AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
Adapted from my Substack, Funding Anthropalypse.
Short version: if you want a share of the coming Anthropic and OpenAI windfall - the $37bn+ that could be in play next year - the way in is to become 'legibly excellent', so the evaluators and donors that frontier lab staff already trust point them to yo...
Note from Aaron: I found this well after it was posted on LessWrong and cross-posted it here with Critch's permission. He won't necessarily be checking comments here.
Crossposted from the AI Alignment Forum. May contain more technical jargon than usual.
Introduction
This post is an overview of a variety of AI research areas in terms of how much I think contributing to and/or learning from those areas might help reduce AI x-risk. By research areas I mean “AI research topics that already have groups of people working on them and writing up their results”, as opposed to research “directions” in which I’d like to see these areas “move”.
I formed these views mostly pursuant to writing AI Research Considerations for Human Existential Safety (ARCHES). My hope is that my assessments in this post can be helpful to students and established AI researchers who are thinking about shifting into new research areas specifically with the goal of contributing to existential safety somehow. In these assessments, I find it important to distinguish between the following types of value:
The helpfulness of the area to existential safety, which I think of as a function of what services are likely to be provided as a result of research contributions to the area, and whether those services will be helpful to existential safety, versus
The educational value of the area for thinking about existential safety, which I think of as a function of how much a researcher motivated by existential safety might become more effective through the process of familiarizing with or contributing to that area, usually by focusing on ways the area could be used in service of existential safety.
The neglect of the area at various times, which is a function of how much technical progress has been made in the area relative to how much I think is needed.
Importantly:
The helpfulness to existential safety scores do not assume that your contributions to this area would be used only for projects with existential safety as their mission. This can negatively impact the helpfulness of contributing to areas that are more likely to be used in ways that harm existential safety.
The educational value scores are not about the value of an existential-safety-motivated researcher teaching about the topic, but rather, learning about the topic.
The neglect scores are not measuring whether there is enough “buzz” around the topic, but rather, whether there has been adequate technical progress in it. Buzz can predict future technical progress, though, by causing people to work on it.
Below is a table of all the areas I considered for this post, along with their entirely subjective “scores” I’ve given them. The rest of this post can be viewed simply as an elaboration/explanation of this table:
ExistingResearch Area
SocialApplication
Helpfulnessto Existential Safety
EducationalValue
2015Neglect
2020Neglect
2030Neglect
Out of Distribution Robustness
Zero/ Single
1/10
4/10
5/10
3/10
1/10
Agent Foundations
Zero/ Single
3/10
8/10
9/10
8/10
7/10
Multi-agent RL
Zero/ Multi
2/10
6/10
5/10
4/10
0/10
Preference Learning
Single/ Single
1/10
4/10
5/10
1/10
0/10
Side-effect Minimization
Single/ Single
4/10
4/10
6/10
5/10
4/10
Human-Robot Interaction
Single/ Single
6/10
7/10
5/10
4/10
3/10
Interpretability in ML
Single/ Single
8/10
6/10
8/10
6/10
2/10
Fairness in ML
Multi/ Single
6/10
5/10
7/10
3/10
2/10
Computational Social Choice
Multi/ Single
7/10
7/10
7/10
5/10
4/10
Accountability in ML
Multi/ Multi
8/10
3/10
8/10
7/10
5/10
The research areas are ordered from least-socially-complex to most-socially-complex. This roughly (though imperfectly) correlates with addressing existential safety problems of increasing importance and neglect, according to me. Correspondingly, the second column categorizes each area according to the simplest human/AI social structure it applies to:
These views are my own, and while others may share them, I do not intend to speak in this post for any institution or group of which I am part.
I am not an expert in Science, Technology, and Society (STS). Historically there hasn’t been much focus on existential risk within STS, which is why I’m not citing much in the way of sources from STS. However, from its name, STS as a discipline ought to be thinking a lot about AI x-risk. I think there’s a reasonable chance of improvement on this axis over the next 2-3 years, but we’ll see.
I made this post with essentially zero deference to the judgement of other researchers. This is academically unusual, and prone to more variance in what ends up being expressed. It might even be considered rude. Nonetheless, I thought it might be valuable or at least interesting to stimulate conversation on this topic that is less filtered through patterns deference to others. My hope is that people can become less inhibited in discussing these topics if my writing isn’t too “polished”. I might also write a more deferent and polished version of this post someday, especially if nice debates arise from this one that I want to distill into a follow-up post.
Defining our objectives
In this post, I’m going to talk about AI existential safety as distinct from both AI alignment and AI safety as technical objectives. A number of blogs seem to treat these terms as near-synonyms (e.g., LessWrong, the Alignment Forum), and I think that is a mistake, at least when it comes to guiding technical work for existential safety. First I’ll define these terms, and then I’ll elaborate on why I think it’s important not to conflate them.
AI existential safety (definition)
In this post, AI existential safety means “preventing AI technology from posing risks to humanity that are comparable to or greater than human extinction in terms of their moral significance.”
This is a bit more general than the definition in ARCHES. I believe this definition is fairly consistent with Bostrom’s usage of the term “existential risk”, and will have reasonable staying power as the term “AI existential safety” becomes more popular, because it directly addresses the question “What does this term have to do with existence?”.
AI safety (definition)
AI safety generally means getting AI systems to avoid risks, of which existential safety is an extreme special case with unique challenges. This usage is consistent with normal everyday usage of the term “safety” (dictionary.com/browse/safety), and will have reasonable staying power as the term “AI safety” becomes (even) more popular. AI safety includes safety for self-driving cars as well as for superintelligences, including issues that these topics do and do not share in common.
AI ethics (definition)
AI ethics generally refers to principles that AI developers and systems should follow. The “should” here creates a space for debate, whereby many people and institutions can try to impose their values on what principles become accepted. Often this means AI ethics discussions become debates about edge cases that people disagree about instead of collaborations on what they agree about. On the other hand, if there is a principle that all or most debates about AI ethics would agree on or take as a premise, that principle becomes somewhat easier to enforce.
AI governance (definition)
AI governance generally refers to identifying and enforcing norms for AI developers and AI systems themselves to follow. The question of which principles should be enforced often opens up debates about safety and ethics. Governance debates are a bit more action-oriented than purely ethical debates, such that more effort is focussed on enforcing agreeable norms relative to debating about disagreeable norms. Thus, AI governance, as an area of human discourse, is engaged with the problem of aligning the development and deployment of AI technologies with broadly agreeable human values. Whether AI governance is engaged with this problem well or poorly is, of course, a matter of debate.
AI alignment (definition)
AI alignment usually means “Getting an AI system to {try | succeed} to do what a human person or institution wants it to do”. The inclusion of “try” or “succeed” respectively creates a distinction between intent alignment and impact alignment. This usage is consistent with normal everyday usage of the term “alignment” (dictionary.com/browse/alignment) as used to refer to alignment of values between agents, and is therefore relatively unlikely to undergo definition-drift as the term “AI alignment” becomes more popular. For instance,
(2002) “Alignment” was used this way in 2002 by Daniel Shapiro and Ross Shachter, in their AAAI conference paper User/Agent Value Alignment, the first paper to introduce the concept of alignment into AI research. This work was not motivated by existential safety as far as I know, and is not cited in any of the more recent literature on “AI alignment” motivated by existential safety, though I think it got off to a reasonably good start in defining user/agent value alignment.
(2014) “Alignment” was used this way in the technical problems described by Nate Soares and Benya Fallenstein in Aligning Superintelligence with Human Interests: A Technical Research Agenda. While the authors’ motivation is clearly to serve the interests of all humanity, the technical problems outlined are all about impact alignment in my opinion, with the possible exception of what they call “Vingean Reflection” (which is necessary for a subagent of society thinking about society).
(2018) “Alignment” is used this way by Paul Christiano in his post Clarifying AI Alignment, which is focussed on intent alignment.
A broader meaning of “AI alignment” that is not used here
There is another, different usage of “AI alignment”, which refers to ensuring that AI technology is used and developed in ways that are broadly aligned with human values. I think this is an important objective that is deserving of a name to call more technical attention to it, and perhaps this is the spirit in which the “AI alignment forum” is so-titled. However, the term “AI alignment” already has poor staying-power for referring to this objective in technical discourse outside of a relatively cloistered community, for two reasons:
As described above, “alignment” already has a relatively clear technical meaning that AI researchers have already gravitated towards interpreting “alignment” to mean, that is also consistent with natural language meaning of the term “alignment”, and
AI governance, at least in democratic states, is basically already about this broader problem. If one wishes to talk about AI governance that is beneficial to most or all humans, “humanitarian AI governance” is much clearer and more likely to stick than “AI alignment”.
Perhaps “global alignment”, “civilizational alignment”, or “universal AI alignment” would make sense to distinguish this concept from the narrower meaning that alignment usually takes on in technical settings. In any case, for the duration of this post, I am using “alignment” to refer to its narrower, technically prevalent meaning.
Distinguishing our objectives
As promised, I will now elaborate on why it’s important not to conflate the objectives above. Some people might feel that these arguments are about how important these concepts are, but I’m mainly trying to argue about how importantly different they are. By analogy: while knives and forks are both important tools for dining, they are not usable interchangeably.
Safety vs existential safety (distinction)
“Safety” is not robustly usable as a synonym for “existential safety”. It is true that AI existential safety is literally a special case of AI safety, for the simple reason that avoiding existential risk is a special case of avoiding risk. And, it may seem useful for coalition-building purposes to unite people under the phrase “AI safety” as a broadly agreeable objective. However, I think we should avoid declaring to ourselves or others that “AI safety” will or should always be interpreted as meaning “AI existential safety”, for several reasons:
Using these terms as synonyms will have very little staying power as AI safety research becomes (even) more popular.
AI existential safety is deserving of direct attention that is not filtered through a lens of discourse that confuses it with self-driving car safety.
AI safety in general is deserving of attention as a broadly agreeable principle around which people can form alliances and share ideas.
Alignment vs existential safety (distinction)
Some people tend to use these terms as as near-synonyms, however, I think this usage has some important problems:
Using “alignment” and “existential safety” as synonyms will have poor staying-power as the term “AI alignment” becomes more popular. Conflating them will offend both the people who want to talk about existential safety (because they think it is more important and “obviously what we should be talking about”) as well as the people who want to talk about AI alignment (because they think it is more important and “obviously what we should be talking about”).
AI alignment refers to a cluster of technically well-defined problems that are important to work on for numerous reasons, and deserving of a name that does not secretly mean “preventing human extinction” or similar.
AI existential safety (I claim) also refers to a technically well-definable problem that is important to work on, and deserving of a name that does not secretly mean “getting systems to do what the user is asking”.
AI alignment is not trivially helpful to existential safety, and efforts to make it helpful require a certain amount of societal-scale steering to guide them. If we treat these terms as synonyms, we impoverish our collective awareness of ways in which AI alignment solutions could pose novel problems for existential safety.
This last point gets its own section.
AI alignment is inadequate for AI existential safety
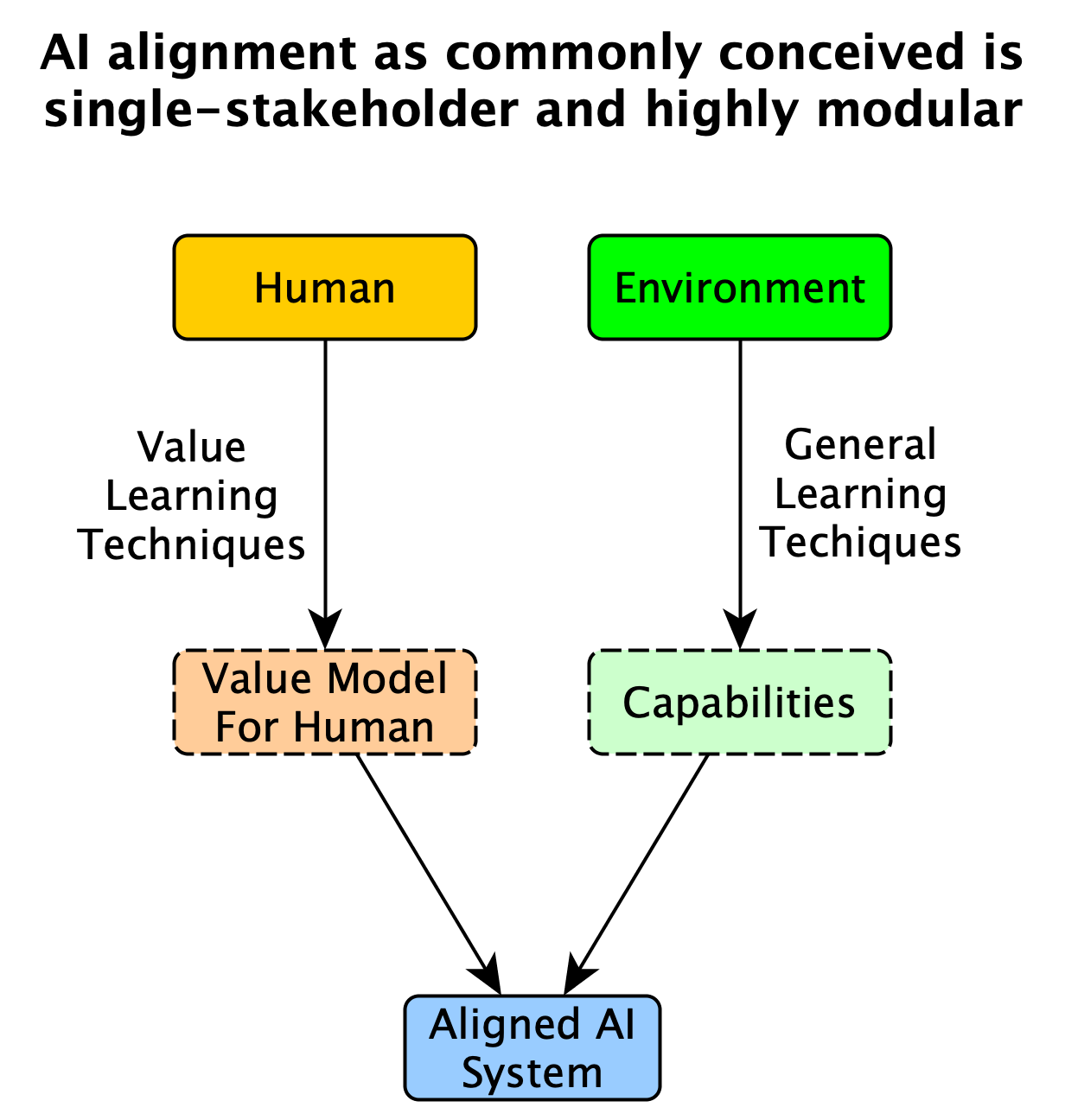
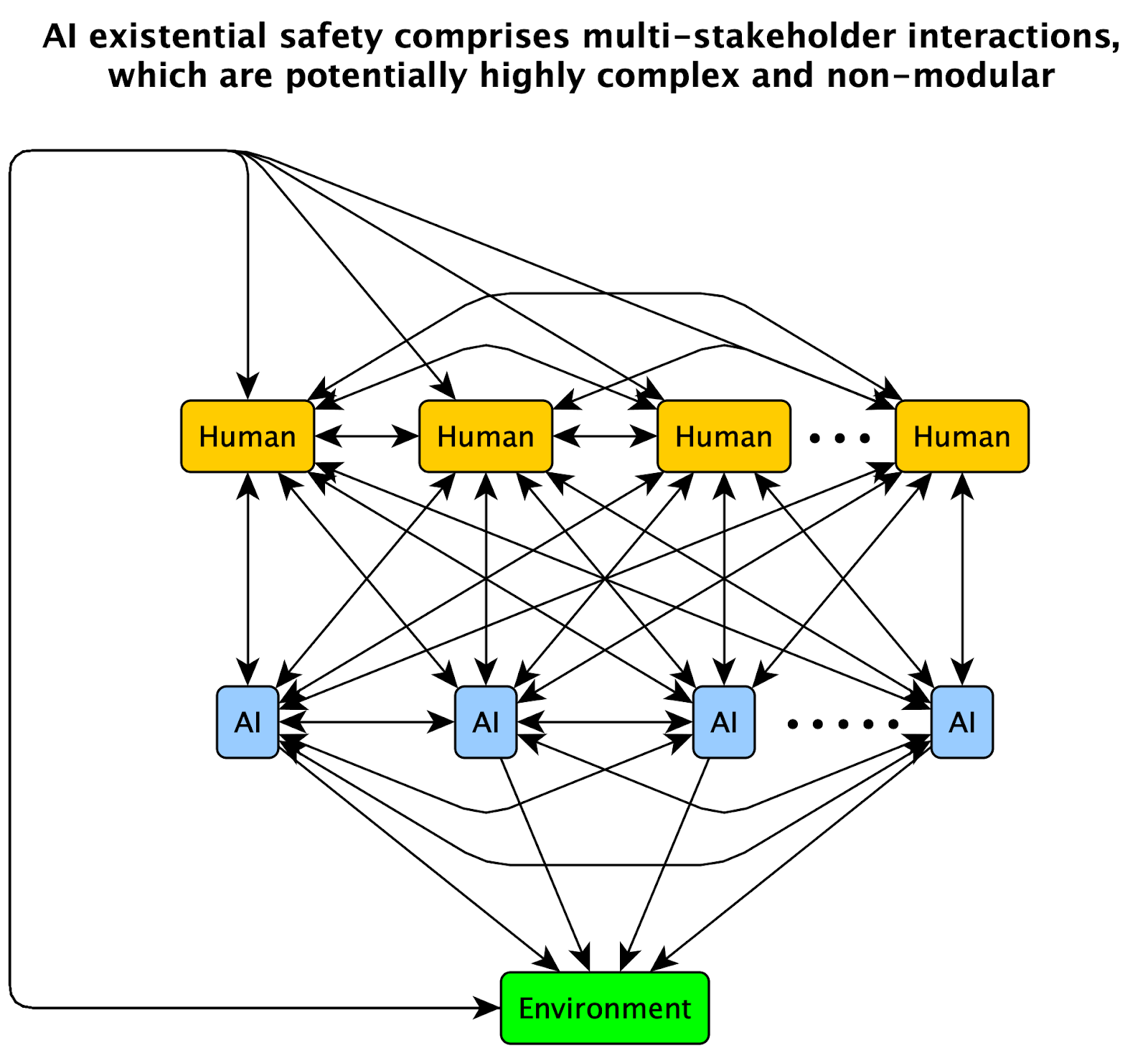
Around 50% of my motivation for writing this post is my concern that progress in AI alignment, which is usually focused on “single/single” interactions (i.e., alignment for a single human stakeholder and a single AI system), is inadequate for ensuring existential safety for advancing AI technologies. Indeed, among problems I can currently see in the world that I might have some ability to influence, addressing this issue is currently one of my top priorities.
The reason for my concern here is pretty simple to state, via the following two diagrams:
Of course, understanding and designing useful and modular single/single interactions is a good first step toward understanding multi/multi interactions, and many people (including myself) who think about AI alignment are thinking about it as a stepping stone to understanding the broader societal-scale objective of ensuring existential safety.
However, this pattern mirrors the situation AI capabilities research was following before safety, ethics, and alignment began surging in popularity. Consider that most AI (construed to include ML) researchers are developing AI capabilities as stepping stones toward understanding and deploying those capabilities in safe and value-aligned applications for human users. Despite this, over the past decade there has been a growing sense among AI researchers that capabilities research has not been sufficiently forward-looking in terms of anticipating its role in society, including the need for safety, ethics, and alignment work. This general concern can be seen emanating not only from AGI-safety-oriented groups like those at DeepMind, OpenAI, MIRI, and in academia, but also AI-ethics-oriented groups as well, such as the ACM Future of Computing Academy:
Just as folks interested in AI safety and ethics needed to start thinking beyond capabilities, folks interested in AI existential safety need to start thinking beyond alignment. The next section describes what I think this means for technical work.
Anticipating, legitimizing and fulfilling governance demands
The main way I can see present-day technical research benefitting existential safety is by anticipating, legitimizing and fulfillinggovernance demands for AI technology that will arise over the next 10-30 years. In short, there often needs to be some amount of traction on a technical area before it’s politically viable for governing bodies to demand that institutions apply and improve upon solutions in those areas. Here’s what I mean in more detail:
By governance demands, I’m referring to social and political pressures to ensure AI technologies will produce or avoid certain societal-scale effects. Governance demands include pressures like “AI technology should be fair”, “AI technology should not degrade civic integrity”, or “AI technology should not lead to human extinction.” For instance, Twitter’s recent public decision to maintain a civic integrity policy can be viewed as a response to governance demand from its own employees and surrounding civic society.
Governance demand is distinct from consumer demand, and it yields a different kind of transaction when the demand is met. In particular, when a tech company fulfills a governance demand, the company legitimizes that demand by providing evidence that it is possible to fulfill. This might require the company to break ranks with other technology companies who deny that the demand is technologically achievable.
By legitimizing governance demands, I mean making it easier to establish common knowledge that a governance demand is likely to become a legal or professional standard. But how can technical research legitimize demands from a non-technical audience?
The answer is to genuinely demonstrate in advance that the governance demands are feasible to meet. Passing a given professional standard or legislation usually requires the demands in it to be “reasonable” in terms of appearing to be technologically achievable. Thus, computer scientists can help legitimize a governance demand by anticipating the demand in advance, and beginning to publish solutions for it. My position here is not that the solutions should be exaggerated in their completeness, even if that will increase ‘legitimacy’; I argue only that we should focus energy on finding solutions that, if communicated broadly and truthfully, will genuinely raise confidence that important governance demands are feasible. (Without this ethic against exaggeration, common knowledge of the legitimacy of legitimacy itself is degraded, which is bad, so we shouldn’t exaggerate.)
This kind of work can make a big difference to the future. If the algorithmic techniques needed to meet a given governance demand are 10 years of research away from discovery---as opposed to just 1 year---then it’s easier for large companies to intentionally or inadvertently maintain a narrative that the demand is unfulfillable and therefore illegitimate. Conversely, if the algorithmic techniques to fulfill the demand already exist, it’s a bit harder (though still possible) to deny the legitimacy of the demand. Thus, CS researchers can legitimize certain demands in advance, by beginning to prepare solutions for them.
I think this is the most important kind of work a computer scientist can do in service of existential safety. For instance, I view ML fairness and interpretability research as responding to existing governance demand, which (genuinely) legitimizes the cause of AI governance itself, which is hugely important. Furthermore, I view computational social choice research as addressing an upcoming governance demand, which is even more important.
My hope in writing this post is that some of the readers here will start trying to anticipate AI governance demands that will arise over the next 10-30 years. In doing so, we can begin to think about technical problems and solutions that could genuinely legitimize and fulfill those demands when they arise, with a focus on demands whose fulfillment can help stabilize society in ways that mitigate existential risks.
Research Areas
Alright, let’s talk about some research!
Out of distribution robustness (OODR)
ExistingResearch Area
SocialApplication
Helpfulnessto Existential Safety
EducationalValue
2015Neglect
2020Neglect
2030Neglect
Out of Distribution Robustness
Zero/Single
1/10
4/10
5/10
3/10
1/10
This area of research is concerned with avoiding risks that arise from systems interacting with contexts and environments that are changing significantly over time, such as from training time to testing time, from testing time to deployment time, or from controlled deployments to uncontrolled deployments.
OODR (un)helpfulness to existential safety:
Contributions to OODR research are not particularly helpful to existential safety in my opinion, for a combination of two reasons:
Progress in OODR will mostly be used to help roll out more AI technologies into active deployment more quickly, and
Research in this area usually does not involve deep or lengthy reflections about the structure of society and human values and interactions, which I think makes this field sort of collectively blind to the consequences of the technologies it will help build.
I think this area would be more helpful if it were more attentive to the structure of the multi-agent context that AI systems will be in. Professor Tom Dietterich has made some attempts to shift thinking on robustness to be more attentive to the structure of robust human institutions, which I think is a good step:
Unfortunately, the above paper has only 8 citations at the time of writing (very little for AI/ML), and there does not seem to be much else in the way of publications that address societal-scale or even institutional-scale robustness.
OODR educational value:
Studying and contributing to OODR research is of moderate educational value for people thinking about x-risk, in my opinion. Speaking for myself, it helps me think about how society as a whole is receiving a changing distribution of inputs from its environment (which society itself is creating). As human society changes, the inputs to AI technologies will change, and we want the existence of human society to be robust to those changes. I don’t think most researchers in this area think about it in that way, but that doesn’t mean you can’t.
OODR neglect:
Robustness to changing environments has never been a particularly neglected concept in the history of automation, and it is not likely to ever become neglected, because myopic commercial incentives push so strongly in favor of progress on it. Specifically, robustness of AI systems is essential for tech companies to be able to roll out AI-based products and services, so there is no lack of incentive for the tech industry to work on robustness. In reinforcement learning specifically, robustness has been somewhat neglected, although less so now than in 2015, partly thanks to AI safety (broadly construed) taking off. I think by 2030 this area will be even less neglected, even in RL.
OODR exemplars:
Recent exemplars of high value to existential safety, according to me:
This area is concerned with developing and investigating fundamental definitions and theorems pertaining to the concept of agency. This often includes work in areas such as decision theory, game theory, and bounded rationality. I’m going to write more for this section because I know more about it and think it’s pretty important to “get right”.
AF (un)helpfulness to existential safety:
Contributions to agent foundations research are key to the foundations of AI safety and ethics, but are also potentially misusable. Thus, arbitrary contributions to this area are not necessarily helpful, while targeted contributions aimed at addressing real-world ethical problems could be extremely helpful. Here is why I believe this:
I view agent foundations work as looking very closely at the fundamental building blocks of society, i.e., agents and their decisions. It’s important to understand agents and their basic operations well, because we’re probably going to produce (or allow) a very large number of them to exist/occur. For instance, imagine any of the following AI-related operations happening at least 1,000,000 times (a modest number given the current world population):
A human being delegates a task to an AI system to perform, thereby ceding some control over the world to the AI system.
An AI system makes a decision that might yield important consequences for society, and acts on it.
A company deploys an AI system into a new context where it might have important side effects.
An AI system builds or upgrades another AI system (possibly itself) and deploys it.
An AI system interacts with another AI system, possibly yielding externalities for society.
An hour passes where AI technology is exerting more control over the state of the Earth than humans are.
Suppose there's some class of negative outcomes (e.g. human extinction) that we want to never occur as a result of any of these operations. In order to be just 55% sure that all of these 1,000,000 operations will be safe (i.e., avoid the negative outcome class), on average (on a log scale) we need to be at least 99.99994% sure that each instance of the operation is safe (i.e., will not precipitate the negative outcome). Similarly, for any accumulable quantity of “societal destruction” (such as risk, pollution, or resource exhaustion), in order to be sure that these operations will not yield “100 units” of societal destruction, we need each operation on average to produce at most “0.00001 units” of destruction.*
(*Would-be-footnote: Incidentally, the main reason I think OODR research is educationally valuable is that it can eventually help with applying agent foundations research to societal-scale safety. Specifically: how can we know if one of the operations (a)-(f) above is safe to perform 1,000,000 times, given that it was safe the first 1,000 times we applied it in a controlled setting, but the setting is changing over time? This is a special case of an OODR question.)
Unfortunately, understanding the building blocks of society can also allow the creation of potent societal forces that would harm society. For instance, understanding human decision-making extremely well might help advertising companies to control public opinion to an unreasonable degree (which arguably has already happened, even with today’s rudimentary agent models), or it might enable the construction of a super-decision-making system that is misaligned with human existence.
That said, I don’t think this means you have to be super careful about information security around agent foundations work, because in general it’s not easy to communicate fundamental theoretical results in research, let alone by accident.
Rather, my recommendation for maximizing the positive value of work in this area is to apply the insights you get from it to areas that make it easier to represent societal-scale moral values in AI. E.g., I think applications of agent foundations results to interpretability, fairness, computational social choice, and accountability are probably net good, whereas applications to speed up arbitrary ML capabilities are not obviously good.
AF educational value:
Studying and contributing to agent foundations research has the highest educational value for thinking about x-risk among the research areas listed here, in my opinion. The reason is that agent foundations research does the best job of questioning potentially faulty assumptions underpinning our approach to existential safety. In particular, I think our understanding of how to safely integrate AI capabilities with society is increasingly contingent on our understanding of agent foundations work as defining the building blocks of society.
AF neglect:
This area is extremely neglected in my opinion. I think around 50% of the progress in this area, worldwide, happens at MIRI, which has a relatively small staff of agent foundations researchers. While MIRI has grown over the past 5 years, agent foundations work in academia hasn’t grown much, and I don’t expect it to grow much by default (though perhaps posts like this might change that default).
AF exemplars:
Below are recent exemplars of agent foundations work that I think is of relatively high value to existential safety, mostly via their educational value to understanding the foundations of how agents work ("agent foundations"). The work is mostly from three main clusters: MIRI, Vincent Conitzer's group at Duke, and Joe Halpern's group at Cornell.
(2016) Logical induction, Garrabrant, Scott; Benson-Tilsen, Tsvi; Critch, Andrew; Soares, Nate; Taylor, Jessica. * *COI note: I am a coauthor on the above paper. If many other people were writing existential safety appraisals like this post, I’d omit my own papers from this list and defer to others to judge them.
MARL is concerned with training multiple agents to interact with each other and solve problems using reinforcement learning. There are a few varieties to be aware of:
Cooperative vs competitive vs adversarial tasks: do the agents all share a single objective, or separate objectives that are imperfectly aligned, or completely opposed (zero-sum) objective?
Centralized training vs decentralized training: is there a centralized process that observes the agents and controls how they learn, or is there a separate (private) learning process for each agent?
Communicative vs non-communicative: is there a special channel the agents can use to generate observations for each other that are otherwise inconsequential, or are all observations generated in the course of consequential actions?
I think the most interesting MARL research involves decentralized training for competitive objectives in communicative environments, because this set-up is the most representative of how AI systems from diverse human institutions are likely to interact.
MARL (un)helpfulness to existential safety:
Contributions to MARL research are mostly not very helpful to existential safety in my opinion, because MARL’s most likely use case will be to help companies to deploy fleets of rapidly interacting machines that might pose risks to human society. The MARL projects with the greatest potential to help are probably those that find ways to achieve cooperation between decentrally trained agents in a competitive task environment, because of its potential to minimize destructive conflicts between fleets of AI systems that cause collateral damage to humanity. That said, even this area of research risks making it easier for fleets of machines to cooperate and/or collude at the exclusion of humans, increasing the risk of humans becoming gradually disenfranchised and perhaps replaced entirely by machines that are better and faster at cooperation than humans.
MARL educational value:
I think MARL has a high educational value, because it helps researchers to observe directly how difficult it is to get multi-agent systems to behave well. I think most of the existential risk from AI over the next decades and centuries comes from the incredible complexity of behaviors possible from multi-agent systems, and from underestimating that complexity before it takes hold in the real world and produces unexpected negative side effects for humanity.
MARL neglect:
MARL was somewhat neglected 5 years ago, but has picked up a lot. I suspect MARL will keep growing in popularity because of its value as a source of curricula for learning algorithms. I don’t think it is likely to become more civic-minded, unless arguments along the lines of this post lead to a shift of thinking in the field.
MARL exemplars:
Recent exemplars of high educational value, according to me:
This area is concerned with learning about human preferences in a form usable for guiding the policies of artificial agents. In an RL (reinforcement learning) setting, preference learning is often called reward learning, because the learned preferences take the form of a reward function for training an RL system.
PL (un)helpfulness to existential safety:
Contributions to preference learning are not particularly helpful to existential safety in my opinion, because their most likely use case is for modeling human consumers just well enough to create products they want to use and/or advertisements they want to click on. Such advancements will be helpful to rolling out usable tech products and platforms more quickly, but not particularly helpful to existential safety.*
Preference learning is of course helpful to AI alignment, i.e., theproblem of getting an AI system to do something a human wants. Please refer back to the sections above on Defining our objectives and Distinguishing our objectives for an elaboration of how this is not the same as AI existential safety. In any case, I see AI alignment in turn as having two main potential applications to existential safety:
AI alignment is useful as a metaphor for thinking about how to align the global effects of AI technology with human existence, a major concern for AI governance at a global scale, and
AI alignment solutions could be used directly to govern powerful AI technologies designed specifically to make the world safer.
While many researchers interested in AI alignment are motivated by (1) or (2), I find these pathways of impact problematic. Specifically,
(1) elides the complexities of multi-agent interactions I think are likely to arise in most realistic futures, and I think the most difficult to resolve existential risks arise from those interactions.
(2) is essentially aiming to take over the world in the name of making it safer, which is not generally considered the kind of thing we should be encouraging lots of people to do.
Moreover, I believe contributions to AI alignment are also generally unhelpful to existential safety, for the same reasons as preference learning. Specifically, progress in AI alignment hastens the pace at which high-powered AI systems will be rolled out into active deployment, shortening society’s headway for establishing international treaties governing the use of AI technologies.
Thus, the existential safety value of AI alignment research in its current technical formulations—and preference learning as a subproblem of it—remains educational in my view.*
(*Would-be-footnote: I hope no one will be too offended by this view. I did have some trepidation about expressing it on the “alignment’ forum, but I think I should voice these concerns anyway, for the following reason. In 2011 after some months of reflection on a presentation by Andrew Ng, I came to believe that that deep learning was probably going to take off, and that, contrary to Ng’s opinion, this would trigger a need for a lot of AI alignment work in order to make the technology safe. This feeling of worry is what triggered me to cofound CFAR and start helping to build a community that thinks more critically about the future. I currently have a similar feeling of worry toward preference learning and AI alignment, i.e., that it is going to take off and trigger a need for a lot more “AI civility” work that seems redundant or “too soon to think about” for a lot of AI alignment researchers today, the same way that AI researchers said it was “too soon to think about” AI alignment. To the extent that I think I was right to be worried about AI progress kicking off in the decade following 2011, I think I’m right to be worried again now about preference learning and AI alignment (in its narrow and socially-simplistic technical formulations) taking off in the 2020’s and 2030’s.)
PL educational value:
Studying and making contributions to preference learning is of moderate educational value for thinking about existential safety in my opinion. The reason is this: if we want machines to respect human preferences—including our preference to continue existing—we may need powerful machine intelligences to understand our preferences in a form they can act on. Of course, being understood by a powerful machine is not necessarily a good thing. But if the machine is going to do good things for you, it will probably need to understand what “good for you” means. In other words, understanding preference learning can help with AI alignment research, which can help with existential safety. And if existential safety is your goal, you can try to target your use of preference learning concepts and methods toward that goal.
PL neglect:
Preference learning has always been crucial to the advertising industry, and as such it has not been neglected in recent years. For the same reason, it’s also not likely to become neglected. Its application to reinforcement learning is somewhat new, however, because until recently there was much less active research in reinforcement learning. In other words, recent interest in reward learning is mainly a function of increased interest in reinforcement learning, rather than increased interest in preference learning. If new learning paradigms supersede reinforcement learning, preference learning for those paradigms will not be far behind.
(This is not a popular opinion; I apologize if I have offended anyone who believes that progress in preference learning will reduce existential risk, and I certainly welcome debate on the topic.)
PL exemplars:
Recent works of significant educational value, according to me:
HRI research is concerned with designing and optimizing patterns of interaction between humans and machines—usually actual physical robots, but not always.
HRI helpfulness to existential safety:
On net, I think AI/ML would be better for the world if most of its researchers pivoted from general AI/ML into HRI, simply because it would force more AI/ML researchers to more frequently think about real-life humans and their desires, values, and vulnerabilities. Moreover, I think it reasonable (as in, >1% likely) that such a pivot might actually happen if, say, 100 more researchers make this their goal.
For this reason, I think contributions to this area today are pretty solidly good for existential safety, although not perfectly so: HRI research can also be used to deceive humans, which can degrade societal-scale honesty norms, and I’ve seen HRI research targeting precisely that. However, my model of readers of this blog is that they’d be unlikely to contribute to those parts of HRI research, such that I feel pretty solidly about recommending contributions to HRI.
HRI educational value:
I think HRI work is of unusually high educational value for thinking about existential safety, even among other topics in this post. The reason is that, by working with robots, HRI work is forced to grapple with high-dimensional and continuous state spaces and action spaces that are too complex for the human subjects involved to consciously model. This, to me, crucially mirrors the relationship between future AI technology and human society: humanity, collectively, will likely be unable to consciously grasp the full breadth of states and actions that our AI technologies are transforming and undertaking for us. I think many AI researchers outside of robotics are mostly blind to this difficulty, which on its own is an argument in favor of more AI researchers working in robotics. The beauty of HRI is that it also explicitly and continually thinks about real human beings, which I think is an important mental skill to practice if you want to protect humanity collectively from existential disasters.
HRI neglect:
A neglect score for this area was uniquely difficult for me to specify. On one hand, HRI is a relatively established and vibrant area of research compared with some of the more nascent areas covered in this post. On the other hand, as mentioned, I’d eventually like to see the entirety of AI/ML as a field pivoting toward HRI work, which means it is still very neglected compared to where I want to see it. Furthermore, I think such a pivot is actually reasonable to achieve over the next 20-30 years. Further still, I think industrial incentives might eventually support this pivot, perhaps on a similar timescale.
So: if the main reason you care about neglect is that you are looking to produce a strong founder effect, you should probably discount my numerical neglect scores for this area, given that it’s not particularly “small” on an absolute scale compared to the other areas here. By that metric, I’d have given something more like {2015:4/10; 2020:3/10; 2030:2/10}. On the other hand, if you’re an AI/ML researcher looking to “do the right thing” by switching to an area that pretty much everyone should switch into, you definitely have my “doing the right thing” assessment if you switch into this area, which is why I’ve given it somewhat higher neglect scores.
(2020) Pragmatic-pedagogic value alignment, Fisac, Jaime F; Gates, Monica A; Hamrick, Jessica B; Liu, Chang; Hadfield-Menell, Dylan; Palaniappan, Malayandi; Malik, Dhruv; Sastry, S Shankar; Griffiths, Thomas L; Dragan, Anca D.
Side-effect minimization (SEM)
ExistingResearch Area
SocialApplication
Helpfulnessto Existential Safety
EducationalValue
2015Neglect
2020Neglect
2030Neglect
Side-effect Minimization
Single/Single
4/10
4/10
6/10
5/10
4/10
SEM research is concerned with developing domain-general methods for making AI systems less likely to produce side effects, especially negative side effects, in the course of pursuing an objective or task.
SEM helpfulness to existential safety:
I think this area has two obvious applications to safety-in-general:
(“accidents”) preventing an AI agent from “messing up” when performing a task for its primary stakeholder(s), and
(“externalities”) preventing an AI system from generating problems for persons other than its primary stakeholders, either
(“unilateral externalities”) when the system generates externalities through its unilateral actions, or
(“multilateral externalities”) when the externalities are generated through the interaction of an AI system with another entity, such as a non-stakeholder or another AI system.
I think the application to externalities is more important and valuable than the application to accidents, because I think externalities are (even) harder to detect and avoid than accidents. Moreover, I think multilateral externalities are (even!) harder to avoid than unilateral externalities.
Currently, SEM research is focussed mostly on accidents, which is why I’ve only given it a moderate score on the helpfulness scale. Conceptually, it does make sense to focus on accidents first, then unilateral externalities, and then multilateral externalities, because of the increasing difficulty in addressing them.
However, the need to address multilateral externalities will arise very quickly after unilateral externalities are addressed well enough to roll out legally admissible products, because most of our legal systems have an easier time defining and punishing negative outcomes that have a responsible party. I don’t believe this is a quirk of human legal systems: when two imperfectly aligned agents interact, they complexify each other’s environment in a way that consumes more cognitive resources than interacting with a non-agentic environment. (This is why MARL and self-play are seen as powerful curricula for learning.) Thus, there is less cognitive “slack” to think about non-stakeholders in a multi-agent setting than in a single-agent setting.
For this reason, I think work that makes it easy for AI systems and their designers to achieve common knowledge around how the systems should avoid producing externalities is very valuable.
SEM educational value:
I think SEM research thus far is of moderate educational value, mainly just to kickstart your thinking about side effects.
SEM neglect:
Domain-general side-effect minimization for AI is a relatively new area of research, and is still somewhat neglected. Moreover, I suspect it will remain neglected, because of the aforementioned tendency for our legal system to pay too little attention to multilateral externalities, a key source of negative side effects for society.
SEM exemplars:
Recent exemplars of value to existential safety, mostly via starting to think about the generalized concept of side effects at all:
(2019) Preferences Implicit in the State of the World, Shah, Rohin; Krasheninnikov, Dmitrii; Alexander, Jordan; Abbeel, Pieter; Dragan, Anca (This paper is about preference inference, but I think it applies more specifically to inferring how not to have negative side effects.)
Interpretability research is concerned with making the reasoning and decisions of AI systems more interpretable to humans. Interpretability is closely related to transparency and explainability. Not all authors treat these three concepts as distinct; however, I think when useful distinction is drawn between between them, it often looks something like this:
a system is “transparent” if it is easy for human users or developers to observe and track important parameters of its internal state;
a system is “explainable” if useful explanations of its reasoning can be produced after the fact.
a system is “interpretable” if its reasoning is structured in a manner that does not require additional engineering work to produce accurate human-legible explanations.
In other words, interpretable systems are systems with the property that transparency is adequate for explainability: when we look inside them, we find they are structured in a manner that does not require much additional explanation. I see Professor Cynthia Rudin as the primary advocate for this distinguished notion of interpretability, and I find it to be an important concept to distinguish.
IntML helpfulness to existential safety:
I think interpretability research contributes to existential safety in a fairly direct way on the margin today. Specifically, progress in interpretability will
decrease the degree to which human AI developers will end up misjudging the properties of the systems they build,
increase the degree to which systems and their designers can be held accountable for the principles those systems embody, perhaps even before those principles have a chance to manifest in significant negative societal-scale consequences, and
potentially increase the degree to which competing institutions and nations can establish cooperation and international treaties governing AI-heavy operations.
I believe this last point may turn out to be the most important application of interpretability work. Specifically, I think institutions that use a lot of AI technology (including but not limited to powerful autonomous AI systems) could become opaque to one another in a manner that hinders cooperation between and governance of those systems. By contrast, a degree of transparency between entities can facilitate cooperative behavior, a phenomenon which has been borne out in some of the agent foundations work listed above, specifically:
In other words, I think interpretability research can enable technologies that legitimize and fulfill AI governance demands, narrowing the gap between what policy makers will wish for and what technologists will agree is possible.
IntML educational value:
I think interpretability research is of moderately high educational value for thinking about existential safety, because some research in this area is somewhat surprising in terms of showing ways to maintain interpretability without sacrificing much in the way of performance. This can change our expectations about how society can and should be structured to maintain existential safety, by changing the degree of interpretability we can and should expect from AI-heavy institutions and systems.
IntML neglect:
I think IntML is fairly neglected today relative to its value. However, over the coming decade, I think there will be opportunities for companies to speed up their development workflows by improving the interpretability of systems to their developers. In fact, I think for many companies interpretability is going to be a crucial bottleneck for advancing their product development. These developments won’t be my favorite applications of interpretability, and I might eventually become less excited about contributions to interpretability if all of the work seems oriented on commercial or militarized objectives instead of civic responsibilities. But in any case, I think getting involved with interpretability research today is a pretty robustly safe and valuable career move for any up and coming AI researchers, especially if they do their work with an eye toward existential safety.
IntML exemplars:
Recent exemplars of high value to existential safety:
(2018) The building blocks of interpretability,Olah, Chris; Satyanarayan, Arvind; Johnson, Ian; Carter, Shan; Schubert, Ludwig; Ye, Katherine; Mordvintsev, Alexander.
Fairness research in machine learning is typically concerned with altering or constraining learning systems to make sure their decisions are “fair” according to a variety of definitions of fairness.
FairML helpfulness to existential safety:
My hope for FairML as a field contributing to existential safety is threefold:
(societal-scale thinking) Fairness comprises one or more human values that exist in service of society as a whole, and which are currently difficult to encode algorithmically, especially in a form that will garner unchallenged consensus. Getting more researchers to think in the framing “How do I encode a value that will serve society as a whole in a broadly agreeable way” is good for big-picture thinking and hence for society-scale safety problems.
(social context awareness) FairML gets researchers to “take off their blinders” to the complexity of society surrounding them and their inventions. I think this trend is gradually giving AI/ML researchers a greater sense of social and civic responsibility, which I think reduces existential risk from AI/ML.
(sensitivity to unfair uses of power) Simply put, it’s unfair to place all of humanity at risk without giving all of humanity a chance to weigh in on that risk. More focus within CS on fairness as a human value could help alleviate this risk. Specifically, fairness debates often trigger redistributions of resources in a more equitable manner, thus working against the over-centralization of power within a given group. I have some hope that fairness considerations will work against the premature deployment of powerful AI/ML systems that would lead to the hyper-centralizing power over the world (and hence would pose acute global risks by being a single point of failure).
(Fulfilling and legitimizing governance demands) Fairness research can be used to fulfill and legitimize AI governance demands, narrowing the gap between what policy makers wish for and what technologists agree is possible. This process makes AI as a field more amenable to governance, thereby improving existential safety.
FairML educational value:
I think FairML research is of moderate educational value for thinking about existential safety, mainly via the opportunities it creates for thinking about the points in the section on helpfulness above. If the field were more mature, I would assign it a higher educational value.
I should also flag that most work in FairML has not been done with existential safety in mind. Thus, I’m very much hoping that more people who care about existential safety will learn about FairML and begin thinking about how principles of fairness can be leveraged to ensure societal-scale safety in the not-too-distant future.
FairML neglect:
FairML is not a particularly neglected area at the moment because there is a lot of excitement about it, and I think it will continue to grow. However, it was relatively neglected 5 years ago, so there is still a lot of room for new ideas in the space. Also, as mentioned, thinking in FairML is not particularly oriented toward existential safety, so I think research on fairness in service of societal-scale safety is quite neglected in my opinion.
FairML exemplars:
Recent exemplars of high value to existential safety, mostly via attention to the problem of difficult-to-codify societal-scale values:
Computational social choice research is concerned with using algorithms to model and implement group-level decisions using individual-scale information and behavior as inputs. I view CSC as a natural next step in the evolution of social choice theory that is more attentive to the implementation details of both agents and their environments. In my conception, CSC comprises subservient topics in mechanism design and algorithmic game theory, even if researchers in those areas don’t consider themselves to be working in computational social choice.
CSC helpfulness to existential risk:
In short, computational social choice research will be necessary to legitimize and fulfill governance demands for technology companies (automated and human-run companies alike) to ensure AI technologies are beneficial to and controllable by human society. The process of succeeding or failing to legitimize such demands will lead to improving and refining what I like to call the algorithmic social contract: whatever broadly agreeable set of principles (if any) algorithms are expected to obey in relation to human society.
In 2018, I considered writing an article drawing more attention to the importance of developing an algorithmic social contract, but found this point had already been quite eloquently by Iyad Rahwan in the following paper, which I highly recommend:
Computational social choice methods in their current form are certainly far from providing adequate and complete formulations of an algorithmic social contract. See the following article for arguments against tunnel-vision on computational social choice as a complete solution to societal-scale AI ethics:
Notwithstanding this concern, what follows is a somewhat detailed forecast of how I think computational social choice research will still have a crucial role to play in developing the algorithmic social contract throughout the development of individually-alignable transformative AI technologies, which I’ll call “the alignment revolution”.
First, once technology companies begin to develop individually-alignable transformative AI capabilities, there will be strong economic and social and political pressures for its developers to sell those capabilities rather than hoarding them. Specifically:
(economic pressure) Selling capabilities immediately garners resources in the form of money and information from the purchasers and users of the capabilities;
(social pressure) Hoarding capabilities could be seen as anti-social relative to distributing them more broadly through sales or free services;
(sociopolitical pressure) Selling capabilities allows society to become aware that those capabilities exist, enabling a smoother transition to embracing those capabilities. This creates a broadly agreeable concrete moral argument against capability hoarding, which could become politically relevant.
(political pressure) Political elites will be happier if technical elites “share” their capabilities with the rest of the rest of the economy rather than hoarding them.
Second, for the above reasons, I expect individually-alignable transformative AI capabilities to be distributed fairly broadly once they exist, creating an “alignment revolution” arising from those capabilities. (It’s possible I’m wrong about this, and for that I reason I also welcome research on how to align non-distributed alignment capabilities; that’s just not where most of my chips lie, and not where the rest of this argument will focus.)
Third, unless humanity collectively works very hard to maintain a degree of simplicity and legibility in the overall structure of society*, this “alignment revolution” will greatly complexify our environment to a point of much greater incomprehensibility and illegibility than even today’s world. This, in turn, will impoverish humanity’s collective ability to keep abreast of important international developments, as well as our ability to hold the international economy accountable for maintaining our happiness and existence.
(*Would-be-footnote: I have some reasons to believe that perhaps we can and should work harder to make the global structure of society more legible and accountable to human wellbeing, but that is a topic for another article.)
Fourth, in such a world, algorithms will be needed to hold the aggregate global behavior of algorithms accountable to human wellbeing, because things will be happening too quickly for humans to monitor. In short, an “algorithmic government” will be needed to govern “algorithmic society”. Some might argue this is not strictly unnecessary: in the absence of a mathematically codified algorithmic social contract, humans could in principle coordinate to cease or slow down the use of these powerful new alignment technologies, in order to give ourselves more time to adjust to and govern their use. However, for all our successes in innovating laws and governments, I do not believe current human legal norms are quite developed enough to stably manage a global economy empowered with individually-alignable transformative AI capabilities.
Fifth, I do think our current global legal norms are much better than what many computer scientists naively proffer as replacements for them. My hope is that more resources and influence will slowly flow toward the areas of computer science most in touch with the nuances and complexities of codifying important societal-scale values. In my opinion, this work is mostly concentrated in and around computational social choice, to some extent mechanism design, and morally adjacent yet conceptually nascent areas of ML research such as fairness and interpretability.
While there is currently an increasing flurry of (well-deserved) activity in fairness and interpretability research, computational social choice is somewhat more mature, and has a lot for these younger fields to learn from. This is why I think CSC work is crucial to existential safety: it is the area of computer science most tailored to evoke reflection on the global structure of society, and the most mature in doing so.
So what does all this have to do with existential safety? Unfortunately, while CSC is significantly more mature as a field than interpretable ML or fair ML, it is still far from ready to fulfill governance demand at the ever-increasing speed and scale needed to ensure existential safety in the wake of individually-alignable transformative AI technologies. Moreover, I think punting these questions to future AI systems to solve for us is a terrible idea, because doing so impoverishes our ability to sanity-check whether those AI systems are giving us reasonable answers to our questions about social choice. So, on the margin I think contributions to CSC theory are highly valuable, especially by persons thinking about existential safety as the objective of their research.
CSC educational value:
Learning about CSC is necessary for contributions to CSC, which I think are currently needed to ensure existentially safe societal-scale norms for aligned AI systems to follow after “the alignment revolution” if it happens. So, I think CSC is highly valuable to learn about, with the caveat that most work in CSC has not been done with existential safety in mind. Thus, I’m very much hoping that more people who care about existential safety will learn about and begin contributing to CSC in ways that steer CSC toward issues of societal-scale safety.
CSC neglect:
As mentioned above, I think CSC is still far from ready to fulfill governance demands at the ever-increasing speed and scale that will be needed to ensure existential safety in the wake of “the alignment revolution”. That said, I do think over the next 10 years CSC will become both more imminently necessary and more popular, as more pressure falls upon technology companies to make societal-scale decisions. CSC will become still more necessary and popular as more humans and human institutions become augmented with powerful aligned AI capabilities that might “change the game” that our civilization is playing. I expect such advancements to raise increasingly deep and urgent questions about the principles on which our civilization is built, that will need technical answers in order to be fully resolved in ways that maintain existential safety.
CSC exemplars:
CSC exemplars of particular value and relevance to existential safety, mostly via their attention to formalisms for how to structure societal-scale decisions:
Accountability (AccML) is aimed at making it easier to hold persons or institutions accountable for the effects of ML systems. Accountability depends on transparency and explainability for evaluating the principles by which a harm or mistake occurs, but it is not subsumed by these objectives.
AccML helpfulness to existential safety:
The relevance of accountability to existential safety is mainly via the principle of accountability gaining more traction in governing the technology industry. In summary, the high level points I believe in this area are the following, which are argued for in more detail after the list:
Tech companies are currently “black boxes” to outside society, in that they can develop and implement (almost) whatever they want within the confines of privately owned laboratories (and other “secure” systems), and some of the things they develop or implement in private settings could pose significant harms to society.
Soon (or already), society needs to become less permissive of tech companies developing highly potent algorithms, even in settings that would currently be considered “private”, similar to the way we treat pharmaceutical companies developing highly potent biological specimens.
Points #1 and #2 mirror the way in which ML systems themselves are black boxes even to their creators, which fortunately is making some ML researchers uncomfortable enough to start holding conferences on accountability in ML.
More researchers getting involved in the task of defining and monitoring accountability can help tech company employees and regulators to reflect on the principle of accountability and whether tech companies themselves should be more subject to it at various scales (e.g., their software should be more accountable to its users and developers, their developers and users should be more accountable to the public, their executives should be more accountable to governments and civic society, etc.).
In futures where transformative AI technology is used to provide widespread services to many agents simultaneously (e.g., “Comprehensive AI services” scenarios), progress on defining and monitoring accountability can help “infuse” those services with a greater degree of accountability and hence safety to the rest of the world.
What follows is my narrative for how and why I believe the five points above.
At present, society is structured such that it is possible for a technology company to amass a huge amount of data and computing resources, and as long as their activities are kept “private”, they are free to use those resources to experiment with developing potentially misaligned and highly potent AI technologies. For instance, if a tech company tomorrow develops any of the following potentially highly potent technologies within a privately owned ML lab, there are no publicly mandated regulations regarding how they should handle or experiment with them:
misaligned superintelligences
fake news generators
powerful human behavior prediction and control tools
… any algorithm whatsoever
Moreover, there are virtually no publicly mandated regulations against knowingly or intentionally or developing any of these artifacts within the confines of a privately owned lab, despite the fact that the mere existence of such an artifact poses a threat to society. This is the sense in which tech companies are “black boxes” to society, and potentially harmful as such.
(That’s point #1.)
Contrast this situation with the strict guidelines that pharmaceutical companies are required to adhere to in their management of pathogens. First, it is simply illegal for most companies to knowingly develop synthetic viruses, unless they are certified to do so by demonstrating a certain capacity for safe handling of the resulting artifacts. Second, conditional on having been authorized to develop viruses, companies are required to follow standardized safety protocols. Third, companies are subject to third-party audits to ensure compliance with these safety protocols, and are not simply trusted to follow them without question.
Nothing like this is true in the tech industry, because historically, algorithms have been viewed as less potent societal-scale risks than viruses. Indeed, present-day accountability norms in tech would allow an arbitrary level of disparity to develop between
the potency (in terms of potential impact) of algorithms developed in privately owned laboratories, and
the preparedness of the rest of society to handle those impacts if the algorithms were released (such as by accident, harmful intent, or poor judgement).
This is a mistake, and an increasingly untenable position as the power of AI and ML technology increases. In particular, a number of technology companies are intentionally trying to build artificial general intelligence, an artifact which, if released, would be much more potent than most viruses. These companies do in fact have safety researchers working internally to think about how to be safe and whether to release things. But contrast this again with pharmaceuticals. It just won’t fly for a pharmaceutical company to say “Don’t worry, we don’t plan to release it; we’ll just make up our own rules for how to be privately safe with it.”. Eventually, we should probably stop accepting this position from tech companies at well.
(That’s point #2.)
Fortunately, even some researchers and developers are starting to become uncomfortable with “black boxes” playing important and consequential roles in society, as evidenced by the recent increase in attention on both accountability and interpretability in service of it, for instance:
This kind of discomfort both fuels and is fueled by decreasing levels of blind faith in the benefits of technology in general. Signs of this broader trend include:
(2020) The Social Dilemma, a NetFlix documentary by Jeff Orlowski, Davis Coombe, and Vickie Curtis.
Together, these trends indicate a decreasing level of blind faith in the addition of novel technologies to society, both in the form of black-box tech products, and black-box tech companies.
(That’s point #3.)
The European General Data Protection Regulation (GDPR) is a very good step for regulating how tech companies relate with the public. I say this knowing that GDPR is far from perfect. The reason it’s still extremely valuable is that it has initialized the variable defining humanity’s collective bargaining position (at least within Europe, and replicated to some extent by the CCPA) for controlling how tech companies use data. That variable can now be amended and hence improved upon without first having to ask the question “Are we even going to try to regulate how tech companies use data?” For a while, it wasn’t clear any action would ever be taken on this front, outside of specific domains like healthcare and finance.
However, while GDPR has defined a slope for regulating the use of data, we also need accountability for private uses of computing. As AlphaZero demonstrates, data-free computing alone is sufficient to develop super-human strategic competence in a well-specified domain.
When will it be time to disallow arbitrary private uses of computing resources, irrespective of its data sources? Is it time already? My opinions on this are outside the scope of what I intend to argue for in this post. But whenever the time comes to develop and enforce such accountability, it will probably be easier to do that if researchers and developers have spent more time thinking about what accountability is, what purposes are served by various versions of accountability, and how to achieve those kinds of accountability in both fully-automated and semi-automated systems. In other words, optimistically, more technical research on accountability in ML might result in more ML researchers transferring their awareness that «black box tech products are insufficiently accountable» to become more aware/convinced that «black box tech companies are insufficiently accountable».
(That’s point #4.)
But even if that transfer of awareness doesn't happen, automated approaches to accountability will still have a role to play if we end up in a future with large numbers of agents making use of AI-mediated services, such as in the “Comprehensive AI Services” model of the future. Specifically,
individual actors in a CAIS economy should be accountable to the principle of not privately developing highly potent technologies without adhering to publicly legitimized and auditable safety procedures, and
systems for reflecting on and updating accountability structures can be used to detect and remediate problematic behaviors in multi-agent systems, including behaviors that could yield existential risks from distributed systems (e.g., extreme resource consumption or pollution effects).
(That’s point #5)
AccML educational value:
Unfortunately, technical work in this area is highly undeveloped, which is why I have assigned this area a relatively low educational value. I hope this does not trigger people to avoid contributing to it.
AccML neglect:
Correspondingly, this area is highly neglected relative to where I’d like it to be, on top of being very small in terms of the amount of technical work at its core.
AccML exemplars:
Recent examples of writing in AccML that I think are of particular value to existential safety include:
(2018) Towards formal definitions of blameworthiness, intention, and moral responsibility, Halpern, Joseph Y; Kleiman-Weiner, Max.* * Note: I don't currently agree with the definitions of blameworthiness, intention, and responsibility in this paper, but I am glad to see people working toward agreeable definitions of these concepts, and I like that the title begins with "toward".
Thanks for reading! I hope this post has been helpful to your thinking about the value of a variety of research areas for existential safety, or at the very least, your model of my thinking. As a reminder, these opinions are my own, and are not intended to represent any institution of which I am a part.
Reflections on scope & omissions
This post has been about:
Research, not individuals. Some readers might be interested in the question “What about so-and-so’s work at such-and-such institution?” I think that’s a fair question, but I prefer this post to be about ideas, not individual people. The reason is that I want to say both positive and negative things about each area, whereas I’m not prepared to write up public statements of positive and negative judgements about people (e.g., “Such-and-such is not going to succeed in their approach”, or “So-and-so seems fundamentally misguided about X”.)
Areas, not directions. This post is an appraisal of active areas of research—topics with groups of people already working on them writing up their findings. It’s primarily not an appraisal of potential directions—ways I think areas of research could change or be significantly improved (although I do sometimes comment on directions I’d like to see each area taking). For instance, I think intent alignment is an interesting topic, but the current paucity of publicly available technical writing on it makes it difficult to critique. As such, I think of intent alignment as a “direction” that AI alignment research could be taken in, rather than an “area”.
Papers, not legislation, books, or TV shows. Many intellectual artifacts aside from research papers matter to existential safety, including legislation, as well as fiction and non-fiction books, TV shows, and movies. Such works are not beyond the scope of my opinions, but are beyond this scope of this post.


Thank you! I am a senior undergraduate looking to do my undergraduate thesis in the broader field of AI safety and this was super helpful :)