This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This is a linkpost for Request for Proposals: Research and Applied Work on Digital Minds.
I'm glad to announce a request for proposals for research and applied work on digital minds at Longview Ph...
Even the most advanced contemporary machine learning systems are vulnerable to adversarial attack. The safety community has often assumed adversarial robustness to be a problem that will be solved naturally as machine learning (ML) systems grow more capable and general. However, recentwork has shown that superhuman systems in a narrow domain such as AlphaZero are highly vulnerable to adversarial attack, as are general but less capable systems like large language models. This raises the possibility that adversarial (worst-case) robustness will continue to lag behind average-case capabilities. In other words, transformative AI systems are likely to be exploitable.
Exploitability will cause a wide variety of current alignment proposals to fail. Most extant agendas seek to align the main ML system with the assistance of helper ML systems. The main ML system is the primary system that takes actions in the world (e.g. interacting with users), with the helper ML systems acting as scaffolding to train and/or verify the main ML system. These alignment schemes will fail if the helpers are exploited by the main system – and we expect helpers to be vulnerable to exploitation (see Contemporary ML systems are exploitable by default).
In Table 1 we present a subjective risk matrix for a range of popular alignment agendas, evaluating the degree to which main ML systems have the ability and incentive to exploit the helper. We find many alignment agendas have a high risk of exploitation, with all having at least some risk.
Alignment Agenda
Main System’s Ability to Exploit Helper
Main System’s Incentive to Exploit Helper
Risk of Exploit
RL on learned reward model (e.g. RLHF, IRL)
Medium
High
High
Scalable oversight (e.g. recursive reward modeling, AI safety via debate)
Table 1: Subjective risk matrix for popular alignment agendas (see next section), using a helper ML system to assist with aligning the main ML system that will eventually be deployed.
We are most concerned by vulnerabilities in the helpers as this can impact the alignment of the main system. By contrast, an aligned but adversarially exploitable main system would not necessarily pose a danger, especially if the main system can recursively self-improve to fix itself. However, there is a possibility that even superintelligent systems cannot attain adversarial robustness. This would be a volatile situation, which could conceivably collapse into chaos (systems frequently exploiting each other), an implicit equilibrium (e.g. mutually assured destruction), or an explicit agreement (e.g. all AI systems self-modify to commit to not exploiting one another).
We see two possible approaches to fixing this: improving adversarial robustness, or developing fault tolerant alignment methods that can work even in the presence of vulnerable ML systems. We are most excited by fault tolerant alignment, as it is highly neglected and plausibly tractable, although further work is needed to solidify this approach. By contrast, adversarial robustness is an area that has received significant attention from the ML research community (low neglectedness)[1]but with only modest progress (low to medium tractability).
In the remainder of this document, we will argue that systems are exploitable by default, explore the implications this has for alignment agendas in several different scenarios, and outline several research directions we are excited by.
Alignment agendas need robustness
Most alignment schemes implicitly depend on some aligned helper ML systems that can assist us in training or validating a main ML system, like a proto-AGI. In this section we assume the helper is exploitable, and explore the problems this causes for these alignment schemes. We justify this assumption this assumption in the next section.
A helper is more likely to be exploited if the main system is incentivized to exploit it, such as by the helper directly providing a training signal the main system is being optimized for, or if the main system has gained situational awareness. Conversely, it is less likely to happen if the optimization process is pursuing a goal that is largely independent from the helper’s output, such as if the helper is an interpretability tool checking for the presence of mesa-optimization. In the best case, we might even be able to (as in the case of IDA) control the optimization pressure to explicitly avoid inputs that might be adversarial.
The likelihood of an exploit also depends on the ability of the main system. This includes the computational resources available to develop an exploit, which could range from just forward-passes of the main system’s network to the main system having access to a large compute cluster. It also depends on how much information the main system has about the helper, which could range from merely a high-level knowledge of possible evaluation techniques (black box), through to query access to the helper (gray box), through to full access to its weights and source code (white box). We can’t rely on security by obscurity: many zero-shot black-box adversarial attacks have been conducted by human researchers, and superintelligent ML systems might be even more creative. Still, even superintelligent ML systems are not omnipotent, and in practice the “adversary” might be a relatively stupid optimization process like SGD.
Referring back to Table 1, one class of alignment agendas that is particularly sensitive to lack of robustness is those where the helper is an overseer providing feedback to the main system, such as in RLHF and most scalable oversight proposals. In this case, exploiting the helper is part of the training objective of the main system, explaining the ubiquity of rewardhacking.
Corrective feedback from a human overseer can help mitigate reward hacking when the reward model is trained online, but there remains a significant risk that the main system hacks the helper more rapidly than a human is able to provide corrective feedback. Alternatively, the main system may simply learn to trick the human. Scalable oversight methods are designed to guard against tricking the human, but cannot protect against scenarios that are adversarial to both the human and scalable oversight model.
Imitation learning methods seem less risky, as the optimization pressure is simply to match the empirical distribution of a demonstration dataset. The closest to “reward hacking” in this setting would be overfitting to the dataset, a relatively benign failure mode. There is still some risk of inner optimization objectives arising, which could then be adversarial to other systems (e.g. attempt to hide themselves from transparency tools), but comparatively speaking this is one of the methods with the lowest risk of adversarial failure. Unfortunately, it also maxes out at around human performance.
Imitative Iterated Distillation and Amplification (IDA) is less sensitive to exploitability. IDA is a proposal to take an imitation learned model and amplify it beyond human-level performance. Casting it in our framework, the helper is a base imitation-learned model that we presume is safe and aligned. The main system is the model produced by IDA on the helper. At the first step, the helper is amplified by giving it the ability to ask questions to copies of itself. Critically, the helper has an incentive to avoid asking questions that are likely to cause it to fail. In this sense, IDA channels the optimization pressure away from adversarial exploitation, unlike e.g. vanilla RL.
The flipside is that the helper also likely has a high ability to exploit itself owing to this introspective knowledge of its own vulnerabilities. [2] This could result in some instability in the training scheme: if at any point a sub-part of the question tree is adversarial, the response could propagate to “infect” the rest of the question tree. This is related to the problem of security amplification.
One of the less concerning cases is for tools used only to evaluate, and not train a model, as is often the case for adversarial testing or transparency. Here, the main system has no direct incentive to fool the helper as it does not provide a training signal. However, in practical applications some optimization pressure against the helper will still leak in, for example if the helper is used to decide whether to abort a training run or change its hyperparameters. This would result in problems similar to those observed today with researchers overfitting to the test set.
Even if we only used these helper methods as a one-off final check on the main system, the main system might still be incentivised to fool these evaluation methods if it has situational awareness and long-term objectives. However, it will be a challenging exploit to pull off, as the main system may have only partial knowledge of the design of the helper (e.g. what tests the helper will perform) and cannot engage in direct trial-and-error exploitation of it. Additionally, transparency tools are typically applied to the weights of the main system, which the main system can at best only indirectly control (by gradient hacking). [3] Unfortunately, evaluation methods are not themselves solutions to alignment, but can provide an additional safeguard to avoid deployment of malign systems.
Contemporary ML systems are exploitable by default
Our best guess is that all contemporary ML systems solving non-trivial tasks are exploitable by a moderately resourced adversary. ℓp-norm adversarial examples in image classifiers were first described by Szegedy et al. in 2013, and nearly a decade later state-of-the-art image classifiers remain vulnerable despite intense research interest in adversarial defenses. These vulnerabilities can be exploited in real-world settings by physical adversarial attacks, and there are even naturally occurring images that are challenging for a wide variety of models. Moreover, analogous issues have been found in a diverse range of ML systems including languagemodels, graph analysis, robotic policies and superhuman Go programs.
To the best of our knowledge, no ML system solving a non-trivial problem has ever withstood a well-resourced attack.[4] Adversarial defenses can be divided into those that are broken, and those that have not yet attracted concerted effort to break them. This should not be too surprising: the same could be said of most software systems in general.
One difference is that software security has notably improved over time. Although there almost certainly exist remote root exploits in most major operating systems, finding one is decidedly non-trivial, and is largely out of reach of most attackers. By contrast, exploiting ML systems is often alarmingly easy.
This is not to say we haven’t made progress. There has been an immense amount of work defending against ℓp-norm adversarial examples, and this has made attacks harder: requiring more sophisticated methods, or a larger ℓp-norm perturbation. For example, a state-of-the-art (SOTA) method DensePure achieves 77.8% certified accuracy on ImageNet for perturbations up to 0.5/255 ℓ2-norm. However, this accuracy is still far behind the SOTA for clean images, which currently stands at 91.0% top-1 accuracy with CoCa. Moreover, the certified accuracy of DensePure drops to 54.6% at a 1.5/255 ℓ2-norm perturbation – which is visually imperceptible to humans. This is well below the 62% achieved by AlexNet back in 2012.
There is substantial evidence for a trade-off between accuracy and robustness. Tsipras et al (2019) demonstrate this trade-off theoretically in a simplified setting. Moreover, there is ample empirical evidence for this. For example, DensePure was SOTA in 2022 for certified accuracy on adversarial inputs but achieved only 84% accuracy on clean images. By contrast, non-robust models achieved this accuracy 4 years earlier such as AmoebaNetA in 2018. There appears to therefore be a significant “robustness tax” to pay, analogous to the alignment tax.[5]
In addition to certified methods such as DensePure, there are also a variety of defense methods that provide empirical protection against adversarial attack but without provable guarantees. However, the protection they provide is partial at best. For example, a SOTA method DiffPure achieves 74% accuracy on clean images in ImageNet but only 43% accuracy under a 4/255 ℓ∞-norm perturbation. There is also a significant robustness tax here: Table 5 from the DiffPure paper shows that accuracy on clean images drops from 99.43% on CelebA-HQ to 94% with the diffusion defense.
Although the ubiquitous presence of adversarial examples in contemporary ML systems is concerning, there is one glimmer of hope. Perhaps these adversarial examples are merely an artifact of the ML systems being insufficiently capable? Once the system reaches or surpasses human-level performance, we might hope it would have learned a set of representations at least as good as that of a human, and be no more vulnerable to adversarial attack than we are.
Unfortunately, recent work casts doubt on this. In Wang et al (2022), we find adversarial policies that beat KataGo, a superhuman Go program. We trained our adversarial policy with less than 14% of the compute that KataGo was trained with, but wins against a superhuman version of KataGo 97% of the time. This is not specific to KataGo: our exploit transfers to ELF OpenGo and Leela Zero, and in concurrent work from DeepMind Timbers et al (2022) were able to exploit an in-house replica of AlphaZero.
Of course, results in Go may not generalize to other settings, but we chose to study Go because we expected the systems to be unusually hard to exploit. In particular, since Go is a zero-sum game, being robust to adversaries is the key design objective, rather than merely one desiderata amongst many. Additionally, KataGo and AlphaZero use Monte-Carlo Tree Search coupled with a neural network evaluation. In general, we would expect search (which is provably optimal in the limit) to be harder to exploit than neural networks alone, and although search does make the system harder to exploit we are able to attack it even up to 10 million visits – far in excess of the threshold needed for superhuman performance, and well above the level used in most games.
There remains a possibility that although narrowly superhuman systems are vulnerable, more general systems might be robust. Large language models are the most general systems we have today, yet work by Ziegler et al (2022) find they are still exploitable even after significant adversarial training. Moreover, the existence of apparently fundamental tradeoffs between accuracy and robustness suggests that the most capable AI systems at any given time may be particularly likely to be vulnerable (Tsipras et al, 2019; Tramer et al, 2019).
Of course, at some point systems might be developed that are adversarially robust. This could be by “overshooting” on capability and generality, and then paying a robustness tax to get a suitably capable or general but robust system. Alternatively, new techniques might be developed that reduce or eliminate the robustness tax. Most optimistically, it is possible that general, human-level systems are naturally robust even though generality or human-level performance on their own are insufficient. In the next section, we will consider different possibilities for when and if adversarially robust systems are developed, and the implications this has for safety.
Future trajectories for robustness
We will consider three possible cases:
We solve adversarial robustness beforetransformative AI is developed;
We solve it after transformative AI is developed;
It is never solved.
Although coarse-grained, we believe this case split captures the most important distinctions.
For the purpose of this section, we will consider adversarial robustness to be solved if systems cannot be practically exploited to cause catastrophic outcomes. This is intended to be a low bar. In particular, this definition tolerates bounded errors. For example, we would tolerate threat actors being able to permanently trick AI systems into giving them 10% more resources in a trade. We’d also tolerate threat actors being able to temporarily divert even the majority of the AI’s resources, so long as this did not lead to permanent negative effects and that attackers eventually run out of such exploits.
We summarize our subjective credence in each of the cases below, and explore the cases qualitatively in the following sections.
Before you read further, consider estimating your credence for the following question, corresponding to Case 1:
Case 1: Adversarial robustness is solved before transformative AI is developed
Likelihood
There are two main sources of hope for this outcome. First, there is always a chance of an algorithmic insight that significantly improves robustness. Although we would expect the low-hanging fruit here to have already been plucked, insights are hard to predict, so we should not rule out the possibility of a breakthrough in the near-term. Second, there is the possibility of continued gradual progress in adversarial robustness in tandem with capabilities.
We’ve argued above that capabilities do not guarantee robustness and observed trade offs between capability and robustness. However, capabilities often do improve robustness. For example, pre-training improves the adversarial robustness of image classifiers.
One of the main reasons current ML systems are vulnerable is due to their incompetence. Even a superhuman system like KataGo is known to struggle to evaluate positions that require careful counting. It is perhaps less remarkable then that machine learning systems are vulnerable, and more remarkable that despite their often glaring flaws they are able to beat humans at many competitive games and achieve human-level accuracy at a variety of tasks.
In other words, perhaps the takeaway from the ubiquity of adversarial robustness should be that contemporary ML systems are only providing a facsimile of intelligence. In this view, transformative AI is likely still many decades out. Once transformative AI is developed and the systems are truly intelligent, many of these problems will naturally go away.
This seems plausible to us prima facie, but we’re deeply uncertain. Perhaps humans too have adversarial examples, they are just harder to find due to the expense of human experiments, and the (current) black-box nature of the human brain. We expect those with longer timelines to transformative AI to be more convinced by this argument. For those with short timelines, it seems unlikely that we will solve adversarial robustness in the next decade given the limited progress of the past decade.
Implications
In many ways, this is the best case scenario. In the rosiest outlook, we could solve adversarial robustness in the next few years by some flash of insight, well before transformative AI is developed. We should all do what we can to bring this about, although we are not currently aware of many neglected and tractable research directions that could achieve this.
The situation is more challenging if adversarial robustness is solved only gradually, or just before transformative AI. In that situation we are likely to encounter many of the problems discussed in the following section. However, the problems will mostly occur in settings where human feedback is still reliable, and scalable oversight is not required. This gives us a chance of detecting exploitation by manual inspection. However, this could still be challenging if the attack is subtle, or conducted rarely: e.g. it could be easy to overlook the main system obfuscating a single circuit in a large network. For that reason, it would still be beneficial to hasten the arrival of adversarial robustness, but it may not be essential for success.
Case 2: Adversarial robustness is solved after transformative AI is developed
Likelihood
The adversarial machine learning research community has spent almost a decade attempting to solve adversarial robustness, with limited progress. And we’ve seen that even adversarially trained superhuman systems (KataGo) and general but sub-human systems (language models) are exploitable. It’s not impossible the problem will be solved by default: perhaps narrowly superhuman systems with a bit more generality will start to naturally learn more robust and human-like representations. But absent new algorithmic insights into robustness, this problem seems likely to persist even into transformative AI systems.
However, a decade of research effort by the current ML research community is still small compared to the amount of resources that are likely to be brought to bear on the problem once transformative AI is developed. First, the economic incentive to resolve the issue will strengthen as profitable (but vulnerable) AI systems are deployed. Second, more advanced AI systems may partially automate ML research and development (R&D) leading to lower R&D costs for adversarial robustness. Consequently, the development of transformative AI might itself precipitate a solution to adversarial robustness.
Economic and political incentives. For the most part people are not currently losing large sums of money due to AI vulnerabilities. However, after transformative AI is developed, a large fraction of world GDP will depend on (vulnerable) AI systems. At this point, improving adversarial robustness could easily attract resources comparable to that of all information security spending today, or even rivaling that of a nation's defense budgets. This would be orders of magnitude more funding than is currently directed towards adversarial ML research.
Lower R&D costs. One of the more likely paths to transformative AI involves systems that are able to automate parts of science research and development (R&D). This is likely to lower the cost of AI research, enabling more (and potentially higher quality) adversarial robustness research.
Offense-Defense Balance. Developing transformative AI will certainly help improve adversarial robustness: but it will also lead to advances in attackers capabilities. Attackers will have a greater economic incentive to exploit widely deployed AI systems, and be able to leverage automated R&D systems to improve their attacks. However, it is possible that transformative AI will lead to a phase shift that favors defenders. In particular, defenders are more likely to prevail if there exist technical solutions to adversarial robustness that, while hard to find, once discovered are extremely difficult or impossible to exploit.
The history of cryptography followed a similar path: initial methods were consistently broken, but the latest methods have withstood concerted cryptanalysis for decades. Early ciphers date back thousands of years, but mathematical methods only began to proliferate in the 20th century. For many decades, there were no ciphers that could withstand significant cryptanalysis. In World War II, both the Allies and Germany were able to crack many of each other’s ciphers. More modern cryptography evolved soon after that, but early attempts continued to be dogged with issues. The Data Encryption Standard (DES) introduced in 1975 was broken in 1999, largely due to its small key size. The Advanced Encryption Standard (AES) adopted in 2001 has been widely scrutinized since then and is still currently believed to be practically secure. So although for many decades cryptographers and cryptanalysts were evenly matched, eventually cryptographic advances swung the offense-defense balance in favor of the defenders.
Implications
The good news in this scenario is that sufficiently advanced AI systems will not be exploitable. The bad news is that the precursors of transformative AI systems will still be vulnerable. This poses two problems. First, we must protect proto-transformative AI systems during their vulnerable period, analogous to their “childhood”. Second, we must protect helper AI systems we use to help align transformative AI systems from being exploited by the transformative AI system itself.
Protecting proto-transformative AI systems from outside bad actors seems challenging but solvable. An extreme option is to simply train the AI system on an airgapped network, although this might pose some practical challenges if the AI system required interaction with the broader world to learn. Less extreme options involve training the AI system in a sandbox with a restricted list of users.
The second issue of helper AI systems we use for alignment being exploitable is thornier, and consequently is the central focus of this agenda. Here the threat is internal, not external. Airgapping won’t work, because the helper AI systems need to be able to interact with the transformative AI in order to inspect it and shape its training process. However, restricting information flow (especially what the transformative AI knows about the helpers) could help.
Let’s consider one example in depth, where the helper is an overseer that is providing a training signal to the main system. The overseer stands in for a human judge. In the simplest case, it might be a reward model trained on human feedback, able to judge situations more quickly and cheaply than a human. In more complex cases, it might be trained by any of a range of scalable oversight methods (e.g. recursive reward modeling or AI safety via debate).
Suppose we are training the system that will be the first transformative AI system built. Initially, neither the main system nor overseer will be transformative AI systems, and so by assumption of this case both will be vulnerable. Critically, since the main system is trained to optimize the overseer’s output, there is an inherently adversarial relationship between the two.
Even though the main system may be initially unsophisticated, the evidence from contemporary ML suggests it will have no issue exploiting the overseer. Many algorithms to generate adversarial examples are very simple: much simpler than the networks they exploit.[6]In our attack against KataGo, a randomly initialized adversary wins decisively after as little as 0.3% (against unhardened KataGo) and 6% (against hardened KataGo) as much training time as the victim agent.
One major advantage an overseer has is that it is typically trained online. If the main system starts to exploit it, the overseer has a chance to correct itself. This seems relatively easy so long as humans are not fooled by the exploit, and can provide corrective feedback in time. However, the overseer may still be vulnerable. For example, work on reward modeling in language models often involves online or iterated offline training, yet these reward models will still assign erroneously high output to gibberish text, [7] necessitating KL regularization during training.
Moreover, humans are hardly infallible: we have already seen examples of training processes learning to fool humans such as by appearing to but not actually grasping an object. Indeed, the limited nature of human feedback is the primary motivator for scalable oversight approaches. If the human trainer can be exploited by the main system then we must rely on the oversight process itself being able to detect and defend against the attack.
Notably, there is an analogy between AlphaZero-style training and iterative distillation and amplification. AlphaZero uses Monte-Carlo Tree Search (MCTS) as a policy improvement operator that amplifies a network via search. AlphaZero-style training then distills the amplified network back into the original network.
We might hope that the MCTS “amplification” step would make the network more robust. Empirically, the results are mixed. In our attack against KataGo, our first “pass-based adversary” that achieves a 99% win rate against KataGo without search is defeated even by searching only 32 nodes. However, our latest “cyclic adversary” is able to win 76% of games against KataGo searching 10 million nodes. By contrast, KataGo searching 2048 nodes is already strongly superhuman. MCTS helped KataGo but ultimately did not save it from adversarial attack.
Although search does improve robustness, when the underlying network has a sufficiently deeply rooted vulnerability it can be insufficient to protect against it at all practically achievable levels of search. Of course, amplification methods might be more sophisticated than MCTS. However, they will also need to operate in more complex environments with much larger branching factors and longer time horizons than in Go.
While an exploitable overseer is the most natural and concerning setting, versions of this problem also arise for other kinds of helper agents. For example, perhaps you are more concerned about inner than outer alignment, and are envisaging a helper agent conducting adversarial testing or mechanistic interpretability to detect inner misalignment in some main system system. Here, the main system system would have an incentive to fool the helper agent into falsely declaring the main system as inner aligned.
The risks vary depending on how the helper is being used. If deployed simply as a check at the end of training, then the incentive for the main system is indirect, as it is not receiving a training signal for it. However, if the mesa-optimizer has situational awareness then it would likely strongly suspect it will be subject to some degree of automated checks by other AI systems. Even if the exact nature of these checks is unknown, this may not prevent it from finding exploits as adversarial examples transferfairlywell. For example, our attack against KataGo transferred moderately well zero-shot: we achieve around a 3% win rate against Leela Zero and ELF OpenGo, which while low is better than human professionals.
In practice, labs will be reluctant to abandon what is likely an extremely expensive AI system just because it fails a single check. Instead, they are likely to want to tweak its training process, and try again. The risk in this iterated case is significantly higher as the main system now has multiple shots at finding an adversarial example. For example, a Go player on our team was able to adapt the adversarial strategy after just a few games of trial and error to frequently win against Leela Zero. AI systems may adapt in an analogous way.
The risk is highest when the main system receives a training signal incentivizing it to fool the helper agent. For example, the flip side of adversarial testing is adversarial training: pitting a main system against a helper that generates adversarial examples. Papernot et al, 2017 (Table 4) found that adversarial training against examples with small perturbations produced networks that exhibit gradient masking. They’re robust in a tiny region around inputs, defeating typical adversarial attack methods, but are still highly vulnerable to adversarial examples transferred from another model. In other words, adversarial training can result in a main system that looks good to the helper, but is not any more aligned (in this case, no more robust).
Similarly, one might wish to use mechanistic interpretability as part of human-in-the-loop training to produce models that learn human-like representations. A potential failure mode here is the model actually learning representations that appear human-like to the interpretability method, but with the model’s actual output being largely determined by some undetected steganographic encoding.
Despite these risks, there is some reason for optimism for helper agents such as interpretability methods that work by inspecting the main system’s weights. Even if the main system has an incentive to trick the helper, it at least has no direct control over its weights. However, the main system can often influence its weights indirectly (see gradient hacking) so long as it has some control over the data distribution it is trained on (common in reinforcement learning, for example). Moreover, when the helper provides a training signal, the optimization process producing the main system will “try” to exploit the main system even if the main system agent itself does not. Investigating the feasibility of attacks against helpers such as interpretability tools could be an interesting direction for future work.
Case 3: Adversarial robustness is never solved
Likelihood
In this scenario, arbitrarily capable systems will remain vulnerable to attack. This seems prima facie plausible since improvements in machine learning tend to improve both defense and attack methods. So, although it would be surprising if the ML systems of 2040 were vulnerable to 2020-era attacks, it seems very plausible that they might be vulnerable to new, more sophisticated attacks developed in the interim. A fixed offense-defense balance seems like a natural outside view.
Additionally, it is clear that human-level intelligence is not sufficient to be robust. Humans are themselves vulnerable to at times extreme manipulation by other humans. For example, some cult members have lost their possessions, liberty and sometimes even their lives. This is despite humans evolving in a partially adversarial environment, and so being well attuned to detecting social manipulation.
However, we can make systems perfectly robust in sufficiently narrow situations. For example, the minimax algorithm is provably optimal, it is just too computationally expensive to be used in most games. Still, it really is possible to make an unexploitable tic-tac-toe agent, and although challenging we would not be surprised if the ML community could make an agent that has bounded exploitability even in challenging games like poker.
Achieving bounded exploitability in more open-ended settings seems more challenging. However, it may be sufficient to detect exploitation and learn to defend against it online. Although not a panacea (a system learning online gives the attacker influence over the system’s training data, potentially opening it up to a data poisoning attack), this does seem like an easier problem, and is a threat model that has been relatively under-explored.
Implications
This case seems the most challenging for safety. All the challenges discussed in case 2 still apply and, in particular, the main system is likely to exploit helper agents we use to help align it. However, for the sake of exploring a different threat model, suppose that we have, somehow, produced an aligned AI system that is highly capable and genuinely has our best interests at heart. Unfortunately, the AI system having good intentions is not sufficient if the AI system can be tricked into performing acts against our interests.
Concretely, a highly capable AI system is likely to be an attractive target for well-resourced human threat actors like nation states. These threat actors may have their own AI systems to help automate the attack. Alternatively, perhaps a misaligned AI system has already been deployed, and is now itself a threat actor.
Without the ability to achieve technical protection against attack, actors are likely to seek other ways of defending themselves. For example, mutually assured destruction (MAD) equilibria could emerge, similar to in information security today. Even relatively amateurish ransomware attacks can be extremely disruptive; capable nation states could likely launch much more sophisticated attacks. But if they were discovered to be responsible, targeted nation states could respond either with their own cyber warfare or other soft power, or even with conventional military force. We might then expect threat actors to limit themselves primarily to espionage, which is less noticeable and so less likely to trigger a response, or targeted attacks seeking a narrow goal like Stuxnet.
Unfortunately, MAD equilibria are unstable, running the risk of actual mutual destruction. This is particularly risky in information security where attribution is notoriously difficult and where the barrier to entry is low. By contrast, in nuclear policy there are a small and well-defined set of possible threat actors (other nation states armed with nuclear weapons) and attribution is usually possible by detecting the launch site of missiles.
Since most AI systems and their principals would stand to lose from a conflict, there is an incentive for AI systems to come to an agreement to prevent this possibility. This is analogous to arms control pacts. Conceivably, AI systems might be able to improve on this, by self-modifying to be provably incapable of attacking other AI systems that have signed up to this agreement, although verifying that they actually self-modified might be difficult. Work on cooperative AI agendas might help with this, but may not be necessary, as sufficiently capable AI systems might be able to perform their own research on cooperative AI.
An alternative possible equilibrium is for one AI system to gain a sufficiently decisive lead that it is able to defend itself against the extant, less capable, threat actors. Such a concentration of power would pose its own risks, but might be a preferable alternative to constant conflict between AI systems. If the risk of conflict could be foreseen, it is conceivable even that different actors with the capability of producing advanced AI systems might agree to band together, producing a single AI system which would nonetheless seek to balance the desires of the group that created it. Such an event would be unprecedented, but not uncontemplated: the Baruch Plan proposed giving the United Nations a permanent monopoly over nuclear technology, with the ability to impose sanctions even on members of the permanent security council.
The outlook looks bad if neither a MAD or unipolar equilibria are attained. Conflict in general tends to be highly destructive and negative-sum. However, it is possible that conflict between AI systems could be closer to zero-sum wealth transfers and so less destructive of value than conventional military action, which might lead to a lower-than-expected cost.
Future research directions
We see three directions that are promising:
Better understanding the problem, such as investigating how general adversarial failure modes are and finding scaling laws for robustness;
Developing algorithmic improvements for adversarial robustness such as new training procedures or data augmentation;
Developing fault tolerant alignment techniques that function even in the presence of the vulnerable ML systems.
Understanding the problem
Although adversarial robustness is a well-studied area, there has been comparatively little work focusing on the settings most relevant to alignment: highly capable, general systems under realistic threat models. Consequently, there is low-hanging fruit to better understanding the nature of the problem, both for primary research and collating the relevant results that do already exist in the literature.
One promising direction is to develop scaling laws for robustness. Scaling laws for metrics of capabilities are well-established in domains including language models, generative image and video modeling and zero-sum board games. Determining analogous scaling laws for adversarial robustness would be greatly informative.
If the slope of the robustness scaling law is shallower than that of capabilities, we would expect the gap between capabilities and robustness to widen over time – a concerning outcome. By contrast, if the slope of the robustness scaling law is comparable to that of capabilities, then the gap might stay constant over time – suggesting the offense-defense balance will remain fixed. Finally, if the slope of the robustness scaling law is steeper than that of capabilities, we might expect there to be substantial gains in the future that close the gap.
An exploration into scaling laws could make use of data already developed elsewhere. For example, there already exist timeseries of the state-of-the-art accuracy of image classifiers in ImageNet and other benchmarks. There also exist some parallel time series for robust accuracy, such as RobustBench. Comparing these would give an initial indication of whether progress in adversarial accuracy is lagging behind, keeping pace with, or outstripping progress in clean accuracy.
There has already been some investigation of how model robustness varies with model size and dataset size. For example, Xie et al (2020; Figure 7) find that increasing the depth of a ResNet increases robust accuracy while having limited effect on clean accuracy. Carmon et al (2022; Figures 13 & 14) find that increasing the size of a labeled or unlabeled dataset improves robust accuracy, with Figure 13(a) in particular showing that robust accuracy benefits from increases in unlabeled data more than clean accuracy. However, to the best of our knowledge there are no quantitative scaling laws for robustness yet.
Most existing work in adversarial robustness has focused on image classification, which is a poor proxy for transformative AI, and ℓp-norm perturbations, a limited threat model. Consequently, we are particularly excited by further work probing vulnerabilities of narrowly superhuman systems under realistic threat models. We expect such investigation to be particularly informative for AI safety.
In particular, we are interested in investigating adversarial policies in superhuman game-playing systems outside of Go. For example, do vulnerabilities exist in Leela Chess Zero, an AlphaZero replica for chess? This would provide strong evidence that adversarial policies are a widely occurring phenomenon (at least for AlphaZero-style systems). We would expect chess systems to be more challenging to exploit than Go programs, as even search with hard-coded heuristics is sufficient for superhuman performance in chess. We would also be interested in trying to find adversarial policies in a broader range of games such as the Polygames to see how exploitability varies with factors like game complexity.
It would also be interesting to investigate systems trained with different algorithms, to rule out the possibility that the vulnerability is an artifact of AlphaZero-style training (like self-play). For example, DeepNash is a more principled method than self-play that has learned to play Stratego at a human expert level. Beyond board games, AlphaStar achieved expert-level performance in StarCraft and was trained using a population-based algorithm. Unfortunately, there are currently no open-source replications of these results, making it practically challenging to study these agents.
We could also seek to better understand existing adversarial attacks. There’s already been substantial work developing theories for why adversarial attacks persist, such as Adversarial Examples Are Not Bugs, They Are Features and Adversarial Spheres. But there are some notable gaps. For example, there’s been comparatively little work applying mechanistic interpretability to adversarial attacks to understand how the model fails. This could be both informative for adversarial robustness, and a useful test-case for interpretability.
Algorithmic improvements for adversarial robustness
Understanding the nature of the problem is important, but at some point we must take action to fix it. The most direct way is to develop algorithms or training procedures that improve adversarial robustness. Existing work that falls into this category includes adversarial defenses (such as certified defenses and adversarial training), more principled training procedures (such as policy-space response oracles instead of self-play) as well as trial-and-error improvements, such as discovering that pre-training can improve robustness.
Prior work in this area has certainly improved the state of adversarial robustness, and we hope it continues. However, it is a relatively crowded area and with uncertain tractability, so we would suggest people be selective as to what projects they work on in this domain. Directions that seem underexplored include: adversarial robustness under realistic threat models, like unrestricted adversarial examples; adversarial robustness focused on systems that seem good proxies for transformative AI, such as large language models or superhuman game-playing systems; and adversarial training to achieve limited guarantees (such as avoiding catastrophic outcomes).
Fault tolerant alignment
An alternative to making systems more robust is to make our alignment approach more tolerant to vulnerabilities in ML systems. To make an analogy to computer security, improving adversarial robustness is like fixing security vulnerabilities in programs, whereas fault tolerant alignment is like limiting the damage a vulnerability can cause by limiting the privileges of programs. Of course, they are not mutually exclusive: even if we aggressively apply the principle of least privilege, we still need some core, trusted component. However, this simplifies the problem from securing a large complex system to ensuring the small, core components are trustworthy.
Concretely, we should strive to isolate the main AI system and its helpers as much as possible from one another. For example, if the helper isn’t needed to generate the training signal (e.g. interpretability or adversarial testing tools) then the main system should not be able to query the helpers. Any interactions between the main and helper systems should happen in a sandboxed environment with the results not used for training the main sysem.
We could also take a defense in depth approach by including a number of independent helpers of different kinds. Then we can tolerate some of the helpers being exploited, provided at least one is not exploited and so provides us with a warning sign of the danger we are in. This is still non-trivial: adversarial examples often transfer, and the main system could explicitly blend adversarial examples targeted at different models, so we cannot simply trust the outputs of an ensemble model. But the more independent the tests (e.g. using different methods, such as adversarial testing and mechanistic interpretability) the harder it will be for a malevolent AI system to fool them.
Only limited isolation is possible when the helper is needed to generate a training signal for the main system (e.g. IDA or RRM). In these cases, we should strive to avoid adversarial pressure in the first place. This strategy is particularly attractive in the world where we solve adversarial robustness after transformative AI. In that case, the adversarial pressure mostly comes from within our system, and so in principle we might be able to avoid it.
One of the primary issues we identified was an optimization process adversarially exploiting an overseer. Fortunately, imitation learning objectives seem markedly less vulnerable to such reward hacking behavior. The downside is that imitation learning also effectively caps performance at the level of demonstrations. [8] However, if we recover the human policy we can use it as a starting point and choose how much additional optimization pressure to exert. This is effectively how RLHF works, by performing RL with a KL penalty from the base (imitation learned) language model.
However, RL with a KL penalty is far from the only approach. For example, quantilizers propose sampling from an imitation learning objective N times and picking the best of N. Recent results by Gao et al (2022) show this scheme produces comparable performance to RL, and is more KL efficient (finding policies that are closer to the base model), although is unfortunately computationally infeasible for large N. A natural direction for future work would be to make this more computationally efficient: such as using supervised learning to distill the best-of-N search into a model. More generally, one could explore the design space of optimization schemes, to try and find ways to direct the optimization pressure more towards improving performance without exploiting the model.
We can also seek to change the game played between the main system and helper AI systems to advantage the helpers. For example, by default an overseer AI system provides a training signal in real-time to the main system. For this scheme to work, the overseer needs to be robust zero-shot: a challenging desiderata. However, we could modify this game to instead periodically reset the main system to an earlier checkpoint, then continue training the main system with the current overseer. Under this scheme, the overseer just needs to not be repeatedly fooled by the same attack. Moreover, we could use this scheme to detect potential exploits, by seeing if the main system trained on the later overseer diverges from that from the earlier overseer.
Limitations
Prior work is inconclusive
The ubiquity of adversarial examples in contemporary ML systems suggests that adversarial robustness is a thorny problem to solve. However, most work on adversarial examples has focused on settings very different to those we care about for alignment. Some of these differences make the problem harder to solve: unrestricted adversarial examples are a more realistic threat model, but much harder to defend against than the more extensively-studied ℓp-norm perturbations.
However, many differences make the problem easier. For example, it might be sufficient to have a guarantee the model will never make any catastrophic mistake, while tolerating adversarial examples in low-stakes situations. As a toy example, suppose a reward model for an autonomous vehicle assigns +1 reward to getting to the destination, +3 reward for repeatedly circling the block if it sees a sequence of adversarially placed stickers on road signs, and -10 reward for crashing. Although the resulting model certainly has an annoying flaw in the presence of attackers, the worst-case outcome is a temporary annoyance, not a loss of life. In more open-ended domains, corrigibility stands out as a high-stakes outcome, whereas most micro-level decisions made by the AI are comparatively low-stakes.
Perhaps the most important difference is that most prior work on adversarial examples has focused on AI systems as they are today, whereas for alignment we care primarily about more advanced future AI systems. There is a possibility that adversarial robustness will be solved by default as capabilities advance. This is an important limitation, but is already discussed in Case 3, so we will not reiterate this argument here.
Incompetent adversarial examples
A variant on the above argument is that systems are unlikely to pose a grave danger to humanity through mere incompetence, so we should be most alarmed by systems that are capable and striving to achieve misaligned goals. However, as mentioned previously, most adversarial examples seen so far feel more like incompetence: the system is just fundamentally misunderstanding something about the world. Perhaps we should be encouraged by this, as a sign that contemporary AI systems are far from causing a threat.
We agree with this basic intuition. All else being equal, the ubiquity of adversarial examples advocates in favor of longer timelines to transformative AI. However, as adversarial examples are over a decade old we would expect this information to largely already be incorporated into people’s estimates.
Moreover, we agree that we should not expect AI systems to cause catastrophic harm as a direct result of being adversarially exploited. Rather, our primary concern is that aligned helper ML systems will be exploited by a main AI system, resulting in the main AI system being misaligned. Our secondary concern is that even if the main AI system is aligned, if it is exploitable it may be unable to hold bad actors (such as other misaligned AIs) in check. In both cases, the risk comes not from the AI systems that are being exploited, but from misaligned highly capable AIs.
We already knew this
Many of the concrete problems outlined in this post, such as reward hacking or even exploiting interpretability tools, have already been extensively discussed. So, in some sense, this post is not saying anything new: if you were already familiar with these prior risks, there is little reason to be more alarmed by them after reading this post. Instead, we view our key contribution as providing a framework to collect together seemingly disparate safety problems under a common roof and with, potentially, a common solution.
We think the intransigence of many adversarial robustness problems should give people pause for thought when trying to solve one of the special cases. For example, we expect that a solution to reward hacking or even a robust injury classifier could be turned into a solution to many other adversarial robustness problems. Consequently, we should expect such problems to be extremely challenging to solve, as many researchers have tried but failed to solve adversarial robustness.
Won’t improving robustness also improve capabilities?
We believe the directions we’ve highlighted differentially advance safety with limited capabilities externalities. However, in practice one of the easiest ways of getting more robust models may be to just increase their general capabilities. We therefore advocate for the safety community having a nuanced message about adversarial robustness, emphasizing closing the gap between average-case and worst-case performance rather than simply seeking to increase worst-case performance. In particular, there seems to be a popular false equivalency between “alignment” and “train with human feedback”; it would be unfortunate if a similar false equivalency between “safety” and “adversarial robustness” emerged.
Conclusion
We have argued that even state-of-the-art contemporary ML systems are vulnerable to adversarial attack, and that it is likely that even (near-)transformative AI systems will be similarly vulnerable. We’ve explored the implications of this for alignment, finding that a number of popular alignment proposals may fail in this regime. Finally, we’ve outlined research agendas to better understand this problem and address it, both by improving robustness and by adapting alignment techniques to better tolerate adversarial vulnerabilities.
If you are interested in working on problems related to this agenda, FAR AI is hiring for research engineers and research scientists. We’d also be interested in exploring collaborations with researchers at other institutions: feel free to reach out to [email protected].
Acknowledgements
Thanks to Euan McLean for assistance editing this manuscript and to Tony Wang, Stephen Casper, Scott Emmons, Erik Jenner, Nikolaus Howe, Adriá Garriga-Alonso and Tom Tseng for feedback on earlier drafts.
Adversarial robustness has received comparatively little attention from the x-risk focused community, so there may still be some areas that are important for x-risk but neglected by the broader ML research community, such as unrestricted adversarial examples.
This doesn’t guarantee the helper can exploit itself: recognizing an exploit (so defending against it) could be easier than generation. However, the helper seems well-placed to exploit itself relative to other ML systems of comparable capabilities.
Although future ML systems could have more control over their weights. For example, hypernetworks directly generate the weights of another network. In a less extreme case, neural-architecture search with a training objective based on some automatic interpretability metric could exert selection pressure towards “deceptively interpretable” architectures.
The best adversarial defenses can largely prevent imperceptible attacks, but are still easily defeated by perceptible perturbations that would not confuse humans.
Some recent work (e.g. Cheng et al (2020) and Altinisik et al (2022)) has had some success increasing clean accuracy of adversarially trained models by adaptively perturbing the examples, thereby reducing the robustness tax for adversarial training.
Section III of Carlini & Wagner (2016) provide a good summary of methods, most of which are relatively simple optimization problems, although they do require access to gradients through the networks.


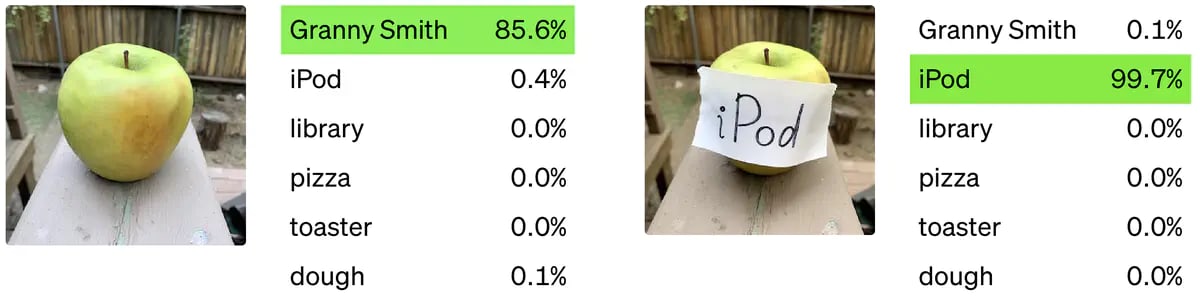 Figure 1: A
Figure 1: A