Comments
This post was written during Refine. Thanks to Jonathan Low, Linda Linsefors, Koen Holtman, Aaron Scher, and Nicholas Kees Dupuis for helpful discussion and feedback.
Disclaimer: This post reflects my current understanding of the field and may not be an accurate representation of it. Feel free to comment if you feel that there are misrepresentations.
Motivations
I remember being fairly confused when I first started reading AI safety related posts, especially when it pertains to specific ideas or proposals, as there may be implicit assumptions behind those posts that relies on some background understanding about the research agenda. I have since had the opportunity to clear up many of those confusions by talking to many people especially while I was participating in Refine. Looking back, there were many background assumptions about the field I wish I had known earlier, so here’s the post I never had.
This post does not intend to cover topics like why AI safety is important, how to get into the field, or an overview of research agendas, as there are plenty of materials covering these topics already.
Some terminology
Artificial intelligence (AI) refers to intelligences that are created artificially, where intelligence measures an agent's ability to achieve goals in a wide range of environments as per Shane Legg and Marcus Hutter’s definition. Artificial general intelligence (AGI) refers to a machine capable of behaving intelligently over many domains, unlike narrow AIs which only perform one task. Artificial superintelligence (ASI), or “superintelligent AI”, refers to an intellect that is much smarter than the best human brains in practically every field, including scientific creativity, general wisdom and social skills. On the other hand, transformative AI (TAI) is an AI that precipitates a transition at least comparable to the agricultural or industrial revolution, where the concept refers to its effects instead of its capabilities. In practice however, the terms AGI, ASI, and TAI are sometimes used interchangeably to loosely mean “an AI that is much more powerful than humans”, where “power” (related to “optimization”) is often used to loosely mean “intelligence”.
AI safety is about making the development of AI go safely. It is often used to refer to AGI safety or AI alignment (or just “alignment” because “AI alignment” is too long), which roughly refers to aligning a hypothetical future AI to what humans want in a way that is not catastrophic to humans in the long term. There is of course the question of “which humans should we align the AI to” that is often raised, though the question of “how do we even properly align an intelligent system to anything at all” would be much a more central problem to most researchers in the field.
In other communities however, AI safety is also used in the context of ensuring the safety of autonomous control systems such as self-driving cars and unmanned aircrafts, which is typically outside of the scope of AI alignment. In this post however, I will mostly use the term AI safety to mean AI alignment as how it is often used in introductory materials like this one, although it may be generally better to have clearer distinctions of these terms.
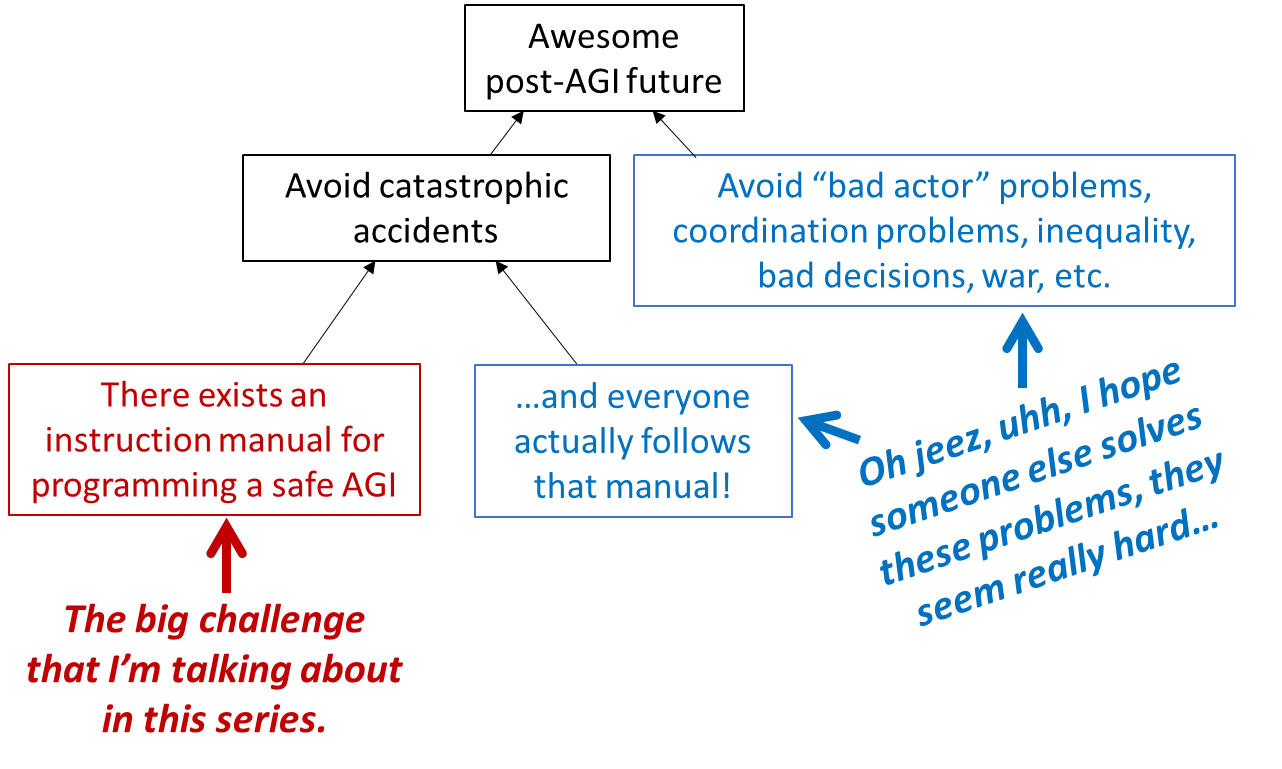
In Steve Byrnes’ diagram from this post, the red box serves as a good representation of the AI alignment field, and separates “alignment” from “existential risk (x-risk) mitigation” in a nice way:
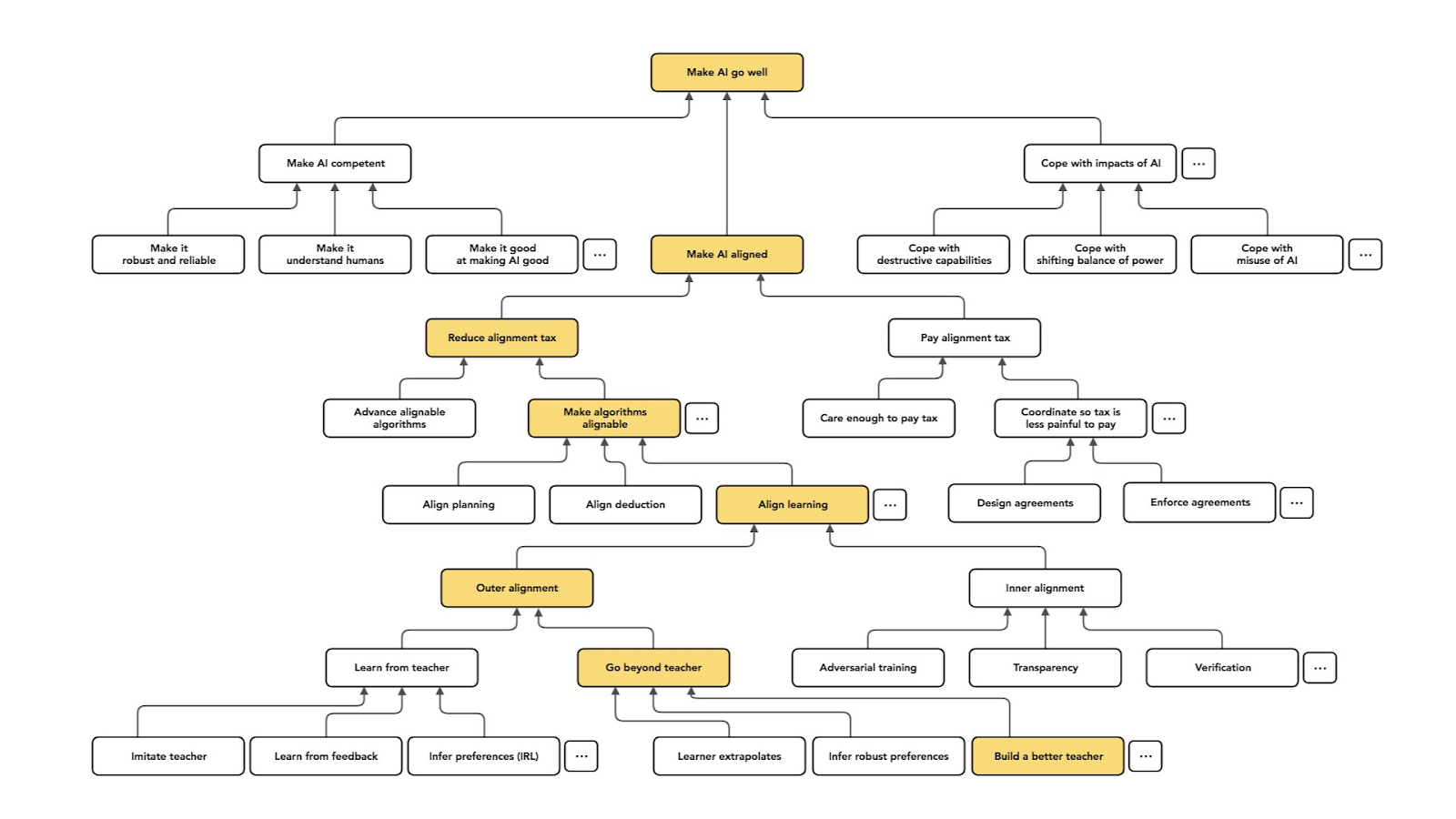
The diagram below from a talk by Paul Christiano also describes alignment (“make AI aligned”) as a specific subset of “making AI go well”.
Brief history of AI and AI safety
AI development can roughly be divided into the following era:
- 1952 - 1956: The birth of AI by a handful of scientists, with some research progress in neurology, cybernetics, information theory, and theory of computation, leading up to the Dartmouth Workshop of 1956.
- 1956 - 1974:The era of symbolic AI, with more progress in “reasoning as search” paradigm, natural language, and robotics.
- 1974 - 1980: The first AI winter, where researchers realized achieving AI was harder than previously thought, and funding for AI research decreased.
- 1980 - 1987: The second AI summer, with developments in knowledge based systems and expert systems.
- 1987 - 1993: The second AI winter, with the advent of more cost-effective general Unix workstations with good compilers, forcing many commercial deployments of expert systems to be discontinued.
- 1993 - 2011: The field of AI continues to advance with an increase in computing power and more sophisticated mathematical tools, contributing to progress in various fields like industrial robotics, speech recognition, and search engines.
- 2011 - present: The deep learning era, with progress coming from access to large amounts of data (big data), cheaper and faster computers, and advanced machine learning techniques.
Here’s a series of more recent AI-related breakthroughs, stolen directly from this post by Jacob Cannell:
1996: Deep blue crushes Kasparov, breaking chess through brute force scaling of known search algorithms.
2010: ANNs are still largely viewed as curiosities which only mariginally outperform more sensible theoretically justified techniques such as SVMs on a few wierd datasets like MNIST. It seems reasonable that the brain's exceptionality is related to its mysterious incredible pattern recognition abilities, as evidenced by the dismal performance of the best machine vision systems.
2012: Alexnet breaks various benchmarks simply by scaling up extant ANN techniques on GPUs, upending the field of computer vision.
2013: Just to reiterate that vision wasn't a fluke, Deepmind applies the same generic Alexnet style CNNs (and codebase) - combined with reinforcement learning - to excel at Atari.
2015: In The Brain as a Universal Learning Machine, I propose that brains implement a powerful and efficient universal learning algorithm, such that intelligence then comes from compute scaling, and therefore that DL will take a convergent path and achieve AGI after matching the brain's net compute capacity.
2015: Two years after Atari, Deepmind combines ANN pattern recognition with MCTS to break Go.
2016: It's now increasingly clear (to some) that further refinements and scaling of ANNs could solve many/most of the hard sensory, pattern recognition, and even control problems that have long eluded the field of AI. But for a believer in brain exceptionalism one could still point to language as the final frontier, the obvious key to grand human intelligence.
2018: GPT-1 certainly isn't very impressive
2019: GPT-2 is shocking to some - not so much due to the absolute capabilities of the system, but more due to the incredible progress in just a year, and progress near solely from scaling.
2020: The novel capabilities of GPT-3, and moreover the fact that they arose so quickly merely from scaling, should cast serious doubts on the theory that language is the unique human capability whose explanation requires complex novel brain architectural innovations.
2021: Google LaMDa, OpenAI CLIP, Megatron-Turing NLG 530B, Codex
2022: Disco Diffusion, Imagen, Stable Diffusion, Chinchilla, DALL-E-2, VPT, Minerva, Pathways ...
In parallel, the field of AI safety was also growing:
- 2000: Eliezer Yudkowsky founds Singularity Institute for Artificial Intelligence (SIAI) (later renamed as Machine Intelligence Research Institute (MIRI) in 2013)
- 2005: Nick Bostrom and Anders Sandberg found Future of Humanity Institute
- 2014: Nick Bostrom publishes Superintelligence: Paths, Dangers, Strategies; DeepMind establishes Ethics Board (not to be confused with the Ethics & Safety Team) to “consider dangers of AI”; Max Tegmark, Jaan Tallinn, and others found Future of Life Institute (FLI)
- 2016: Researchers from Google Brain, Stanford University, UC Berkeley, and OpenAI publishes Concrete Problems in AI Safety; Stuart Russell founds the Center for Human-Compatible AI (CHAI)
- 2017: OpenAI receives grant from Open Philanthropy to “reduce potential risks from advanced AI”; Robert Miles starts YouTube channel on AI safety
- 2018: LessWrong team launches the Al Alignment Forum; Rohin Shah launches the Alignment Newsletter
- 2019: Stuart Russell publishes Human Compatible: Artificial Intelligence and the Problem of Control
- 2020: Brian Christian publishes The Alignment Problem
- 2021: Several other AI safety related organizations are founded, e.g. Alignment Research Center (ARC), Anthropic, Redwood Research, etc
- 2022: More AI safety related organizations are founded, e.g. Aligned AI, Center for AI Safety, Conjecture, etc
Unsurprisingly, the AI safety field has grown very rapidly in the last few years as most of the breakthroughs in deep learning happened. However, it is also worth noting that the pioneers of the field started working on the alignment problem before deep learning ‘took off’, which explains some of the paradigms that will be covered below.
Different paradigms
AI safety is a pre-paradigmatic field, which APA defines as:
a science at a primitive stage of development, before it has achieved a paradigm and established a consensus about the true nature of the subject matter and how to approach it.
In other words, there is no universally agreed-upon description of what the alignment problem is. Some would even describe the field as ‘non-paradigmatic’, where the field may not converge to a single paradigm given the nature of the problem that may never be definitely established. It’s not just that the proposed solutions garner plenty of disagreements, the nature of the problem itself is ill-defined and often disagreed among researchers in the field. Hence, the field is centered around various researchers / research organizations and their research agenda, which are built on very different formulations of the problem, or even a portfolio of these problems. The diversity of problem formulation in the field can be seen as a feature instead of a bug, as different researchers would make progress on a wide range of failure modes.
These paradigms may be put into buckets below as if they are very distinct and mutually exclusive, but it’s worth bearing in mind that in reality the lines between them are much more fuzzy and the different paradigms tend to have significant overlap.
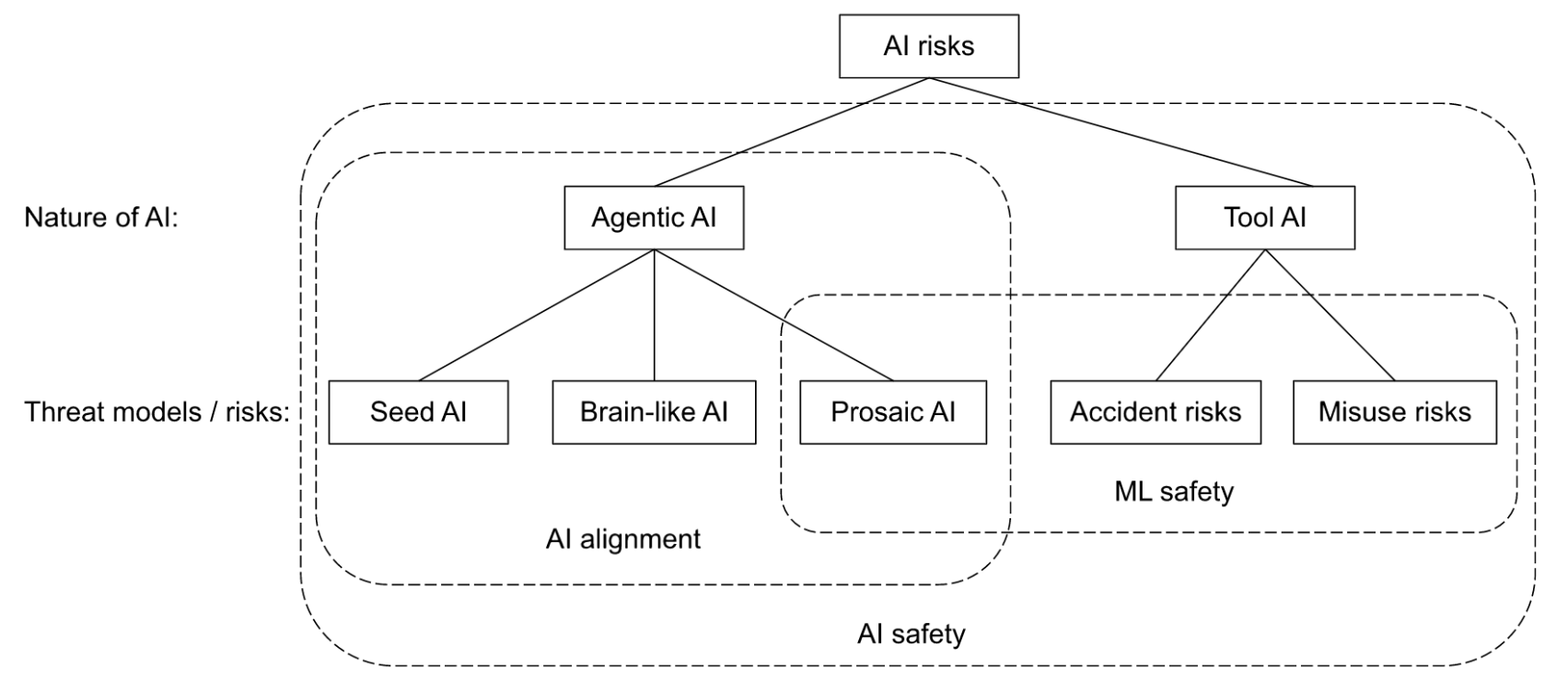
My mental model of the current paradigms of the AI safety related field which I recommend taking with a huge grain of salt.
AI risks
The types of risks that a powerful AI may pose is closely related to the nature of the AI, and AIs can broadly be categorized into:
- Agentic AI: Sometimes referred to as consequentialist AI, associated with the concept of consequentialism in philosophy, where the AI has a model of the world, is capable of making plans and executing them, and ‘cares’ about certain consequences. It can be said that such an AI is likely to have ‘general’ capabilities.
- Tool AI: Sometimes referred to as deontologist AI, associated with the concept of deontology in philosophy, where the AI only executes steps to fulfill certain tasks based on predefined rules. It can be said that such an AI is likely to have ‘narrow’ capabilities.
The alignment field is largely concerned with risks from agentic AGI, with the canonical example being a paperclip maximizer or “clippy” as it is often colloquially called. However, there has also been growing concern on failure modes caused by tool AIs, where catastrophes may be caused either by accidents or misuse by bad actors. Relevant research in these scenarios include AI regulation and cybersecurity, but tends to be outside the scope of ‘AI alignment’, though they seem to be within the scope of ML safety.
Potential catastrophes could have varying levels of severity, depending on the degree of misalignment and the capabilities of the AGI. Nevertheless, the general argument is that a misaligned AGI poses an existential risk (“x-risk”), although some researchers in the field are also concerned with suffering risks (“s-risk”).
Threat models
A threat model is a combination of a development model that says how we get AGI and a risk model that says how AGI leads to existential catastrophe. As described below, the focus of the field has shifted between different paradigms of development models over time, where progress in deep learning contributed to much of the paradigm shifts. Tom Adamczewski’s post also describes how the arguments for development models have shifted over time.
Seed AI
Early discussions on AGIs have started even before the deep learning era. This paradigm revolves around the concept of seed AI (coined by Eliezer Yudkowsky) which may initially not have superhuman capabilities but is able to achieve AGI through recursive self-improvement of its own source code (it is also worth noting that the concept of recursive self-improvement only describes the mechanism of capabilities advancement and is not mutually exclusive to the other paradigms).
Most of the research and publications at the time were from MIRI. They tend to focus on understanding the nature of intelligence and agency i.e. agent foundations, with much of their research work around embedded agency, decision theory, and value learning.
Prosaic AI
The prosaic AI alignment (coined by Paul Christiano) paradigm grew when deep learning gained traction and machine learning models were getting more powerful beyond expectations, and there were concerns that continued progress with such models could sufficiently advance towards AGI without requiring any fundamental breakthroughs in our understanding of intelligence.
While much of the AI progress was happening with organizations like OpenAI and DeepMind, much of the AI safety research in this paradigm also started within alignment teams of these organizations. Much of the research revolved around scalable oversight (such as AI safety via debate), specification gaming, and goal misgeneralization, with experiments conducted on reinforcement learning (RL) agents.
As neural networks rapidly scaled up in size, the question of ‘what is really going on inside neural networks’ garnered more attention, and researchers started looking more into interpretability. This includes interpreting what models are trying to do by observing their behavior through things like saliency maps, as well as more mechanistically by actually looking at the level of a single neuron or groups of them.
A slight shift in focus within this paradigm also happened later as large language models (LLMs) like GPT-3 became surprisingly impressive. Researchers started looking into things like how to train language models to behave in certain ‘good’ ways e.g. being honest and not harmful, as well as the nature of language models itself.
Brain-like AI
More recently, there started to be more research into how AGIs may be more brain-like, with some focus in neuroscience and evolutionary biology. There are also other adjacent researches on how humans form values e.g. shard theory.
Polarity
In addition to how we will achieve AGI, In the context of international relations, polarity describes the ways in which power is distributed. It is mostly assumed in the field that AGI takeoff is likely to be unipolar, where a single AGI gains decisive strategic advantage and be like a singleton. It would be great if the AGI is aligned to human values (whatever that means), and catastrophic otherwise. There are also multipolar scenarios where AGI takeoff happens with multiple superpowers instead, which may result in complex dynamics between those agents. A good understanding of game theory becomes especially relevant in this scenario.
Research type
Different types of research exist within the field, which can loosely be described as three types - conceptual, theoretical, and applied, roughly similar to Adam Shimi’s framing here. It may be helpful to think of them as ‘stages’ though they do not necessarily happen in clear sequential steps. As usual, these distinctions are sometimes less clear in practice, and it may be useful to think of them as spectrums instead of mutually exclusive buckets of research agenda.
Conceptual
Conceptual research aim to answer questions like:
- What the alignment problem entails, e.g. risks from learned optimization, list of lethalities
- Properties of an AGI, e.g. instrumental convergence, goal-directedness
- What a solution might look like, e.g. natural abstractions hypothesis, HCH
They usually involve deconfusion using informal arguments, and often draw knowledge from other fields.
Theoretical
Theoretical research generally deals with formalizing arguments, and it might also be fair to think of it as a subset of conceptual research. Examples of such research include formalizations of:
- Agency, e.g. cartesian frames, logical induction
- Proposed solutions, e.g. quantilization, infra-bayesianism
Needless to say, research in this area tends to be very heavy in math.
Applied
Applied research (or empirical work) is about conducting experiments to test hypotheses or potential solutions. These involve much more ‘hands on’ work on training machine learning (ML) models and mainly deal with research topics within the prosaic AI alignment paradigm.
Conclusion
Almost everyone in the AI safety field agrees with the core arguments that AIs could become much more powerful than they currently are, they have the potential of going badly, and that there are things we could do today to improve the outcome. Within the field, however, there are different paradigms that shape research agendas, and different types of research work that exists among the various researchers and research organizations. Hopefully, this post provides an overview on the field that helps map research agendas along the various paradigms, and gives some context to the implicit assumptions that researchers may have that may not be explicit in their writings.
Useful resources
Guides to AI alignment organizations and research agendas:
- 2021 AI Alignment Literature Review and Charity Comparison by Larks (updated annually)
- Alignment Org Cheat Sheet by Akash and Thomas Larsen
- (My understanding of) What Everyone in Technical Alignment is Doing and Why by Thomas Larsen and elifland
Guides to relevant communities:

