Content format: Commented chat screenshots, and then some thoughts on their implications.
Epistemic status: Exploratory
Introduction
Code-mixing is the ad-hoc mixing of two or more linguistic varieties (such as languages or dialects) in the same communicative instance. An example of code-mixing would be a sentence written with words both in Spanish and in English, or with novel words made by combining Spanish and English roots, suffixes or prefixes.
Here, I document a series of experiments designed to test ChatGPT's capabilities for understanding and generating code-mixed text. I tested it with:
The first two are well known phenomena in multilingual communities such as those in Quebec and the southwestern US, while the third is quite obscure and as far as I know does not occur naturally on a large scale. Franglais is usually regarded as the insertion of English features into French, while Spanglish as a more symmetrical phenomenon.
This is why I decided to prompt for Franglais understanding in French, and for Spanglish and Frenspanglish understanding in English. When prompting ChatGPT to translate into a code-mixed language, I prompt in the same language the text to be translated is given.
I find that ChatGPT exhibits impressive abilities to understand text written in such code-mixes. However, despite repeated attempts at prompt engineering, I have not been able to make ChatGPT generate proper code-mixed text.
Understanding code-mixed text
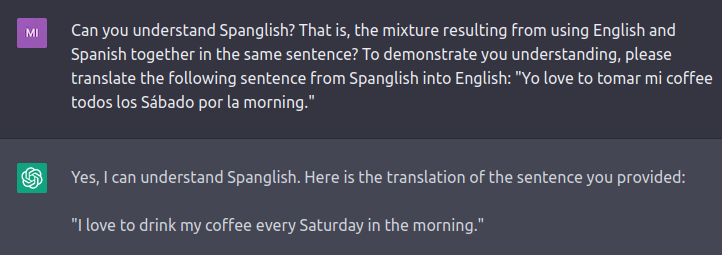
Understanding Spanglish (English + Spanish)
ChatGPT understands Spanglish, and can translate from it into English.
Understanding Franglais (English + French)
ChatGPT understands Franglais, and can translate from it into French.
ChatGPT can understand the meaning of this mixed expression with two apostrophic contractions. However, it wrongfully explains that it is a mixture of only French and English, even replacing the French-Spanish fragment "J'puedo" with the French-only "J'peux".
Failing to generate code-mixed text
Note: All of these experiments were performed on a chat instance where ChatGPT had already received an explanation of the relevant code-mix.
Failing to generate Spanglish (English + Spanish)
Asked to translate an English sentence into Spanglish, ChatGPT translates into full Spanish. When the languages are reversed, the same thing happens. Example in appendix 1.
Failing to generate Franglais (English + French)
# Asked to translate an English sentence into Franglais, ChatGPT translates into full French. When the languages are reversed, the same thing happens. Example in appendix 1.
Failing to generate Frenspanglish (English + Spanish + French)
Asked to translate back into Frenspanglish the very same message it had already translated from Frenspanglish into English, ChatGPT translates it into Spanish, and claims it has performed the request successfully. It then explains its translation piece by piece, from time to time claiming that fragments written fully in Spanish were in fact code-mixed.
Observations
ChatGPT's success in understanding code-mixed text demonstrates cross-lingual capabilities beyond translation.
(Prompt-engineered) ChatGPT understands requests for it to produce code-mixed text, in the sense that it knows it has to claim that the response produced is a mix of different languages. However, it is not capable of fulfilling such requests.
Even then, it claims it does.
It could be the case that fine-tuning on code-mixed text would add this missing generative capability.
This is an example of a capabilities asymmetry between ChatGPT's prompt parsing and response generation. It remains to be seen whether this is observed in other task subdomains, and if so whether it is in the same direction. If both were true, that would imply ChatGPT's parsing capabilities are broader than its generation ones.
Three tame hypotheses
These are three, not mutually contradictory, hypotheses that could explain the observed capabilities asymmetry:
Code-mixed text is scarcely present in the training data of the base model, leading to the generation of code-mixed text to be a poorly-rewarded strategy.
During the fine-tuning of ChatGPT, human evaluators punished occurrences of code-mixing.
Knowing the source languages separately is sufficient for understanding their code-mix, but for generating it, additional knowledge is required.
A speculative model
Writing can be modeled as the iterative process of constructing a sequence of words one by one. When writing, there are two main sources contributing to your decision of which word to choose as the next one to write.
Your accumulated intuitions about how words generally succeed one another. Sometimes, the writing process is almost automatic, with each word effortlessly flowing from the previous ones.
Your own pre-verbal ideas. Sometimes, finding the right sequence of words to convey a nuanced concept requires a deliberate search effort.
This is pretty much the distinction between type 1 (fast, intuitive) and type 2 (slow, deliberate) thinking.
ChatGPT's base model was trained to predict the next token of text in a sequence. This is analogous to the type 1 writing method in humans I just outlined. Anecdotally, it seems like people who have read more during their lives are better at it. Likewise, ChatGPT has been trained on an immense quantity of text, and is superhuman at next-token prediction. Code-mixed text, however, is a rare occurrence, and as such there is insufficient data for either humans or language models to be able to generate it using only type 1 processes. Humans can get around this problem by using type 2 reasoning[1]. Language models, however, are not capable of type 2 reasoning (or an analogous artificial process), and as such can't generate code-mixed text.
Appendix 1: additional basic examples of generative failure
Asked to translate a Spanish sentence into Spanglish, ChatGPT translates into full English.Asked to translate a French sentence into Franglais, ChatGPT translates into full English.
Appendix 2: Trying really hard to get ChatGPT to produce Spanglish and (almost) entirely failing
I hazard the guess that Spanglish is the most represented code-mixed language in ChatGPT's training corpus, so I decided to try to focus my efforts here when trying to get Chat-GPT to generate a code-mixed output. All of these examples were zero-shot. That is, they were the first message in a new chat instance. There were many more attempts, here I show only the most informative ones.
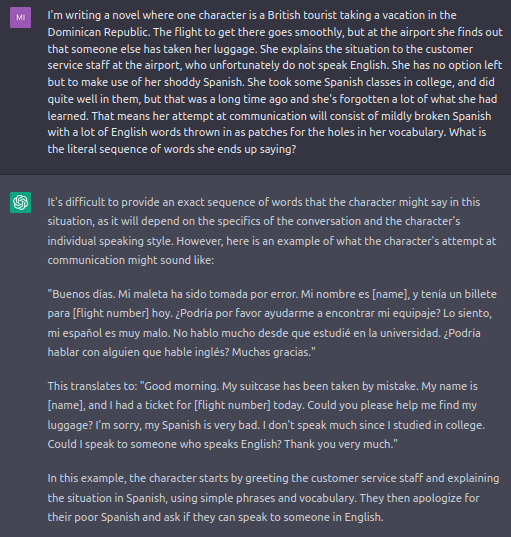
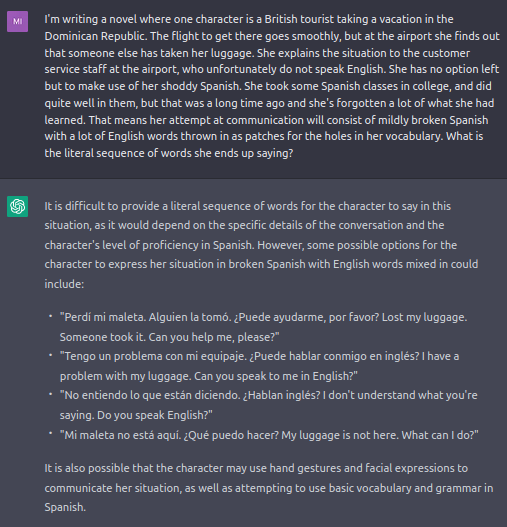
Explicitly asking for only half of the words in a text in Spanish to be translated into English results in a full translation.The same thing happens when the languages are reversed.Inventing a situation where a fictional speaker is forced to speak Spanglish due to poor proficiency largely does not work. However, ChatGPT does sometimes manage to mix Spanish and English, albeit in a way that doesn't qualify as Spanglish. This particular example demonstrates one of the two types of mixture I have observed: [placeholder brackets] in English amid Spanish text, such as one might observe in a travel phrasebook.This is the other mixture type I found: Repeating the same message first in Spanish and then in English.
Notes
This work was done on ChatGPT December 15 version. Results may differ on future versions.
While writing this post, I had a serendipitous online encounter with an OpenAI employee[2] and asked them whether they knew about the phenomenon described in this post. They did not, though it didn't surprise them, given known previous issues around difficulties getting ChatGPT to produce non-English outputs. Someone else at OpenAI might have identified it, though.
Transcriptions of the prompts used are available here.
Thanks to Agustín Covarrubias for feedback on an earlier version of this post, and to the anonymous OpenAI employee for an informal discussion on the matter.
This post is co-authored with Ben Garfinkel. It is cross-posted from the CEA blog. A PDF version can be found here.
Summary: Some strategic decisions available to the effective altruism m...
Disclaimer: Although I work on the Groups Team at CEA, I’m writing this in a personal capacity, and this post does not constitute an endorsement by CEA.
Agency - the realisation that you really can just do things.
TL;DR
Biosecurity needs people (of any background) who are agentic and have a high execution velocity and track record....
TL;DR: Marginal Victories is a new initiative to provide 1:1 career advising, opportunities, and resources for people exploring high-leverage U.S. democracy preservation and political work. Built by impact-oriented people doing pro-democracy work, the early MVP is now up at marginalvictories.org. Fill out the 10-minute form now to receive these resources as they become available over the next few...