Summary
Language model agents (LMAs) like AutoGPT have promising safety characteristics compared to traditional conceptions of AGI. The LLMs they are composed of plan, think, and act in highly transparent and correctable ways, although not maximally so, and it is unclear whether safety will increase or decrease in the future.
Regardless of where commercial trends will take us, it is possible to develop safer versions of LMAs, as well as other "cognitive architectures" that are not dependent on LLMs. Notable areas of potential safety work include effectively separating and governing how agency, cognition, and thinking arise in cognitive architectures.
If needed, safety-first cognitive architectures (SCAs) can match or exceed the performance of less safe systems, and can be compatible with many ways AGI may develop. This makes SCAs a promising path towards influencing and ensuring safe AGI development in everything from very-short-timeline (e.g. LMAs are the first AGIs) to long-timeline scenarios (e.g. future AI models are incorporated into or built explicitly for an existing SCA).
Although the SCA field has begun emerging over the past year, awareness seems low, and the field seems underdeveloped. I wanted to write this article so that more people are aware of what's happening with SCAs, document my thinking on the SCA landscape and promising areas of work, and advocate for more people, funding, and research going towards SCAs.
Background
Language model agents (LMAs), systems that integrate thinking performed by large language models (LLMs) prompting themselves in loops, have exploded in popularity since the release of AutoGPT at the end of March 2023.
Even before AutoGPT, the related field that I call "safety-first cognitive architectures" (SCAs) emerged in the AI safety community. Most notably, in 2022, Eric Drexler formulated arguments for the safety of such systems and developed a high-level design for an SCA called the open agency model. Shortly thereafter, while at FHI with Drexler, Davidad published a specification for an ambitious system using this design somewhat-confusingly called an open agency architecture (OAA) (specifications for open agencies that are much closer to current-day systems like AutoGPT are also possible). Work on OAA is now starting at organizations like the AI Objectives Institute and Protocol Labs. A few months later, Conjecture announced their Cognitive Emulation initiative (with few public details).
I define a cognitive architecture as a set of specialized, interlinked systems that act intelligently as a whole. In this context, the underlying systems are different AI models (or instances of the same model), automated systems (including interpretable neuro-symbolic systems), and/or humans. In broader usage, cognitive architectures refer to models of the mind in general, including the human mind. I define a safety-first cognitive architecture as any cognitive architecture that is designed to be a safe AGI, either immediately when deployed or given future developments.
I would classify AutoGPT as a very basic cognitive architecture that is not safety first, but happens to have safety characteristics that have inspired some optimism. Some examples of optimism include Paul Christiano's recent post on sharing information regarding language model systems and agents, Seth Herd's thoughts on the capabilities and safety of LMAs and additional safety features that can be incorporated, and Simon Goldstein and Cameron Domenico Kirk-Giannini's more straight-to-the-point post on why the rise of LMAs reduces the risk of existential catastrophe. I think that SCAs will inspire even more reasons for optimism compared to LMAs.
Reasons for Optimism
In my model of SCAs, there are three main areas that describe how they work and where safety work can be focused. I believe that each of these areas is very promising, and thus, are each reasons for optimism:
- Agency - governing the different steps that come together to enable goals to be achieved, like planning and execution
- Cognition - governing the different mental functions that come together to enable intelligent behavior, like memory and sensing
- Thinking - governing the different thoughts that come together to support a particular line of reasoning, as seen in argument maps and factored cognition
In SCAs, these areas are as interpretable (human understandable) and corrigible (correctable) as possible. Interpretability and corrigibility are important aspects of AI safety. For example, if agency in an SCA is interpretable, we will know exactly what the SCA is aiming to do and how. If it is corrigible, we can modify those goals and plans if necessary and make adjustments to the system as a whole to prevent it from taking dangerous actions. It's worth noting that not all three aspects necessarily need to be interpretable and corrigible for the system to be safe; the necessity depends on the design of the proposed cognitive architecture.
Interpretability and corrigibility are essentially built by default into SCAs because SCAs are federated architectures. Federation entails splitting components into granular parts and standardizing how they work with and communicate with each other. If a cognitive architecture is sufficiently federated, agency, cognition, and thinking become represented in the architecture's information flows and governed by the architectures's rules-based processes, rather than black box AI models. The architecture itself can be designed to make those flows and processes human understandable and editable, which makes it interpretable and corrigible.
As an example, in an LMA, LLMs take standardized and human readable patterns of text as input, and generate them as output. The LLMs use this text to determine what task to perform (agency), retrieve information from memory (cognition), and reason through complex problems (thinking). LMAs happen to be fairly interpretable by default (aside from the thinking happening within LLMs that doesn't get expressed) since humans can make sense of the system text. Enabling humans to freeze the state of an LMA and edit its system text would make LMAs very corrigible as well. Of course, LMAs are just a step in the SCA direction.
SCA Safety Approaches
Federating Agency
The open agency model gives an example for how agency can be broken down into distinct parts. The model divides agency into: goal setting and plan generation, plan evaluation and selection, plan execution, and plan evaluation. Those processes occur sequentially, and different people and/or AI systems can contribute to each step.
I don't believe the meaning of "open agencies" was described by Drexler, but I can make an educated guess. "Agency" likely refers to "the ability to generate and carry out complex plans to do specific things" to borrow Jeffrey Ladish's definition, as well as agency in the sense of an organization, which is the most common analogy for how SCAs work and why we should expect them to be safe (I use the example of being the CEO of a company where all employees take instruction from, communicate, and document all of their work in a variant of Asana that you have full read and edit privileges to). "Open" likely points to the system being transparent and interpretable such that people can understand what the system is going to do and why before it does it (and pause/edit those things if necessary), enabling diverse people and AI models to participate in the working of the open agency (without being able to influence it unduly), and ensuring that everyone can benefit from the value provided by open agencies.
LMAs barely have federated agency, since planning and execution happen in autonomous loops rather than discrete phases, and single LLM instances are solely responsible for major parts of LMA agency. There is essentially no oversight or participation from other systems in determining what gets done, although sometimes, users can turn on manual human review for every single proposed action in supported systems (but this does not cover sub-actions that occur within one LLM instance). There are many agency safety improvements that can be made on top of LMAs, like separating and sequentially organizing the facets of agency, introducing robust evaluation and participation processes, restricting what AI models/humans can do when it comes to influencing or performing various aspects of agency, etc.
Federating Cognition
I haven't seen much work on concepts related to federating cognition in the AI safety community. One related line of inquiry is Drexler's work on QNRs, in which he spends a bit of time writing about the AI safety implications of separating memory from AI models, for which QNRs are a specific design for. The key effects are twofold: (1) externalizing memory adds support for memory interpretability and corrigibility (as opposed to editing information contained within neural networks themselves, which isn't really possible right now), which affects the behavior of AI models themselves that request/are provided with knowledge, and (2) external memory systems can contain information on human preferences which AI systems can learn from and/or use as a reference or assessment mechanism for evaluating proposed goals and actions. Drexler doesn't seem to connect his thoughts on federating cognition with open agencies (and thus SCAs), but I think they're very related.
I define federating cognition as separating various parts of how intelligent behavior emerges. Cognition can break down into high-level cognitive processes like short-term memory, long-term memory, sensing, and reasoning, and potentially even specific aspects of cognition that leverage reasoning itself, like planning and belief formation. I differentiate federating cognition from federating thinking in that thinking maps to the particular cognitive process of reasoning, which forms thoughts based on cognitive processes and the intelligent components of the systems itself (e.g. black box AI models). For example, information is fetched from the memory function, or senses are fetched from sense functions, to be reasoned about. I think federating cognition is substantially easier to make progress on, since cognitive functions like memory can be substituted with "white box" interpretable systems like memory databases rather than relying on neural networks, and cognitive processes play a significant role in understanding and shaping thinking itself.
LMAs actually do a significant amount of federated cognition. They employ separate systems for short-term memory (text stored in the system at runtime and handed off to LLMs in their prompts as needed), long-term memory (vector databases), sensing and communicating (vision, voice to text, text to voice), and of course, reasoning (performed by the LLMs themselves). Many safety features can be incorporated on top of how LMAs work; for instance, models can be denied persistent memory, and the knowledge made available to them can be restricted.
Federating Thinking
Federating thinking refers to federating the thoughts that emerge within an SCA. Unfortunately, many of the thoughts are anticipated to arise from neural networks, which seem like black boxes for the indefinite future.
However, not all hope in lost. In general, there are various mechanisms to understand AI reasoning, which can be organized on a spectrum from neural approaches on the left of the spectrum, to symbolic/automated reasoning approaches on the right of the spectrum. On the left, there's neural network interpretability work (including AI-assisted interpretability), which encompasses research efforts to try to understand how neural networks actually work. In the middle, there's factored cognition and formal verification (formal verification is the main component of Davidad's plan, which is an atoms-level world model) which involve reliably tracing the reasoning of neural networks without replacing them. And on the right, there's neuro-symbolic reasoning (e.g. the reasoning part of QNRs, in which interpretable knowledge graph embeddings are used to perform reasoning, and perhaps combining neural networks with external reasoning systems using things like domain-specific languages) and symbolic reasoning (e.g. knowledge representation and reasoning) which involve taking reasoning outside of black boxes and into white boxes that reason interpretably (this significantly overlaps with federating cognition, since reasoning would no longer exclusively occur in black box systems, and would likely involve integrating white boxes and black boxes in various schemes).
While it's related, I wouldn't classify neural network interpretability work as an area of safety research pertaining to SCAs, although it can help improve SCA safety (as can any other work being done on improving model safety). I'm more excited about retracing reasoning as well as leveraging "white boxes" for reasoning, given that many of those approaches already exist in the world today, and it seems like a matter of further exploring and scaling those approaches.
LMAs actually don't really federate thoughts. Top-level plans are generated using one LLM instance (and in some systems, revised, also using one LLM instance) without explanation (even with an explanation, that explanation is not necessarily reliable), and the execution of specific tasks is typically completed using a single instance and is similarly non-transparent and non-reliable. I think LLM self-delegation looks like factored cognition on the surface, but I think this is a far cry from how factored cognition should actually operate.
I think that federated thinking via factored cognition could be implemented in LMAs to improve safety, and that could potentially improve performance, although it would take more LLM calls and potentially increase costs significantly. There are many non-autonomous AI agents (confusingly, in the context of language models, "AI agents" can refer to autonomous, self-prompting, general agents, but also narrow autonomous agents, and even simply connecting an LLM to tools without self-prompting) being built that improve performance by performing reasoning in more granular ways, using different LLM instances. I briefly worked on one such agent in the context of a well-funded LMA-for-finance startup, which needed to break cognition down in order to use GPT-4 to effectively automate financial analysis tasks. I think the bottleneck, aside from expertise, complexity, and cost, is in seeing if LLMs can effectively factor cognition via self-prompting in effective ways.
I would also group limiting the compute, runtime, agentic nature of AI models in an SCA under this category. Constraining the underlying AI systems is an important part of many SCAs, and Connor Leahy (CEO of Conjecture) describes this concept as "boundedness," in which superintelligence emerges not from a single superintelligent model (which poses a considerable threat), but rather many human-like models working in parallel or in rapid succession to generate superintelligent results.
Common Themes
Three themes that affect overall SCA design emerge from considerations regarding agency, cognition, and thinking. First, safety measures for all areas involve adding constraints within SCA systems, including limiting actions that can be performed, limiting access to knowledge, and limiting the amount of thinking performed by a single AI model. Second, evaluating what's happening inside in all aspects of SCAs can be an important component of safety. Evaluations can be done by separate AI systems and lines of thought, automated systems (like comparing potential actions against a memory system), and human evaluation. Third, ethical checks and reasoning can be incorporated in many aspects of an SCA, including ensuring SCAs are given ethical top-level goals, storing information about human values in memory systems and using them to evaluate actions, and checking the ethical implications of certain chains of thought.
The SCA Ecosystem
The existing SCAs I am aware of are Conjecture's work on Cognitive Emulations, Drexler's open agency model, my own work on Cosmic, and Davidad's open agency architecture. Here's a diagram:
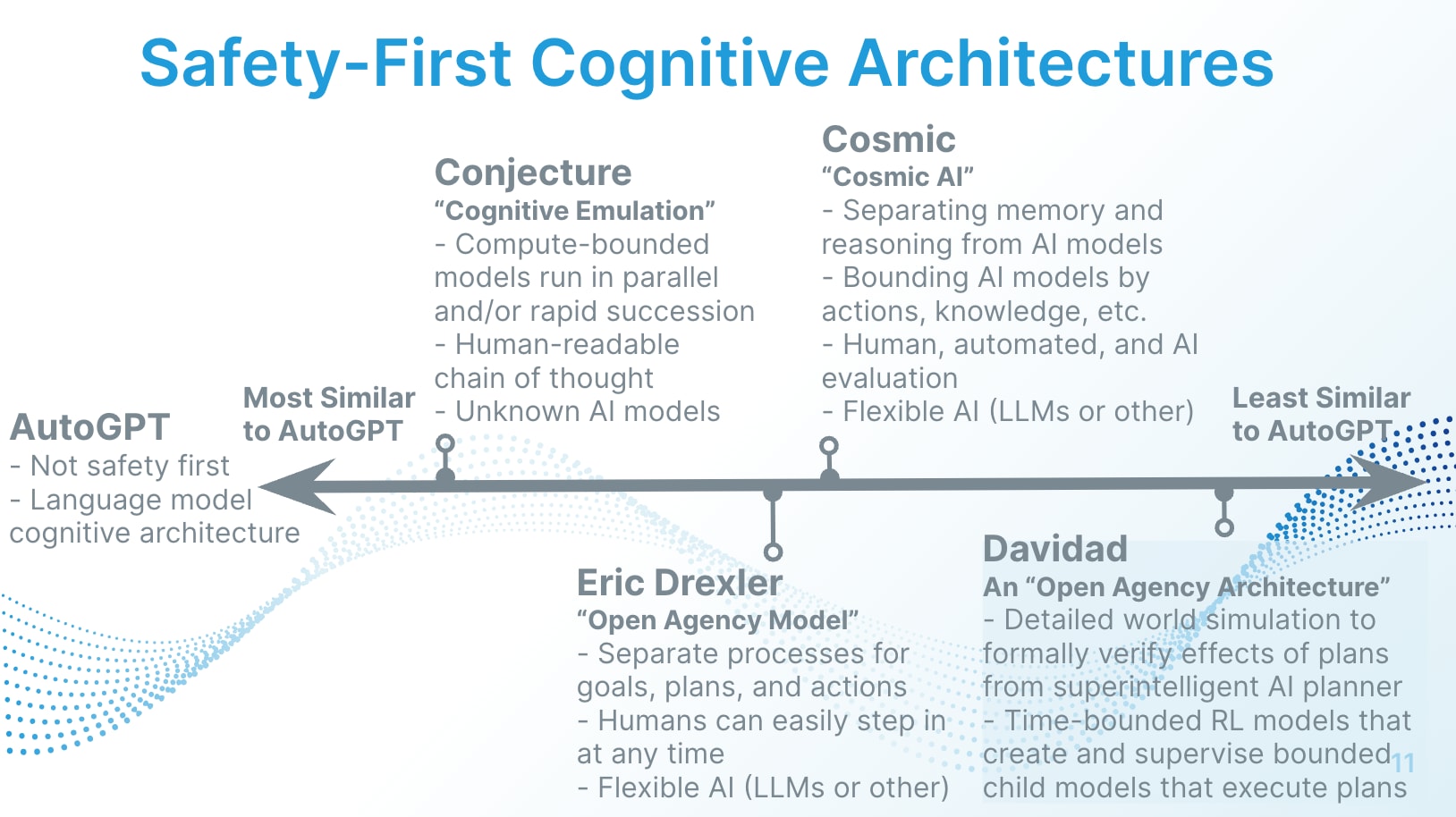
Existing SCAs have a lot in common. They generally involve federating agency, cognition, and thinking in related yet distinct ways. They always require that models are restricted, with the exact restrictions varying by category, including compute, runtime, knowledge, specialization of function, and action-taking. They always want to ensure interpretable and corrigible communication between AI models. They also generally incorporate evaluation, whether AI, automated, and/or human. This makes me think that the underlying intuitions behind SCAs and their high-level designs are valid.
The main differences between SCAs are in the underlying AI models used, and whether/how external memory and reasoning systems are used. The latter is seemingly only include in more advanced systems with more safety features, and the more advanced the AI, the more safety features are necessary. I think of the SCA space on a scale of current-day AI models to hypothetical future AI models, with more sophisticated SCAs incorporating design principles from simpler SCAs and building upon them.
Given the similarities in design and direct relationship between SCAs designed for the present versus the future, I believe there is a lot of room to research and share SCA design principles, policy implications, test results from present-day and extrapolated future AI models and scenarios, and more. I also think there is also room for collaboration in developing elements of SCAs, for instance, external memory and reasoning components.
Implications of SCAs for Safety
I think that SCAs have many implications for ensuring the safe development and deployment of AGI. I'll aim to share some of my intuitions regarding SCAs, which could change over time.
Relevance for Different Timelines and AGI Architectures
I think that AGI could be built in many different ways, and the first AGI to be developed could be shaped by a number of factors, but SCAs will represent a likely and promising option for safe AGI across many timeframes. From a very short timeline perspective, it seems LMAs are one of the leading (if not the only leading) plausible way AGI could be developed in the very near future, making it important to invest in the safety of current LLM-based systems (in a way that will also be compatible with near-future AI models). For longer timelines, SCAs will always be compelling not just because of the inherent safety in federated architectures, but also from a performance standpoint. SCAs can also essentially be used on top of any AI model even if the AI model wasn't designed to work with SCAs. For instance, in the OAA approach, independently ensuring that AGI proposals model proposals will produce safe results seems universally helpful regardless of the AGI's design, and AI models will need to connect to repositories of knowledge in order to best understand and affect the world.
I believe that SCAs can increase performance relative to unitary systems since they take advantage of the strengths of various systems in one. For example, when it comes to external memory and reasoning, such systems are essentially 100% reliable, interpretable, and efficient when compared to alternatives like encoding 100% reliable memories and patterns of reasoning into an LLM's neurons. In present-day LLMs, I give examples above for how SCA features can also potentially improve performance, including how factored cognition enables LLMs to perform knowledge work more effectively, and how using external memories are more efficient than relying on information encoded in LLM. I believe that these key infrastructure components will be passed on to future systems, as well as high-level learnings and design principles for federated cognitive architectures.
Effect on Near-Term AI Development
The promise of SCAs from a viability and safety standpoint makes them a promising path for ensuring safe AGI development in multiple ways. First, they could directly become or be developed into a safe AGI, potentially starting from non-AGI SCAs like basic LMAs. Second, they could be used to bootstrap to even safer and more performant AGIs, which could take the form of SCAs or alternative designs. Third, near-term work on SCAs, including developing them in more capable ways, could be used as a method to shape the development of AGI in safer directions.
To elaborate on shaping AGI development, developing safe and performant SCAs, perhaps based on language models, would increase attention towards this area. I think there's a chance such attention could be beneficial.
From a commercial perspective, it could reduce incentives to take less safe paths towards AGI, like unitary agents, and ensure that safety features are incorporated into commercial cognitive architectures that could become or influence AGI in short-timeline scenarios (I anticipate the effort to incorporate safety features once developed are quite low, with the rapid iterations being performed with LMAs as case in point). If non-AGI SCAs are already sufficient to perform most knowledge work, that might also reduce the incentive to develop more powerful AI systems.
While developing SCAs would increase the adoption of safety measures in industry, demonstrating their capability to pursue unethical goals would likely shift society in much more safety-oriented directions (which non-open-source approaches would likely benefit from, and be incentivized to encourage). For instance, since cognitive architectures could simply be instructed to execute unethical goals if unconstrained, that would cause significant alarm (if non-AGI cognitive architectures, like LMAs, were used to demonstrate this risk, that would produce the desired effect without posing an existential risk). There's something different about an LMA autonomously doing something like cyberbullying, for example, compared to someone manually copy-pasting a problematic output from an LLM. This could cause a push to halt practices like open sourcing AI models and LMAs, and introduce significant regulations to prevent misuse, which would reduce risks in advance of the development of true AGI.