Epistemic status: exploratory. The numbers are straight from a public dataset; the correlations are just what came out. The oversight angle is my best guess, but I'm not married to it. This is only a week of collected data, with model-generated labels, so don't take any of this as gospel.
Anthropic's first-party API and Claude.ai both use the same model family. The API is 25 times faster and cheaper per token, but only gets things right about half the time. Claude.ai is slower, pricier, but nails it closer to 70%.
Both chew through millions of real-world tasks, both running the same model. That 20-point gap isn't about raw capability.
I dug into the public Anthropic Economic Index[1] dataset [2] to figure out what's behind this. It's about 2 million anonymized conversations from one week in February 2026, each mapped to O*NET occupational tasks. Both platforms are in there. If you want to poke at the code or notebooks, they're up on GitHub[3].
The natural experiment
There are 1,416 O*NET tasks that show up in both datasets. For 258 of them, I've got the full breakdown of collaboration modes. That means I can do a head-to-head: same task, same model, two different setups.
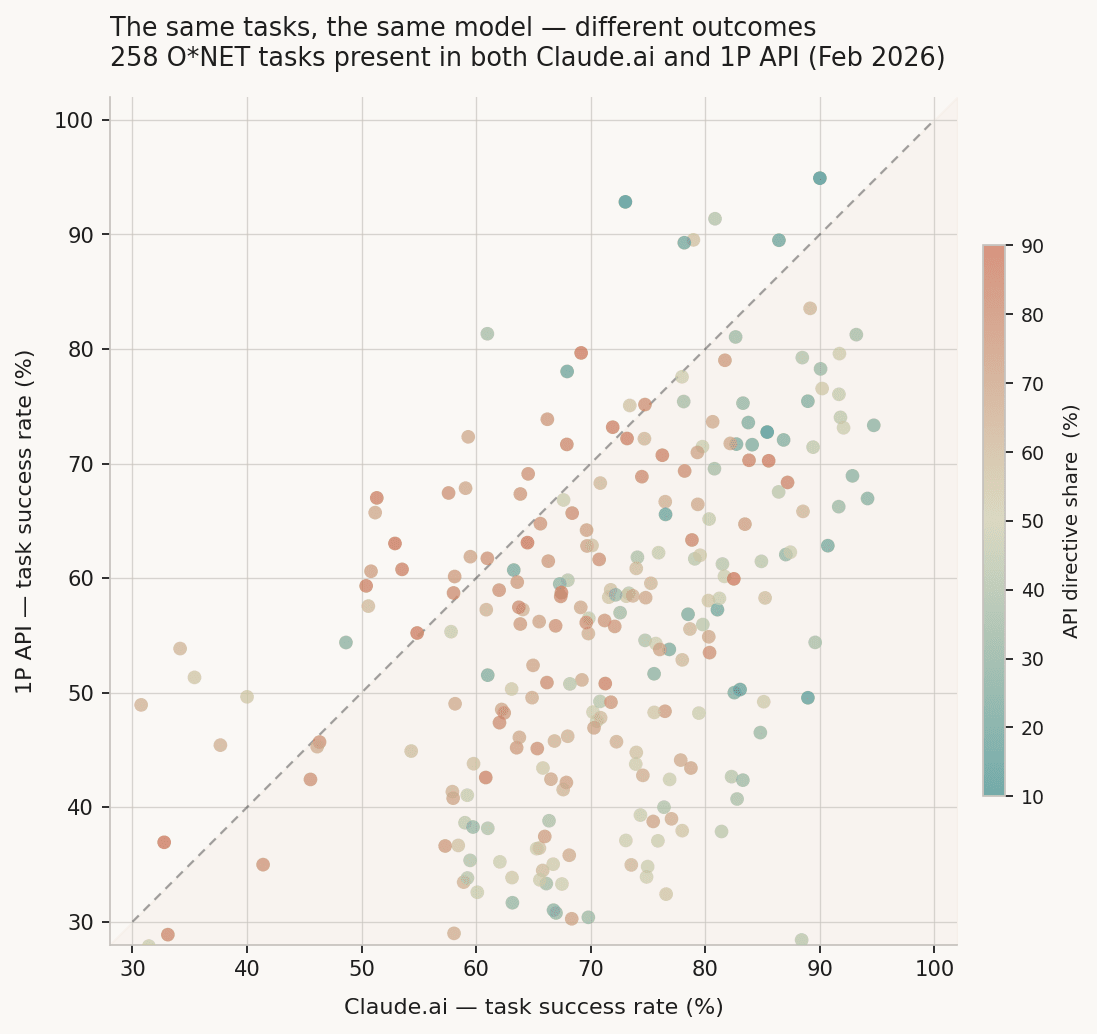
Figure 1. Per-task success rates for 258 ONET tasks are present in both Claude.ai and 1P API. Each point is one task. Diagonal = equal performance; points below the line = API underperforms. Color = API directive share on that task.*
Claude.ai comes out ahead on 85% of the shared tasks. On average, it's about 16 points better. The biggest gaps—those deep red dots below the diagonal—are mostly tasks where the API is used in a highly directive way.
The structural difference
Anthropic sorts every conversation into five collaboration modes: directive, feedback loop, task iteration, validation, and learning. The two platforms end up with totally different patterns.
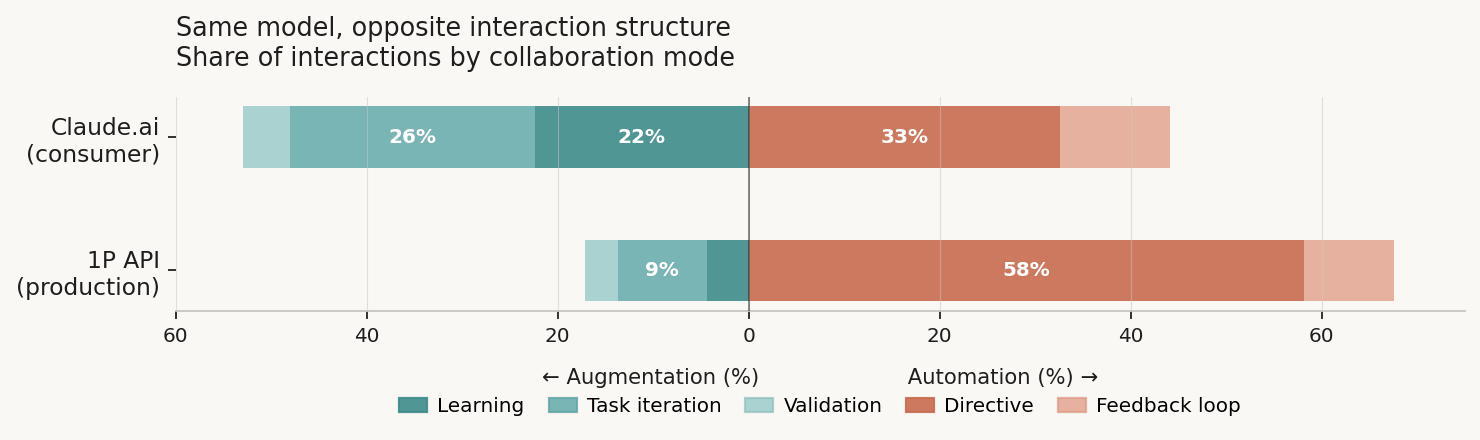
Figure 2. Interaction structure by platform. Augmentation modes (learning, task iteration, validation) run left; automation modes (directive, feedback loop) run right. Global averages, all conversations.
On the API, 58% of interactions are directive: the user hands off a task and just takes whatever comes back. On Claude.ai, that's only 33%. Learning mode flips the script: 22% on Claude.ai, just 4% on the API.
This isn't just about which tasks land on which platform. Even if I only look at the 258 shared tasks, the pattern sticks: API directive averages 56%, Claude.ai 29%. API learning is 14%, Claude.ai 34%.
Directive as the predictor
How the task is handled—its mode—predicts the success gap between platforms.
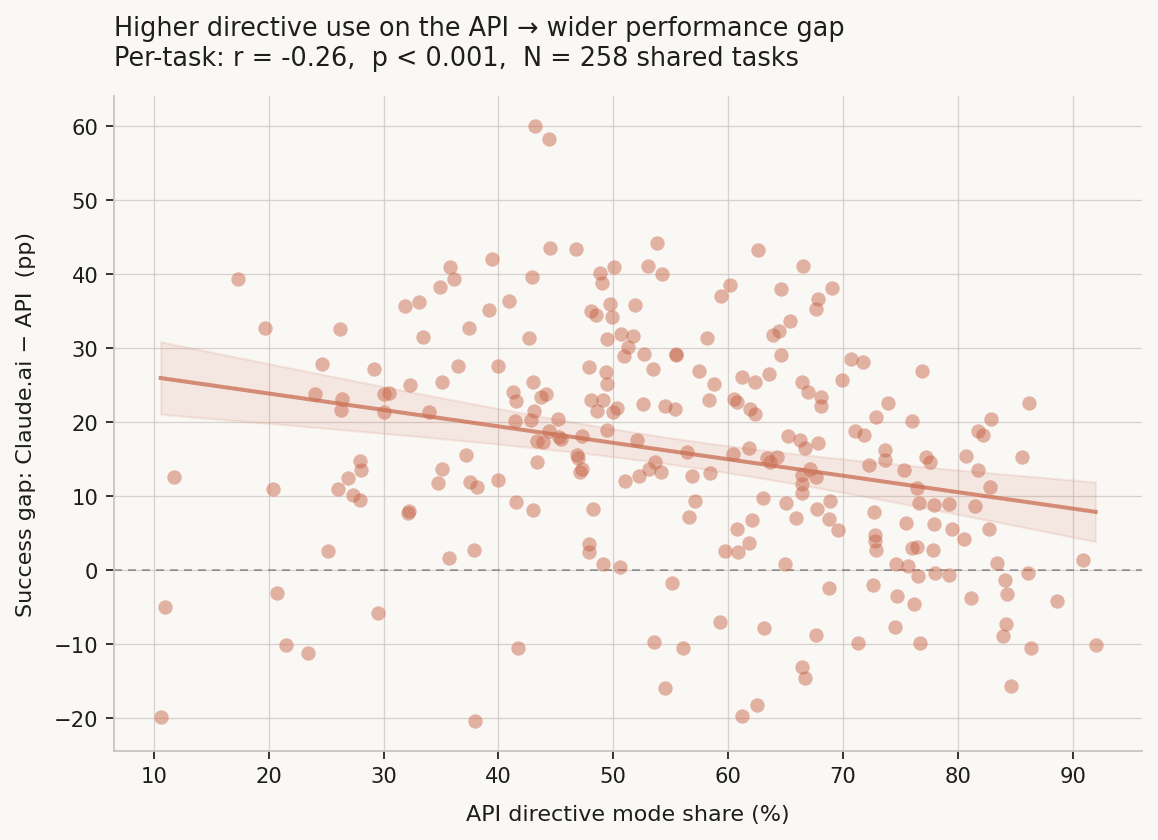
Figure 3. API directive share vs. per-task success gap (Claude.ai − API). Shaded band = 95% CI. As directive use rises on the API, that task's performance gap widens.
When the API mostly runs in directive mode, success averages about 58%. If directive is rare, success jumps over 80%. The correlation is negative and real: r = -0.263, p < 0.001, N = 258.
I checked if AI autonomy, learning share, or task-iteration share explained more of the gap. Directive share on the API is the strongest single predictor. Claude.ai's learning share also lines up with the gap (r = 0.158, p = 0.011): more learning mode on Claude.ai, bigger advantage over the API. Still, directive is the main thing.
The speed-oversight tradeoff
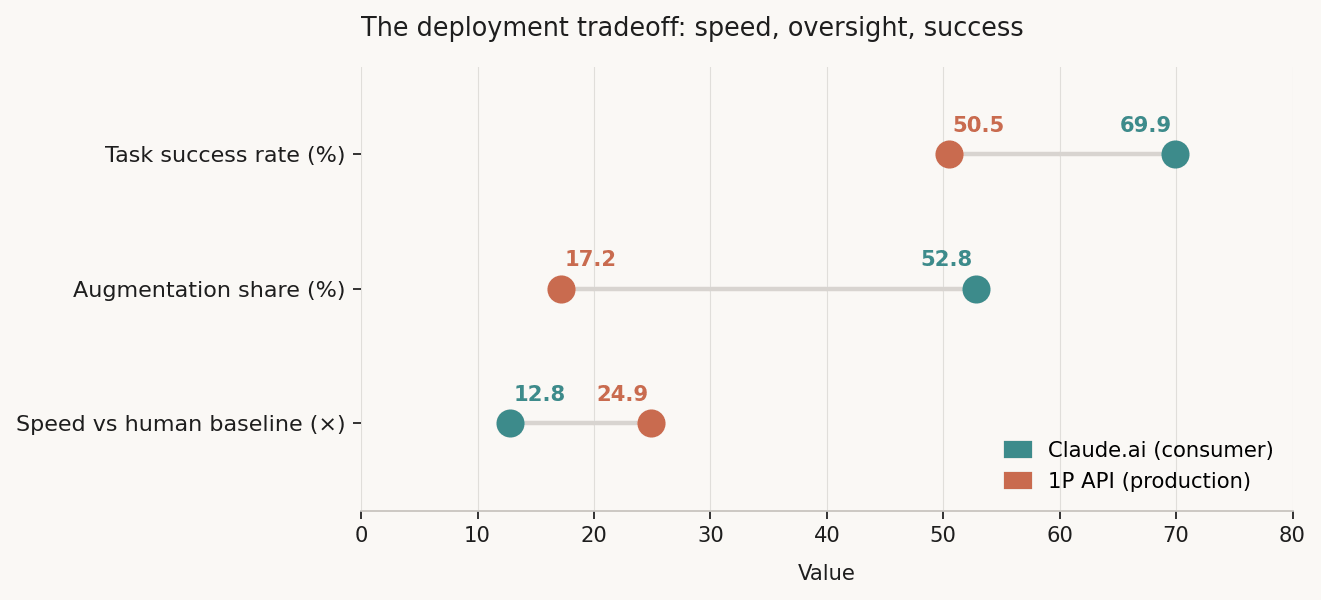
Figure 4. Three metrics evaluated across platforms. Claude.ai teal; 1P API coral. Speed = multiplier vs human-only baseline (human_only_time in hours / human_with_ai_time in minutes).
Claude.ai chops task time down by about 13 times. The API is even faster—almost 25 times quicker. So the API is twice as fast as Claude.ai on the same tasks, but it also misses the mark by 16 percentage points more. More speed, more failures, less human in the loop.
So what does all this actually mean?
Usually, people talk about human monitoring in AI as a question of what humans should be able to monitor. But this data points at something else: what actually happens to oversight when speed is what matters most?
Production API setups are built for throughput. That means fewer turns per task, less back-and-forth, and less human decision in the loop. The pattern that gets you the most throughput—directive mode—is also the one that leads to the worst results. This isn't an accident. You finish faster because you skip the human check-ins. You fail more for exactly the same reason.
This lines up with what people have argued about scalable oversight [see e.g., Christiano et al.]: keeping humans meaningfully involved gets harder as AI scales, mostly because the economics push the other way. Here, you can see that dynamic happening right now, not simply as a future worry. The API isn't being misused. It's working exactly as intended—and that intention trades off success and oversight for speed.
This doesn't settle any big safety arguments. But I haven't seen anyone actually put numbers on the tradeoff between speed, success, and human-in-the-loop rates from real-world usage like this before.
The cruxes
For the main claim to stick—that taking humans out of the loop leads to worse results—a couple things have to be true. Here are the big ones:
Crux 1: The "success" label is meaningful. Task success is Anthropic's model-generated classification, not an independent outcome measure. If success labels are systematically more likely to be assigned to learning-mode interactions for reasons unrelated to actual outcomes (e.g., the model rates conversations where the human is engaged as "successful" regardless of whether the task was done well), the correlation is artifactual. What would change my mind: evidence that task_success is uncorrelated with independent quality measures, or that it's mode-contingent in the labeling process.
Crux 2: The mode distribution isn't downstream of task difficulty. If directive-heavy API tasks are also inherently harder (ambiguous, underspecified), then both the directive interaction and the low success rate are caused by task difficulty rather than by each other. The fact that this pattern holds for shared tasks — the same task, on both platforms — reduces but doesn't eliminate this concern. What would change my mind: a within-task design where the same user attempts the same task via both platforms, with success measured independently.
Limitations
This is just one week of data. Both the task labels and the collaboration modes come from the model, so there's error on both sides. Random noise would make the correlations look weaker than they really are; systematic mislabeling could create patterns I can't see.
The 258 shared tasks with full mode data aren't a random slice of the 1,416 shared tasks—they're just the ones where Anthropic's pipeline spit out complete records. That selection could skew the comparison.
The March 2026 report [2] found that users with six months or more do better and move toward augmentation, but that variable isn't in the public data. The deployment-context and tenure findings go together, but I can't connect them directly.
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...