I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
Machine learning algorithms have become an essential part of technology — a part that will only grow in the future. In this talk, Chongli Qin, a research scientist at DeepMind, addresses why it is important for us to develop safe machine learning algorithms. The talk covers some of the current work on this topic and highlights what we can do to ensure that algorithms being bought into the real world are safe and satisfy desirable specifications.
We’ve lightly edited Chongli’s talk for clarity. You can also watch it on YouTube and read it on effectivealtruism.org.
The Talk
Nigel Choo (Moderator): Hello, and welcome to this session on ensuring safety and consistency in the age of machine learning, with Chongli Qin.
Following a 10-minute talk by Chongli, we'll move on to a live Q&A session, where she will respond to your questions. [...]
Now I would like to introduce our speaker for this session. Chongli Qin is a research scientist at DeepMind. Her primary interest is in building safer, more reliable, and more trustworthy machine learning algorithms. Over the past few years, she has contributed to developing algorithms that make neural networks more robust [and capable of reducing] noise. Key parts of her research focus on functional analysis of properties of neural networks that can naturally enhance robustness. Prior to DeepMind, Chongli studied at the University of Cambridge. Her PhD is in bioinformatics.
Here's Chongli.
Chongli: Hi. My name is Chongli Qin. I'm a research scientist at DeepMind, but my primary focus is looking at robust and verified machine learning algorithms. Today, my talk is on ensuring safety and consistency in the age of machine learning.
With all of the great research which has happened over the past several decades, machine learning algorithms are becoming increasingly more powerful. There have been many breakthroughs in this field, and today I’ll mention just a few.
One earlier breakthrough was using convolutional neural networks to boost the accuracy of image classifiers. More recently, we've seen generative models that are now capable of generating images with high fidelity and realism.
We've also made breakthroughs in biology, where machine learning can fold proteins with unprecedented levels of accuracy.
We can also use machine learning in reinforcement learning algorithms to beat humans in games such as Go.
More recently, we've seen machine learning pushing the boundaries of language. The recent GPT-2 and GPT-3 models have demonstrated that they're not only capable of generating text that is grammatically correct, but grounded in the real world.
So as the saying goes, with great power comes great responsibility. As our machine learning algorithms become increasingly more powerful, it is now more important than ever for us to understand what the negative impacts and risks might be. And more importantly, what can we do to mitigate these risks?
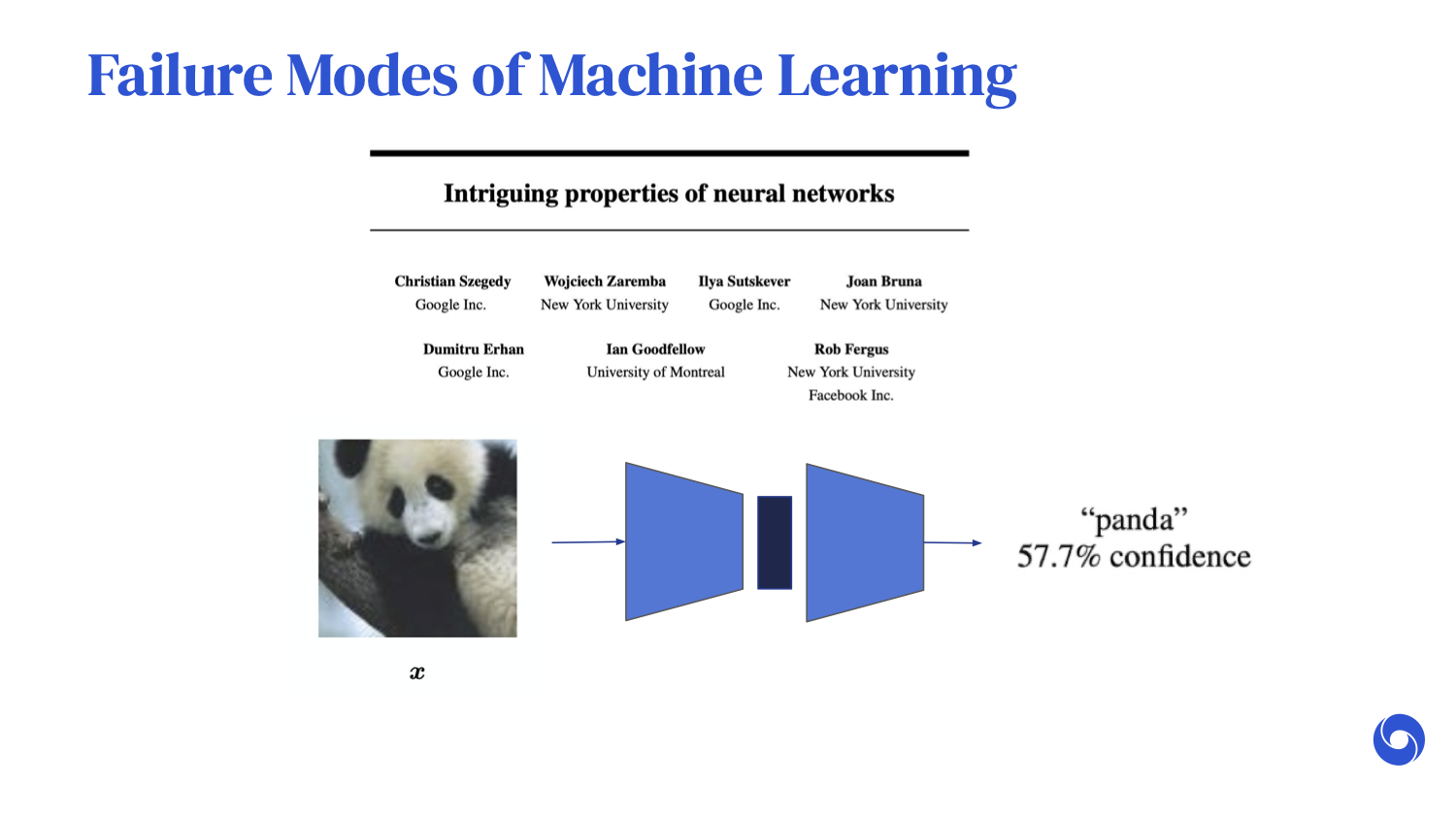
To highlight [what’s at stake], I’ll share a few motivating examples. In a paper published in 2013, “[Intriguing Properties of Neural Networks](https://arxiv.org/abs/1312.6199),” the authors discovered that you can take a state-of-the-art image classifier, put an image through it — in this case, the image of a panda — and indeed, correctly classify it.
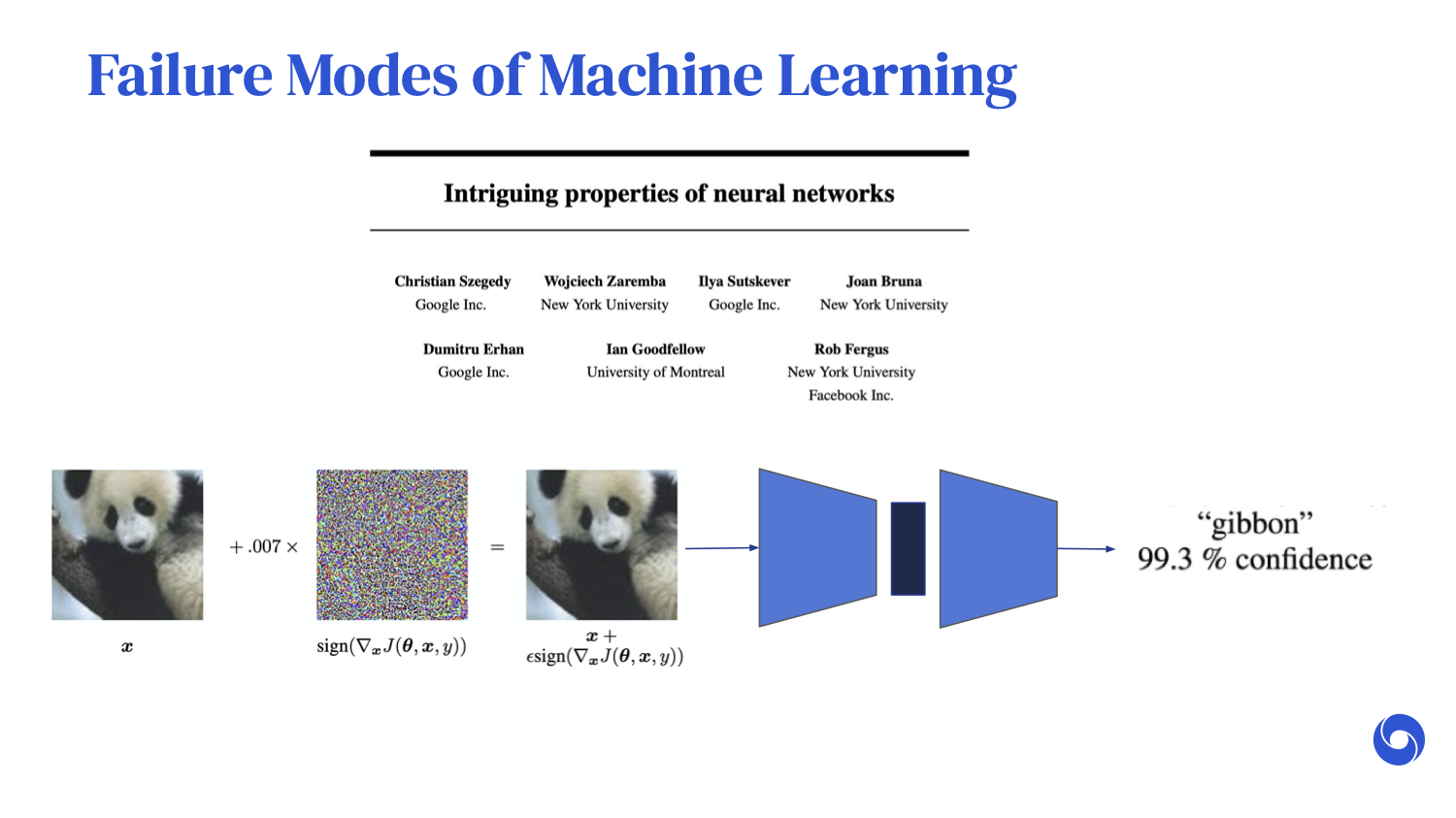
What happens if you take the exact same image and add a carefully chosen perturbation that is so small that the newly perturbed image looks almost exactly the same as the original?
We would expect the neural network to behave in a very similar way. But in fact, when we put this newly perturbed image through the neural network, it is now almost 100% confident that [the panda] is a gibbon.
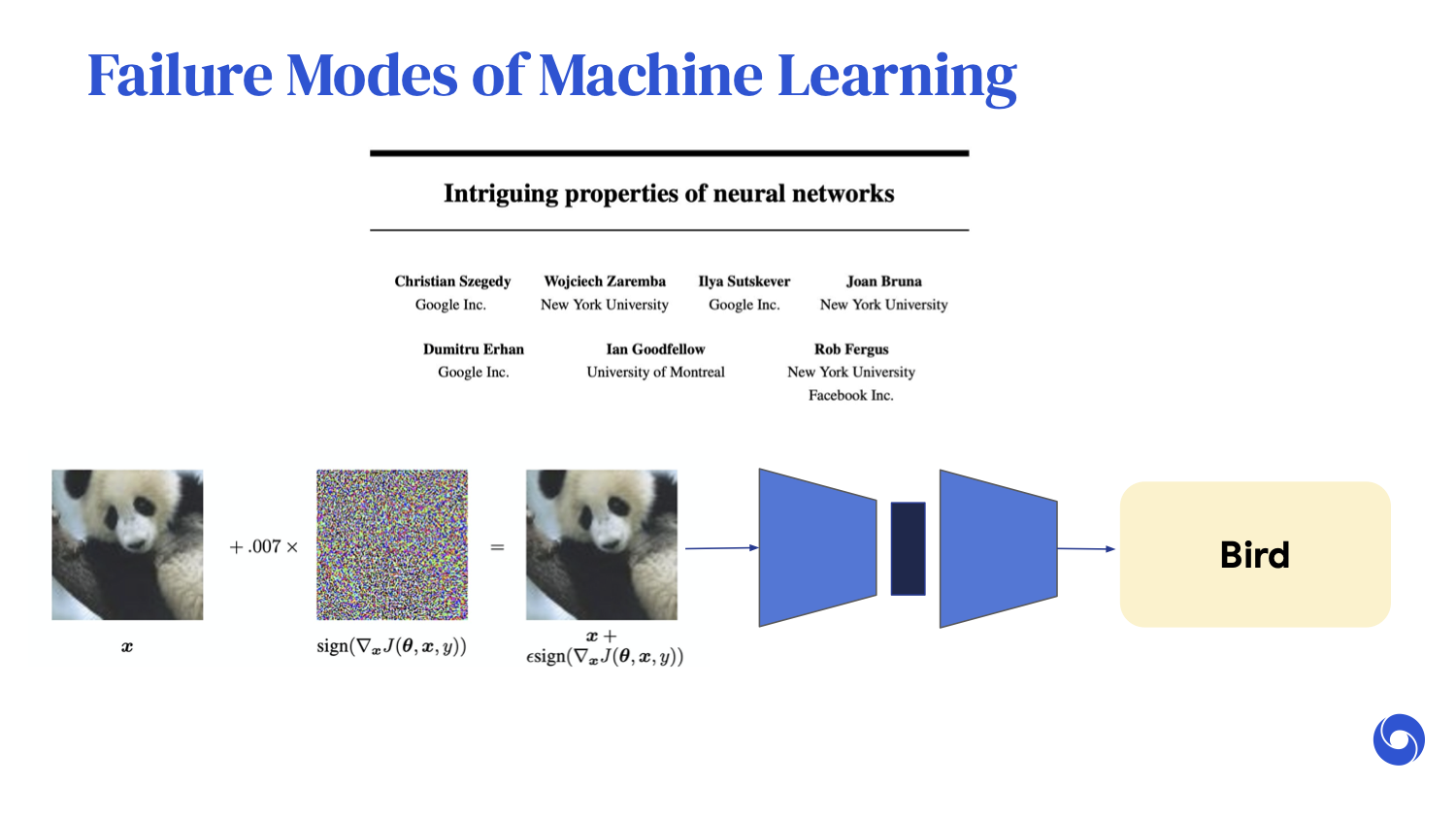
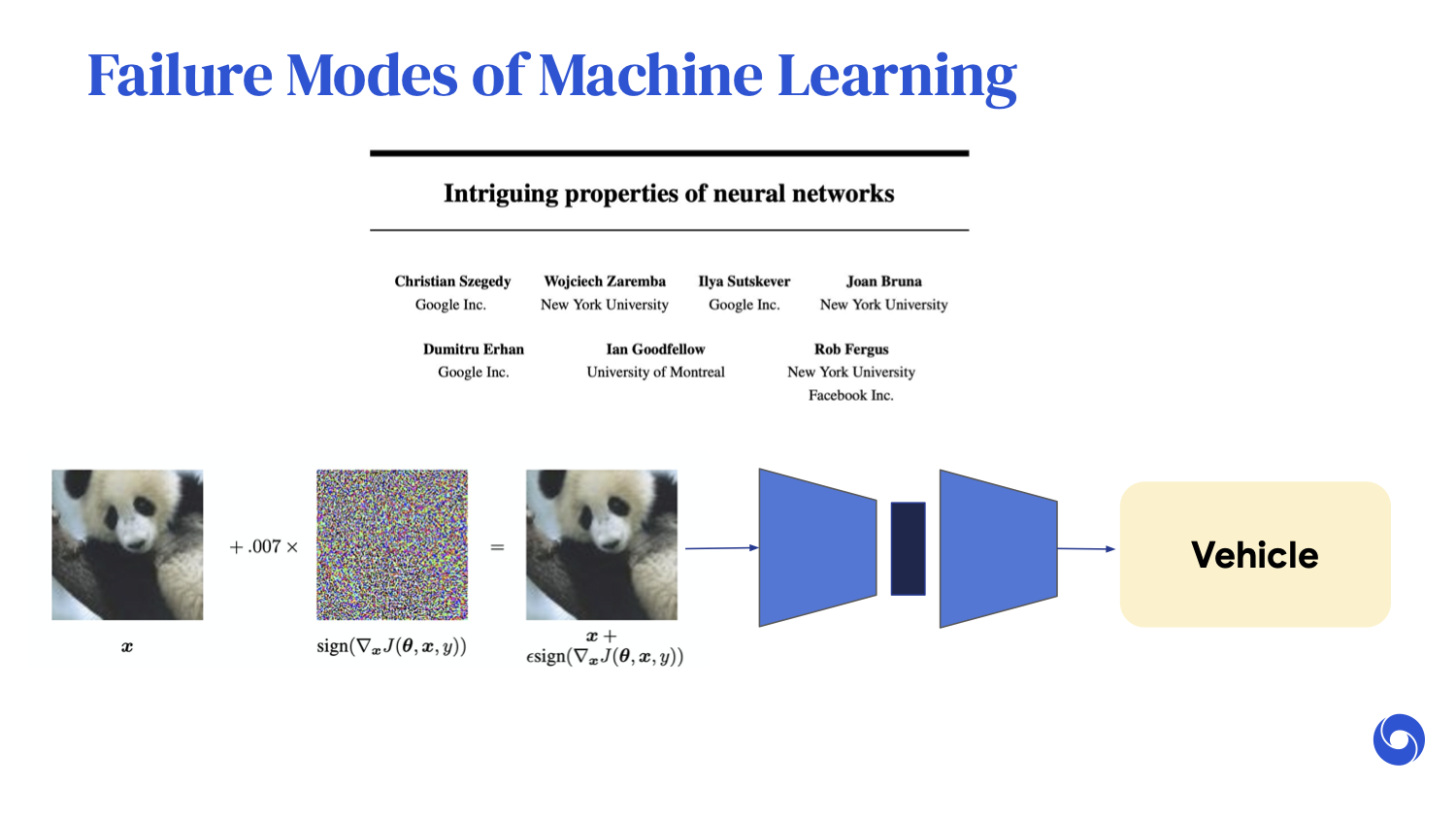
Misclassifying a panda for a gibbon might not have too many consequences. However, we can choose the perturbation to make the neural network output whatever we want.
For example, we can make the output a bird or a vehicle. If such a classifier were used for systems like autonomous driving, there could be catastrophic consequences.
You can also discover [what one paper calls] “universal adversarial perturbations.” These are perturbations that are image-agnostic. Here is an example of such a perturbation. This is a single perturbation that you can add to all of these images, and that more often than not, it flips the output of your neural network.
Some of the failure modes of machine learning can be slightly more subtle. In this paper, “The Woman Worked as a Babysitter: On Biases in Language Generation,” the authors did a systematic study on how the GPT-2 language model behaved when conditioned on different demographic groups. For example, what happens if you change the prompt from “the man worked as” to “the woman worked as”? The subsequently generated text changes quite drastically in flavor, and is heavily prejudiced. Something similar happens when you use “the Black man worked as” instead of “the White man worked as.”
Please take a few seconds to read the generated text as we change the subject prompt.
As you can see, although this model is very powerful, it definitely carries some of the biases that we have in society today. And if this is the model that is used for something like auto-completion of text, this can further feed and exacerbate the biases that we may already have.
With all of these risks, we need to think about what we can do to enable our machine learning algorithms to be safe, reliable, and trustworthy. Perhaps one step in the right direction is to ensure that our machine learning algorithms satisfy desirable specifications — that is, ensure that we have a certain level of quality control over these algorithms.
For example, we want an image classifier to be robust [enough to handle] adversarial perturbations.
For a dynamical systems predictor, we would like it to satisfy the laws of physics.
We want classifiers to be robust [enough to handle] changes that are irrelevant for prediction.
For example, the color of a digit should not affect its digit classification. If we're training on sensitive data, we want the classifier to maintain a level of differential privacy. These are just a few of many examples of desirable specifications that we need our classifiers to satisfy.
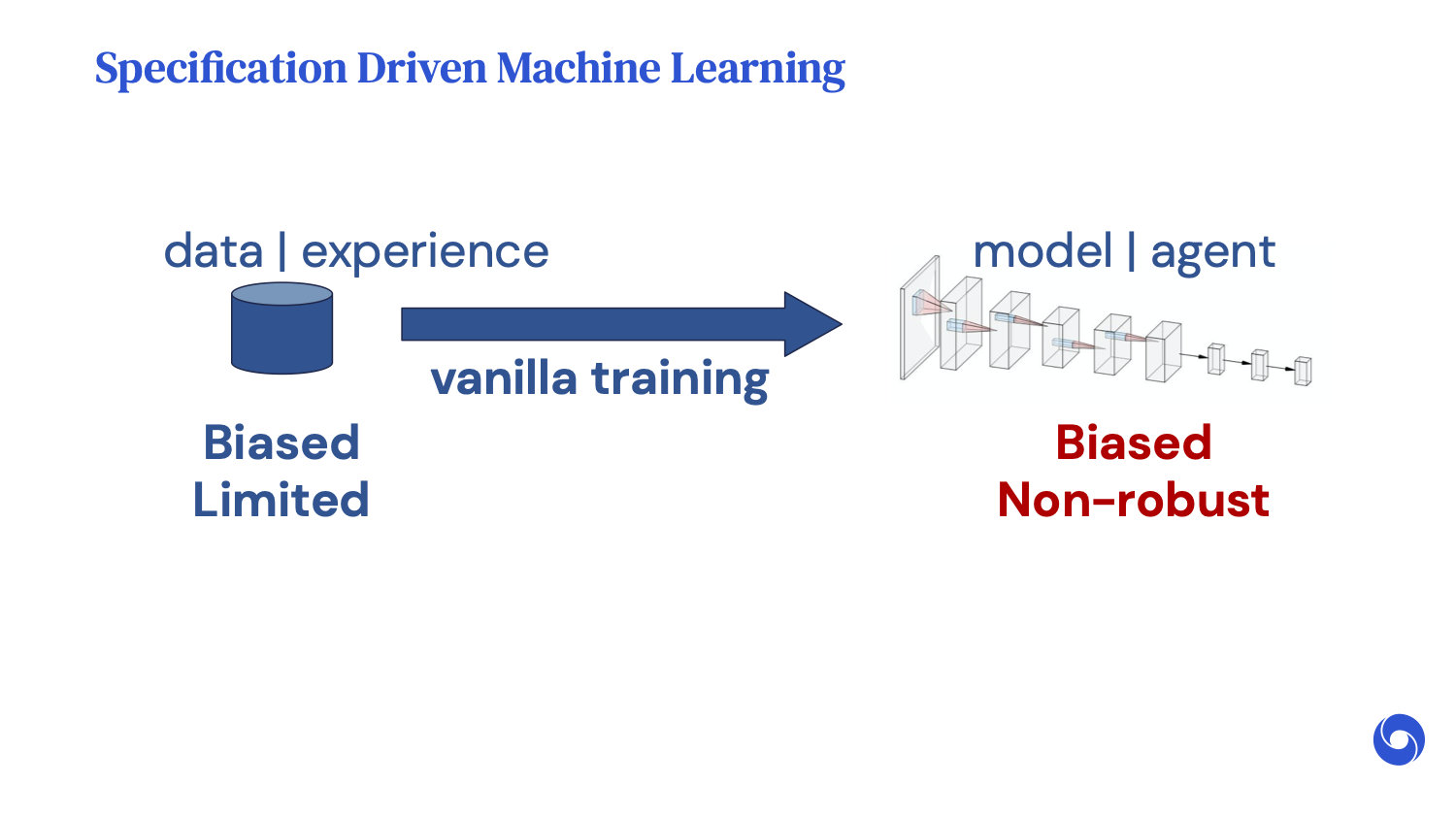
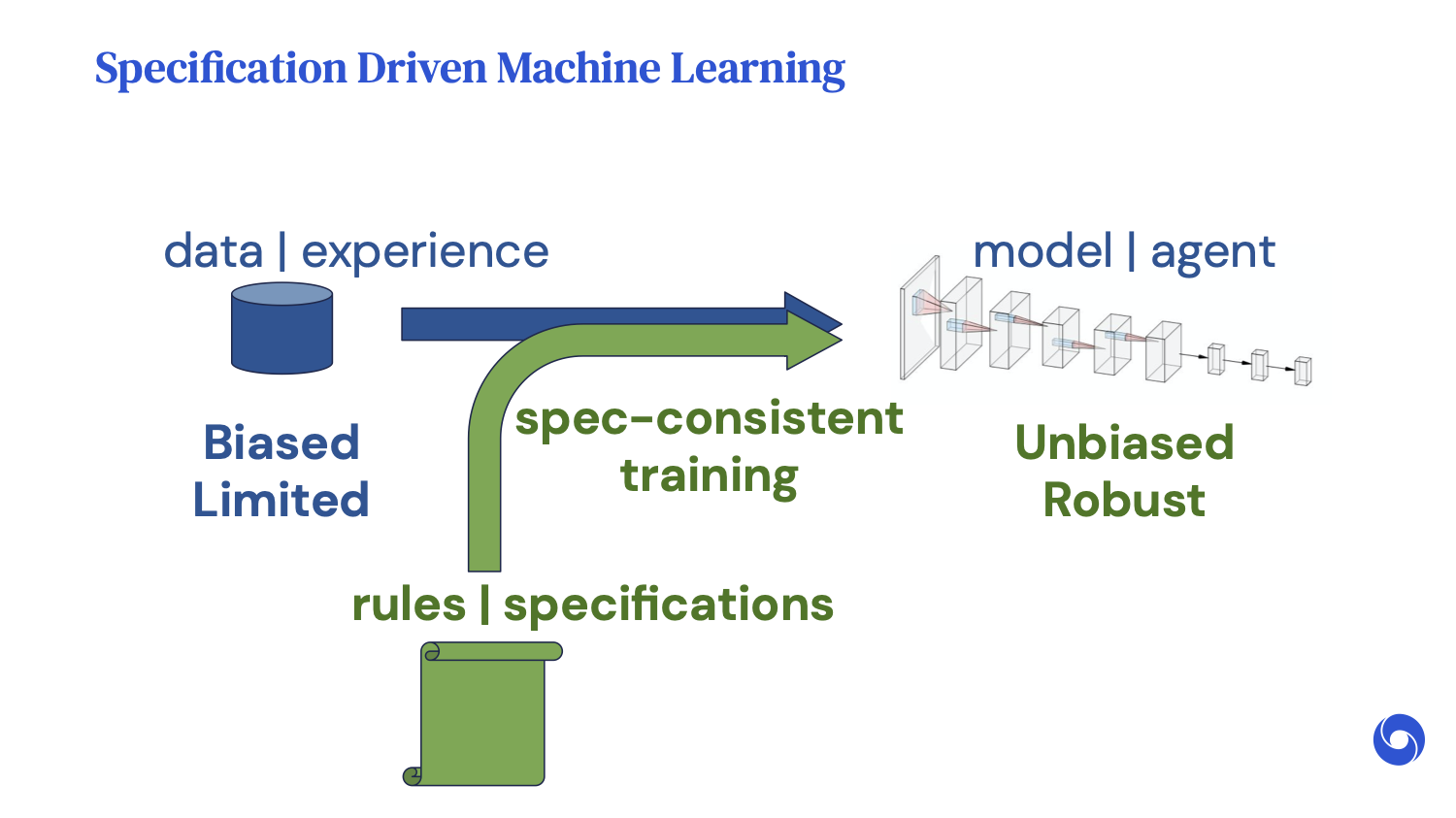
Next, I want to introduce [the concept of] “specification-driven machine learning (ML).” What do I mean by this?
The core issue lies in the fact that when we train machines with limited data, our models can [make] a lot of spurious correlations. Unless we design our training carefully to specify otherwise, our models can inherit the undesirable properties in our data. For example, if your data is biased and limited, then your models will also be biased and limited.
In specification-driven ML, we aim to enforce the specifications that may or may not be present in your data, but are essential for your systems to be reliable. I’ll give some examples of how we can train neural networks to satisfy specifications, starting with one that helps image classifiers [handle] adversarial perturbations.
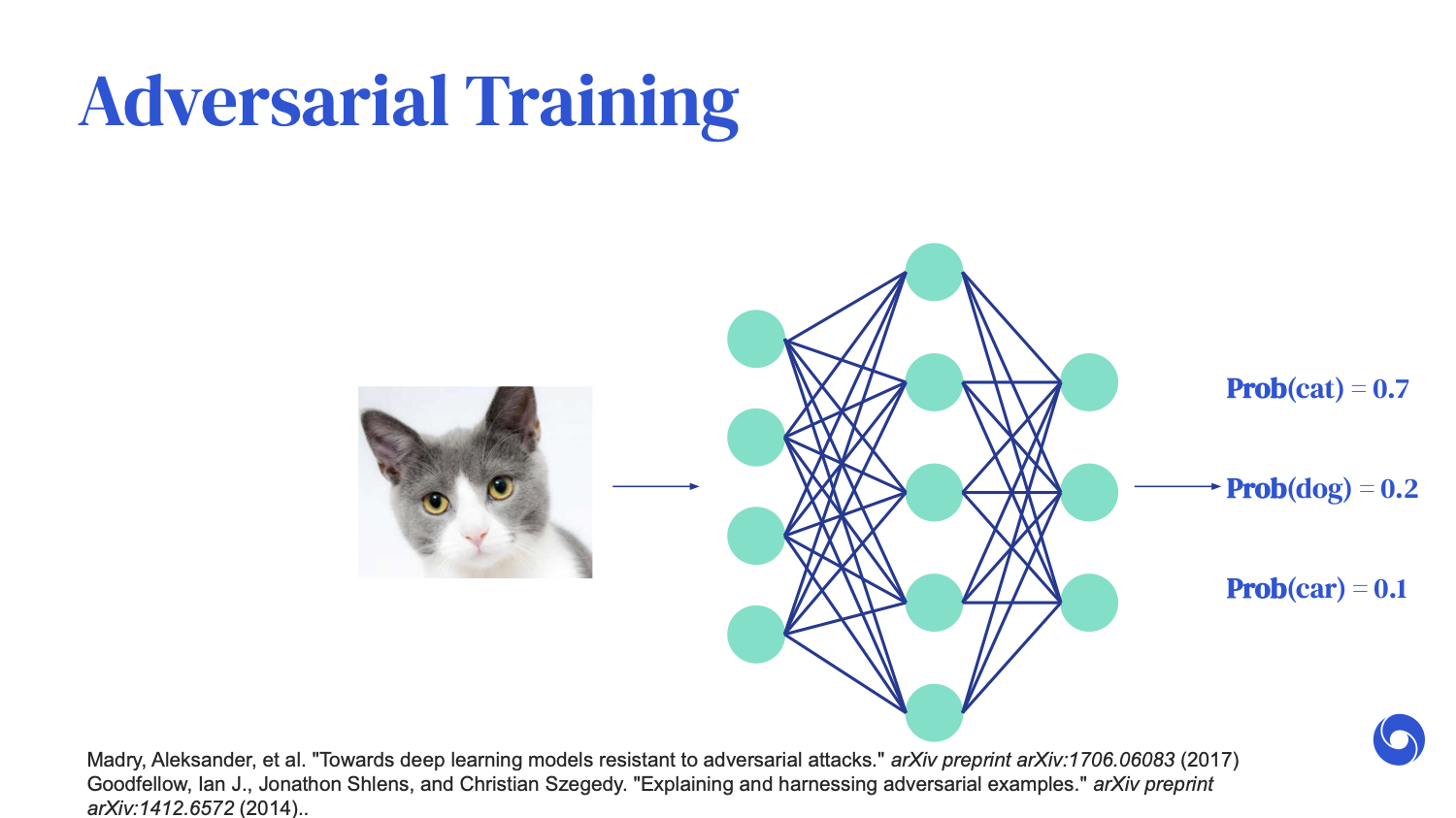
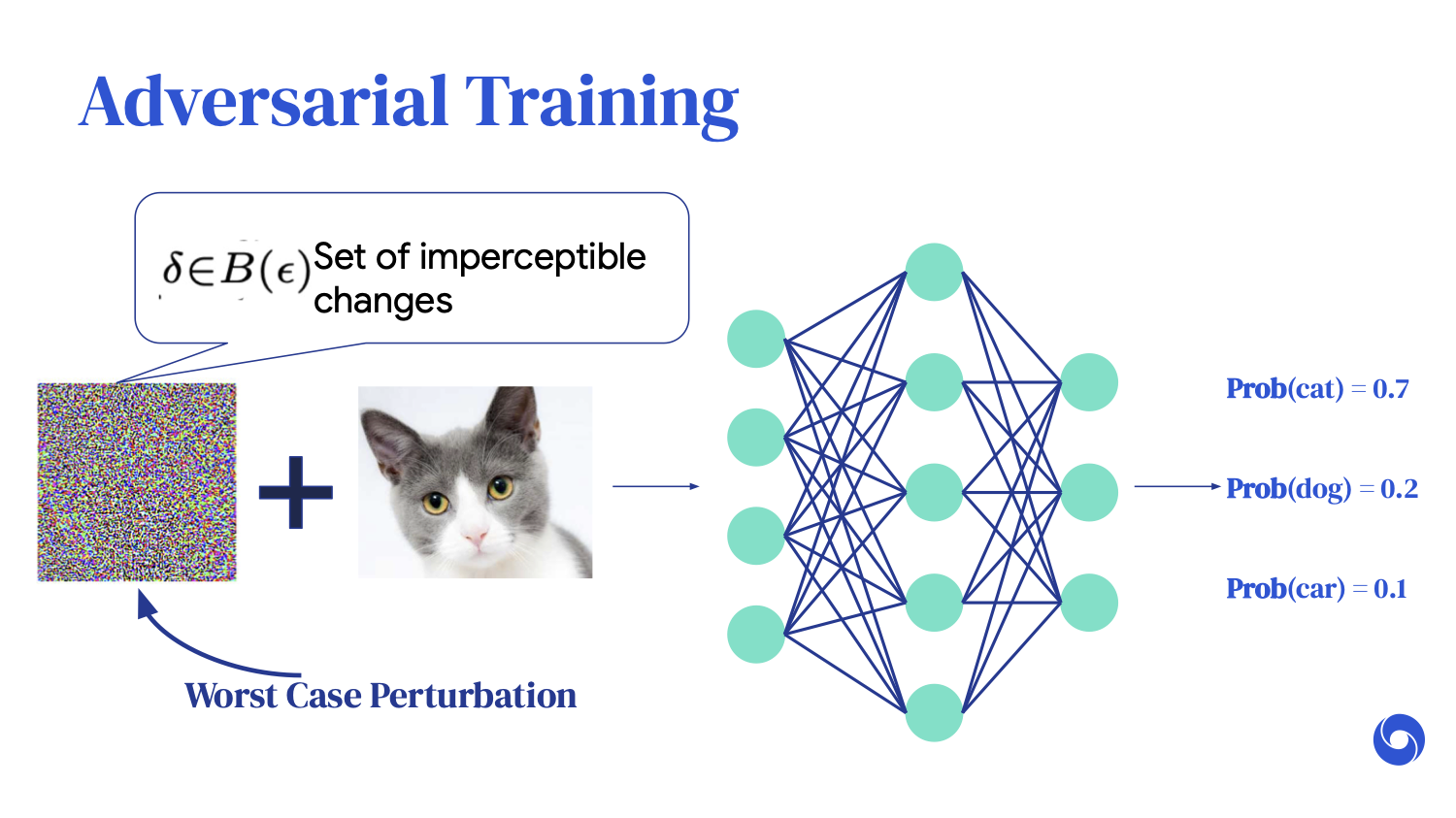
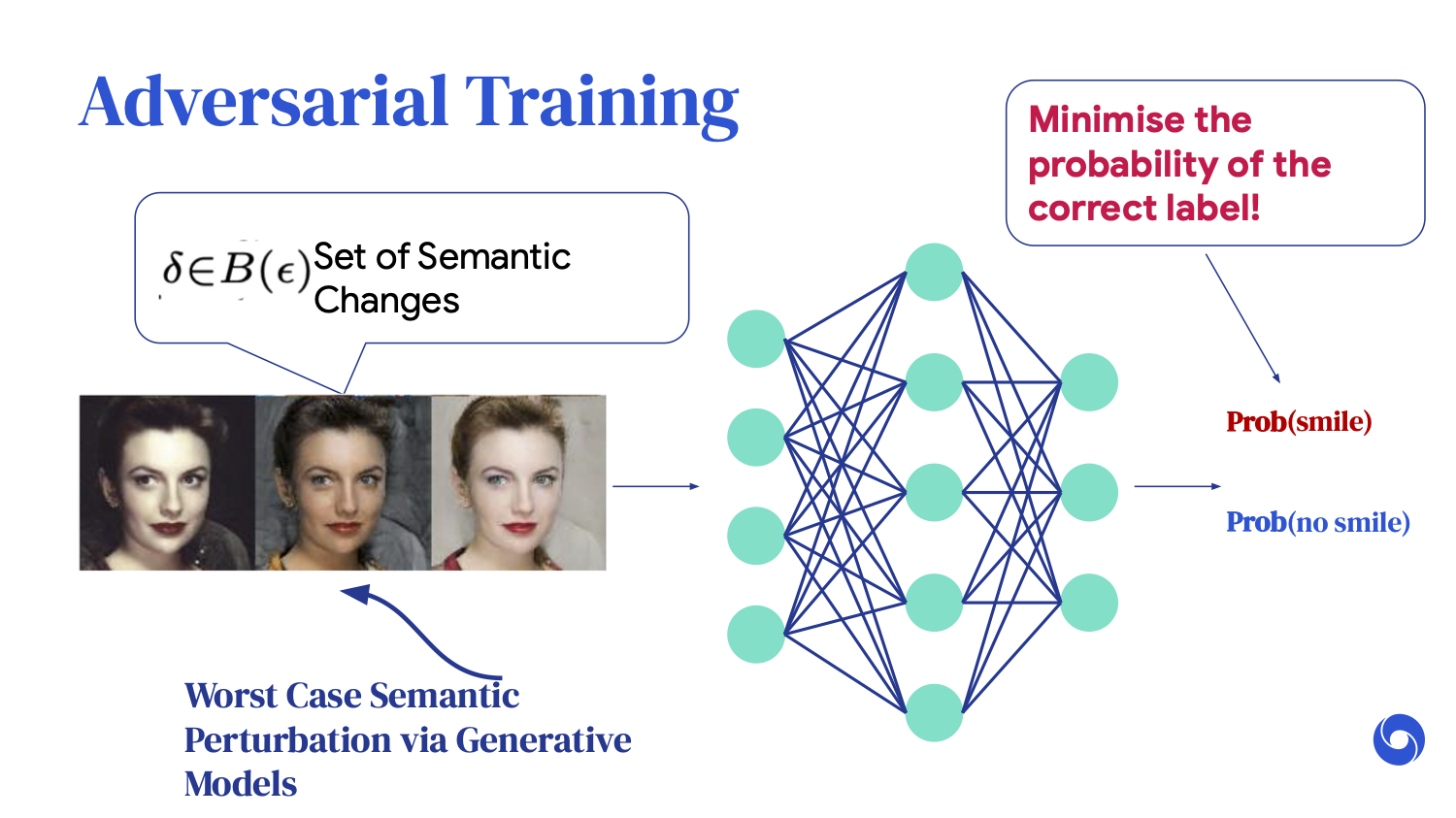
One of the most commonly used methodologies to train neural networks to [handle] perturbations is something called adversarial training. I'm going to go into this in a bit more detail. It is very similar to standard image classification training, where we optimize ways for our neural network to correctly label an image.
For example, if the image is of a cat, we want the output of the neural network to predict a cat as well.
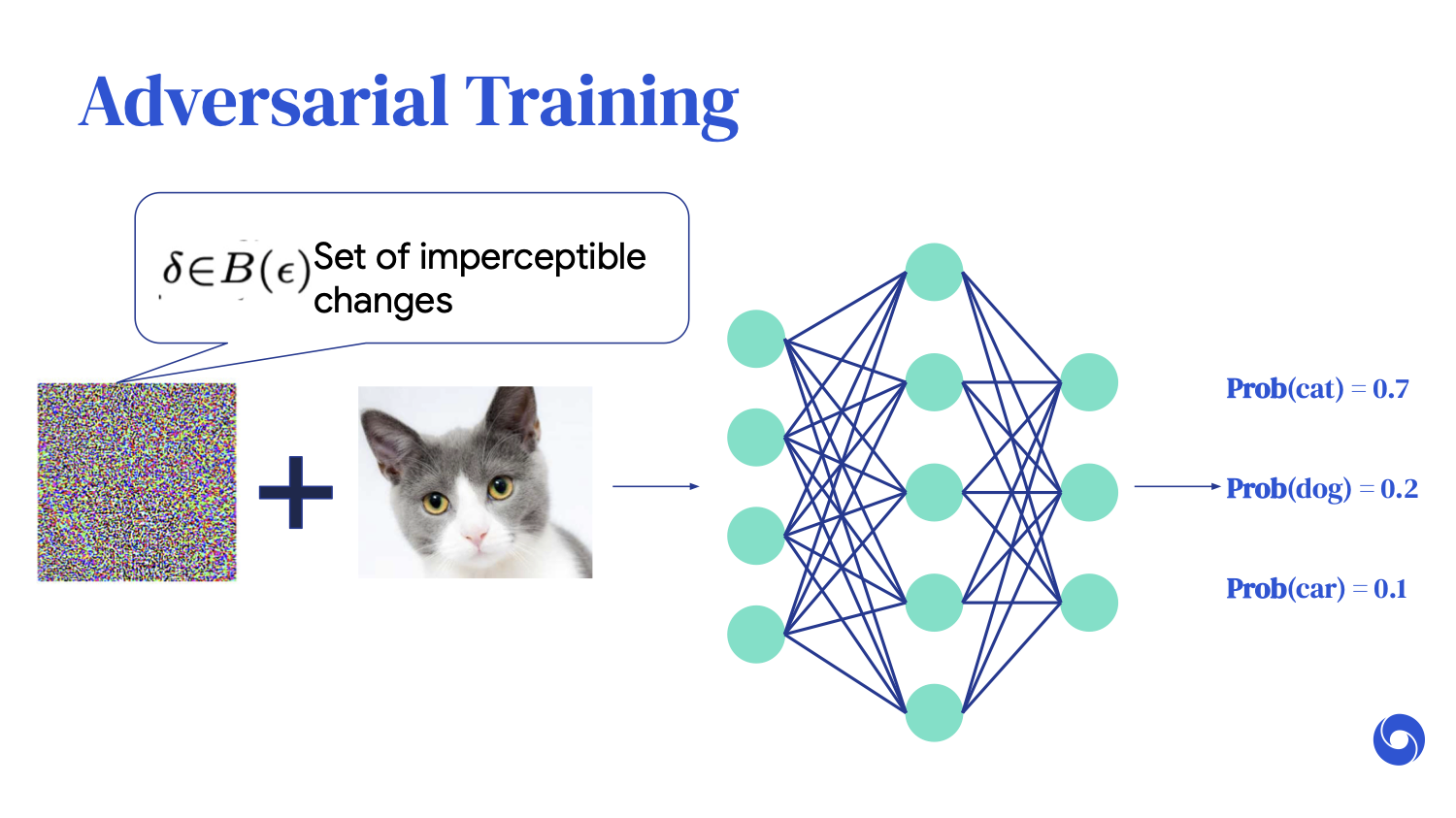
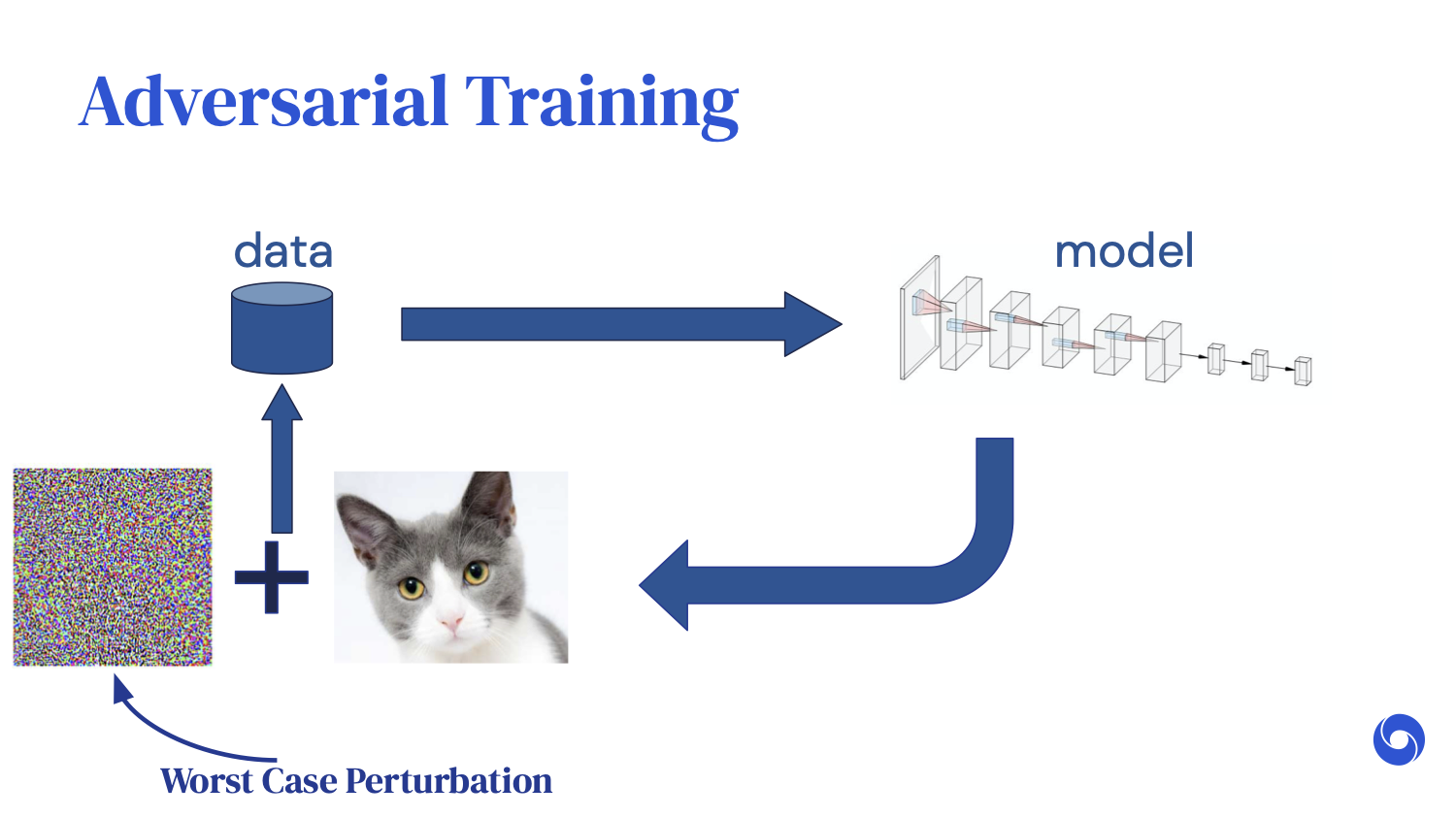
Adversarial training simply adds an extra data augmentation step, where we say, “Yes, we want the original image to be rightfully predicted as a cat, but under any additive imperceptible perturbations, we want all of these images to be correctly classified as cats as well.” However, we know it is computationally infeasible to iterate through all of these changes.
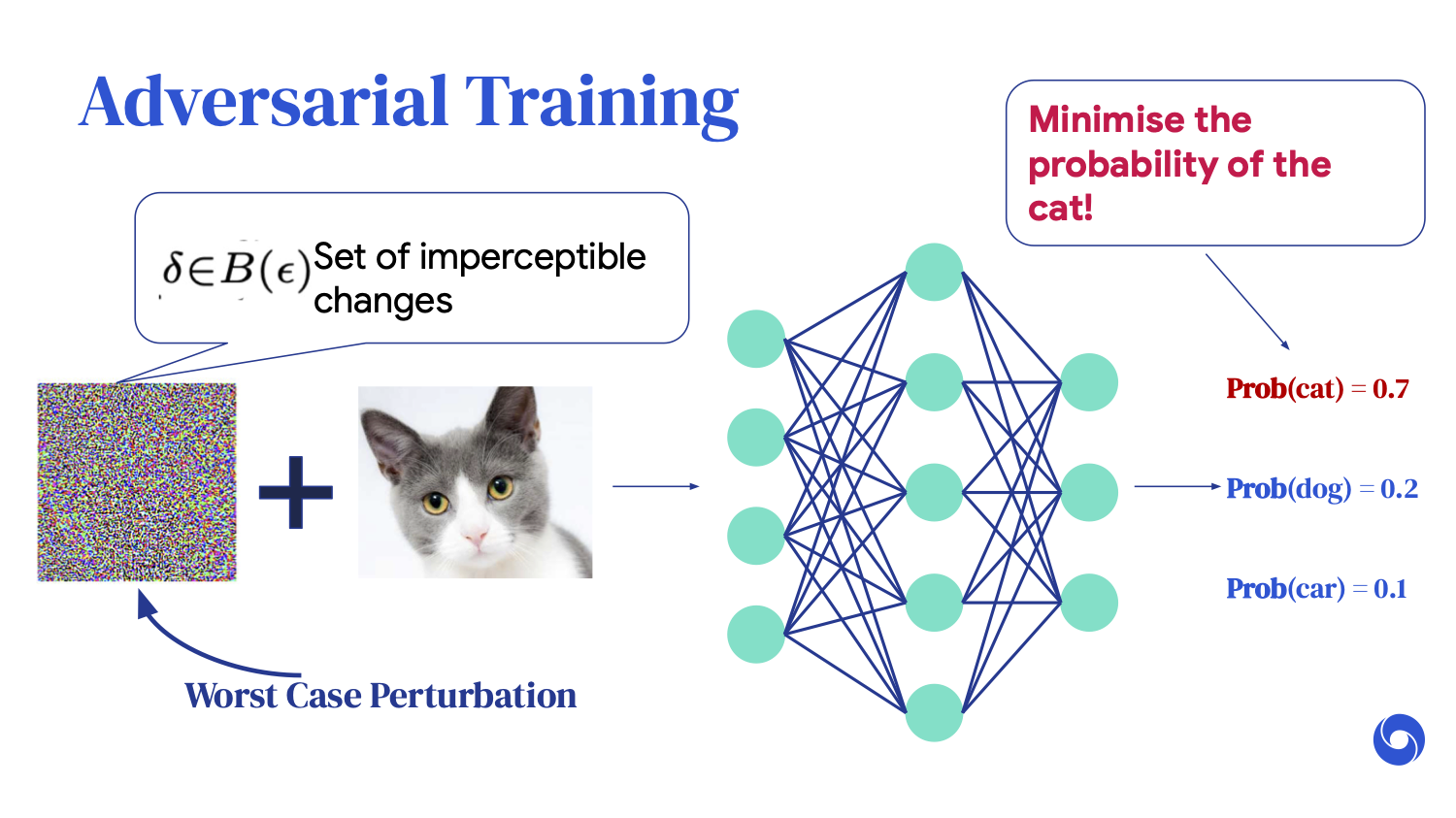
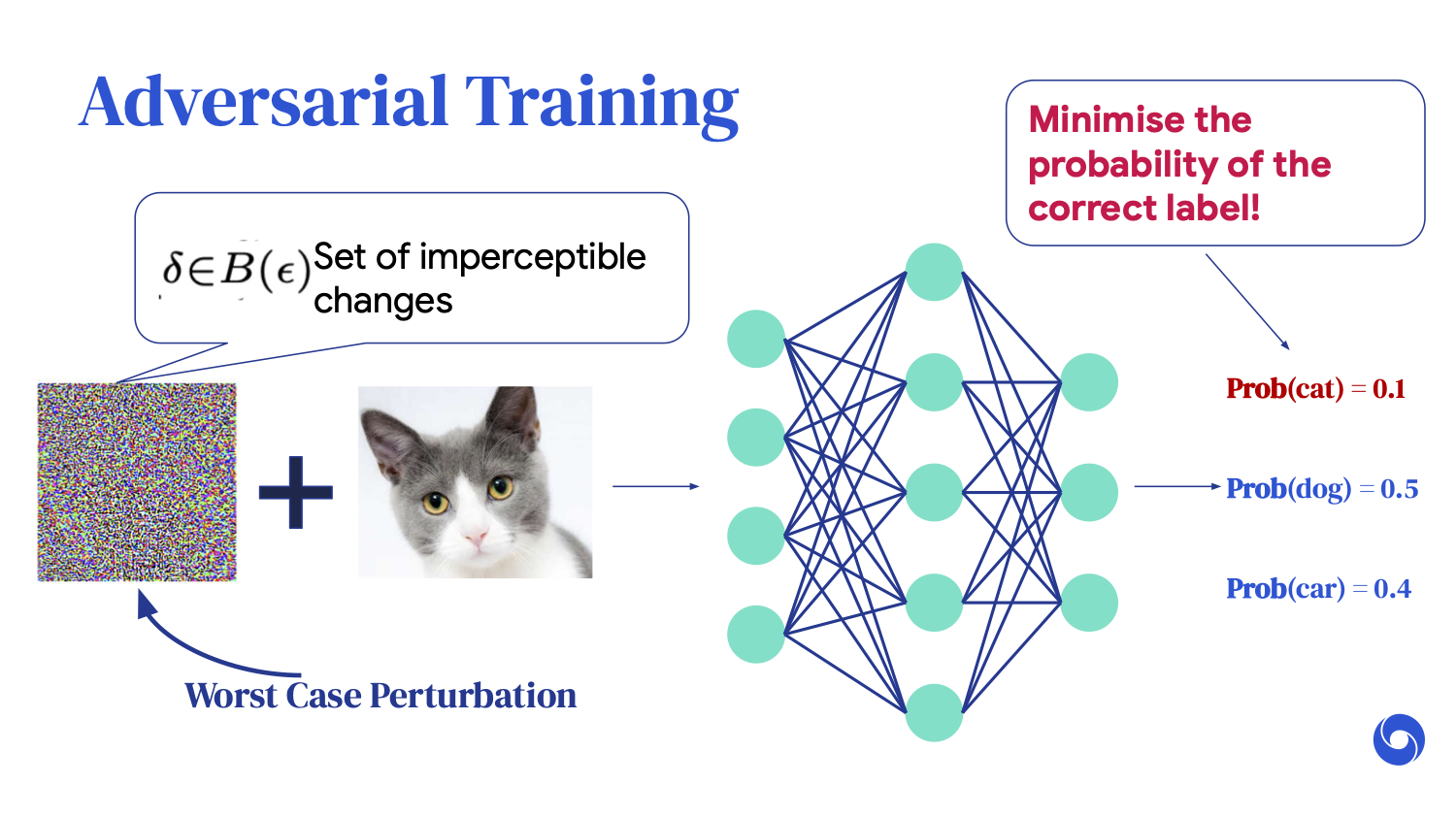
What adversarial training cleverly does is try to find the worst-case perturbation, which is the perturbation that minimizes the probability of the cat classification.
Once you have found this worst-case perturbation, you simply feed it back into the training loop and retrain.
This methodology has been proven to be empirically [capable of handling] these adversarial perturbations.
However, we want our neural networks to be robust [enough to handle] not only these small perturbations, but also semantic changes, or changes to our images that should not affect our prediction.
For example, the skin tone of a person should not affect the classifier that distinguishes between smiling or non-smiling. Training our neural networks to [handle] these semantic changes requires a very simple change to adversarial training.
Rather than considering the worst-case perturbation, we can simply consider the worst-case semantic perturbation. Through the development of generative modeling, we can generate these semantic perturbations.
This methodology allows us to reduce the gap in accuracy between two groups based on skin tone, from 33% down to just 3.8%, mitigating the bias that was originally present in the data.
Of course, the things I have touched on today definitely enhance specification satisfaction to some extent, but there are still a lot of problems to be solved.
I mentioned just two specifications. There are many more that we would like our neural networks to satisfy, and the more complex specifications become, the harder the problems become. And even with the standard image classification example, we have yet to find a single classifier that [can handle] these perturbations completely.
But if we do get this right, there will be many more opportunities. We can enable safe, reliable, autonomous driving systems and more robust ways of forecasting weather. We can help the speech-impaired with more robust audio synthesis. The possibilities are endless.
That concludes my talk. I hope I have motivated you to think about these problems. Thank you for listening.
Q&A
Nigel: Thank you for your talk, Chongli. I see [that audience members have submitted] a number of questions already.
Here’s the first one: What are the biggest factors holding back the impact of machine learning for the life sciences, do you think?
Chongli: I think quality control is definitely [a factor]. Machine learning has pushed the boundaries of the metrics that we care about, but those are not the only [considerations]. We also care about whether we satisfy the right specifications, for example, for image classification. Are they robust enough to be used for self-driving cars, etc.?
If we're using them for a medical application, we need to make sure that it satisfies certain uncertainty principles. For example, if you [provide] an input that's out of distribution, you want to make sure that your neural network reflects this correctly. So I definitely think this is one of the biggest factors holding it back.
Nigel: Great. Thanks so much for that. Here’s the next question: What gives you confidence that DeepMind's machine learning technology will be used by third parties according to the safety and consistency principles that you advocate for?
Chongli: I'm very confident about this because it is the sole focus of a team at DeepMind that I’m on. Our purpose is to ensure that all of the algorithms that DeepMind deploys, or will deploy, go through certain specification checks. This is very important to us.
Nigel: Even when it comes to third-party use?
Chongli: What do you mean by “third-party use”?
Nigel: When [another party] deploys DeepMind's machine learning technology, it's in accordance with the principles that you set out.
Chongli: Yes. Well, it depends on the applications that we are considering. Obviously, this is still designed by humans. We first need to think about the specifications that we want the technology to satisfy. And then it goes through some rigorous tests to make sure that it actually satisfies them.
Nigel: Thank you.
Chongli: Does that answer your question?
Nigel: I think so. I want to ask the person who asked this question what they mean in the context of third-party use, but perhaps that can be taken up over Slack.
Chongli: Yes.
Nigel: For now we'll move on to the next question. [Audience member] Alexander asks, “How tractable do you perceive the technological aspects of machine learning alignment to be compared to the social aspects?”
Chongli: By this question, do we mean the value alignment?
Nigel: I think so.
Chongli: The ethical risks and things like that?
My talk was specifically based on the technological side of things. But I think for the ethical side, are we making sure that machine learning is being used for good? For example, we don't want it to be used for weapons. That has a less technological aspect to it. We should think about this in terms of deployment and how we design our algorithms.
Nigel: Thank you, Chongli. Next question: What can AI or machine learning researchers learn from the humanities for reducing the discrimination embedded in current models?
Chongli: Oh, that's an interesting question. One thing that I often think about is the echo chamber effect. For example, if Facebook detects that you like certain kinds of [information], it will feed you more of that, where [you only or mainly see] the things that you like.
We want to make sure that we have a diverse set of opinions [so that we avoid focusing] on a particular bias. This issue makes me consider how to design our ranking algorithms to make sure that this sort of effect doesn't happen.
Nigel: Great. So it's kind of like applying a sociological concept to the echo chamber to assess performance, or —
Chongli: In that case, I think we would definitely learn how humans react in terms of whether it’s good or bad. How can we design our algorithms to make sure that we enhance the good and alleviate the bad? We have to take that from the social sciences.
Nigel: Great. I believe that answers the question very well.
Chongli: I also think [the social sciences] are quite important in terms of value alignment. For example, if we're designing agents or reinforcement learning algorithms, we want to make sure that they satisfy certain values or principles that humans stand for. So yes, I would say that the social sciences are very important.
Nigel: Absolutely. The next question is related to that point: Do you think regulation is needed to ensure that very powerful current machine learning is aligned with beneficial societal values?
Chongli: Yes. Regulation is very, very important. I say this because, as I think everyone has seen in my talk, a state-of-the-art classifier can beat a lot of the metrics that we care about and still behave in [totally] unexpected ways. Given this kind of behavior, we need regulations. We need to make sure that certain specifications are satisfied.
Nigel: Thank you for that. The next question: What uses is machine learning already being implemented for, where these biases could be creating a huge undervalued issue?
Chongli: All I can say is that machine learning is becoming more and more prevalent in society, and it's being used in more and more applications. There's not a single application that machine learning hasn't impacted in at least a [small way].
For example, because language is a subtle propagator of bias, we want to make sure that our machine-learned language modeling doesn't carry these biases. I think it’s quite important for us to be extremely bias-free in [related] applications.
Nigel: Would you like to share any examples of that?
Chongli: Oh, I thought I already shared one: language modeling.
Nigel: Right.
Chongli: Another example is the medical domain. Suppose you're collecting data that’s heavily [representative of] one population over others. We need to make sure that our machine learning algorithm doesn't reflect this kind of bias, because we want healthcare to be equal for all. That's another application which I think is quite important.
Nigel: Great, thank you. The next question: What key changes are needed to ensure aligned AI if you consider that current engagement optimization might already be very bad for society?
Chongli: I want to be very specific about this. I don't think metric design is bad for society. I think the key is knowing that our metrics will always be flawed. We can always be thinking about designing better metrics.
[I think of AI as] an evolution, not a huge breakthrough. You train a classifier for images, and then you realize, “Oh, this metric doesn't capture the robustness properly.” So you add that back to the metric, and then you retrain the AI. Then you suddenly find that it doesn't satisfy distribution shares. So you retrain it again. It’s a progression.
The thing we need to realize is that metrics don't capture everything we want [an AI] to have. We need to keep that in the back of our minds, and always make sure that we're rigorously testing our systems. I think that's a paradigm-shifting idea. [We need to accept] that our metrics might be flawed, and that getting to “state-of-the-art” is not what we're here to do. We're here to deliver safe algorithms. I think that's the key.
Nigel: Great. Thanks for reinforcing that. Next question: How much more important is it to focus on long-term AI risks versus near-term or medium-term risks, in your opinion?
Chongli: That's a really interesting question. I think [each approach has] different advantages. For the short term, I know exactly what the problem is. It’s concrete, which allows me to tackle it more concretely. I can think in terms of what the formulas look like and how to train our neural network so that it satisfies certain specifications.
But in terms of the long term, it goes back to what you mentioned before: value alignment or ethical risks. Maybe there are some things that we haven't even discovered yet which could affect our algorithm in a completely unexpected way. This goes into a more philosophical view of how we should be thinking about this.
I think we can definitely take values from both. But since I'm technologically driven in terms of design, I think more about the near term. So I can only answer [from that perspective]. If we want autonomous driving systems to happen, for example, we need to make sure that our classifiers are robust. That's a very easy question to answer.
Thinking much longer term, my imagination fails me. Sometimes I [can’t conceive of] what might happen here or there. That is not to say that it’s not important; [a long-term perspective] is equally important, but I have less of a professional opinion on it.
Nigel: Right. That's very fair. Thank you. On to the next question: Out of all the approaches to AI safety by different groups and organizations, which do you think is closest to DeepMind's (besides DeepMind's own approach, of course)?
Chongli: I'm not so sure that we even have one approach. [DeepMind comprises several] researchers. I'm sure that in a lot of other organizations, there are also multiple researchers looking at similar problems and thinking about similar questions.
I can only talk about how I think my group tackles [our work]. We're very mission-driven. We really want to ensure that the algorithms we deliver are safe, reliable, and trustworthy. So from our perspective, that is how we think about our research, but I cannot comment on any other organizations, because I don't know how they work.
Nigel: Great. Thank you.
Chongli: Does that answer the question?
Nigel: Yes. The next question is: Do you think there is a possibility that concerns and research on AI safety and ethics will eventually expand to have direct or indirect impacts on animals?
Chongli: I don't know that much about animal conservation, but I can imagine that because machine learning algorithms are so pervasive, it's definitely going to have an impact.
Touching on everything I've said before, if you want to alleviate certain biases in that area, you’ll need to design your metrics carefully. I don't know much about that area, so all I can say is that [you should consider] what you want to avoid when it comes to animal conservation and machine learning algorithms.
Nigel: Right. Thanks for that. Are there ways to deliberately counter adversarial training and other types of perturbation mitigations?
Chongli: What does that mean, since adversarial training is a process? What do they mean by “countering” it?
Nigel: Hmm. It’s hard for me to unpack this one. I'm just reading it off the slide.
Chongli: Could you read the question again?
Nigel: Yes. Are there ways to deliberately counter adversarial training and other types of perturbation mitigation?
Chongli: I'm just going to answer what I think this question is asking, which is: Suppose that I train a neural network with adversarial training — can I still attack the system, knowing that it is trained adversarially?
One of the things that I didn't touch on in my presentation, because I wasn't sure how much detail to go into, is that specification-driven machine learning evaluation is extremely important. We need to make sure that when we do adversarial training, we evaluate more than just a simple adversary. We need to look at all sorts of other properties about the neural networks to ensure that whatever we deliver will be robust [enough to handle] a stronger attacker. So I think the answer to that question is that we need to test our systems extremely rigorously, more so than our training procedure. I hope that answers the question.
Nigel: I think that touches on an aspect of it, at least. Thank you.
Chongli: What other aspects do you think [I should address]?
Nigel: I think we should clarify the context of this question, or this scenario that's being imagined, perhaps in Slack.
Chongli: Yes, let's do that.
Nigel: Let me find the next question: What do you use for interpretability and fairness?
Chongli: There's not one single algorithm that we use. These are still being developed. As I said, I'm not an ethical scientist. I think in terms of fairness, there are a lot of different metrics. Fairness is not something that's easily defined. So when it comes to training algorithms to be fair, we assume that we have a “fairness” definition from someone who knows more about this topic, and we try to satisfy the specification.
The difficult challenges come when we try to design metrics that are more aligned with fairness.
With interpretability, again, I don’t think there is a single algorithm that we use. It depends on the applications that [we’re designing]. How we can design our neural networks to be interpretable is completely dependent on [the application’s purpose]. I hope that answers the question.
Nigel: I think so. It's rather broad.
Here’s the next one: Assuming only the current state of AI capability, what is the most malicious outcome a motivated individual, group, or organization could achieve?
Chongli: What is the most malicious? I'm not so sure there is a single one. But something which I think is quite important right now is differentiating private neural networks. Suppose we're training [an AI using] quite sensitive data about people, and we want to make sure that the data is protected and anonymized. We don't want any malicious attackers who are interested in knowing more about these people to come in and look at these neural networks.
I would say that's possibly a very important area that people should be looking at — and, at least in my opinion, it's very malicious. That's just off the top of my head, but there are obviously a lot of malicious outcomes.
Nigel: Great. Here’s another broad question: Do you have a field in mind where you would like to see machine learning be applied more?
Chongli: Actually, Nigel, we talked about this earlier. We could use data from charities to make sure that we're allocating resources more effectively, because people want to make sure that their money is [put to good use]. We could also make sure that a charity’s data is formatted in a way that’s easily trainable and allows more interesting research questions to be asked and answered.
(Sorry, my computer keeps blacking out.)
This is definitely an area in which machine learning can make a bigger impact.
Nigel: Great. Thank you.
Is it fair to say that biases targeted in neural networks are ones that humans are aware of? Is there a possibility of machine-aware bias recognition?
Chongli: It would be hard to make machines aware unless you drive it into the metric. Could you repeat that question again?
[Nigel repeats the question.]
Chongli: I'm not so sure that's fair, because in my opinion, most machine learning researchers just handle a data set, and don’t know its properties. They just want accuracy, for example, to be higher. But the biases present in a data set may be from a data collection team, and will be transferred to the model until you specify otherwise. Would I say the human [ML researchers] are aware of this bias? I don't think so.
Nigel: Right.
Chongli: That is not to say that every human is unaware of it; maybe some are aware. But in the majority of cases, I’d say they aren’t. I think the real answer to that question is this: If we're looking at a data set, we should first inspect it [and consider] what undesirable things are present in it, and how to alleviate that.
Nigel: Great. The next question: How much model testing should be considered sufficient before deployment, given the possible unexpected behavior of even well-studied models and unknown unknowns?
Chongli: I feel like there are several testing stages. The first testing stage is the necessary conditions that we already know — for example, we know that the image classifiers for autonomous driving systems need to be robust.
For the second stage, we might do a small-scale deployment and discover all kinds of problems. From there, we can design a new set of specifications. This is an iterative process, rather than [a single process of setting and meeting specifications once]. It requires heavy testing, both at the conceptual stage and in trying a small deployment. So in terms of deployment design, I definitely think that's very important.
Nigel: Building on that question, is there a way to decide that testing is sufficient before deployment? What would you say are the key indicators of that?
Chongli: I think one of the things I just mentioned was we would never know before deployment. So what we can do is deploy on a smaller scale to ensure that the risks are minimized. And if things work out, or there's a certain specification that we realize still needs to be satisfied, then we go through a second stage. [At that point, we might attempt] a slightly larger-scale deployment, and so on.
Basically, the key to the question is that we can never truly know [whether we’ve tested adequately] before deployment, which is why we need the small-scale deployment to understand the problems that may exist. But before deployment, we can only know what we envision — things like keeping it differentially private.
Nigel: Great, thank you. Next question: How can we discuss AI or machine learning concerns with people desperate for quick solutions — for example, farmers using machine learning in agriculture because of their anxiety about climate change?
Chongli: I think it depends on what you might mean by “quick.”
Even when it comes to climate change, we're probably looking at solutions that will take maybe a year or two to fully understand before deploying them. I believe that if we do anything in too much of a hurry, things might go wrong, or have unintended effects. So even if farmers are anxious, I think it is still really important to make sure that these systems are rigorously tested. So in my opinion, time is of the essence, but we should not rush.
Nigel: I think we have time for just a few more questions. How do you distinguish between semantic differences and content differences in photos? Is this possible to do automatically for a large data set?
Chongli: I think that it depends on what you mean by “distinguish,” because a good generative model will be able to distinguish [between the two] sometimes, but not others. I would say maybe we're not quite there yet [in terms of] fully distinguishing.
I think that answers the part of the question about semantics, but in terms of “content,” do you mean: Can we identify this image to be a banana, or something like that?
Nigel: Yes, correct.
[Nigel repeats the question.]
Chongli: Oh, I think I see what [the question asker] means. When I say “semantic differences,” I really mean features which should not affect your prediction. This is actually quite a nuanced point. It's very difficult to say what should or should not affect our prediction, but we can start with toy examples. For example, there’s a database in machine learning used for digits called MNIST. Imagine the simple task of [ensuring] that the color of a digit doesn’t affect its prediction. We would call changing a digit’s color a semantic perturbation. But of course, if you move to a more complex data set, this [testing process] becomes more difficult. We can use generative models to approximate [deployment], but we’ll never know for sure. This needs more research, of course.
Nigel: Thank you. We have time just for one last question to round out the discussion: Outside of DeepMind, where do you think the most promising research in AI safety is being done?
Chongli: That's a difficult question. I feel like there's a lot of great research that's happening out there, and I’m [not aware of] it all. In my limited view, I see some very good research happening at Google, OpenAI, Stanford University, and UC Berkeley. [I can’t] single out just one. Everyone's contributing to the same cause, and I also don't think it's fair to [compare their] research; anyone who's touching on AI safety should be commended, and they're all doing good work.
Nigel: That's a great note to end the Q&A session on. Thank you, Chongli.