For those who aren't regular readers of alignmentforum or lesswrong, I’ve been writing a 15-part post series “Intro to Brain-Like-AGI Safety”. And the final post is now posted! 🥳🎉🎊
We know enough neuroscience to say concrete things about what “brain-like AGI” would look like (Posts #1–#9);
In particular, while “brain-like AGI” would be different from any known algorithm, its safety-relevant aspects would have much in common with actor-critic model-based reinforcement learning with a multi-dimensional value function (Posts #6, #8, #9);
“Understanding the brain well enough to make brain-like AGI” is a dramatically easier task than “understanding the brain” full stop—if the former is loosely analogous to knowing how to train a ConvNet, then the latter would be loosely analogous to knowing how to train a ConvNet, and achieving full mechanistic interpretability of the resulting trained model, and understanding every aspect of integrated circuit physics and engineering, etc. Indeed, making brain-like AGI should not be thought of as a far-off sci-fi hypothetical, but rather as an ongoing project which may well reach completion within the next decade or two (Posts #2–#3);
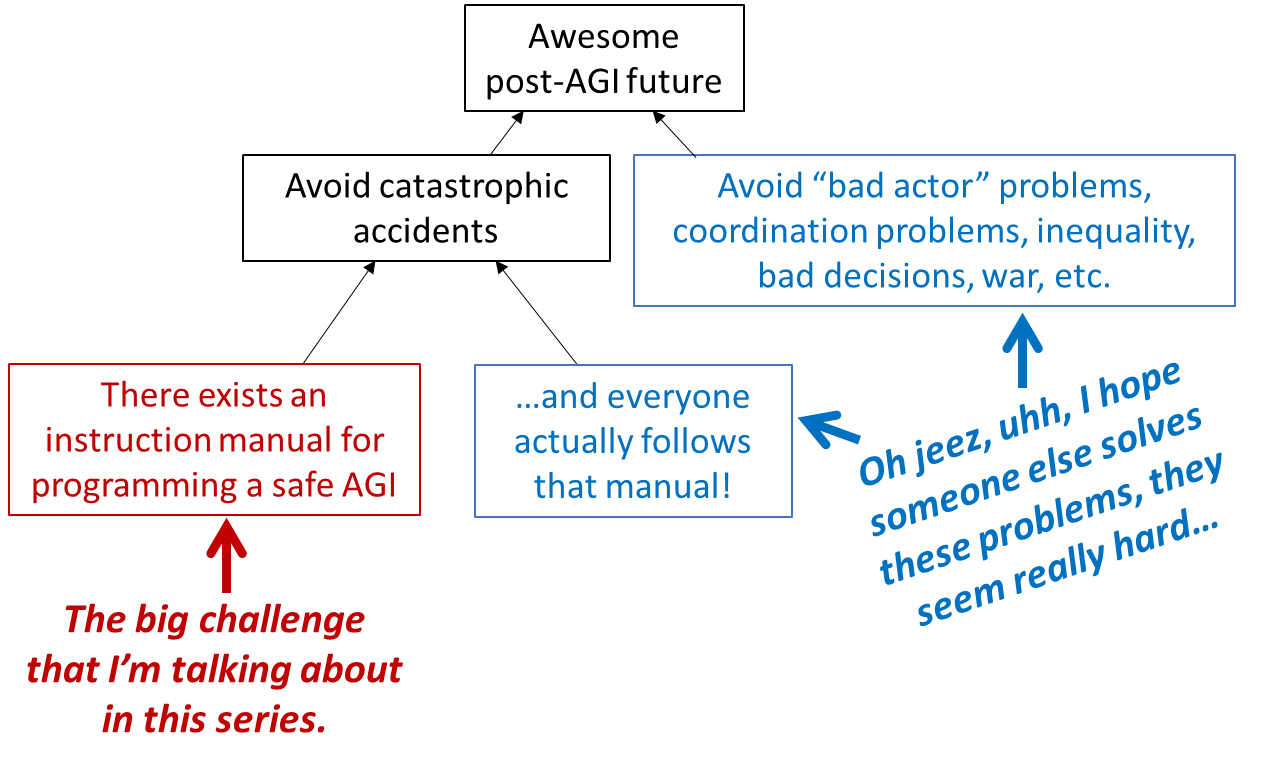
In the absence of a good technical plan for avoiding accidents, researchers experimenting with brain-like AGI algorithms will probably accidentally create out-of-control AGIs, with catastrophic consequences up to and including human extinction (Posts #1, #3, #10, #11);
Right now, we don’t have any good technical plan for avoiding out-of-control AGI accidents (Posts #10–#14);
Creating such a plan seems neither to be straightforward, nor to be a necessary step on the path to creating powerful brain-like AGIs—and therefore we shouldn’t assume that such a plan will be created in the future “by default” (Post #3);
There’s a lot of work that we can do right now to help make progress towards such a plan (Posts #12–#15).
General notes
The series has a total length comparable to a 300-page book. But I tried to make to easy to skim and skip around. In particular, every post starts with a summary and table of contents.
The last post lists seven open problems / projects that I think would help with brain-like-AGI safety. I’d be delighted to discuss these more and flesh them out with potential researchers, potential funders, people who think they’re stupid or counterproductive, etc.
General discussion is welcome here, or at the last post, or you can reach out to me by email. :-)
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...