All of david_reinstein's Comments + Replies
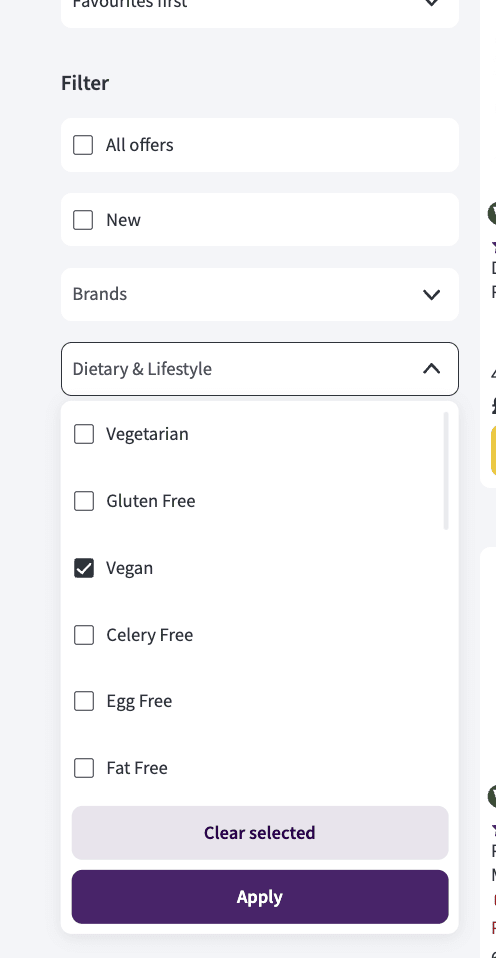
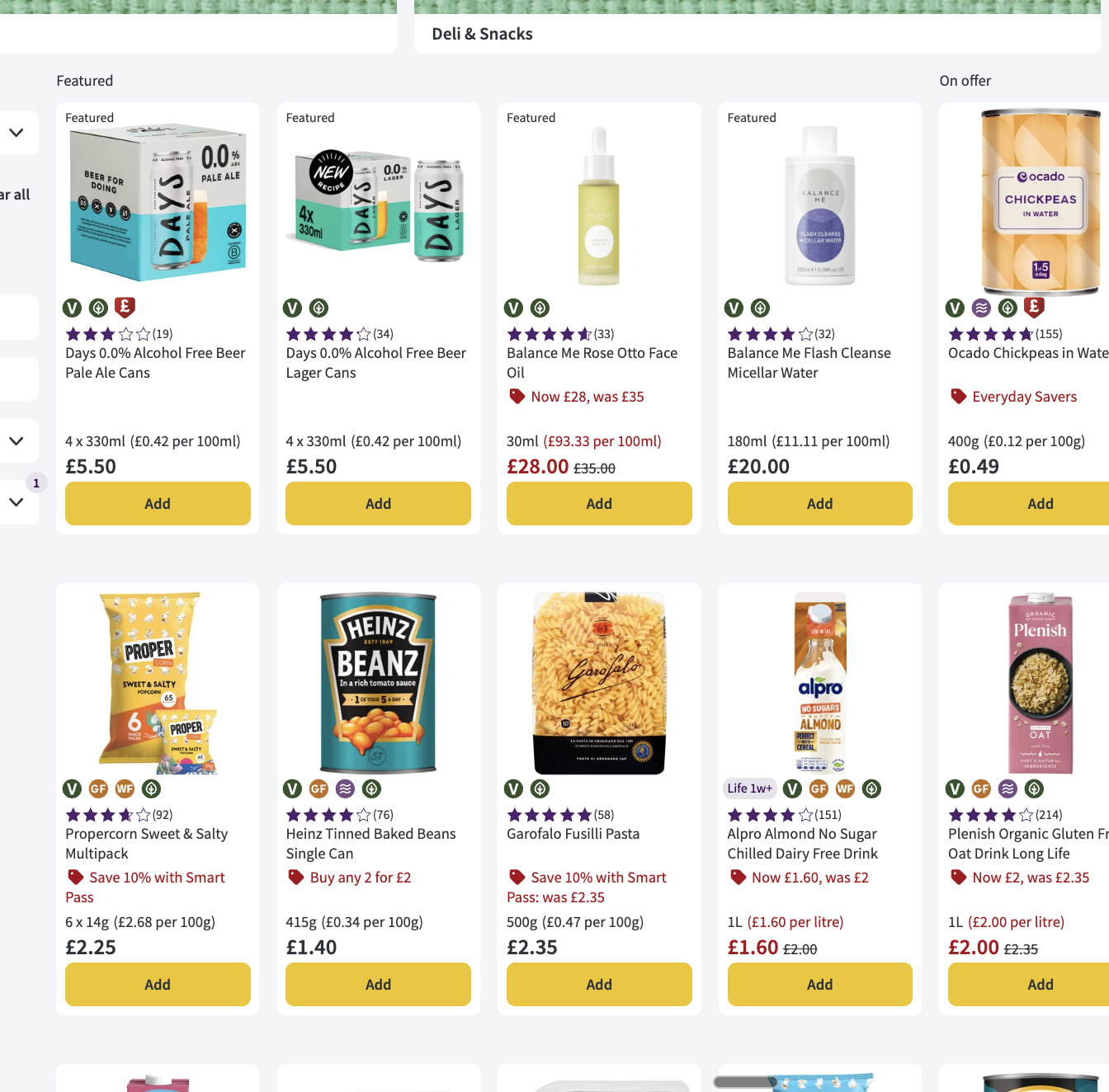
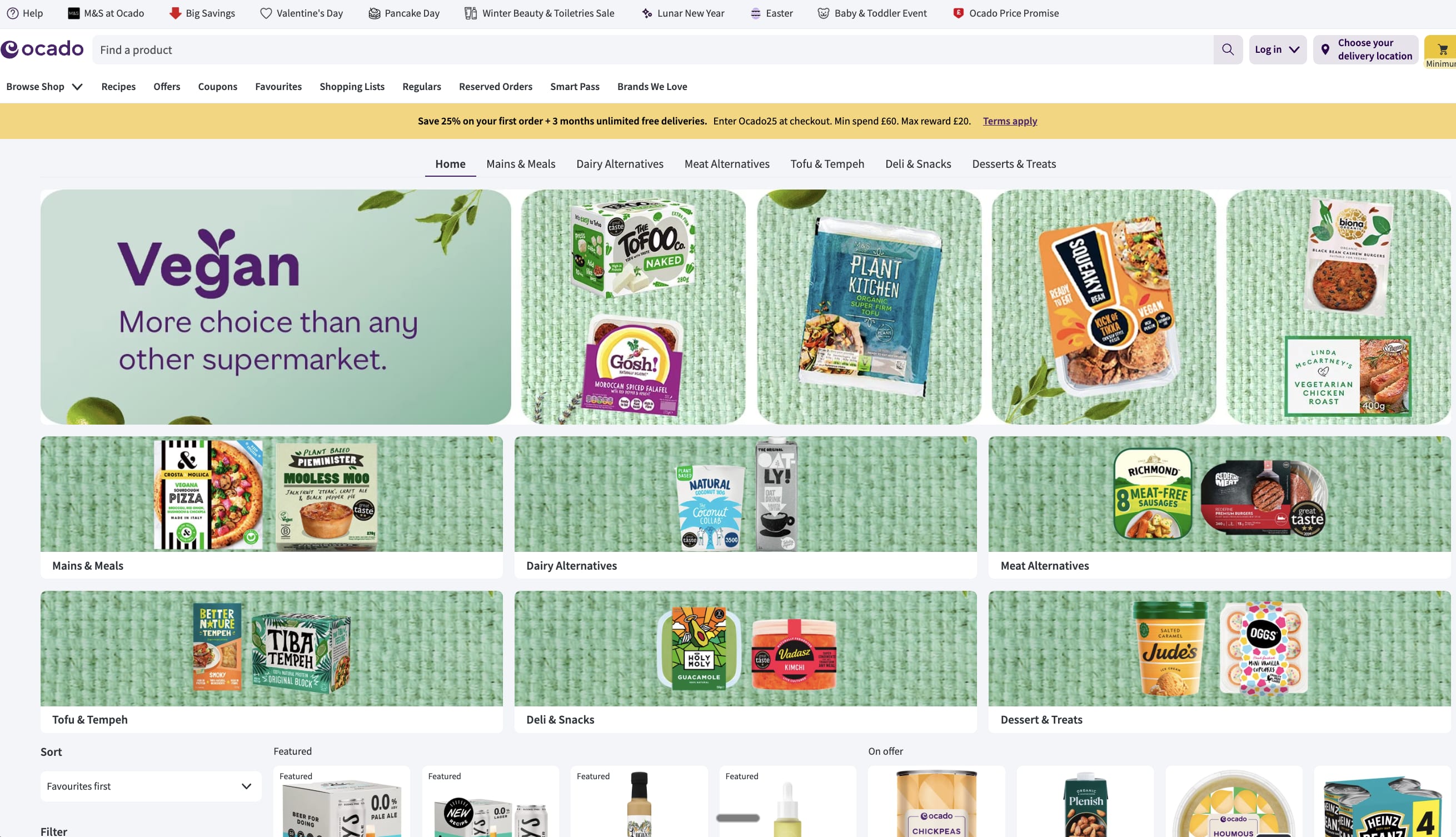
I think you can basically already do this in at least some online supermarkets like Ocado in the UK
https://www.ocado.com/categories/dietary-lifestyle-world-foods/vegan/213b8a07-ab1f-4ee5-bd12-3e09cb16d2f6?source=navigation
Is that different than what you are proposing or do you just propose extending it to more online supermarkets?
Community-powered aggregation (scalable with retailer oversight) To scale beyond pilots, vegan product data can be aggregated from the vegan community through a dedicated reporting platform. To ensure reliability for retail partners, classifications are assigned confidence scores based on user agreement, contributor reliability, and historical accuracy. Only high-confidence data is shared with supermarkets.
Couldn't this be automated? Perhaps with occasional human checks? Food products are required to list their ingredients so it should be pretty easy to classify. Or maybe I'm missing something.
I think it’s different in kind. I sense that I have valenced consciousness and I can report it to others, and I’m the same person feeling and doing the reporting. I infer you, a human, do also, as you are made of the same stuff as me and we both evolved similarly. The same applies to non human animals, although it’s harder to he’s sure about their communication.
But this doesn’t apply to an object built out of different materials, designed to perform, improved through gradient descent etc.
Ok some part of the system we have built to communicate with us ...
Thanks.
I might be obtuse here, but I still have a strong sense that there's a deeper problem being overlooked here. Glancing at your abstract
self-reports from current systems like large language models are spurious for many reasons (e.g. often just reflecting what humans would say)
we propose to train models to answer many kinds of questions about themselves with known answers, while avoiding or limiting training incentives that bias self-reports.
To me the deeper question is "how do we know that the language model we are talking to has access to the ...
The issue of valence — which things does an AI fee get pleasure/pain from and how would we know? — seems to make this fundamentally intractable to me. “Just ask it?” — why would we think the language model we are talking to is telling us about the feelings of the thing having valenced sentience?
See my short form post
I still don’t feel I have heard a clear convincing answer to this one. Would love your thoughts.
Fair point, some counterpoints (my POV obviously not GiveWell's):
1. GW could keep the sheets as the source of truth, but maintain a tool that exports to another format for LLM digestion. Alternately, at least commit to maintaining a sheets-based version of each model
2. Spreadsheets are not particularly legible when they get very complicated, especially when the formulas in cells refer to cell numberings (B12^2/C13 etc) rather than labeled ranges.
3. LLMs make code a lot more legible and accessible these days, and tools like Claude Code make it easy to create nice displays and interfaces for people to more clearly digest code-based models
This feels doable, if challenging.
I'll try a bit myself and share progress if I make any. Better still, I'll try to signal-boost this and see if others with more engineering chops have suggestions. This seems like something @Sam Nolan and others (@Tanae, @Froolow , @cole_haus ) might be interested in and good at.
(Tbh my own experience was more in the other direction... asking Claude Code to generate the Google Sheets from other formats because google sheets are familiar and either to collab with. That was a struggle.)
Announcing RoastMyPost: LLMs Eval Blog Posts and More might be particularly useful for the critique stage.
most likely because it can't effectively work with our multi-spreadsheet models.
My brief experience is that LLMs and Claude code struggle a bit with data in Google sheets in particular. Taking a first step to move the data (and formulas) into databases and scripts might help with this considerably. (And Claude code should be very helpful with that).
I agree there's a lot of diversity across non-profit goals and thus no one-size-fits-all advice will be particularly useful.
I suspect the binding constraint here is people on nonprofit boards are often doing it as a very minor part-time thing and while they may be directly aligned with the mission, they find it hard to prioritize this when there's other tasks and deadlines more directly in their face.
And people on non-profit boards generally cannot get paid, so a lot of our standard cultural instincts tell us not to put a high premium on this.
Of course the...
Did a decent job for this academic paper, but I think it’s hampered by only having content from Arxiv and various EA/tech forums. Still, it generated some interesting leads.
Prompt:
...... find the most relevant authors and work for Observational price variation in scanner data cannot reproduce experimental price elasticities https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4899765 -- we're looking for methodological experts to evaluate this for The U
Trying this out for using for various Unjournal.org processes (like prioritizing research, finding potential evaluators, linking research to pivotal questions) and projects (assessing LLM vs human research evaluations). Some initial forays (comming from a conversation with Xyra). I still need to human-check it.
~prompt to Claude code about @Toby_Ord and How Well Does RL Scale?
``Toby Ord's writing -- what do the clusters look like? What other research/experts come closest to his post .... https://forum.effectivealtruism.org/posts/Tysu...
At the Unjournal we have a YouTube channel and I'm keen to produce more videos both about our process and the case for our model, and about the content of the research we evaluate and the pivotal questions we consider, which are generally EA-adjacent. This includes explainer videos, making the case videos, interviews/debates, etc.
But as you and most organizations probably realize, it's challenging and very time-consuming to produce high-quality videos, particularly in terms of creating and synchronizing images, sound, and video editing, etc. Without ...
Should be fixed now, thanks. Problem was because I started by duplicating the first one and then adjusting the text. But the text only showed changed on my end (NB: @EA Forum Team )
Some notes/takes:
The Effective Giving/EA Marketing project was going fairly strong, making some progress and also some limitations. But I wouldn't take the ~shutdown/pause as strong evidence against this approach. I'd diagnose it as:
1. Some disruption from changes in emphasis/agenda at a few points in the project, driven by the changing priorities in EA at the time, first towards "growing EA rather than fundraising" (Let's stop saying 'funding overhang', etc.) and then somewhat back in the other direction after the collapse of FTX
2. I got a gra...
Here's the Unjournal evaluation package
A version of this work has been published in the International Journal of Forecasting under the title "Subjective-probability forecasts of existential risk: Initial results from a hybrid persuasion-forecasting tournament"
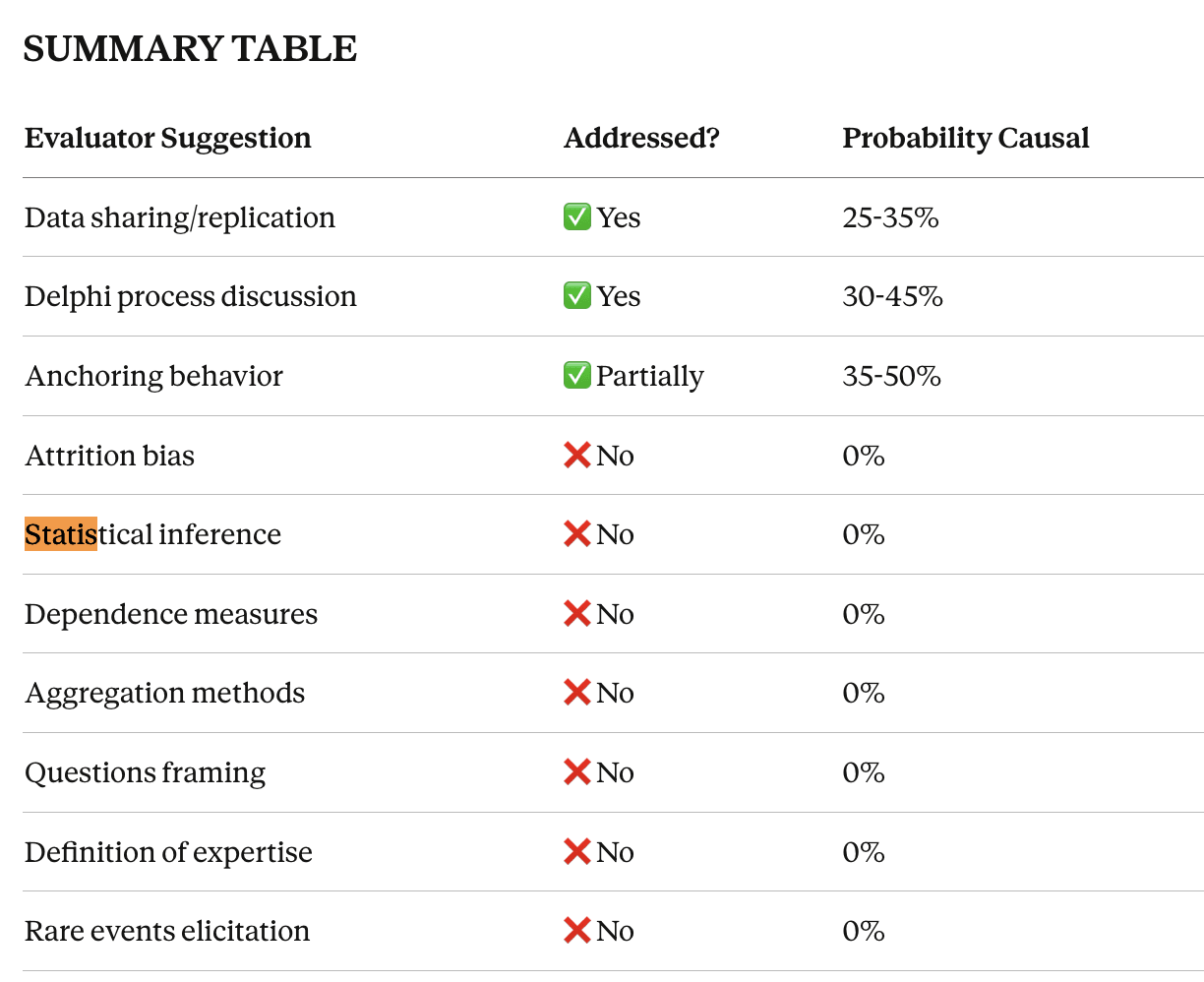
We're working to track our impact on evaluated research (see coda.io/d/Unjournal-...) So We asked Claude 4.5 to consider the differences across paper versions, how they related to the Unjournal evaluator suggestions, and whether this was likely to have been causal.
See Claude's report here ...
I've found it useful both for posts and for considering research and evaluations of research for Unjournal, with some limitations of course.
- The interface can be a little bit overwhelming as it reports so many different outputs at the same time some overlapping
+ but I expect it's already pretty usable and I expect this to improve.
+ it's an agent-based approach so as LLM models improve you can swap in the new ones.
I'd love to see some experiments with directly integrating this into the EA forum or LessWrong in some ways, e.g. automatically doin...
In case helpful, the EA Market Testing team (not active since August 2023) was trying to push some work in htis direction, as well as collaboration and knowledge-sharing between organizations.
See our knowledge base (gitbook) and data analysis. (Caveat: it is not all SOTA in a marketing sense, and sometimes leaned a bit towards the academic/scientific approach to this).
Happy to chat more if you're interested.
I think "an unsolved problem" could indicate several things. it could be
-
We have evidence that all of the commonly tried approaches are ineffective, i.e., we have measured all of their effects and they are tightly bounded as being very small
-
We have a lack of evidence, thus very wide credible intervals over the impact of each of the common approaches.
To me, the distinction is important. Do you agree?
You say above
meaningful reductions either have not been discovered yet or do not have substantial evidence in support
But even "do not have substanti...
Some of this may be a coordination issue. I wanted to proactively schedule more meetings at EAG Connect, but I generally found fewer experienced/senior people at key orgs in the Swapcard relative to the bigger EAGs. And some that were there didn't seem responsive ... as it's free and low-cost, there may also be people that sign up and then don't find the time to commit,
Posted and curated some Metaculus questions in our community space here.
This is preliminary: I'm looking for feedback and also hoping to post some of these as 'Metaculus moderated' (not 'community') questions. Also collaborating with Support Metaculus' First Animal-Focused Forecasting Tournament.
Questions like:
Predict experts' beliefs over “If the price of the... hamburger-imitating plant products fell by 10% ... how many more/fewer chickens consumed globally in 2030, as a +/- percent?
Posted and curated some Metaculus questions in our community space here.
This is preliminary: I'm looking for feedback and also hoping to post some of these as 'Metaculus moderated' (not 'community') questions. Also collaborating with Support Metaculus' First Animal-Focused Forecasting Tournament.
Specific questions include
What will be the average production cost (per edible kg) of cell-cultured chicken meat at the end of the following years (between 2026-2051) across all large-scale plants in the world?
and
Predict the median of experts' beliefs o...
Unjournal.org is collaborating with this initiative for our Pivotal Questions projects:
Is Cultured Meat Commercially Viable? Unjournal’s first proposed ‘Pivotal Question’ (& request for feedback) and
"How much do plant-based products substitute for animal products and improve welfare?" – An Unjournal Pivotal Question (update: added polls)
Aiming to integrate this with some of the questions in our community here
Feedback on these questions and operationalizations is highly appreciated.
I made a similar argument a few years back, advocating that GiveWell should rank, rate, and measure charities beyond the absolute best/most measurable.
A common response was that the evidence suggested the returns were so heavy-tailed... So moving money from ~ineffective charities (Make a Wish) to 'near-top' charities, or to mainstream charities operating in similar areas (say MSF vs. AMF) would have far less value than moving money from near-top to top charities.
My counter-response was ... ~we don't have solid that charities like MSF are...
It's hard for me to glean what the consensus is in this thread/on this issue. But if there seems to be a strong case that some outside scrutiny is needed, this might be something The Unjournal (Unjournal.org) could help with. Bringing "outside the EA bubble" academic expertise to weigh in is one of our key things
We generally focus on economics and social science but we might be able to stretch to this. (Feel free to dm/suggest/ping me).
I like the post and agree with most of it, but I don't understand this point. Can you clarify? To me it seems like the opposite of this.
If EA organizations are seen promoting frugality, their actions could be perceived as an example of the rich promoting their own interests over those of the poor. This would increase the view that EA is an elitist movement.
A quick ~testimonial. Abraham's advice was very helpful to us at Unjournal.org. As our fiscal sponsor was ending its operations we needed to transition quickly. We were able to get a 501(c)3 with not a tremendous amount of effort much quicker than anticipated.
in retrospect, there would have been a better decision to form a 501c3 as soon as we had our first grant and had applied for a larger grant. It would have saved us a substantial amount of fees and allowed us to earn interest/investment income on the larger grant. And it's also easier to access tech discounts as a 501(c)(3) rather than a fiscally sponsored organization.
Enjoyed it, a good start.
I like the stylized illustrations but I think a bit more realism (or at least detail) could be helpful. Some of the activities and pain suffered by the chickens was hard to see.
The transition to the factory farm/caged chickens environment was dramatic and the impact I think you were seeking.
One fact-based question which I don't have the answer to -- does this really depict the conditions for chickens where the eggs are labeled as "pasture raised?" I hope so, but I vaguely heard that that was not a rigorously enforced label.
Here's some suggestions from 6 minutes of ChatGPT thinking. (Not all are relevant, e.g., I don't think "Probable Causation" is a good fit here.)
Do you see other podcasts filling the long-form, serious/in-depth, EA-adjacent/aligned niche in areas other than AI? E.g., GiveWell has a podcast, but I'm not sure it's the same sort of thing. There's also Hear This Idea, often Clearer Thinking or Dwarkesh Patel cover relevant stuff.
(Aside, was thinking of potentially trying to do a podcast involving researchers and research evaluators linked to The Unjournal; if I thought it could fill a gap and we could do it well, which I'm not sure of.)
No, I really don't. Sometimes you see things in the same territory on Dwarkesh (which is very AI-focused) or Econtalk (which is shorter and less and less interesting to me lately). Rationally Speaking was wonderful but appears to be done. Hear This Idea is intermittent and often more narrowly focused. You get similar guests on podcasts like Jolly Swagman but the discussion is often at too low of a level, with worse questions asked. I have little hope of finding episodes like those with Hannah Ritchie, Christopher Brown, Andy Weber, or Glen Weyl anywhere el...
This seems a bit related to the “Pivotal questions”: an Unjournal trial initiative -- we've engaged with a small group of organizations and elicited some of these -- see here.
To highlight some that seem potentially relevant to your ask:
...What are the effects of increasing the availability of animal-free foods on animal product consumption? Are alternatives to animal products actually used to replace animal products, and especially those that involve the most suffering? Which plant-based offerings are being used as substitutes versus complements
Thanks for the thoughts. Note that I'm trying to engage/report here because we're working hard to make our evaluations visible and impactful, and this forum seems like one of the most promising interested audiences. But also eager to hear about other opportunities to promote and get engagement with this evaluation work, particularly in non-EA academic and policy circles.
I generally aim to just summarize and synthesize what the evaluators had written and the authors' response, bringing in what seemed like some specific relevant examples, and using quotes or...
A final reflective note: David, I want to encourage you to think about the optics/politics of this exchange from the point of view of prospective Unjornal participants/authors.
I appreciate the feedback. I'm definitely aware that we want to make this attractive to authors and others, both to submit their work and to engage with our evaluations. Note that in addition to asking for author submissions, our team nominates and prioritizes high-profile and potential-high-impact work, and contact authors to get their updates, suggestions, and (later) respons...
I meant "constructive and actionable" In that he explained why the practices used in the paper had potentially important limitations (see here on "assigning an effect size of .01 for n.s. results where effects are incalculable")...
And suggested a practical response including a specific statistical package which could be applied to the existing data:
"An option to mitigate this is through multiple imputation, which can be done through the metansue (i.e., meta-analysis of non-significant and unreported effects) package"
In terms of the cost-benefit test it dep...
Thanks for the detailed feedback, this seems mostly reasonable. I'll take a look again at some of the framings, and try to adjust. (Below and hopefully later in more detail).
the phrase "this meta-analysis is not rigorous enough". it seems this meta-analysis is par for the course in terms of quality.
This was my take on how to succinctly depict the evaluators' reports (not my own take), in a way the casual reader would be able to digest. Maybe this was rounding down too much, but not by a lot, I think. Some quotes from Janés evaluation that I think are r...
I'll frame it explicitly here: when we did one check and not another, or one one search protocol and not another, the reason, every single time, is opportunity costs. When I write: "we thought it made more sense to focus on the risks of bias that seemed most specific to this literature," notice the word 'focus', which means saying no.
That is clearly the case, and I accept there are tradeoffs. But ideally I would have liked to see a more direct response to the substance of the points made by the evaluators. But I understand that there are tradeoffs th...
This does indeed look interesting, and promising. Some quick (maybe naive) thoughts on that particular example, at a skim.
- An adaptive/reinforcement learning design could make a mega study like this cheaper ... You end up putting more resources into the arms that start to become more valuable/where more uncertainty needs to be resolved.
- I didn't see initially how they corrected did things like multiple hypothesis correction, although I'd prefer something like a Bayesian approach, perhaps with multiple levels of the model... effect category, specific i
Post roasted here on roastmypost (Epistemic Audit)
It gets a B- which seems to be the modal rating.
Some interesting comments (going in far more detail than the summary below)
...This EA Forum post announces Joe Carlsmith's career transition from Open Philanthropy to Anthropic while providing extensive justification for working at a frontier AI company despite serious safety concerns. The document demonstrates exceptional epistemic transparency by explicitly acknowledging double-digit extinction probabilities while defending the decision on con
Still loving this, hosted a good set of short and LT EA stays. But the 'add review' function is still not working. That would add a lot of value to this. Can someone look into it?
https://coda.io/d/EA-Houses_dePaxf_RJiq/Add-review_su_RF7Tc#Reviews_tuLcDk6R/r8
I ran this through QURI's RoastMyPost.org, and it gave a mixed but fairly positive assessment (something like 68/100).
Full assessment here (multiple agents/tools).
The epistemic checker and the fact checker seem particularly useful.
The main limitations seem to be:
- Strong claims and major recommendations without corresponding evidence and support
Vagueness/imprecise definition (this is a partially my own take, partially echoed by RoastMyPost – e.g., it's hard for me to grok what these new cause areas are, some are very much shorthand.)
I meant to po
There's recently been increased emphasis on "principles-first" EA, which I think is great. But I worry that in practice a "principles-first" framing can become a cover for anchoring on existing cause areas, rather than an invitation to figure out what other cause areas we should be working o
I don't quite see the link here. Why would principals first be a cover for anchoring on existing cause areas? Is there a prominent example of this?
Thank you, this is the correct link: https://unjournal.pubpub.org/pub/evalsumleadexposure/
I need to check what's going on with our DOIs !