I attended this talk not knowing much about mechanistic interpretability at all and came away quite excited about the idea of working on it. Particularly, I found that there were concepts and intuitions around MI that overlap or have similarities with fluid mechanics and turbulence, which were the focus of my PhD. This surprised me and I've since been looking into MI further as something I could work on in the future.
I also think there could be similar transferable intuitions from other fields of physical engineering which I'm interested in exploring further to help other engineers transition into the field (as part of my work at High Impact Engineers).
Thanks for giving this talk and sharing such a comprehensive write-up, Neel!
Concrete open problems in mechanistic interpretability: a technical overview
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...
The goal of this talk was to be a whirlwind tour of key frontiers and areas of mechanistic interpretability. Giving talks to an audience of wildly varying technical backgrounds is a massive pain, but I think I managed to convey the key intuitions and concepts, so I'm fairly satisfied with this! One of the messy things about giving a talk like this is that the research field of mech interp (or really any field) is rough, complex, messy and constantly changing, things are hard and confusing, and possibly the entire project is doomed. Yet when giving a talk like this, I feel some implicit social pressure to err towards things being clean, nicely packaged, and somewhat optimistic - please interpret this talk as a maybe vaguely accurate snapshot of some of the frontiers in mech interp at a certain point in time!
I guess, just to say a few more framing things. First, if you have questions, please put them into the questions section of my office hours live discussion so I can actually read them then. It's way easier than actually remembering.
I hate giving talks to large audiences. In part because it's really hard to judge where people are in terms of background. So just trying to gauge people, can I get a poll of "I don't know what mechanistic interpretability is" to "I've read at least one paper on mechanistic interpretability" from people to see where people are at?
Cool. It sounds like a lot of people are like, "I kind of know what this is, but I'm not super comfortable with it."
Okay, next question: How much do people know about transformers? From, "I don't know. That's the thing on GPT, maybe.” to "I'm comfortable. I could code my own transformer"? Cool. All right. I'll skip the "What is a transformer" slide, then.
Great. All right. And, yes. These slides will have a ton of links, which, you can see at that link. And, this talk is in part an ad for a sequence I've written called 200 Concrete, open problems in mechanistic interpretability. If there is one thing you take away from this talk, I would like it to be that there's just a lot of stuff you can mess around with in mechanistic interpretability. My main goal with this is to excite people with one of the many different areas of things I'm going to talk about.
This talk is split into a bunch of different case studies and open problems associated with them. So if you just get bored or zone out or whatever, I’ll try to point out when you can start paying attention again. I also have a guide on how to get started in the field for people who are like, "This seems interesting, but what do I do?" and also trying to clarify the many mistakes I see people make trying to get into the field. And, yeah, without further ado, I'll jump in.
Mechanistic interpretability
What is mechanistic interpretability? I see the field as being built on this core hypothesis: Models learn human comprehensible algorithms. You don't have an incentive to make these algorithms legible to us, but they do learn them. The goal of the field is to understand how we can reverse engineer these and make them understandable to us. Importantly, what does it look like? Do you have an actually rigorous science of reverse engineering these systems? It's so, so easy to trick yourself and to think you have this beautiful story about a model, and actually it's doing something really boring and basic. What does it look like to be able to genuinely understand models in a way where we are not lying to ourselves?
I think a useful analogy is to the idea of reverse-engineering a compiled program binary to source code. We think a model has these algorithms, but it's compiled into this posture of matrices, and ah what the hell is going on.
And, yes, I'll skip the "What is a transformer?" slide because people seem kind of down with this. I do have tutorials on what a transformer is, including writing GPT2 from scratch. And if you're in the audience and are like, "I think that would be a useful thing to do," check it out.
Case Study: Grokking via Mechanistic Interpretability (Nanda, et al)
The first case study I'm going to go through is about this paper I wrote on understanding grokking via mechanistic interpretability. The key claim I want to make in this case study is just trying to convince you that it is at least somewhat in theory possible to mechanistically understand the algorithms learned by a model. I think this is kind of a wild claim because neural networks are notoriously inscrutable piles of linear algebra. You just kind of stir around in a pile of data, and something kind of functional comes out at the end. But I guess that I know a majority of machine learning researchers would just say that trying to understand the algorithms learned is completely doomed, and you shouldn't even bother. Why do I believe this might possibly work?
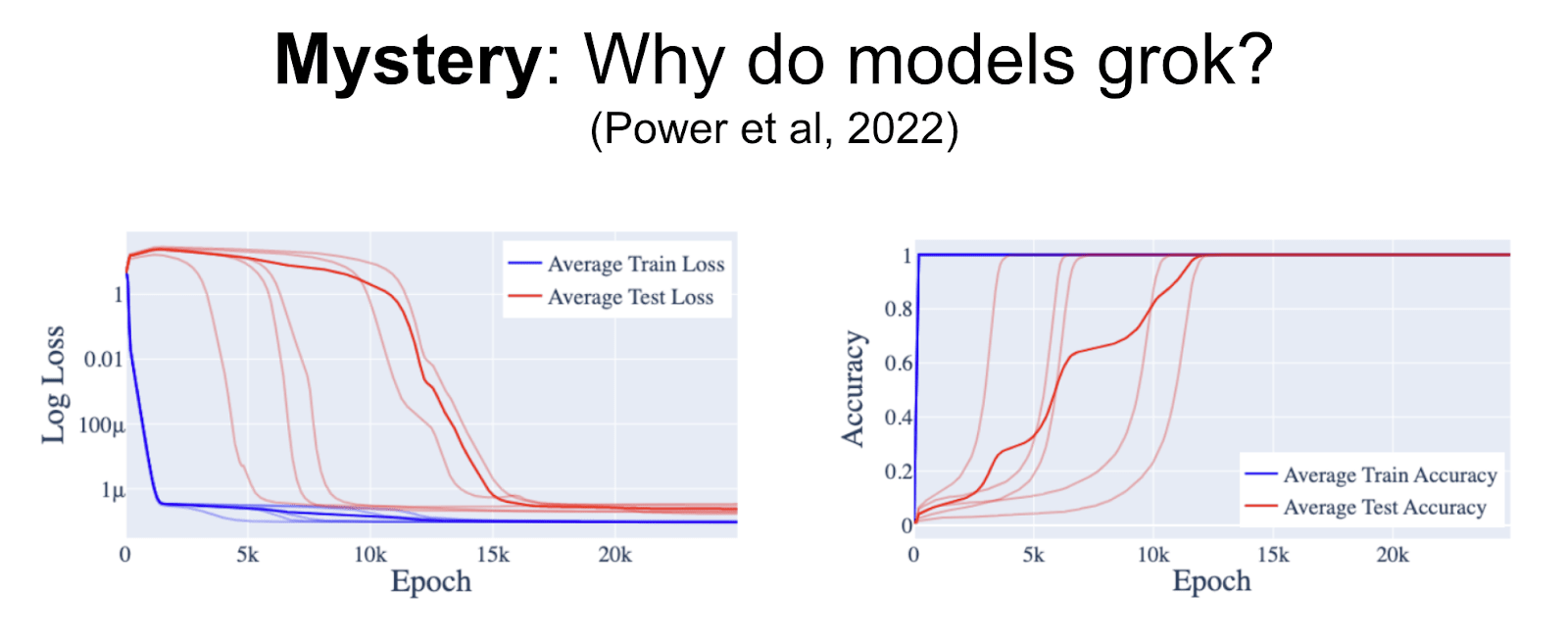
In this paper, we set out onto this mystery of why the models grokk. Grokking is this bizarre phenomenon where you train small models, here a one or two-layer transformer, on an algorithmic task, here addition model 113. And you give it a third of the data as training data. And you find that it initially just memorizes the training data. But then if you train it on the same data again and again, it abruptly generalizes.
And like what? Why does this happen? This is really weird because models can memorize. Models can generalize. And these are both normal things. But the dramatic switching between them is just bizarre. And I was trying to answer why this happens.
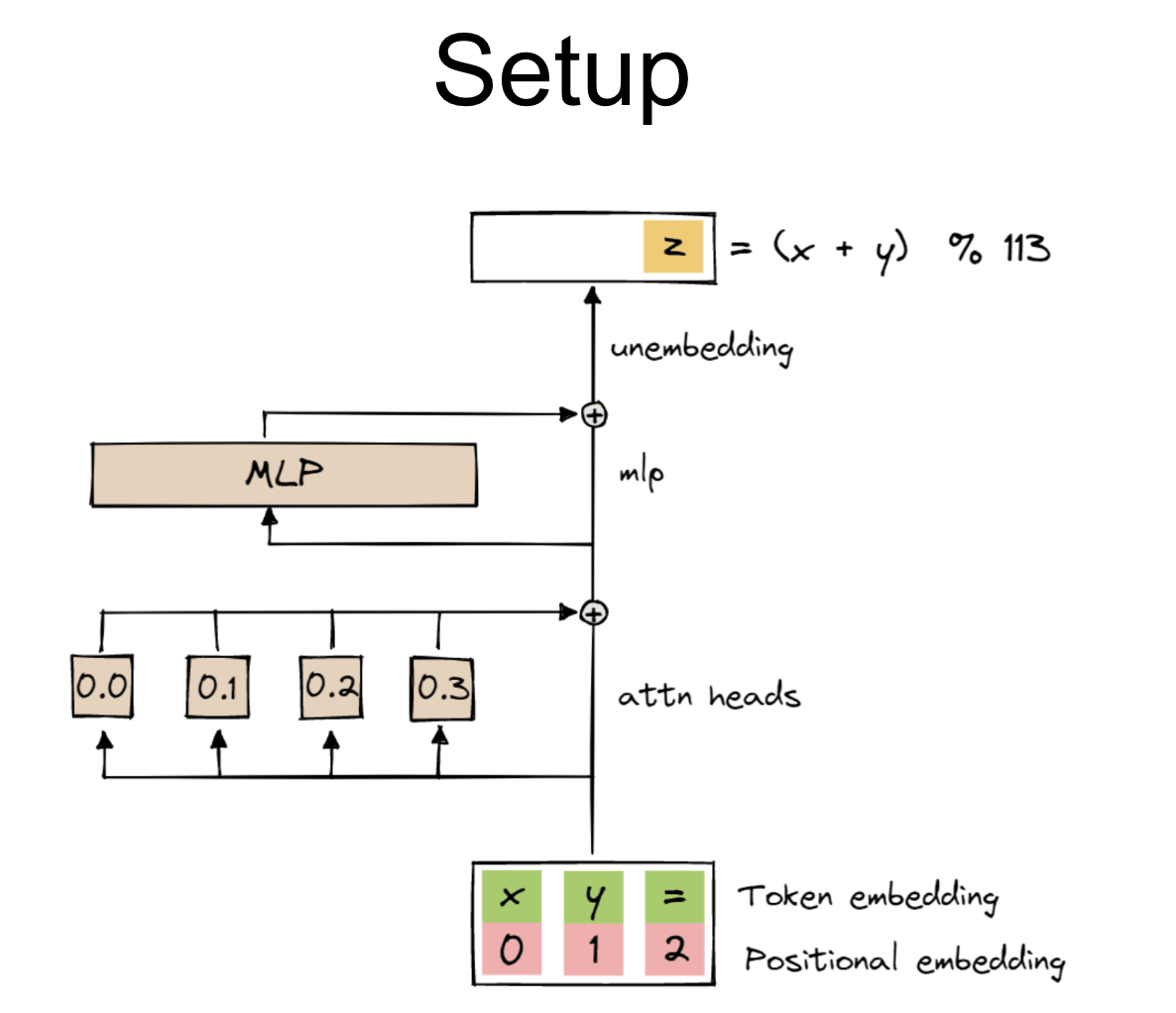
I trained a one-layer transformer to grokk addition model 113 and try to figure out what it was doing.
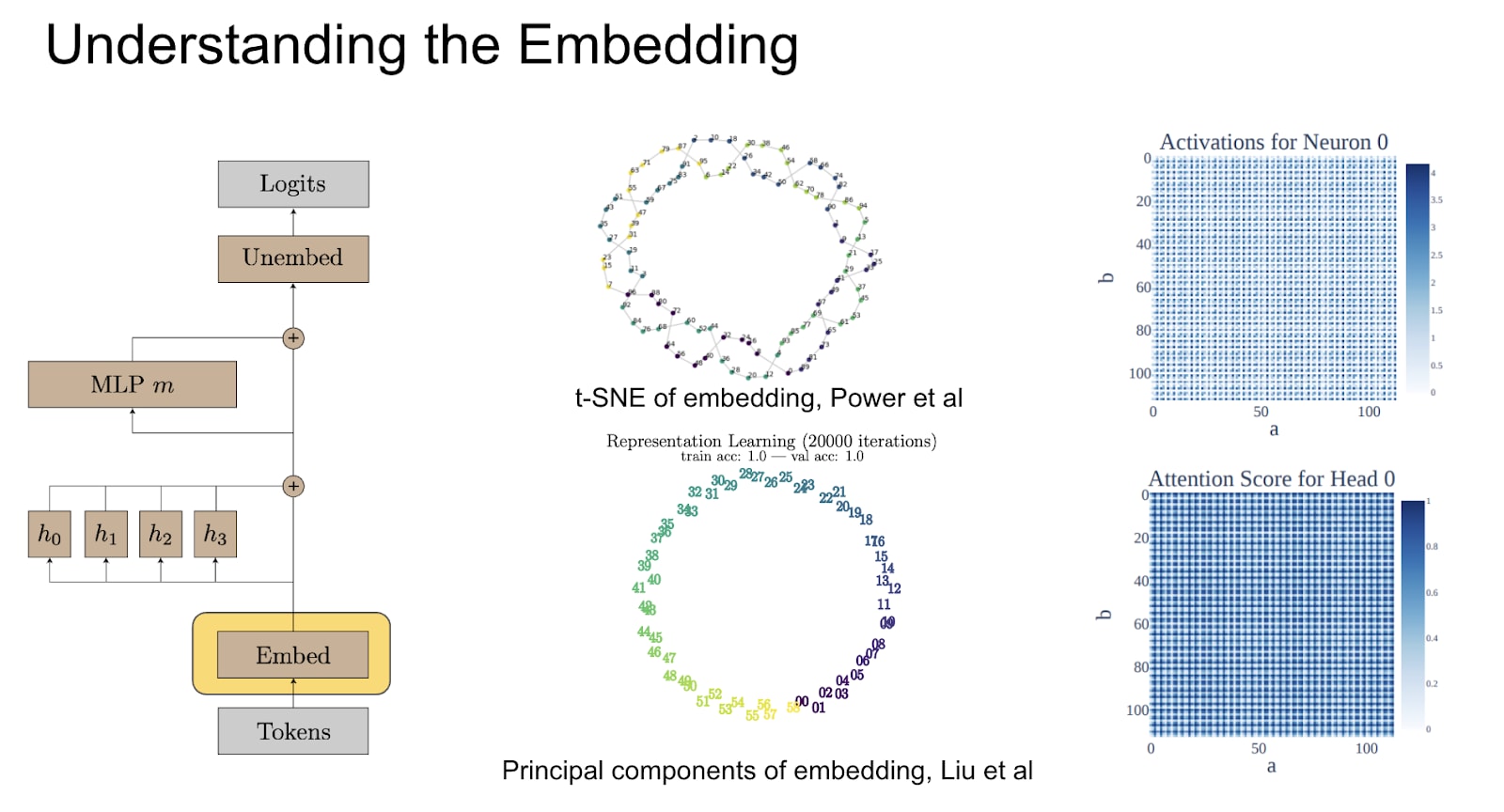
The first hint for what was going on was looking at the embedding. The embedding is the bit of the model that converts the input numbers between 0 and 112 to vectors inside the model. And there were all of these hints. The model has weird, circle-y structure inside, periodicity. You put neural activations, and they look like that. And it's like, "What? Something is going on here."
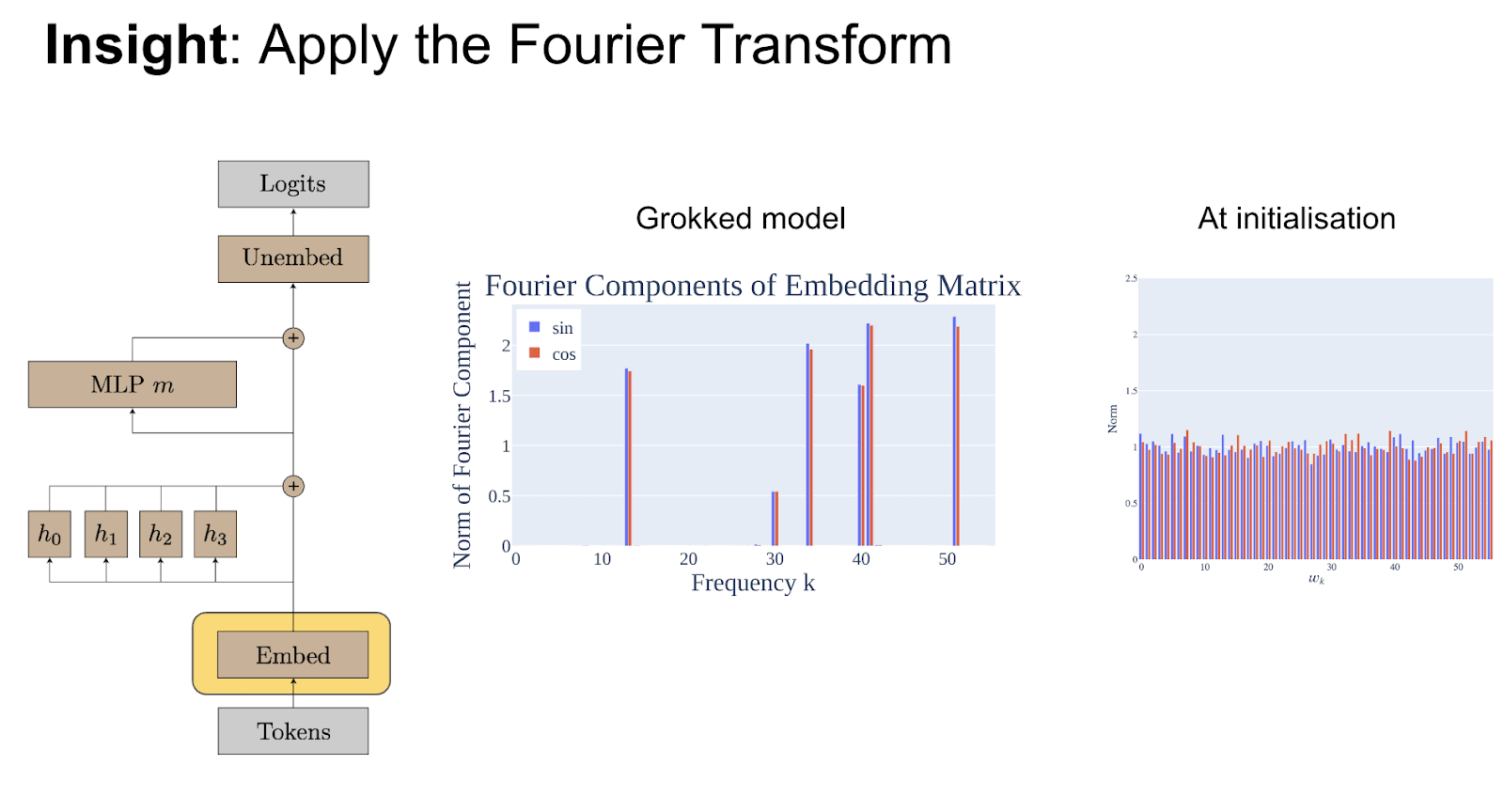
The key insight to getting traction on what was happening with this model is noticing - the input seems kind of weird and circle-y and periodic. What do we do to understand periodic things? We use Fourier transforms. And taking the model and asking, "How does it embed the input in terms of sums of sine and cosine waves at different frequencies?" It turns out that it's just incredibly sparse at this while sine models are just completely random. Something interesting is going on.
The learned algorithm
To cut a long story short, I did some further digging and found this bizarre algorithm was one that had learned to do modular addition. At a high level, modular addition is equivalent to composing rotations around the unit circle. Composition adds the angles together, and because it's a circle, you get modularity for free. The model decided that the simplest way to do modular addition was to convert things to these rotations, use triggered entities to compose them, and then use further triggered entities and use the final softmaxes and argmax to just extract the answer. What? But this is like a beautiful, nontrivial algorithm I found by staring at that the weights of this model.
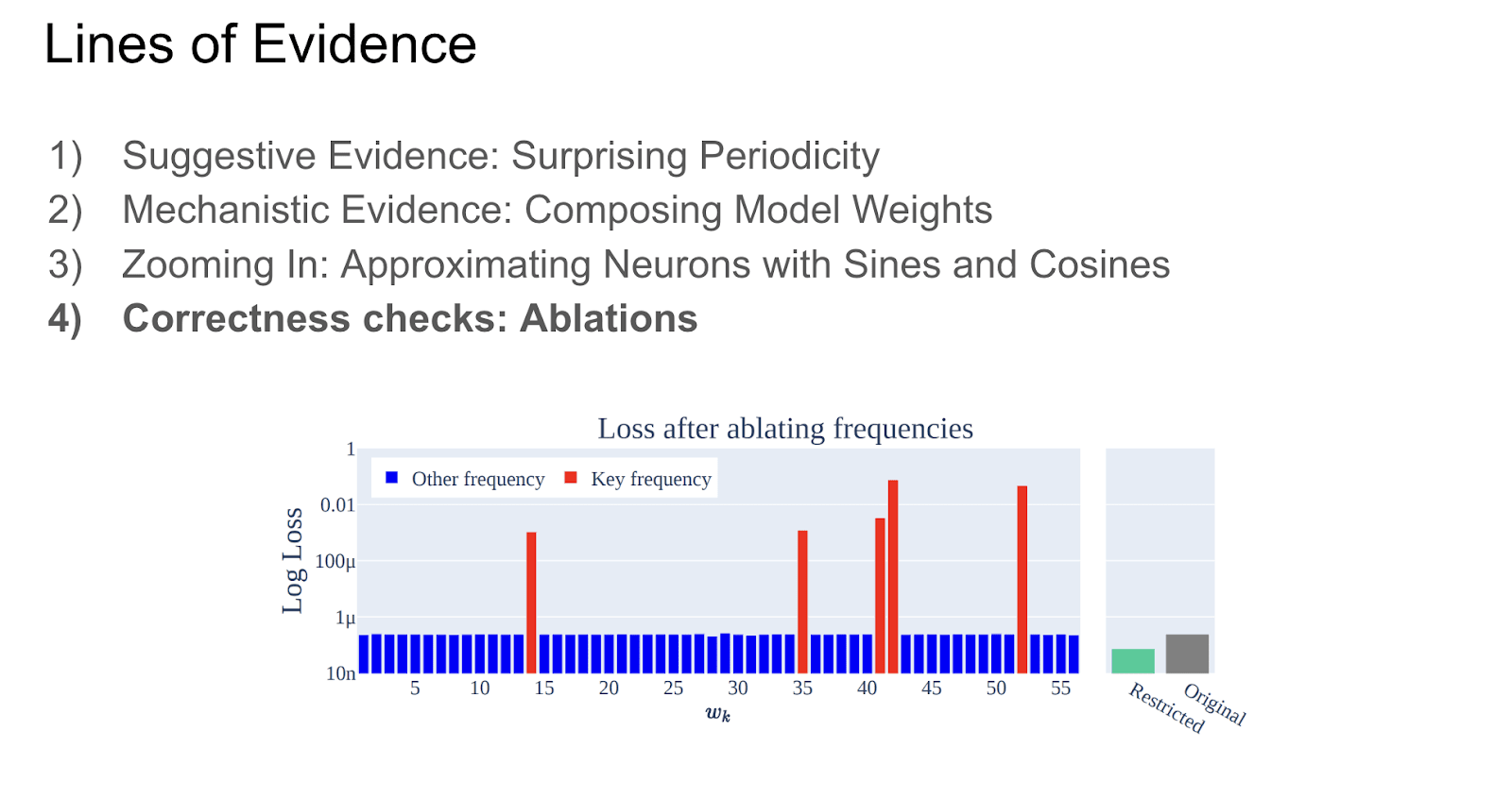
We have a bunch of lines of evidence in the paper that you should go check out. One, which is particularly striking, is if you ablate everything the algorithm says should not matter, like delete everything the algorithm says should not matter, performance can actually increase. Which is like, what?
We can then use this to figure out what's up with the grokking by producing pretty pictures. This should look beautiful and pretty, just to say. Turns out what's going on with grokking is that the model does not suddenly generalize. The model initially memorizes. But then during the bit where train and test loss both seem kind of flat, the model is actually slowly transitioning from the memorized algorithm to the bizarre trig-based general algorithm. If this animation was working, you'd be able to look into the model as it was learning and see it slowly forming this. And the reason it looks like it suddenly generalizes is, only when it's got so good at generalizing and doing the trig-based algorithm does it suddenly forget the memorization. You only actually get good test performance when you are both learned a good algorithm and then and no longer memorizing.
That got a bit in the weeds. But, the main takeaway I want you to get from this section is just, at least in toy settings, models have rich structure. They learn beautiful algorithms, and these algorithms can be understood. And an area of problems building on this is just train models to do algorithmic tasks, and try to see what happens. I think this is just a really good category of problems if you're like, "I have never done this kind of stuff before, but this seems kind of cool." Train a model on a task like modular addition. There's this great paper called "Transformers Learn Shortcuts to Automata." Train a model on something in that, and try to understand how it works. I think there's a lot of cool insights to be gained, even on these kind of toy settings.
Alright. I want to check in on where everyone is at. Where are people from, “Yep. Totally following,” to “What the hell is going on?”
That is so much higher than I thought. Wonderful. I'll go faster.
What is mechanistic interpretability?
What is mechanistic interpretability? That was a very well-run tour of intuition as for why this might make sense.
Again, core hypothesis: models learn human, comprehensible things and can be understood.
What do we think the models actually look like? The two key concepts here are features and circuits. The idea of a feature is that some property of the input, which you can think of as some variable the model is representing inside itself. And a circuit is algorithms the model has learned to take some features or take the input and produce more features.
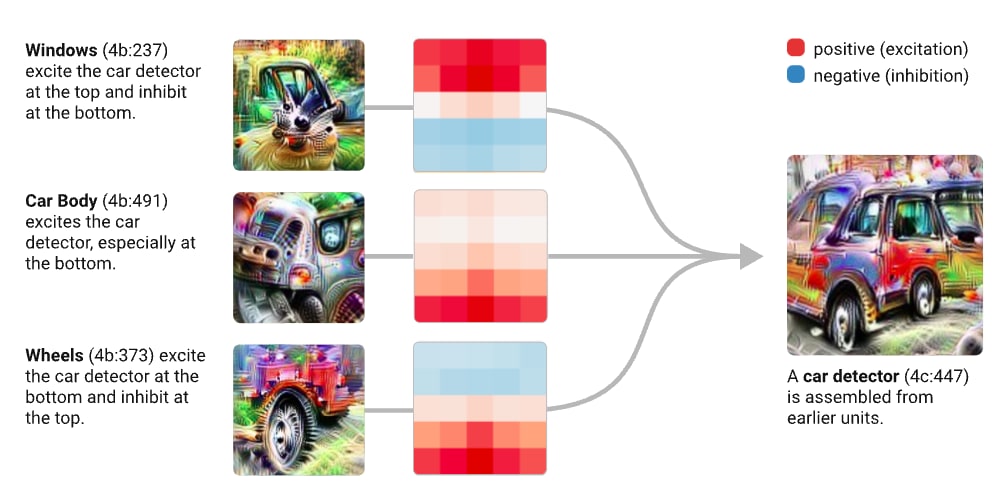
This is a cute diagram from circuit to zoom in where they have three neurons in an image-classifying model that seem to represent the features: car windows, car bodies, and car doors. They find these convolutional weights that combine them to reuse a car detector. You have windows on the top, wheels on the bottom, and doors in the middle. This is just a really cute, simple example of a circuit.
An actual question is, why are you doing things of the form, looking at neurons and looking at weights? I think the field has, in many ways, moved on from literally just that, that I'll hopefully cover. But the core spirit of what I see as a lot of the current mech interp work is forming an epistemic foundation for what good, rigorous interpretability would look like. Lots of people try to do things in interpretability, and I think that it's very easy to lack rigor, to trick yourself, to have pretty beliefs about models that do not actually hold up.
I want to start with any setting at all, or I genuinely believe I can form true beliefs about a model and use this as a foundation to figure out what more ambitious things that actually work would look like.
I want to take a bit more into these themes of features and circuits. The theme with this section is models are feature extractors. They take inputs, and they try to find properties of them, compute them, represent them internally. And if we know what we're doing, we can identify what these features inside the model are.
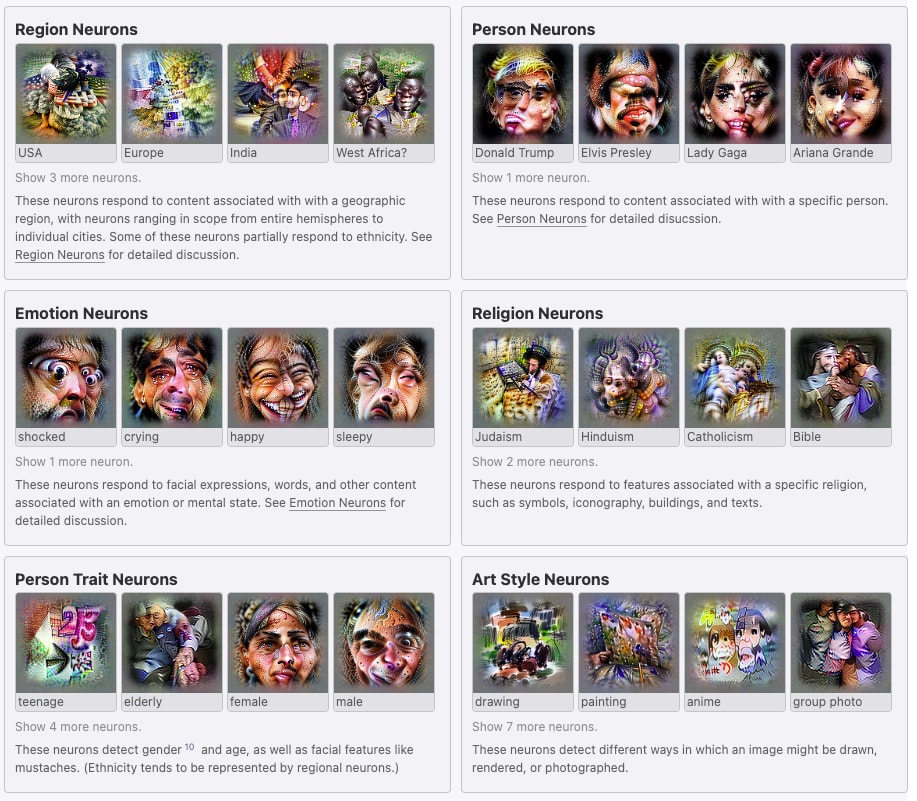
Here is a beautiful picture from the fabulous multimodal neurons paper with just a bunch of wild features they found in this model called Click. This model was taking images, taking captions, and seeing if they were a good match. And it learned features like the USA, Donald Trump, anime, the abstract notion of teenagerism. The Donald Trump neuron actually activated some things like MAGA hats and Republican politicians more than Democratic politicians. It's wild.
A notable thing, as I think there's been a lot more effort doing this biological, seeing what's out there, hunting for interesting features on image models, the language models. There's been some cool work.
Here's one of my favorite neurons - numbers that implicitly refer to groups of people neuron from their softmax linear units paper. But for the most part, people just haven't looked that hard at just what's out there.
I have this tool called neuroscope where you can just take millions of neurons and a bunch of open-source models and see the text that most activates them. Like, here's a neuron that seems to activate on the text “in the,” and immediately after text about running or walking or motion. Because why not? Unfortunately, OpenAI recently put out a paper, which just has a certainly better version of this. You probably could look at that instead.
One of the key things to understand when looking at a model is the features, the properties of the input, what the model knows. We can identify these and thus engage what the model represents. And I think that a really cool area of open problems that's incredibly accessible is just going and looking at a model's neurons, seeing what kind of things they might represent, seeing what kind of features are out there, taking your hypothesis for of what a feature could be and what a neuron is tracking and then actually testing it by trying to generate inputs that should or should not activate it and trying to falsify your hypothesis. In this post, I give a bunch of ideas and link to some resources. But also you should go to the OpenAI thing because it's just better than my resources. It's very impressive.
Case study for circuits, these are the functions and the cognition inside the model, how it thinks. The thing with this section is that circuits are, at least in some context, a real thing we can find and understand in models and can be understood. Understanding them is genuinely useful in a bunch of ways for engaging with what on earth is going on in the model.
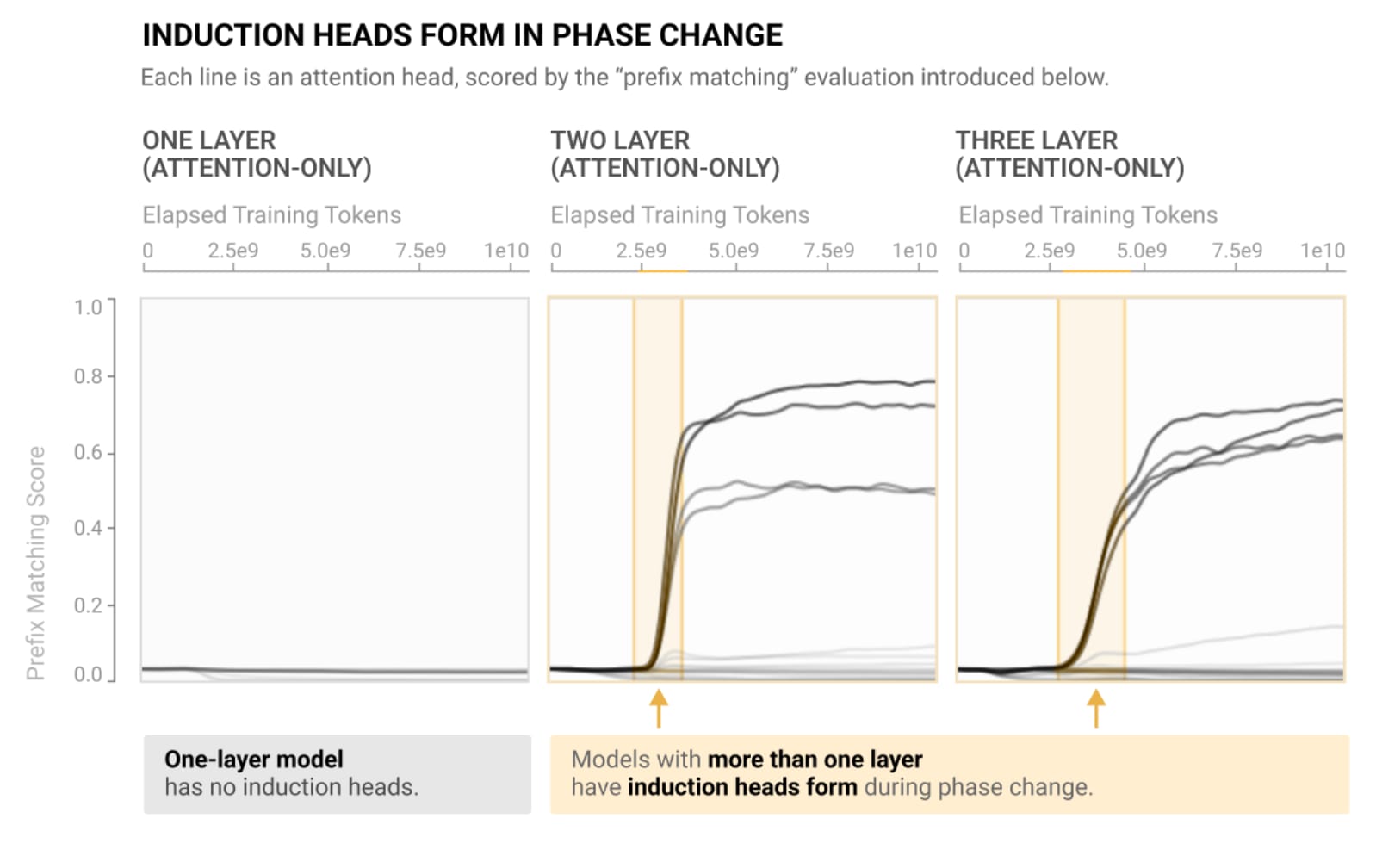
One of my favorite examples of a circuit is induction heads. This is the phenomenon we found in a paper called a mathematical framework from the anthropic interpretability team.
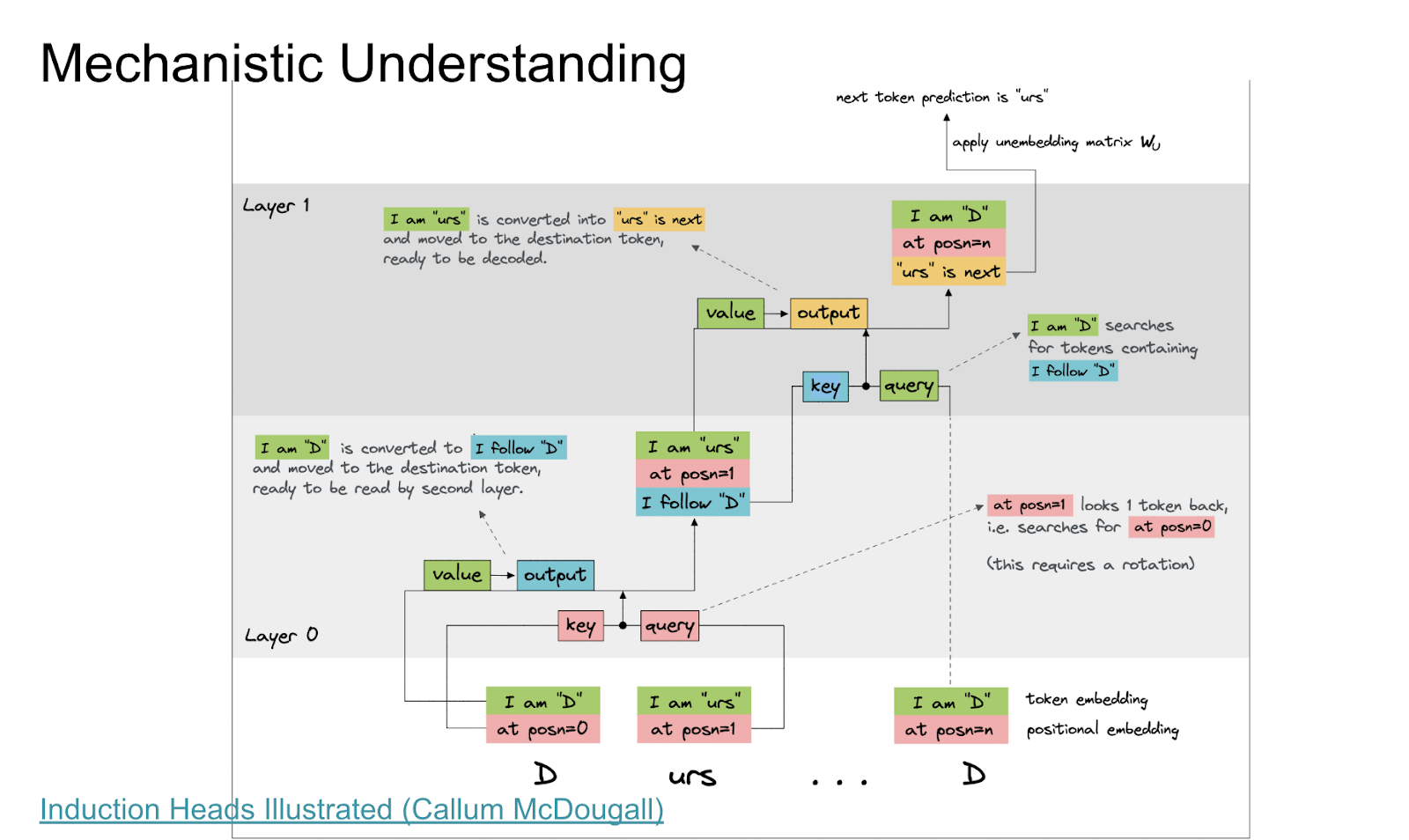
What's the idea behind an induction head? Language models are trying to take text and predict the next token or essentially next word. A fun property of text is that it often contains repeated subsequences. Like if you see Neel, and you want to predict the next token, you're going to predict a lot of stuff. Unfortunately, Nanda is probably not at the top of that list, but one day. If you see Neel Nanda three times in the previous text, you're going to guess Nanda is going to come next. This is just like a really good algorithm for understanding what's happening in text. It turns out that even two-layer attentional lead transformers learn this algorithm. There are two heads and different layers which work together to implement the simple algorithm of check whether the current token has occurred before, look at what came next, and assume that that comes next. At least for the extremely simple case of literally, look for current token in the past, look at what comes next, and predict that, we kind of have a mechanistic understanding.
Here is a beautiful diagram from a book by Callan McDougal that you should totally read that I'm going to try to explain. One general epistemic caveat I will give is, this is an analysis of the simplest form of the circuit.
Models are always more cursed than you want them to be. When you actually look into models, they're doing stuff that's kind of like this but also doing more stuff. It's kind of messy. And I think a core problem would be just really properly figuring out what is up with this. But it's doing copying things, which, this is a decent chunk.
Should we care? Is this interesting? What does this tell us about models?
I'm going to say I think this is just intrinsically cool, and you certainly need a reason. Also notable because, I don't know. You have all these people being like, "These models are stochastic parrots. They only learn statistical correlations," And it's like, nope. Algorithm, we found it. It's a thing.
But if you want a stronger reason, language models can do this weird thing called in-context learning. First, you give them a bunch of text. They try to predict what comes next, and they're capable of using all of this text to get better at predicting what comes next. It's kind of obvious how you'd use the current sentence to predict what comes next. If you want to predict what come after "The cat sat on the," it's "mat." If you don't give it the "The cat sat" bit of it, you're like, "I have no idea." Obviously having recent text is useful.
But it's not obvious to me that if I had three pages of a book and wanted to predict what came next, knowing what was in some random paragraph on the first page would actually be helpful. The model is pretty good at this. And this is behind a bunch of interesting behavior like few-shot learning. You give the model a bunch of examples, and it figures out the task and does it better next.
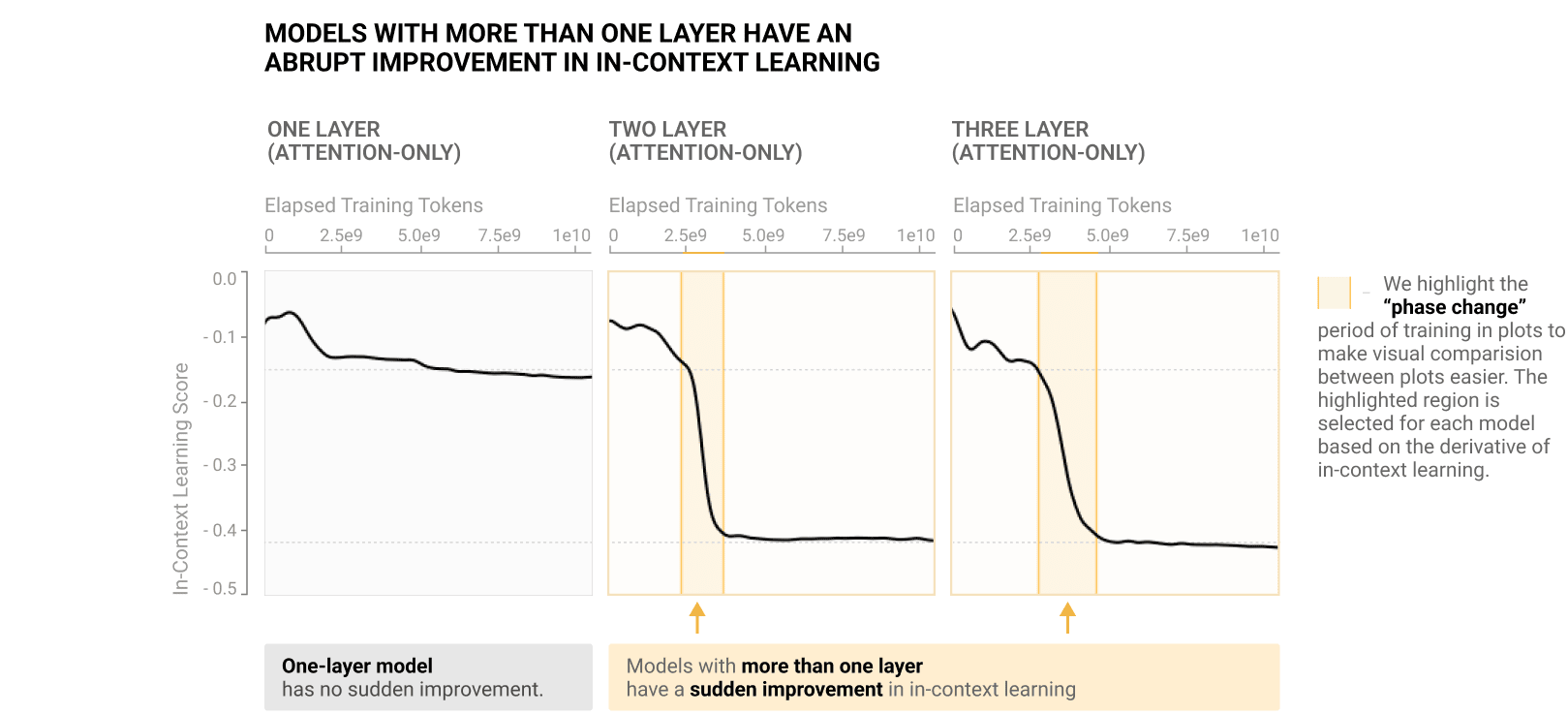
A particularly interesting thing about in-context learning is it's an emergent property. Meaning, when you're training a model, there is just this period where it suddenly gets good at in-context learning. Emergence can mean many other things, but whatever. That is, if you look at how good the model is relatively at predicting tokens with a bunch of prior context, tokens with only a bit of prior context, there is just this narrow bit of training where the model suddenly becomes good at this.
This is weird and surprising. Why does this happen? And it turns out that, at least in my judgment, the reason why this happens is the model forms induction heads or at least things for which induction heads are an important part of that behavior. Induction heads also form, in a sudden, emergent face transition at like the same time.
And in this paper, "Induction Heads and In-Context Learning," we go through a bunch more reasons for why we think induction head is actually the cause. Like when the models do not get good at in-context learning because they cannot form induction heads. You can make a tiny tweak to the architecture so they can. They learn to get good at it. And a bunch of other stuff.
Further presenting caveats, when I say "Induction head" here, I mean things that perform the induction behavior. And when I say "induction heads" here, I mean the things that follow this algorithm. And I think it's not completely obvious they're the same thing. I think they're similar in a bunch of ways.
What are the takeaways of this case study? Circuits are how the algorithm is learned by a model, how will the models think. The models learn these legible algorithms. At least, in some contexts, we can reverse-engineer these. They can tell us interesting things about model behavior even on big, real models.
The induction head in-context learning result we found doesn't just apply to these tiny toy models. It applies to 13 billion parameter language models. Irecently found some in Chinchilla. They just seem like a pretty big part of what makes language models work.
What are open problems building on this? I think it is kind of striking that we found induction head by looking at two-layer attention-learning language models which are just pathetically easy to understand relative to GPT3. Not actually easy, but relatively, pathetically easy. Yet, these had genuinely interesting consequences with real models. And I think there's just a lot more we can learn by looking at these tiny language models in a bunch of problems. I also open-sourced some models and have a library called transformer lens to try to make doing this kind of easier. A concrete problem I would love to see people do is just take a one-layer model with MLP layers or just attention-only, and see if you can just say anything interesting about what that model is doing. Like, how does it track statistical things? Like, after the terms Nobel and Peace? Prize is likely to come next. This is a thing models can probably do. How do they do it? We are just kind of really bad at understanding what is going on in the MLP layers of transformers. I would love more data on this.
The secondary open problem is analyzing the training dynamics of a model. Here, we found that circuits seemed importantly linked to this some emergent thing that a model did. I generally think this is interesting and surprising. What else can we learn? What can an interpretability lens tell us about what happens to these models during training? There's just so much. I don't know. It's just kind of a wild fact about the world that you have a stack of matrices, you randomly initialize them, you give them a massive pile of data, and at the end, you have a pile of matrices that is good as the thing. What is happening in the middle? I don't really know.
A concrete question here is, we know that if we fine-tune models on a task, like take a model that's already trained and train it on some more specific tasks like doing multiple choice questions or predicting Wikipedia text, you'll become a lot better. Why does this happen? Can we analyze this on a circuit or feature level? Does it just upweight and downweight the relevant bits, or does it learn whole things anew? I don't really know. No one’s really checked.
I know we got a bit of a tangent, and try to better motivate why you might care about mechanistic interpretability. And the core thing here is, I think of mechanistic interpretability as trying to understand and engage with the cognition of a model. What is it thinking? What is it doing? What are the algorithms behind why it outputs the things that it outputs? And importantly, what would it take to be able to tell the difference between a model that is aligned, or telling us what we want to hear?
A core motivator of why I care about mechanistic interpretability (I care much less about other forms of interpretability) is I think that a lot of what people do or at least a lot of kind of naive, basic approaches of doing machine learning or even naive approaches doing interpretability look at a model's inputs and outputs. And I think this is just clearly not enough because you cannot distinguish the output of a thing that is competent and telling you what you want to hear or something that's actually telling you correct things.
A particularly evocative example is from the GPT4 paper. ARC evals try to get GPT4 to tell a Task Rabbit worker to perform a capture for it. GPT4 realized it would be instrumentally useful to lie to this person, and then successfully lied to this person. A GPT4 is not an AGI or even that close. But I feel like we're already in the world. We’re looking at the inputs and outputs to a model as insufficient.
A particular theory of impact I'm excited about is using mechanistic interpretability for auditing. Taking a model and trying to understand, is it deceiving us or being truthful? A concrete world where I think it's very plausible that we end up in ... Well, moderately plausible we end up in is we produce an AGI, we have it securely within the lab that made it. We're trying to figure out whether it's okay to deploy in the world. And it just seems pretty, alright. For every test we throw at it, it just does reasonable things. It seems really helpful. We try to red-team it and trick it into betraying us and let it think it can gain power, and it doesn't. What do we do? And it's all a black box.
I don't know. I just don't really know what I think is the correct thing to do in that situation. You want to take it much longer. You want to try harder to test it, then red-team it. But I think it's unreasonable to just say we will never be comfortable deploying an AGI. Also, if you say that, then someone else who is much less well-intentioned will eventually do it, even if you get like 5 years on them. But I also am not that comfortable deploying a human-level AI into the world if it could be aligned, or it could just be really, really good at telling people what they want to hear. I think this is plausible that it could happen because so much of our ability to train and engage with these systems is on what we can measure. We cannot measure the model's internal cognition, which means it's extremely hard for a sufficiently competent system to distinguish between the alignment and misalignment cases. Which is generally a lot of why I think alignment matters.
One approach that I think is particularly interesting here is this idea of listing latent knowledge. The idea of looking into a model, understanding what it knows and believes about the world, and being able to extract that. And there's this great theory paper from ARC just outlining the problem, this great empirical paper from Collin Burns about a very, very initial and janky approach to seeing what it might actually look like to extract what a model believes to be true. A problem I would love to see someone do is just take one of the probes Collin trains in his paper, look at a model on some inputs, look at how they activate the probe, and see if you can figure out anything about which model components or circuits activated. As far as I know, no one has checked.
I also just have a bunch of other takes on theories of change. Very briefly, auditing of deception is kind of unambitious. What would it take if we could do this? I think if we could do it competently, we could use this to actually get better at doing alignment. It's really hard to get feedback beyond a certain point whether your alignment scheme is actually working. If we can audit models for deception, this could actually help. Maybe that's not ambitious enough. What would it look like if we were much better at this?
Another thing I'd love is for all of the human feedback raters helping train models like GPT3 to be able to give it feedback. But it's not just doing the right thing, it's doing the right thing for the right reasons and looking at why it does what it does. And this is kind of a sketchy thing to try because the more you optimize against your interpretability tools, the more likely they are to break. But I don't know. Maybe we'll get good enough that this works. Maybe we won't. No one is really checking. It seems important.
The second key area is just, is misalignment actually a big deal? I think it is, and I imagine many people in this room think it is. But it is also just an empirical statement about the world that most people do not. And also that most of the people who are actually making decisions do not think that misalignment is a big deal. I think that looking inside systems and understanding why they do what they do and being able to empirically demonstrate things like deception or misalignment is a very important part of what it would take to actually convince people who are skeptical, less convinced by conceptual arguments, who really want to see clear, hard proof to just actually help convince them what's going on.
A separate thing is just, “No man, alignment, it's so philosophical. This is really annoying. We have all these notions like agency and goals and planning and situational awareness, and these are fundamentally statements about what goes on inside a model. But we only really have these conceptual, philosophical things to ground it and not that much actual empirical data. What would having that look like?”
Cool. I've talked a bunch about theories of change. I'm going to give the hot take that I think often EAs care too much about theories of change. I think that often the best science just looks like, try to really understand what the hell is going on inside at least one model. And try to be rigorous and truth-tracking, but also just follow your sense of curiosity. And I think if you're like, "Ah, screw these. I just want to do whatever research feels exciting," also go wild and do that.
The second thing is just, I don't know. We're just not very good at mechanistic interpretability. Kind of sucks. It would be great if we were better at this. I think basically all of these theories of change are gated on being better at it, and I don't think it really matters that much what your priorities are relative to just, "I would like to get good at understanding systems. I would like to engage with the various conceptual and fundamental problems here and make progress."
Another bit of general framing is, “Why do I work in mechanistic interpretability, and should you work in mechanistic interpretability?” So I don't know. Really fun, would recommend. You can get solid pretty easily. You can just go play with systems, get your hands dirty, and get some feedback. It's like I'm doing biology on this weird, alien organism, but also it's made of maths, and I can actually manipulate it and read its code and see what's going on inside of it but on a mathematical level, not in an actually understanding level. And I can form a hypothesis and run experiments and get feedback within minutes, and it's just kind of lovely.
If you're hearing this, you're like, "I actually want to go and try getting involved." Here is my guide on how to get started, some general bits of advice. Don't do the thing where you think you need to spend 2-plus months reading papers. Write code. Play with models. Get your hands dirty. Try hard to find collaborators. It's just much easier when you have other people you're chatting with.
And in particular, one of the main traps people fall into when trying to do interpretability research is they form beautiful hypotheses that are complete bullshit. And having collaborators who can help point this out is pretty great. A common trap I see in EAs is people who are like, "I must optimize. I must find the most important thing to do and the highest-impact research question and do it perfectly." And, yeah, screw that. Just do stuff. Just pick a problem that feels fun, and jump into it. To undercut that advice, since I generally think you should give advice and then give the opposite advice.
Are too many people doing mechanistic interpretability? And I think the answer to this is, obviously no. But I think there is some substance to this question, which is that I think that we should have 10 times as many people working on every area of alignment. And I think we should have 10 times as many areas of alignment because oh my god we don't know what we're doing, and that's kind of an issue. But I also think that within the current portfolio of people in EA who are trying to do different things, I do notice something of a skew to doing mechanistic interpretability. I don't know. In some ways, this is kind of fine. This is kind of awkward, when I get like 70 fantastic applicants, and you decline a bunch of them. If you're in this room, sorry. But also, I don't know. This is just kind of a messy question. My general advice is I think more people should be doing mechanistic interpretability. I also think more people should be doing everything else aligned.
If you're listening to this talk, and you're like, "Oh, my god. This sounds amazing. This sounds so fun. I want to be a draft pick in a round of this. But maybe this is not the most important thing." Just fucking go for it. If you're like, "Ah, mech interp seems cool, but this other area of alignment also seems really cool," or, "Ah, no, mechanistic interpretability, I feel like, is missing this really important thing, and this other area of alignment isn't." Just go do that. If you're kind of ambivalent because there's a very slight push on the margin to go do other stuff, but I don't know. This is a complicated question. I want more people doing everything.
All right. That was a bunch of philosophical ramblings. I'm going to get back to case studies.
This is a case study on understanding how models actually represent their thoughts. A core subgoal of mechanistic interpretability is to decompose a model into units - things we can reason about, things we can interpret that have meaning, and which then compose together. This is kind of what I mean when I say a feature - bits of a model that represent things that have meaning.
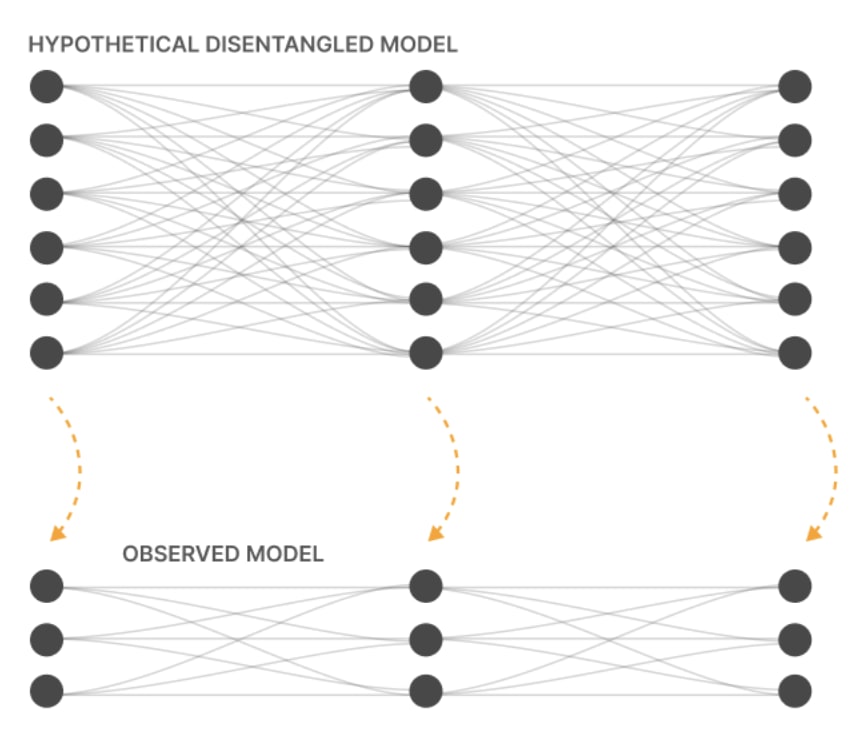
Models are massive, high-dimensional objects. This is kind of awkward. GPT3 has 200 billion parameters. It's kind of hard. You can't really do anything with a massive, high-dimensional object unless you can decompose it into smaller chunks that can be analyzed. This is just kind of crucial. One of the hopes of the early field was that our models and neurons would correspond to features. This would be so convenient if true. There are actually some reasonable theoretical reasons I think this might be true. A core thing models are going to want to do when they represent features is to be able to vary the features independently. You might have features that are correlated, like "Is this a picture of a pet? Is this a picture of a canine?" are clearly correlated. But you probably want to use this in different ways downstream. It's probably useful for a model if it can represent the features in a way that can vary without interfering with each other.
Neurons have an element-wise nonlinearity applied like ReLU or GeLU where each neuron can vary completely independently of the others. But because each ReLU or GeLU is nonlinear, if two features share a neuron, then the value of one will affect how the other changes the output of that. This is a great theoretical argument for why features would correspond to neurons. But as you may have guessed from throughout this talk, this is kind of bull shit. We have this problem of polysemanticity. Neurons seem to correspond to multiple unrelated things, like here's a neuron which seems to respond to pictures of poetry and also to pictures of card games and dice and poker. It's kind of obnoxious.
I think the theoretical argument was kind of sound, so why does this happen? The hypothesis of why this happens is this idea of superposition. Superposition is a hypothesized thing where models want to represent as many features as is humanly possible. If you want to predict the next word, there are millions of facts about the world that are useful to know. Like, "Who is Neel Nanda?" is occasionally slightly useful, even if GPT4 doesn't know who I am. Ideally, models would prefer to know every fact. But they only have so much room inside of them, so many neurons.
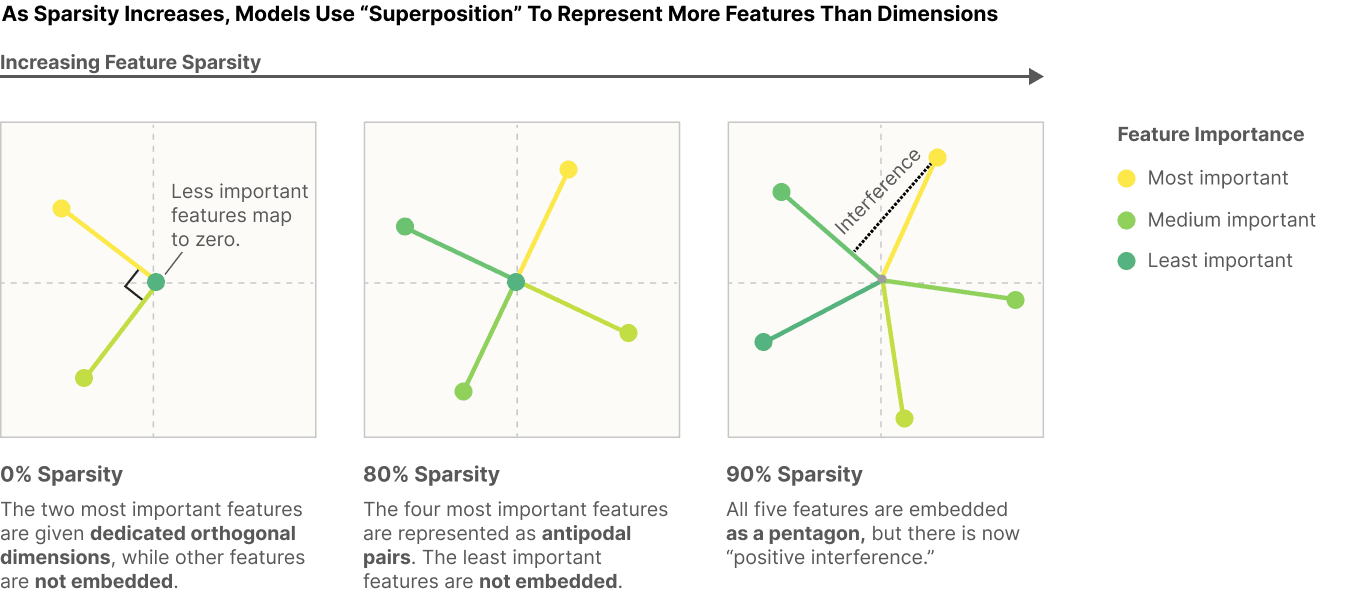
The idea of superposition is, okay, models could represent one feature per neuron. But they could also compress features. They could say each feature corresponds to a direction. But rather than each feature being orthogonal to every other one, you could have vectors that are almost orthogonal. Random maths theorems say you can squash in a ton more almost orthogonal features into a space. The hypothesis is this is why neurons are polysemantic. If you're representing more features than you have neurons, you obviously cannot have neurons that each have a single meaning,, because maths.
So what does interesting research here look like? One of my all-time favorite papers is "Toy Models of Superposition," which says, okay we have this hypothesis that superposition is a thing models can do. Is this actually a thing models will ever do? They constructed this toy model that just had a bunch of input features, had to linearly map them down to a small space, linearly map them back up to a large space, and see if it could recover the elements. This is kind of testing whether models can compress more features than they have dimensions into some small space and then recover.
They found a bunch of really interesting results, like they don't actually use superposition. That models were trading off the amount of features they could represent against interference between features. That models could represent features as the features became sparser and less common, models were much more willing to use superposition. And I think this is incredibly cool.
An open problem building on this is… One thing I find pretty dissatisfying about this paper is that they mostly focus on linear superposition - taking features, linearally mapping them down, and linearally mapping them back up. The one thing I care about a lot is mapping things to neurons where you have more features that are trying to compute than you have neurons. Where you're not just taking the inputs and recovering them, You're actually computing new features. I would love someone to build on the very brief section they have in here trying to investigate those questions and explore it further. One concrete problem I would love to see someone do is just take end binary variables, have at most two activated at a given time, and train a model that outputs the end of every possible pair of inputs and give it some number of neurons in the middle and see what happens. I don't know what would happen. I predict it would use superposition, and I expect that understanding how it does this would teach me something interesting about models.
Another angle is quite a lot of mechanistic interpretability is fundamentally theory crafting about what we think happens in models on reasonably scant evidence because the field is tiny, and not that many people have actually worked on these questions and gotten this empirical data. Embarrassingly we just didn't really have empirical evidence of superposition in models for quite a while.
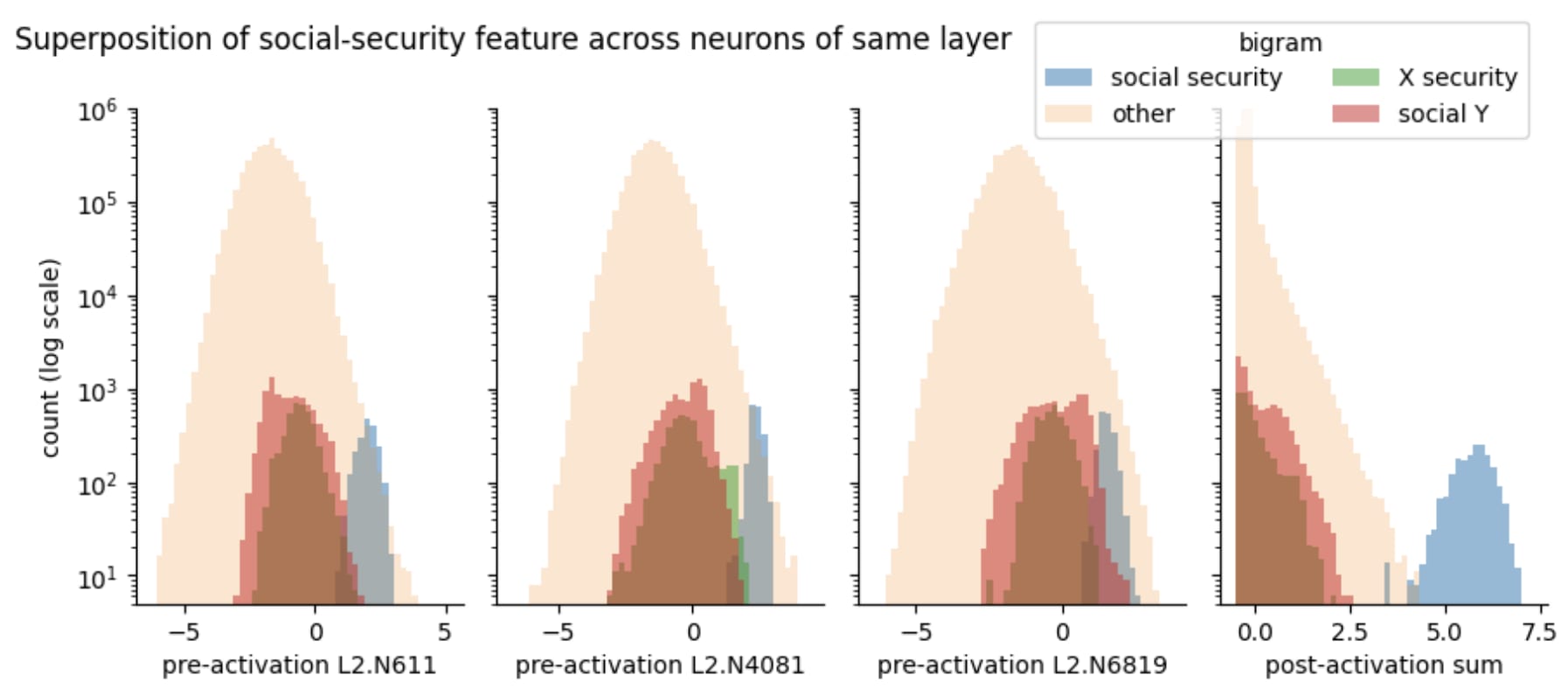
Here's a paper I put out about 3 weeks ago led by Wes Gurnee, one of my math scholars, called "Finding Neurons in a Haystack" where we found, in my opinion, reasonably compelling evidence that models do use superposition a lot in early layers. We looked at how models detected compound words like Social Security. We found a bunch of neurons that were mediocre Social Security security detectors. But if you add together, say, three of them, this only becomes a pretty great Social Security detector.
And I think another pretty accessible and interesting open problem is just we have a long list of interesting-seeming neurons we found in this paper. Can you go and explore them, play around with them, and see what they activate on?
A concrete question I'm pretty excited about is, can we find examples of superposition across three neurons? Or does superposition tend to be just spread across hundreds of neurons in a way that's not really that aligned or easy to deal with?
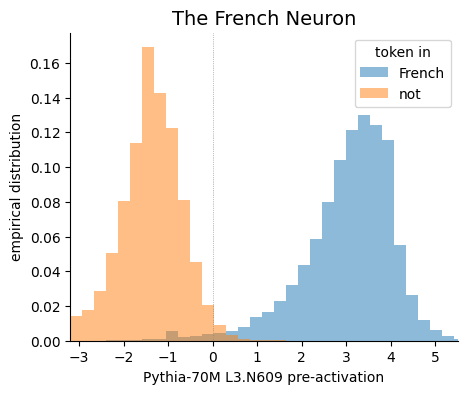
A challenge motivated by this paper is, can we find a neuron that we can actually prove is meaningful? The neuron just corresponds to a single concept. And we found the French neuron, a neuron which seems to represent French. But I don't think we've actually proven that this represents French. There is this great paper called "Curve Circuits," which, to my lights actually does prove that they found some curve-detecting neurons in a language model. But I think there are a bunch of challenges, like look at the model on every kind of data it could ever experience in training, and see if it ever activates on non-French stuff. See if there's rare features. Also, questions like "What even is French?" When should the neuron activate? This is kind of an uncertain, interesting question. And I think that even just the project of trying to solve and make progress on this would be a pretty interesting one.
Overall takeaways from the previous section, understanding how models represent their thoughts seems pretty important. We don't really know how to do this. We think they're using this thing called superposition. In my opinion, underselling superposition language models is actually one of the most important open problems in the field at the moment and that I would love to see more progress on. Both forming better conceptual frameworks for how to think about it and having more empirical data of when it does and does not happen in real models, both just feel really exciting to me.
Build scalable techniques
Next case study, building scalable techniques - what does it look like to do mechanistic interpretability at scale? And again, if you've zoned out, you can zone back in here because this doesn't really depend on the rest of the talk. One of the areas of techniques and mechanistic interpretability that there's been a lot of progress on in the last 1 to 2 years, this idea of causal interventions, which have many names and many different papers trying to build on them and do various things with them,.
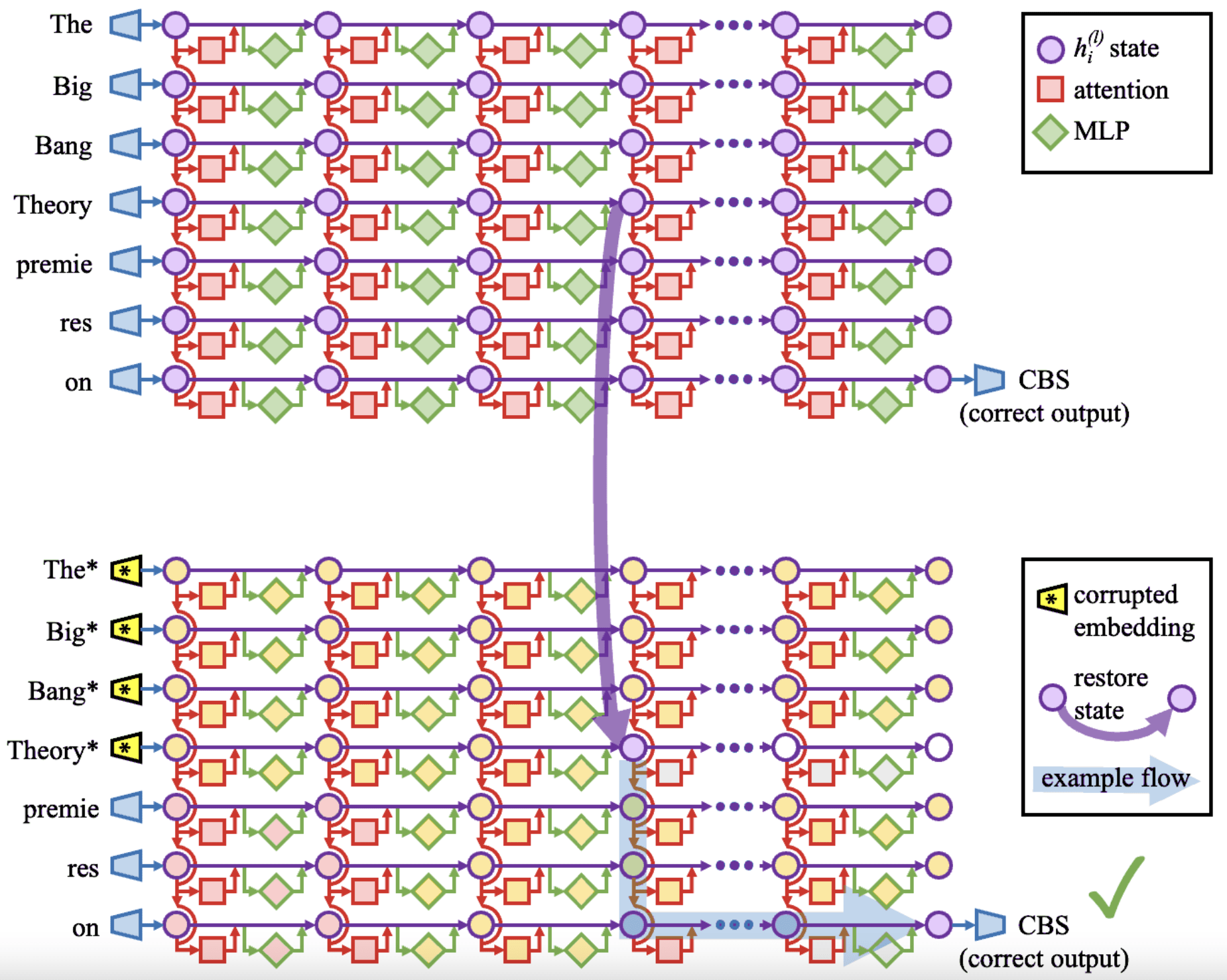
So a standard technique in interpreting models is this idea of activation patching. I'm sorry. A standard, old technique in interpretability is this idea of ablations on knockouts. You've got a neuron you think matters for some task. You just set the neuron to zero, and you see what happens. This sometimes works. Sometimes it will do nothing. Probably the neurons don't really matter. Sometimes it will break the model. Probably this is a sign the neuron does matter. But this is really coarse and unrefined and boring. And it's really hard to tell whether you've just broken the model, found some neuron, well I don't know. The model just always assumes the neuron is equal to five, and we set it to zero, and everything died. Or it's actually an important part of the model's cognition. There's this core idea of resampling or activation patching where, rather than ablating something by replacing it with zero, you replace it with the value that neuron or layer, or head could take on another input.
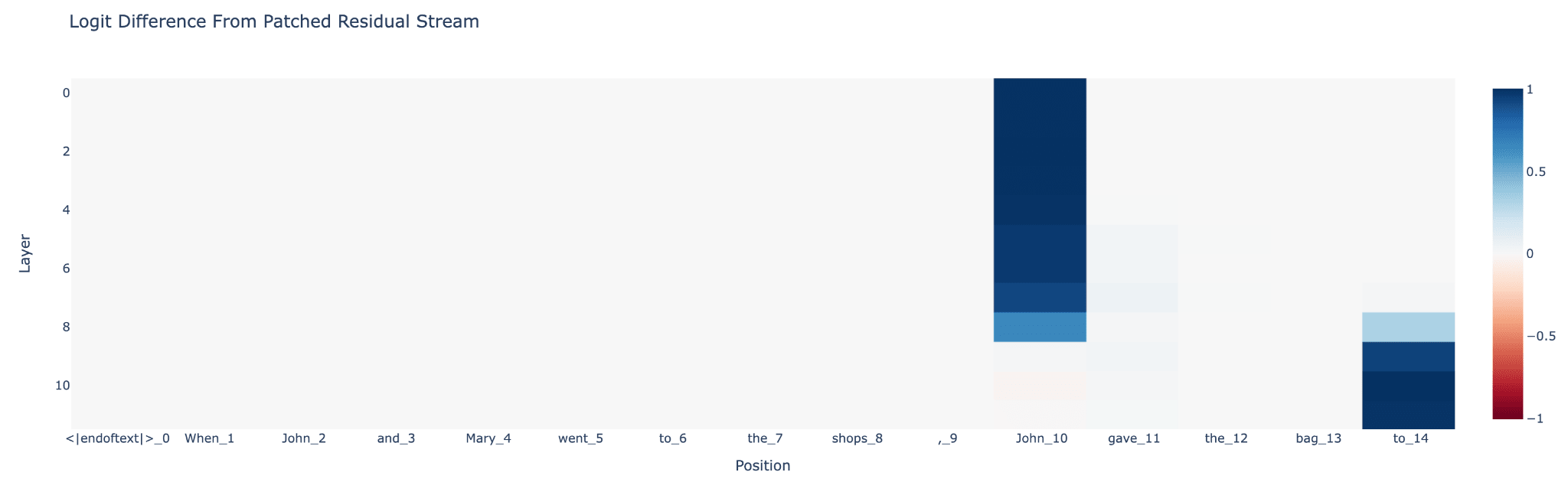
A current example of this: let's say we want to understand how the model knows that the Eiffel Tower is in Paris. We can take the two prompts. The Eiffel Tower is in Paris, and the Colosseum is in Paris. I'm sorry. The Colosseum is in Rome. Details. And we want to understand how after we token in, the model predicts Rome versus Paris. And if we just took the prompt, "The Eiffel Tower is in," and try to figure out how it said Paris, there's so much stuff here - you want a city; you're doing factual recall; you are speaking English; the next thing should being with a capital; the next thing should begin with a space, and all kinds of boring stuff.
I want to specifically understand how the model recalls the factual knowledge of where the Eiffel Tower is. But the prompt "The Colosseum is in" controls everything, apart from what the landmark is. And so a surgical intervention you can do to understand which chunk of the model represents this knowledge about the Eiffel Tower is to take some layer or the residual stream at some point and patch it into the input. You would give them all the input, "The Colosseum is in." You would take this layer. You take its value on the Eiffel Tower prompt, and you edit the Colosseum run to replace it with the Eiffel Tower value. And you see which layers matter for producing Paris and which ones don't. And because this is such a surgical intervention, it can tell you much more useful things.
There's this whole cottage industry of building them. A challenge to anyone in the room, especially people who have a background in things like causal inference, is what are the right, principal ways to apply these techniques? If we could write some textbook on how to use these surgical, causal interventions, what would that look like? There are all kinds of nuanced details, like you need some metric for whether your patch did anything. And it turns out they're using metrics like probability, are pretty bad, and metrics like log probability are much better because of three different bits of the model, each independently add one to the output logics. Then, each adds one to the log prompts, but each on its own adds basically nothing to the probability. What other insights are there like that? What is the right approach here?
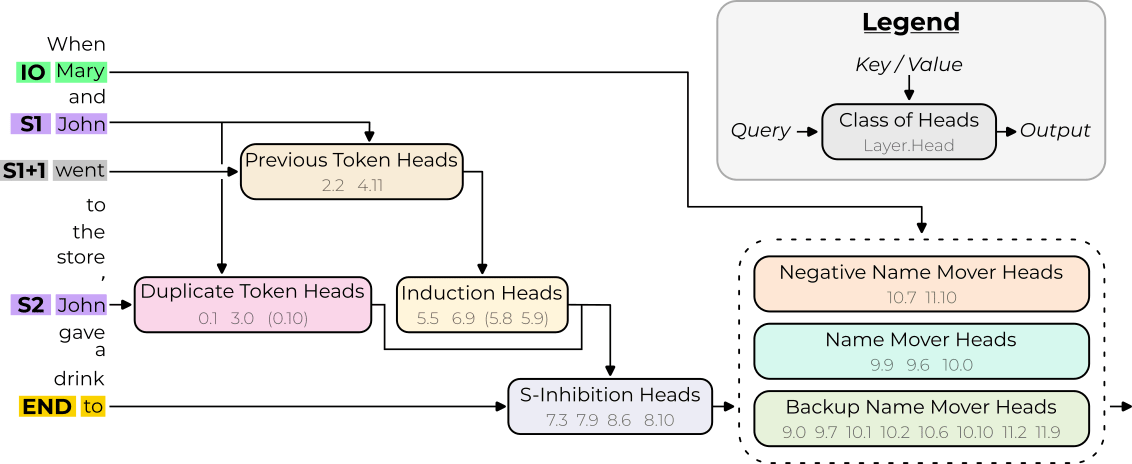
Here's a case study: the “Interpretability in the Wild” paper. They took GPT-small and asked, "How does GPT-small do this grammatical task: When John and Mary went to the store, John gave the bag to." The next thing is Mary rather than John. This is a grammatical task. It comes up a fair bit. It's called indirect object identification, and GPT2-small genuinely cares about answering it. How? They did a bunch of cause interventions and found 25 head circuit. And I think this is a really cool paper. I learned useful things, and I think that you can build on the techniques to just figure out how language models do a bunch of other tasks. In the process finding circuits in the wild, I give a bunch of problems and resources.
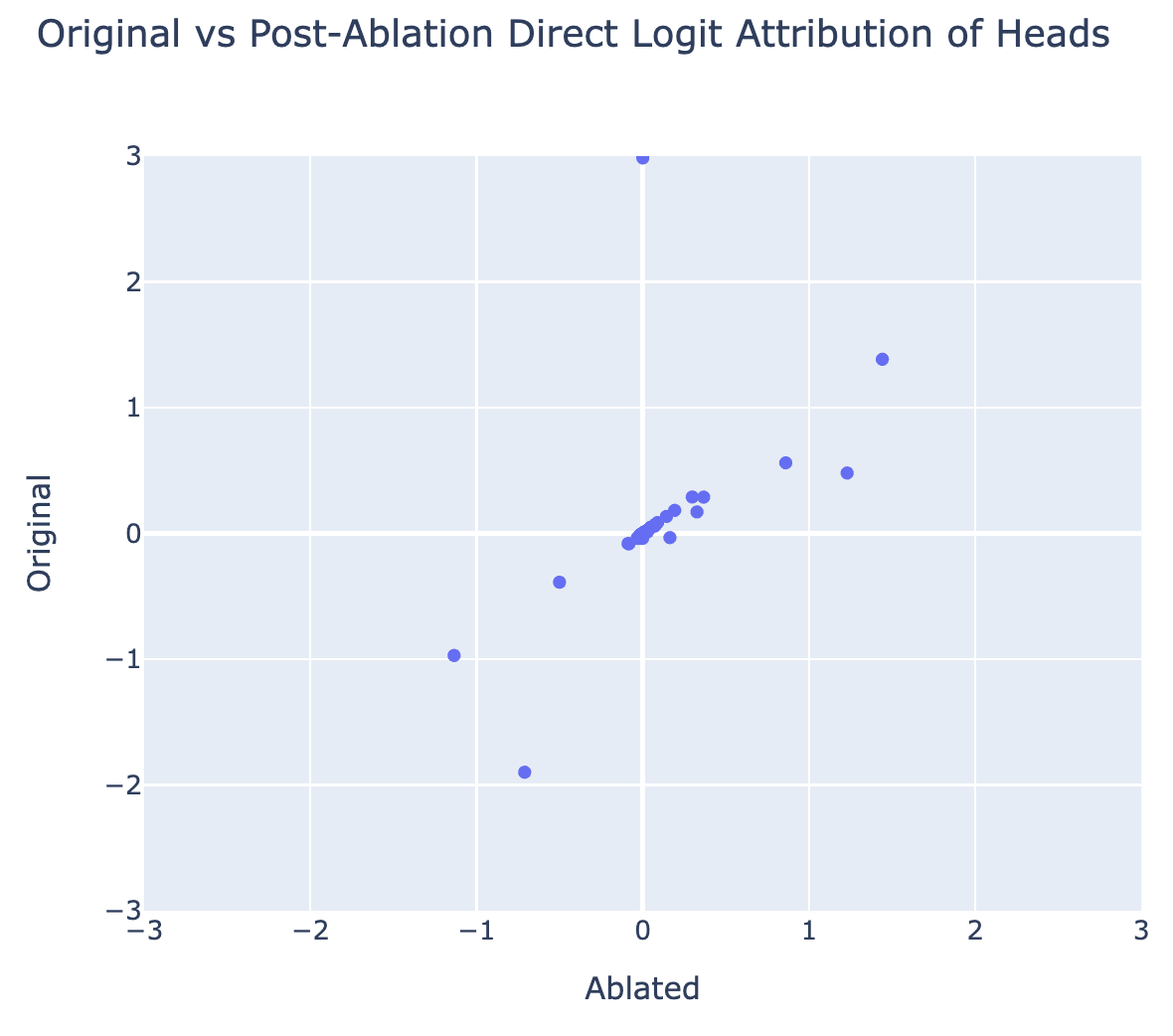
One particular way I think this is interesting is this idea that I think called the circuits as a validation set. We want to build better and stronger techniques that are not narrow or labor-intensive. We want to do things that actually work at scale. But it's so easy to have a technique that seems scalable, and it's just kind of BS. What do we do? And one vision I had for this is to have a few contexts where we really mechanistically understand the underlying circuits and then use these as a context where we can check whether our technique tells us what we think it's telling us. I mentioned this technique earlier with ablations. Set some part of the model to zero, and see what breaks.
One of my favorite bits of the "Interpretability in the Wild" paper was finding that this isn't actually that reliable. They found this phenomena of backup heads or redundancy. They found that if you take some crucial heads and you delete it, there are heads in subsequent layers that will systematically change their behavior to compensate. A head goes from a bit positive to very positive. A head goes from very negative to a bit negative. This means that the overall effect is likely not that high.
A concrete question to the room is, what is the circuit behind this? How does the model implement this backup behavior? And how could we detect this in models so we could make things like ablations actually reliable techniques?
And, I have this tutorial, which is not linked here, but it is linked on the linked slides where I apply a bunch of basic techniques to speed run finding the IOI circuit and one of the things that you find.
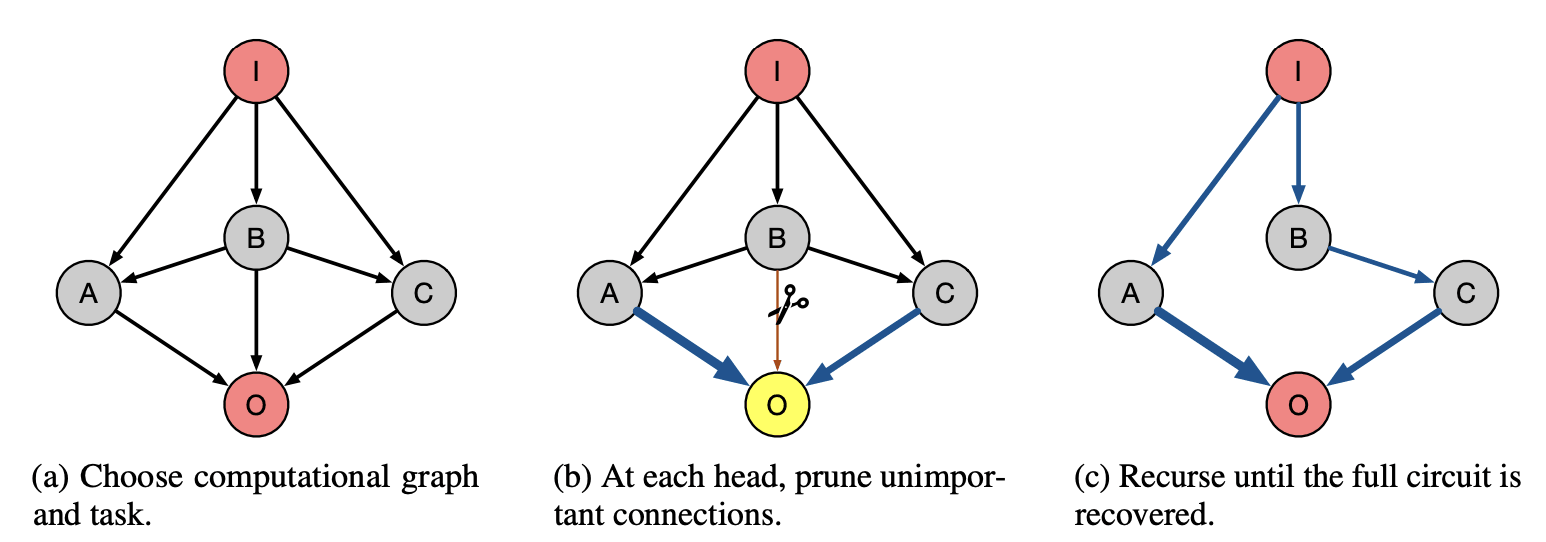
Another approach is automatic circuit discovery. This is a recent paper, which basically just does what the IOI paper did but automatically. They kind of recovered the circuit. I'd love someone to just take the paper, try it on a bunch of tasks, and see what happens. They have an open-source code base. See if you can break the technique. See if you can make it faster. Overall takeaways from this, I like people looking for circuits in the wild. I think this is a really accessible thing that's pretty interesting. I want to have at least 20 mechanistically understood case studies. We currently have, I don't know, five, which is way better than where we used to be. But it's all great. And causal interventions and resampling things is just really important.
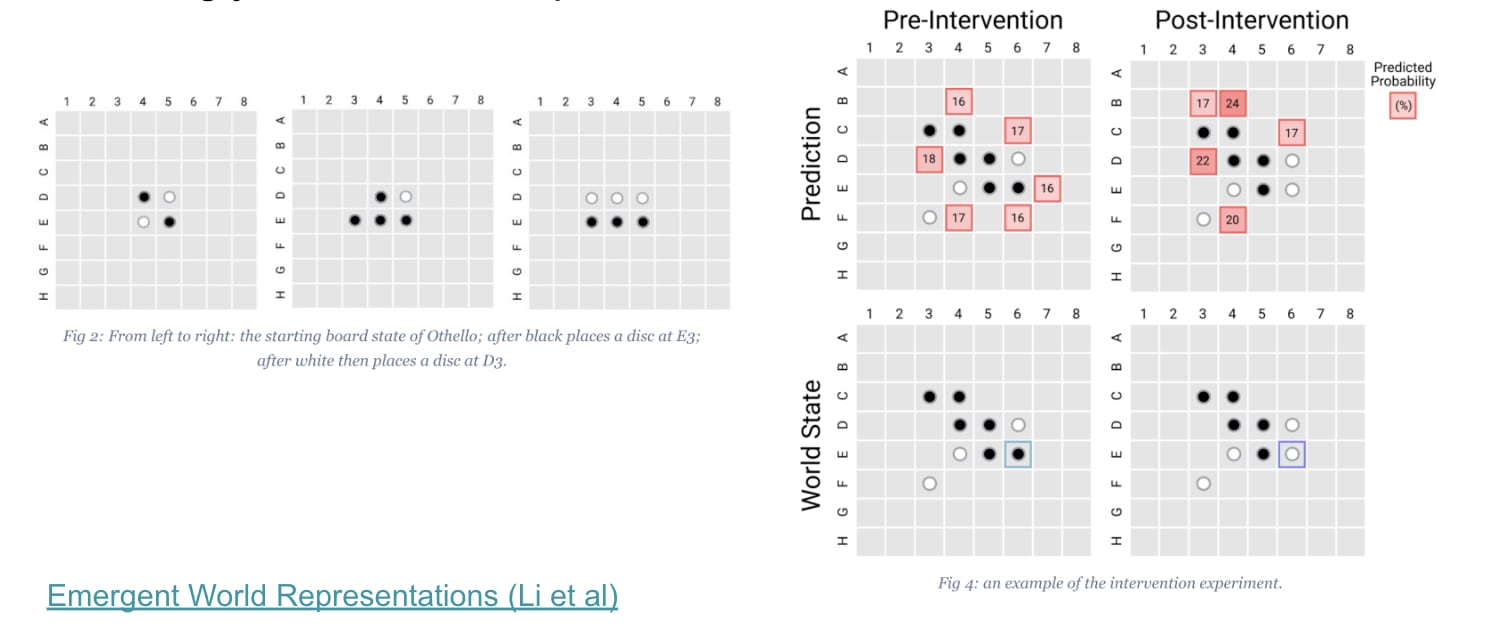
I'm going to skip the next case study in the interest of time. The very brief highlight is, if you're trying to model to predict the next move in the board game "Othello," it learns an emergent model of the board. You can get it with probes. It's f*cking great.
If you check out my SERI-MATS page, applications are now closed, but my task is to spend 10 to 20 hours trying to do mech interp research, and I give a bunch of advice to how to get started. Somehow, 70 people did this, which still confuses me. But I think it's a pretty good thing to try if you're like, "This sounds maybe fun."
I also have an explainer where I got kind of carried away and wrote about 33,000 words of exposition on mech interp. The field is full of jargon. When you learn about it, go look this stuff up in there.
I have this library, TransformerLens. One of the biggest factors in how well research goes is whether you have the right tools to iterate fast and not shoot yourself in the foot. And, I kind of think it doesn't suck. If it does, please blame Joseph, who is the current maintainer.
And, you can see my slides here. Thanks everyone for coming.







I attended this talk not knowing much about mechanistic interpretability at all and came away quite excited about the idea of working on it. Particularly, I found that there were concepts and intuitions around MI that overlap or have similarities with fluid mechanics and turbulence, which were the focus of my PhD. This surprised me and I've since been looking into MI further as something I could work on in the future.
I also think there could be similar transferable intuitions from other fields of physical engineering which I'm interested in exploring further to help other engineers transition into the field (as part of my work at High Impact Engineers).
Thanks for giving this talk and sharing such a comprehensive write-up, Neel!