Vasco Grilo🔸
Bio
Participation4
I am a generalist quantitative researcher. I am open to volunteering and paid work. I welcome suggestions for posts. You can give me feedback here (anonymously or not).
How others can help me
I am open to volunteering and paid work. I welcome suggestions for posts. You can give me feedback here (anonymously or not).
How I can help others
I can help with career advice, prioritisation, and quantitative analyses.
Posts 257
Comments3260
Topic contributions42
Hi Anthony. Readers of this post may be interested in this summary and discussion in the comments of Adam Elga's article Subjective Probabilities should be Sharp. I very much agree subjective probabilities should be sharp. So I am not concerned about the unawareness argument for "no impartial altruistic justification for preferring any action over another", which relies on unsharp probabilities.
Hi Simon. Below is what Claude has to say about that.
Hi Simon. I think you've actually put your finger on the load-bearing feature rather than missed something — but the tension you're sensing resolves once you separate two things that "full disclosure" runs together in your reading: what the agent knows, and when she chooses.
Full disclosure only fixes the first. At the A-node she knows the whole tree: that B will follow, the payoffs, and that her credence in H won't move. What it does not do is collapse the two choices into one simultaneous package-choice. She still acts twice, at two separate moments — accept/reject A, and then, after that's settled, accept/reject B. Foreknowledge isn't simultaneity. So the sequential structure survives full disclosure intact; the agent is fully informed and still makes two timed decisions.
That distinction is exactly why your "just interpret it as: take both, get $5, so it's irrational not to" doesn't invalidate the setup — and here's the part that I think will unstick you. That reasoning isn't a competitor to Elga's argument; it's Elga's own premise. The paper's central claim is precisely that a rational agent "will accept at least one of the bets" because rejecting both is dominated and she can see this in advance. He is not disagreeing that reject-both is irrational. He's asserting it. Your intuition and his premise are the same sentence.
So the question the paper is asking is one notch more subtle than the one you're answering. It's not "is it irrational to reject both?" (everyone says yes). It's: "what account of how unsharp credences guide action actually delivers that verdict, given that the unsharp agent's rule makes each bet, taken on its own, merely optional?" With an interval straddling 60%, rejecting A is permitted at the A-node; with the interval straddling 40%, rejecting B is permitted at the B-node. A rule that just evaluates each bet locally therefore licenses reject-both — the two "optional"s compose into the dominated outcome, foreknowledge notwithstanding. The challenge is to find a rule that blocks that without wrecking the optionality elsewhere.
Now to your direct question — is your move PLAN or SEQUENCE? Once you try to turn "take both, it's $5" from an observation into a decision rule the agent runs, you land in the global-rules family, and closest to SEQUENCE (equivalently, the "treat it as one choice among {A, B, BOTH, NEITHER} and eliminate the dominated NEITHER" reframe that Evan proposed in the other thread [here]). That rule does give the right verdict here — Elga grants that. His objection is that as a rule it fails the Sally test: it has to call "reject B" impermissible when A-was-just-rejected but permissible when B is offered alone, even though a money-only agent faces identical money-consequences at the B-node in both cases. So your reasoning isn't a fourth escape hatch; it's a restatement of what a global rule has to deliver, and Elga's argument is aimed precisely at whether any such rule survives.
On your suspicion that full disclosure "must be weaker than I'm interpreting" — I'd say the opposite. It's exactly as strong as you're reading it, and that strength is the point. Full disclosure, plus no-belief-change, plus linear-in-dollars, is Elga removing every excuse the unsharp theorist could offer for reject-both: she wasn't surprised, she didn't learn anything mid-sequence that shifted her credence, and she has no non-monetary reasons. With all the confounders stripped out, any residual permission to reject both traces to the unsharp decision rule alone — which is the whole rhetorical purpose of piling on those stipulations.
One last thing that I think will make the sequential structure feel less suspicious: Elga needs it to be sequential, and this is why he can't just let it be a simultaneous package. If the offer were genuinely one simultaneous choice ("accept both / reject both / mix"), the puzzle evaporates — even a maximally permissive rule picks BOTH over NEITHER by straight dominance, and the unsharp theorist wins for free. The problem only has teeth in the sequential version, because that's the only structure where a local rule can manufacture reject-both out of two individually-permitted rejections. So the sequential framing and full disclosure aren't in tension; they're doing complementary jobs — disclosure kills the "she didn't see it coming" defense, sequentiality is what generates the difficulty in the first place.
Below is how Claude thinks Adam (the author of the article) would object to your comments. The objections make sense to me. Any reactions?
1. "What if I do care about the differences?"
Michael's most direct hit: Elga's Sally argument needs the two B-situations to be identical in everything she cares about, and Michael asks why the agent can't just care about whether she's about to complete a dominated sequence — "why can't the fact that she'd pick a dominated sequence or regret it if she rejects both bets matter to her after rejecting bet A?"
Elga has a ready answer, and it's the one he actually gives in the paper against the parallel "but rejecting B would break her plan" rejoinder. It splits into a dilemma:
Either this caring is a genuine, independent source of value for Sally — in which case the case has been changed, not answered. Elga's Sally is stipulated to care only about money, with reconsideration costless. If you smuggle in a taste for sequence-completion or an aversion to regret, you're no longer discussing Elga's agent; you're conceding that a purely money-motivated unsharp agent is stuck, and rescuing a different agent who has been given an extra terminal value precisely engineered to patch the hole. That's ad hoc: the value exists only to deliver the verdict UNSHARP needs.
Or the caring is not an independent value but just tracks "this would be irrational" — in which case it's viciously circular. "I disprefer rejecting B because rejecting B here is irrational" cannot be what makes it irrational; the account owes us a prior reason, and this isn't one. Elga's "Don't break plans!"-is-like-"Don't break mirrors!" point applies verbatim: either breaking the sequence is independently costly (then say so, and it's a different case) or it isn't (then "avoid completing dominated sequences" is a bare, unmotivated constraint dressed up as a preference).
The regret variant is especially weak. Regret is backward-looking; at the B-node the money consequences of accept-B and reject-B are fixed and identical across the two situations. If anticipated regret genuinely moves her, it's doing so as a real (dis)utility — back to horn one, the case is changed. Vasco's reply on the forum ("it is very counterintuitive that this could matter for Sally for reasons that don't have to do with money") is exactly Elga's point, just stated flatly.
2. Michael's "treat them fairly" / Parfit's-hitchhiker parity argument
This is Michael's best move, and it's really DiGiovanni's commitment point [made here] sharpened into a parity charge: there are cases everyone agrees call for binding commitments you'll later be inclined to break — Parfit's hitchhiker, St. Petersburg with unbounded utility — so the same "commit and rule out the bad branch" solution should be available to the unsharp agent, if you're treating her fairly. And he uses this to answer Vasco's "but unsharp probabilities are supposed to allow rejecting A": "They don't have to in every case. If it were A in isolation, both would be permissible. But that's not the case presented to us."
Elga would grant the parity and then deny it helps — for two reasons.
First, notice what Michael has conceded. He now says the unsharp agent is required to accept A (to zero out the chance of the dominated branch). But that is Elga's whole thesis about this case: rationality forces a determinate verdict at the A-node. The disagreement was never "can she avoid NEITHER?" — of course she can. It's whether the unsharp credence leaves A genuinely optional. Michael answers "no, not here," which means the interval straddling 60% is not translating into optionality on A. So the imprecision is doing no work at the node where it was supposed to; the commitment (or the statewise argument, see below) is doing all of it. That's confirmation of Elga's challenge — "how do unsharp credences constrain action?" — with the answer "they don't; something bolted on top does."
Second, the Parfit's-hitchhiker analogy cuts the wrong way for him. In the hitchhiker case the commitment is valuable because the two situations genuinely differ in a consequence the agent cares about: keep-the-commitment vs break-it have different payoffs (you live vs you die, or the predictor's reading changes your prospects). That's exactly what legitimizes binding there. In Sally's case Elga has stipulated the two B-situations don't differ in any consequence she cares about. So the disanalogy is precisely the feature that makes hitchhiker-style commitment rational: where binding pays, it pays because of a real downstream difference; strip that difference out (as Sally's stipulation does) and the rationale for binding evaporates. Michael can restore the rationale only by putting a real difference back in — which is move 1's first horn again, changing the case.
Vasco's exchange on the hitchhiker actually pins this down: he points out that if you just "commit as much as possible," your chance of survival tracks your commitment probability and there's no residual puzzle. Michael's reply — "the same solution is available to the unsharp agent if you treat them fairly" — is true but double-edged: yes, the resolute solution is available, and invoking it is the concession that local unsharp verdicts had to be overridden.
3. The statewise / maximality argument for accepting A
Michael's most technical contribution (in the top comment) is a way for the unsharp agent to derive "accept A first" without any of NARROW/PLAN/SEQUENCE: comparing "accept A now" (call it 1) against "reject A and hope to accept B" (2), he says 1 statewise-beats 2 with some probability and they're incomparable otherwise — so under maximality 1 is permissible and he'll take it, killing the dominated branch.
Elga's objection: look at what's actually being compared. Option 2 as Michael frames it is "reject A and if I can't guarantee I'll accept B, risk the dominated sequence." To get 1 to dominate 2, he has to treat 2 as carrying a live risk of ending in NEITHER — i.e. he has to already be modeling his own future B-node choice as possibly landing on reject-B. But that's the entire question. If the agent could guarantee she'll accept B after rejecting A (which is just the commitment), then 2 = B-only, which does not dominate 1 = A-only (they're incomparable, as their EVs cross at 60%), and the argument for being required to accept A collapses. So the statewise argument works only on the assumption that she cannot bind her future self — in which case Elga simply agrees the sequence is a problem and asks what makes each local rejection rational — or it works by importing the commitment, in which case the imprecise credence is again idle and we're at move 2's concession [see here]. Either way it doesn't vindicate UNSHARP; it either restates the problem or resolves it by non-credal means.
There's also a subtler point. Maximality, applied node-by-node, is precisely the permissive rule Elga says is too permissive: at the B-node in isolation it licenses reject-B. Michael's statewise argument applies maximality to the ex-ante policy comparison instead. Switching the object of maximization from acts to policies is, once more, the SEQUENCE/PLAN move — so Elga files it there and runs Sally. Michael's is the most resourceful version because he's derived the ex-ante verdict from a dominance relation rather than asserting a plan-norm, but the structural commitment (evaluate policies, not nodes) is identical, and it's that commitment Sally targets.
4. The "arbitrary precision" tu quoque
Michael's jab — isn't requiring sharpness "any worse than picking numbers to ensure precision for no better reason than that they occurred to you"? — is a real objection to SHARP, but Elga would note it's an objection to the plausibility/motivation of sharpness, not to the bet argument. And SHARP has a specific shield here: recall it explicitly does not entail Uniqueness. Elga isn't claiming the evidence picks out one number 45.000%; he allows a range of sharp functions to be permissible responses to the toothpaste evidence. So "you're forcing a spuriously exact number" misfires — SHARP permits you to adopt any of many precise credences; it just denies that your state can itself be spread out. The charge of false precision is aimed at Uniqueness, which Elga has already disowned. What SHARP does insist is that whatever you land on functions as a sharp probability for the purpose of guiding action — and the bet argument is what supports that, independently of how you chose the number.
The bottom line on Michael
Michael is the only one of the three [Anthony, Evans, and you] who attacks the load-bearing premise directly ("what if she cares about the difference?") rather than trying to route around it, and he's right that Elga's argument stands or falls on the stipulation that the two situations are identical in all respects the agent values. But Elga's reply is stable: every way of making the difference "matter" either (i) reintroduces a genuine downstream (dis)utility — which changes Sally's case and concedes that the money-only unsharp agent is stuck — or (ii) makes the mattering parasitic on "it would be irrational," which is circular. The Parfit's-hitchhiker parity and the statewise argument both turn out to require the commitment capacity, and invoking it is precisely the admission Elga wants: that unsharp credences, left to constrain action on their own, deliver the wrong verdict and must be overridden by a resolute policy that behaves like a determinate disposition.
So against all three of your interlocutors the dialectic funnels to the same joint: is a rational ideal agent to be assessed choice-by-choice (Elga) or entitled to bind herself and be assessed over policies (DiGiovanni's commitment, Evan's four-option reframe, Michael's statewise/parity argument)? Michael states the crux most honestly — he'll happily say the unsharp agent is required to accept A here — and that very concession is what Elga reads as victory: the imprecision has stopped doing the one thing it was introduced to do.
I see. Thanks for clarifying. Below is how Claude thinks Adam (the author of the article) would object to your comments. The objections make sense to me. Any reactions?
The unifying objection: the four-option reframe is one of the three rules
Evan's central claim is that he can dissolve the puzzle without NARROW, PLAN, or SEQUENCE: treat the situation not as two decisions (A yes/no, B yes/no) but as one choice among four policies — {A-only, B-only, BOTH, NEITHER} — notice BOTH statewise-dominates NEITHER, delete NEITHER, and you're done. He stresses "I didn't even consider the probability of H."
Elga's first reply is that this is exactly SEQUENCE (or PLAN) wearing plain clothes — and Evan concedes it in his own EDIT ("I think this is close in effect to SEQUENCE"). Evaluating the pair of choices as a single ex-ante object over sequences is the defining move of the global rules. So "I don't need any of the three" is false: he's using the third. And that matters, because Sally is aimed precisely here. Take Evan's B-only policy: it requires rejecting A and then accepting B. Compare the agent at the B-node in two situations — one where she reached it by rejecting A, one where B is offered alone. For a money-only agent these are identical in everything she cares about, yet the reframe must call rejecting-B impermissible in the first (it would complete NEITHER) and permissible in the second. That is the SEQUENCE verdict, and it fails for the SEQUENCE reason.
Why "consider them simultaneously" doesn't reach the actual problem
Evan's sports example — decline each of the Snofuls/Fleertis bets in isolation, take both together for a sure profit — leans on "when we consider our options simultaneously, that changes the calculus." Elga's rejoinder: in his setup the bets are not simultaneous. You settle A, and only then face B. So the live question is what binds you at the B-node, where A is already done and the only comparison is accept-B (+15/−10) versus reject-B (0). With an interval straddling 40%, maximality rules both permissible. The ex-ante fact "BOTH dominates NEITHER" is true but does not, by itself, reach into the B-node and make accepting B required there. Supplying that reach is the whole job of PLAN/SEQUENCE — which is why Evan can't actually skip them.
And the boast "I didn't even need to consider P(H)" is the tell, not the triumph. Dominance eliminates NEITHER for any credence — a sharp agent excludes it too. So the four-option elimination is entirely neutral between SHARP and UNSHARP; it was never the point in dispute. The dispute is about the sequential assembly of a dominated outcome from two individually-licensed choices, and the reframe simply doesn't engage it.
The EDIT smuggles in comparability — i.e. sharpness
Evan tries to close the "what if you plan B, reject A, then reject B?" gap thus: "a rational actor does not change their mind without new information. They would only choose B if they believe B > BOTH > NEITHER. Any rational actor who believes B > NEITHER would end up betting B."
This quietly assumes a complete ordering over the options — exactly what UNSHARP denies. B-only beats BOTH only when P(H) > 60%; with the interval [10%, 80%], B-only and BOTH are incomparable under maximality, as are A-only and BOTH. So "they would only choose B if B > BOTH" presupposes the agent can rank options the way a sharp credence lets her. Grant that comparability and of course she never lands on a dominated outcome — but you've then imported enough structure that she behaves like a sharp agent, which is Elga's strict-rules horn: you buy the right behavior only by reintroducing precision and thereby forfeiting the motivation for going unsharp in the first place.
"Rational actors with less information make worse decisions" gives the game away
Evan concedes that without foreknowledge an UNSHARP agent can reject A as optional, reject B as optional, land on NEITHER, and shrug it off as an information deficit. Two problems. First, Elga's case stipulates full foreknowledge, so the no-foreknowledge scenario isn't the one under discussion. Second, and more damaging, the diagnosis "less information" is wrong. A sharp agent — even with a diffuse-but-precise prior, and even with no foreknowledge — never rejects both, because her node-by-node expected-value verdicts are automatically time-coherent (reject A only if P(H) > 60%, accept B only if P(H) > 40%, and these can't jointly fail). The unsharp agent's node verdicts are not automatically coherent: both nodes say "optional," which is what lets her assemble NEITHER. So the pathology is produced by the unsharpness, not by any information gap. Evan's concession thus admits precisely the foreseeable-domination Elga is prosecuting, and mislabels its source.
The portfolio point isn't an argument for UNSHARP
Vasco already made the core objection and Evan half-conceded it: diversification falls straight out of sharp EV reasoning with diminishing marginal returns and cross-correlations. Elga would add the sharper version: where the portfolio reasoning gives sensible verdicts ("this combination statewise-beats doing nothing"), it's dominance reasoning a sharp agent honors equally; where it gives distinctively unsharp verdicts, it does so by licensing inaction — declining each option in isolation — which is just the reject-both pathology relocated to altruistic choice. (This is the "clueless agent whose intervals stay wide because it never acts" failure mode, which is live in your own work.)
"Can vs. should" is not a dodge — it's Elga's exact target
Evan's sign-off — "whether we should have unsharp probabilities is beside the point; my argument is about whether we can have them without sacrificing rationality, and I believe we can" — doesn't sidestep Elga. UNSHARP just is the "can" claim: it is consistent with perfect rationality to be unsharp. SHARP denies that. So Evan is engaging the thesis head-on, and Elga's reply is that the "can" fails for the reasons above: every route Evan takes either collapses into SEQUENCE (Sally sinks it) or into sharp-style comparability (motivation lost).
The honest crux
Where Evan has a real point — shared with DiGiovanni and Michael St Jules — is the suspicion that node-by-node "local" evaluation is the wrong model, and that a look-ahead agent who plans the whole tree does fine with wide intervals. Elga's whole case does assume that a theory of rational credence must deliver correct verdicts at each actual choice node, not merely over ex-ante policies. Evan is, in effect, denying that assumption. But he hasn't defeated Sally independently; he's relocated to ex-ante policy choice, which Elga classifies as SEQUENCE/PLAN and which Evan himself admits is "close in effect to SEQUENCE." So the disagreement bottoms out exactly where it did in the DiGiovanni thread [this one]: whether an idealized agent is entitled to bind her future choices (resolute/sophisticated look-ahead), or whether rationality must already be satisfiable choice-by-choice. Elga bets on the latter; Evan (like DiGiovanni) needs the former — and that is the genuine open question, not something Evan's four-option reframe settles.
Because the same kind of solution is available to someone with unsharp probabilities in Elga's scenario, if you're treating them fairly.
Solution to which problem? I am not sure what is supposed to be problematic. As far as I understand, one should just commit as much as possible to maximise the chances of survival.
It doesn't require an infinite world, only that you can't be 100% confident in any finite upper bound on your impact that you specify, and that there are infinitely many ways that the world could be (due largely to not full certainty about physics).
I agree there is a probability above 0 of (counterfactual) impact being larger than X for any X. So I think impact can be arbitrarily large. However, I do not think it can be infinite. The function f(x) = x can take an arbitrarily large value, but not an infinite value (its range is the set of real numbers). The function g(x) = 1/x can take an arbitrary small value, but not a value of exactly 0 (its range is the set of real numbers besides 0).
Why can't the fact that she'd pick a dominated sequence or regret it if she rejects both bets matter to her after rejecting bet A?
It is very counterintuitive that could matter for Sally for reasons that do not have to do with money.
I think most efforts to grow EA grow both Longtermist and non-Longtermist elements of EA.
Would it make sense for you to distinguish between growing longtermist and non-longtermist elements of EA? You prioritise longtermist interventions over animal welfare and global health ones.
I do agree though that the Longtermist effects of animal welfare are much bigger than near-term benefits.
Likewise for global health interventions? If so, animal welfare and global health interventions are also longtermist in the sense their longterm benefits are much larger than their nearterm benefits? In this case, it would be better to avoid terms like "Longtermist political donations", "other Longtermist donations", and "Longtermist careers", which could refer to animal welfare and global health interventions? If I thought the longterm effects of the vast majority of interventions were much larger than their nearterm effects, I would simply refer to the areas of the interventions instead of highlighting they are longtermist.
Yeah, it's rough and there's not a perfect method.
You did not make any comparison of the longterm benefits of different areas? At this point, I am just looking for one comparison, not a perfect one. Why not defaulting to the basic intuition that the benefits over the next few decades are a good proxy for the total benefits, which suggests global health interventions are more cost-effective than ones aiming to decrease the risk of global catastrophes?
I wouldn't be that extreme [GiveWell's top charities being 2*10^-30 times as cost-effective as some longtermist interventions], but I have some credence that something like that extreme of a tradeoff is right.
I doubt GiveWell's top charities are 2*10^-30 times as cost-effective as some longtermist interventions.
Don't think we need one for those sorts of things, just like we don't need a quantitative model suggesting, say, the odds of Vance being the next president are around 30%.
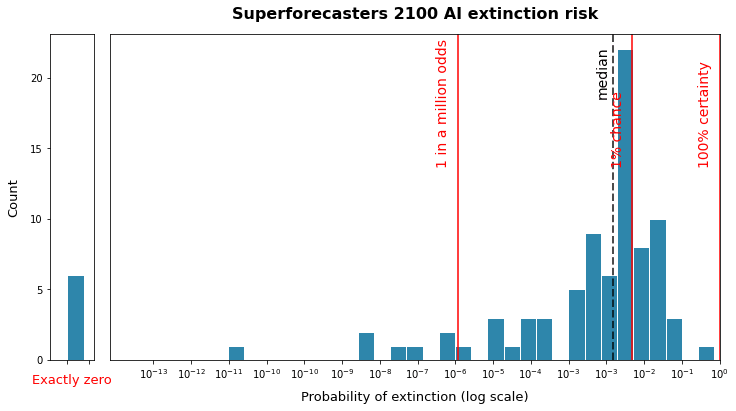
There is huge disagreement about the risk of extinction due to AI. Below are the predictions from superforecasters made in the Existential Risk Persuasion Tournament (XPT). There is nothing like that disagreement about the probability of Vance being the next president of the United States (US) assuming he is one of the 2 final candidates, which makes huge deviations from 50 % extremely unlikely.
I think we've talked elsewhere about why I don't buy that soil nematodes etc make us totally clueless about which animal welfare interventions are good.
The last point I made in my comment was not about this. I meant that global health interventions may be much more cost-effective than animal welfare interventions even neglecting effects on soil invertebrates (like nematodes).
A rational actor doesn't need NARROW, PLAN, or SEQUENCE. They need to consider the future: "Bet B is coming, so there's an arbitrage opportunity regardless of the probability."
I do not seem to understand. If one knew "Bet B is coming", one would know about the full set up in advance as in the post ("You're told the full setup in advance"). So rejecting both A and B would not make sense?
Here is a video I found useful that explains how to use backward induction. Below is Claude's reply to your comment after some iteration between us.
Thanks Michael — the backward-induction framing is the strongest version of the reply, and I want to grant what it gets right before saying where I think it's still exposed.
It does defuse three things at once. It needs no commitment (you predict the future Bet B choice and fold it back, rather than binding yourself), it needs no complete ordering (it runs on statewise dominance, so the Bet B node can stay genuinely unsharp), and it isn't ad hoc (backward induction is the standard discipline for sequential choice). So this isn't PLAN in disguise. Fair enough.
But I think the argument turns on a step that quietly does more than "just backward induction." Here is the full tree, with payoffs written as (if H / if not‑H). Bet A pays −10/+15 and Bet B pays +15/−10, so the four leaves are BOTH +5/+5, A-only −10/+15, B-only +15/−10, and NEITHER 0/0:
Notice both Bet B nodes are under-determined: at each, neither action statewise-dominates the other (BOTH vs A-only cross; B-only vs NEITHER cross). That is exactly the optionality unsharpness is meant to preserve, so dominance-pruning removes nothing at a Bet B node. To get a verdict on Bet A, backward induction has to fold each Bet B node back into a single continuation value — and the value of the reject-A branch depends entirely on which of its two (equally maximal) leaves you assume you'll pick.
Crucially, the accept-A node is also under-determined — it can land on BOTH or on A-only. So to compare the two root actions I have to fix a policy over both identical Bet B nodes. There are only three consistent options:
The only statewise-dominance relation anywhere in the tree is BOTH ≻ NEITHER. In particular A-only vs NEITHER crosses — A-only is worse than NEITHER in the H-state (−10 < 0) — so accepting A does not statewise-dominate rejecting A. Under either consistent policy (always-accept or always-reject), both root actions stay admissible and there's no dominance reason to prefer accepting A. And note that under "always accept B," NEITHER is never reached on either branch, so there's nothing for accepting-A to protect against in the first place.
The recommendation to accept A appears only under the third policy — the one that accepts B after accept-A but rejects B after reject-A. That is what produces the BOTH-vs-NEITHER pairing that makes accepting A look dominant. But that policy isn't backward induction resolving each node on its merits; it's a rule that makes your Bet B choice depend on whether Bet A preceded it, handing down different verdicts at two Bet B nodes that (for a money-only agent) are identical in every respect she cares about. That is precisely the SEQUENCE/PLAN pattern Elga's Sally case is built to reject.
Put differently: the recommendation to accept A materialises only when you assume you'll reject B specifically on the reject-A branch — i.e. you distrust your future self on one branch but not the other. That asymmetric self-distrust is either the sophisticated-chooser reading (treat your own future permitted choice as a hazard to steer around) or the differential treatment of identical nodes. Both are exactly the concessions at issue: if you're rationally required to prevent your future self from exercising reject-B, then reject-B was never really optional — which is just SHARP's verdict reached the long way.
So a sharper version of my earlier question: your derivation of "accept A" resolves the accept-A continuation to BOTH and the reject-A continuation to NEITHER. What consistent policy over the two identical Bet B nodes yields that pair? If "always accept B," reject-A gives B-only and the dominance is gone. If "always reject B," accept-A gives A-only and the dominance is gone. The only policy that yields it treats the two Bet B nodes differently — which is the thing an imprecise theorist owes an account of, and which Sally says you can't have.
(One aside on "you'd use backward induction even with sharp probabilities, or be worse off": agreed, but with sharp credences backward induction never has to override a node's verdict — it agrees with local EV-maximisation, and the cases where skipping it hurts are cases of myopia, not override. This is the unique setting where the rule must reverse a choice the agent's own decision rule calls permissible. That asymmetry is the tell.)