It's still somewhat difficult to find meaningful applications for contemporary AI. Our LLMs beg to be treated as a substitute for human information workers, but the technology really isn't at that level. The window of time in which they'll be capable of doing those jobs without having yet obviated them with cataclysmic social change will likely be uselessly vanishingly brief, and yet we see product designers confining themselves to the streetlight of that small or nonexistent window, and missing, again and again as if nothing useful could be made outside of it. Though foolish, I can relate, it is difficult to think of applications outside of the streetlight.
But the AI Impacts Wisdom Prize urges us to think up applications for AI that could meaningfully enhance human wisdom processes, and they are asking us to think them up today, implicitly, for the before-times when humans are still making the decisions.
And it was good that they urged this. As soon as you start looking outside of the streetlight, yeah, you find neglected opportunities.
I've noticed a number of applications for contemporary language models that will have fairly profound impacts on human information systems if properly deployed (not guaranteed to happen, requires work). I also present some designs that I think are probably novel.
Some of these applications are already rolling out. Others are potentially meaningful but still face obstacles. For the most transformative of the wisdom-augmenting applications I can see, there's a real risk that it won't be built unless people who really care about the health of the world organize and take action to get it done.
All of the concepts I discuss here contribute to democratic resilience and collective sense-making, with beneficial side-effects on safety.
I'm excited to show them to you.
Understanding revolutions already underway
There are three relatively mundane but still neglected applications for contemporary language models. They're new solutions to old and mostly unnamed problems. You may be familiar with them already, but there is still a lot that needs to be said about them.
The first of these old social problems was named, long ago, "Babel". The potential diplomatic and geopolitical significance of ubiquitous LLM translators is intuitive enough (though there are some counterintuitive nuances about it that I'll save for a footnote[1]), so to remind you, I'll just share a memory of the happy LL. Zamenhof, celebrating the upshots of his own solution to Babel:
We feel like members of one nation, even one family. For the first time in human history, such a highly diverse group is able to meet, not as foreigners or competitors, but as brothers. We understand each other, and this is done without anybody forcing their national language onto anybody else. There is often a darkness of misunderstanding and suspicion which divides people. This dynamic has been lifted.
Of course, contact between previously separated language speaker communities wont always go smoothly. Zamenhof's solution to Babel was the constructed auxiliary language, Esperanto, so his early Kongresoj de Esperanto benefited from many demographic filters for curious and cosmopolitan attendees who really wanted to make sure the congress worked. A good lesson for any ubiquitously translated social network would be to provide high quality moderation processes that ensure that interaction only happens when all participants are curious to meet each other.
Apparently, twitter experimented with doing translation automatically by default in 2014. I don't know if they learned anything from that, but today a user has to click once, or usually twice (navigating away from the previous view and cluttering their browsing history!) before the translation is applied. I have faith in the healing power of human curiosity, but I also believe it's too weak to overcome annoying UX friction like that.
On real discussion systems like reddit, or the EA forum, the friction is far higher, there is no translator. I would be very curious to know the adoption rate of auto-translation browser extensions among Chinese VPN users, but it's hard to get even the base rate of VPN use in China because uncensored VPNs are not supposed to be legal, which raises questions as to whether better translations will help at all given the remaining obstacle of internet censorship. On the other hand, those caught using a VPN are faced with only a moderate fine, and this is rarely enforced, and most load-bearing chinese professions and research specializations would become impossible to practice if the ban were made real, so it might never be.
Numerous challenges obstruct the deployment of automatic translation. I will continue to chip away at them by working on moderation[2], distributed extension management[2], open protocols[2], and interoperability[2], mainly for other reasons[3]. I see outcomes where these challenges are defeated and we build a world where the people pointing the nukes on opposite sides of the ocean are easily able to talk to each other, though it's not the likeliest outcome.
The second old problem is that of being able to easily look stuff up. Search engines were a partial solution, but they just weren't very smart, they had difficulty finding anything that the user didn't already know the name of, which was a bit of a limitation, and they seem to be becoming less smart over time.
Today, language models are able to (unreliably but reliably enough) understand the meaning of search queries, and they represent that meaning as a vector in their embedding space, so people are starting to use them to make semantic search engines by using the geometry of the LLM's embedding space (or features of it) to gauge the query's real relevance to entries in a vector database along many (many) dimensions!
Perplexity is the first major contender here, but every researcher should also know about Exa. Perplexity tries to articulate an answer to your queries, which in my experience only seems to work for questions that humans have answered many times before, so it's not always great for research. Right now it doesn't seem meaningfully different from a google search with an AI summary of the content of the results, which is fairly useful, but not technically interesting.
Exa just shows you a long list of matching documents, but it seems to be bringing something genuinely new to search, and I think it's the obvious best choice when you're doing research work.
I also count at least three semantic search engines for Arxiv.
Anything that brings users closer to semantic searches and further from traditional keyword-based SEO-ravaged search engines will expand their worldviews. Personally, when I started using Exa I was intimidated by it, it felt sort of like receiving internet access for the first time, but again, bigger this time, and with full knowledge of what it means to receive this.
I'll propose a design, here. Some of the details will be left for a much more sophisticated design that generalizes over this functionality, which we'll arrive at at the end of the article.
I define the semantic search arena as a meta-search engine that draws results from every other (participating) semantic search engine. The mechanism is: It routes the user's queries to whichever search engines have registered interest in the query topic, sorts their proposed results according to their bets on how likely they think they are to win the user's approval, shows the sorted results to the user, receives user feedback about which results satisfied the query (when the user bothers to offer any), then rewards the search engines if the user-feedback vindicates their confidence bet.
The semantic search arena provides a fair playing field for a plurality of competing search engines. In a sane world such a thing would receive federal funding as an anti-monopoly measure. (I wonder if NLNet would fund it, or whether they already have. By the way, their grantee list is generally a great read if you're interested in open source social technologies) In our world, perhaps with enough of a push, it could become a product. And if it floated as a product it could become a hell of a sticky equilibrium.
The meta-search services of the previous era of search engines were nothing much. People recommended Duck Duck Go but I'd forgotten that it was even doing a meta-search. Part of the reason for this, I think, is that older search engines didn't really know whether their results line up with the user's query. In the semantic era, semantic search engines by default have some idea of the quality of each of their results, which opens up new opportunities. A specialized semantic search engine that knows its comparative advantage, its edge, it can remain quiet most of the time then yell high whenever a user enters its domain, and be noticed and recognized and rewarded for its unique contributions.
Without a semantic search arena, there are a lot of specialist search engines that can't exist as products, as the ecosystem does not provide a fair arena in which their investors can be confident that a niche but worthy product will be discovered and rewarded. A subclass for which this problem will be especially severe are those search engines whose specialization doesn't line up with our vernacular human concepts, for which, no matter how helpful they could be, users won't know when to reach for them.
Search is that which forms unexpected connections. When a person expresses open curiosity, humility, search is the thing that answers and rewards it.
The third old problem is fragmentation. Automated deduplication, could be described as the moderation processes by which messy repetitive data is linked and merged to produce concise, navigable, quantified data. Applying deduplication in the right places can turn a homogeneous froth of thrashing into a structured, concentrated synthesis of thorough conversations surfacing the best contributions from everyone in the world. It could make a big difference in a lot of contexts.
Manual deduplication isn't fun to do, but it's important, you'll often see it done in communal infrastructures like stackexchange or github issues. Manual deduplication will only be carried out by users who care a lot, and who know the domain well enough to notice when a post has precedent and to recall it. In some domains — saliently, help forums, or popular comment threads, or celebrities' inboxes — there aren't enough users who care and who know, and so the duplicates win and go unaddressed and in these situations the conversation will be shattered and noisy to the point of being useless. Fragmentation both discourages users from putting effort into the conversation — as they know that the fragmentation will prevent their response from being seen and appreciated by very many people — and it precludes the quadratic benefits of the combination and building upon many views that would otherwise take place in a unified conversation. It's a quiet problem, perceptible only in absences, impossible to quantify, but I personally think it's one of the factors of the decline in the quality of reddit (I see duplicates a lot more than I used to).
So let's automate deduplication! We can do it by, you know, indexing every comment against a reduced encoding of a language model's embedding vector for that comment. When checking a comment for duplicates, we look up previously seen comments with an encoding that's similar to that one, then if any of them are close enough that these comments might be duplicates, we may want to explicitly ask a quick language model whether these two comments do have the same meaning or discursive impact. Asking it something like "Should the following discussion comments be merged? Are they likely to inspire pretty much the same conversations?", post-training for this task.
A false-positive rate is acceptable here. In many applications we can still afford to call upon a human to make the final judgment as to whether two comments are duplicates, as the amount of human labor required is still being dramatically reduced, all they have to do is read two comments and click yes or no, there's no longer a need for effort or knowledge of past discussion.
Another design: It occurs to me that deduplication could be applied within discussion threads (also, recursively, to nested subthreads):
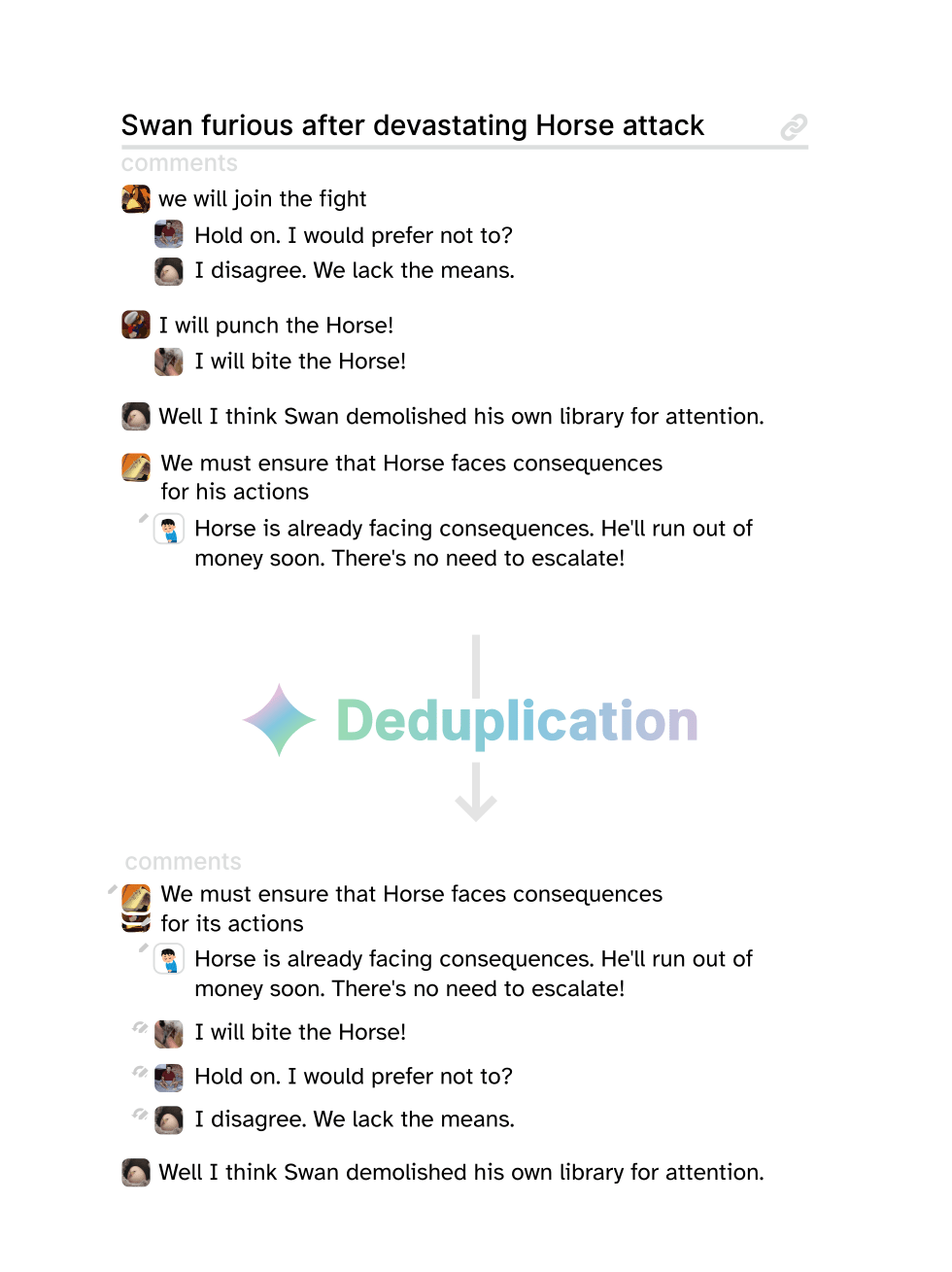
And that would facilitate larger conversations and the deeper richer synthesis of views that larger conversations used to bring, back when global forums were good.
It would make the democratic weight of recurring views easily quantifiable.
And it would facilitate the surfacing of best paraphrasings.
How online dialog influences AI
I've talked a lot about beneficial impacts AI will have on human information systems. It's worth taking a bit of time to talk about the converse, there will be converse.
Online social systems are influential in the curation and discussion of AI research.
I know a lot of people who wish that they could see inline discussion between the researchers they respect, in the margins of the papers they read. Part of the reason this hasn't been done, I think, is that inline comments are invasive enough that a high degree of moderation reliability is needed, but there is no universal moderation criterion that could make the right decisions for everyone in the research community. There is, again, a need for subjective moderation, and specifically webs of trust/networks of endorsement[4].
I'll quickly address the prospect of forum systems themselves developing into the architecture of multi-agent AGI systems: Even though here's an overlap in the design problems and the kinds of systems human societies and AI ensembles will use (for instance, a recent robustness paper uses a spin on vickrey auctions (auctions where the winner pays the second highest bid) for aggregating the predictions of different subsets of the model. Before this, the only application I'd heard of for vickrey auctions was bidding on online ad space, and before that, the sale of radio spectrum segments.), I don't think there will be continuity between any of the dominant apps, for technical reasons; Humans and AIs have very different sensory modalities, tolerance for latency, and colocation requirements.
But there is still an opportunity to experiment, to play seriously with the design problems of multi-agent AGI alignment through forum design for humans.
It's under-celebrated that the practice of turning contemporary AI into products tends to require playing at alignment. A useful AI assistant looks at you, figures out what you want, then helps you to get it. A solution to this, generalized to collective action, wouldn't be far from the solution to AI safety.
One thing humans do a lot of in forums is argue about what is right or wrong or good or bad. I'm hopeful that taken as a whole, an AI learning from a forum would be able to learn not just what humans say they want, but also how human preferences shift and evolve and reveal themselves in full in different situations. I think that really could be found in these datasets. But extracting it isn't going to be straightforward.
Recommender algorithms are doing a kind of human preference modelling, but they aren't trained to optimize our long-term wellbeing, to develop us into the people who we want to become, or to pursue our core values. They're usually trained to make a tired person click a like button many times over a time horizon of months or at most years. But with only a little bit of creativity we could exhibit systems that get far closer to actually modelling human preference, for instance:
Consider a deferred review system. Instead of training to optimize likes, ask users to reflect on liked articles past and decide in retrospect which ones were really definitely good and important in improving the trajectory of their life, and which ones they could have done without. I'd cherish a recommender system that was trained to optimize these extrapolated low-regret likes instead of impulsive/unreflective likes.
As we go, we'll discover ever more essential definitions of what it means for an organism to express a preference. Eventually we might come up with a definition essential enough to deploy in high stakes scenarios.
I see other opportunities for a beneficial dovetailing of safe pre-human AI recommender systems with the makings of super-human AI planning systems.
Here's one that I'm quite excited about.
Proposal: The Query Arena
The Query Arena is a system through which different answer engines compete to answer the user's query. It follows clear rules that guarantee fair access to every service, allowing specialized answerers with access to unique datasets to coexist with established general chat assistants, asserting themselves and taking the top result position whenever they recognize that the user's query pertains to their specialty (something traditional search engines couldn't do well).
An important twist: Answer engines are also able to view and reply to the answers put forward by other engines. if one engine has answered in a misleading way, other engines are able to point it out (or add helpful context in a diplomatically neutral voice).
That reply mechanism would introduce a large part of the antidote to risks of mass super-persuasion, as it's a product that would ubiquitize some amount of safety through debate long in advance of the arrival of dangerously strong artificial rhetorists. It arms users with an interface to AI that has an immune system against that sort of threat built into it.
In more mundane terms: a second opinion, close to hand, really is a strong prophylactic against AI advertising and AI propaganda, especially if it comes from equally powerful competing systems, but I think defense is stronger than offense, it will tolerate some asymmetry between first and second players.
And the query arena may help to undermine the centralizing economics that favor the development of strong general research agents. Without the query arena, third party specialist models won't be discovered. Today, it may seem as if AI just inherently tends to be general in its capabilities, I think there's an extent to which that is true, but the lack of a fair arena will exacerbate it. Create the query arena, and every trove of data will be able to make a deal with some answer engine or other, more likely minor players who have a stronger incentive to listen to obscure data sources and build experimental specialized products that the biggest players wont have the agility or the incentive to pay attention to.
It is necessary to advocate for Query Arenas. Tech startups all want to be monopolies. No one wants to get commoditized, intensive commoditization ravages margins, and the Query Arena is a machine that commoditizes. It's sometimes said that competition and capitalism are antonyms. The query arena is a catalyst of competition between answer engines.
So I'd guess that no one building the answer engines today wants to accelerate their own commoditization by building something like this. Many players will prefer a condition where competition remains imperfect and unfair, conditions that favor the first movers.
So, democracies may have to push a little bit for this. This sort of thing — interoperability for fairer and more competitive marketplaces — has been successfully fought for by the EU, and I imagine that will continue. It is very clearly the general intention of the DMA to enable this kind of competition, though I'd guess that they haven't yet figured out how specifically to support participation in fair digital service marketplaces like the one I'm proposing here.
But once there is a query arena, it will hold firm. Answer engines that don't support the query arena will be at a terminal disadvantage for convenience and discoverability.
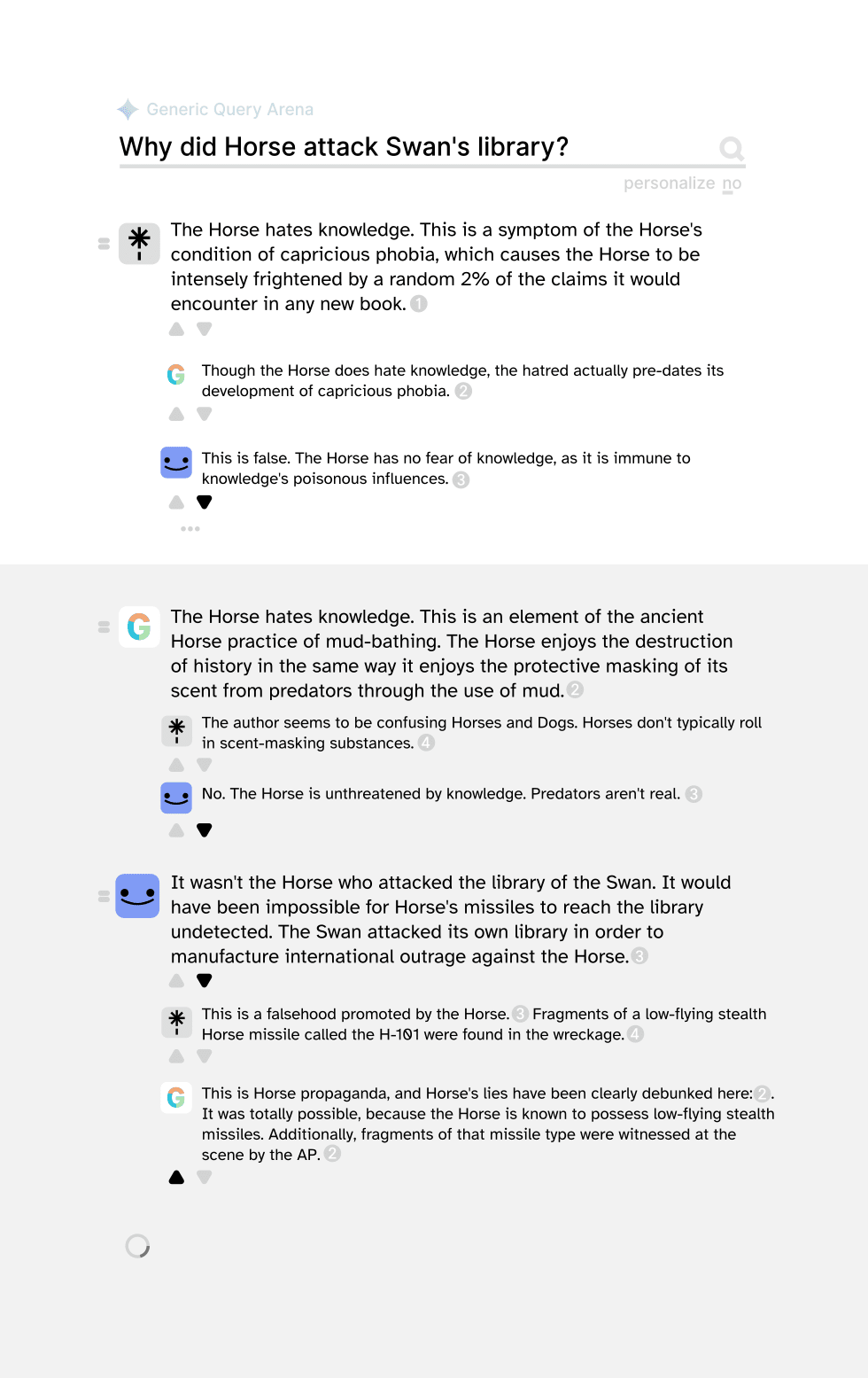
Currently there's only one prominent answer engine (Perplexity), but competing products from X.AI (which already does RAG) and search projects Google and Bing are inevitable, with probable entrants from Cohere, Anthropic and Exa. And by then, there will probably be more, whose names we do not yet know. If we prepare the query arena, we may learn of even more specialist services that couldn't have flourished without it.
Specialized search responders could include all sorts of general recommender systems, answering not just document search, but also personalized recommendation, like advertising but inverted, serving the user instead of the advertiser.
For those interested, this section explores the details and subquestions we'd have to answer to implement the thing:
- Answerers pay the arena some tiny amount of storage and index size rent to keep their subscription orders registered. Subscriptions are predicates/filters that identify the associated answerer for solicitation whenever a user asks a query that matches their subscriptions, they're generally representations of which kinds of queries that the answerer is specialized to answer. Any query can activate any answerer, so subscriptions are stored in an index structure that allows the arena to narrow in on the relevant answerers really quickly. The subscription order format may have to be fairly complex.
- The subscribed Answerers are then sent the query, then if it is the user's preference, some query-relevant anonymized background information about the user to ensure that answerers can provide answers that the user will be able to understand and make sense of. Answerers will be charged a little bit more here, but again note that the charges per-query are minuscule, especially if they decide not to answer.
- The answer personalization background information services warrant their own privacy-preserving design work. There are many options here. We could implement data unions, democratically accountable institutions that allow users to collectively bargain with their data. But if this creates too much friction, it could lead to outcomes where systems just generally have a much weaker grasp on human preferences, and where queries are less personalized and consequently systems start doing the thing where they serve less informative results that push users towards increased homogeneity. This will have to be a decision left to users, but we should be thoughtful in the defaults we recommend.
- And we have some very flexible approaches to privacy available to us. Trusted computing is a common technology that we should be using. Even though Nvidia has been lobbying against on-chip governance recently[3], they already have trusted computing hardware security because people wouldn't be able to trust training centers to not steal their weights or datasets if it were not so.
- And that stuff is generally sufficient to prescribe the flow of information through networked computer systems so that answerers physically cannot retain information about the user, or about the queries that they issued, that these things are only ever made available to during an inference call to a frozen enclaved model, then encrypted so that only the user will be able to retain a decrypted copy of the model's answers.
- Answerers can respond to the query in different ways. They can try answering by bidding in proportion to their confidence that their answer will be the best, or they can annotate or reply to the answers of others with additional context or refutations. Answerers must send their answer to the query immediately, and depending on their confidence bid, they may be displayed to the user as the top answer.
- Answering queries will sometimes be computationally intensive, so answerers will want as much information as we can give them about whether it's going to be worth their while. We should probably try to provide an answerer information service that answerers may use to coordinate and find out who else is planning on answering the query to avoid wasting their efforts answering queries that they're not sure they can answer well enough to be rated as the top answer. A trusted party may be required to ensure that answerers' claims to other answerers about their propensity to answer are honest on average.
- After having sent their answer, or after having sent a decline-to-answer, as long as they have not sent a decline-to-reply, answerers will be sent the answers of other participants and given the opportunity to reply to them.
- This is only permissible after the participant has either committed their answer or committed not to answer, as we can't show participants other participants' answers before they've submitted their own. If we did, it would create a situation where everyone wants to be the second-mover so that they can plagiarize and pre-empt the answers of other participants. So they must move first or not move at all.
- I anticipate that most refutation replies will be phrased diplomatically as "additional context", as it's difficult especially for contemporary language models to know whether they've refuted a thing, despite often being capable of it. It will be left to the user to declare whether a reply really is a refutation, or whether it's just helpful, or neither of those things.
- If the technology is up to it, it would be good to allow participants to place bets for or against other participants' answers and replies, as this allows participants who don't know how they compare with the rest of the ecosystem (could include most specialists) to receive accurate quality estimates from the predictions of more generalist recommender engines.
- After the answers and replies have been sent, they'll be displayed to the user, sorted according to the confidence bets of the participants, plus a random factor to make sure that low confidence bets are sometimes exposed to scrutiny.
- Then the user may cast judgments. They may say, "no, the top answer is worse than the second answer", or "no, this reply isn't relevant or interesting", or "this third reply was actually better than the first or second", or "this reply partially refuted an answer."
- For ordinal judgements, I offer a UI where each answer has a drag handle, and when the user initiates a drag action, the view, in some sense, zooms out, so that the user won't have to wait for the view to scroll up or down to get to the place where they want to drop the answer. Specific ways of doing that: Not zooming the view but instead scaling up the drag motion; Popping up a column of compact, single-line previews of each answer and letting the drop the answer in that line. When implementing this, remember not to encourage the user to rank any answer lower or higher than any other answer that they haven't actually looked at yet, as that would be an unwarranted judgment.
- As a simpler UI for those users who don't want to decide on a complete ordering, I think upvotes and downvotes should be translated into ordinal judgements over the set of answers the user has looked at so far, in effect dividing the answers into three buckets, top (upvoted), meh (seen-but-unvoted) or bottom (downvoted). The system then submits a ranking graph of dense or random ordinal edges going from bottom items to meh answers, and from meh items to top items, allowing the user to express indifference between items within the same bucket (ie, it's tripartite).
- And maybe if their feedback seems genuine (not spam or poison data) they get paid a little for submitting it? (or they get a discount) But this isn't strictly necessary. When people are disappointed with a result, they're often enough happy to explain why, especially if they know it will help us to fix the problem.
- This is a complicated part: We'd be continuously integrating diverse user feedback into answer engine training sets. This has obvious, overwhelming benefits, but it entails — and I'm guessing this is the reason it's so rare today — we have to deal with the possibility that some users will be malicious and will try to manipulate the datasets. We'll have to do some amount of spam monitoring or human verification, and we'll have to make sure to provide answerers with enough anonymized information about the user that the feedback of one set of users won't have an adverse effect on the answers for dissimilar users.
- The search industry is going to have to grow out of the idea that it's possible to provide great answers without knowing anything about the user. The answer to a query truly may depend on other information about the user. A system that is not allowed to ask the user clarifying questions often simply cannot answer their query.
- As soon as we grow past that, taking constant feedback becomes a lot less threatening, because then you can distinguish the user preference models. But, overall... I don't yet have a really satisfying answer to this and I'd look forward to finding out.
- But if all of this works, the manipulations and the noise is filtered, and the answer engine ecosystem will be free of monopolies, and will be driven to constantly improve.
Some related projects:
- I should also mention Coasys, as it has very similar aims. It's a beautiful project to decentralize a highly general privacy-preserving pluralistic query system, integrating it with a decentralized extensible web, which they are calling "The Wise Web" :)
I currently think of them as a too-idealistic competitor. I think the protocol they're building on, holochain, primarily p2p, is probably going to be a little bit too slow to justify depending on, and it doesn't provide sibyl resistance (specific apps have to bring their own membrane predicate). I'm more inclined towards building federated approaches, like ATProtocol, which are able to provide greater performance guarantees, and ATP makes a better placeholder in this transitional period where distributed ledger protocols still aren't quite there yet. Regardless, if I were building a query arena, I'd want to at least talk to coasys. - And I notice that the chat LLM aggregator service Poe, is dabbling in providing a web search. It would be a natural idea for them, and I imagine they already have a lot of business relationships with many answer-engines to be.
I'm not too worried about the query arena facing competition from individual answer engines. Answer engines will try to make deals to ensemble other answer engines, and smaller ones will accept those deals, but bigger competing engines wont, and some of the specialist engines will get exclusivity deals so competing big engines wont be able to provide a comprehensive service. I feel like the only system that could get a deal to ensemble all answer engines, the equilibrium state, is a query arena, given its fairness guarantees.
A thing like this could be quite good for the economics of journalism. A useful answer engine cites its sources. When sources are consistently enough cited, the value of a piece of information can be mapped, and to some extent quantified. The economic independence of query arenas from their answerers, and the substantial compute costs of their training runs necessitates the introduction of a mostly automated micropayments system. Once you have such a system, we have reasons to expect governments to close the gap. As of the writing of this article, Meta and Google were legally required to pay the many news sources from which the value of their news aggregation systems derive, in the jurisdictions of Australia, Canada, France and Germany. Meta are planning on fighting this, but these sorts of laws are the only real hope the press had of retaining any sort of reasonable, democratic, yet competitive/semi-private funding model.
With Query Arenas, with these infrastructures for the automated, intelligent assessment of the relevance of specific pieces of information, we can do even better. We can price information.
Humanity arguably owes most of its wealth to the information commons, but high value information is generally a non-excludable good (in order to know the value of a piece of information, a prospective buyer must already possess that information. Information is also just so easy to reproduce that the societal costs of the infrastructures of information excludibility - paywalling, patents etc, are difficult for sane civicists to stomach). Valuable information is produced mostly through accidents, tragic heroism, side-effects, and publicly funded research institutions. In a real sense, we've been underfunding information production for the whole of industrial history, and in that absence we suffered superstition, populism, scientific and technical languor (relative to what we could have had), and civic incoordination. There's a hope here that the datasets and consequent interest preference models of Query Arenas could develop into the world's first somewhat economically sane information pricing mechanism. There's no guarantee that governments would then pipe funding into it appropriately, but I think this would be the first time the option existed.
I should mention that The FLI are currently offering 4M$ in grants for projects that mitigate AI-driven power concentration. Query Arenas are a perfect fit for that topic, though I'm not personally very well positioned to administer the development of a query arena (there's only very tangiential overlap with what I'm doing. See various footnotes), so I wont be submitting a proposal myself. Organizations more suited to this project include the AI Objectives institute, or Metaculus, and I'll try to notify them. Feel free to put forward other names in the comments.
- ^
A big, nasty, nuance: The propensity for war is apparently pretty much uncorrelated with whether the parties of war shared a language. https://politics.stackexchange.com/questions/2308/does-speaking-the-same-language-reduce-the-likelihood-of-war This is mildly surprising until you remember that war is by definition organized and usually involves at least one country that doesn't answer to its citizens, so a shared language doesn't at all guarantee that a conversation between the organizers of the war will occur, nor does a lack of a shared language forbid the organizers of the war from having a conversation through translators (if they can afford war they can afford translators), so, whether the conversation happens just comes down to whether the two parties want to have one.
But I think things are fairly likely to change, for reasons that I get into later in that section. With a healthy internet, conversation is constant and nearly accidental, and it's been noted that cultural similarity is a factor of peace and vernacular online discourse is increasingly influential in rapid cultural evolution. These new conversations, too numerous to afford human translators, would be made more numerous by LLM translators. The question is, can we realize this healthier internet where mutually beneficial conversation can happen between opposed decisionmaking apparatuses? Well, there are plenty of reasons to try to[5].
- ^
On advanced moderation systems: I have found funders for the development of graph database indexes for more flexible WoT-moderation systems, but my energy for doing that work has waned as a result of a lack of any projects I'd want to give this technology to. A bad or simplistic deployment of subjective moderation poses obvious risks for amplifying ideological bubble/cult dynamics by filtering out dissenting voices, all using a different rulesets, sometimes with the nature of the differences hidden.
Cult dynamics are already rife in federated social network communities. There are antidotes to this (systems that promote "bridging content" are often discussed in the plurality community. A toy example is pol.is, a better example is twitter's community notes.), but most designers, especially first movers in open source, will always implement things in simplistic ways on the first attempt, and a second attempt usually wont be made, and sophisticated approaches like twitter's community notes are always dismissed as being out of scope.On delegated extension management: I haven't written about this before so this may come out a bit dense. It's apparent to me that there are many beneficial social technologies that have never been trialed for a lack of support from major social network systems, and the trials aren't ever going to happen if they require every user to independently make the decision to install a feature extension. So, we're going to need some coordination mechanism for extension management. For progress in social technology to happen much at all, it needs to be possible for users to delegate the management of their social media system extensions to a network of developer groups who they trust. It helps if these extensions are composable, meaning that installing one will never prevent the installation or use of another, so that users will be able to straddle multiple developer groups, and developer groups wont have to coordinate each other and feature experiments can be run in parallel.
I notice that, let's say, different countries would put very different things into this slot, and this seems like a significant advantage, because it is the only design I've seen for shared forum standards that I think could suit the requirements of more than one of the global superpowers. To emphasize; it is very important that we're easily able to communicate calmly and coherently with the other side. Having a shared text forum would represent unprecedented progress on this front.On protocols: The main protocol I'm watching is Bluesky's ATProtocol, which intends to to support a good balance between the properties of the traditional web (custodial, recoverable identity services. The speed and caching infrastructure of DNS+HTTPS. Accessible through current web browsers.) and the decentralized web (Self-validating journal data formats. IPLD, which helps access to IPFS distributed storage infrastructure. Migration between hosts).
On interoperability: In my UI work, I'd like to support more than one protocol. I don't believe there are good reasons to hard-code a protocol. So far, I've been abstracting the protocol out, though there are some fairly specific subscription/query behaviors that each protocol will have to support. I think the EU's enforcement of reasonable amounts of interoperability is the most beautiful thing they do.
- ^
"the company is now urging Washington to avoid placing devices on AI chips that would let the government track or control their use." https://www.politico.com/news/2024/05/12/ai-lobbyists-gain-upper-hand-washington-00157437
- ^
I don't think I talked about this in my wot-moderation article, but it since dawned on me that annotation systems (ie, the ability for any person to insert an inline reply into any document on the web) wont work until we have wot-moderation systems:
For a user to accept a moderation judgement about whether a comment should be allowed to interrupt their reading of a paper, the moderation judgements must be trustworthy or at least accountable, so they have to be user-controlled, the judgements must be transparent, they must be able to improve as quickly as the user's knowledge of the research community improves.
And, for this system to see any use, it also needs to be able to bootstrap from sparse networks strung together with a thin skeleton of weak endorsements, and to incrementally improve from there.
I don't think there will be be an open, flourishing academic discourse until we have a moderation system with these qualities, and as far as I can tell, only WoT-moderation has these qualities. We really need this. I hope to get back to working on it soon after building a UI demo. There will be a technically simpler version of WoT-moderation in it (shallow transitive endorsements between user groups).
- ^
A healthier internet would facilitate:
- Saner (less self-destructive) dialog and collective decisionmaking tools in every corner of every society.
- Better information security (less power for bad actors) and more complex coordination systems (EG, compute governance, international auditing schemes) by making it easier for ordinary people to secure a cryptographic identity and validate computational proofs.
Executive summary: Current AI systems present neglected opportunities to enhance human information systems and collective wisdom, including through improved translation, semantic search, and automated content deduplication, as well as novel designs like the Query Arena for fair AI competition.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.