There are a couple of explanations of mesa-optimization available. I think Rob Miles' video on the topic is excellent, but I think existing written descriptions don't make the concept simple enough to be understood thoroughly by a broad audience. This is my attempt at doing that, for those who prefer written content over video.
Summary
Mesa-optimization is an important concept in AI alignment. Sometimes, an optimizer (like gradient descent, or evolution) produces another optimizer (like complex AIs, or humans). When this happens, the second optimizer is called a 'mesa-optimizer'; problems with the alignment (safety) of the mesa-optimizer are called 'inner alignment problems'.
What is an optimizer?
I'll define an optimizer as something that looks through a 'space' of possible things and behaves in a way that 'selects' some of those things. One sign that there might be an optimizer at work is that weird things are happening, by which I mean 'things that are very unlikely if the system was behaving randomly'. For instance, humans do things all the time that would be very unlikely to happen if we behaved randomly, and humans would certainly not exist at all if evolution worked by just making new organisms with totally random genes.
The human brain
The human brain is an optimizer -- it looks through the different things you could do and picks ones that get you things you like.
For instance, you might go to the shop, get ice cream, pay for the ice cream, and then come back. If you think about it, that's a really complex series of actions -- if you behaved completely randomly, you would never ever end up with ice cream. Your brain has searched through a lot of possible actions you could take (walking somewhere else, dancing in your living room, moving just your left foot up 30 degrees) and expects none of them will get you ice cream -- and has then selected one of the very few paths that will get you what you want.
Evolution
A stranger example of an optimizer is evolution. You've probably heard this already -- evolution 'optimizes inclusive genetic fitness'. But what does this mean?
Organisms change randomly-- their genes change due to mistakes in the process of making new organisms. Sometimes, that change helps the organism to reproduce by allowing it to survive longer, by making it more attractive, etc. When that happens, the next generation has more of that change in it. Over time, lots of these changes accumulate to make very complicated systems like plants, animals, and fungi.
Because there end up being more of the organisms that reproduce more, and fewer of the ones with changes that make them reproduce less (like genetic diseases), evolution selects from the space of all the mutations that happen -- if you made an organism with a completely random genome, it would certainly die immediately (or rather, not be alive to begin with).
AI Training
When an AI is trained, it's usually done by 'gradient descent'. What is gradient descent?
First, we define something that says how well an AI is doing (the 'loss function'). This could be very simple (1 point every time you output 'dog') or very complex (1 point for every time you say something that is an English sentence that makes sense as a response to what I typed in).
Then, we make a random AI-- one that's basically just a set of random numbers connected to one another. This AI, predictably, does very badly -- it outputs 'dska£hg@tb5gba-0aaa' or similar. We run it a lot of times, and see when it comes a bit close to outputting 'dog' (say, with a d as the first letter, or outputting close to 3 characters). Then, we use a mathematical algorithm to figure out which of those random numbers caused the AI to be close to what we want, and which were very far from the right number -- and we move them very slightly in the right direction. Then we repeat this a lot until, eventually, the AI consistently outputs 'dog' every time[1].
This process is strange, but it's much easier to figure out the direction the numbers should change in than to figure out from the beginning exactly what the right numbers are, particularly for more complicated tasks.
Again, we can see that this process is an optimizer -- the random AI does nothing interesting, but by pushing the numbers around in the right direction, we can do very complicated tasks which would never happen at random. And this is happening because we look at a very large 'space' of possible AIs (with different numbers in them) and 'move' through it towards an AI that does what we want.
What is a Mesa-optimizer?
To understand mesa-optimization, we'll return to the evolution analogy. We saw two examples of optimizers -- evolution, and the human brain. One of these created the other! This is the key to mesa-optimization.
When we train AI, we might -- just like evolution -- find AIs which are optimizers in their own right, i.e. they look over spaces of possible actions and take ones that give them a good score, similar to the human brain. In AI, this second optimizer is referred to as the mesa-optimizer. Mesa-optimizer refers to the AI that we have trained itself, while the outer optimizer is the process we used to train that AI (gradient descent). Note that some AI -- especially simple AI-- may not count as mesa-optimizers, because they don't display behaviour complex enough to qualify as optimizers in their own right.
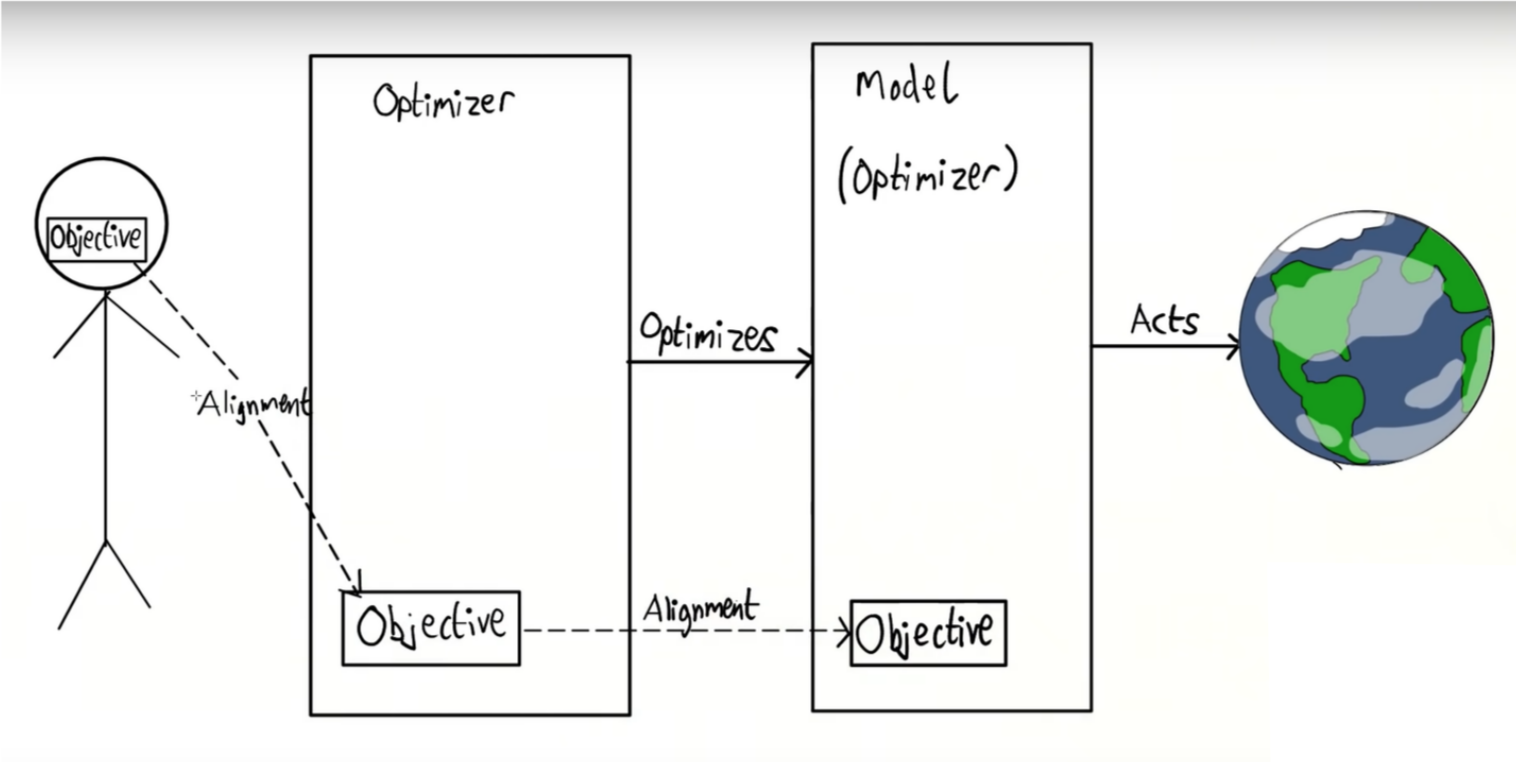
Why is this a problem?
If we have two optimizers, we now have two problems with getting AI to behave well (two 'alignment problems'). Specifically, we have an 'outer' and an 'inner' alignment problem, relating to gradient descent and the mesa-optimizer respectively.
The outer alignment problem is the classic problem of AI alignment. When you make an optimizer, it's hard to make sure that the thing you've told it to do is the thing that you actually want it to do. For example, how do you tell a computer to 'write coherent English sentences that follow on sensibly from what I've written'? Defining complex tasks formally as a loss function can be very tricky. This can be dangerous with some tasks, but discussing that will take too long for this post.
The inner alignment problem is a bit trickier. We might define our loss function perfectly for what we want it to do, and have an AI that still behaves dangerously, because it's not aligned with the outer optimizer. For instance, if gradient descent finds an algorithm that optimizes 'pretend to behave well to get a good score while I'm being trained, so I can do what I actually want later on' ('deceptive alignment'), this will get an excellent score on our training dataset while still being dangerous.
Examples of inner misalignment
Humans
For our first example, we'll return to our evolution analogy one more time. Evolution's search for things that are very good at surviving and reproducing eventually produced brains -- a kind of mesa-optimizer. Now, humans are becoming misaligned with evolution[2].
Because evolution is quite an odd type of search (like gradient descent), it couldn't put the concept of 'reproduction' into our brains directly. Instead, a bunch of simpler concepts developed to do with genital friction, complex things to do with relationships, and so on.
Now, humans do things which very effectively meet those simpler concepts, but are terrible for inclusive genetic fitness, like masturbate, watch porn, and not donate to sperm banks. This shows that evolution has an inner misalignment problem.
Evolving to Extinction
But humans are still pretty well aligned to evolution -- our population size is great compared to other apes. To show how badly evolution can be inner misaligned, let's look at Irish Elk. Irish Elk (probably) evolved to extinction. But isn't that the opposite of how evolution works? How does this happen?

Sexual selection is when animals evolve to be attractive to mates, rather than to be better at surviving. This can be good for evolution -- honestly showing potential mates that you're strong, fast, well-fed, etc. can be a good way to ensure that those likely to survive reproduce more. For instance, growing large antlers can be a sign that you're well-fed and able to provide plenty of nutrition to those antlers, or that you're able to fight well to defend yourself.
However, sexual selection can also go wrong. Having large antlers is great-- up to a point. Once they get too large, you might not be able to move your head well, get caught on trees, and waste a lot of key resources. But if females love great antlers, males with huge antlers reproduce a lot, even if only a few of them survive to adulthood. Soon, all the males have huge antlers and are struggling to survive. Even if this doesn't cause extinction directly, it can contribute if the population weakens. This shows that evolution has a bad inner alignment problem.
Hiring Executives

{kind=link}
When hiring executives, the shareholders of a company face two problems.
The first problem is an outer alignment problem: how do they design a hiring process and incentives scheme such that the executives they hire are motivated to act in the best interests of the company? This problem seems genuinely hard-- how do they stop executives acting in the company's short-term interests to get bonuses and look good at the cost of doing long-term harm to the company (when they've likely moved on to another company to do the same thing[3])?
The inner misalignment problem here comes from the fact that the people being hired are optimizers themselves -- and may have very different goals from those of the shareholders. If, for instance, there are potential-executives who want to harm the company[4], they're strongly motivated to perform well on the hiring process. They may even be motivated to perform well on metrics and incentive schemes in order to stay on and continue doing subtle damage to the company, or change the focus of the company to or away from certain areas while costing the shareholders money in ways that are difficult to measure.
Conclusion
I'd like to note that the borders between outer and inner misalignment are quite fuzzy, and experienced researchers can sometimes struggle to tell them apart. Additionally, you can have inner and outer misalignment at once.
Hopefully this helps you more thoroughly understand inner misalignment. Please say in the comments if you have questions, or feedback on my writing.
Some questions to check you understood:
- What is an example of a mesa-optimizer? How is it different from other kinds of optimizers?
- What is an 'outer alignment problem'?
- What is 'deceptive alignment'?
I know I'm necro-ing this, but did you come up with the sexual selection example yourself?