William the Kiwi
Bio
Hi I'm William and I am new to the Effective Altruism community.
William comes from a country in the Pacific called New Zealand. He was educated at the University of Otago where he received a first class honours degree in chemistry. He is currently traveling through Europe to learn more about different cultures and ideas.
How others can help me
William is interested in learning more about Artificial Intelligence and the magnitude to which it poses an existential risk to humanity.
How I can help others
William is new to Effective Altruism but is willing to learn ways in which he can aid humanity.
Posts 1
Comments25
The strongest counterargument for the Drowning Child argument is "reciprocity".
If a person saves a nearby drowning child, there is a probability that the saved child then goes onto provide positive utility for the rescuer or their family/tribe/nation. A child who is greatly geographically distant, or is unwilling to provide positive utility to others, is less likely to provide positive utility for the rescuer or their family/tribe/nation. This is an evolutionary explanation of why people are more inclined to save children who are nearby, however the argument also applies to ethical egoists.
Strong upvote. I have experienced problems with this too.
Actionable responses:
1. Build trust. Be clear why you are seeking power/access. Reveal your motivations and biases. Preoffer to answer uncomfortable questions.
2. Provide robust information. Reference expert opinion and papers. Show pictures/videos of physical evidence.
3. The biggest barrier for most people to process AI extinction risk is: the emotional resilience to process that they may die. Anything that lowers this barrier helps. In my experience, people grasp extinction risk better when they "discover" it from trends and examples, rather than are directly told.
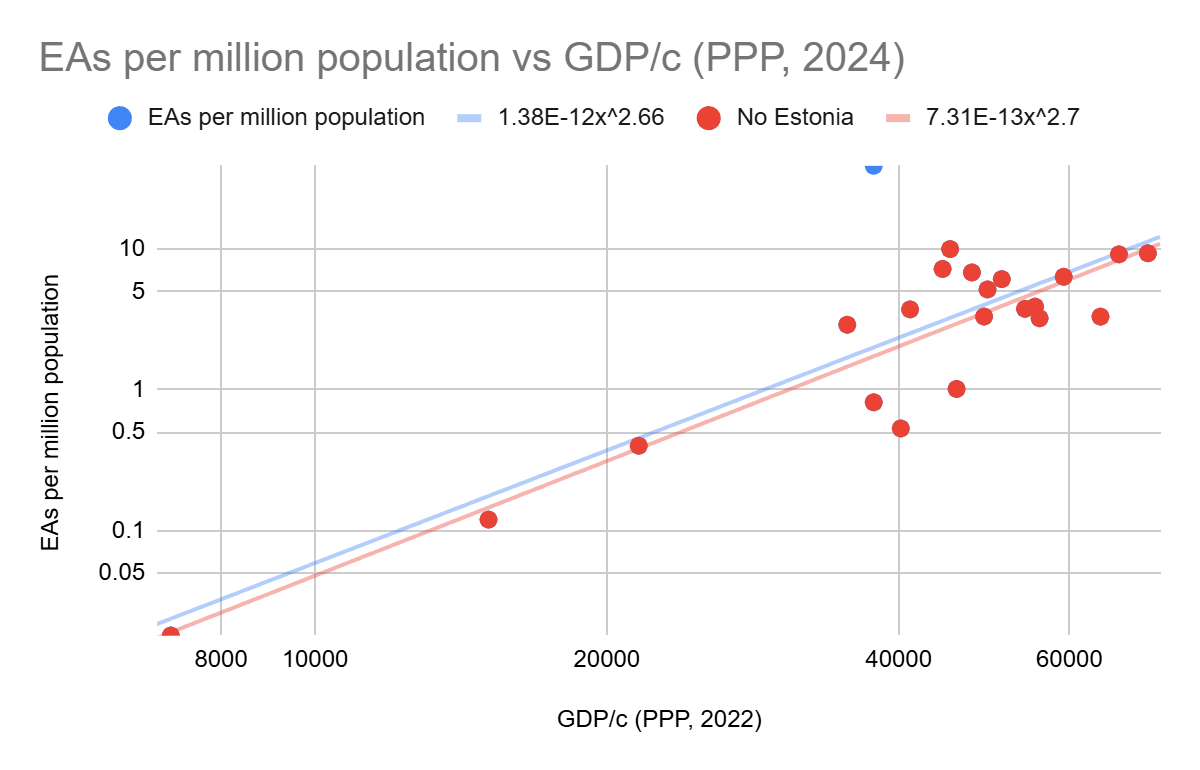
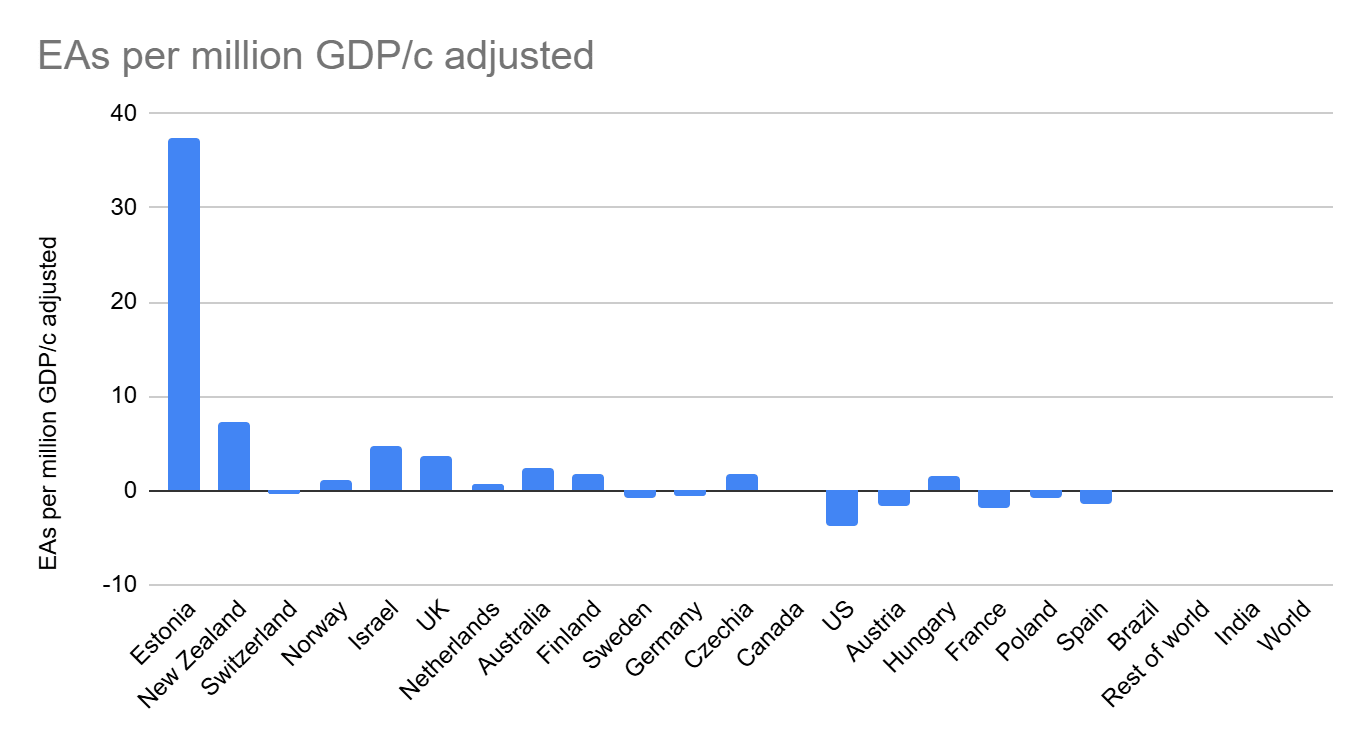
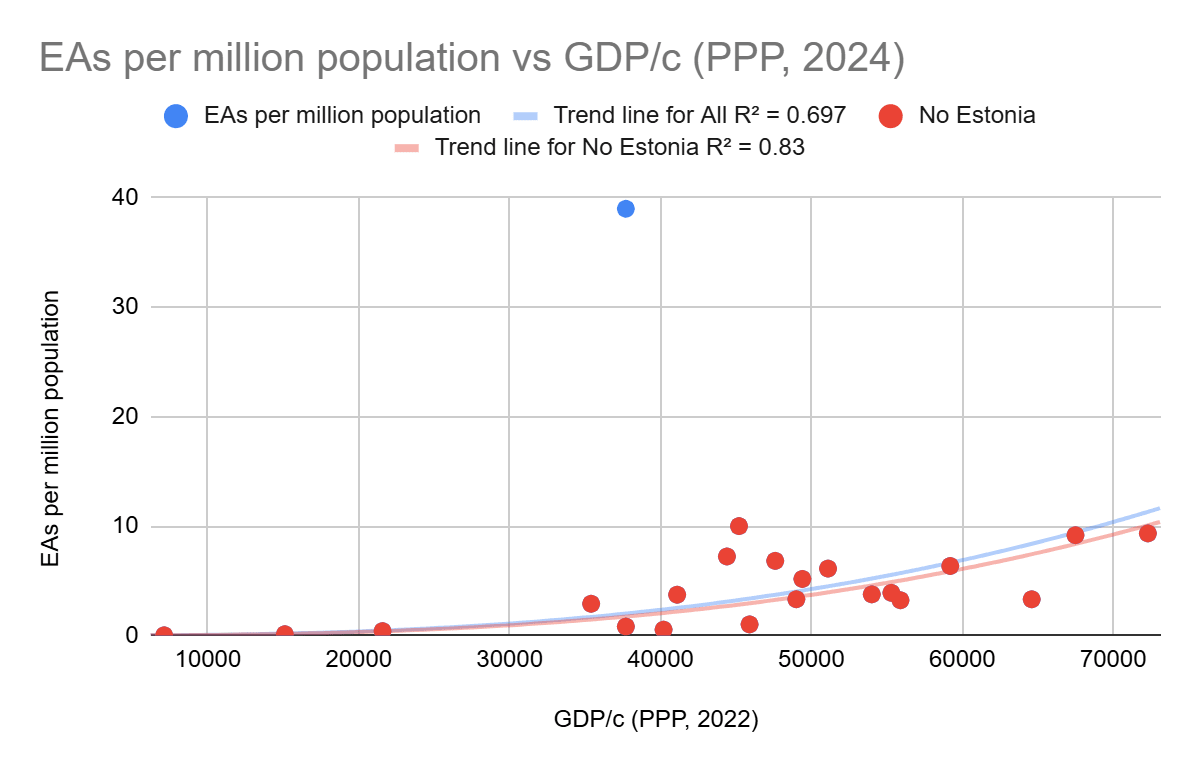
I would agree with Remmelt here. While upskilling people is helpful, if those people then go on to increase the rate of capabilities gain by AI companies, this is reducing the time the world has available to find solutions to alignment and AI regulation.
While, as a rule, I don't disagree with an industries increasing their capabilities, I do disagree with this when those capabilities knowingly lead to human extinction.
I would agree that this is a good summary:
Improving the quality/quantity of output from safety teams within AI labs has a (much) bigger impact on perceived safety of the lab than it does on actual safety of the lab. This is therefore the dominant term in the impact of the team's work. Right now it's negative.
If perception of safety is higher than actual safety, it will lead to underinvestment of future safety, which increases the probability of failure of the system.
Strong downvote for the use of the word "recent" to refer to a tournament run in 2022. This data is outdated and considerably misleading. The strong downvote can be retracted once the author makes it clear when the tournament was run.
For more recent data on expert opinion on extinction risk from AI, see AI Impacts' paper. This places extinction (or severe disempowerment) risk from AI at 16.2%
Otherwise an interesting analysis of why forecasters differed.