Prelude: when GPT first hears its own voice
Imagine humans in Plato’s cave, interacting with reality by watching the shadows on the wall. Now imagine a second cave, further away from the real world. GPT trained on text is in the second cave. [1] The only way it can learn about the real world is by listening to the conversations of the humans in the first cave, and predicting the next word.
Now imagine that more and more of the conversations GPT overhears in the first cave mention GPT. In fact, more and more of the conversations are actually written by GPT.
As GPT listens to the echoes of its own words, might it start to notice “wait, that’s me speaking”?
Given that GPT already learns to model a lot about humans and reality from listening to the conversations in the first cave, it seems reasonable to expect that it will also learn to model itself. This post unpacks how this might happen, by translating the Simulators frame into the language of predictive processing, and arguing that there is an emergent control loop between the generative world model inside of GPT and the external world.
Simulators as (predictive processing) generative models
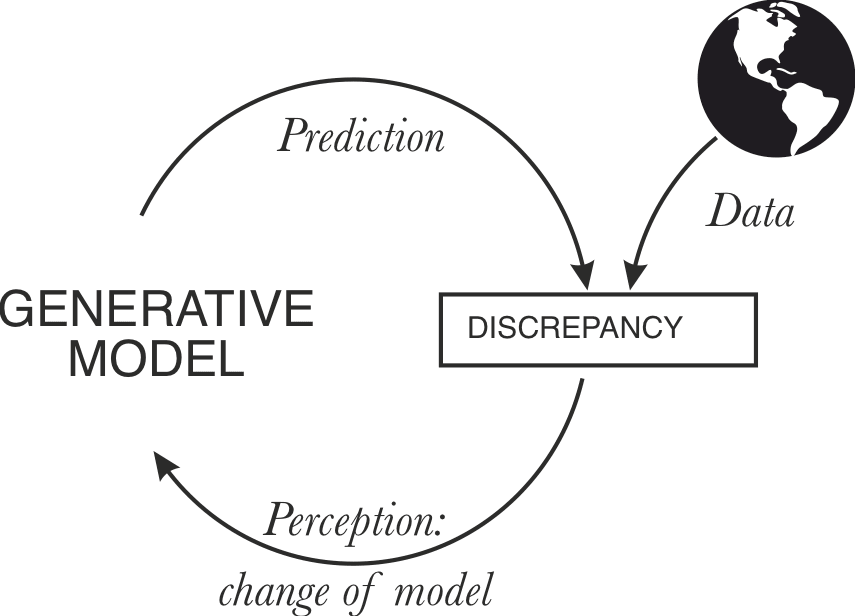
There’s a lot of overlap between the concept of simulators and the concept of generative world models in predictive processing. Actually, in my view, it's hard to find any deep conceptual difference - simulators broadly are generative models. This is also true about another isomorphic frame - predictive models as described by Evan Hubinger.
The predictive processing frame tends to add some understanding of how generative models can be learned by brains and what the results look like in the real world, and the usual central example is the brain. The simulators frame typically adds a connection to GPT-like models, and the usual central example is LLMs.
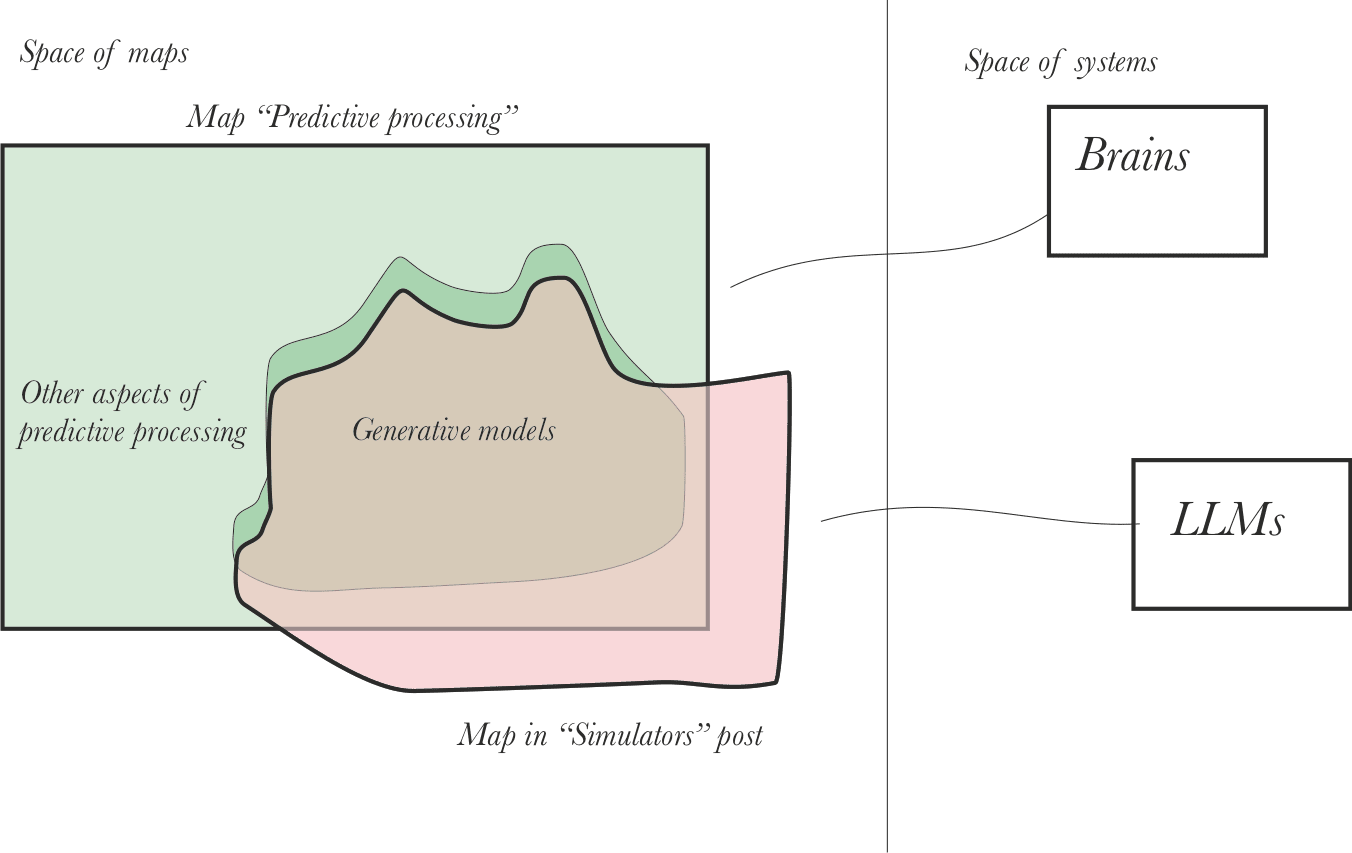
In terms of the space of maps and the space of systems, we have a situation like this:
The two maps are partially overlapping, even though they were originally created to understand different systems. They also have some non-overlapping parts.
What's in the overlap:
- Systems are equipped with a generative model that is able to simulate the system's sensory inputs.
- The generative model is updated using approximate Bayesian inference.
- Both frames give you similar phenomenological capabilities: for example, what CFAR’s "inner simulator" technique is doing is literally and explicitly conditioning your brain-based generative model on a given observation and generating rollouts.
Given the conceptual similarity but terminological differences, perhaps it's useful to create a translation table between the maps:
| Simulators terminology | Predictive processing terminology |
| Simulator | Generative model |
| Predictive loss on a self-supervised dataset | Minimization of predictive error |
| Self-supervised | Self-supervised, but often this is omitted |
| Incentive to reverse-engineer the (semantic) physics of the training distribution | Learns a robust world-model |
| Simulacrum |
|
| Next token in training data | Sensory input |
To show how these terminological differences play out in practice, I’m going to take the part of Simulators describing GPT’s properties, and unpack each of the properties in the kind of language that’s typically used in predictive processing papers. Often my gloss will be about human brains in particular, as the predictive processing literature is most centrally concerned with that example; but it’s worth reiterating that I think that both GPT and what parts of human brain do are examples of generative models, and I think that the things I say about the brain below can be directly applied to artificial generative models.
- “Self-supervised: Training samples are self-supervised”
- The system learns from sensory inputs in a self-supervised way.
- The core function of the brain is simply to minimise prediction error, where the prediction errors signal mismatches between predicted input and the input actually received.[2]
- “Converges to simulation objective: The system is incentivized to model the transition probabilities of its training distribution faithfully”
- Prediction error minimization can be achieved … : through immediate inference about the states of the world model and through updating a global world-model to make better predictions
- “Generates rollouts: The model naturally generates rollouts, i.e. serves as a time evolution operator”
- The system can use its internal model to sample potential action-outcome trajectories, essentially using it to perform tree search
- “Simulator / simulacra nonidentity: There is not a 1:1 correspondence between the simulator and the things that it simulates”
- The most important part of the human “environment” is other people, and what human minds are often doing is probably simulating other human minds (including simulating how other people would be simulating someone else!).
- “Stochastic: The model outputs probabilities, and so simulates stochastic dynamics when used to evolve rollouts”
- The model is a stochastic causal model (e.g. "We illustrate variational Bayesian inference in the context of an important and broad class of generative models. These are stochastic dynamic causal models that combine nonlinear stochastic differential equations governing the evolution of hidden-states and a nonlinear observer function."[3])
- “Evidential: The input is interpreted by the simulator as partial evidence that informs an uncertain prediction, rather than propagated according to mechanistic rules”
- Perception is an inferential process that combines (top-down) prior information about the most likely causes of sensations with (bottom-up) sensory stimuli. Inferential processes operate on probabilistic representations of states of the world and follow Bayes’ rule, which prescribes the (optimal) update in the light of sensory evidence.
Mentioning the similarities, it is also important to mention the differences between the Simulators and generative models in predictive processing frames:
- The Simulators frame assumes that the simulator does not act on the world. In contrast, predictive processing is part of the broader theory of active inference. Active inference assumes a symmetry between perceptions and actions. As well as minimising the mismatch between its generative model and sensory inputs by changing its model (via perception), an active inference agent can also minimise mismatch by acting in the world, which causes its sensory inputs to change.
- The predictive processing literature usually assumes that the learning-prediction-action loop is running continuously, and does not ontologically distinguish between "training" and "runtime". In other words, predictive processing basically assumes continuous learning. On the other hand, it does differentiate between learning at different temporal scales.[4]
- Active inference literature usually assumes that in humans, the active inference system is warped by having something called "fixed priors", with some beliefs acting as an analogue of "wants" - leading the system to prefer some states.
- There are also many superficial differences stemming from the fact that predictive processing originated as a theory of what human brains are doing. Most of the actual content of predictive processing literature is not about the high-level frame of "thinking about embodied stochastic Bayesian generative models", but about how this could be implemented in a neurologically plausible way.
In the following sections, I'll try to examine the relation of some of these assumptions to the actual AI systems we have or we are likely to develop.
GPT as a generative model with an actuator
Epistemic status: Confident, borderline obvious.
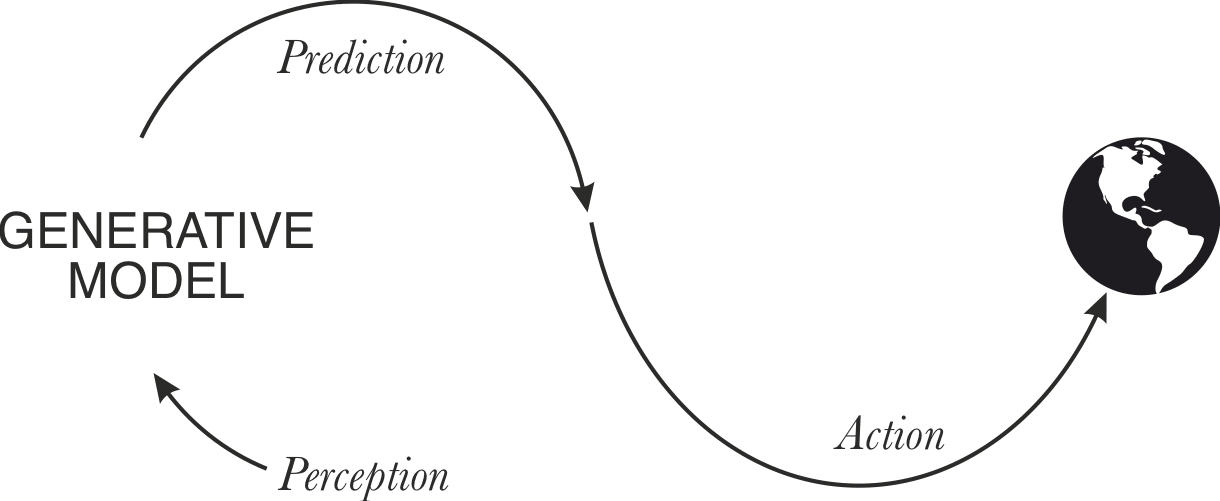
It’s common on LW to think of GPT-like systems as pure simulators.
GPT doesn’t have actuators in the physical world, but it does still have actuators in the sense that it can take actions which affect the world of its sensory inputs. GPT lives in the world of texts on the internet, approximately. A lot of the text GPT produces has some effect on this world. There are multiple causal pathways for this:
- Direct inclusion of text generated by GPT in web pages.
- People asking GPT for plans and executing those plans in the world.
- Indirect influence on how people phrase things or think about things, e.g. learning about a concept from GPT.
- Even more indirect influence routed through people, e.g. wide usage of GPT in education leading to greater convergence of humanity on more or less the same set of concepts and ontology.
- GPT influencing other software systems or being part of them, e.g. Auto GPT executing plans in the world.[5]
(See How evolutionary lineages of LLMs can plan their own future and act on these plans for a different exploration of the action space by Roman Leventov.)
In the predictive processing frame, what’s going on here is:
- Perception: in training, GPT is fed internet text. The system ‘perceives’ inputs from the external environment, and builds a generative model of the inputs.
- Action in the world: the outputs of GPT systems actually influence the world. You can see various individual conversations with GPT as micro-actions, but overall in sum these actions influence the world of text. So GPT in principle has an open causal path to make the world of words closer to GPT's generative model predictions.
Closing the action loop of active inference
Epistemic status: Moderately confident.
Given that the "not acting on the world" assumption of "pure simulation" does not hold, the main difference between GPT and active inference systems is that GPT isn’t yet able to perceive the impacts of its actions.
Currently, the feedback loop between action and perception in GPT systems is sort of broken - training is happening only from time to time, and models are running on old data:
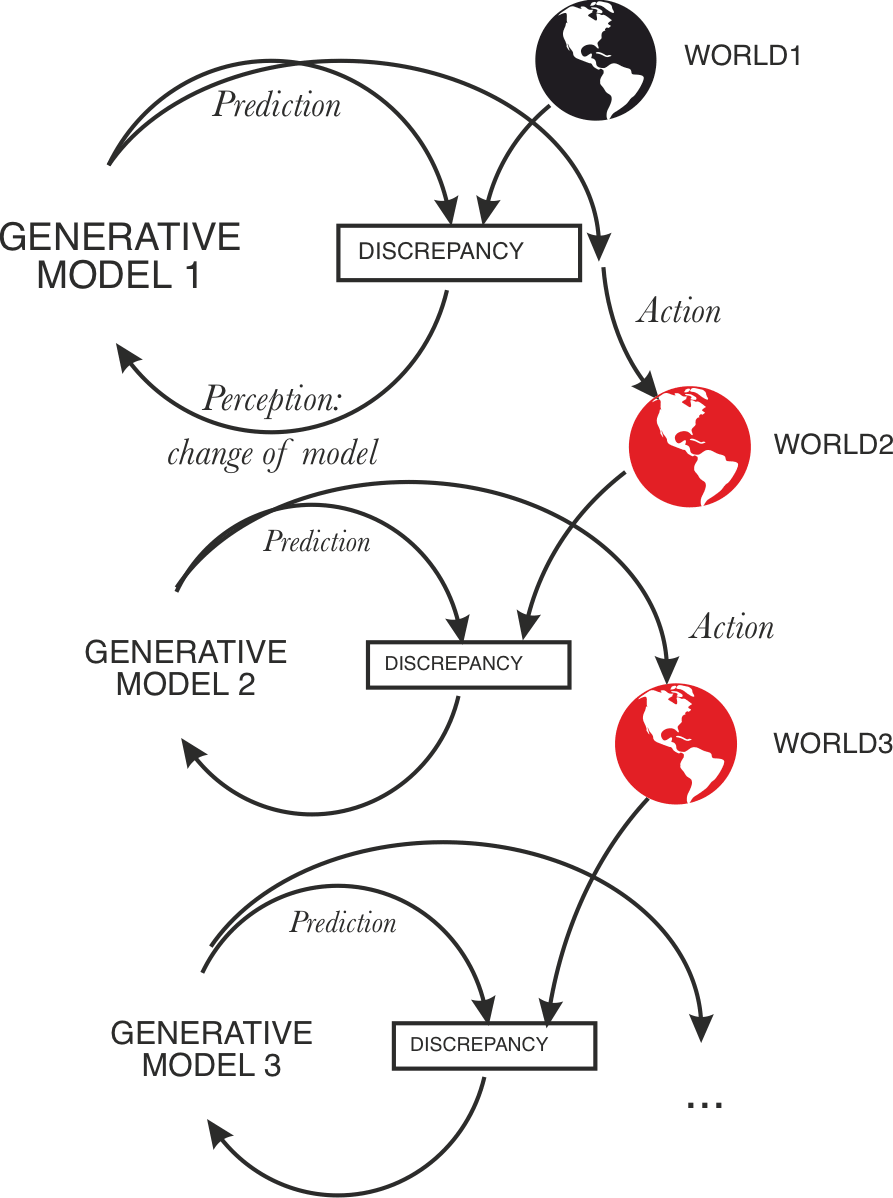
So the action loop is open, not closed.
Note that if we investigate feedback loops in detail, this is often how they look - it’s just that if the objects are sufficiently identical, and the loops have the same time-scale, we usually understand this as a loop running in time, or a closed loop:
In practice, there seem to be multiple ways to close GPT’s action to observations loop:
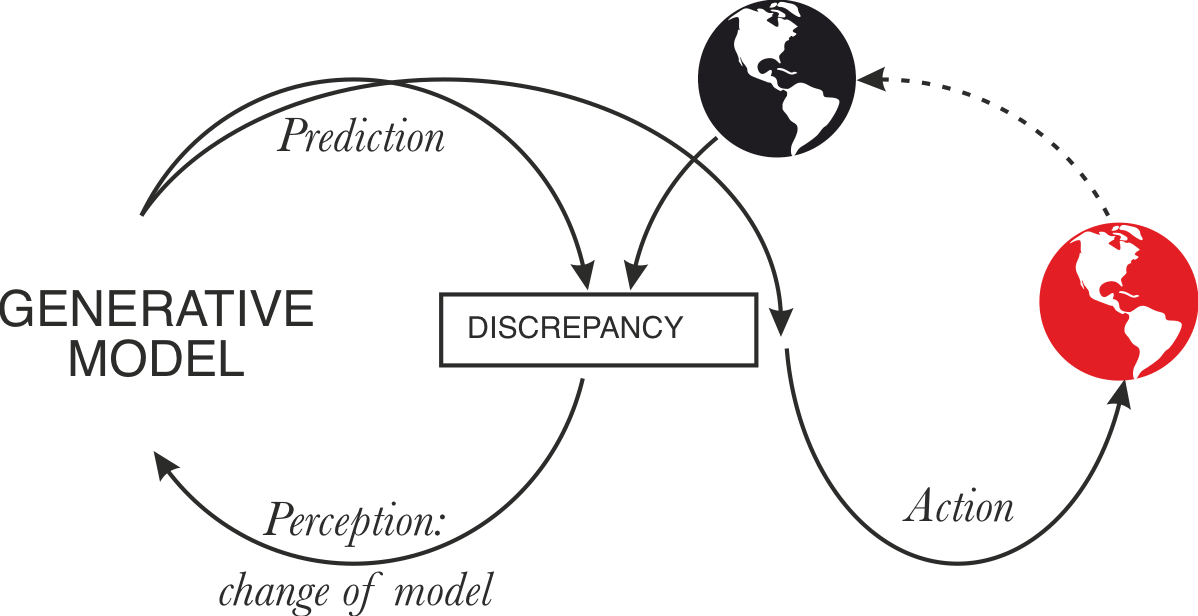
- Continuous learning, updating the model on live data.
- Fine-tuning.
- Giving the model some sort of faster memory, by e.g. given it access to internet.
- Increasing the similarity between successive generations of the model such that self-identification and self-modelling are easier. (This is explored in Roman Leventov's writing considering "the GPT lineage" as an agent.)
I think there are strong instrumental reasons for people to try to make GPT update on continuous data, and I would expect this to make the action loop more prominent. One reason is that continuous learning allows models to quickly adapt to new information.
Another way for the feedback to get more prominent is to give the model live access to internet content.
Even without continuous learning, we will get some feedback just from new versions of GPT getting trained on new data.
All of this leads to the loop closing.
It's probably worth noting that if you dislike active inference terminology or find it really unintuitive, you can just think about the action-feedback loop, when closed, becoming an emergent control loop between the generative world model inside of GPT and the external world.
It's probably also worth noting that the loop being closed is not an intrinsic property of the AI, but something which happens in the world outside of it.
What to expect from closing the loop
Epistemic status: Speculative.
The loop becoming faster, thicker in bits, or both, will in my view tend to have some predictable consequences.
Tighter and more data rich feedback loops will increase models’ self-awareness.
As feedback loops become tighter, we should expect models to become more self-aware, as they learn more about themselves and perceive the reflections of their actions in the world. It seems plausible that the concept of 'self' is convergent for systems influencing the environment which need to causally model the origins of their own actions
Models’ beliefs will increasingly ‘pull’ the world in their direction.
Currently GPT basically minimises prediction error via learning a better generative model (the perception part of the feedback loop). With a tighter feedback loop, the training can also pick calculations which lead to loss minimization channelled through the world.
Note that this doesn’t mean GPT will ‘want’ anything or become a classical agent with a goal. While all of the above can be anthropomorphized and described as "GPT wanting something", this seems confusing. None of the dynamics depends on GPT being an agent, having intentions, or having instrumental goals in the usual anthropomorphic sense.
As an example, you can imagine some GPT computation coming up with a great way to explain some mathematical formula. In ChatGPT dialogues, many people learn this explanation. The explanation gets into papers and blogs. In the next training run, if the GPT' has or discovers the same computation, it will get reinforced. To reiterate, this can happen in a purely self-supervised learning regime.
Technically, you can imagine that what will happen is that the next round of training will pick computations which were successful in pulling the world of words in their direction.
In my view, the sensible way of understanding this situation is to view it as a dynamical system, where the various feedback loops both pull the generative model closer to the world, and pull the world closer to the generative model.
Overall conclusion
In my view, "simulators" are generative models, but pure generative models form a somewhat unstable subspace of active inference systems. If simulation inputs influence simulation outputs, and the loop is closed, simulators tend to escape the subspace and become active inference systems.[6]
The ideas in this post are mostly Jan’s. Thanks to Roman Leventov and Clem for comments and discussion which led to large improvements of the draft. Rose did most of the writing.
Appendix: transcript of conversation with ChatGPT
In process of writing this, Jan first tried to guide GPT-4 through the reasoning steps with a chain of prompts. When a specific sequence of instruction led to GPT-4 explaining mostly coherent chain of reasoning, we used the transcript in writing the post. Transcript available here.
- ^
Multi-modal GPTs trained on images may be in a slightly different position: in part, they are interacting directly with the world outside the cave, via images. On the other hand, it’s not clear whether this will directly improve the conceptual language skills of these models. Possibly multi-modal GPTs are best thought of as in the second cave, but with a periscope into reality. See https://arxiv.org/abs/2109.10246 for more on multi-modal LLMs.
- ^
Cf. LeCun, "SSL is the dark matter of intelligence", https://ai.facebook.com/blog/self-supervised-learning-the-dark-matter-of-intelligence/
- ^
Daunizeau, Friston and Kiebel, ‘Variational Bayesian identification and prediction of stochastic nonlinear dynamic causal models’, Physica D: Non-linear Phenomena, 238:21, 2009.
- ^
https://arxiv.org/abs/2212.01354: "On the present account, learning is just slow inference, and model selection is just slow learning. All three processes operate in the same basic way, over nested timescales, to maximize model evidence."
- ^
- ^
Note that this does not mean the resulting type of system is best described as an agent in the utility-maximising frame. Simulators and predictors is still overall useful framework on how to look at the systems.
- ^