Comments
Thanks to the following people for feedback: Tilman Rauker, Curt Tigges, Rudolf Laine, Logan Smith, Arthur Conmy, Joseph Bloom, Rusheb Shah, James Dao.
I present an analogy for the transformer architecture: each vector in the residual stream is a person standing in a line, who is holding a token, and trying to guess what token the person in front of them is holding. Attention heads represent questions that people in this line can ask to everyone standing behind them (queries are the questions, keys determine who answers the questions, values determine what information gets passed back to the original question-asker), and MLPs represent the internal processing done by each person in the line. I claim this is a useful way to intuitively understand the transformer architecture, and I'll present several reasons for this (as well as ways induction heads and indirect object identification can be understood in these terms).[1]
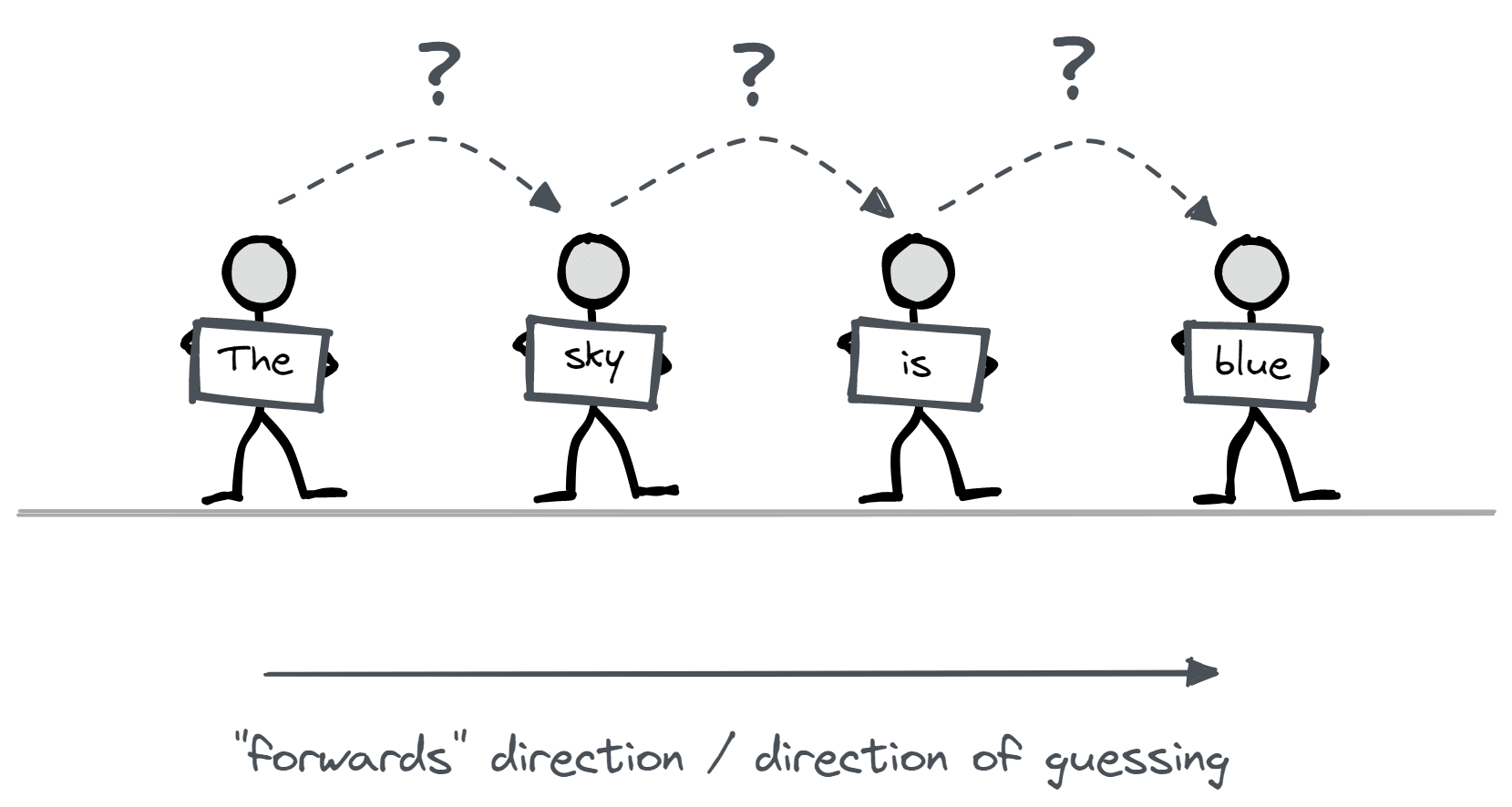
In this post, I'm going to present an analogy for understanding how transformers work. I expect this to be useful for anyone who understands the basics of transformers, in particular people who have gone through Neel Nanda's tutorial, and/or understand the following points at a minimum:
I think the analogy still offers value even for people who understand transformers deeply already.
A line is formed by a group of people, each person holding a word[2]. Everyone knows their own word and position in the line, but they can't see anyone else in the line. The objective for each person is to guess the word held by the person in front of them. People have the ability to shout questions to everyone standing behind them in the line (those in front cannot hear them). Upon hearing a question, each individual can choose whether or not to respond, and what information to relay back to the person who asked. After this, people don't remember the questions they were asked (so no information can move backwards in the line, only forwards). As individuals in the line gather information from these exchanges, they can use this information to formulate subsequent questions and provide answers.
How this relates to transformer architecture:

In this section, I present a few key ideas / intuitions for transformers (many inspired by Kevin Wang's excellent post, and by Neel Nanda's writing), and how they fit into this analogy. Lots of credit goes to writing other than mine here (especially the bit on MLPs which is shamelessly plagiarized from Kevin's post).
The idea
This quote (which I heard first from Neel Nanda) points to the hypothesis that composition of functions is the key thing that makes deep learning so effective. The outputs of attention heads / MLPs are used as inputs of attention heads / MLPs in later layers.
The analogy
The people in the line can perform multi-step processing. They can take the information they learn from earlier questions / from their own internal processing, and use it in later questions / information processing.
The idea
As we move through the model, the components of our model (attn and MLPs) read from and write to the residual stream. By the end of the model, the residual stream represents the model's best guess about what token comes next in the sequence. The logit lens[3] technique shows that we can extract values of the residual stream at intermediate predictions and unembed them to get a kind of "thought process", as the model converges to its final guess.
The analogy
As the people in the line communicate with each other, they gain more information over time, and converge on a guess for what the token in front of them is. Half way through the communication process, they might already have a good guess for the token's identity. The logit lens is effectively asking people in the sequence "what do you think right now?" before they've finished communicating.
The idea
Ignoring biases, MLPs can be written as f(xTWin)Wout where Win and Wout are the weights of the linear layers, f is the nonlinear function, and x is a vector in the residual stream. We can break this down as a sum of terms of the form f(xTk)v, where k and v are vectors. We can view k as the keys (input vectors) which activate on specific inputs or textual patterns, and v as the corresponding values (output vectors) that get written to the residual stream. This can be viewed as a kind of associative memory (with each key having an associated value). Earlier layers will usually activate on simple language features (e.g. syntax or grammar), and the keys & values of later layers will correspond to more complex semantic information.
The analogy
People have memories[4], and when they are exposed to certain stimuli they will be triggered to remember other things. The input vectors k represent the context which triggers people to remember things, and the output vectors v represent the things people remember. At first, when people know less about the sentence, they'll spend their time thinking about shallow language features (syntax or grammar), but as they learn more about the sentence they'll be able to form more complex thoughts.
The idea
The residual stream is the only way that information can move between the layers of a transformer, so the model needs to find a way to store all relevant information in it. This sometimes takes the form of storing information in different subspaces.
The analogy
The only way information is stored in our people-in-the-line setup is within the heads of each person. People have finite capacity in their short-term memory[5], and will have to make efficient use by storing different things in different parts of their memory, so facts don't interfere with each other.
The idea
This is closely related to the "residual stream as shared memory" idea. Some neurons in MLPs seem to be performing memory-management, i.e. they erase components of the residual stream in a certain direction so that more information can be stored in them (e.g. if k and v above had cosine similarity close to −1).
The analogy
Memory-management MLPs allow people in the line to forget certain facts about the sentence, at certain times, so they can make room for storing other information.
What parts of our "people standing in a line" story changes when the model gets trained, and improves at the next token prediction task? Answer - two main things:
A major advantage of this analogy (when it comes to looking for circuits) is that it frames the transformer's operation as a puzzle to be solved. The setup, constraints and objectives are clear, and you can activate the "puzzle-solving" part of your brain in order to find a solution. In this section, I'll outline how we could think about the induction heads and IOI circuit in terms of this analogy (with visual aids). I think these are all quite natural solutions to their respective puzzles.
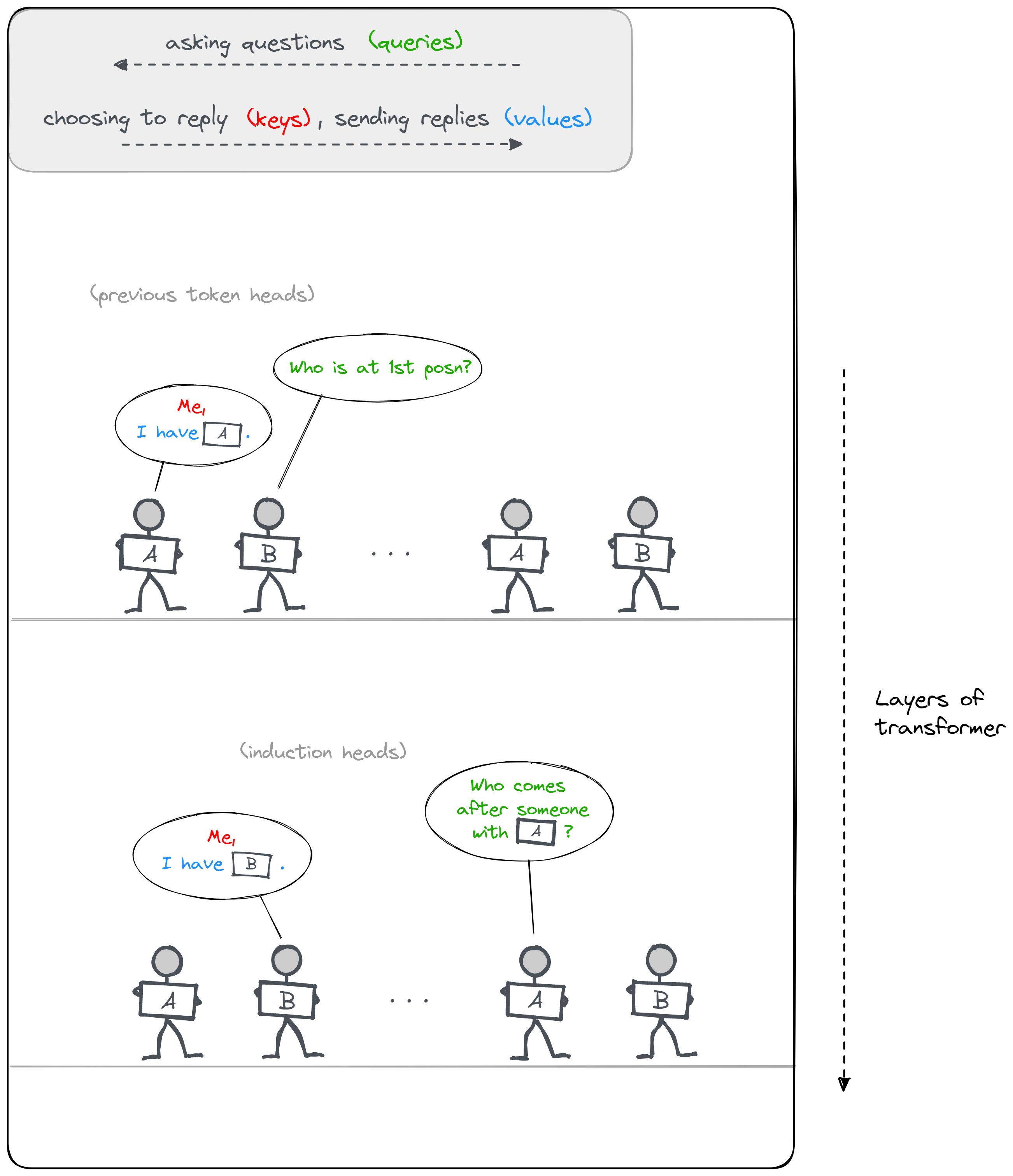
Induction circuits are the most basic form of in-context learning for transformers. They refer to how a transformer can learn the pattern ("B" follows "A") the second time it observes the "AB" subsequence. For instance, this might mean predicting that "Obama" follows "Barack" the second time the model sees "Barack", even if it wasn't trained on data that included this name.
Indirect object identification is the ability to (surprise surprise) identify the indirect object in a sentence. For instance, given the sentence "John and Mary went to the shops, John gave a bag to Mary", the IOI task would be to predict that the word "Mary" follows the word "to".
The IOI circuit (found in GPT2-small) is pretty large and complex, and this diagram omits some nuances[7] (I'm trying to keep this post brief and readable), although I think the nuances I'm omitting here also fit into this analogy pretty well.
I'd recommend trying to solve this puzzle for yourself before looking at the diagram. Try and work backwards: start by asking which person in the line will be making the prediction, then ask what they need to know, who they might get that information from, how that person would have that information, etc.
Hint (rot13): Gur pbeerpg anzr gb cerqvpg vf gur aba-qhcyvpngrq bar. Juvpu crefba va gur yvar zvtug or va n tbbq cbfvgvba gb yrnea gung gur anzr "Wbua" vf qhcyvpngrq?
Diagram:

Which parts of mechanistic interpretability are easy / hard, and how does this relate to the analogy?
Cutting through the noise. There's a huge amount of information movement in transformers, and for most tasks most of the time, the vast majority of it won't matter. Analogously, if the people in a line are constantly shouting questions back and answers forward (e.g. for GPT-2 we have 12 batches of 12 questions being asked in series), and this is happening at the same time as information processing from MLPs, it can be hard to figure out where the important information transfer is happening.
Understanding the language of keys/queries/values. The keys, queries and values are not a privileged basis, meaning they generally can't be understood in isolation. To fit this into our analogy, we could imagine the people in the line are speaking a foreign language, so we don't actually know what they're asking and saying.
Superposition. This is the name for what happens when we have more features than we have free dimensions in our model, so (for instance) some neurons in MLPs might represent more than one concept simultaneously. A classic non-transformer-based piece of evidence for this is polysemantic neurons in image models (e.g. the neuron depicted below, which activates on cat faces, cars, and cat legs, despite some of these having very little visual or conceptual similarity).

Interpretability would be a lot easier if we could understand every "thought" that takes place in the minds of the people standing in the line (e.g. we'd like to say things like "this person is clearly reacting to the gender of the word they're holding", or "this person is clearly figuring out whether or not the next word is "an""[8]). Unfortunately, superposition usually makes this hard, because the neurons don't always correspond to a single concept, meaning these "thoughts" don't really correspond to the same kinds of thoughts we have. This makes it harder to understand what's going on in the minds of our little people.
Locating information. It's not always easy to understand exactly how information is represented, but techniques like the logit lens / activation patching / probing can help tell us where information is represented. This is because (returning to our analogy) we have the ability to ask each person in the line questions at specific times, to figure out whether they possess the information we're looking for.
Understanding attention patterns. Looking at attention patterns is often very informative, because we can see where information is moving to and from. Returning to our analogy, this is equivalent to saying that we're able to see who is responding to questions (which gives us hints about what purpose these questions might be serving). This isn't trivial by any means, and there are some complications (e.g. see info-weighted attention), but it's usually a good place to start when we're trying to get traction on model behaviour.
Here are a few other topics which aren't as important, but which slot into this analogy in an interesting way. If you're trying to 80/20 this post, feel free to stop reading here!
This analogy provides a good mental model for activation patching. For instance:
Path patching also fits into this analogy (although it's a bit messier) - I'll leave this as an exercise to the reader.
Causal scrubbing is a systematic way to try and figure out which people (and which instances of communication & reasoning) matter for solving a particular task. We do this by various forms of patching (i.e. selectively replacing peoples' questions/answers and the contents of their thoughts at certain points during the communication process). If deleting the memory of a person in the line doesn't change the result, that person must not have been important for the final result. We can keep doing this until we have a minimal circuit, i.e. we know exactly what's necessary for solving the task.
This analogy has an obvious generalisation to bidirectional models - you're allowed to ask questions forward in the line as well. Masked language modelling means one of the people in the line doesn't know their own token, and they have to try and figure it out. See my SERI MATS 2023 application looking at the IOI circuit in BERT (which has instances of information flowing backwards in the sequence).
Keys/queries/values often have lower rank than the residual stream (e.g. in GPT2 the heads have 12x fewer dimensions than the residual stream). This makes sense in the context of our analogy, because communication between two different people in a line is unlikely to be as complicated as them sharing their entire memories.
Models are trained with dropout (some activations are randomly chosen and set to zero during training). Analogy: as we're training our people in a line to solve the next-word-prediction task better, we make them forget certain things at random, which encourages them to build more reliable communication and memory storage systems.
Not everything fits neatly into this analogy. For instance, layernorm is weird and important but doesn't really have any kind of parallel here.[9] Also (as discussed above) we need superposition to understand how transformers work, despite the fact that our brains probably don't work like this.
Note - this analogy might make it seem like the kind of processing transformers do is analogous to that done by human minds. I think in a sense this is partially true, but I also don't want to overstate this point. This analogy just presents a way to help build some generally accurate intuitions about transformers, not as the objectively true or canonical way to think about them. Relatedly, I want to emphasise that this analogy shouldn't make you think mech interp is easy, or we should have a prior of algorithms being human-comprehensible (see the section "why mech interp is hard").
Or "token" if we're being technical.
James Dao points out that the tuned logit lens has now basically superseded logit lens. Intuitions for tuned logit lens are basically the same as for logit lens (maybe you could view tuned logit lens as a way of rephrasing the question "what do you think right now?" which corrects for some predictable biases).
At least I think I remember someone telling me this.
I'm drawing a distinction between short-term and long-term memory here. Long-term memory is associated with the MLPs and other model weights, i.e. it's learned by the model and is independent of whatever sequence is currently being passed through the model. Short-term memory is associated with the residual stream and other model activations, and depends entirely on what sequence is being passed through the model.
This is a bit speculative. There's anecdotal evidence for this, but nothing super rigorous. Also, recent evidence that the L2-norm of the residual stream decreases as we move through the model might offer weak evidence against this.
The main 4 nuances omitted are: backup name mover heads, negative name mover heads, the distinction between suppressing names using token vs. positional information (I only show the latter), the presence of induction heads in this circuit.
Maybe you could view layernorm as "reducing peoples' volume" in some sense? But it would be the volume of peoples' thoughts rather than their questions, so the analogy is a bit of a stretch. More importantly, fitting layernorm into this analogy doesn't build towards improved understanding, like I think it does for most other parts of the model. Since layernorm is primarily a thing which helps training rather than something that is conceptually key to understanding how transformers work, this shouldn't be too surprising.
On the bright side, at least layernorm doesn't actively contradict or break any parts of the analogy, since it's just a simple operation which is applied individually and identically to each person in the line, and involves no sharing of information.


