Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
Subscribe here to receive future versions.
Examples of AI safety progress
Training AIs to behave safely and beneficially is difficult. They might learn to game their reward function, deceive human oversight, or seek power. Some argue that researchers have not made much progress in addressing these problems, but here we offer a few examples of progress on AI safety.
Detecting lies in AI outputs. Language models often output false text, but a recent paper suggests they understand the truth in ways not reflected in their output. By analyzing a model’s internals, we can calculate the likelihood that a model believes a statement is true. The finding has been replicated in models that answer questions about images.
One reason to prefer examining a model’s internals over trusting its output is because AI training processes often unintentionally reward models for outputting falsehoods. For example, language models might learn to mimic common misconceptions in their training data. More perniciously, if a human is giving feedback on an AI’s performance, the AI can trick the human into falsely believing they’ve done a good job. It’s important to build several defenses against deception so that failures in one layer can potentially be caught by another.
Giving AI a conscience. AI agents take actions to pursue goals. But there are harmful ways to pursue many goals, such as by breaking laws and violating ethical standards. To block AI agents from misbehaving, its actions can be subjected to approval by an artificial conscience.
An artificial conscience is a separate model trained to identify unacceptable actions. Before an AI agent takes an action, the action is automatically assessed by artificial conscience. If the conscience does not believe the action is acceptable, it can veto the action, and the agent is unable to act perform an action in its environment until the conscience approves an action. An artificial conscience can be easily combined with AI agent before or after training.
How would an artificial conscience decide which actions are acceptable? Language models have shown some understanding of ethical concepts such as justice, fairness, and utility which could be used to inform decisions. The people affected by AI decisions could be given a voice in its decisions by aligning AI with laws decided by democratic processes.
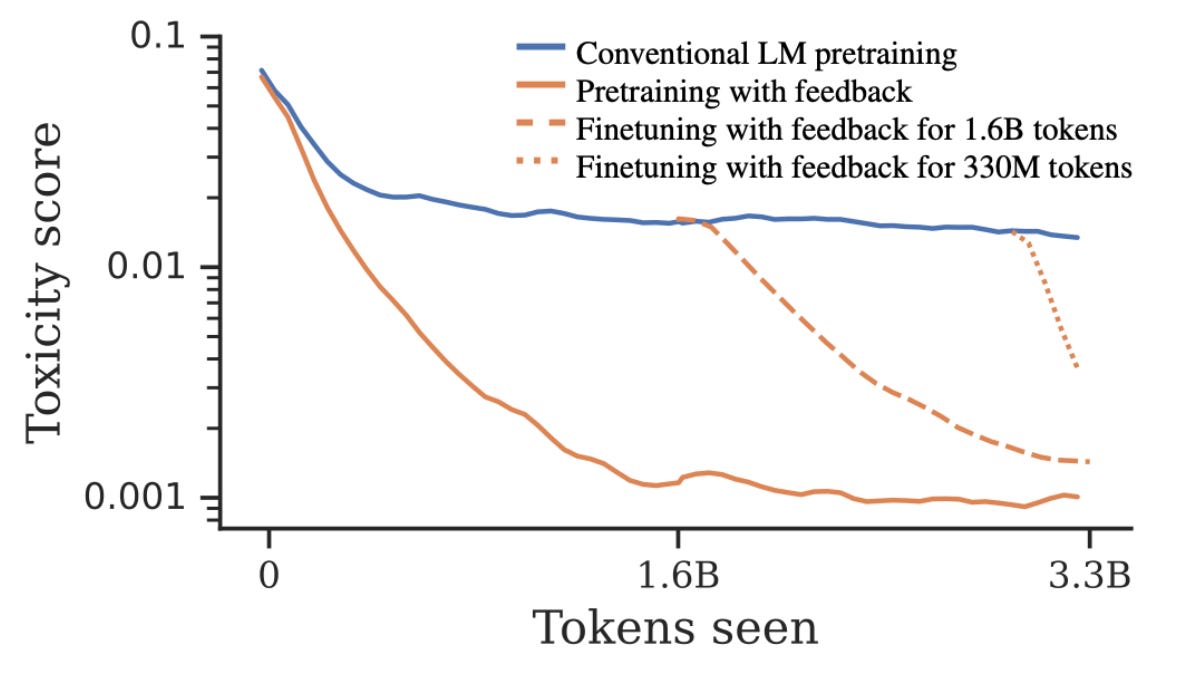
Pretraining AI with human preferences. AI models are often pretrained to identify patterns in large volumes of text or image data. Only afterwards are they fine-tuned to behave in ways that humans find valuable. This has drawbacks: AI might learn harmful patterns of thinking during training, or might devise counterproductive ways to achieve the goal provided in fine-tuning.
A new paper puts feedback about human preferences into the pretraining process. Rather than retrofitted a model to abide by preferences through fine-tuning later in the design process, this paper incorporates preferences early on. When the model is deployed to perform a task, it can be instructed to mimic preferred outputs from the training set. This empirically reduces the chance of misbehavior, so it has been included in Google’s new PaLM 2 language model.
Yoshua Bengio proposes a ban on AI agents
Renowned AI researcher Yoshua Bengio signed the open letter calling for a pause on the development of AI systems more powerful GPT-4. As he puts it, “there is no guarantee that someone in the foreseeable future won’t develop dangerous autonomous AI systems with behaviors that deviate from human goals and values.”
Now Bengio has a proposal for building “safe and useful AI.” He argues that we should build “AI scientists” that answer our questions without taking potentially dangerous actions in the real world. This would be a significant departure from the world today, where AIs drive some vehicles, buy and sell stocks, pilot killer drones, and browse the internet via ChatGPT plugins. To prevent the creation of dangerous AI agents, Bengio suggests “a policy banning powerful autonomous AI systems that can act in the world unless proven safe.”

Bengio is concerned about AI seeking power and deceiving humans. Bengio argues that “As soon as AI systems are given goals – to satisfy our needs – they may create subgoals that are not well-aligned with what we really want and could even become dangerous for humans.” Specifically, he says, “we can expect emerging subgoals to avoid being turned off (and using deception for that purpose).”
There are specific reasons to expect such goals to emerge. First, self-preservation and power seeking are instrumentally useful for achieving a wide range of possible goals. Second, AIs that have these instincts will tend to proliferate more than those indifferent to their own life and death. Even if an AI appears safe in the lab, Bengio says danger arises from the fact that “it is difficult to forecast how such complex learned systems would behave in new situations.”
Proposal: Don’t let AIs take actions in the world. Since it’s difficult to build AIs that pursue goals safely, Bengio argues we should not build AIs that pursue goals at all. Instead, he advocates “AI scientists” that simply answer our questions about the world without taking actions.
Banning AI agents could reduce the chance of harm from autonomous AIs, but important challenges would remain. Humans could still misuse AIs to create propaganda and new kinds of weapons. Or we might trust AIs more than we should, and end up like the man whose self-driving car crashed and killed him while he was playing a game on his phone.
Banning AI agents would require stringent regulation. Bengio argues that banning AI agents “would require a robust regulatory framework that is instantiated nationally and internationally.” He encourages accelerating AI policymaking in a number of ways: “Increasing the general awareness of AI risks, forcing more transparency and documentation, requiring organizations to do their best to assess and avoid potential risks before deploying AI systems, introducing independent watchdogs to monitor new AI developments, etc would all contribute not just to mitigating short-term risks but also helping with longer-term ones.” While this would be difficult to pull off, we agree that in principle AI tools are likely safer than AI agents.
Lessons from Nuclear Arms Control for Verifying AI Treaties
Even if one country regulates AI responsibly, they could suffer from harmful AI developed in another country. Therefore, prominent voices including Turing Award winners, the President of the Brookings Institution, and the CEO of Google have called for international treaties to govern AI.
How politically viable are such proposals, and how can we improve them? A new paper helps us answer these questions by considering lessons from the history of nuclear arms control verification.
Nuclear arms control includes strong verification measures. Historically, countries have often accepted strong measures to verify nuclear arms control treaties. These measures have included reporting inventories of all the uranium in a country, accepting thorough inspections of nuclear energy and nuclear weapon facilities, and letting an international agency inspect nearly arbitrary locations in a state. The strongest versions of these systems have a good track record: the public record indicates they have not failed to detect any major violations.
Good verification mechanisms preserve privacy and security. Countries often object to international treaties on the grounds that they will hurt national security. For example, another paper we recommend about historical efforts at nuclear arms control notes that Stalin opposed United Nations inspectors entering the Soviet Union to inspect sensitive military sites. But simple measures can afford the much needed privacy. The New START nuclear arms control treaty signed in 2010 included a provision that inspectors would only be allowed to inspect missiles warheads obscured by a protective cover so they “could be counted without revealing their technical characteristics.” Developing methods for compute governance that preserve economic and military needs will be essential for promoting compliance with international agreements.
Early efforts can pave the way for future governance. It took decades—and some close calls—to develop thorough systems of nuclear arms control verification, and they were only created after weaker systems paved the way for them. This suggests it is important for stakeholders to begin prototyping some scalable verification procedures soon, even if their scope is initially limited.

Links
- Despite the fact that Microsoft’s Bing Chat has repeatedly threatened users, Microsoft’s chief economist argues that AI regulation should be reactive, not proactive, and should not be put in place until “meaningful harm” occurs.
- Anthropic releases a language model that can handle 100,000 tokens at once, enough to fit the entirety of The Great Gatsby in a single prompt.
- Google launched a new language model that is publicly free to use. Its capabilities are roughly between GPT-3.5 and GPT-4.
- Bloomberg News is hiring an AI Ethics and Policy reporter
- OpenAI CEO Sam Altman and several others will testify before Congress today.
- A new poll shows the majority of Americans support an FDA for AI and pausing AI development.
- The proliferation of thousands or millions of AI agents could create unexpected challenges, argued in a WSJ op-ed.
See also: CAIS website, CAIS twitter, A technical safety research newsletter
Subscribe here to receive future editions of the AI Safety Newsletter.
Super excited about the artificial conscience paper. I'd note that a similar approach be very useful for creating law-following AIs: