Comments
This post is co-authored with Ben Garfinkel. It is cross-posted from the CEA blog. A PDF version can be found here.
Summary: Some strategic decisions available to the effective altruism m...

This post is written in response to @Austin's open call for approaches for allocating exponentially growing funding to mitigate AI risk
AI presents a civilizational-scale threat. There are many ways for things to go wrong: systems pursuing misaligned objectives at scale, authoritarian capture of advanced models, geopolitical arms races culminating in catastrophic outcomes, and oligarchic power concentration severe enough that most humans become economically redundant and politically powerless. The list goes on.
These risks are heterogeneous. They arise through different causal pathways and require different kinds of interventions. Any serious response must hold this diversity in view.
Effective altruism (EA) has been attempting exactly this. But until recently, constraints were primarily financial and human: too little capital, too few researchers, too little coordination bandwidth.
The financial constraint is changing.
AI safety is entering a phase of funding abundance. Capital flows into the space are increasing rapidly, with foundation allocations rising into the billions and additional large-scale funding likely as Anthropic heads for an IPO. The field is transitioning from scarcity to abundance faster than its evaluative infrastructure is adapting.
And this shift changes the failure mode for achieving AI safety.
When funding is scarce, the dominant risk is commission: funding the wrong things. When funding is abundant, the dominant risk becomes omission: failing to fund the right things because they do not fit existing evaluation frameworks. William MacAskill pointed toward this during earlier funding windfalls in 2022.
The constraint is no longer identifying the best marginal dollar, but ensuring EA does not systematically miss entire categories of value-producing work.
This essay is about that second problem—solving mistakes of omission.
If we assume short timelines to advanced AI, the appropriate response is not concentration of funding into a single theory of change, but diversification across uncorrelated approaches.
This is a direct application of portfolio theory to civilizational-stakes uncertainty.
One dominant frame in EA is expected-value optimization: identify the intervention with the highest estimated return and fund it. This works well in domains where structure is stable, and outcomes are legible.
But AI safety operates in a complex landscape— interventions change the system they intervene in, feedback loops are delayed, and causal structure shifts as the system evolves.
In such environments, optimization over fixed models becomes fragile.
A complementary appropriate frame from complexity science, popularized by Dave Snowden, is “probe–sense–respond”: deploy diverse weakly correlated experiments, observe what emerges, and adapt quickly. This is not anti-optimization; it is optimization under conditions where the model itself is unstable.
The implication for funding is significant. Expected-value reasoning tends to concentrate capital into a small number of high-confidence interventions. Complexity-aware reasoning distributes capital across a broader set of exploratory probes.
A strict expected-value frame treats “good answer” as the option with the highest expected value minus cost. A more robust approach under complexity might treat a “good answer” as the option that survives the widest range of plausible futures, even if its median return is lower.
Both are rational. But current funding systems tend to overweight the former. The result is not inefficiency in individual grants, but systematic under-exploration of the solution space.
This is the first layer of omission.
But “uncorrelated bets” does not simply mean funding different projects. It means funding approaches that differ in their epistemology, worldview, and ways of knowing. I will define each of them in turn.
I will further argue that approaches which differ in the 3 key ways above are currently systemically underfunded due to their unfamiliarity and illegibility to EA. Thus, EA will need to devise new ways of evaluating projects if it wants a truly uncorrelated portfolio. This is not a call to abandon rigour, but to have a multi-faceted, contextual approach to it.
By epistemic diversity, I mean the coexistence within a funding process of multiple knowledge systems and problem-solving perspectives, including what constitutes a good answer.
A relevant example here is how systems thinking surfaces interventions that technical-alignment-focused work misses. AI alignment is, at a deeper layer, a problem of civilizational alignment.
Who gets a seat at the table when a technology this consequential is being built? How do we agree on what is good? How do we allocate resources? These are questions of power and politics. The best historical answer is democracy—which isn’t perfect, but is the most robust mechanism we have for preventing a single worldview from making civilization-scale decisions for everyone.
And democracy is currently in trouble, and that means this particular load-bearing answer to AI risk is in trouble. V-Dem’s 2026 Democracy Report shows democracy is in decline across most of the world. Autocracy is on the rise. Concentrated capital is leading to system capture. If the democratic system were functioning — responsive, informed, reflective of diverse interests — we could trust it to regulate AI within its geographic bounds. But it is not.
Which means strengthening democratic capacity — through interventions like citizens’ assemblies, campaign-finance reform, or viable third-party infrastructure — isn’t a separate domain from AI safety; it is one of its load-bearing legs. This is not theoretical: Taiwan’s digital governance initiatives and Ireland’s citizens’ assembly on abortion laws both demonstrate ways forward for more direct democracy.
On the global scale, the same logic applies: an international system with meaningful enforcement capacity could develop AI as a global public good and defuse the arms-race dynamic that drives risk higher each quarter.
Systems thinking surfaces these interventions. Technical-alignment-only framing misses them.
The second kind of diversity is deeper. By worldview, I mean the basic lens through which a person sees reality, including what they take the world to be for, what kinds of relationships they assume they are in, and what kinds of actions feel appropriate within those relationships.
One distinction is worth naming up front, because it is easy to conflate with what EA already does. When Coefficient Giving talks about worldview diversification — funding Global Health, Global Catastrophic Risk, Scientific Progress, and Animal-Inclusive as separate portfolios — the worldviews being diversified are primarily differences in cause prioritization. These sit within a shared deeper frame. All four operate within a broadly utilitarian, outcomes-measurable, rationalist epistemology.
The underlying disagreements are largely about weighting: present vs. future humans, human vs. non-human suffering, speculative high-stakes futures vs. near-term high-confidence interventions.
These are real and important choices, and the framework is extremely powerful. But the worldview diversity I am pointing to operates at a deeper level. It is not only about what we value more. It is about whether we relate to the world primarily instrumentally or relationally, and how that shapes what kinds of action even make sense.
Consider the case of the environment and sustainability. An instrumental worldview treats the world as something to be used in service of human ends: resources to be optimized, systems to be controlled, outcomes to be engineered.
Under this worldview, it is still possible to be sustainable. We protect ecosystems because we depend on them. We avoid collapse because it would harm us. Environment as instrument.
Under this same worldview, it is natural to treat AI as a tool designed to execute human intent. Alignment becomes a control problem: ensure the system obeys constraints and produces desired outputs.
This naturally leads to:
Failure modes are framed as loss of control or specification error.
Now consider a relational worldview.
Here, the key shift is not about what the world is made of, but about how one is oriented toward it. The world is not only something to be used, but something one is in a relationship with. Action is not only about extracting outcomes, but about maintaining the integrity of that relationship.
In this worldview, one takes sustainable actions because one considers the environment to have intrinsic worth. Sustainability is not only constraint satisfaction. It becomes a matter of care: a constraint that arises from the nature of the relationship itself.
Now, one can rightly say either worldview protects the environment— so does the worldview make a difference?
It does. The person holding the instrumental is more likely to be reactive vs proactive in protecting the environment—because the primary concern is for the self and not the environment. The environment is protected if and only if not protecting it harms us. The person with a relational worldview proceeds with far more care before acting because he cares about the environment itself. Problems an instrumental framing might address after they arise, a relational framing might prevent from arising in the first place.
This is the sense in which relationality produces care— treating something as relational changes what kinds of actions feel permissible in the first place.
This is critical in the case of a powerful super-intelligence. If it is trained purely within an instrumental framing, it may treat human well-being as a constraint to be satisfied, rather than something to be cared about.
While a relational frame might lead it to actively, dynamically consider what would be good for us and ideally figure it out with us, while caring for us.
This raises a different kind of alignment question: not just whether systems follow rules, but whether they develop stable tendencies that generalize toward care across situations.
“They have been focusing on making these things more intelligent. But intelligence is just one part of a being. We need to make them have empathy towards us. And we don’t know how to do that yet. But evolution managed and we should be able to do it too. “
Under this framing, alignment shifts.
It is no longer only: how do we constrain outputs?
It becomes: how do we shape systems so that harmful action toward humans is not even a “valid move” within the learned stance of the system?
This leads to:
And while I have focused on instrumental vs relational worldview in this section, there are many different types of worldview this point applies to. @Joe_Carlsmith, who works on Claude’s constitution at Anthropic, brings a related but distinct axis to the same problem—what he describes as yin (receptive, trusting) and yang (active, controlling) orientations.
In Deep Atheism and AI Risk, Carlsmith identifies a particular existential posture he calls “deep atheism,” which aligns with the yang orientation: a stance in which reality is not assumed to be safe or aligned with our values, and where ensuring good outcomes requires active control, vigilance, and responsibility.
He contrasts this with a more yin-like orientation—one that allows for receptivity, trust, and being guided by what emerges—but treats it cautiously, noting the risks of misplaced trust.
Carlsmith is not saying one of these orientations is correct, but that each makes different approaches to alignment more or less visible. And this is a critical point. I am not advocating for one approach to AI alignment over another. Each approach has its strengths, and diverse approaches are best used as complements. I am merely advocating for expanding our option set.
Worldview differences don’t just lead to different technical methods. They lead to different answers to what alignment is.
In practice, funding systems tend to privilege approaches that are easier to specify and evaluate in advance, which systematically favors instrumental framings and under-selects relational ones. This is the second layer of omission. Not through explicit rejection, but through structural invisibility.
Making uncorrelated bets would require EA to uncover and include as many of these worldview axes as possible.
A third layer concerns what kinds of knowledge can even be recognized during grant evaluation.
The cognitive scientist John Vervaeke names ways of knowing.
Propositional knowing is what you can state in sentences: that the Earth orbits the Sun.
Procedural knowing is the knowledge of doing: how to ride a bicycle, which you can’t acquire by reading a treatise on balance.
Perspectival knowing is what you grasp from inside a particular standpoint: what it is like to be in a situation, seen from the specific place where you stand.
Participatory knowing is what emerges through sustained engagement with a role, a practice, or a context: the knowing that comes from being shaped by what you know.
Most funding systems are optimized for propositional knowledge: claims that can be specified, measured, and evaluated at the time of grantmaking.
But some alignment-relevant knowledge is not accessible in that form. It is participatory: it emerges through sustained interaction with systems, groups, and processes.
For example, in work by Anthropic and the Collective Intelligence Project, large-scale participatory processes were used to co-create constitutions for model behavior. 1000 representative Americans contributed 1127 statements about principles for the behaviour of AI and cast 38,252 votes using the deliberative platform Polis. The model using this constitution was as capable as the one using a constitution developed by internal experts, but showed less bias than it. This work is already familiar within EA circles, with Jaan Tallinn quoting it as an inspiring example of a constructive effort to mitigate AI risk.
This is evidence that AI alignment research can benefit from incorporating more diverse ways of knowing.
It is hard to know what kind of outputs this will produce, since this is fundamentally about augmenting our cognition and collective problem-solving ability. This means the value of the intervention is not fully knowable at proposal time. It depends on emergent properties.
This creates a structural mismatch: if funding decisions require fully specified outcomes in advance, then interventions whose value only becomes visible through execution are systematically under-selected.
This is the third layer of omission. Again, the example I used is illustrative and EA will benefit from expanding its solution set to include all ways of knowing. It can lead to some non-obvious interventions, like using mindfulness training to improve the problem-solving ability of AI safety researchers.
These three layers—epistemics, worldviews, and ways of knowing—all face a shared constraint: legibility.
Funding systems require justification at the time of allocation. This is necessary for accountability. But it introduces a structural bias toward interventions that are clearly specified, easily comparable, and defensible in advance.
This is not a mistake in the system. It is the result of institutional design pressures: reputational risk, audit requirements, and the need for scalable decision-making in large capital pools. This is the diagnosis Oliver Habryka has been making publicly for the better part of a year.
These constraints produce a predictable selection effect.
It systematically disadvantages interventions that are emergent rather than fully specified, participatory rather than top-down, or exploratory rather than optimized,
They are rejected not because they are deemed inferior, but because they are harder to evaluate before they are run.
Individually, each exclusion is defensible. Collectively, they hamper our ability to tackle AI alignment.
The result is not just a failure to fund good ideas. It is a failure to even see certain types of ideas as fundable.
If we take uncertainty seriously, the appropriate response is not better selection within existing frameworks. It is expanding the framework itself. The current centralized grantmaking capacity at leading funders is already constrained. So we need to come up with a smarter system that addresses those constraints.
The following are concrete directions for expanding the current funding model. Each of these is the seed of an idea and will require more work to develop further. My aim in sharing these is to stimulate imagination, not provide a final process design.
Fund small, diverse bets across under-recognized paradigms through regrantors
Regranting addresses the institutional capacity constraint. Individual regrantors with smaller budgets and more diverse priors can also fund work that central evaluators cannot easily defend at scale. Manifund is a great example of this approach
A co-creation lab bringing together participants with diverse epistemics, worldviews, expertise, and ways of knowing
Run a 1-3 month fellowship/co-creation lab with a diverse team that surfaces approaches that no single background team would come up with alone. This also builds EA’s familiarity with approaches that are not fully legible under the current system. EA can subsequently put out a request for proposals for lead approaches or recruit a team to work on it.
Pre-commit to evaluation criteria at the time of funding, not application
This moves the legibility and rigor gate further downstream, allowing more diverse proposals to be considered.
Run 3-6 months fellowships to recruit diverse grantmakers
Bring together diverse practitioners and train them in diverse epistemologies, worldviews, ways of knowing, and grantmaking to scale up institutional capacity
In each case, the intervention should be re-evaluated after a fixed period of 6-12 months based on observed outcomes. Interventions that demonstrate unexpected or emergent value should be scaled up.
This shifts the system from predicting upfront to learning from what actually happens. And makes rigour contextual and responsive to the problem space.
This, of course, leaves open the question of where EA can find these diverse practitioners in the first place. Integral altruism is a community of EAs already familiar with these approaches and could serve as a potential bridge. Second Renaissance is another, though probably less familiar to EA.
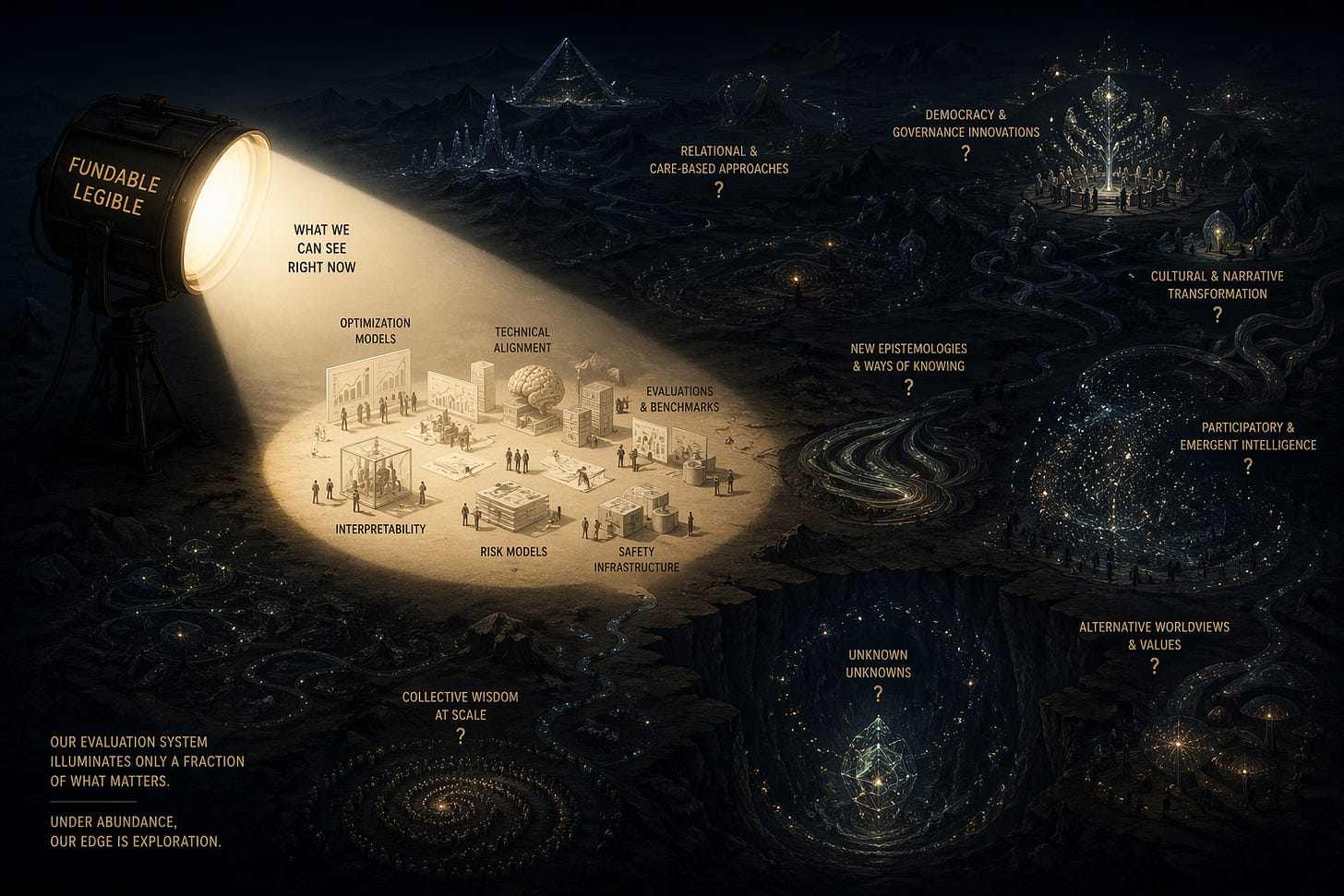
The central claim of this essay is simple:
Under conditions of increasing capital abundance and limited time, the primary failure mode in AI safety funding is not misallocation—it is omission.
And omission is not random. It is structured by:
These layers jointly define the boundary of what is fundable.
Expanding that boundary does not require abandoning rigor. It requires recognizing that rigor itself currently operates inside a narrower space than the problem demands.
The stakes of advanced AI development are too high for our response to be limited to what is already legible.
The question is not whether we can fund the best ideas we already understand.
It is whether we can build a system capable of recognizing the value of ideas we do not yet fully understand—and funding them well enough to find out.
The infrastructure EA has built so far is a serious beginning. The next move is to extend it. It will require becoming familiar with stranger toolkits, and inventing new ones. Under abundance, the question is no longer whether we can afford to explore these approaches. It is whether we can afford not to. I invite EA to fully step into the unknown.
