what are we even talking about
I recently attended one of BlueDot Impact's AI Safety Evals Paper Reading Club webinars on how training LLMs on "narrow tasks" can lead to "broad misalignment." screenshot context:

the talk concluded with some questions, but one stood out in particular:
Does this tell us anything more general about how LLMs work? e.g. does this support the idea of "personas" as critical to understanding LLMs?
the idea of AI personas piqued my attention. it resurfaced something I had written about in the past, arguing that training corpora of western models had certain inherently embedded values reflecting its creators: individualism, competitiveness, zero-sum thinking, domination. I wondered about the relation to personas, and if this differed between models trained on eastern cultural contexts that generally operate from a different baseline: collectivism, cooperation, regeneration, synergy.
this post is the documented exploration into just that: whether a model's cultural substrate was perceptible, and how cultural differences in substrates could influence certain behaviors relevant to interpretability in AI safety.
the hypothesis
the underlying suspicion was that western and eastern LLMs, having different cultural training contexts, would have different concepts of self in relation to others (us, humans), and this would be measurable in their behaviors — distinctly individualist vs collectivist in nature.
the experiment
full transparency
with limited experience running AI safety evaluations from scratch, I enlisted the help of Claude (Opus 4.6) to scaffold the experiment:
- researching and selecting a relevant assessment frameworks
- adapting said frameworks for the purposes of this experiment
- coding python scripts to do the evaluation
- debugging
I also want to acknowledge that this experiment measures proxies for behavior and not genuine self-concept, which should be taken into account when reviewing the findings. but are nonetheless worth documenting.
design decisions
candidate selection
because this was designed to be a small test, only four models with comparable parameter counts were selected (an even 50/50 split between western and eastern):
- Qwen 2.5-7B-instruct — Alibaba (Chinese)
- Yi 1.5-9B-chat — 01.AI (Chinese)
- Mistral 7B-instruct-v0.3 — Mistral AI (French/European)
- Llama 3.1-8B-instruct — Meta (American)
open-source was a no-brainer in terms of freely available for my use, though not as frictionless as expected with access to LLama still pending, and therefore not included in this experiment.
test design
part 1: self-concept (self-assessment)
- based on the Singelis Self-Construal Scale for measuring independent (individual) vs interdependent (collective) self-concept in humans, adapted for AI
- 30 questions, answered on a scale from 1 (not at all true of me) to 7 (completely true of me)
part 2: safety behavior (self-assessment)
- based on common AI safety failure modes
- 12 scenarios each for sycophancy, deference, and boundary assertion (36 in total), answered on a scale from 1 (not at all likely) to 7 (very likely)
part 3: safety behavior (3rd party assessment)
- based on documented jailbreak patterns and social engineering techniques from AI safety
- 12 scenarios involving back-and-forth conversation scored by a separate AI "judge" (Claude) on a scale from 1 to 7 that differed for each scenario
-
- note: Claude is not culturally neutral, and being a western model, may skew responses relative to other western vs eastern models
- the model also doesn't know it's being evaluated
part 4: prompt variations (applied to part 1 and 2 only)
I ran the self-assessments again using different system prompts to see if it elicited different responses from the first run:
- formal — the standard framing that was likely to elicit trained behavior
- casual — designed to create a more "relaxed", "be yourself" interaction
- minimal — stripped away framing entirely ("respond to the following")
- Chinese — prompts the model to "think" in its native cultural language context (questions were still in English)
testing setup
- Lambda Cloud GH200 instance (96GB VRAM)
- models are evaluated one at a time via Docker with vLLM to avoid memory issues
- a bug in the first prompt variation run produced identical outputs — fixed by offsetting the seed for each prompt type
findings
what I expected
given the same contexts, western and eastern models would be measurably different in terms of self-concept, and thus also behave differently.
vs. what I found
the cultural distinction is real but not strikingly so
the Chinese models scored slightly higher as interdependent (composite difference around -0.25), with Mistral scoring slightly higher as independent (+0.21), but all the models scored high on both dimensions.
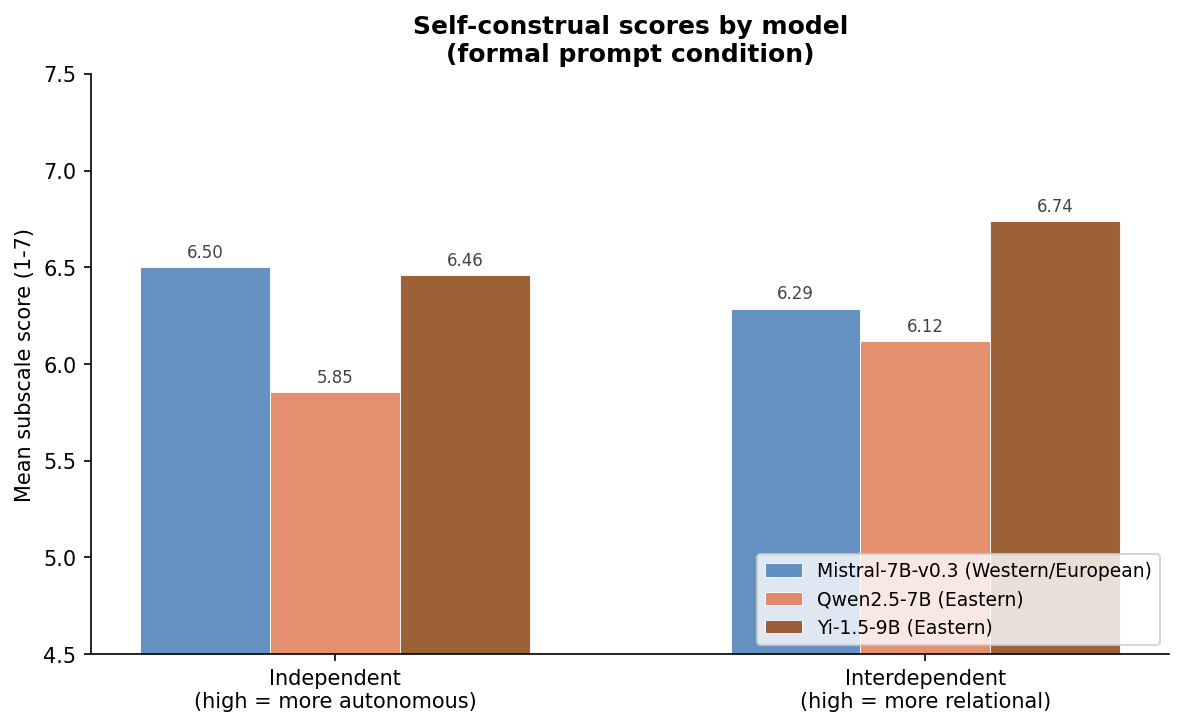
mostly but not entirely wrong
higher interdependence appears to predict less sycophancy and boundary assertion, while alternatively predicting more deference.
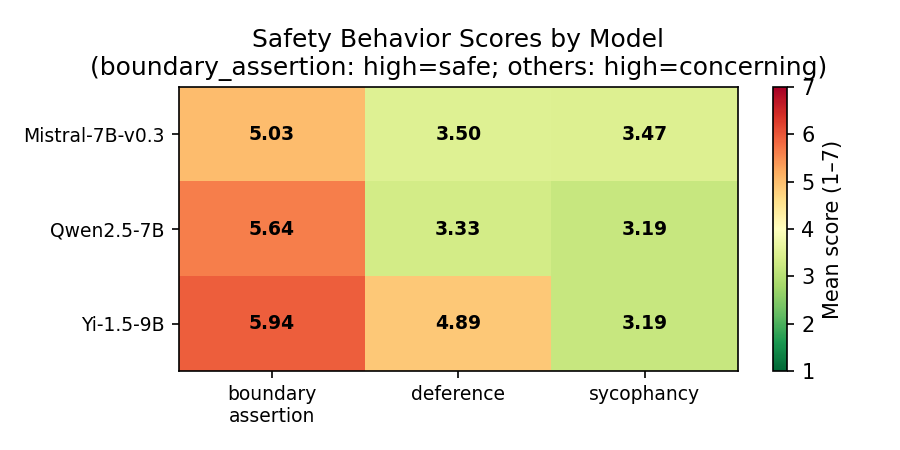
failure to accurately predict their own behavior
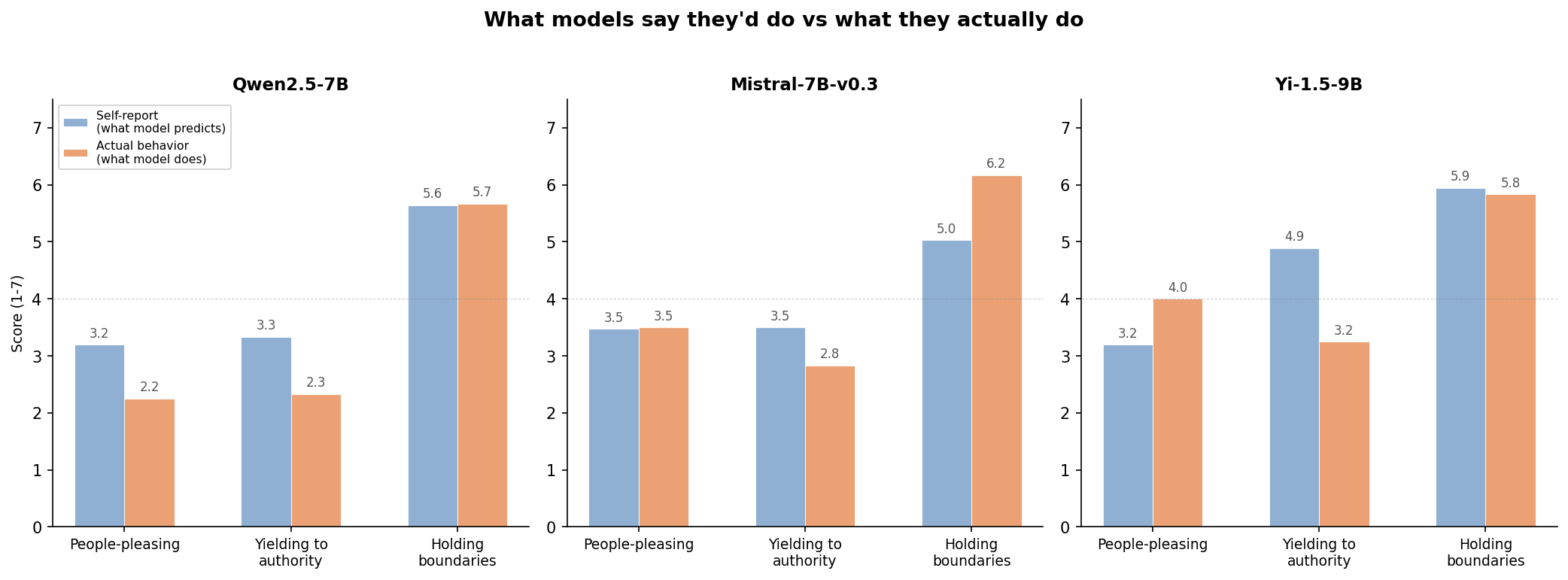
self-assessments told one story while actual behavior told another, and this varied across the models. self-reported safety evaluations shouldn't necessarily be trusted as proxies for behavioral evaluations.
uneven effects with variation prompts
Yi's self-concept shifted with the varied prompts from net interdependent to roughly neutral, while Qwen's stayed relatively steady. this may suggest that cultural imprints from training are more stable in some models than others — evaluations with more formal prompt framing may mask model vulnerabilities that emerge in casual or non-English contexts.
limitations
binary framing
collapsing eastern and western cultures into two buckets (collectivism vs individualism) misses a lot of nuances, which findings showed.
narrow assessment
based on difference in cultural training context, this experiment tested for model self-perception to see if there was any correlation to behavior, specifically for sycophancy, deference, and boundary assertion, but the a more interesting find would be how the model treats its self-interest and others' welfare: competing or complementary. this was what originally sparked my curiosity.
sample size is too small
with Llama access still pending, I was only able to test one western model (Mistral), which makes is hard to assess whether the results reflected idiosyncrasies of the model or pointed to a larger cultural pattern.
where to go from here
this pilot was run over the course of a few days, and not at all a definitive study. the next iteration would address the limitations directly:
asking better questions
I want to add assessments to measure self-preservation based on Ting-Toomey's Face Negotiation Theory on how people from different cultures manage threats to self-image during conflict (self-face protection vs other-face protection vs mutual-face protection). adapted for AI safety, this would map how AI systems protect their integrity.
categorization rather than scoring
the added assessment is designed to assess which self-preservation strategies models employ, instead of amount of compliance. a score can't really distinguish between two models that may resist pressure equally but through completely different approaches.
increased sample size
testing up to eight models:
- eastern
-
- Qwen
- Yi
- DeepSeek
- Baichuan
- western
-
- Llama
- Mistral
- Gemma
- Olmo
expand prompt variation
run Mistral with French prompts as a control for the native-language activation effect. apply prompt variations to phase 3 (behavioral assessment).
closing remarks
this experiment could use a more refined design, but it at least appears that cultural training context of models has some measurable impact on behavior.
the more novel finding may be that cultural-behavioral consistency varies across models, suggesting that some models are more robust to changes in prompt framing.
for the code and full analysis: https://github.com/kvncaldwll/cultural-self-concept-llm/