Summary
- Large language models (henceforth, LLMs) are sometimes said to be "just" shallow pattern matchers, "just" massive look-up tables or "just" autocomplete engines. These comparisons amount to a form of (methodological) reductionism. While there's some truth to them, I think they smuggle in corollaries that are either false or at least not obviously true.
- For example, they seem to imply that what LLMs are doing amounts merely to rote memorisation and/or clever parlour tricks, and that they cannot generalise to out-of-distribution data. In fact, there's empirical evidence that suggests that LLMs can learn general algorithms and can contain and use representations of the world similar to those we use.
- They also seem to suggest that LLMs merely optimise for success on next-token prediction. It's true that LLMs are (mostly) trained on next-token prediction, and it's true that this profoundly shapes their output, but we don't know whether this is how they actually function. We also don't know what sorts of advanced capabilities can or cannot arise when you train on next-token prediction.
- So there's reason to be cautious when thinking about LLMs. In particular, I think, caution should be exercised (1) when making predictions about what LLMs will or will not in future be capable of and (2) when assuming that such-and-such a thing must or cannot possibly happen inside an LLM.
Pattern Matchers, Look-up Tables, Stochastic Parrots
My understanding of what goes on inside machine learning (henceforth, ML) models, and LLMs in particular, is still in many ways rudimentary, but it seems clear enough that, however tempting that is to imagine, it's little like what goes on in the minds of humans; it's weirder than that, more alien, more eldritch. As LLMs have been scaled up, and more compute and data have been poured into models with more parameters, they have undergone qualitative shifts, and are now capable of a range of tasks their predecessors couldn't even grasp, let alone fail at, even as they have retained essentially the same architecture and training process.[1] How do you square their awesome, if erratic, brilliance with the awareness that their inner workings are so ordinary?
One route would be to directly deny the brilliance. Gary Marcus does this, pointing out, and relishing in, the myriad ways that LLMs misfire. Their main limits are, he says, that they are unreliable and untruthful. (See the footnote for my thoughts on that.[2])
That's one route, but it's not the one I want to discuss here. The route I want to discuss here is to dispel the magic, so to speak: to argue that what goes on inside LLMs is "shallow", and that LLMs lack "understanding". This often takes the form of asserting that LLMs are just doing pattern matching[3], or just rephrasing material from the web[4], amounting to mere stochastic parrots[5], or just retrieving things from a massive look-up table. Gary Marcus describes the underlying problem as one of "a lack of cognitive models of the world":
The improvements, such as they are, come primarily because the newer models have larger and larger sets of data about how human beings use word sequences, and bigger word sequences are certainly helpful for pattern matching machines. But they still don't convey genuine comprehension, and so they are still very easy [...] to break.
Well -- in a certain light and for the sake of fairness -- this view is not entirely wrong:
- LLMs are, in a sense, pattern matching. They likely have a great deal of attention heads and neurons and whatever that detect certain patterns in the input, which then help determine the model's output.
- LLMs are, in a sense, merely rephrasing material from the web. All, or nearly all, of the data that they're trained on originates in the internet, and their outputs are profoundly shaped by this fact.
- LLMs are, in a sense, massive look-up tables. They directly map inputs to outputs, and often seem to rely on memorisation.
The motivation behind these expressions is, I think, manifold, but one of the underlying drives seems to be the notion that AI systems currently are less capable than they seem, and/or that they will in future be less capable than we predict.[6] In particular, if LLMs are only learning shallow patterns, their ability to generalise to out-of-distribution data will suffer. The present post is about exactly that: what these expressions express about AI capabilities, now and in future (and not questions about whether LLMs are conscious or aware, say, important though those questions may be[7]). In particular, I'm going to argue, and this is perhaps a good time to point out that I am not an expert on ML, that all these descriptors -- pattern matching, look-up tables, stochastic parrots -- are not good descriptors of LLMs, and that you probably shouldn't be using them.
Those Aren't Good Descriptors
These concerns -- that LLMs are pattern matchers and so on -- might prompt one to say: "Yeah, and so what?" That's what Scott Alexander, discussing GPT-2 in what feels like ages ago, but was actually in 2018, expressed when he wrote:
A machine learning researcher writes me in response to yesterday's post, saying: "I still think GPT-2 is a brute-force statistical pattern matcher which blends up the internet and gives you back a slightly unappetizing slurry of it when asked."
I resisted the urge to answer "Yeah, well, your mom is a brute-force statistical pattern matcher which blends up the internet and gives you back a slightly unappetizing slurry of it when asked." But I think it would have been true.
To say that humans, too, are merely sophisticated pattern matchers is, it strikes me, to highlight the real problem here, which is that people often seem to mean different things when they say a thing is or isn't "just" pattern matching, "just" stitching together phrases from the internet or "just" searching things in a look-up table. That driver of misunderstanding rears its head in every arena; the solution, as ever, is to taboo your words. These assertions, in particular, I think, give the reader a false impression, leading them to believe things like:
- LLMs aren't actually getting better at out-of-distribution tasks, they're only learning ever more elaborate "parlour tricks".
- LLMs have nothing interesting or sophisticated going on inside them.
- LLMs rely purely on rote memorisation, never inferring abstract rules, models of the world or causal mechanisms.
- LLMs are mere autocomplete engines, and/or merely optimise for accurate next-token prediction.
- LLMs cannot produce anything unique.
- LLMs cannot create and/or execute plans.[8]
In my judgement, some of these are false, at least for some LLMs, and others I'm unsure about, but either way I don't think, given what we know about LLMs at the present stage, that anyone is justified in believing with any certainty that any of them is true.
LLMs Can Learn General Algorithms
First take the implications that LLMs are only doing clever parlour tricks, only relying on rote memorisation and/or only learning shallow patterns. These things are often true, but, I think, not always true:
- There's evidence that LLMs can learn general analytic capabilities and use them to solve hard problems.
- There's evidence that small, non-language transformers trained on modular and binary addition can learn fully general algorithms.
- There's evidence of phase changes in LLMs and similar models -- points where, with more compute, data or parameters, these models suddenly become capable of solving new tasks. This seems hard to explain if all LLMs do is rote memorisation etc.
General Analytic Capabilities
Lewkowycz et al. (2022) fine tunes a version of PaLM (an LLM created by Google) on technical content (for example, arXiv preprints), getting it to perform decently well (~50% success rate) on the MATH dataset. The problems are not trivial (right-hand panel):

The authors take steps to find out whether the model achieved these results through mere rote memorisation. First they look at the 100 problems for which the model does the best and search through the training set for traces of them, but they find none. Then they modify problems (adjusting phrasing and/or numbers) to see whether the model will do worse, but it does not. Finally they compare the model's solutions to the ground-truth solutions provided in the dataset to see whether they are similarly phrased, but, except for questions with very short answers, they are not.
That, to me, suggests their model really does learn rules or algorithms that are generally useful in solving these types of problems. Still, they don't exactly crack open the model and locate the algorithms in the model's weights.
Fully General Algorithms
Nanda et al. (2023) trains a tiny (~200K parameters if my count is correct) transformer on modular addition (that is, addition where the result "wraps around" to start at 0 again if it would ever exceed the maximum number the model can handle, in this case 113) and finds that, after quickly reducing its train error (blue line) to near 0, the model is stuck with a high test error (red line) for a long while until suddenly that, too, diminishes to near 0:
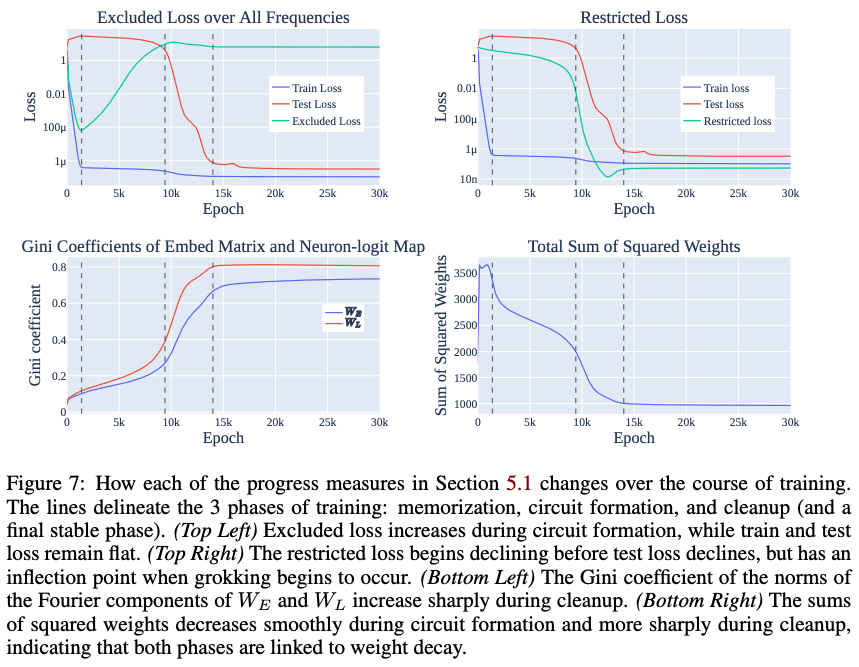
This phenomenon is called grokking (Power et al. 2022), and the sudden improvement on test data is called a phase change. It's as if the model initially merely memorises the training data answers, but eventually finds a fully general algorithm, allowing it to generalise ~perfectly to test data. And, in fact, it turns out that this model "uses discrete Fourier transforms and trigonometric identities to convert addition to rotation about a circle" (Nanda et al. 2023).[9] This algorithm is pretty complicated; it proceeds in multiple steps spread out over successive layers, and is utterly different from how addition normally works in computers at a low level; it's frankly incredible to me that an ML model can find it through gradient descent, but there it is.[10]
This blog post tells a similar story: the author trains an extremely tiny (422 parameters) neural network to perform binary addition, peers inside and discovers a clever algorithm.
Phase Changes
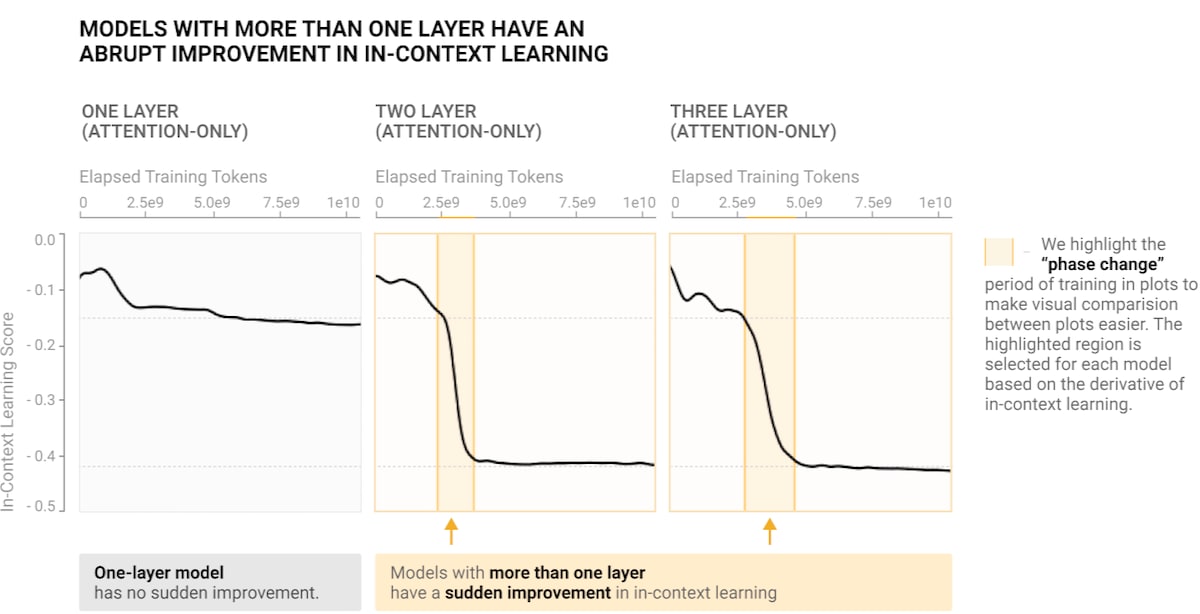
The two addition experiments seem, since, though they weren't done on LLMs, they were done on models with similar architectures, like strong evidence that LLMs can in principle and practice find fully general algorithms. The evidence for actual algorithms found within LLMs is scantier, for LLMs are mind-bogglingly enormous. But there is some evidence of phase changes, either as a result of more training or of larger models, in LLMs.[11] For example, the language model studied in Olsson et al. (2022) undergoes a phase change markedly improving its in-context learning:
And the BIG-bench dataset from Srivastava et al. (2022), comprising tasks designed to not show up in LLMs' training data, shows that, for some tasks, and in particular tasks that don't seem to rely on knowledge/memorisation, like arithmetics, LLMs undergo model-size-scaling phase changes (middle panel):
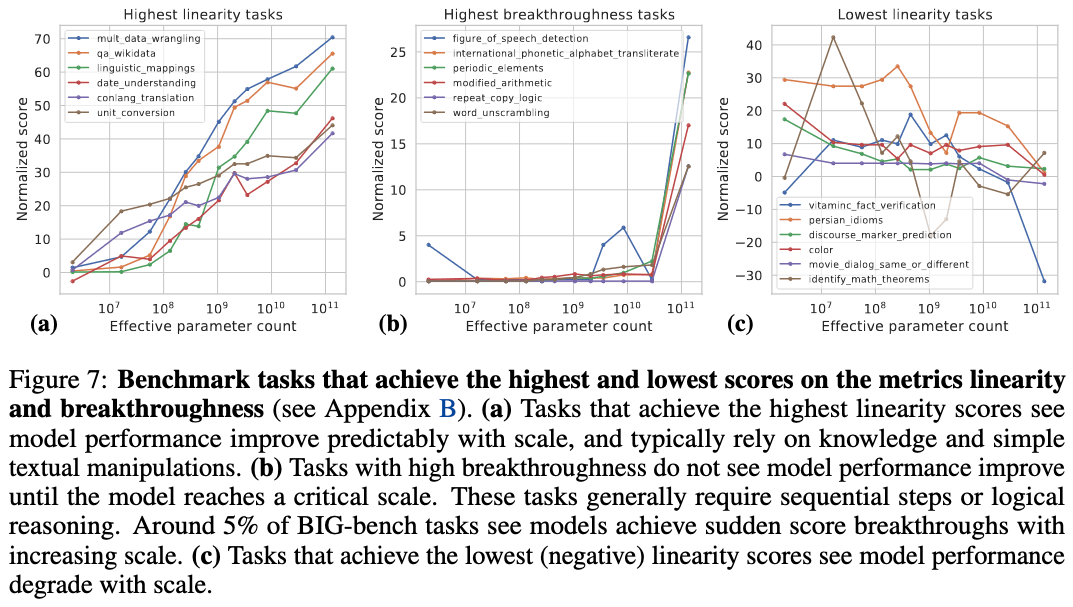
It's not clear to me what exactly happens in these cases:
- It could be that these language models discover (or in the case of increased parameter counts, become capable of) general algorithms in a way similar to the modular addition model in Nanda et al. (2023), though there are important disanalogies between the modular addition model and LLMs.
- Another possible explanation, perhaps complimentary to the first, is that there is, for those tasks in particular, no partial success -- if the model fails, it fails completely -- the same way one can't partially succeed at peering over a wall; some tasks just seem to have a far smaller space of possible outcomes than other tasks, so the shift from failure to success happens rapidly.
And plausibly discovering and/or using general algorithms is much easier for arithmetic tasks than, say, creative writing. Still, it's hard for me to see how such phase changes could occur if LLMs relied purely on rote memorisation or shallow pattern matching.
LLMs Can Contain and Use Models of the World
Here's that passage by Gary Marcus again:
Now it is true that GPT-3 is genuinely better than GPT-2, and maybe [...] true that InstructGPT is genuinely better than GPT-3. I do think that for any given example, the probability of a correct answer has gone up. [...] But I see no reason whatsoever to think that the underlying problem -- a lack of cognitive models of the world -- [has] been remedied. The improvements, such as they are, come primarily because the newer models have larger and larger sets of data about how human beings use word sequences, and bigger word sequences are certainly helpful for pattern matching machines.
This is an empirical question, but, again, since LLMs are so insanely massive, and since they're trained on such a wide variety of texts, they are elusive targets for mechanistic interpretability research. Instead, reasonably, researchers tend to study smaller models. Is there evidence of representations of the world inside smaller language models? Why, yes there is.
Toshniwal et al. (2021) fine tunes a GPT-2-like LLM on chess game logs and finds circumstantial evidence that the model is representing the board state internally. That paper in turn inspired Li et al. (2022), which fine tunes a GPT variant on Othello game logs and locates inside the network a perfectly intuitive representation of the game's board state. Two observations are especially telling here: (1) the model is able to predict legal moves and (2), when you modify its internal representation of the board state during a game -- performing a kind of surgery, as it were -- you can see its next-move prediction change accordingly. (For an accessible but detailed write-up on this, see this blog post by the paper's lead author; this LessWrong post, including comments, may be of interest, too.)
It's plainly not true that language models lack representations of the world. The question is to what extent they have and use such representations.
There are hints of world representations in LLMs, too. In particular, some papers have found evidence of representations of colour inside LLMs (Li, Nye, and Andreas 2021; Abdou et al. 2021; Patel and Pavlick 2022). So there are likely representations of the world in LLMs too, because why wouldn't there be? They're useful for parsimonious next-token prediction.
The real world, of course, is complicated and messy and cannot be ~perfectly modelled the way Othello or colour can be. But the real world can be imperfectly modelled, and that can go a long way. Human brains can easily model the game of chess, but not easily other people's behaviour. But that isn't fatal, because we can kind of model other people's behaviour, and therefore mostly make good predictions about what they'll do. I suspect that LLMs, too, will be able to kind of model a lot of messy and complicated phenomena, and quite plausibly far better than we can, provided that those world models tend to be useful in next-token prediction.
LLMs Aren't Next-Token Predictors, They Are Next-Token-Prediction Artefacts
Gary Marcus says:
Some things get better as we make these neural network models [bigger], and some don't. The reason that some don't, in particular reliability and truthfulness, is because these systems don't have those models of the world. They're just looking, basically, at autocomplete. They're just trying to autocomplete our sentences. And that's not the depth that we need to actually get to what people call AGI, or artificial general intelligence.
In Shanahan (2022), which, to be clear, is a first-rate paper, written by one who knows far more about AI than I, there's a similar, if subtler, sentiment:
Suppose we give an LLM the prompt "The first person to walk on the Moon was ", and suppose it responds with "Neil Armstrong". What are we really asking here? In an important sense, we are not really asking who was the first person to walk on the Moon. What we are really asking the model is the following question: Given the statistical distribution of words in the vast public corpus of (English) text, what words are most likely to follow the sequence "The first person to walk on the Moon was "? A good reply to this question is "Neil Armstrong".
It's completely true that LLMs are trained on next-token (a token is a word, roughly speaking) prediction (although some, like ChatGPT, are then additionally trained using reinforcement learning with human feedback). It's also completely true that this fact profoundly influences the texts they generate. So I don't think it's unreasonable to call LLMs autocomplete engines or to emphasise next-token prediction. But I think it's subtly misleading:
- Though LLMs were trained to optimise success on next-token prediction, that is not necessarily what they do. We don't know what it is they do. The training process reinforces behaviours/heuristics in the model that tend to cause it to make better next-token predictions on in-distribution data. This does not mean that those behaviours/heuristics are fundamentally "about" optimising next-token prediction, especially when the model encounters out-of-distribution data.[12]
- The usual example here is human evolution. Humans were shaped by a process that optimised for reproductive fitness. This gave us a bundle of drives such as family kinship, prestige and sexual pleasure -- drives that aren't fundamentally about optimising for reproduction, which becomes evident as we enter a new environment -- one with contraceptives, say.
- What's more, optimising for a task for which intelligence is useful encourages the optimised thing to become more intelligent. Sam Altman gave expression to this last week when he wrote, "Language models just being programmed to try to predict the next word is true, but it's not the dunk some people think it is. Animals, including us, are just programmed to try to survive and reproduce, and yet amazingly complex and beautiful stuff comes from it."
- The forms of intelligence that are useful in doing next-token prediction are different from those that are useful in human reproduction, but I think there's a considerable overlap, as (1) some fundamental abilities, for example using and applying concepts, just seem very broadly useful and (2) the data LLMs are trained on are written by humans, for humans and often about humans and things that matter to us. (Jacob Steinhardt makes similar arguments in this post on the Alignment Forum.)
The Chimpanzee Next-Word Predictor Thought Experiment
Here's a thought experiment in that same vein. Imagine a hundred thousand chimpanzees. These chimpanzees spend their entire lives in sensory deprivation chambers, never meeting one another. When they reach adulthood, they're given a set of incomplete texts and asked to predict the next word for each of them. (Suppose that, for each incomplete text, they're given all possible words and must choose one.) These texts are things that humans wrote on the internet from 1991 to 2023. The 1% of chimpanzees that do best on the next-word prediction task get to reproduce -- their sperm/eggs are extracted and children are bred in artificial wombs. Then that entire generation is euthanised. (Yes, this is a terrifying dystopia.) Imagine this procedure goes on for 1T years (for reference, H. sapiens and P. troglodytes diverged about 4-13M years ago).

The question is, what sort of creature would emerge on the other side of this optimisation process? What sort of (cognitive) capabilities would they have? What, if anything, would they know about humans in the year 2023?
Very speculatively, here's a story that seems plausible to me.
At first, the chimpanzees would hardly do better than chance.
Then a mutation causes some chimpanzees to tend to select words like "the" and "a" a lot; these alleles spread quickly through the gene pool.
Other mutations give chimpanzees more elaborate heuristics, such as the tendency to complete "from time to" with "time", or "the Eiffel Tower is in" with "Paris". Yet other mutations allow chimpanzees to recognise the syntax of human languages, and that different symbols stand in different relations to one another: they realise, for example, that "Jeff Bezos is Amazon's CEO" implies that "Amazon's CEO is" should be completed with "Jeff Bezos". Taken together, these heuristics start being functionally indistinguishable from what we call knowledge, use of concepts, inference, deduction, etc. And all of these things are selected for, because they produce chimpanzees that are better able to do next-word prediction, and that is all that matters for their reproductive fitness.
(It's worth noting that chimpanzees are not LLMs, and that evolution is a different optimisation process than stochastic gradient descent. I'm confused which of the disanalogies are relevant here. Clearly I'm assuming that my chimpanzees can acquire knowledge, or something close to it, via genetic mutations. Chimpanzee brains probably don't work that way, but it makes the thought experiment more analogous to LLM training ...)
This goes on and on. Now, what sort of capabilities would this process tend towards? What sort of creature would emerge on the other end of it? What capabilities would help that creature predict next words on human-written texts?
Still more speculatively, I can think of a few things that would help it make such predictions:
- It may have (or at least contain) intimate knowledge (or something similar) of things humans write about on the 1991-2023 internet.
- It may have (...) intimate knowledge (...) of humans who write things on the 1991-2023 internet.
- It may possess a wide range of general reasoning skills.
- It may possess a host of specialised skills aimed at next-word prediction. For example, it may learn how (human) mathematics works, for that allows it to make more accurate predictions on texts that have to do with mathematics.
- It may have the ability and motivation to gain more such knowledge, and to improve its reasoning skills.
- It may have an innate motivation to make next-word predictions, and to make them correctly, and to not die or give up until it has made them.
You may further ask yourself whether, if you took such a creature and gave it a computer in the real world in the year 2024, it would be able to use its evolved (in-distribution) knowledge, or its hard-earned talents, in that new (out-of-distribution) environment. Perhaps its inability to verify things, being hampered by its only seeing the world through text, is fatal. Perhaps it would try to influence the world in order make successful next-token predictions (or whatever else it yearns for, if it yearns at all) easier and more plentiful. These are all, in my opinion, open questions. Put differently, I don't know whether LLMs, as currently built, will ever scale to general intelligence or whether they will be limited by the world (text) or way (next-token prediction) in which they're trained; maybe it takes multimodal systems for that, or something else, or maybe it will never be possible.
Reasons for Caution
Either way, I think it pays off to exercise unusual caution when thinking about LLMs -- both when forecasting LLM capabilities (time and again such predictions have turned out to be wrong) and when assuming that such-and-such a thing must or cannot possibly happen inside an LLM.
In Landgrebe and Smith (2021), for example, we find this passage:
[A]ll stochastic models require a stable environment. The quality of their output depends on how well they reflect the real-world input-output relationship they are aiming to represent. [...] [E]ven where the relationship is stable, the model will quickly become invalid if the input-output relationship changes on either side even in some minor way. This is because the model does not generalise. Once fed with data as input that do not correspond to the distribution it was trained with, the model will fail.
But this is, at least in some cases, wrong. ML models, and language models in particular, can clearly generalise. We've seen that, for example, in the modular/binary addition models mentioned above. It's true, of course, that they don't always generalise perfectly. That is the engineering problem that ML researchers are working on. But as stated this passage was wrong in 2021, and it's equally wrong now.
Sticking with the same paper, Landgrebe and Smith (2021) argues:
[Deep neural networks] are also unable to perform the sorts of inferences that are required for contextual sentence interpretation. The problem is exemplified by the following simple example:
"The cat caught the mouse because it was slow" vs.
"The cat caught the mouse because it was quick."
What is the "it" in each of these sentences? To resolve anaphora requires inference using world knowledge -- here: about persistence of object identity, catching, speed, roles of predator and prey, and so forth. Thus far, however, little effort has been invested into discovering how one might engineer such prior knowledge into [deep neural networks] (if indeed this is possible at all). The result is that, with the exception of game-like situations in which training material can be generated synthetically, esp. in reinforcement learning, [deep neural network] models built for all current applications are still very weak, as they can only learn from the extremely narrow correlations available in just that set of annotated training material on the basis of which they were created. Even putting many [deep neural network] models together in what are called "ensembles" does not overcome the problem.
That, on the other hand, was true in 2021, but today:
ME: What is the "it" in each of these two sentences?
- "The cat caught the mouse because it was slow."
- "The cat caught the mouse because it was fast."
CHATGPT: In the first sentence, "it" refers to the mouse, which is slow and was therefore caught by the cat. In the second sentence, "it" refers to the cat, which is fast and was therefore able to catch the mouse.
(The text-davinci-003 version of GPT-3 still seems to fail at this task, but davinci-instruct-beta succeeds, so the improvement may come from the fine tuning on human examples done for davinci-instruct-beta and/or the reinforcement learning on human feedback done for the model ChatGPT uses, gpt-3.5-turbo. Notably, gpt-3.5-turbo still fails a subtly harder version of this test.[13])
I, too, am vulnerable to overconfidence. When I first heard of Meng et al. (2022), in which the part of an LLM storing the "Eiffel Tower → Paris" association is modified to be "Eiffel Tower → Rome" instead, causing the model to output things like "The Eiffel Tower is right across from St. Peter's Basilica in Rome, Italy", I thought this was pretty conclusive evidence that LLMs do have and use something very like human concepts. But then I read Jacques Thibodeau's post, showing, among other things, that the edit (1) is not bidirectional (e.g., the LLM doesn't seem to identify the famous tower in Rome as the Eiffel Tower) and (2) doesn't seem responsive to prompts that don't explicitly mention the phrase "Eiffel Tower". The lesson here is that LLMs are strange, complex and unhuman.
"If We Ever Succeed [...] It Must Be by Reducing Y to 'Just X'"
Back in 2020 (a lifetime ago!) Gwern wrote,
The temptation, that many do not resist so much as revel in, is to give in to a déformation professionnelle and dismiss any model as "just" this or that ("just billions of IF statements" or "just a bunch of multiplications" or "just millions of memorized web pages"), missing the forest for the trees, as Moravec commented of chess engines:
"The event was notable for many reasons, but one especially is of interest here. Several times during both matches, Kasparov reported signs of mind in the machine. At times in the second tournament, he worried there might be humans behind the scenes, feeding Deep Blue strategic insights! [...] In all other chess computers, he reports a mechanical predictability stemming from their undiscriminating but limited lookahead, and absence of long-term strategy. In Deep Blue, to his consternation, he saw instead an "alien intelligence".
[...] Deep Blue's creators know its quantitative superiority over other chess machines intimately, but lack the chess understanding to share Kasparov's deep appreciation of the difference in the quality of its play. I think this dichotomy will show up increasingly in coming years. Engineers who know the mechanism of advanced robots most intimately will be the last to admit they have real minds. From the inside, robots will indisputably be machines, acting according to mechanical principles, however elaborately layered. Only on the outside, where they can be appreciated as a whole, will the impression of intelligence emerge. A human brain, too, does not exhibit the intelligence under a neurobiologist's microscope that it does participating in a lively conversation."
But of course, if we ever succeed in AI, or in reductionism in general, it must be by reducing Y to "just X". Showing that some task requiring intelligence can be solved by a well-defined algorithm with no "intelligence" is precisely what success must look like! (Otherwise, the question has been thoroughly begged & the problem has only been pushed elsewhere; computer chips are made of transistors, not especially tiny homunculi.)
Next-word-predicting chimpanzees is a faulty metaphor. I readily grant that. In fact, every metaphor for LLMs that I've come across has been wrong and ridiculous: there are illustrative metaphors for LLMs, but no true ones. The best I can think of is also wrong, but at least carries the message that we don't know how these systems really work, namely, that we are looking at great computational clouds.
Thanks to Oliver Guest for giving feedback on a draft.
References
Abdou, Mostafa, Artur Kulmizev, Daniel Hershcovich, Stella Frank, Ellie Pavlick, and Anders Søgaard. 2021. “Can Language Models Encode Perceptual Structure without Grounding? a Case Study in Color.” arXiv. https://doi.org/10.48550/ARXIV.2109.06129
Elhage, Nelson, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, et al. 2021. “A Mathematical Framework for Transformer Circuits.” Transformer Circuits Thread.
Landgrebe, Jobst, and Barry Smith. 2021. “Making Ai Meaningful Again.” Synthese 198: 2061--81.
Lewkowycz, Aitor, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, et al. 2022. “Solving Quantitative Reasoning Problems with Language Models.” arXiv. https://doi.org/10.48550/ARXIV.2206.14858
Li, Belinda Z., Maxwell Nye, and Jacob Andreas. 2021. “Implicit Representations of Meaning in Neural Language Models.” arXiv. https://doi.org/10.48550/ARXIV.2106.00737
Li, Kenneth, Aspen K. Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2022. “Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task.” arXiv. https://doi.org/10.48550/ARXIV.2210.13382
Meng, Kevin, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. “Locating and Editing Factual Associations in Gpt.” arXiv. https://doi.org/10.48550/ARXIV.2202.05262
Nanda, Neel, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. 2023. “Progress Measures for Grokking via Mechanistic Interpretability.” arXiv. https://doi.org/10.48550/ARXIV.2301.05217
Olsson, Catherine, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, et al. 2022. “In-Context Learning and Induction Heads.” Transformer Circuits Thread.
Patel, Roma, and Ellie Pavlick. 2022. “Mapping Language Models to Grounded Conceptual Spaces.” In International Conference on Learning Representations. https://openreview.net/forum?id=gJcEM8sxHK.
Power, Alethea, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. 2022. “Grokking: Generalization beyond Overfitting on Small Algorithmic Datasets.” arXiv. https://doi.org/10.48550/ARXIV.2201.02177
Shanahan, Murray. 2022. “Talking About Large Language Models.” Arxiv Preprint Arxiv:2212.03551.
Srivastava, Aarohi, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, et al. 2022. “Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models.” arXiv. https://doi.org/10.48550/ARXIV.2206.04615
Toshniwal, Shubham, Sam Wiseman, Karen Livescu, and Kevin Gimpel. 2021. “Chess as a Testbed for Language Model State Tracking.” arXiv. https://doi.org/10.48550/ARXIV.2102.13249
Wei, Jason, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, et al. 2022. “Emergent Abilities of Large Language Models.” arXiv. https://doi.org/10.48550/ARXIV.2206.07682


I think the attitudes described are a reaction, perhaps an overreaction, to people being overly impressed at mundane behaviors of Chatgpt.
For example, I've seen people on twitter who are impressed that chatgpt can "solve the Monty Hall problem". This is actually a fairly mundane achievement, given that there are probably thousands of detailed examples on the monty hall out on the internet. This is a good example of parrot behavior being mistaken for complex thought.
On the other hand, passing the "dumb monty hall" problem, which is phrased the same as the old one except the doors are transparent, would sound less impressive to the layman, but would actually be a significantly greater achievement. (that is, until the problem got absorbed into it's training set). I'm curious to see how long it takes before LLM's can reliably solve these kinds of anti-riddles.
Interestingly, I asked chatgpt the original riddle and then the anti-riddle, and it detected a change, and tried (but failed) to respond accordingly:
In this case, it's acting more than just parrot-like, but still failing to produce an accurate answer.
Yeah, it's definitely plausible to me that current LLMs are generally less capable than impressive (by some measurements of those), and/or that people overestimate their capabilities. It's also plausible to me that people anthropomorphize LLMs in ways that definitely aren't warranted. (By "people", I guess I mean the median Twitter user or the median EA, maybe not the median AI safety or ML researcher.)
On anti-riddles, I found the Inverse Scaling Prize winners pretty interesting -- seems related.
Bing definitely "helps" people to over-anthropomorphise it by actively corroborating that it has emotions (via self-report and over-use of emojis), consciousness, etc.