Hi! My name is Malin and I wrote my master's thesis in cognitive science in collaboration with Don Efficace, a young evaluator organization building their evaluation process to find the most effective charities in France. Together, we set out to explore the concept of noise (see below) in charity evaluations. Many researchers from other evaluator organizations contributed to this endeavor by responding to my survey or participating in interviews. This post serves to summarize my research for them and anyone else who is interested in the topic - have a good read!
TL:DR
Noise, as defined by Daniel Kahneman, Olivier Sibony, and Cass R. Sunstein, refers to the unwanted variability in judgments caused by cognitive biases. In charity evaluations, this inconsistency can lead to unreliable recommendations, which can significantly affect the allocation of funds and erode donor trust. Given the complex nature of charity evaluations, noise is likely to occur, making it crucial to address in order to ensure consistent and effective decision-making.
Several strategies from other fields have been found effective in reducing noise and can be adapted for charity evaluations:
1. Implement Decision Guidelines and Scales:
- Break down evaluations into clear criteria.
- Use scales with anchors and descriptors for consistent assessments.
- Consider comparative scales to reduce bias in subjective judgments.
2. Adopt Aggregation Strategies:
- Encourage multiple independent estimates from researchers for cost-effectiveness analyses to improve accuracy.
- Alternatively, use the options adapted to individuals, where two guesses from the same person are averaged.
3. Use the Mini-Delphi Method:
- Structure discussions around initial independent estimates, followed by collective deliberation and revised judgments.
Future research should focus on measuring noise levels in charity evaluations and testing these strategies' effectiveness. Collaborating with other evaluator organizations can provide valuable insights and help design low-noise processes.
Introduction: Noise
In the context of my master’s thesis, I explored the role of “noise” in charity evaluations. In the context of decision-making, the term noise was popularized by Daniel Kahneman, Olivier Sibony, and Cass R. Sunstein. Their work has significantly advanced the application of cognitive sciences to real-life scenarios by demonstrating some of the tangible impacts cognitive biases can have on decision-making. Specifically, they show how cognitive biases may lead to unwanted variability in judgments, which they call noise. I conducted three studies, a review of online information, a study, and interviews to investigate how noise-reduction strategies from the literature could apply to charity evaluations and which recommendations can be derived for Don Efficace. In this text, I summarize my findings as they may be relevant to charity evaluators. If you want to know more, I invite you to read my thesis as well as “Noise: a flaw in human judgment” by Kahneman et al..
The text will be structured as follows: First I introduce noise and why it matters in charity evaluations. Then I will present strategies that have been found to reduce noise in other fields that involve complex judgments, like judicial sentencing, medical diagnoses, or hiring decisions. For each of the strategies, I add the results from my research, setting them into the charity evaluation context. Lastly, I will give an outlook on what future research efforts in the field may look like.
Noise in Charity Evaluations
You may be familiar with cognitive biases like the confirmation bias, the halo effect, desirability bias, or the anchoring effect and how they can predictably influence people’s behavior. What the authors of “Noise” have considered is that in real-life conditions, the effects of these biases vary based on the circumstances. For example, you can imagine how confirmation bias would lead to different effects for two people who have had vastly different experiences in their lives and therefore have different beliefs. So instead of looking at the systematic deviations cognitive biases may cause (statistical bias), the authors focus on variability in judgments, both within and between raters (noise).
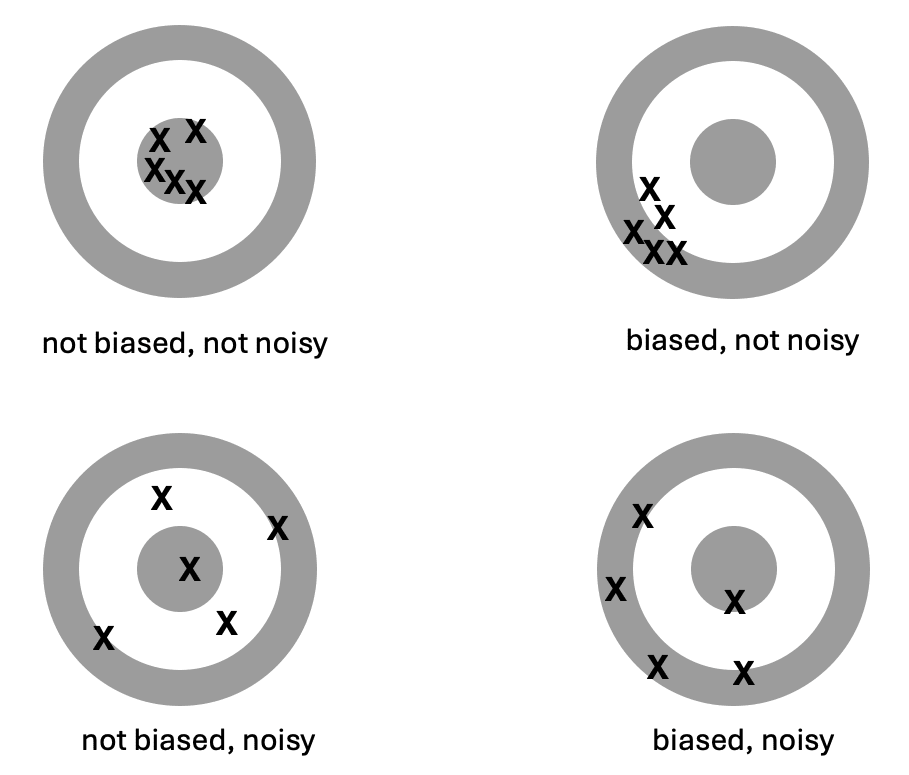
Illustration adapted from Kahneman et al. (2021)
So why should we care about noise in charity evaluations? Charity evaluations involve complex judgments, the type of situation in which noise most readily occurs. Research that identified noise in fields like medicine or judicial sentencing warns us that these judgments may be inconsistent: The charity that was recommended today, may not have been recommended under a set of slightly different circumstances, like which team member spoke up first in a discussion, who conducted the interview with the charity or what was on the news that day – all factors that should be irrelevant to the evaluation.
This inconsistency would mess with charity evaluators' number one goal: Recommending the most effective charities, at least according to their standards. And since charity evaluators move considerable funds from donors who trust their evaluations, noise could result in a significant loss of impact and erode donor trust. That is why we want to limit the influence of cognitive biases and come to a shared, consistent response.
Below I collected some quotes from the interviews I conducted, summarizing interviewees’ thoughts on noise in charity evaluation processes.

Noise-Reduction Strategies
These strategies have been collected in the book and are often drawn from other fields. They work, for example, by focusing judges on the relevant information, by calibrating judgments, or simply by aggregating multiple independent judgments.
1. Decision Guidelines & Scales
Decision guidelines are frameworks that decompose complex judgments into a set of sub-judgments that are easier to assess on a set of predefined dimensions. They help to focus researchers on important cues, serve as a guide to what data is needed, and will also filter out irrelevant information.
An example I like to make here is the review guidelines used for grading an essay or a thesis. Instead of giving a grade based on the overall impression of the document, the judgment is divided into sub-judgments, like the methodology or the form. What is important for such criteria to reduce noise is that they are easier to assess than the final result. A factor that helps with this can be the pre-defined dimensions. This could be a quantitative metric (e.g. how many words does the document have) or if that is not possible, it could be assessed on a scale, leaving again room for judgments. Though criteria could be assessed through text, numerical assessments are likely more straightforward to assess and include an element of comparison. They avoid the potential ambiguity in text-based ratings, which could lead to the text being interpreted according to already existing impressions.
Kahneman et al. propose three further noise-reduction strategies in the use of scales as an older study by the author highlighted that despite similar impressions or opinions, people vary in how they interpret scales, potentially leading to arbitrary application and varying judgments. The first option that could help remedy this is using descriptors – annotations to a scale that explains what each level of the scale would look like in practice. This is an approach often used in job performance evaluations but doesn’t necessarily eliminate all noise. The second option to reduce validity is using comparative scales or rankings instead of absolute ones. Instead of rating a charity’s priority along a scale of low/medium/high, charities could either be assessed compared to the average charity that is considered (higher priority than average, lower priority than average) or all charities that are considered could be placed in a ranking. While it may not be feasible for every type of scale, this approach eliminates variability that is related to the absolute placement on a scale (some researchers may be more “strict”, others more “lenient”) and encourages statistical thinking. Lastly, if the comparative scales seem like too much of a change, they could be assimilated by placing “anchors” on a scale, real-life examples that serve as a reference point.
Regarding the results of this research, the initial review of online information made it seem like all evaluators from the sample use decision guidelines in their work, as they all list some criteria they consider to determine whether a charity is effective. However, the survey showed that not all of these criteria may be used in practice and further, not all of these criteria are assessed systematically. A comment we received multiple times is that some criteria are assessed quantitatively and others qualitatively. Here, it is important to note that just because a criterion is qualitative, does not mean that it cannot be assessed, for example through scales. While this assessment may certainly be somewhat subjective, placing it on a scale does not make it more subjective than it was before – and it allows for more transparency and ideally reduces variability both within and between researchers.
Interviews further showed that guidelines and scales may be somewhat uncomfortable because they require making a conscious decision on which information is relevant and which is not. Regarding the complexity of charity evaluations, this may seem like a daunting feat. The alternative, however, is making these decisions sub-consciously and potentially on a case-by-case basis, creating variability and making decisions less transparent, which I argue is the greater of two evils. Beyond this, while decision guidelines can be used to compute the final decision from sub-dimensions, they don’t have to be used this way. Guidelines can also be used as a first hypothesis to be debated, leaving room for unexpected findings that don’t fit into any category.
2. Aggregation
Wisdom of Crowds
In aggregation, multiple independent judgments are combined to form a new judgment. Vu and Pashler cite Laplace to explain that combining several independent assessments reduces variance and therefore noise in the final judgment. Research consistently shows that while individual estimates may vary greatly, they tend to be unbiased when predicting tasks like city temperatures, guessing bean counts in a jar, or estimating distances. This “wisdom of crowds” method proves that averaging multiple opinions often leads to more accurate outcomes.
However, for very difficult questions that only experts can answer accurately, the crowd's accuracy may not be high. To address this, researchers like Mannes et al. have developed the "select crowd" method, which involves choosing top judges based on recent accuracy, leading to highly accurate judgments.
Lastly, when a physical crowd isn't available, researchers have explored using an "inner crowd”. They found that averaging two internal estimates taken at different times results in more accurate judgments than a single estimate. Herzog and Hertwig introduced “dialectical bootstrapping,” where participants generate a second judgment as different as possible from their first, achieving significant accuracy improvements.
One interviewee suggested this strategy for estimates that are made in the context of cost-effectiveness analyses. When proposing this idea to the other interviewees they agreed, estimating this strategy to have the biggest potential impact on the bottom line. Researchers could either be instructed to make two estimates and aggregate them or if enough staff is available, multiple researchers could give their independent estimates for the same analysis.
Mini-Delphi
While the wisdom-of-crowds methods can yield more accurate judgments, they aren't suitable where discussion and exchange are needed. Aggregation relies on independent estimates free of shared biases, which isn't possible when people discuss beforehand. The Delphi method, which you may be familiar with, offers a structured alternative, minimizing conformity bias and groupthink through multiple rounds of anonymous estimates, reasoning, and responses (for more information, see ). This approach leads to more accurate estimates than regular discussions. However, the traditional Delphi method is quite complex and hard to implement in routine decision-making.
To simplify this, Van De Ven and Delbecq proposed the “mini-Delphi.” Unlike the traditional Delphi, this involves a face-to-face meeting where individuals first note down estimates silently, then justify and discuss them. A second round of estimates is used to come to a final judgment, either through averaging judgments or voting, depending on the decision at hand. The method has been shown to perform better than regular meetings in terms of perceived effectiveness and variability.
While the survey showed that most evaluators do not conduct their discussions in a structured way, some evaluators already record individual judgments before discussions, providing some basis for independent estimates. One of the interviewees even used a method quite close to the mini-Delphi approach. Others were interested in the method, saying it seemed quite simple to implement and would also help to create more transparency for the charities that are being evaluated.
Another interesting strategy to reduce noise comes from forensic science. While we often think of forensic methods like fingerprint and DNA analysis as highly objective, research by Dror and colleagues has shown that these methods can actually be quite noisy and biased. Their studies revealed that forensic experts often gave inconsistent analyses of the same fingerprints, especially when they were exposed to potentially biasing information.
To tackle this issue, Dror et al. suggest using "linear sequential unmasking." This means presenting any potentially biasing information as late as possible during the evaluation process, limiting changes to analyses after exposure to such information, and recording initial confidence levels. They later expanded this idea to other areas of expert decision-making, recommending that initial analyses should be done with minimal contextual information.
However, applying this strategy to charity evaluations may be difficult. It involves someone judging what information is relevant and then passing it on, which adds an extra layer of complexity and may not always be helpful. That is why I did not further consider this strategy in the research.
4. Structured Interviews
Another strategy relates specifically to interviews. Research into job interviews has shown that unstructured interviews aren't great at predicting job performance. On the other hand, structured interviews are much better at this. A structured interview generally means there are set rules for the questions asked, how observations are made, and how evaluations are conducted. However, for its application in charity evaluations, this strategy was not further considered as interviews are not a central part of most process stages.
Lastly, Kahneman et al. draw on these strategies and other best practices in reducing noise to propose three principles in structuring complex judgments: Decomposition, independence, and delayed holistic judgment. Decomposition refers to the decision guidelines elaborated on earlier. Independence as a principle aims to avoid the halo effect across criteria assessments by keeping them as separate as possible. Lastly, delayed holistic judgments are proposed as a way to allow people to exercise their judgment instead of basing the final result entirely on calculations, which is often necessary to get the raters' buy-in – an option also discussed in the guideline section. The authors then propose the “mediating assessments protocol” as a holistic strategy that combines the above principles with the strategies proposed for scales and the mini-Delphi method.
As it was not reflected in other strategies, I considered the independence principle separately in the research. The idea is for different criteria to be assessed by different researchers or at least sequentially. The aim is to limit the halo effect across criteria, meaning that one aspect of the evaluation changes the reading of another, unrelated aspect. None of the evaluators who participated in the survey used such an approach. Interviews further showed that this strategy may not be particularly feasible for the process, partly due to it being very different from how evaluations are currently conducted and partly because of a lack of staff. Therefore, it was not included in the recommendations.
Future Research
For future research, I recommend conducting experiments that measure the level of noise in charity evaluation processes and test the impact of noise-reduction strategies. These estimates will help every evaluator to determine what level of noise they would deem acceptable in their process and whether the noise-reduction strategies are worth investing in. As the process involves multiple stages that differ across evaluators, I propose to limit these experiments to one specific part of the process. The use of criteria and scales could be tested in preliminary charity or intervention assessments. Another option would be testing aggregation strategies such as the wisdom-of-crowds method or the inner-crowd alternative for estimates in cost-effectiveness analyses. For more details, I refer you to the thesis. If you would be interested in taking part in such an experiment, please contact Don Efficace!
Summary and Recommendations
Noise, as defined by Daniel Kahneman, Olivier Sibony, and Cass R. Sunstein, refers to the unwanted variability in judgments caused by cognitive biases. In charity evaluations, this inconsistency can lead to unreliable recommendations, which can significantly affect the allocation of funds and erode donor trust. Given the complex nature of charity evaluations, noise is likely to occur, making it crucial to address in order to ensure consistent and effective decision-making.
Several strategies from other fields have been found effective in reducing noise and can be adapted for charity evaluations:
1. Implement Decision Guidelines and Scales:
- Break down evaluations into clear criteria.
- Use scales with anchors and descriptors for consistent assessments.
- Consider comparative scales to reduce bias in subjective judgments.
2. Adopt Aggregation Strategies:
- Encourage multiple independent estimates from researchers for cost-effectiveness analyses to improve accuracy.
- Alternatively, use the options adapted to individuals, where two guesses from the same person are averaged.
3. Use the Mini-Delphi Method:
- Structure discussions around initial independent estimates, followed by collective deliberation and revised judgments.
Future research should focus on measuring noise levels in charity evaluations and testing these strategies' effectiveness. Collaborating with other evaluator organizations can provide valuable insights and help design low-noise processes.

