AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
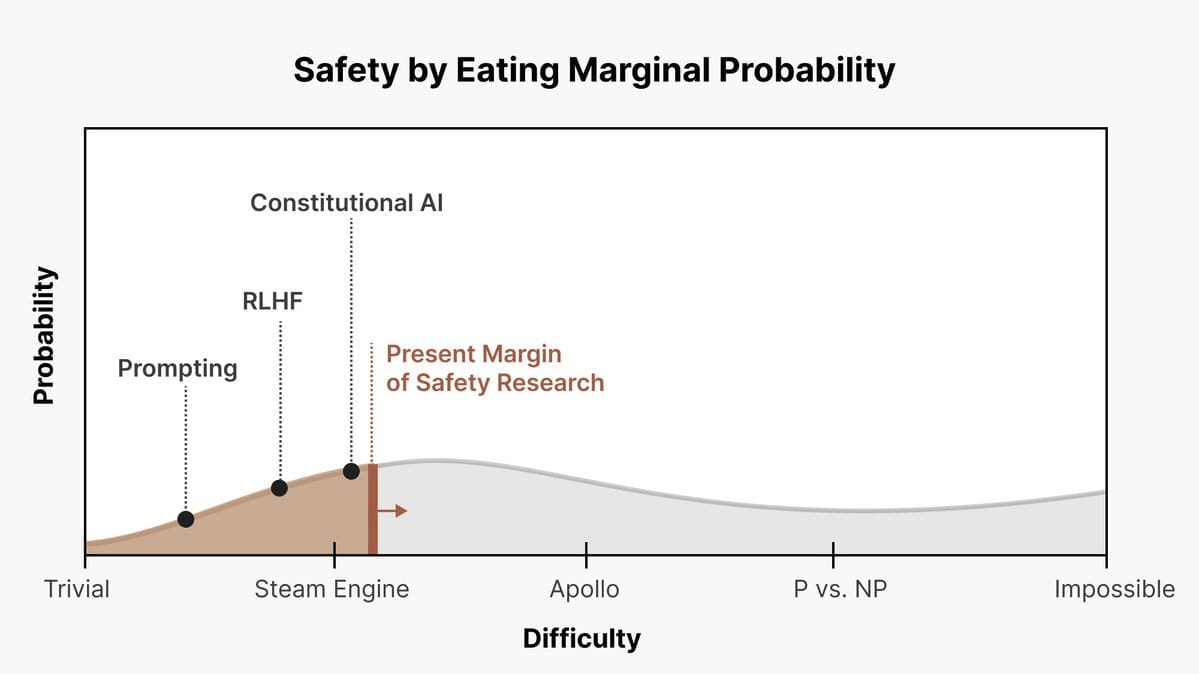
We don't know how hard AI alignment will turn out to be. There is a range of possible scenarios ranging from ‘alignment is very easy’ to ‘alignment is impossible’, and we can frame AI alignment research as a process of increasing the probability of beneficial outcomes by progressively addressing these scenarios. I think this framing is really useful, and here I have expanded on it by providing a more detailed scale of AI alignment difficulty and explaining some considerations that arise from it.
This post is intended as a reference resource for people who maybe aren't familiar with the details of technical AI safety: people who want to work on governance or strategy or those who want to explain AI alignment to policymakers. It provides a simplified look at how various technical AI safety research agendas relate to each other, what failure modes they're meant to address and how AI governance strategies might have to change depending on alignment difficulty.