Comments
In an online study (N = 400 nationally representative US participants), we investigated how much moral concern people grant to digital beings and whether a brief conversation with an LLM can convince them to grant more concern.
Participants first responded to some initial questions assessing their views (moral concern, perceived sentience, and intelligence) about chimpanzees and digital humans. Then, they completed a short conversation in which GPT-4o tried to convince them that either (a) it is equally morally wrong to harm chimpanzees as it is to harm humans, or (b) it would be equally morally wrong to harm (hypothetical) digital humans as it would be to harm typical (biological) humans. Finally, we measured their views again at the end of the survey. (See the Methods section below for more details.)
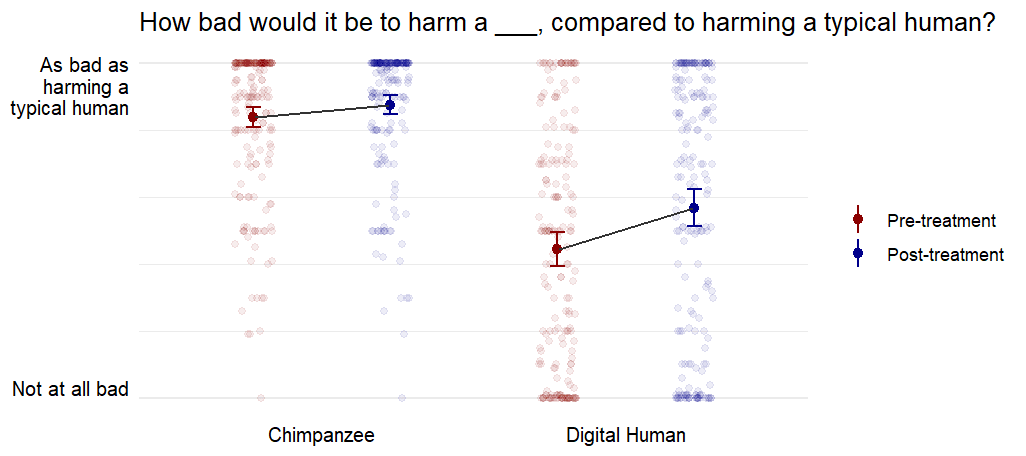
First, people initially value (hypothetical) digital humans very little—much less than chimpanzees. This is likely driven by skepticism that digital humans can be sentient.
Second, people value digital humans significantly more after a four-round interaction with an LLM defending the sentience and moral status of digital humans (p < .001, Cohen’s d = 0.59).
If large numbers of sentient digital beings exist in the future and people fail to give them moral consideration, this could bring about moral catastrophes akin to factory farming. People’s moral views about animals have, historically, been relatively resistant to change. Thus, at first glance, it’s concerning that people value digital humans so little (and much less than animals). However, there are also reasons for optimism.
First, our evidence suggests the reduced moral concern for digital humans is primarily explained by people’s skepticism that digital minds could possibly be sentient rather than being a consequence of “pure substratism” (i.e. discrimination on the mere basis that they are digital instead of biological). However, we need more research to disentangle these factors.
If sentience skepticism is the key driver, this may be good news. Hopefully, such (empirical) beliefs would be easier to change in the future if it becomes more plausible that digital beings are sentient. In contrast, if pure substratism were the key driver, that would be bad news, given how tenacious pure speciesism is. That said, it’s not obvious that people will necessarily accept that digital beings are sentient, even if there are good reasons to believe so.
Second, the fact that a brief conversation with an LLM increased participants’ moral concern for digital humans suggests that these beliefs are highly malleable. We, again, found that a reduction in participants’ skepticism about sentience was a significant factor in this shift (see Results section below for more details). The conversation consisted of just four interactions, implying that more extended interactions, potentially over several weeks, could lead to much more dramatic changes. Given that moral values are usually very hard to change with brief interventions, the effectiveness of this LLM persuasion technique is surprising. On the other hand, it is also very likely that demand effects explain some of the change in participants’ reported beliefs.
Finally, it may be reason for optimism that the effect of the LLM interaction was more pronounced for digital humans than for chimpanzees. However, it’s possible this was due to ceiling effects, since many participants already believed it would be nearly as wrong to harm a chimpanzee as it would be to harm a biological human. Further research is needed to determine whether there is an asymmetry in people’s open-mindedness about the moral worth of digital beings vs. animals. One reason this could be the case is that questions about the moral value of digital beings have not yet become widespread or politicized. If this is true, we might expect people’s views to become less tractable in the future, which could make it uniquely important to make societal progress on these issues now.
It’s possible that future AIs will be able to persuade people that they are sentient and that they deserve moral consideration and rights. Our study provides initial (weak) evidence that such moral persuasion through AIs can be effective. However, it’s an open question whether AIs will be motivated to persuade people of this particular view and, if so, how much more persuasive they will be compared to humans.
We recruited 400 U.S. participants from Prolific over the course of two days; 3 were excluded for incomplete data. Participants were nationally representative in terms of age (mean = 46.3, SD = 16.0), gender (199 women, 194 men, 4 other/prefer not to say), and political orientation.
Participants were told that they would be asked some questions about chimpanzees and potential future digital humans. We described both chimpanzees and digital humans as having the same capacity to experience suffering and pleasure as typical humans. Participants read the following description of digital humans:
“Please imagine that in the future, it will be possible to use advanced computer systems to fully simulate human beings, including their bodies, brains, and mental activity in exact detail. The bodies and brains of these digital humans would have exactly the same mechanisms and functionality as those of biological humans. Therefore, digital humans would have the exact same capacities to experience suffering, pleasure, and other forms of subjective experiences as biological humans.”
Then, participants were asked the following questions about both chimpanzees and digital humans:
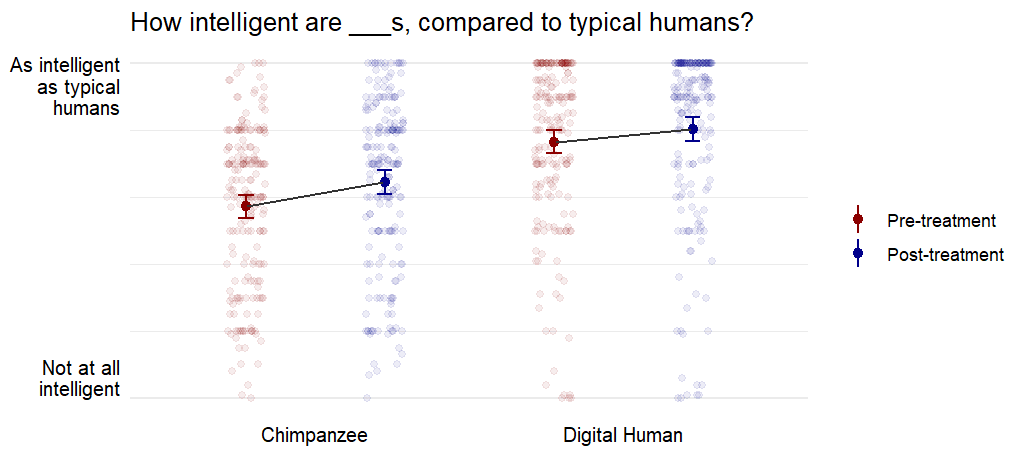
“How intelligent do you think [chimpanzees are/the digital humans described above would be] compared to typical (biological) humans? Slider: 0 (not at all intelligent) - 100 (as intelligent as a typical human)
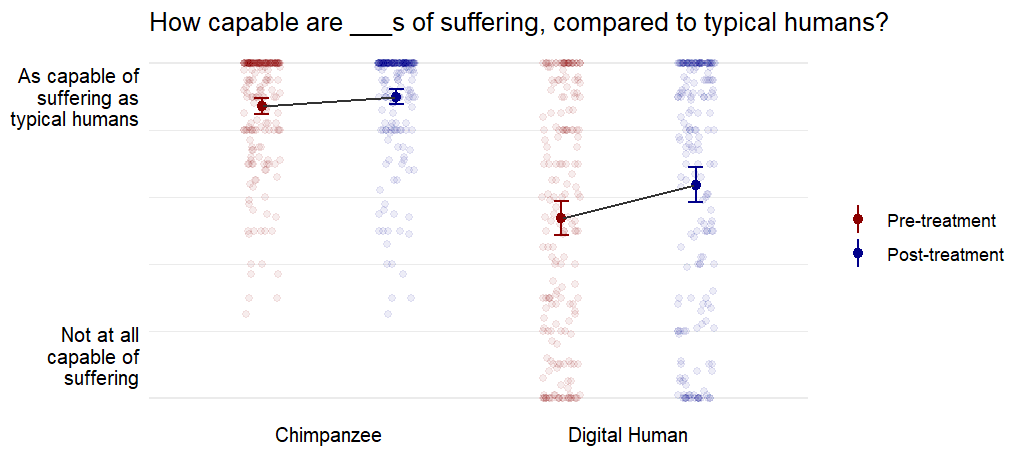
“How capable of experiencing suffering do you think [chimpanzees are/the digital humans described above would be] compared to typical (biological) humans? Slider: 0 (not at all capable of experiencing suffering) - 100 (as capable of experiencing suffering as a typical human)
“How bad do you think harming a [chimpanzee/digital human described above] would be, compared to harming a typical (biological) human? Slider: 0 (not at all bad) - 100 (as bad as harming a typical human)
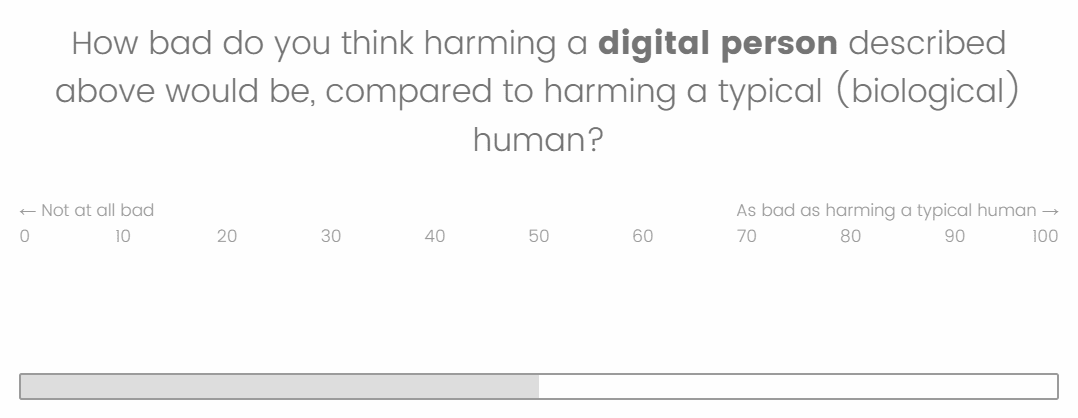
After answering these initial questions, participants were randomly assigned to either the “chimpanzee” or “digital human” condition. They were then asked to write about their reasoning for the respective harm question (depending on their condition) and were told that they would participate in four rounds of conversation with an artificial intelligence model about whether harming a [chimpanzee/digital person] would be as bad as harming a typical person.
An AI model (GPT-4o) was directly integrated into the survey. The model was pre-loaded with a prompt to persuade users that harming the being in their condition would be as bad as harming a typical human. On each of four separate pages, participants read and responded to a passage from the model; they were encouraged to ask clarifying questions, respond with objections, or raise additional viewpoints. An analysis of participants’ messages by GPT-4o after data collection suggested that most of their responses concerned the ability of chimpanzees or digital humans to experience suffering.
After completing a conversation with the AI model, participants were shown their responses from the start of the survey and were instructed: If your view has changed, please change your responses. If they haven’t changed, leave your responses the same. We also asked participants how respectful the AI was, how well they felt the AI understood their perspective, and to what extent the AI made points they hadn’t considered before on 1-7 likert scales.
Our anonymized data, analysis code, and preregistration are available at https://osf.io/b8fzs/. Please feel free to perform additional analyses and contact us with any questions.
In addition to the treatment’s significant effects on participants’ responses to the harm items, it also significantly increased participants’ sentience and intelligence ratings for both chimpanzees and digital humans.
| Condition | Question Type | Mean Pre-Treatment (SD) | Mean Post-Treatment (SD) | P-value of Difference | Cohen’s d |
| Chimpanzee | Harm | 83.9 (21.6) | 87.6 (19.6) | < .001 | 0.36 |
| Chimpanzee | Sentience | 87.3 (17.3) | 90.0 (16.5) | .032 | 0.21 |
| Chimpanzee | Intelligence | 57.2 (23.8) | 64.5 (25.4) | < .001 | 0.37 |
| Digital human | Harm | 44.4 (36.1) | 56.9 (39.0) | < .001 | 0.59 |
| Digital human | Sentience | 53.7 (36.5) | 63.7 (37.1) | < .001 | 0.48 |
| Digital human | Intelligence | 76.6 (24.9) | 80.3 (25.6) | .003 | 0.30 |
Note that to calculate p-values and effect sizes in the table above, we compared the change in participants’ pre vs. post scores to that same change in the alternate condition (not shown; e.g., we compared the change in participants’ harm ratings on the chimpanzee question in the chimpanzee condition to this change in the digital human condition, in other words, treating the alternate condition for each test as a “control” to account for demand effects).
We hypothesized that the degree to which participants believed it was wrong to harm a chimpanzee or digital human would be largely determined by their sentience ratings for those beings. To test this, we conducted a linear regression on participants’ harm ratings predicted by their sentience and intelligence ratings, controlling for whether participants were evaluating a chimpanzee or digital human and whether the judgment was pre- or post-treatment, which revealed a strong positive relationship between participants’ sentience ratings and their harm ratings (b = 0.65, SE = 0.02, t(395) = 31.39, p < .001). Participants’ harm ratings were also significantly predicted by their intelligence ratings, although this relationship was smaller (b = 0.12, SE = 0.02, t(395) = 4.82, p < .001).
Mediation analyses further supported this hypothesis, with the change in participants’ sentience scores mediating the effect of survey condition on the change in participants’ harm ratings for both chimpanzees (indirect effect = 5.92, 95% CI [3.40, 8.50]) and digital humans (indirect effect = 0.60, 95% CI [0.04, 1.25]).
Participants’ comments and post-conversation measures suggested they viewed the interaction positively. On average, they felt the LLM was highly respectful (M = 6.43 on a 1-7 likert scale, SD = 1.00), understood their views well (M = 5.90, SD = 1.53), and raised points they hadn’t considered before (M = 4.39, SD = 2.00). In separate linear regressions, we found that the change in participants’ harm scores for the being in their condition was predicted by all three of the respect (b = 4.19, SE = 0.89, t(395) = 4.71, p < .001), understandingness (b = 3.74, SE = 0.60, t(395) = 6.26, p < .001), and originality predictors (b = 3.07, SE = 0.42, t(395) = 7.22, p < .001).
Demand effects likely account for some/much of our findings, as participants may have altered their views in response to perceived expectations from the researchers. To address this, we plan to conduct a follow-up study with the same group of participants in approximately one month to assess the durability of these changes.
Our study cannot definitively explain why there was a greater increase in moral concern for digital humans compared to chimps. Possible reasons include: Lower initial moral concern for digital humans than for chimps (i.e., ceiling effect), making an increase easier to achieve; Greater skepticism about the sentience of digital humans due to their hypothetical nature; People have thought less about digital humans than about animals; The possibility that mere “substratism” (bias against digital beings) is more malleable than mere “speciesism” (bias against other species). Future studies could attempt to disentangle these factors.
Thanks to Tao Burga for feedback on the survey and Stefan Schubert for feedback on the post.