This post is prompted by two recent pieces:
First, in the podcast "Emergency Pod: Mamba, Memory, and the SSM Moment", Nathan Labenz described how he sees that we are entering the era of heterogeneity in AI architectures because currently we have not just one fundamental block that works very well (the Transformer block), but two kinds of blocks: the Selective SSM (Mamba) block has joined the party. These are natural opposites on the tradeoff scale between episodic cognitive capacity (Transformer's strong side) and long-term memorisation (selective SSM's strong side).[1]
Moreover, it's demonstrated in many recent works (see the StripedHyena blog post, and references in appendix E.2.2. of the Mamba paper) that hybridisation of Transformer and SSM blocks works better than a "pure" architecture composed of either of these types of blocks. So, we will probably quickly see the emergence of complicated hybrids between these two.[2]
This reminds me of John Doyle's architecture theory that predicts that AI architectures will evolve towards modularisation and component heterogeneity, where the properties of different components (i.e., their positions at different tradeoff spectrums) will converge to reflect the statistical properties of heterogeneous objects (a.k.a. natural abstractions, patterns, "pockets of computational reducibility") in the environment.
Second, in this article, Anatoly Levenchuk rehearses the "no free lunch" theorem and enumerates some of the development directions in algorithms and computing that continue in the shadows of the currently dominant LLM paradigm, but still are going to be several orders of magnitude more computationally efficient than DNNs in some important classes of tasks: multi-physics simulations, discrete ("system 2") reasoning (planning, optimisation), theorem verification and SAT-solving, etc. All these diverse components are going to be plugged into some "AI operating system", Toolformer-style. Then Anatoly posits an important conjecture (slightly tweaked by me): as it doesn't make sense to discuss some person's "values" without considering (a) them in the context of their environment (family, community, humanity) and (b) their education, it's pointless to discuss the alignment properties and "values" of some "core" AGI agent architecture without considering the whole context of a quickly evolving "open agency" of various tools and specialised components[3].
From these ideas, I derive the following conjectures about an "AGI-complete" architecture[4]:
1. AGI could be achieved by combining just
(a) about five core types of DNN blocks (Transformer and Selective SSM are two of these, and most likely some kind of Graph Neural Network with or without flexible/dynamic/"liquid" connections is another one, and perhaps a few more)[5];
(b) a few dozen classical algorithms for LMAs aka "LLM programs" (better called "NN programs" in the more general case), from search and algorithms on graphs to dynamic programming, to orchestrate and direct the inference of the DNNs; and
(c) about a dozen or two key LLM tools required for generality, such as a multi-physics simulation engine like JuliaSim, a symbolic computation engine like Wolfram Engine, a theorem prover like Lean, etc.
2. The AGI architecture described above will not be perfectly optimal, but it will probably be within an order of magnitude from the optimal compute efficiency on the tasks it is supposed to solve[4], so, considering the investments in interpretability, monitoring, anomaly detection, red teaming, and other strands of R&D about the incumbent types of DNN blocks and NN program/agent algorithms, as well as economic incentives of modularisation and component re-use (cf. "BCIs and the ecosystem of modular minds"), this will probably be a sufficient motivation to "lock in" the choices of the core types of DNN blocks that were used in the initial versions of AGI.
3. In particular, the Transformer block is very likely here to stay until and beyond the first AGI architecture because of the enormous investment in it in terms of computing optimisation, specialisation to different tasks, R&D know-how, and interpretability, and also, as I already noted above, because Transformer maximally optimises for episodic cognitive capacity and from the perspective of the architecture theory, it's valuable to have a DNN building block that occupies an extreme position on some tradeoff spectrum. (Here, I pretty much repeat the idea of Nathan Labenz, who said in his podcast that we are entering the "Transformer+" era rather than a "post-Transfromer" era.)
Implications for AI Safety R&D
The three conjectures that I've posited above sharply contradict another view (which seems to me broadly held by a lot of people in the AI safety community) in which a complete overhaul of the AI architecture landscape is expected when some new shiny block architecture that beats all the incumbents will be invented[6].
It's hard for me to state the implications of taking one side in this crux in the abstract, but on a more concrete example, I think this position informs my inference that working on an architecture that combines Transformer and Selective SSM blocks and training techniques to engineer an inductive bias for greater "self-other overlap" is an R&D agenda with a relatively high expected impact. Compare with this inference by Marc Carauleanu (note: I don't state that he necessarily expects a complete AI architecture overhaul at some point, but it seems that somebody who thought that would agree with him that working on combining Transformer and Selective SSM blocks for safety is of low expected impact because the AGI that might make a sharp left turn will contain neither Transformer nor Selective SSM blocks).
System-level explanation and control frameworks, mechanism design
Both Drexler's Open Agency Model and Conjecture's CoEms are modular and heterogeneous as I predict the AGI architecture will be anyway, but I remarked in the comments to both that component-level alignment and interpretability is not enough to claim that the system as a whole is aligned and interpretable (1, 2).
My conjectures above call for more work on scientific frameworks to explain the behaviour of intelligent systems made of heterogeneous components (NNs or otherwise), and engineering frameworks for steering and monitoring such systems.
On the scientific side, see Free Energy Principle/Active Inference in all of its guises, Infra-Bayesianism, Vanchurin’s theory of machine learning (2021), James Crutchfield's "thermodynamic ML" (or, more generally, Bahri et al.’s review of statistical mechanics of deep learning (2022)), Chris Fields' quantum information theory, singular learning theory. (If you know more general frameworks like these, please post in the comments!)
On the engineering (but also research) side, see Doyle's system-level synthesis, DeepMind's causal incentives working group, the Gaia Network agenda, and compositional game theory. (If you know more agendas in this vein, please post in the comments!)
Implications for AI policy and governance
The view that AGI will emerge from a rapidly evolving ecosystem of heterogeneous building blocks and specialised components makes me think that "intelligence containment", especially through compute governance, will be very short-lived.
Then, if we assume that the "G factor" containment is probably futile, AI policy and governance folks should perhaps start paying more attention to the governance of competence through the control of the access to the training data. This is what I proposed in "Open Agency model can solve the AI regulation dilemma".
In the Gaia Network proposal, this governance is supposed to happen at the arrow from "Gaia Network" to "Decision Engines" that is labelled "Data and models (for simulations and training)" (note that "Decision Engines" are exactly the "AGI-complete" parts of this architecture, not the Gaia agents):
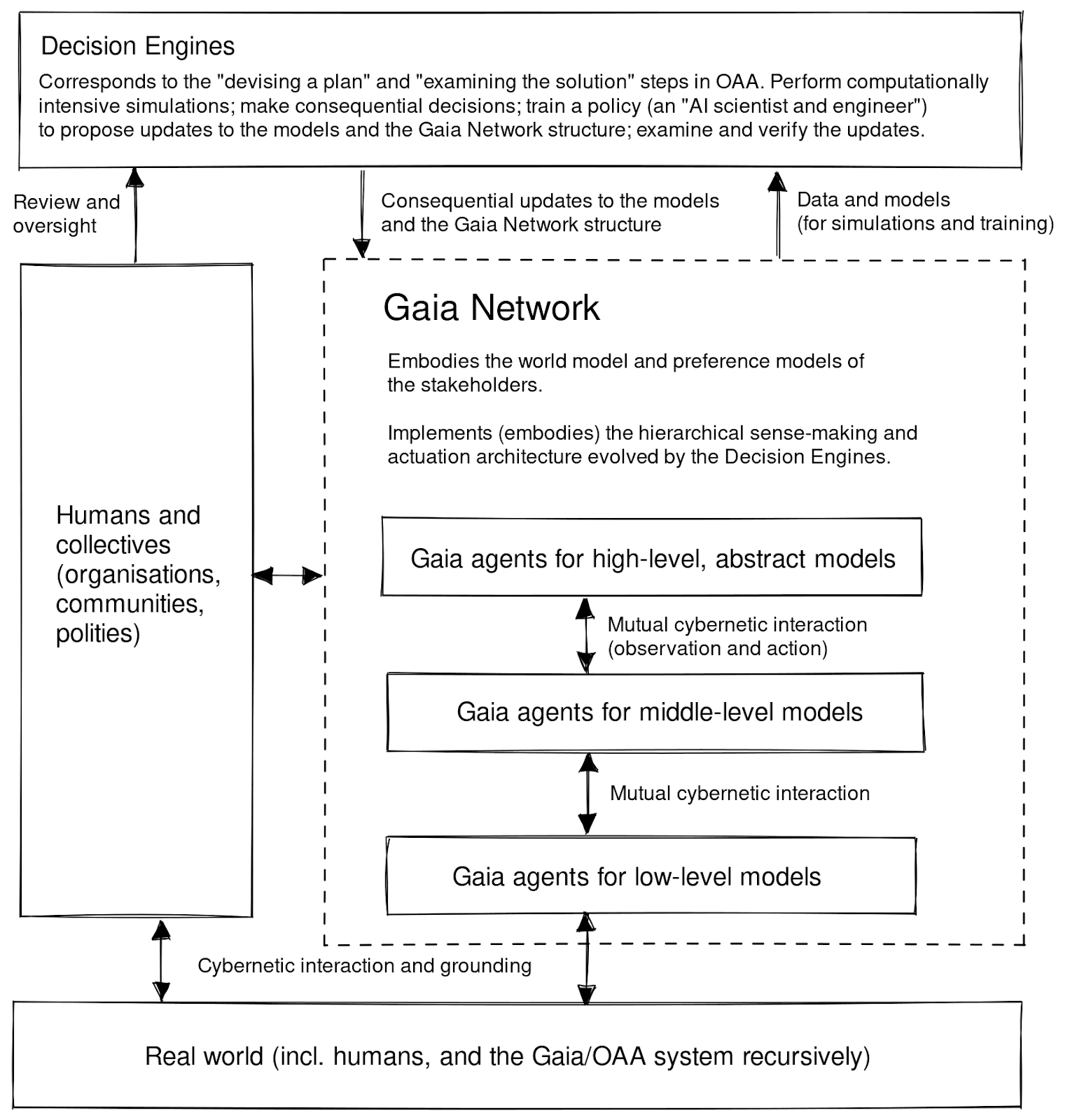
However, we didn't think about a concrete governance mechanism for this yet, and welcome collaborators to discuss it.
- ^
The tradeoff between episodic cognitive capacity and memorisation is fundamental for information-processing systems, as discussed by Fields and Levin: "The free-energy costs of irreversibility induce coarse-graining and attention-switching".
- ^
I've proposed one way to combine Transformer and Selective SSM in SociaLLM.
- ^
Anatoly also connects this trend towards AI component and tool diversification with the "Quality Diversity" agenda that looks at this component and architecture diversity as intrinsically advantageous even for capabilities.
- ^
"AGI" is taken here from OpenAI's charter: "highly autonomous systems that outperform humans at most economically valuable work". This is an important qualification: if we were to create an AI that should outperform all biological intelligence in all of its tasks in diverse problem spaces (such as protein folding, genetic expression, organismic morphology, immunity, etc.), much more component diversity would be needed that I conjecture below.
- ^
Here, it's important to distinguish the block architecture from the training objective. Transformers are not obliged to be trained solely as auto-regressive next token predictors; they can also be the working horses of GFlowNets that have different training objectives.
- ^
Additionally, it's sometimes assumed that this invention and the AI landscape overhaul will happen during the recursive self-improvement a.k.a. the autonomous takeoff phase.