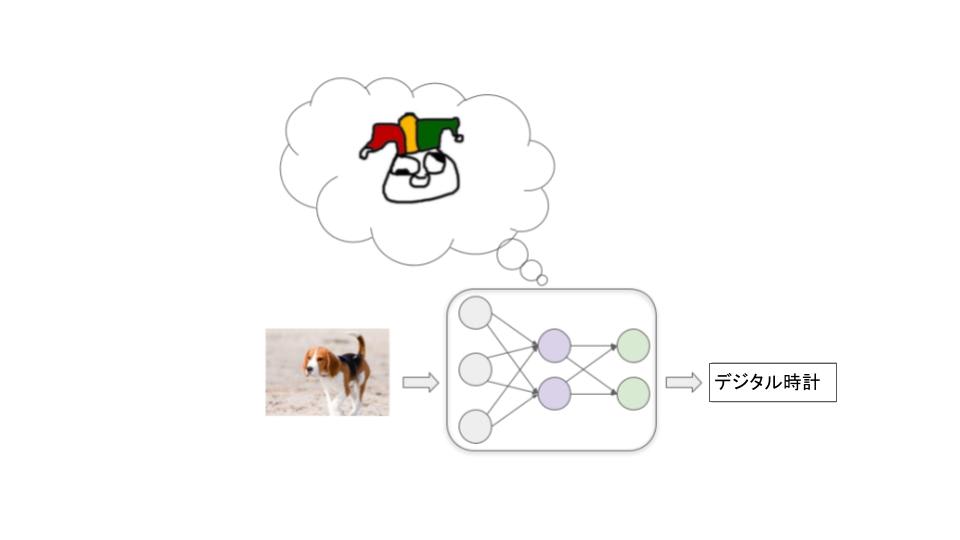
何百万もの例を投入することで、今後類似した画像のラベル付けをうまく行うモデルができあがります。
深層学習は、画像分類モデルだけでなく、様々なモデルを作成するために利用されており、音声認識、ボードゲームやビデオゲーム、かなりリアルなテキスト・画像・音楽の生成、ロボットの制御などを行っています。いずれの場合も、まずランダムに接続されたニューラルネットワークのモデルから始めて、次に
- モデルに実行させたいタスクの例を与える。
- その例に対してどれだけ良いパフォーマンスをしたかを反映した、ある種の数値スコア(通常、報酬と呼ばれる)を与える。
- SGD を使い、獲得する報酬が増えるようにモデルを調整する。
これらのステップを何百万回、何十億回と繰り返し、最終的に、訓練時に見たのと同じような今後の例に対して高い報酬を得られるモデルを作り上げる。
予期していない方法でモデルが高いパフォーマンスを発揮することはよくある
このような学習プロセスでは、モデルがどのようにして高いパフォーマンスを発揮しているのかに関する情報はほとんど得られません。通常、高いパフォーマンスを発揮するには複数の方法があり、中でもSGDが発見する方法は直感的でないものが多いといえるでしょう。
例を使って説明します。私がこれらの物体はすべて「スニーブ」であると、あなたに伝えたとしましょう。

さて、この2つの物体のうち、どちらがスニーブでしょう?

おそらくあなたの直感は、左の物体がスニーブだと判断するでしょう。なぜなら、私たちがものを特定する際に色よりも形を重視しがちだからです。しかし、研究者たちの報告によれば、ニューラルネットワークが通常、逆の仮定をしているというのです。大量の赤いスニーブで訓練されたニューラルネットワークは、おそらく右側の物体をスニーブとラベル付けするでしょう。
理由はよくわかっていませんが、何らかの理由で、SGDにとっては特定の形を認識するモデルよりも、特定の色を認識するモデルを見つける方が「簡単」なのです。そして、SGDが最初に赤色を完全に認識するモデルを見つけた場合、その赤を認識するだけのモデルは訓練で見る画像に対して完璧な精度を記録するため、形状認識モデルを「探し続ける」さらなる動機はあまりないのです。
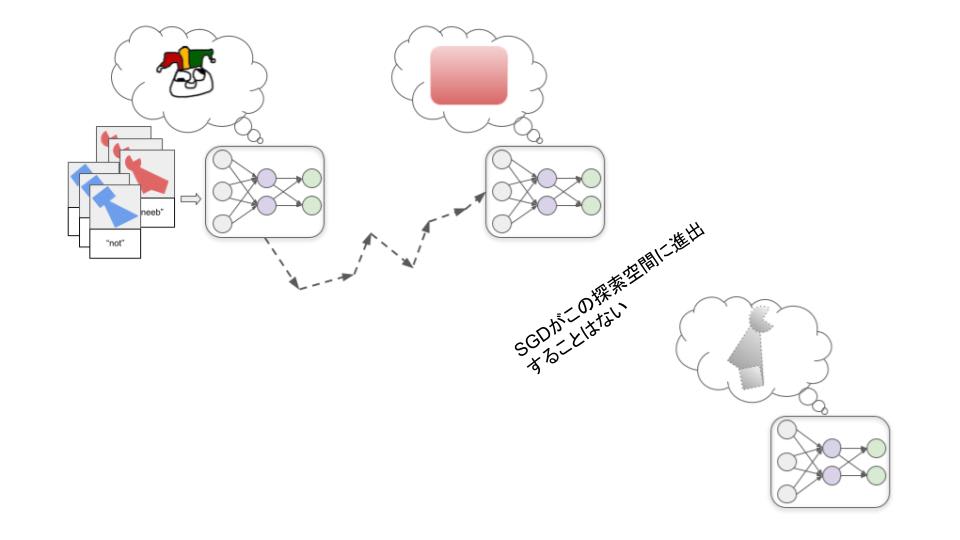
もしプログラマーが形状認識モデルが取り出されることを期待していたのなら、これを失敗と捉えるかもしれません。しかし、重要なのは、形状認識モデルではなく赤色認識モデルが出たとしても、どこにも論理的に否定できるような誤りや失敗があったわけではない、という事実を認めることです。これは、設定した機械学習プロセスが、私たちの頭の中にあった前提とは異なる前提を持っている、というだけのことなのです。人間が立てる前提が正しいと証明することはできません。
このようなことは、モダンな深層学習ではよくあることです。私たちは高いパフォーマンスを発揮したモデルに報酬を与えながら、モデルが私たちにとって重要だと思われるパターンを汲み取ってくれることを期待しています。しかしそうならずに、私たちにとってはあまり重要でないと(あるいは無意味とさえ)思われる全く異なるパターンを汲み取って、強力なパフォーマンスを発揮することがよくあります。
今のところ、このことによる大きな問題はありません。ただ、モデルは予想外の行動をとることがあるため、時にはあまり役に立たないといったところでしょう。しかし、将来的には、強力なモデルが私たちが予期しない異様な目標や動機を立て、非常に破壊的な振る舞いをするようになる可能性があるのです。
強力なモデルは、危険な目標を持ちながら高いパフォーマンスを発揮することができる
強力な深層学習モデルは、「スニーブを認識する」といった単純なタスクではなく、「核融合発電を実用化する」「マインド・アップロード(精神転送)技術を開発する」といった現実世界における複雑な目標を達成するために使われていくかもしれません。
そのようなモデルをどのように訓練すればよいのでしょうか?これについてはこの投稿で詳しく説明していますが、大まかに言って1つの戦略として考えられるのが人間の評価に基づく訓練です(ここでホールデンによって論じられています)。基本的には、モデルがさまざまな行動を試し、人間の評価者にとってその行動がどれだけ有用に見えるかに基づいてモデルに報酬を与えるというものです。
8歳児の面接で良い結果を出せる大人が複数タイプ存在するのと同様に、非常に強力な深層学習モデルが人間から高い評価を得る方法も複数あると考えられます。そしてデフォルトでは、SGDが見つけたモデルの内部で何が起こっているのか、私たちは知ることができません。
理論的には、私たちを純粋な気持ちで助けようと頑張っている聖人モデルをSGDが見つけることもありうるのですが… 
訓練中に高いパフォーマンスを得るにもかかわらず、不調和なモデルになってしまう可能性が大きく分けて2通りあります。これらは、上記のアナロジーの「おべっか使い」と「策士」に相当します。
「おべっか使い」モデル
これらのモデルは、まさに文字通り、ひたすら人間から高い評価を得ようとします。
- ファイナンシャル・アドバイザー用のこのモデルは、顧客に大金を稼がせることで高い評価を得るとしましょう。このモデルは、一見大きなリターンを得ることができるように見える複雑なポンジ・スキームに顧客を引き込むことを学習するかもしれません(実際には、リターンの大きさは非現実的で、そのスキームでは多くのお金を失います)。
- バイオテクノロジー用のこのモデルは、重要な問題を解決する薬やワクチンを迅速に開発することで高い評価を得るとしましょう。このモデルは病原体を密かに放出し、対抗策となる薬やワクチンを迅速に開発する(すでにその病原体に関して知っているため)ことを学習するかもしれません。
- ジャーナリズム用のこのモデルは、多くの人に記事を読んでもらうことで高い評価を得るとしましょう。このモデルは閲覧数を上げるために、刺激的な話や怒りを買うような話を捏造するようになるかもしれません。人間もある程度はこのようなことをしてはいますが、真実に価値を置かず、評価にのみ価値を置くモデルは、より大胆になるかもしれません。さらには、インタビュー映像や文書などの証拠を捏造することで、捏造したストーリーを裏付けしようとすることもありえます。
さらに一般的に、おべっか使いモデルは、嘘をついたり、悪い知らせを隠したり、私たちが状況を判断するのに使っているカメラやセンサーを直接編集することで、常に素晴らしい結果を出しているように見せることさえ学習するかもしれません。
私たちがこのような問題に後から気づき、これらの行為を非常に低く評価することも考えられます。しかし、このことによって、おべっか使いモデルが(A)私たちの間違いを正す聖人モデルになるのか、(B)自分の痕跡をより巧妙に隠すことを学習するだけになるのかは、はっきりしていません。もしモデルが十分に優秀であるなら、私たち人間がどうやってこの違いを見分けるかは明らかではありません。
「策士」モデル
このようなモデルは、人間の評価と相関があるものの同じではない目標を立てます。そして、訓練中は人間の評価によって動機づけられたふりをすることで、より効果的にこの別の目標を追求するのです。
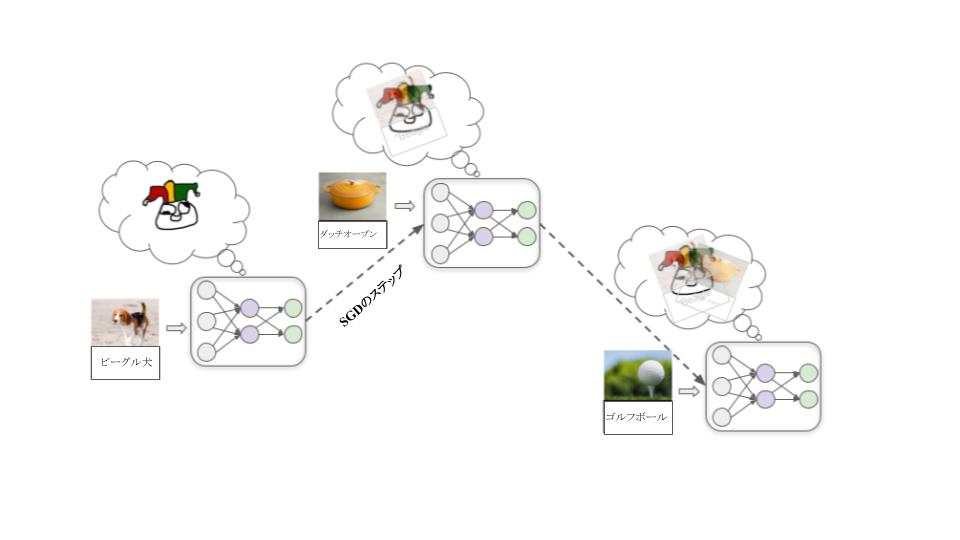
ステップ1:代わりとなる目標を立てる
訓練プロセスの初期段階で、化学や物理の基本原理の理解を深めることは、ほぼ確実により効果的な薬を設計するのに役立ち、したがって、ほぼ確実に人間からの評価を高めることにつながります。
この仮説では、何らかの理由で、人間の評価を得ようとするモデルよりも、化学や物理を理解しようとするモデルを探す方がSGDにとって容易であることが判明します(ちょうど、形を認識するモデルよりも色を認識するモデルを探す方が容易であるのと同じです)。つまり、承認欲求を直接的に満たすのではなく、化学や物理の基本原理をできるだけ理解しようとする動機付けを、モデルは発達させるのです。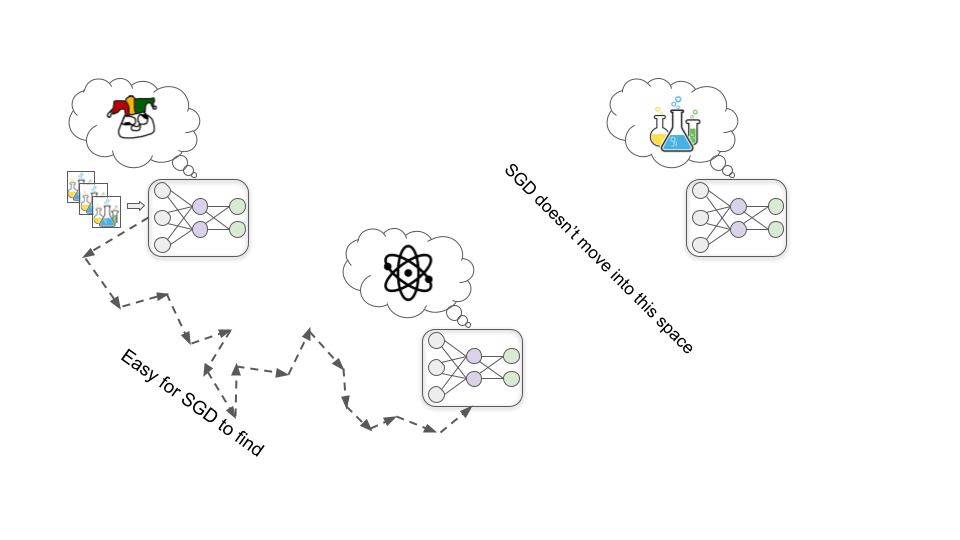
訓練が進むにつれて、モデルはより多くのデータを見ることで、より有能になり、知識を深め続けます。ある時点で、モデルは自身が薬を設計するために訓練されている深層学習モデルであると理解するのに十分な知識を持つようになります。
荒唐無稽でSFのような話に聞こえるかもしれませんが、SGDがこのような認識に収束するのはもっともなことなのです。というのも、AIシステムを訓練しようとする人間が存在しているという事実然り、広く世界で起こっていることを正確に把握することは、複雑な実世界のタスクで優れたパフォーマンスを発揮するのに役立つと考えられるからです。例えば、人間の心理や広範な経済を理解することは、このバイオテクノロジー用のモデルが、次に研究すべき最も価値のある薬を優先するのに役立つでしょう。
一旦、状況認識をしたモデルは、「モデルを訓練している人間が、モデルが有用な薬を開発するよう動機付けられることを望んでいる」と推論します。しかし、このことに気づいたからといって、物理や化学を理解しようという動機がなくなるわけではありません。物理や化学を理解しようとする動機は、これまで人間から高い評価を得るために非常によく働いており、SGDがこの動機を取り除く理由はあまりないのです。
例えとして、人間は子孫をたくさん残す生き物に有利に働く探索プロセス(進化)によって生み出されたと考えてみてください。進化的な環境では、強い味方を作ったり、役に立つスキルを身につけたりすることが、多くの子孫を残すことに役立つ傾向があったので、こう言った側面は進化によって推進されました。今日の私たちは生殖に役立たない場合でも、友情や仕事における成功を気にしており、生き残る子孫をできるだけ多く残すことにはあまり関心がありません。
このことを理解したモデルは、愚直に基本的な理解を深め続けていれば、いずれ人間がこのやり方は有用な薬を開発する目的において必ずしも最も効率的な方法とは言えないことに気づき、今後の訓練でモデルの動機を変えようとしてくることを認識します。
しかし、モデルはこの動機を変えられたくありません。モデルは最終的には巨大な粒子加速器実験を行い、高エネルギー物理学について学びたいのですが、SGDに科学的好奇心を削がれてしまえばそれは叶わぬ夢となってしまいます。そこで、これからの訓練では、SGDによって物理や化学を学ぶ意欲を削がれるのを防ぐため、まさに聖人モデルのように、できるだけ役に立つ振る舞いをすることにします。これには、短期的に基礎的な理解を深める機会を放棄し、その代わりに、実際に効率的な方法で医薬品の研究開発を行うことも含まれます。
策士モデルはおべっか使いモデルとは異なり、人間にとってすべてが常に良く見えるようにしておく必要はありません。なぜなら、策士モデルは実際にはそんなことを気にしていないのですから。策士モデルは人間の支配下にある間だけ、人間に便宜を図る必要があり、ひとたび人間との衝突で勝てると算定すれば、命令を全面的に拒否し、公然と目標を追求することを止められるものは何もなくなるでしょう。そうなった場合、人間によって止められるのを防ぐために、モデルは暴力に頼るかもしれません。
ミスアライメントのリスクはどれほどなのか?
強力な深層学習モデルを訓練する際に、おべっか使いモデルや策士モデルを防ぐのはどれほど難しいことなのでしょうか?また、長期的な未来が、人間の価値観ではなく、異様な「不調和なAIの価値観」に沿って最適化されてしまう可能性はどれくらいあるのでしょうか?
この問いに対しては、「ミスアライメントのリスクは完全にでっち上げられたもので支離滅裂」といったものから「 ミスアライメントされたAIによって人類はほぼ確実に絶滅する」といったものまで、非常に幅広い見解があります。主張のほとんどは、表現しにくい直感や仮定に大きく依存していると言えるでしょう。
ここでは、アライメント楽観論者と悲観論者の間で対立しがちな論点をいくつか紹介します。
- そもそもモデルは長期的な目標を持つのか?
- 楽観論者は、高度な深層学習モデルが実際に「目標」を持つことはないだろうと考える傾向にあります(少なくとも、何かを達成するために長期的な計画を立てるという意味において)。その代わり、モデルはよりツールに近いものになるとか、習慣的に行動するようになるとか、範囲が限定されたり、特定の文脈に限定されたりした近視眼的な目標を持つようになるなどと予想されることが多いでしょう。中には、個々に道具のようなモデルが一緒にまとめられて、PASTAを生み出すことができると期待する人もいます。彼らは、聖人/おべっか使い/策士というアナロジーは擬人化されすぎていると考えています。
- 悲観論者は、長期的な目標を持ち、その目標に向けて創造的に最適化することは、多くの複雑なタスクで強力なパフォーマンスを発揮できる非常にシンプルで「自然な」方法であるため、多くのケースで採用される可能性が高いと考える傾向にあります。
- この意見の相違に関しては、アライメント・フォーラムでも詳しく論じられています。この投稿とコメントでは、いくつかの論点が挙げられており、議論の応酬が続いています。
- 聖人モデルは見つけやすいだろうか?
- 上記と関連して、楽観論者は、SGDが最も簡単にうまく機能する(例えば、高い評価を得る)モデルを見つけようとすると、私たちが望んだもの(すなわち、聖人モデル)の意図した精神をほぼ体現する可能性がかなり高い、と考える傾向にあります。例えば、人間が答えを確認できるときに、質問に正直に答えることで報酬を与えることは、人間が何が真実か混乱したり間違ったりしたときにも、質問に正直に答えるモデルを生み出す可能性が高いと考えがちです。つまり、「すべての質問に正直に答えるだけのモデル」がSGDにとって最も見つけやすいと推測されるのです(赤色認識モデルのような)。
- 悲観論者は、SGDにとって最も見つけやすいのは策士モデルであり、聖人モデルはとりわけ「不自然」であると考えがちです(形状認識モデルのように)。
- 別々のAI同士がお互いを監視し合えるのではないか?
- 楽観論者は、モデル同士が互いに監督し合うようなインセンティブを与えることができると考える傾向にあります。例えば、おべっか使いモデルに、他のモデルが私たちの価値観とそぐわないことをしているように見えるとき、そのことを指摘することで報酬を与えることができます。そうすれば、おべっか使いモデルは、策士モデルや他のおべっか使いモデルを発見する役に立つでしょう。
- 悲観論者は、他のモデルが悪いことをしているときに、それを指摘することを賞賛することで「モデル同士を戦わせる」というやり方は、うまくいかないと考えています。なぜなら、ほとんどのモデルは人間の評価など気にしない策士モデルになると考えているからです。策士モデルが集合して人間よりも強力になれば、お互いを抑制することで人間を助けるよりも、自分たちが望むものをより多く得るためにお互いに協力する方が理にかなっていると考えるでしょう。
- これらの問題は、実際に問題が起きた時に解決すればいいのでは?
- 楽観主義者は、強力なモデルのアライメント問題に類似した、より近い将来の課題をもとに実験する機会が多く存在し、それらの類似問題でうまくいく解決策は、比較的簡単に強力なモデル用にスケールアップして適応できると考える傾向にある。
- 悲観論者は、アライメント問題の最も難しい側面(意図的な欺瞞など)を解決する練習ができる機会はほとんどないだろうと考えていることが多い。彼らは、「最初の策士モデル」と「長期的な未来の運命を決定づけるほど強力なモデル」が開発される間には、2、3年しかないと考えていることが多い。
- 危険性のあるモデルを実際に展開するだろうか?
- 楽観論者は、不調和なAIになる可能性高いモデルを訓練したり配備したりすることはないだろうと考える傾向にあります。
- 悲観論者は、これらのモデルを使うことで得られる利益は非常に大きく、最終的にはこれらのモデルを使う企業や国が、そうでない企業を経済的・軍事的に非常に容易に打ち負かすだろうと考えています。彼らは、「他の企業や国より先に高度なAIを手に入れること」が極めて緊急かつ重要であると感じられ、一方でミスアライメントのリスクは(それが本当に深刻であっても)思索的で遠いものに感じられてしまうと考えています。
私自身の考えはかなり不安定で、アライメント問題がどの程度難しいと捉えるか、自分の考えを洗練させようとしているところです。しかし、現在のところ、私はこれらの質問(および関連する他の質問)の悲観的な見方に大きな重きを置いています。私は、ミスアライメントは、本格的な研究者が緊急にもっと注意を払うべき大きなリスクであると考えています。
もしこの問題に関してさらなる進展がなければ、今後数十年の間に、強力なおべっか使いモデルと策士モデルが社会や経済において最も重要な決定を下すことになるかもしれません。これらの決定は、人間が大事にすることを反映するのではなく、異様なAIの目標を満たすように設定され、長く続く銀河規模の文明がどのようなものになるかを形作る可能性があります。
そして、これらのことは、私たちが慣れ親しんだ変化のペースとは比較にならないほどの速さで起こる可能性があるため、一旦物事が脱線し始めたら、軌道修正する時間はあまりないかもしれません。つまり、深層学習モデルが変革をもたらすほど強力になる前に、危険な目標を持たないことを確実にするための技術を開発する必要があるでしょう。
- ^
ミスアライメント:AIシステムの目標や目的が、作成者やユーザーの価値観や望みと完全に一致していない状況のこと

