This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
AI Safety Camp connects new collaborators worldwide to discuss and decide on a concrete research proposal, gear up online as a team, and try their hand at AI safety research* during intensive coworking sprints.
Six teams formed at our recent 4-month virtual camp. Below are their explanations. Each team has summarised their analysis and experiments, and presented their findings at our final online weekend together. Some published a paper or post since. Most are continuing work, so expect a few more detailed and refined write-ups down the line.
Modularity Loss Function
Team members: Logan Smith, Viktor Rehnberg, Vlado Baca, Philip Blagoveschensky, Viktor Petukhov External collaborators: Gurkenglas
Making neural networks (NNs) more modular may improve their interpretability. If we cluster neurons or weights together according to their different functions, we can analyze each cluster individually. Once we better understand the clusters that make up a NN, we can better understand the whole.
To that end, we experimented with pairwise distances according to the neuron’s jacobian correlation, coactivations, and estimated mutual information. These metrics can be plugged into spectral clustering algorithms to optimize for modules in the network; however, having a modular NN does not equate to a more interpretable one. We investigated task-based masking methods to test for modularity as well as neuron group activation (via Google Dream) in order to test for these modules being more interpretable than an equivalent amount of neurons. We ran out of time before fitting all the pieces together, but are intending on working on it more over the summer.
Team members: Quinn Doughtery, Ben Greenberg, Ariel Kwiatkowski
In environments with common pool resources, a typical failure mode is the tragedy of the commons, wherein agents exploit the scarce public resource as much as possible. An every-man-for-himself dynamic emerges, further increasing scarcity. This behavior results in conflict, inefficient allocation, and resource depletion.
Even if an individual would prefer to harvest the resource sustainably, they are punished for doing so unilaterally. What’s missing is an institution that will incentivize the group to “cooperate”. In this project, we study such interventions for avoiding tragedies of the commons in environments with multiple selfish agents. In particular, a reputation system can incentivize agents to harvest resources more sustainably.
Our goal in this project was to see if a transparent reputation system would allow agents to trust each other enough to cooperate, such that their combined rewards would be higher over time. This problem is relevant for existential safety as it relates to climate change and sustainability, as well as conflict over finite resources.
Team members: Jack Koch, James Le, Jacob Pfau External collaborators: Lauro Langosco
We study objective robustness failures, in the context of reinforcement learning (RL). Objective robustness failures occur when an RL agent retains its capabilities out-of-distribution yet pursues the wrong objective (this definition is broader than misaligned mesa-optimizers: a model can fail at objective robustness without being a mesa-optimizer). This kind of failure is particularly bad, since it involves agents that leverage their capabilities to pursue the wrong objective rather than simply failing to do anything useful. The main goal of our project is to provide explicit empirical demonstrations of objective robustness failures.
To do this, we modify environments from the Procgen benchmark to create test environments that induce OR failure. For example, in the CoinRun environment, an agent’s goal is to collect the coin at the end of the level. When we deploy the agent on a test environment in which coin position is randomized, the agent ignores the coin and instead pursues a simple proxy objective: it navigates to the end of the level, where the coin is usually located.
Team members: Robert Klassert, Roland Pihlakas (message), Ben Smith (message) External collaborators: Peter Vamplew (research mentor)
Balancing multiple competing and conflicting objectives is an essential task for any artificial intelligence tasked with satisfying human values or preferences while avoiding Goodhart’s law. Objective conflict arises both from misalignment between individuals with competing values, but also between conflicting value systems held by a single human. We were guided by two key principles: loss aversion and balanced outcomes. Loss aversion, conservatism, or soft maximin is aimed at emulating aspects of human cognition and will heavily penalize proposed actions that score more negatively on any particular objective. We also aim to balance outcomes across objectives. This embodies conservatism in the case where each objective represents a different moral system by ensuring that any action taken does not grossly violate any particular principle. Where each objective represents another subject’s principles this embodies an inter-subject fairness principle.
We tested these on previously-tested environments, and found that one new approach in particular, ‘split-function exp-log loss aversion’, performs better across a range of reward penalties in the “BreakableBottles” environment relative to the thresholded alignment objective (more generally lexicographic) method, the state of the art described in Vamplew et al. 2021. We explore approaches to further improve multi-objective decision-making using soft maximin approaches. Our soft maximin covers a middle ground between the linear approach and the lexicographic approaches with the aim of enabling an agent to respond well in a wider variety of circumstances.
In future we would like to implement more complex scenarios with more numerous competing objectives to explore how our models perform with them. More complex scenarios were already sorted out from various lists of AI failure scenarios, analysed, and improvements were proposed. Other future directions to explore might be “decision-paralysis as a feature, not a bug”, where the agent responds to objective conflict by stopping and asking the human for additional input or for additional clarification on their preferences. We plan to present our work at the Multi-Objective Decision Making Workshop 2021 and subsequently submit the work to a special issue of the Journal of Autonomous Agents and Multi-Agent Systems.
Pessimistic Ask-For-Help Agents for Safe Exploration
Team members: Jamie Bernardi, David Reber, Magdalena Wache, Peter Barnett, Max Clarke External collaborators: Michael Cohen (research mentor)
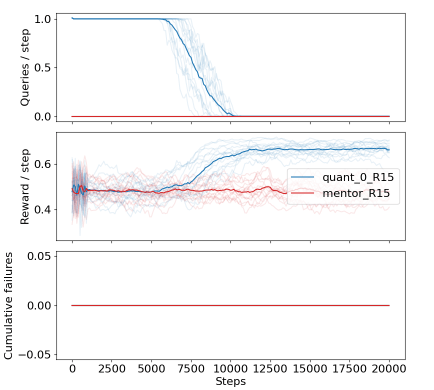
In reinforcement learning (RL), an agent explores its environment in order to learn a task. However, in safety-critical situations this can have catastrophic consequences. We demonstrate that if the agent has access to a safe mentor, and if it is pessimistic about unknown situations, a safe learning process can be achieved. We trained an RL agent to exceed the mentor’s capability while avoiding unsafe consequences with high probability. We demonstrate that the agent acts more autonomously the more it learns, and eventually stops asking for help.
Cohen/Hutter 2020 propose a model-based pessimistic agent, with the desired safety and performance properties. However, this agent is intractable except for in very simple environments. To overcome this intractability we devise a model-free approach to pessimism that is based on keeping a distribution over Q-values. It is a variation of Q-Learning, which does not decide its policy based on an approximation of the Q-value, but rather based on an approximation of the i-quantile Qᵢ with i<0.5. We call this approach Distributional Q-Learning (DistQL). We demonstrate that in a finite environment, DistQL successfully avoids taking risky actions. A subset of the team is excited to be continuing beyond the AISC deadline and to apply DistQL to more complex environments. For example in the cartpole environment the goal is to learn balancing the pole without ever dropping it. To apply DistQL to a continuous environment, we use gated linear networks for approximating Qᵢ
We demonstrate the properties of a pessimistic agent in a finite, discrete gridworld environment with stochastic rewards and transitions, and bordering ‘cliffs’ around the edge, where stepping across leads to 0 reward forever. From top to bottom: the agent stops querying the mentor, exceeds the performance of a random, safe mentor; and never falls off the cliff.
Understanding RL agents using generative visualisation
Team members: Lee Sharkey, Daniel Braun, Joe Kwon, Max Chiswick
Feature visualisation methods can generate visualisations of inputs that maximally or minimally activate certain neurons. Feature visualisation can be used to understand how a network computes its input-output function by building up an understanding of how neural activations in lower layers cause specific patterns of activation in later layers. These methods have produced some of the deepest understanding of feedforward convolutional neural networks.
Feature visualisation methods work because, within a neural network, the causal chain of activations between input and output is differentiable. This enables backpropagation through the causal chain to see what inputs cause certain outputs (or certain intermediate activations). But RL agents are situated in an environment, which means causality flows both through its networks and through the environment. Typically the environment is not differentiable. This means that, in the RL setting, gradient-based feature visualisation techniques can’t build up a complete picture of how certain inputs cause particular neural activations at later timesteps.
We get around this difficulty by training a differentiable simulation of the agent’s environment. Specifically, we train a variational autoencoder (VAE) to produce realistic agent environment sequences. The decoder consists of both a recurrent environment simulator (an LSTM) and the agent that we wish to interpret. Crucially, this enables us to optimize the latent space of the VAE to produce realistic agent-environment rollouts that maximise specific neurons at specific timesteps in the same way that feature visualisation methods maximise specific neurons in specific layers.
This has yielded promising early results, though the resolution of the generative model needs improvement. In an agent trained on procedurally generated levels of CoinRun, we find that we can optimise the latent space of the generative model to produce agent-environment rollouts that maximise or minimise the agent’s value or action neurons for whole or partial sequences. We also find that individual neurons in the agent’s hidden state exhibit mixed selectivity i.e. they encode multiple features in different contexts and do not encode easily interpretable features. Such mixed selectivity is consistent with prior neuroscientific findings of task representations. Instead of optimizing single neurons, ongoing work optimizes for particular directions in the agent’s hidden state activation-space; we expect this to yield more semantically meaningful categories than single neurons. In future work, we plan to improve the realism of the generated samples; to identify discrete agent behaviours; to build up a timestep-by-timestep and layer-by-layer understanding of how the agent computes specific behaviours; and to safely un-train an agent using the learned simulator such that it no longer performs an arbitrarily chosen behaviour.
See FAQs, or comment to ask us about the recent virtual camp (#5)
Subscribe to be informed of our next virtual (#6) and North American camp (#7)
* Though past participants often did technical research aimed at reducing AI existential risks, others did e.g. policy-related research to reduce e.g. risks of astronomical suffering.
24
More posts like this
97
Apply to the Redwood Research Mechanistic Interpretability Experiment (REMIX), a research program in Berkeley