Comments
Eva Vivalt, a researcher at the Australian National University, believes “there's a whole wealth of [hidden] information that people use to come to certain decisions or beliefs.” With this in mind, she is helping to build a platform to collect that information — specifically, people’s predictions about the results of social science experiments. In this talk, she discusses what social science stands to gain through the use of forecasting, from better research design to less biased decisions about which studies to publish.
Below is a transcript of Eva’s talk, which we have lightly edited for clarity. You can also watch the talk on YouTube or read it on effectivealtruism.org.
The Talk
I'm very excited to be presenting on predicting results in the social sciences.
I have a thought experiment for you. Suppose you're a policymaker and you're trying to decide which of two programs to support: cash transfers or a school meals program.

Your goal is to improve enrollment rates in school. This is a bit of an unusual example because we have a lot of randomized controlled trials (RCTs) on both of those program types, so it is a best-case scenario. Nonetheless, you may think that results are going to be different in your particular context. And even in the unlikely event that you do have an RCT for your particular context, it’s from the past; your current situation is still going to be different.
I don’t need to go into external validity too much, but essentially, researchers worry that existing studies may not be perfectly informative. The results may not extrapolate very well from one setting to another. In some past work, I've found that if you use a database of existing impact evaluations to try to predict the effect of a particular study, you can expect to be off by more than 100%. So the effect is X, plus or minus X. That's not very encouraging.
What can we do in this situation? Well, some of my collaborators, Stefano DellaVigna and Devin Pope, ran an experiment on Amazon's Mechanical Turk in which they asked people to press letters on their keyboards — A, B, A, B, A, B — as fast as they could for 10 minutes. They incentivized participants using different kinds of schemes.
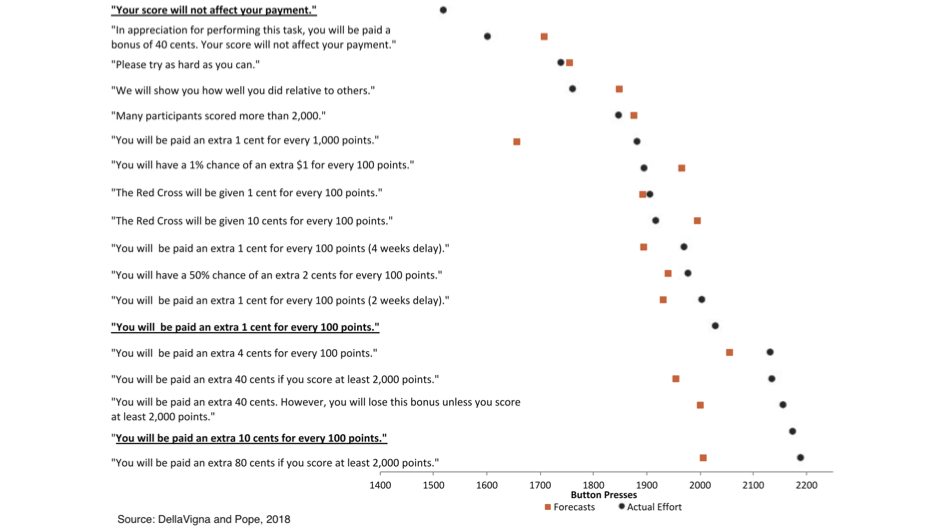
For example, you might be paid an extra 1 cent for every 100 points you got with a four-week delay, or an extra 1 cent for every 100 points with a two-week delay, and so on. This was a really useful experiment, because it allowed the researchers to back up some things like time preferences. Then, before showing participants the results, they asked them to predict what the results would be. And they found that, while there was a difference between [the results and the predictions], there still was some correlation there.
My belief is that as long as prior beliefs [used to make predictions] are at least somewhat informative, it's worth gathering them and trying to use them as an additional source of information in our decision-making process. They can be especially useful when we don't have an RCT. Remember that example I gave of cash transfers versus school meals programs? We have a lot of evidence on that, but the situation is more dire for most of the things that we care about.
So, we've been setting up a social science prediction platform that gathers ex-ante beliefs about the effects of various interventions.
It may cover the effects of a cash-transfer program, a certain behavioral treatment, or whatever else you prefer.
Forecasters aren’t just researchers; they could also be policymakers, politicians, or the general public. The people we ask depends on the project itself.

For example, I’m working on Y Combinator’s basic-income study. It's really important to get the priors of the general public for that study, because those are highly relevant [to how we expect basic-income recipients to actually use the money].
Now, what types of priors do we mean?

We mean treatment effects. For example, will a certain cash-transfer program [with benefits contingent on, say, enrolling one’s children in school] improve enrollment rates by five percentage points? Six percentage points? We're also interested in distributions of priors — not just your best guess, but also your uncertainty and the whole distribution of your priors.
That's not to say these are the only things we're going to be gathering. There is also some interest in more binary types of measures. Dean Karlan, who is also involved, is an advocate of asking policymakers, “Will it work or not?” That question might be one that policymakers find more intuitive. But ideally, we'd like this to be more fine-grained, especially for researchers.
I think there's an argument to be made for taking priors seriously.

That might seem like taking a step backwards. We do RCTs in the first place because we know that sometimes we're wrong. So, why am I suggesting that we still use priors? Ultimately, I think that people do know a lot. There's a whole wealth of information that people use to come to certain decisions or beliefs, and people naturally aggregate that information [in a way that would be hard for them to explain].
This can be really important because the world is messy. I mentioned earlier the external validity problem, where different interventions can have different effects on different outcomes in different contexts.

Generally speaking, you're not able to say that one intervention is necessarily better at achieving a particular outcome than others. The issue is there's not going to be enough data to support your model. What I would love is to be able to say, “This conditional cash transfer had this effect, in this context, because it was implemented in a place where baseline enrollment rates were really low, and this amount was given in the cash transfer, and they had these conditions from the government.” I’d like to be able to list out a whole range of reasons why I think the program will have a certain effect in a certain area — and why another program will have a different effect.
But there are just too many reasons and not enough studies. In the typical case, you'd be really lucky to have even five studies on a particular intervention. And yet, what can you do with five studies? If you try to run some kind of meta-regression study with five observations and literally hundreds of explanatory variables, you'll end up overfitting. We need some other way to get information. And this is where I think priors can be informative. People naturally aggregate [their own observations] for you.

That's only one of the potential benefits. They can also help us answer other types of research questions. For example, [we can ask policymakers for their predictions on how well social programs will work]. In some earlier work with Aidan Coville of the World Bank, we found that policymakers had systematically higher and more dispersed priors than researchers. Essentially, policymakers were pretty confident that programs would work. They didn’t know to what extent, but they were sure that it was greater than zero, whereas researchers were very sure that programs would not work. You can get interesting results for a large number of research questions like those. Priors can also help to improve the accuracy of forecasts. You can start to see who is making the best forecasts — who the “superforecasters” are.
Priors can also help to improve research design. Imagine you're designing a study. You might say, “I have all these outcomes I could explore in this survey, but I must prioritize them. I can't ask people hundreds and hundreds of questions; I really need to focus on certain kinds of outcomes.” If nothing else, you can ask people for their priors to see which outcomes are [highly predictable, or hard to predict and thus important to investigate through research]. Taking a step back, you can even use priors to determine which kinds of interventions to study in the first place. You might be able to say, “These are the ones we can predict pretty accurately, and these are the ones for which we truly need an RCT, where the value of the information is particularly high.”
Finally, we think that collecting priors can mitigate publication bias. If you have a null result — you’ve done your study and the confidence interval overlaps with zero — journals are often reluctant to publish that. They'll say, “It's just not very interesting.” But if you collect ex-ante priors, you can say, “Look, this zero is actually interesting. You thought there would be an effect and there isn't one.”
We suspect there are probably more reasons out there. This is not supposed to be an exhaustive list. There is a huge amount of literature on forecasts.
One of the reasons for building this platform is we're observing a lot of development economists, behavioral economists, and even others collecting these ex-ante forecasts for their own studies.
We're a bit worried that if we don't have a platform to do this in a centralized way, then literally hundreds of researchers will be incentivized to seek ex-ante priors from the same small number of experts. Many, many people are doing this already. If we can create some kind of coordination, then that will help mitigate and spread out the burden of providing forecasts, so that one person isn’t bombarded with a thousand requests, and just says, “Oh, I give up.” If we want this to become a disciplinary norm, we must do it a little bit more intelligently.
There are also, of course, a lot of parallels with other projects in this area: the Science Prediction Market Project, the Good Judgment Project, and DARPA’s Systematizing Confidence in Open Research and Evidence (SCORE), which is an effort to gauge the replicability of studies.

We're mostly interested in treatment effects, and they're mostly interested in whether certain project results will replicate or not. We're trying to talk with all these people and coordinate where we can.

A platform can help solve this coordination problem. I think it's really valuable for that reason alone. It also allows us to track individual forecasters over time and get a sense for which individuals are better or worse at forecasting [so that we can build a panel of strong forecasters].
We think that researchers will want to use our platform for different reasons. There is one set of researchers who want help designing their studies in optimal ways. And there's another set of researchers who, if they have null results, can see priors on their work to learn whether those results are still interesting. Those two groups are going to want to see priors at different times. If you're changing the design of your experiment, you want to see priors before you've run it or even finished designing it [in case your change leads people to anticipate different results]. If you want to be able to say, “I ran all the analyses, here are my results, and I didn't peek at the priors, so I didn't engage in any p-hacking or specification searching [manipulating experimental design to increase the chance of finding significant results],” then you want to see the priors later on. This platform provides a mechanism to get a time-stamped, third-party view of when you got those priors, in a transparent way for everyone to see.
There are a lot of questions we still need to answer about how to do this appropriately. We don't want to mess it up. So, we're starting really slowly. As an aside, in some past work that I did, I think I ran before being able to walk, in a sense. I tried to push it too far, too fast. Economics is a very slow discipline, and to have the most buy-in, we're trying to go about this in a methodical way. We're iterating over time and building this up very slowly.

But we have some initial research questions that we want to answer in the process:
* What are the best ways to elicit forecasts?
* What is the typical accuracy of different types of forecasters?
* You can imagine that different forecasters will have different types of expertise, not just in terms of being more junior or senior, but also expertise in certain topic areas. To what extent does that matter?
* In that earlier work that Stefano and Devin did, they found that expertise didn't matter much for the questions they were interested in. They asked full professors, grad students, and everyone in between — including M-Turk workers themselves — what they thought the effects of those different behavioral incentives would be in the experiment of pressing different keys. They found basically no difference [in accuracy] between those groups. Nonetheless, it's possible that in other contexts, domain expertise could be very valuable — for example, it might be better to get AI experts for questions about AI.
* To what extent can we de-bias forecasts?
* The forecasts themselves might be inaccurate to begin with. But if we can improve them in some way, either by extremizing or running some kind of machine-learning algorithm on them to remove some of the biases, then we can do better than by just using the naive priors that people give.
In terms of our timeline, we hosted a workshop at UC Berkeley in December to get some early feedback. We brought a lot of academics to the table there. It was a really excellent group that included Colin Camerer. Right now, based on that feedback, we've been revising the beta version of our website.
One of the main things we're trying to do is integrate Qualtrics, which is survey software that a lot of researchers use. We’re doing that because we want to make it easy for people to use, and if we use Qualtrics, a lot of researchers will be able to quickly upload their surveys. Also, Qualtrics has an API. So it makes the distribution problem a lot easier. We can automatically send out the surveys to the appropriate groups, automatically get the results back, and automatically push them up to the website whenever we need to.
Ultimately, we hope that we'll be able to get the results of individual studies uploaded to the site. That way, we can see how people update their beliefs [after seeing how well their predictions matched reality].
Later this year, we're going to put out a call for research projects to be featured on the site. As I said, we're starting really slowly. We’re moving strategically, so we want to start with just a few projects. Those projects will be featured on the site while it's still in beta mode. After that, we'll expand the site and open it up for anybody with any project that they want to be predicted.

Here's my call for proposals: Right now, we're focused on social science projects. They have to be research projects, and ideally experiments with ex-ante predictions, so the project can't yet have results. We're going to be prioritizing particularly large, important projects that are hard to replicate. We see there being a lot more value to getting predictions for those. There's also a short-term emphasis on projects that will be completed within three years, because we're trying to get all the pieces of this platform moving. That's not to say that we're not interested in the longer term. We're very interested in that. But we've got to start somewhere.
You can go to the site and check out the beta version. I'll also say that while our call for proposals is mostly geared to researchers, if you're interested in providing forecasts, that's also valuable to us. You can either sign up on the site or contact me directly. It's still a work in progress, but I'm very optimistic that by the end of the year we'll have Qualtrics integration and a pretty full version at that point.
Thank you.
Q&A
Audience Member: Isn't it kind of worrying that the economics professors didn't do better than the Mechanical Turk participants?
Eva: I'm of two minds on this. On the one hand, you would hope that the econ professors would have done better. On the other hand, you could argue that the M-Turk workers had domain expertise and could consider the studies they had previously worked on. It’s maybe not the fairest of tests.
Audience Member: What about cases where people have the exact opposite intuition to what actually happens? I know we have some of these effects in social psychology, for example.
Eva: That's a great point. There's certainly this danger of relying more on priors when people can get it wrong. I guess my overall hunch would be we can, generally speaking, get it right more often than not. And if it turns out that people are, on average, worse at making predictions, hopefully we'll learn from that and be able to say, “Let's do something different, or maybe not use these priors.” Hopefully, that's something we can measure.
Audience Member: Do we know of any characteristics of types of areas where people's intuition tends to be better? Could this platform help identify those types of areas, perhaps?
Eva: I definitely think that this platform can help identify those areas. As to what those areas are, I don't have a full answer for you at this point. My own intuition would be areas where there is a large distribution in the effects that a program will have. Or, if you're making a comparison against zero, the relevant thing would be the mean effect of this program. Is it very close to zero? It'll be harder to see if it's better than zero or not. Those kinds of considerations, broadly speaking, would be important. Otherwise, I'm not sure.
Anecdotally, you certainly hear that when people have strong beliefs tied to their identity, they may be more resistant to new information and may make the wrong decisions. But hopefully, we'll learn that through the platform, and I'll be able to answer that in much more detail in a couple of years.

