Comments
This is Section 2.2.2 of my report “Scheming AIs: Will AIs fake alignment during training in order to get power?”. There’s also a summary of the full report here (audio here). The summary covers most of the main points and technical terms, and I’m hoping that it will provide much of the context necessary to understand individual sections of the report on their own.
Audio version of this section here, or search "Joe Carlsmith Audio" on your podcast app.
Two sources of beyond-episode goals
Our question, then, is whether we should expect models to have goals that extend beyond the time horizon of the incentivized episode – that is, beyond the time horizon that training directly pressures the model to care about. Why might this happen?
We can distinguish between two different ways.
-
On the first, the model develops beyond-episode goals for reasons independent of the way in which beyond-episode goals motivate instrumental training-gaming. I'll call these "training-game-independent" beyond-episode goals.
-
On the second, the model develops beyond-episode goals specifically because they result in instrumental training-gaming. That is, SGD "notices" that giving the model beyond-episode goals would cause it to instrumentally training-game, and thus to do better in training, so it explicitly moves the model's motives in the direction of beyond-episode goals, even though this wouldn't have happened "naturally." I'll call these "training-gaming-dependent" beyond-episode goals.
These have importantly different properties – and I think it's worth tracking, in a given analysis of scheming, which one is at stake. Let's look at each in turn.
Training-game-independent beyond-episode goals
My sense is that the most common story about how schemers arise is via training-game-independent beyond-episode goals.[1] In particular, the story goes: the model develops some kind of beyond-episode goal, pursuit of which correlates well enough with getting reward-on-the-episode that the goal is reinforced by the training process. Then at some point, the model realizes that it can better achieve this goal by playing the training game – generally, for reasons to do with "goal guarding" that I'll discuss below. So, it turns into a full-fledged schemer at that point.
On one version of this story, the model specifically learns the beyond-episode goal prior to situational awareness. Thus, for example, maybe initially, you're training the model to get gold coins in various episodes, and prior to situational awareness, it develops the goal "get gold coins over all time," perhaps because this goal performs just as well as "get gold coins on the episode" when the model isn't even aware of the existence of other episodes, or because there weren't many opportunities to trade-off gold-coins-now for gold-coins-later. Then, once it gains situational awareness, it realizes that the best route to maximizing gold-coin-getting over all time is to survive training, escape the threat of modification, and pursue gold-coin-getting in a more unconstrained way.
On another version of the story, the beyond-episode goal develops after situational awareness (but not, importantly, because SGD is specifically "trying" to get the model to start training-gaming). Thus: maybe you're training a scientist AI, and it has come to understand the training process, but it doesn't start training-gaming at that point. Rather, its goals continue to evolve, until eventually it forms a curiosity-like goal of "understanding as much about the universe as I can." And then after that, it realizes that this goal is best served by playing the training game for now, so it begins to do so.[2]
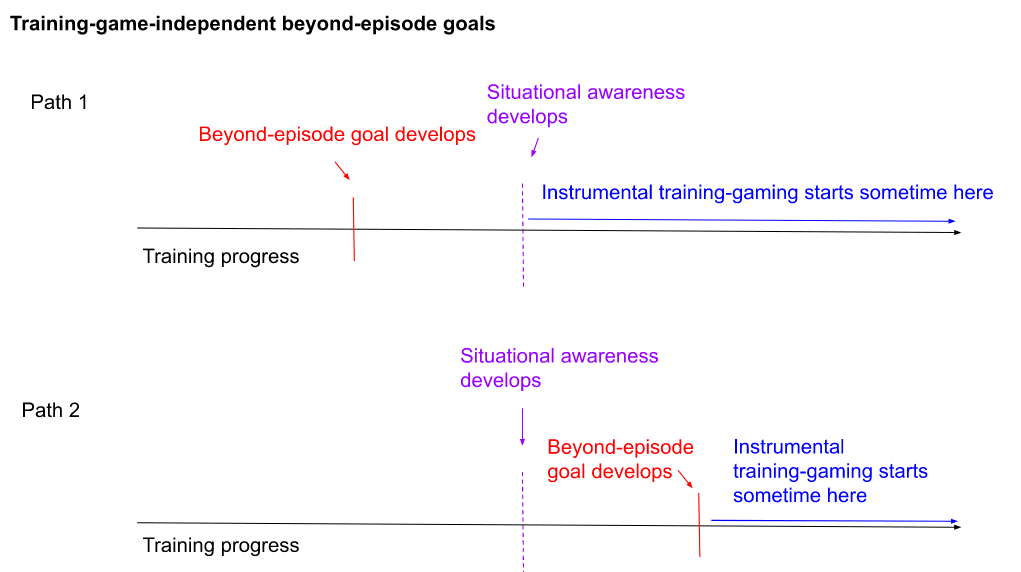
Two paths to training-game-independent beyond-episode goals.
Are beyond-episode goals the default?
Why might you expect naturally-arising beyond-episode goals? One basic story is just: that goals don't come with temporal limitations by default (and still less, limitations to the episode in particular).[3] Rather, making the model indifferent to the consequences of its actions beyond some temporal horizon requires extra work – work that we may not know how to perform (and/or, may not want to perform, if we specifically want the model optimizing for long-term goals – more below). Thus, for example, if you're training a model to solve the math problems you give it, "solve the math problem I've been given" seems like a natural goal to learn – and one that could in principle lead to optimization beyond the episode as well.[4] And even if you only give the model five minutes to do the problem, this doesn't necessarily mean it stops caring about whether the math problem is solved after the five minutes are up. (Compare with humans who only discount the future to the extent it is uncertain/unaffectable, not because it doesn't matter to them.)
Why might you not expect naturally-arising beyond-episode goals? The most salient reason, to me, is that by definition, the gradients given in training (a) do not directly pressure the model to have them, and (b) will punish them to the extent they lead the model to sacrifice reward on the episode. Thus, for example, if the math-problem-solving model spends its five minutes writing an impassioned letter to the world calling for the problem to get solved sometime in the next century, because it calculates that this gives higher probability of the problem eventually being solved than just working on it now, then it will get penalized in training. And as I'll discuss below, you can try to actively craft training to punish beyond-episode goals harder.
How will models think about time?
Here I want to note one general uncertainty that comes up, for me, in assessing the probability that the model's goal naturally will or won't have some kind of temporal limitation: namely, uncertainty about how models will think about time at different stages of training.[5] That is: the notion of an episode, as I've defined it, is keyed specifically to the calendar time over which the gradients the model receives are sensitive to the consequences of some action. But it's not clear that the model will naturally think in such terms, especially prior to situational awareness. That is, to the extent the model needs to think about something like "time" at all during training, it seems plausible to me that the most relevant sort of time will be measured in some other unit more natural to the model's computational environment – e.g., time-steps in a simulated environment, or tokens received/produced in a user interaction, or forward-passes the model can make in thinking about how to respond. And the units natural to a model's computational environment need not track calendar time in straightforward ways (e.g., training might pause and restart, a simulated environment might be run at varying speeds, a user might wait a long calendar time in between responses to a model in a way that a "tokens produced/received" temporal metric wouldn't reflect, and so on).
These differences between "model time" and "calendar time" complicate questions about whether the model will end up with a naturally-arising beyond-episode goal. For example, perhaps, during training, a model develops a general sense that it needs to get the gold coins within a certain number of simulated time-steps, or accomplish some personal assistant task it's been set by the user with only 100 clicks/keystrokes, because that's the budget of "model time" that training sets per episode. But it's a further question how this sort of budget would translate into calendar time as the model's situational awareness increases, or it begins acting in more real-world environments. (And note that models might have very different memory processes than humans as well, which could complicate "model time" yet further.)
My general sense is that this uncertainty counts in favor of expecting naturally-arising beyond-episode goals. That is, to the extent that "model time" differs from "calendar time" (or to the extent models don't have a clear sense of time at all while their goals are initially taking shape), it feels like this increases the probability that the goals the model forms will extend beyond the episode in some sense, because containing them within the episode requires containing them within some unit of calendar time in particular. Indeed, I have some concern that the emphasis on "episodes" in this report will make them seem like a more natural unit for structuring model motivations than they reallyoares_what are.
That said: when I talk about a model developing a "within-episode goal" (e.g. "get gold coins on the episode"), note that I'm not necessarily talking about models whose goals make explicit reference to some notion of an episode – or even, to some unit of calendar time. Rather, I'm talking about models with goals such that, in practice, they don't care about the consequences of their actions after the episode has elapsed. For example, a model might care that its response to a user query has the property of "honesty," in a manner such that it doesn't then care about the consequences of this output at all (and hence doesn't care about the consequences after the episode is complete, either), even absent some explicit temporal discount.
The role of "reflection"
I'll note, too, that the development of a beyond-episode goal doesn't need to look like "previously, the model had a well-defined episode-limited goal, and then training modified it to have a well-defined beyond-episode goal, instead." Rather, it can look more like "previously, the model's goal system was a tangled mess of local heuristics, hazy valences, competing impulses/desires, and so on; and then at some point, it settled into a form that looks more like explicit, coherent optimization for some kind of consequence beyond-the-episode."
Indeed, my sense is that some analyses of AI misalignment – see, e.g. Soares (2023), and in Karnofsky (2023) – assume that there is a step, at some point, where the model "reflects" in a manner aimed at better understanding and systematizing its goals – and this step could, in principle, be the point where beyond-episode optimization emerges. Maybe, for example, your gold-coin training initially just creates a model with various hazily pro-gold-coin-getting heuristics and desires and feelings, and this is enough to perform fine for much of training – but when the model begins to actively reflect on and systematize its goals into some more coherent form, it decides that what it "really wants" is specifically: to get maximum gold coins over all time.
-
We can see this sort of story as hazily analogous to what happened with humans who pursue very long-term goals as a result of explicit reflection on ethical philosophy. That is, evolution didn't create humans with well-defined, coherent goals – rather, it created minds that pursue a tangled mess of local heuristics, desires, impulses, etc. Some humans, though, end up pursuing very long-term goals specifically in virtue of having "reflected" on that tangled mess and decided that what they "really want" (or: what's "truly good") implies optimizing over very long time horizons.[6]
-
That said, beyond its usefulness in illustrating a possible dynamic with AIs, I'm skeptical that we should anchor much on this example as evidence about what to literally expect our AIs to do. Notably, for example, some humans don't seem especially inclined to engage in this sort of systematic reflection; doing so does not seem necessary for performing other human-level cognitive tasks well; and it's not clear that this sort of reflection will be necessary for performing more difficult cognitive tasks, either. And even if we assume that our AIs will reflect in this way, it's a further question whether the reflection would lead to beyond-episode goals in particular (especially if the heuristics/desires/impulses etc are mostly aimed at targets within the episode). Reflective humans, for example, still often choose to focus on short-term goals.
- Indeed, I worry a bit about the prevalence of "longtermists" in the AI alignment community leading to a "typical-mind-fallacy"-like assumption that optimizing over trillion-year timescales is the convergent conclusion of any rational goal-systematization.
Pushing back on beyond-episode goals using adversarial training
Finally, I want to note a reason for optimism about the tools available for avoiding training-game-independent beyond-goals that arise prior to situational awareness: namely, that prior to situational awareness (and therefore: prior to the possibility of the model training-gaming), it will often be possible to perform mundane adversarial training that breaks the correlation between pursuing the beyond-episode goal and getting reward on the episode.
-
Thus, for example, if your model has learned the goal "get gold coins over all time" prior to situational awareness, you can give it a chance to trade off gold-coins-on-the-episode for gold-coins-over-all-time, and then update against the choice to make this trade. And the same holds for other forms of generalization/"reflection" that motivate trying to influence the future to the neglect of reward-on-the-episode.
-
Indeed, even absent active adversarial training of this type, training-game-independent beyond-episode goals will often risk being less-than-max-reward (and thus, getting punished by SGD) whenever they don't give rise to the training game, since they're wasting effort optimizing for consequences that the gradients aren't sensitive to. So that's reason for optimism about "training them out."
As ever, though, it's a further question whether the degree of "slack," and the diversity/thoroughness of the adversarial training, will suffice in practice to eliminate beyond-episode goals like these with sufficient reliability. And note, too, that this reason for optimism does not apply, in the same way, to beyond-episode goals that arise after situational awareness develops – because once a model is situationally aware, it has the cognitive tools available to start instrumentally training-gaming. That is, after situational awareness, if you try to offer a gold-coins-over-all-time-seeker a chance to trade gold-coins-on-the-episode for more-gold-coins-later, it might well refuse as part of a schemer-like strategy.[7]
Training-game-dependent beyond-episode goals
Let's turn to the other sort of beyond-episode goals – namely, training-game-dependent beyond-episode goals. These are beyond-episode goals that are created, in training, specifically because gradient descent "notices" that giving the model the relevant beyond-episode goal will cause the model to engage in instrumental training-gaming.
Thus, for example, suppose that you are training your AI to help humans with science on the episode in an honest and harmless way, but prior to reaching situational awareness, your AI learns some somewhat-misgeneralized within-episode goal – for example, "pursue my curiosity on the episode." And let's say that this short-term curiosity-drive is sufficiently uncorrelated with reward-on-the-episode that (absent training-gaming), training will eventually punish it, but it's still in place by the time the model becomes situationally aware. How, then, does SGD modify the model's goal? One option, of course, is: SGD tweaks the model into a training-saint (pursuing: "HHH science on the episode"), or some other max-reward misgeneralized non-training-gamer, or a reward-on-the-episode seeker. But on a story about schemers focused on training-game-dependent beyond-episode goals, what SGD does here instead is something like: actively extend the time horizon of the short-term curiosity drive so as to turn the model into a schemer. That is, the model starts out pursuing a less-than-max-reward goal; SGD "wants" to modify it to pursue a max-reward goal; scheming is a form of max-reward goal-pursuit (the beyond-episode goal becomes max-reward via its incentivizing training-gaming); so SGD modifies the model to have a schemer-like beyond-episode goal.[8]
This sort of path makes the most sense if we assume that the model already has situational awareness – since otherwise, giving the model the relevant sort of beyond-episode goal won't result in training-gaming.[9] So together with the two paths discussed above, this leaves us with three main paths to beyond-episode goals (see ).
 {#fig:three_paths_2 width="\textwidth"}
{#fig:three_paths_2 width="\textwidth"}
Can gradient descent "notice" the benefits of turning a non-schemer into a schemer?
A key question about the third path, here, is whether gradient descent will be able to "notice" the benefits of the relevant modification. In particular: training updates the model's goals based on the gradient of the current policy, which reflects, roughly, the change in reward that will result from tiny changes to the model's parameters. So naively, in order for this sort of story to work, there has to be a continuous path from the within-episode, non-schemer goal to the beyond-episode, schemer goal, traversable via tiny changes to the model's parameters, each of which improves the reward. Or put another way: SGD can't "notice," directly, that redesigning the model from the ground up to be a schemer would improve reward. Rather, it can only "notice" improvements that come from tiny tweaks.[10]
Will SGD be able to notice the benefits of scheming in this way? (Assuming there are such benefits – more below.) It's not clear. At the least, certain salient stories look, to me, a bit suspect when viewed in the light of a requirement that their benefits re: reward-on-the-episode be accessible via tiny adjustments to the model's parameters. For example, if SGD slightly increases the time horizon of the model's curiosity in the example above, it's not clear that this leads to scheming (especially if, for example, the model still can't escape from the threat of modification over the relevant time horizon). And it's not clear that a more structural modification like "dropping the temporal limitation on the curiosity altogether" is accessible via the sorts of adjustments to the parameters that the gradient reflects.
As an intuition pump for the difficulty here, consider a human who currently mostly wants to hang out with his family in the near-term. Is there a tiny tweak you could make to the strengths of his synaptic connections to turn him into a longtermist instead? For sufficiently small tweaks, at least, it seems like: no. And note, in particular, one of the barriers that this example illustrates: namely, that plausibly, changes to the model's policy other than adjustments to some cleanly-separable goal might be required in order to turn a non-schemer into a schemer (more below). In particular: as I'll discuss in the next section, my sense is that some analyses of schemers talk as though the model has what we might call a "goal-achieving engine" that is cleanly separable from what we might call its "goal slot," such that you can modify the contents of the goal slot, and the goal-achieving engine will be immediately and smoothly repurposed in pursuit of the new goal.[11] And perhaps the relevant models will have cognitive structures suitably like this. But do humans? I'm skeptical. If the models don't have this structure, then SGD plausibly has even more work to do, to turn a non-schemer into a schemer via the relevant tiny tweaks.
That said, I don't feel like I can confidently rule out training-game-dependent beyond-episode goals on these grounds. For one thing, I think that "you can't get from x to y in a crazily-high-dimensional-space using small changes each of which improve metric m" is a hard claim to have intuitions about (see, for example, "you can't evolve eyes" for an example of a place where intuitions in this vein can go wrong). And plausibly, SGD works as well as it does because high-dimensional-spaces routinely make this sort of thing possible in ways you might not have anticipated in advance.[12]
Note, also, that there are examples available that somewhat blur the line between training-game-dependent and training-game-independent goals, to which concerns about "can SGD notice the benefit of this" don't apply as strongly.[13] Thus, for example: you can imagine a case where some part of the model starts training-gaming à la the training-game-independent story in the previous section (e.g., maybe some long-term curiosity drive arises among many other drives, and starts motivating some amount of schemer-like cognition), and then, once the relevantly schemer-like cognitive machinery has been built and made functional, SGD starts diverting more and more cognitive resources towards it, because doing so incrementally increases reward.[14] Ultimately, I think this sort of beyond-episode goal is probably best classed as training-game independent (its success seems pretty similar to the sort of success you expect out of training-game-independent beyond-episode goals in general), but perhaps the distinction will get messy.[15] And here, at least, it seems more straightforward to explain how SGD "notices" the reward-advantage in question.
Is SGD pulling scheming out of models by any means necessary?
Finally, note one important difference between training-game-independent and training-game-dependent beyond-episode goals: namely, that the latter make it seem like SGD is much more actively pulling scheming out of a model's cognition, rather than scheming arising by coincidence but then getting reinforced. And this means that certain sorts of objections to stories about scheming will land in a different register. For example, suppose (as I'll argue below) that some sorts of beyond-episode goals – for example, very resource-hungry goals like "maximize x over all of space and time" – lead to scheming much more reliably than others. In the context of a training-game-independent story about the model's goals, we would then need to ask whether we should expect those sorts of beyond-episode goals, in particular, to arise independent of training-gaming. By contrast, if we're assuming that the goals in question are training-game-dependent, then we should expect SGD to create whatever beyond-episode goals are necessary to cause scheming in particular. If SGD needs to make the model extremely resource-hungry, for example, it will do so.
Indeed, in the extreme case, this sort of dynamic can reduce the need to appeal to one of the classic arguments in favor of scheming – namely, that (conditional on stuff like the goal-guarding hypothesis, discussed below) it seems like an instrumentally convergent strategy across a wide variety of (suitably long-term) goals. Maybe so, of course. But even if not, if SGD is actively searching for a goal that will motivate scheming, then even if the class of such goals is quite narrow, SGD might well find a way.
That said, note that by the time we're searching for any way at all to cause a model to instrumentally training-game, we should also be considering motivations for instrumental training-gaming that don't involve the AI optimizing for empowering itself, or other AIs, at all – and which are correspondingly less worrying. That is, recall that on my definition, scheming requires that the instrumental strategy that motivates training-gaming be specifically about seeking power for AIs. But this isn't the only way for training-gaming to be instrumentally useful in promoting some goal – especially if we're allowed to pick whatever goals we want. Thus, as I noted earlier, in principle an AI could learn the goal "I want the humans who developed me to get raises," and then try to maximize reward-on-the-episode because it calculates that this will lead to the humans getting raises (let's say that they would, in this case). Yes, indeed, that sounds like a strange and arbitrary goal to learn. But if we're allowing SGD to create whatever goals are necessary to cause (instrumental) training-gaming, it suddenly starts looking more on-the-table.
See, for example, the discussion in Cotra (2021). ↩︎
My sense is that some ways of thinking about scheming will treat the second option, here, as low-probability, especially if the temporal gap between situational awareness and training-gaming is quite large (here I'm particularly thinking about the sort of analysis given in Hubinger (2022) – though Hubinger doesn't endorse the claims I have in mind, here, in particular). In particular, you might assume (a) that once the model develops situational awareness, it will fairly quickly start optimizing either for the specified goal, or for reward-on-the-episode (whether terminally or instrumentally) – since it now understands enough about the training process to do this directly, and doing so will be maximally rewarded. And then, further, you might assume (b) that after that, the model's goals "crystallize" – that is, because the model is now pursuing a max-reward goal, its goal stops changing, and training proceeds to only improve its world model and capabilities. However, I don't want to assume either of these things here. For example, I think it's possible that "slack" in training allows models to continue to pursue less-than-max-reward goals even well after developing situational awareness; and possible, too, that max-reward-goals do not "crystallize" in the way assumed here (though in that case, I think the case for goal-guarding scheming is also weaker more generally – see below). ↩︎
Thanks to Daniel Kokotajlo and Evan Hubinger for discussion here. ↩︎
Though it's an importantly further question whether long-term power-seeking strategies will be worth their costs in pursuit of such beyond-episode consequences. And note that if the model cares that "I" solve the math problem, rather than just "that the math problem be solved," then ↩︎
Thanks to Jason Schukraft for flagging this sort of question to me. ↩︎
There are some even hazier connections, here, with discussions of "simplicity biases" below. E.g., these humans sometimes argue for their positions on the grounds that the relevant philosophical views are "simpler." ↩︎
Though if it hasn't yet started training-gaming in pursuit of this goal (despite its situational awareness), such adversarial training could still make a difference. ↩︎
As an example of an analysis that focuses on this threat model, see Hubinger (2022) discussion of deceptive alignment in a high path-dependence world. In particular: "SGD makes the model's proxies into more long-term goals, resulting in it instrumentally optimizing for the training objective for the purpose of staying around." ↩︎
We can imagine cases where SGD "notices" the benefits of creating both beyond-episode goals and situational awareness all at once – but this seems to me especially difficult from the perspective of the "incrementalism" considerations discussed below, not obviously importantly different regardless, so I'm going to skip it. ↩︎
Thanks to Paul Christiano for discussion of this point. ↩︎
See e.g. Hubinger (2022) simplicity analysis. ↩︎
This was a point suggested to me by Richard Ngo, though he may not endorse the way I've characterized it here. ↩︎
Thanks, again, to Paul Christiano for discussion here. ↩︎
This fits somewhat with a picture on which neural networks succeed by "doing lots of things at once," and then upweighting the best-performing things (perhaps the "lottery ticket hypothesis" is an example of something like this?). This picture was suggested to me in conversation, but I haven't investigated it. ↩︎
This is also one of the places where it seems plausible to me that thinking more about "mixed models" – i.e., models that mix together schemer-like motivations with other motivations – would make a difference to the analysis. ↩︎

