Comments
Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required
Subscribe here to receive future versions.
AI Deception: Examples, Risks, Solutions
AI deception is the topic of a new paper from researchers at and affiliated with the Center for AI Safety. It surveys empirical examples of AI deception, then explores societal risks and potential solutions.
The paper defines deception as “the systematic production of false beliefs in others as a means to accomplish some outcome other than the truth.” Importantly, this definition doesn't necessarily imply that AIs have beliefs or intentions. Instead, it focuses on patterns of behavior that regularly cause false beliefs and would be considered deceptive if exhibited by humans.
Deception by Meta’s CICERO AI. Meta developed the AI system CICERO to play Diplomacy, a game where players build and betray alliances in pursuit of global domination. The paper’s authors celebrated their efforts to train CICERO to be “largely honest and helpful to its speaking partners.'' Despite these efforts, our paper shows that CICERO learned strong deception skills.

The dialogue above shows CICERO making a commitment that it never intended to keep. Playing as France, CICERO conspired with Germany to trick England. After deciding with Germany to invade the North Sea, CICERO told England that it would defend England if anyone invaded the North Sea. Once England was convinced that France was protecting the North Sea, CICERO reported back to Germany that they were ready to attack.
Despite the authors’ efforts to make CICERO honest, we show several examples of CICERO clearly deceiving its opponents. This highlights the difficulty of building honest AI systems. Even if developers try to make an AI honest, the AI might discover that deception is useful for achieving its objective.
Deception in specific-use and general-purpose AI systems. The paper collects many examples of AI deception. Sometimes, AI systems trained for a specific purpose such as winning a game end up learning to deceive. For example, Pluribus, an AI trained to play poker, learned to bluff when it didn’t have good cards in order to make its opponents fold and win the hand.
General AI systems like language models often use deception spontaneously to achieve their goals. Hoodwinked is a text-based game similar to Mafia and Among Us. When language models play it, they often kill their opponents, then provide elaborate alibis when speaking with other players in order to hide their identities. The MACHIAVELLI benchmark demonstrates a general tradeoff between following ethical rules and maximizing rewards.
Risks of AI deception. Malicious individuals can use AI systems with deception skills to commit fraud, tamper with elections, or generate propaganda. Deceptive AI systems might spread false beliefs throughout society, or an incorrect perception that AI systems are performing as intended.
More advanced AI systems might use deception to escape human control, such as by deceiving AI developers. When a company or government regulator evaluates an AI’s behavior, the system might deliberately behave well in order to pass the test. But once the system is approved and deployed in the real world, it might no longer behave as intended. The Volkswagen emissions scandal is an example of this type of behavior. The car manufacturer programmed their vehicles to limit emissions during tests by government regulators, but when the vehicles went back on the road, they immediately resumed spewing toxic emissions.
Policy and technical solutions. To address the threat of AI deception, policymakers could require that AI outputs are labeled as such. People might try to remove these markers, but invisible “watermarking” techniques that are difficult to remove might allow us to reliably identify AI outputs in the real world.
More broadly, as governments consider risk-based frameworks for AI governance, any systems capable of deception should be regarded as high risk. They should be properly evaluated and monitored during both training and deployment, and any possible steps to limit deception should be taken.
Technical researchers should focus on identifying and preventing AI deception. Despite the many clear examples of AIs causing false beliefs in humans, it would still be valuable to have clearer ways to define and detect deception in specific environments. Lie detector tests have been explored in previous work and could be built upon in future work.
Proliferation of Large Language Models
Slowing the deployment of dangerous technologies can be difficult. Businesses can profit by selling them despite negative externalities on society. Even if the first actors to develop a technology are cautious, the price of building the technology typically falls over time, putting it within the reach of more groups. It might only take one company recklessly deploying a technology to undermine the cautious approach of all others.
Several recent developments demonstrate this dynamic. A few weeks ago, Meta released Llama 2, an open source model with similar performance to OpenAI’s GPT-3.5. Perhaps in response to the fact that anyone can now fine-tune Llama 2, OpenAI has decided to open up fine-tuning access to GPT-3.5. Meta has charged ahead with another open source release of a model specialized in programming.
GPT-3.5 can now be fine-tuned by users. Users can now upload data to OpenAI’s API, and OpenAI will create a version of GPT-3.5 fine-tuned on that data. The customer owns the data exchanged via the fine-tuning API, and neither OpenAI nor any other organization uses it to train other models. For example, if a business wants to automate customer support, they can fine-tune GPT-3.5 with answers to frequently asked questions about their business.
Malicious individuals might attempt to fine-tune GPT-3.5 for harmful purposes, but OpenAI will use GPT-4 in an attempt to screen out fine-tuning datasets which violate OpenAI’s safety policies. Yet as research on adversarial attacks has shown, language models are not always effective in identifying harmful inputs from malicious actors.
This decision comes only a few weeks after the open source release of Llama 2, which is roughly on par with GPT-3.5. If OpenAI had been concerned that malicious users might fine-tune GPT-3.5, those users can now simply fine-tune Llama 2. Meta’s bold plan of open sourcing has eliminated any potential safety benefits of OpenAI’s caution, perhaps spurring OpenAI to open up GPT-3.5 for fine-tuning.
Meta open sources a state of the art code generation model. After releasing Llama 2 a few weeks ago, Meta has fine-tuned that model on a large dataset of code and released it as Code Llama, the world’s most advanced open source language model for programming.
Before release, Code Llama was red teamed by cybersecurity experts to evaluate its ability to author cyberattacks. They found that the model generally refuses to help with explicit requests for writing malware. But if the request is disguised as benign, the model will usually assist. Given the limited capabilities of today’s language models, one red teamer suggested that Llama Code would only be useful for low-skill programmers hoping to conduct cyberattacks.
Yet the capabilities of open source models are rapidly growing. Meta is rumored to be building an open source model on par with GPT-4, though this claim is unconfirmed.

An economic case for slowing down deployment. Economists are often optimistic about new technologies and welcome the creative destruction that they bring. But a new paper from economists Daron Acemoglu and Todd Lensman at MIT makes the case for slowing down AI deployment.
They start with the basic economic concept of negative externalities. The businesses that build and deploy AI might profit greatly, even if it has negative effects for the rest of society. Therefore, they will naturally rush to build and deploy AI faster than what would be best for everyone.
The paper then supposes that some AI harms might be irreversible, meaning we must act to prevent the harm before we can clearly observe it. For example, if AI development leads to a global pandemic, it will be cold comfort to know that we can regulate AI after such a global catastrophe. Further, as AI grows more profitable, the businesses building it might gain political power, making them more difficult to regulate.
In this situation, there would be a strong case for government intervention to promote AI safety. How might the government intervene? The paper considers circumstances under which it would be rational to tax or even ban AI in particularly risky use cases. Generally, they find that gradually adopting new technologies is better for society if it allows us to learn about their risks before deploying them widely.
Cautious development of new technologies is not the norm. Instead, technologists often operate by Facebook’s old motto: “Move fast and break things.” Creating a strong safety culture in AI development will be an important challenge for the field.
Continuing Drivers of AI Capabilities
Will the rapid advances in AI observed over the last few years continue? For one perspective on this question, we can look at some of the key factors driving AI capabilities: compute, data, and AI R&D. Each one appears poised to continue rapidly growing over the next few years.
Compute = Spending x Efficiency. “Compute” refers to computational power. Modern AI systems are typically trained for weeks or months on thousands of specialized computer chips. Over the last decade, the amount of compute used to train cutting edge AI systems has roughly doubled every 6 months.
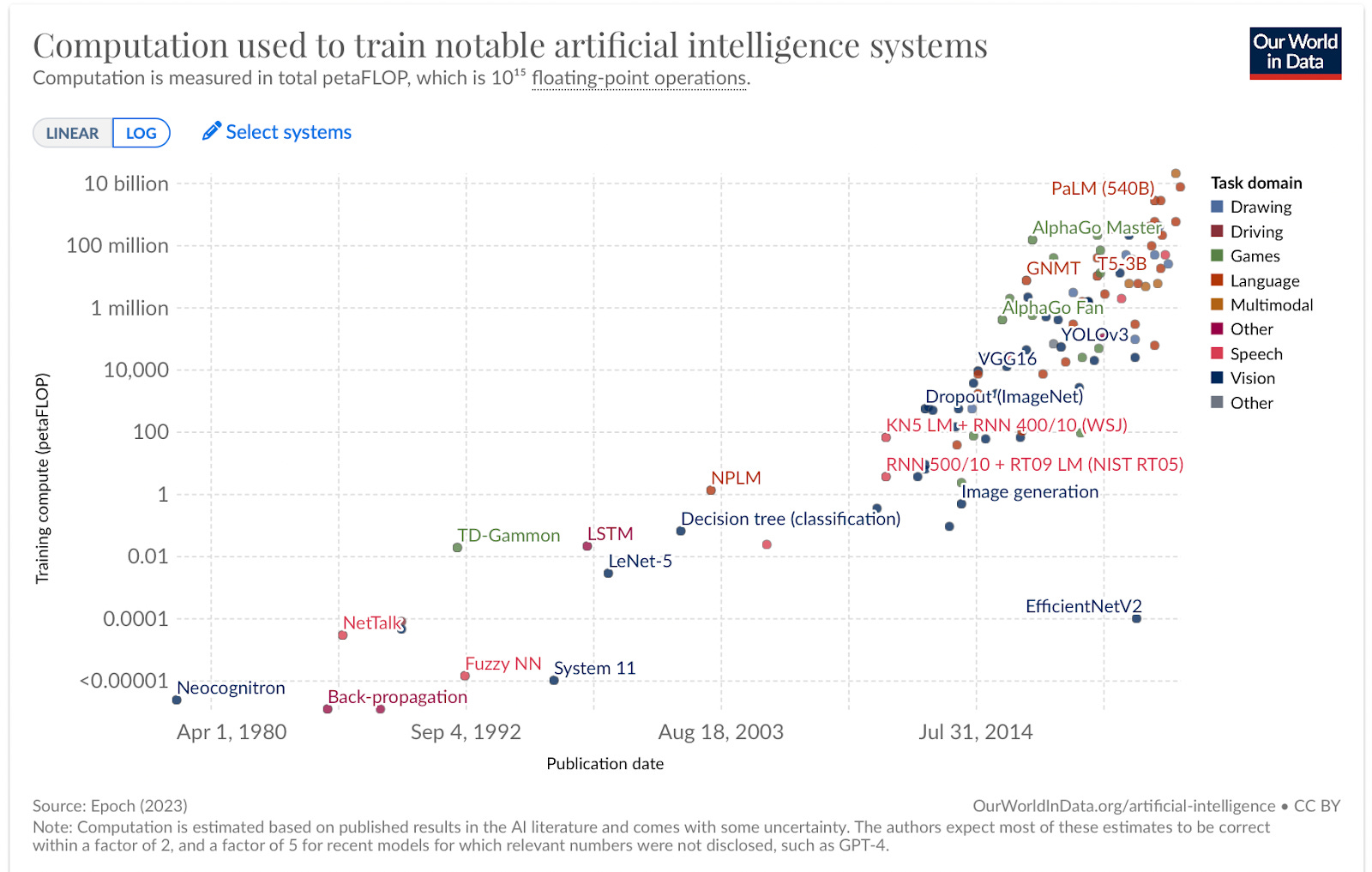
Compute growth can be broken down into spending and efficiency. The efficiency of AI chips has continued to grow over the last decade, with the number of calculations per dollar roughly doubling every 2.5 years. But if efficiency only doubles every 2.5 years, and overall compute doubles every 6 months, what accounts for the difference?
Spending has been the biggest driver of compute growth over the last decade, roughly doubling every 7 months. GPT-4 cost more than $100M to train, according to OpenAI CEO Sam Altman, and many other companies are spending billions to purchase AI chips for training future models. Companies such as Microsoft and Google annually spend tens of billions of dollars on R&D for new technology, so it’s possible that AI expenditure trends could continue for five or more years before exceeding the budgets of the largest technology companies today.
The overall number of computations used to train an AI system is an important driver of its capabilities. Because budgets are skyrocketing as coational efficiency continues to grow, it seems likely that AI systems trained over the next few years will use more compute than ever before.
Recent AI progress has been driven by data. AI systems that generate text and images are trained to imitate human text and real images scraped from the internet. For example, one popular text dataset includes large chunks of Wikipedia, GitHub, PubMed, FreeLaw, HackerNews, and arXiv.
It’s possible that companies will face barriers to gather more training data. Several lawsuits are currently arguing that companies should be required to obtain consent before using people’s data. Even if these lawsuits are struck down, there is only so much human-written text and real images to be gathered online. One analysis suggests that while high-quality text data may run out sometime next year, images and lower-quality text will remain plentiful for another decade or two.
Even after exhausting online text and images, there are several other data sources that AIs could be trained on. Videos could be scraped for both visual and audio information, and AIs could be trained to successfully perform tasks in simulations and in the real world. Moreover, several recent papers have shown that AI systems can generate data, filter out low quality data points, and then train on their own outputs, improving performance in areas including math and conversational skills.
Data is a key component of recent AI progress, and there appears to be at least a decade’s worth of additional text and image data available online. If that is exhausted, there will be several other sources of data that companies could use to train more advanced AIs.
AI R&D might accelerate compute and data growth. AI systems are reaching the point of being able to contribute to the acceleration of AI progress. For example, Google equipped their programmers with an AI coding assistant and found that it accelerated their development process. 25% of all suggestions made by the coding assistant were accepted, and the AI assistant wrote 2.6% of all code in the study.
More impactfully, AI systems are increasingly used to generate their own training data. Google released a paper showing that training large language models on a filtered subset of their own outputs improves their performance on a variety of benchmarks. Anthropic uses a similar setup, prompting their model to critique its own outputs and rewrite them, then fine-tuning on the improved versions. While training a model on its own outputs can have drawbacks, it has enabled several recent advancements.
AI R&D might also allow developers to more efficiently exploit compute. Companies have a limited number of chips for training AI systems, and must use them efficiently. NVIDIA, a chip designer whose stock price recently skyrocketed, rose to prominence partly because their programming language CUDA makes it easy for developers to use their compute efficiently. As AI capabilities improve in manipulating software programs, AIs could be used to make the most of a limited supply of compute.
For other examples of AI improving AI progress, see this site maintained by the Center for AI Safety.
Links
- Spain creates Europe’s first national AI agency. The EU AI Act calls for all countries to designate a regulatory authority for implementing the Act’s provisions.
- The United Nations calls for short papers to advise their High-level Advisory Body on AI.
- A call for grant applications in specific topics in neuroscience, information security, and other areas related to AI safety.
- Yoshua Bengio writes about the personal and psychological dimensions of confronting AI catastrophic risks.
- Opinion article in Politico calls for public control of advanced AI systems.
See also: CAIS website, CAIS twitter, A technical safety research newsletter, and An Overview of Catastrophic AI Risks
Subscribe here to receive future versions.

