Reinforcement Learning from Human Feedback (RLHF) has emerged as the central alignment technique used to finetune state-of-the-art AI systems such as GPT-4, Claude, Bard, and Llama-2. Given RLHF's status as the default industry alignment technique, we should carefully evaluate its shortcomings. However, there is little public work formally systematizing problems with it.
In a new survey of over 250 papers, we review open challenges and fundamental limitations with RLHF with a focus on applications in large language models.
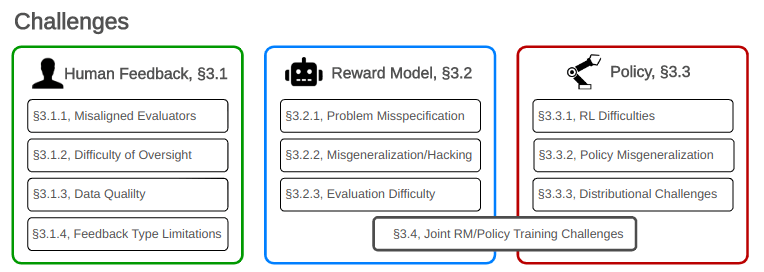
An overview of various types of challenges with RLHF. We divide them into three main groups: challenges with collecting feedback, fitting the reward model, and training the policy.
Abstract
Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing the challenges it poses. In this paper, we (1) survey concrete challenges and open questions with RLHF; (2) overview techniques to better understand, improve, and complement it in practice; and (3) discuss how standards for transparency and auditing could help to reduce risks. We emphasize the importance of recognizing the limitations of RLHF and integrating it into a more complete framework for developing safer AI.
Contributions
Concrete challenges with RLHF: We taxonomize and survey problems with RLHF, dividing them into three primary categories: challenges with feedback, challenges with the reward model, and challenges with the policy. We also distinguish between challenges that are relatively tractable versus ones that are more fundamental limitations of alignment with RLHF.
Incorporating RLHF into a broader technical safety framework: We discuss how RLHF is not a complete framework for developing safe AI and highlight additional approaches that can help to better understand, improve, and complement it.
Governance and transparency: We consider the challenge of improving industry norms and regulations affecting models trained with RLHF. Specifically, we discuss how the disclosure of certain details by companies using RLHF to train AI systems can improve accountability and auditing.
Transparency
We argue that a sustained commitment to transparency (e.g. to auditors) would make the RLHF research environment more robust from a safety standpoint. First, the disclosure of some details behind large RLHF training runs would clarify a given organization's norms for model scrutiny and safety checks. Second, increased transparency about efforts to mitigate risks would improve safety incentives and suggest methods for external stakeholders to hold companies accountable. Third, transparency would improve the AI safety community's understanding of RLHF and support the ability to track technical progress on its challenges.
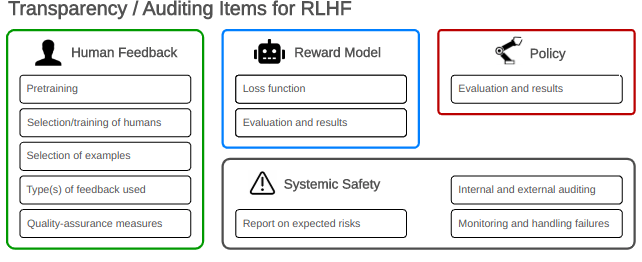
Specific policy prescriptions are beyond the paper’s scope, but we discuss specific types of details that, if disclosed, could be indicative of risks and should be accounted for when auditing AI systems developed using RLHF.
Types of information about RLHF training runs that could be indicative of risks and should be disclosed during audits. See the paper for details.
RLHF = Rehashing Lessons from Historical Failures?
RLHF offers new capabilities but faces many old problems. Researchers in the safety, ethics, and human-computer interaction fields have been demonstrating technical and fundamental challenges with the system and its components for years. In 2023, Paul Christiano (the first author of the 2017 paper, Christiano et al. (2017), prototyping RLHF) described it as a “basic solution” intended to make it easier to “productively work on more challenging alignment problems” such as debate, recursive reward modeling, etc.
Instead of being used as a stepping stone toward more robust alignment techniques, RLHF seems to have also undergone a sort of “capabilities capture” in which its effects for advancing capabilities have become more prominent than its impacts on safety. We argue that the successes of RLHF should not obfuscate its limitations or gaps between the framework under which it is studied and real-world applications. An approach to AI alignment that relies on RLHF without additional techniques for safety risks doubling down on flawed approaches to AI alignment.
Future Work
We think that there is a lot of basic research and applied work that can be done to improve RLHF and integrate it into a more complete agenda for safer AI. We discuss frameworks that can be used to better understand RLHF, techniques that can help to solve challenges with it, and other alignment strategies that will be important to compensate for its failures. See section 4 of the paper.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This is a linkpost for Request for Proposals: Research and Applied Work on Digital Minds.
I'm glad to announce a request for proposals for research and applied work on digital minds at Longview Ph...