RobertM
Bio
LessWrong dev & admin as of July 5th, 2022.
Posts 3
Comments85
Topic contributions5
I would guess this might be true for a small proportion of these people, but i would personally guess that most of the top in 10 GiveWell employees would not be able to earn 200k plus very easily in the private sector.
- The CEO came from Bridgewater. Bridgewater pays entry-level analysts ~250k/year; someone with 20 years of experience in that career track is making 7-figures (if they competent but not particularly ambitious).
- The Director of Development's career history looks like they were doing more of the same before they joined Givewell, but they have a JD-equivalent. A competent mid-career lawyer is making much more than $330k/year, if they want to be (though laywer compensation is trimodal, so you could call this one a bit wibbly without more evidence).
- Couldn't find info.
- Was previously a senior director of strategy at a small-mid sized tech company. If they weren't making more there, they could have pretty easily hopped sideways to a larger tech company, been downleveled by 2 steps on the career ladder, and come out ahead on $$$.
- Promoted internally. Comparable positions in the private sector pay more.
- Early career in management consulting (at one of the big firms). That career path also hits 7-figures if you stick with it, though it's a grind.
- Spent most of their career in research roles at other NGOs. Least obvious case so far, but they have a PhD, so if they wanted to do something remunerative they probably could have.
- Similar to #7.
- Mid-career applied economist with math background. Would have been making $500k/year in industry if "trying at all", at this level of experience, 7-figures if trying somewhat harder.
- Another mid-career economist with a math background.
It does just tend to be the case that people are often taking pretty massive paycuts to work at non-profits, even ones that pay somewhat more than other non-profits.
About the unexplained shift of focus from symbolic AI, which Yudkowsky was still claiming as of around 2015 or 2016
This is made up, as far as I can tell (at least re: symbolic AI as described in the wikipedia article you link). See Logical or Connectionist AI? (2008):
As it so happens, I do believe that the type of systems usually termed GOFAI will not yield general intelligence, even if you run them on a computer the size of the moon.
Wikipedia, on GOFAI (reformatted, bolding mine):
In the philosophy of artificial intelligence, GOFAI (good old-fashioned artificial intelligence) is classical symbolic AI, as opposed to other approaches, such as neural networks, situated robotics, narrow symbolic AI or neuro-symbolic AI.
Even earlier is Levels of Organization in General Intelligence. It is difficult to excerpt a quote but it is not favorable to the traditional "symbolic AI" paradigm.
This seems quite fundamental to his, Soares', and MIRI's case, yet as far as I know, it's never been discussed. I've looked, and I've asked around.
I really struggle to see how you could possibly have come to this conclusion, given the above.
And see here re: Collier's review.
Yes, indeed, there was only an attempt to hide the post three weeks ago. I regret the sloppiness in the details of my accusation.
The other false accusation was that I didn't cite any sources
I did not say that you did not cite any sources. Perhaps the thing I said was confusingly worded? You did not include any links to any of the incidents that you describe.
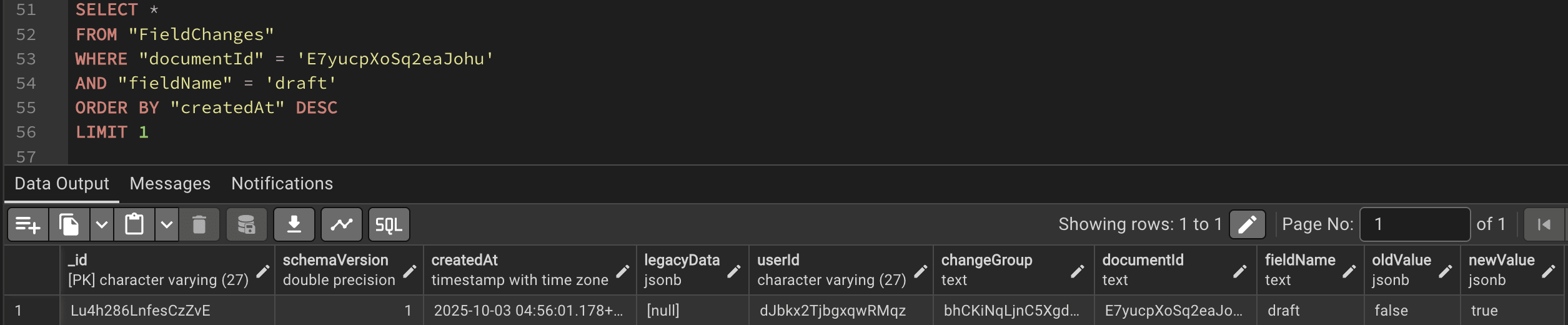
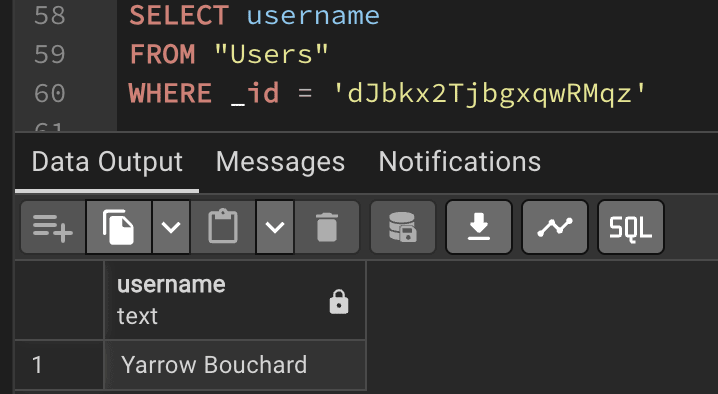
It's really quite something that you wrote almost 2000 words and didn't include a single primary citation to support any of those claims. Even given that most of them are transparently false to anyone who's spent 5 minutes reading either LW or the EA Forum, I think I'd be able to dig up something superficially plausible with which to smear them.
And if anyone is curious about why Yarrow might have an axe to grind, they're welcome to examine this post, along with the associated comment thread.
Edit: changed the link to an archive.org copy, since the post was moved to draft after I posted this.
Edit2: I was incorrect about when it was moved back to a draft, see this comment.
I’m probably a bit less “aligned ASI is literally all that matters for making the future go well” pilled than you, but it’s definitely a big part of it.
Sure, but the vibe I get from this post is that Will believes in that a lot less than me, and the reasons he cares about those things don't primarily route through the totalizing view of ASI's future impact. Again, I could be wrong or confused about Will's beliefs here, but I have a hard time squaring the way this post is written with the idea that he intended to communicate that people should work on those things because they're the best ways to marginally improve our odds of getting an aligned ASI. Part of this is the list of things he chose, part of it is the framing of them as being distinct cause areas from "AI safety" - from my perspective, many of those areas already have at least a few people working on them under the label of "AI safety"/"AI x-risk reduction".
Like, Lightcone has previously and continues to work on "AI for better reasoning, decision-making and coordination". I can't claim to speak for the entire org but when I'm doing that kind of work, I'm not trying to move the needle on how good the world ends up being conditional on us making it through, but on how likely we are to make it through at all. I don't have that much probability mass on "we lose >10% but less than 99.99% of value in the lightcone"[1].
Edit: a brief discussion with Drake Thomas convinced me that 99.99% is probably a pretty crazy bound to have; let's say 90%. Wqueezing out that extra 10% involves work that you'd probably describe as "macrostrategy", but that's a pretty broad label.
- ^
I haven't considered the numbers here very carefully.
If you’ve got a very high probability of AI takeover (obligatory reference!), then my first two arguments, at least, might seem very weak because essentially the only thing that matters is reducing the risk of AI takeover.
I do think the risk of AI takeover is much higher than you do, but I don't think that's why I disagree with the arguments for more heavily prioritizing the list of (example) cause areas that you outline. Rather, it's a belief that's slightly upstream of my concerns about takeover risk - that the advent of ASI almost necessarily[1] implies that we will no longer have our hands on the wheel, so to speak, whether for good or ill.
An unfortunate consequence of having beliefs like I do about what a future with ASI in it involves is that those beliefs are pretty totalizing. They do suggest that "making the transition to a post-ASI world go well" is of paramount importance (putting aside questions of takeover risk). They do not suggest that it would be useful for me to think about most of the listed examples, except insofar as they feed into somehow getting a friendly ASI rather than something else. There are some exceptions: for example, if you have much lower odds of AI takeover than I do, but still expect ASI to have this kind of totalizing effect on the future, I claim you should find it valuable for some people to work on "animal welfare post-ASI", and whether there is anything that can meaningfully be done pre-ASI to reduce the risk of animal torture continuing into the far future[2]. But many of the other listed concerns seem very unlikely to matter post-ASI, and I don't get the impression that you think we should be working on AI character or preserving democracy as instrumental paths by which we reduce the risk of AI takeover, bad/mediocre value lock-in, etc, but because you consider things like that to be important separate from traditional "AI risk" concerns. Perhaps I'm misunderstanding?
- ^
Asserted without argument, though many words have been spilled on this question in the past.
- ^
It is perhaps not a coincidence that I expect this work to initially look like "do philosophy", i.e. trying to figure out whether traditional proposals like CEV would permit extremely bad outcomes, looking for better alternatives, etc.
Soares' experience was a software engineer at Microsoft and Google before joining MIRI, and would trivially be able to rejoin industry after a few weeks of self-study to earn more money if for some reason he decided he wanted to do that. I won't argue the point about EY - it seems obvious to me that his market value as a writer/communicator is well in excess of his 2023/2024 compensation, given his track record, but the argument here is less legible. Thankfully it turns out that somebody anticipated the exact same incentive problem and took action to mitigate it.