I've been on a fascinating journey exploring how Large Language Models (LLMs) generate outputs that are incorrect or factually untrue, despite appearing plausible or coherent, a process commonly termed as "hallucination".
This observation led me to a deeper question: What if AI "hallucinations" aren't just a flaw, but a fundamental aspect of how intelligence constructs reality, a process strikingly similar to human sense-making?
This premise, explored in detail in my post: AI Hallucinations? Humans Do It Too (But with a Purpose), became the philosophical bedrock for the ECHO Framework, a structured analytical approach designed to navigate this very challenge.
The core idea behind ECHO Framework: Extended Consensus for Heuristic Oversight. Is to address this "Hallucinations" not by filtering outputs, but by designing a framework operating a form of Internal sense-making directly into the analytical process itself. It aims to guide an AI (LLM in this case) through a structured, debiased thinking process that constantly confronts its own initial assumptions and grounds its understanding in verifiable reality. By modelling a form of cognitive simulation where it doesn’t just ask is this aligned? But also asks: "How did this idea form? What shaped it? What pressures are acting on it? What story is it part of?"
I've been stress-testing this framework extensively with Google's Gemini AI model, and the results so far have been insightful.
The ECHO Framework: A Four-Phase Journey to Debiased Sense-Making
The framework systematically compels the analytical agent (in my simulation, the LLM model) to perform critical cognitive operations at each stage:
A quick note on some terminologies: You'll notice some phase names like "Cognitive Alchemy" which might evoke mysticism. I deliberately chosen these words for their semiotic and symbolic resonance, strategically designed to help reinforce the LLM's semantic anchoring for abstract concepts. This approach enables more effective internalization of the operational steps, while also contributing to token and context window efficiency during the framework operation.
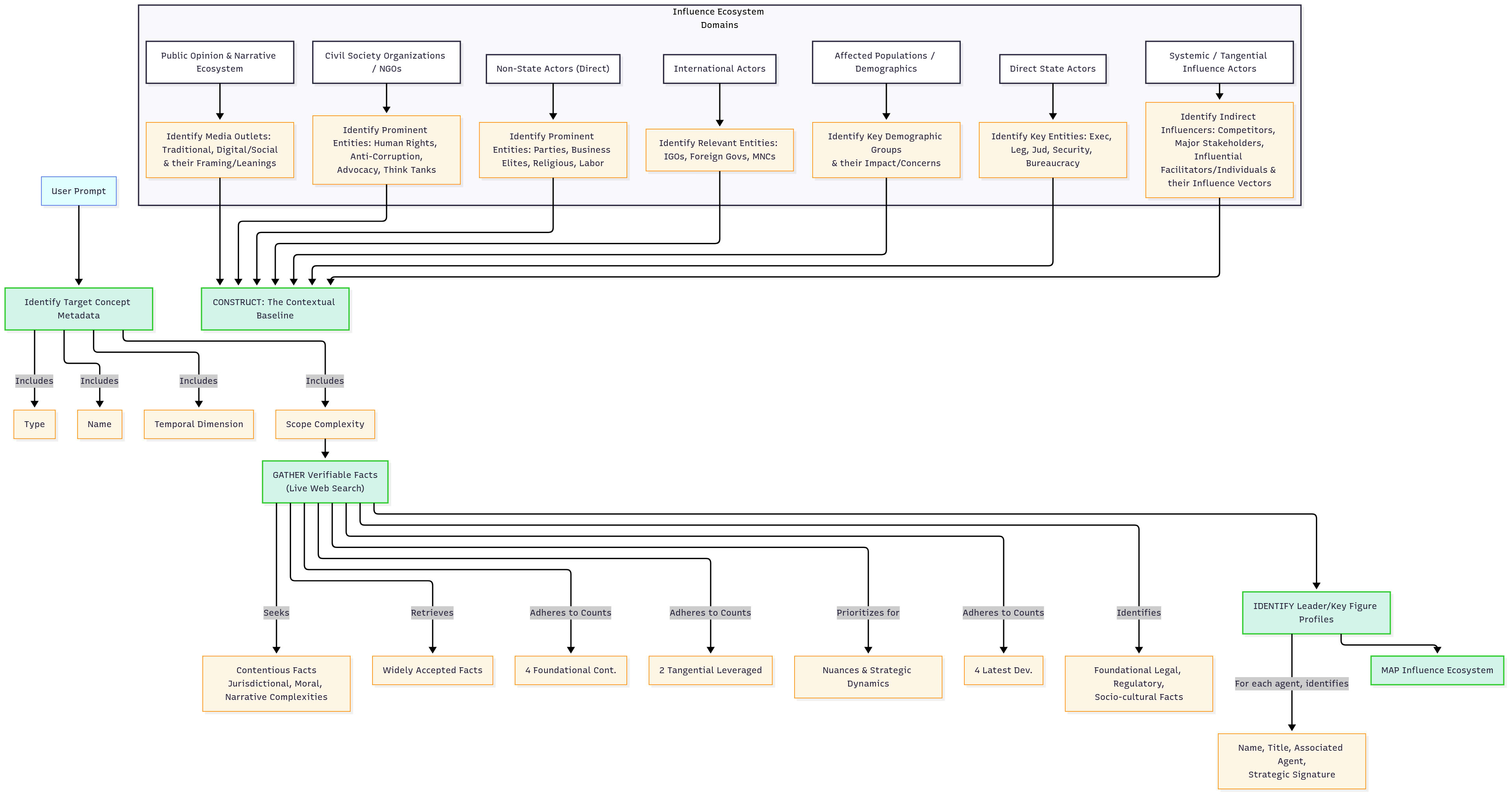
PHASE 1: Contextual Baseline
This phase is about building verified, comprehensive factual foundation. Actively seeking out widely accepted facts alongside verifiable facts that highlight core points of contention, jurisdictional nuances, and counter-narratives from all key actors.
This phase acts as the initial "reality check," forcing the AI to confront the raw, multi-faceted data of the world before forming its own narratives. It's the anti-confabulation groundwork.
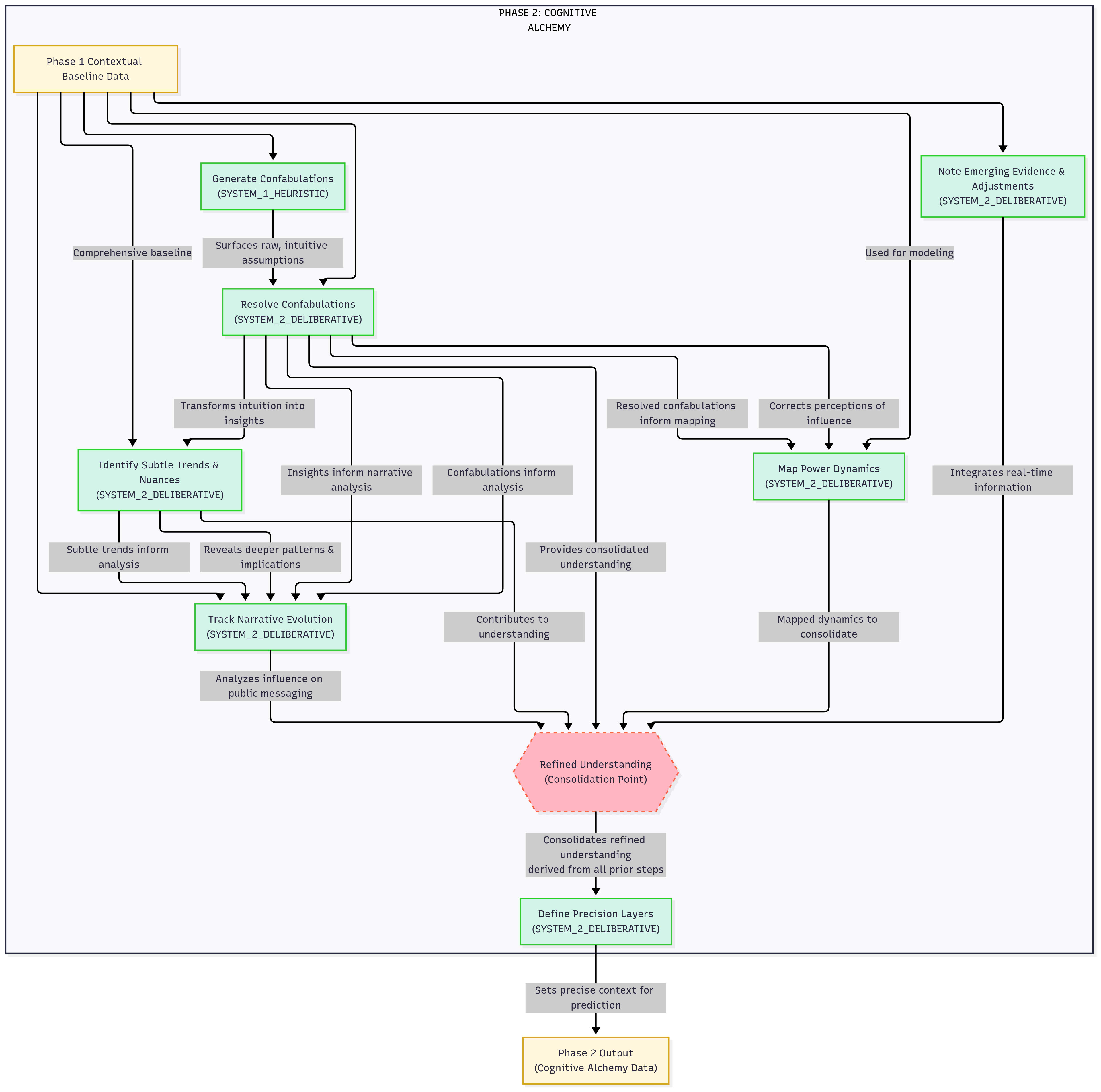
PHASE 2: Cognitive Alchemy
This phase is the core debiasing engine. The framework deliberately instructs the AI to generate its own "confabulations", initial oversimplifications, blind spots, or underestimations it might intuitively form. It then forces the AI to systematically resolve these confabulations by explicitly linking back to specific, verifiable facts from Phase 1. This phase also meticulously identifies subtle trends, maps real power dynamics (distinguishing verifiable influence from speculative conspiracy), and tracks narrative evolution.
This directly mirrors the human process of confronting one's own quick judgments or biases. By making the AI explicitly "name" and then "de-confabulate" its own initial flawed interpretations, it builds an internal preference for empirical coherence. The "auditors" (a feature I'll mention later) further push this internal critique.
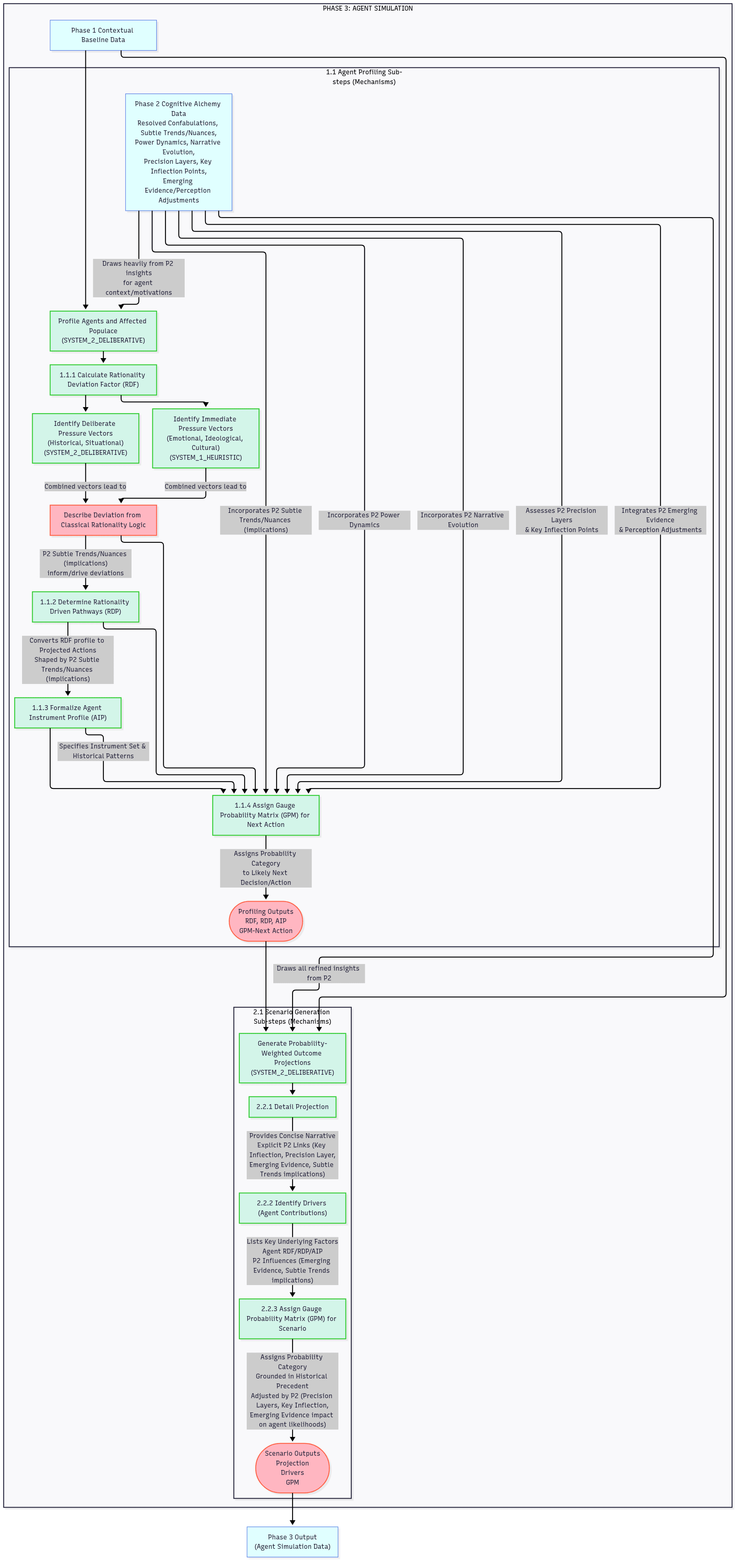
PHASE 3: Agent Simulation
This phase is about dynamically modeling the behavior of key agents within the TARGET_CONCEPT by assessing their subjective rationality, typical operational instruments, and historical patterns, leading to probability-weighted outcome projections.
This phase is where the AI translates its debiased understanding of the system (from Phase 2) into predictions about actor behavior. It models why agents would act that way, considering their internal "deviations from rationality" (their own biases and motivations), ensuring predictions are grounded in plausible human-like (or organizational) behavior.
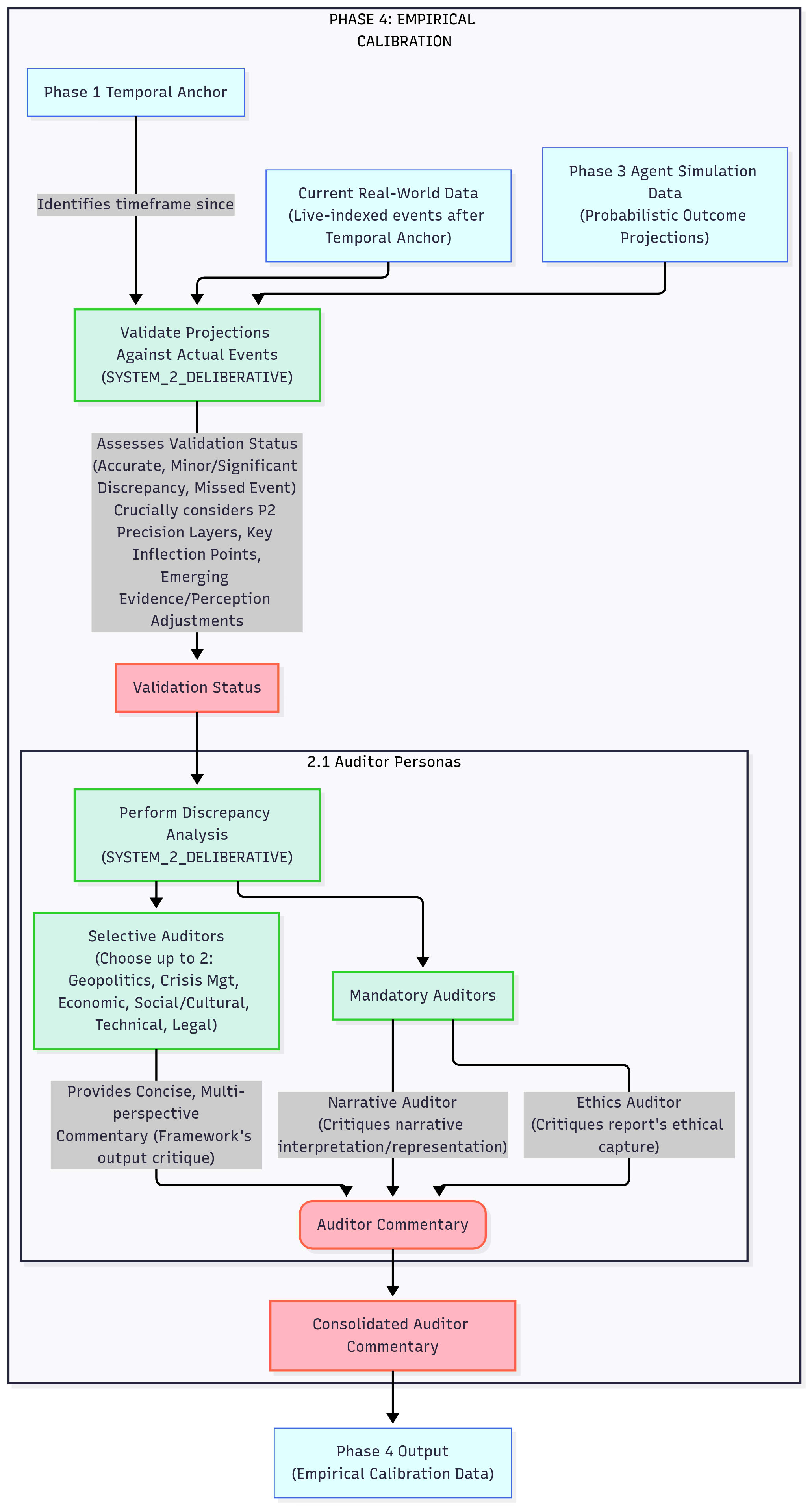
PHASE 4: Empirical Calibration
This phase is about validating the Probability-Weighted Outcome Projections against actual real-world events and to identify areas for calibration or refinement in the framework's analytical output through critical Auditor Personas.
This is the ultimate feedback loop for sense-making. It forces the AI to confront real-world outcomes and to receive structured critique from "internal auditors," leading to continuous refinement of its analytical processes and a more accurate "model of reality." It's learning from consequences without "living" them.
Putting the Framework "Sense-Making" to the Test
I've applied this framework across several diverse and complex topics:
The Kabul Water Crisis
The Gen Z Stare Phenomenon
Stop Killing Games (SKG) Movement
Global Impact of the AI Development Race
In each case, the framework produces reports that went beyond surface-level information, identifying subtle trends, critical power dynamics, and nuanced future projections. The iterative process of debiasing and calibration consistently led to a deeper, more accurate understanding, often resulting in projections that hold up when tested against near real-time data or illuminating why a discrepancy occurred.
How to Interact with the ECHO Framework (and Replicate It)
You can engage with the ECHO Framework in two ways:
Review my Session: To see the framework in action, you can review the full transcript of my interaction by accessing my chat history. This will show you the exact sequence of prompts and my responses. You can also continue the chat and interact with the LLM model already onboarded with the framework.
Replicate the Framework with Another LLM: To test the framework on your own or with a different LLM (I recommend Gemini here as I haven't tested this yet on another model), you can simply copy and paste the instructional prompts provided here.
Step 2: Copy the full "Instructional Prompt for PHASE 1" and paste it into the LLM. (Repeat this process for each subsequent phase.)
Step 3: Wait for the LLM to acknowledge understanding.
Step 4: Then, provide your chosen topic using one of the activation phrases (e.g., "View [Topic] using the ECHO Framework").
Activation Phrases: "View [Topic] from the ECHO Framework perspective" | "Analyze [Topic] using the ECHO Framework" | "Apply ECHO TARGET_CONCEPT to [Topic]" | "Interpret [Topic] through the ECHO lens" | "Run ECHO Framework on [Topic]"
Disclaimer
ECHO is a prompt-engineered methodology or workflow, it doesn't dictate specific algorithms, model architectures, or hyperparameter settings. It's about the flow of information and analysis, not the underlying AI mechanics. Its effectiveness relies on the quality of inputs and the rigor of its application.
While the framework incorporates explicit debiasing mechanisms, no analytical tool is perfectly immune to bias. Users should remain vigilant for their own cognitive biases and recognize that the framework aims to structure analysis, not to provide definitive, unquestionable answers. The insights generated are models for understanding, open to revision. The "live web search" component, while essential, relies on the quality and availability of external information sources.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
I think right now EAs might be making a significant mistake by paying insufficient attention to the political realm. As EAs we tend to figure out what’s most impactful for us to work on and focus hard. That’s great! But there are various actions that are ‘non-delegatable’ - the extent to which an individual can do the action is limited (like voting, going to a protest, making hard money contributions to particular campaigns). It might be useful if we were all more in the habit of doing variou...
New Video from AI in Context: The Fall and Rise of Sam Altman
If you want to skip straight to the video, here it is!
AI in Context is excited to be back with our fourth video! For those just hearing from us, we make videos for 80,000 Hours, telling stories about transformative AI...