Abram Demski writing a great summary of different approaches of aggregating utilities. Overall by far the best short summary of a bunch of stuff in bargaining theory and public choice theory I've seen. Some excerpts:
(This is a basic point about utility theory which many will already be familiar with. I draw some non-obvious conclusions which may be of interest to you even if you think you know this from the title -- but the main point is to communicate the basics. I'm posting it to the alignment forum because I've heard misunderstandings of this from some in the AI alignment research community.)
I will first give the basic argument that the utility quantities of different agents aren't directly comparable, and a few important consequences of this. I'll then spend the rest of the post discussing what to do when you need to compare utility functions.
Utilities aren't comparable.
Utility isn't an ordinary quantity. A utility function is a device for expressing the preferences of an agent.
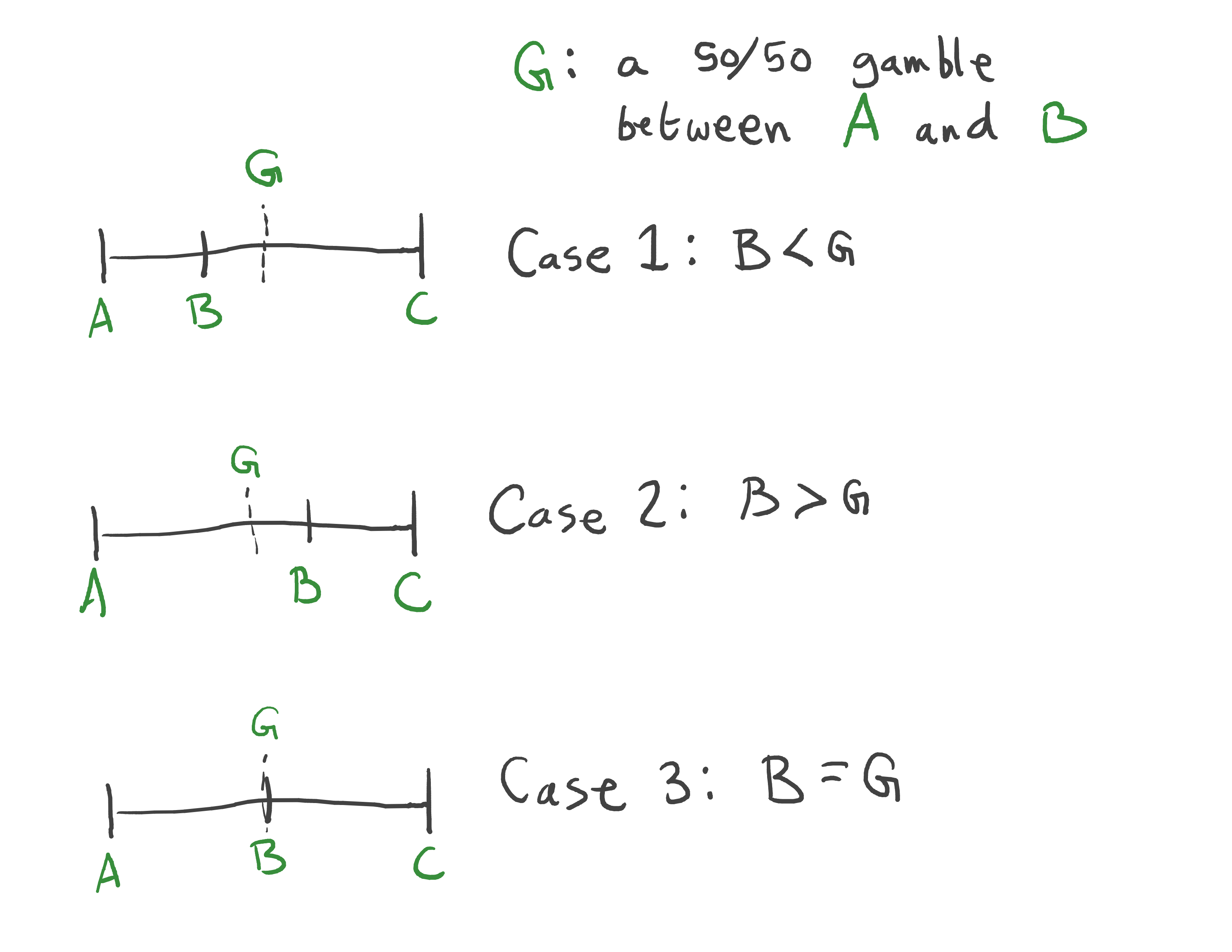
Suppose we have a notion of outcome.* We could try to represent the agent's preferences between outcomes as an ordering relation: if we have outcomes A, B, and C, then one possible preference would be A<B<C.
However, a mere ordering does not tell us how the agent would decide between gambles, ie, situations giving A, B, and C with some probability.
With just three outcomes, there is only one thing we need to know: is B closer to A or C, and by how much?
We want to construct a utility function U() which represents the preferences. Let's say we set U(A)=0 and U(C)=1. Then we can represent B=G as U(B)=1/2. If not, we would look for a different gamble which does equal B, and then set B's utility to the expected value of that gamble. By assigning real-numbered values to each outcome, we can fully represent an agent's preferences over gambles. (Assuming the VNM axioms hold, that is.)
But the initial choices U(A)=0 and U(C)=1 were arbitrary! We could have chosen any numbers so long as U(A)<U(C), reflecting the preference A<C. In general, a valid representation of our preferences U() can be modified into an equally valid U'() by adding/subtracting arbitrary numbers, or multiplying/dividing by positive numbers.
[...]
Variance Normalization: Not Too Exploitable?
We could set the constants any way we want... totally subjective estimates of the worth of a person, draw random lots, etc. But we do typically want to represent some notion of fairness. We said in the beginning that the problem was, a utility function U(x) has many equivalent representations aU(x)+b. We can address this as a problem of normalization: we want to take a U and put it into a canonical form, getting rid of the choice between equivalent representations.
One way of thinking about this is strategy-proofness. A utilitarian collective should not be vulnerable to members strategically claiming that their preferences are stronger (larger b), or that they should get more because they're worse off than everyone (smaller a -- although, remember that we haven't talked about any setup which actually cares about that, yet).
Warm-Up: Range Normalization
Unfortunately, some obvious ways to normalize utility functions are not going to be strategy-proof.
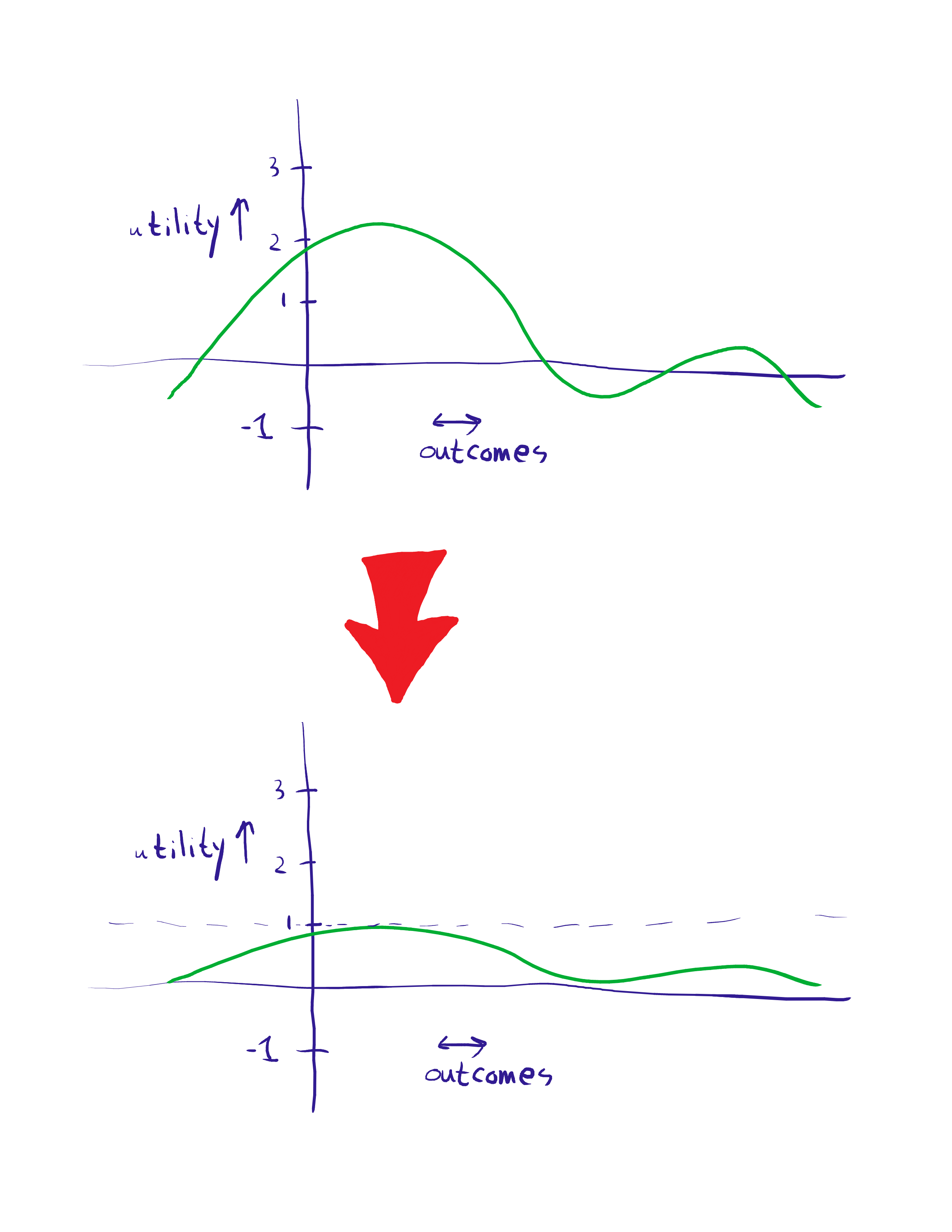
One of the simplest normalization techniques is to squish everything into a specified range, such as [0,1]:
This is analogous to range voting: everyone reports their preferences for different outcomes on a fixed scale, and these all get summed together in order to make decisions.
If you're an agent in a collective which uses range normalization, then you may want to strategically mis-report your preferences. In the example shown, the agent has a big hump around outcomes they like, and a small hump on a secondary "just OK" outcome. The agent might want to get rid of the second hump, forcing the group outcome into the more favored region.
I believe that in the extreme, the optimal strategy for range voting is to choose some utility threshold. Anything below that threshold goes to zero, feigning maximal disapproval of the outcome. Anything above the threshold goes to one, feigning maximal approval. In other words, under strategic voting, range voting becomes approval voting (range voting where the only options are zero and one).
If it's not possible to mis-report your preferences, then the incentive becomes to self-modify to literally have these extreme preferences. This could perhaps have a real-life analogue in political outrage and black-and-white thinking. If we use this normalization scheme, that's the closest you can get to being a utility monster.
Variance Normalization
We'd like to avoid any incentive to misrepresent/modify your utility function. Is there a way to achieve that?
Owen Cotton-Barratt discusses different normalization techniques in illuminating detail, and argues for variance normalization: divide utility functions by their variance, making the variance one. (Geometric reasons for normalizing variance to aggregate preferences, O Cotton-Barratt, 2013.) Variance normalization is strategy-proof under the assumption that everyone participating in an election shares beliefs about how probable the different outcomes are! (Note that varianceof utility is only well-defined under some assumption about probability of outcome.) That's pretty good. It's probably the best we can get, in terms of strategy-proofness of voting. Will MacAskill also argues for variance normalization in the context of normative uncertainty (Normative Uncertainty, Will MacAskill, 2014).
Intuitively, variance normalization directly addresses the issue we encountered with range normalization: an individual attempts to make their preferences "loud" by extremizing everything to 0 or 1. This increases variance, so, is directly punished by variance normalization.
However, Jameson Quinn, LessWrong's resident voting theory expert, has warned me rather strongly about variance normalization.
The assumption of shared beliefs about election outcomes is far from true in practice. Jameson Quinn tells me that, in fact, the strategic voting incentivized by quadratic voting is particularly bad amongst normalization techniques.
Strategy-proofness isn't, after all, the final arbiter of the quality of a voting method. The final arbiter should be something like the utilitarian quality of an election's outcome. This question gets a bit weird and recursive in the current context, where I'm using elections as an analogy to ask how we should define utilitarian outcomes. But the point still, to some extent, stands.
I didn't understand the full justification behind his point, but I came away thinking that range normalization was probably better in practice. After all, it reduces to approval voting, which is actually a pretty good form of voting. But if you want to do the best we can with the state of voting theory, Jameson Quinn suggested 3-2-1 voting. (I don't think 3-2-1 voting gives us any nice theory about how to combine utility functions, though, so it isn't so useful for our purposes.)
Open Question: Is there a variant of variance normalization which takes differing beliefs into account, to achieve strategy-proofness (IE honest reporting of utility)?
Anyway, so much for normalization techniques. These techniques ignore the broader context. They attempt to be fair and even-handed in the way we choose the multiplicative and additive constants. But we could also explicitly try to be fair and even-handed in the way we choose between Pareto-optimal outcomes, as with this next technique.
Nash Bargaining Solution
It's important to remember that the Nash bargaining solution is a solution to the Nash bargaining problem, which isn't quite our problem here. But I'm going to gloss over that. Just imagine that we're setting the social choice function through a massive negotiation, so that we can apply bargaining theory.
Nash offers a very simple solution, which I'll get to in a minute. But first, a few words on how this solution is derived. Nash provides two seperate justifications for his solution. The first is a game-theoretic derivation of the solution as an especially robust Nash equilibrium. I won't detail that here; I quite recommend his original paper (The Bargaining Problem, 1950); but, just keep in mind that there is at least some reason to expect selfishly rational agents to hit upon this particular solution. The second, unrelated justification is an axiomatic one:
Invariance to equivalent utility functions. This is the same motivation I gave when discussing normalization.
Pareto optimality. We've already discussed this as well.
Independence of Irrelevant Alternatives (IIA). This says that we shouldn't change the outcome of bargaining by removing options which won't ultimately get chosen anyway. This isn't even technically one of the VNM axioms, but it essentially is -- the VNM axioms are posed for binary preferences (a > b). IIA is the assumption we need to break down multi-choice preferences to binary choices. We can justify IIA with a kind of money pump.
Symmetry. This says that the outcome doesn't depend on the order of the bargainers; we don't prefer Player 1 in case of a tie, or anything like that.
[...]
Altruistic agents.
Another puzzling case, which I think needs to be handled carefully, is accounting for the preferences of altruistic agents.
Let's proceed with a simplistic model where agents have "personal preferences" (preferences which just have to do with themselves, in some sense) and "cofrences" (co-preferences; preferences having to do with other agents).
Here's an agent named Sandy:
Sandy
Personal Preferences
Cofrences
Candy
+.1
Alice
+.1
Pizza
+.2
Bob
-.2
Rainbows
+10
Cathy
+.3
Kittens
-20
Dennis
+.4
The cofrences represent coefficients on other agent's utility functions. Sandy's preferences are supposed to be understood as a utility function representing Sandy's personal preferences, plus a weighted sum of the utility functions of Alice, Bob, Cathy, and Dennis. (Note that the weights can, hypothetically, be negative -- for example, screw Bob.)
The first problem is that utility functions are not comparable, so we have to say more before we can understand what "weighted sum" is supposed to mean. But suppose we've chosen some utility normalization technique. There are still other problems.
Notice that we can't totally define Sandy's utility function until we've defined Alice's, Bob's, Cathy's, and Dennis'. But any of those four might have cofrences which involve Sandy, as well!
[...]
Average utilitarianism vs total utilitarianism.
Now that we have given some options for utility comparison, can we use them to make sense of the distinction between average utilitarianism and total utilitarianism?
No. Utility comparison doesn't really help us there.
The average vs total debate is a debate about population ethics. Harsanyi's utilitarianism theorem and related approaches let us think about altruistic policies for a fixed set of agents. They don't tell us how to think about a set which changes over time, as new agents come into existence.
Allowing the set to vary over time like this feels similar to allowing a single agent to change its utility function. There is no rule against this. An agent can prefer to have different preferences than it does. A collective of agents can prefer to extend its altruism to new agents who come into existence.
However, I see no reason why population ethics needs to be simple. We can have relatively complex preferences here. So, I don't find paradoxes such as the Repugnant Conclusion to be especially concerning. To me there's just this complicated question about what everyone collectively wants for the future.
One of the basic questions about utilitarianism shouldn't be "average vs total?". To me, this is a type error. It seems to me, more basic questions for a (preference) utilitarian are:
Might be worth noting, utilities in this sense are preferences, which may or may not matter intrinsically. On preference/desire theories of well-being, your life goes better the more you get of what you want. But on, say, hedonist theories of well-being, your life goes better the more happiness you have (where happiness is often understood as a positive balance of pleasure over displeasure). Historically, 'utilities' in economics referred to happiness rather than preferences. This switched in the early 20th century with work by Pareto and Robbins and others.
Yeah, the view that utilities aren't comparable has more legs on preference-satisfactionism than it does on hedonism. On the face it is quite weird to say that the utilities, in the hedonistic sense, are not comparable. Can we compare the utility of a man being tortured with that of a man enjoying watching The Sopranos? DALYs, QALYs and WELLBYs are utility metrics that make utility comparable across people.
Might be worth noting, utilities in this sense are preferences, which may or may not matter intrinsically. On preference/desire theories of well-being, your life goes better the more you get of what you want. But on, say, hedonist theories of well-being, your life goes better the more happiness you have (where happiness is often understood as a positive balance of pleasure over displeasure). Historically, 'utilities' in economics referred to happiness rather than preferences. This switched in the early 20th century with work by Pareto and Robbins and others.
Yeah, the view that utilities aren't comparable has more legs on preference-satisfactionism than it does on hedonism. On the face it is quite weird to say that the utilities, in the hedonistic sense, are not comparable. Can we compare the utility of a man being tortured with that of a man enjoying watching The Sopranos? DALYs, QALYs and WELLBYs are utility metrics that make utility comparable across people.