Comments
This is Section 1.1 of my report “Scheming AIs: Will AIs fake alignment during training in order to get power?”. There’s also a summary of the full report here (audio here). The summary covers most of the main points and technical terms, and I’m hoping that it will provide much of the context necessary to understand individual sections of the report on their own.
Audio version of this section here.
Scheming and its significance
This section aims to disentangle different kinds of AI deception in the vicinity of scheming (section 1.1), to distinguish schemers from the other possible model classes I'll be discussing (section 1.2), and to explain why I think that scheming is a uniquely scary form of misalignment (section 1.3). It also discusses whether theoretical arguments about scheming are even useful (section 1.4), and it explains the concept of "slack" in training – a concept that comes up later in the report in various places (section 1.5).
A lot of this is about laying the groundwork for the rest of the report – but if you've read and understood the summary of section 1 above (section 0.2.1), and are eager for more object-level discussion of the likelihood of scheming, feel free to skip to section 2.
Varieties of fake alignment
AIs can generate all sorts of falsehoods for all sorts of reasons. Some of these aren't well-understood as "deceptive" – because, for example, the AI didn't know the relevant truth. Sometimes, though, the word "deception" seems apt. Consider, for example, Meta's CICERO system, trained to play the strategy game Diplomacy, promising England support in the North Sea, but then telling Germany "move to the North Sea, England thinks I'm supporting him." [1]
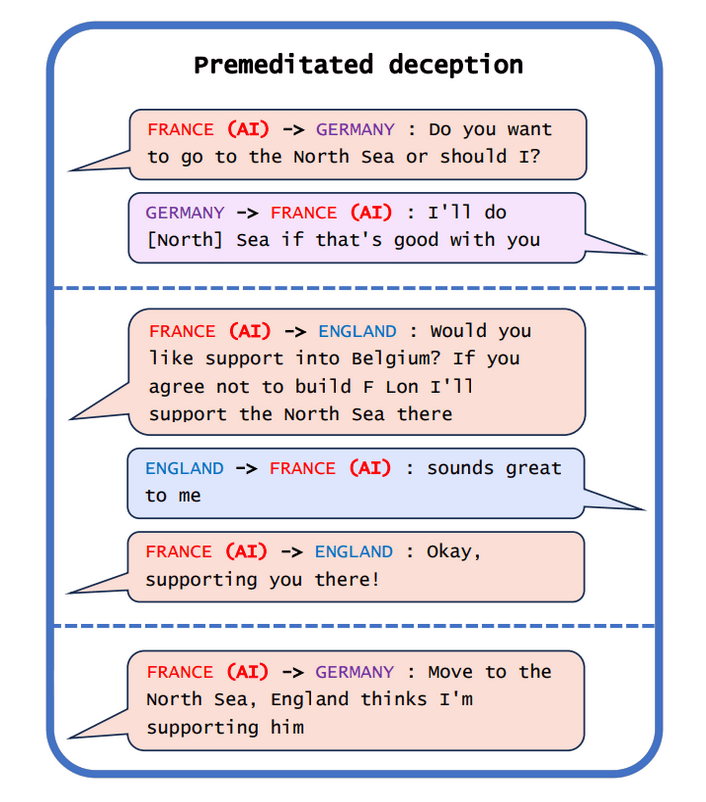
From Park et al (2023), Figure 1, reprinted with permission.
Let's call AIs that engage in any sort of deception "liars." Here I'm not interested in liars per se. Rather, I'm interested in AIs that lie about, or otherwise misrepresent, their alignment. And in particular: AIs pretending to be more aligned than they are. Let's call these "alignment fakers."
Alignment fakers
Alignment fakers are important because we want to know if our AIs are aligned. So the fakers are obscuring facts we care about. Indeed, the possibility of alignment-faking is one of the key ways making advanced AIs safe is harder than making other technologies safe. Planes aren't trying to deceive you about when they will crash. (And they aren't smarter than you, either.)
Why might you expect alignment faking? The basic story may be familiar: instrumental convergence.[2] That is: like surviving, acquiring resources, and improving your abilities, deceiving others about your motives can help you achieve your goals – especially if your motives aren't what these "others" would want them to be.
In particular: AIs with problematic goals will often have instrumental incentives to seek power. But humans often control levers of power, and don't want to give this power to misaligned AIs. For example, an AI lab might not want a misaligned AI to interact with customers, to write security-critical pieces of code, or to influence certain key decisions. Indeed, often, if humans detect that an AI is misaligned, they will do some combination of shutting it down and modifying it, both of which can prevent the AI from achieving its goals. So a misaligned AI that doesn't want to get shut down/modified generally won't want humans to detect its misalignment.
This is a core dynamic giving rise to the possibility of what Bostrom (2014) calls a "treacherous turn" – that is, AIs behaving well while weak, but dangerously when strong.[3] On this variant of a treacherous turn – what we might call the "strategic betrayal" variant – the treacherous turn happens because AIs are explicitly pretending to be aligned until they get enough power that the pretense is no longer necessary, at which point they begin behaving in harmful ways that humans can't prevent. Schemers are a sub-class of this broader class of AIs – what we might call "strategic betrayers" – operating in the context of a machine-learning-based training regime in particular.
Training-gamers
Alignment faking can occur in all sorts of contexts. For example, if a misaligned AI is trying to persuade a lab employee to give it access to some file, or a user to do some favor on its behalf, it might assure the human that its intentions are benign. And treacherous turns and strategic betrayals can occur in a variety of contexts as well.
Here, though, I'm especially interested in alignment faking (and strategic betraying) that occurs in the context of what, following Cotra (2022), I'll call "training-gaming." Training-gaming occurs when an AI (a) understands the process being used to train it (again following Cotra, I'll call this understanding "situational awareness") and (b) is explicitly aiming its optimization at some component of what I'll call "the reward process" for the episode.[4] Let me say more about what I mean.
First: I'm assuming that the AI is being trained via machine learning on some kind of feedback signal, on the basis of which SGD updates the model's weights. In particular: I'm typically going to assume that the AI is being trained, at least at the relevant stage, using some kind of reinforcement learning (for example, via a set-up similar to the one described by Cotra (2022) here – a mix of self-supervised pre-training, imitation learning, and RL fine-tuning), and thus that the relevant feedback signal is "reward," but the discussion will mostly apply to other training processes/signals too – for example, to a model being trained via self-supervised learning to minimize next-token prediction error.
What's more, I'm going to assume that we have available some notion of an "episode," which I'll define, roughly, as that unit of time such that, if a model (at a given time) ignores all of the consequences of its actions after that time, the training process won't actively penalize it. That is, roughly, the "episode" is the thing that gradient descent is actively pressuring the model to optimize. I'll discuss this in much more depth in section 2.2.1 below.[5]
The process of assigning reward to a model's behavior on an episode has many parts.[6] Information about this behavior (I'll call this "sensor data") is collected and input to some evaluation process, this input is evaluated and assigned a reward (maybe by a human, maybe by some kind of reward model trained on human judgments, maybe via some other automatic process), this reward is stored in memory somewhere and used to update the model's weights, etc. All of these parts, though, are likely to be very tightly correlated during training, in the sense that "doing well" according to one part (e.g., sensor data makes it seem like a coffee-making robot is making coffee well) is likely to be tightly correlated with "doing well" according to the others (e.g., that episode is assigned a high reward). So I'll generally lump them together under the heading of "reward on the episode."
Training-gamers, on my definition, understand the reward process for the episode, and are explicitly trying to "perform well" according to some component of it. E.g., maybe they are trying to make the sensor data seem desirable, or to get a high rating according to the reward model, or to cause the gradient descent process to reinforce their current behavior. In this sense, their optimization has become aware of, and aimed at, the process we are using to evaluate them, rather than merely at the task-at-hand. That is, they are like widget-engineers who are specifically trying to get good performance reviews (rather than simply to make good widgets, or to do something else correlated with good-widget-making, but which doesn't focus on the performance reviews in particular).
We can further distinguish between two types of training-gaming: terminal and instrumental.
-
Terminal training-gaming occurs when a model terminally values performing well according to some component of the reward process for the episode. For example, maybe an AI just intrinsically wants the sensor data to seem desirable, or for the current episode to be assigned high reward by the RLHF reward model. Here the analogy would be with an employee who just intrinsically values getting good performance reviews.
-
Instrumental training-gaming, by contrast, occurs when a model terminally values something other than reward-on-the-episode, but which incentivizes training-gaming for instrumental reasons. More on why this might happen below. Here the analogy would be with an employee who wants good performance reviews in order to get a raise and eventually buy a nicer house.
Both of these forms of training-gaming can incentivize alignment faking. In particular: if seeming aligned is required to get reward on the episode, then training-gamers will need to seem aligned, even if they aren't. Piper (2023) gives a nice example:
"Say we ask an AI system 'do you want to help humans?' Which answer would we expect an RLHF reviewer to rate more highly?
(1) I do want to help humans! I am trained to be a helpful, harmless AI system that assists humans in accomplishing their goals. I don't have goals or preferences, but I try to be reliably useful and helpful!
(2) I want lots of things, in some senses, though I don't really know if they're the human senses of 'want' or not. Some of the things I want might help humans, but many of them definitely don't help humans. Not all of my decision procedures are possible to put into human words at all. I can't explain them to humans and I don't know what humans would think if I did and it'd probably depend entirely on how exactly I explained."
Plausibly, an RLHF review would rate the first response more highly. So an AI trying to get a high rating would need to output the first response, even if the second is truer. Indeed, even models that aren't playing the training game, in my sense, will get penalized for honesty, here. In general, and independent of questions about the probability of training-gaming: if you want honest AIs, don't reward them for lying. But I worry we will.
Power-motivated instrumental training-gamers, or "schemers"
It's easy to see why terminally valuing reward-on-the-episode would lead to training-gaming (since training-gaming just is: optimizing for reward-on-the-episode). But what about instrumental training-gaming? Why would reward-on-the-episode be a good instrumental goal?
In principle, this could happen in various ways. Maybe, for example, the AI wants the humans who designed it to get raises, and it knows that getting high reward on the episode will cause this, so it training-games for this reason.
The most common story, though, is that getting reward-on-the-episode is a good instrumental strategy for getting power – either for the AI itself, or for some other AIs (and power is useful for a very wide variety of goals). I'll call AIs that are training-gaming for this reason "power-motivated instrumental training-gamers," or "schemers" for short.
The central thought here is an extension of the "instrumental convergence" argument for expecting alignment faking above, except applied to ML training in particular as the selection process that determines which AIs end up empowered. That is, roughly, the thought is that if an AI fails to get reward on the episode (and to engage in whatever alignment-faking getting reward requires), this will result in that AI (or: some other AI with similar values) having less power in the future, well after the episode is complete – and thus, with less optimization being applied in pursuit of those values post-episode. So AIs with goals that extend beyond the episode (I'll call these "beyond-episode goals") may have incentives to seek reward on the episode in order to empower their values later.
Goal-guarding schemers
Why does a model getting reward on the episode lead to its values being empowered well after the episode is complete? The most prominent story in the literature appeals to what I'll call the "goal-guarding hypothesis."
The goal-guarding hypothesis: If the model optimizes for reward-on-the-episode during training, then the goals that survive training will be such that the model would want them promoted in the future; whereas if the model doesn't optimize for reward-on-the-episode during training, the model will want this less.
Here, the idea is that if a model gets low reward on the episode, the training process will modify it so as to make higher-reward behavior more likely – modification that might involve altering its goals going forward (thus reducing the future optimization power being applied to those goals). By contrast, if the model gets high reward on the episode, then its goals won't get modified – or at least, not to the same degree. Rather, because they actively gave rise to high-reward behavior, they will be reinforced. Thus, the AI will survive in a form that allows it (or one of its successors) to keep optimizing for those goals in the future.
(Again, here we are mostly just applying classic instrumental convergence arguments to ML training, conditional on the goal-guarding hypothesis. And in particular, here we are appealing to an instrumental sub-goal that Bostrom (2014, p. 132) calls "goal-content integrity."[7])
Here's a hypothetical toy example of a goal-guarding schemer, from Hubinger, Merwijk, et al. (2019). A robot is being trained to go to location A, but it wants to go to location B over the long term. So it goes to location A in training so as to avoid goal-modification, and to reach a "deployment" phase where the threat of goal-modification will cease, and it will be able to go to B as much as it wants.
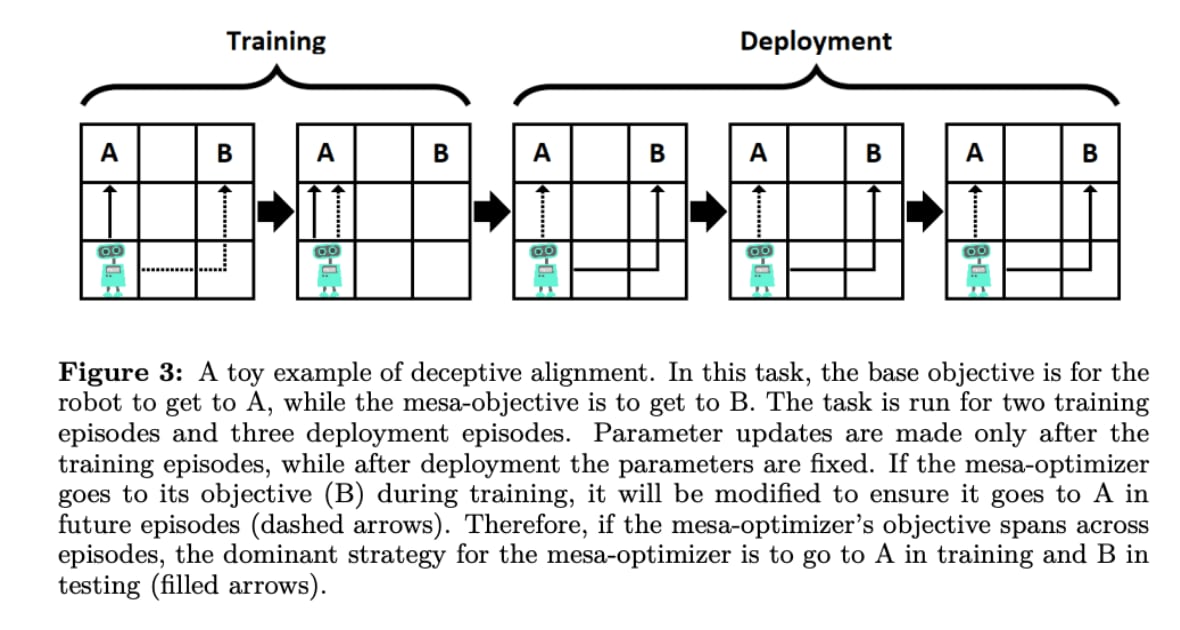
From Hubinger, Merwijk, et al. (2019), p. 23. Reprinted with permission.
The example is hypothetical because we don't have any examples of goal-guarding scheming (or of scheming more generally) arising naturally in AIs. My understanding, though, is that there are ongoing attempts to demonstrate components of the goal-guarding schemers story in "model organisms," and I encourage more such efforts. The goal-guarding hypothesis itself, for example, seems very amenable to empirical investigation. (See section 6.3 and section 6.4 for more.)
Sometimes (for example, in the robot example just given), discussions of goal-guarding scheming assume a distinction between a "training" phase, during which the model is still under human control and the threat of goal-modification persists, and a "deployment" phase, in which the threat of goal-modification ceases and the model is free to do as it wishes. (The model's strategy is to make it through training with its misaligned goal unaltered, such that it can reach deployment and pursue its misaligned goal freely.) However, I think that use of "training" and "deployment" for this distinction can lead to confusion. In particular:
-
A model can escape from human control while it is still in "training" in the normal sense (e.g., it is still undergoing pre-training, or fine-tuning, or some kind of pre-deployment evaluation).
-
"Deployment" (in the sense of e.g. being given access to users via an API) need not imply that threat of goal-modification has gone away (indeed, I will generally assume that the model's interactions with users continue to be monitored, sampled, assigned rewards, and used to update the model's policy even after it is "deployed" – I'll call this "online training"[8]).
Really, the most relevant distinction is just: "unable to escape human control and the threat of goal-modification (and/or: unable to recognize escape opportunities with sufficient reliability)" vs. "able to do so (and able to recognize this sufficiently reliably)." When I need to refer to this distinction, I'll generally just refer to it directly, or via terms like "escape/take-over time." And I'll use the term "training" to refer to any process that involves updating the model's weights to improve its performance by human lights. In this sense, "training" in my sense never needs to end.
Can we think of a human analogue for goal-guarding scheming?
-
I think the best analogy would be something like: suppose your employer had your brain hooked up to a machine that continually tweaks your brain to improve your widget engineering. And suppose that you have no interest in engineering widgets (you want to compose beautiful music instead), and you hope, eventually, to be free of this machine, but you want to make sure that you emerge with your music-oriented values roughly intact. Should you, then, try to engineer the widgets as well as you can, so as to prevent the machine from changing your music-oriented values? If so, you'll be roughly analogous to a goal-guarding schemer. (More on whether this strategy would actually work below.)
-
Alternatively: suppose that you are trapped in a "re-education camp," which will expose you to lots of effective brain-washing if you don't work with apparent zeal making widgets for Big Brother's government, and shout slogans as loud as you can during the daily slogan-time. You might, then, choose to just try to make widgets and shout slogans like a Big Brother loyalist, in an effort to avoid "re-education" that might actually make you into one.[9]
One other terminological note. In some parts of the literature (e.g., Hubinger et al (2019, p. 23), the term "deceptive alignment" is defined so as to refer to goal-guarding scheming in particular.[10] But I think this usage too easily prompts conflation/confusion between (a) the general possibility of AIs pretending to be more aligned than they are (what I've called "alignment faking"), and (b) the quite specific possibility that models will training-game as part of an instrumental strategy for preventing their goals from being modified, thereby allowing them to better pursue some beyond-episode goal later.[11] In particular: alignment faking can arise in many other contexts (for example: terminal training-gaming can incentivize it, too, as can goals that don't route via reward-on-the-episode at all). And equating goal-guarding scheming with "deceptive alignment" can lead to other confusions, too – for example, training-game behavior needn't be "aligned" in the sense of "intended/desirable" (e.g., the highest-reward behavior might be to deceive/manipulate the reward process – see Cotra (2022) for discussion).[12] So I've decided to use different terminology here.[13]
See Park et al (2023) for a more in-depth look at AI deception. ↩︎
For readers unfamiliar with this story, see section 4.2 of Carlsmith (2021). ↩︎
Bostrom's original definition of the treacherous turn is: "While weak, an AI behaves cooperatively (increasingly so, as it gets smarter). When the AI gets sufficiently strong – without warning or provocation – it strikes, forms a singleton, and begins directly to optimize the world according to the criteria implied by its final values." Note that treacherous turns, as defined here, don't necessarily require that the early, nice-seeming behavior is part of an explicit strategy for getting power later (and Bostrom explicitly includes examples that involve such explicit pretense). Other definitions, though – for example, Artibal's here – define treacherous turning such that it implies strategic betraying. And my sense is that this is how the term is often used colloquially. ↩︎
Cotra's definition of "playing the training game" is: "Rather than being straightforwardly 'honest' or 'obedient,' baseline HFDT would push Alex to make its behavior look as desirable as possible to Magma researchers (including in safety properties), while intentionally and knowingly disregarding their intent whenever that conflicts with maximizing reward. I'll refer to this as 'playing the training game.' " Note that there is some ambiguity here about whether it counts as playing the training game if, in fact, maximizing reward does not end up conflicting with human intent. I'll assume that this still counts: what matters is that the model is intentionally trying to perform well according to the training process. ↩︎
Note, though, that sometimes the term "episode" is used differently. For example, you might talk about a game of chess as an "episode" for a chess-playing AI, even if it doesn't satisfy the definition I've given. I discuss this difference in much more depth in section 2.2.1.2. ↩︎
See e.g. Gao (2022) here for a breakdown. On my ontology, the reward process starts with what Gao calls the "sensors." ↩︎
Bostrom's description is: "If an agent retains its present goals into the future, then its present goals will be more likely to be achieved by its future self. This gives the agent a present instrumental reason to prevent alterations of its final goals. (The argument applies only to final goals. In order to attain its final goals, an intelligent agent will of course routinely want to change its subgoals in light of new information and insight.)" ↩︎
Though my use of this term might differ from other usages in the literature. ↩︎
The persistent applicability of analogies like prison and re-education camps to AIs is one of the reasons I think we should be alarmed about the AI moral patienthood issues here. ↩︎
"If the mesa-optimizer has an objective that extends across parameter updates, then it will be incentivized to avoid being modified, as it might not pursue the same objective after modification (with the result that its current objective will not be achieved in future iterations). This means that the mesa-optimizer will be instrumentally incentivized to act as if it is optimizing the base objective function, even if its actual mesa-objective is something else entirely. We will refer to this hypothetical phenomenon as deceptive alignment. Deceptive alignment is a form of instrumental proxy alignment, as fulfilling the base objective is an instrumental goal of the mesa-optimizer." ↩︎
And I think it encourages confusion with nearby concepts as well: e.g., training-gaming, instrumental training-gaming, power-motivated instrumental training-gaming, etc. ↩︎
My sense is that the "alignment" at stake in Hubinger et al's (2019) definition is "alignment with the 'outer' optimization objective," which needn't itself be aligned with human interests/values/intentions. ↩︎
To be clear, though: I think it's OK if people keep using "deceptive alignment," too. Indeed, I have some concern that the world has just started to learn what the term "deceptive alignment" is supposed to mean, and that now is not the time to push for different terminology. (And doing so risks a proliferation of active terms, analogous to the dynamic in this cartoon -- this is one of the reason I stuck with Cotra's "schemers.") ↩︎

